 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
IterMVS: Iterative Probability Estimation for Efficient Multi-View Stereo
Dec 09, 2021
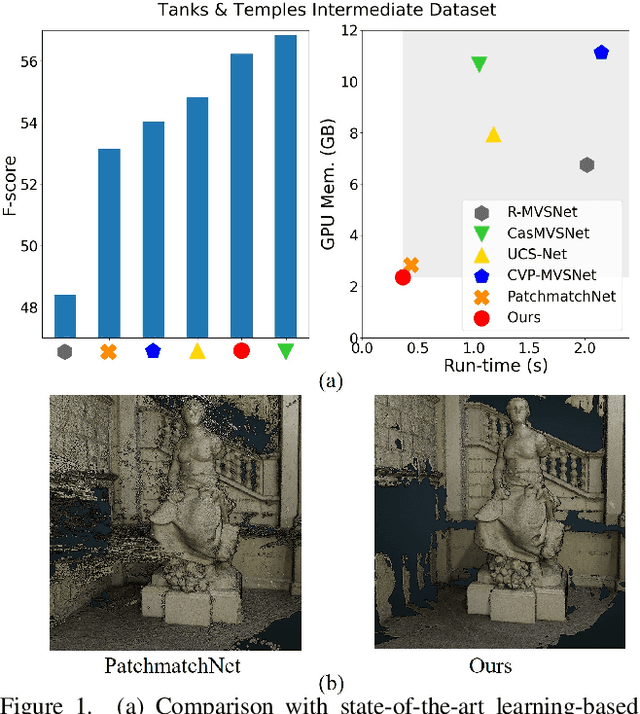
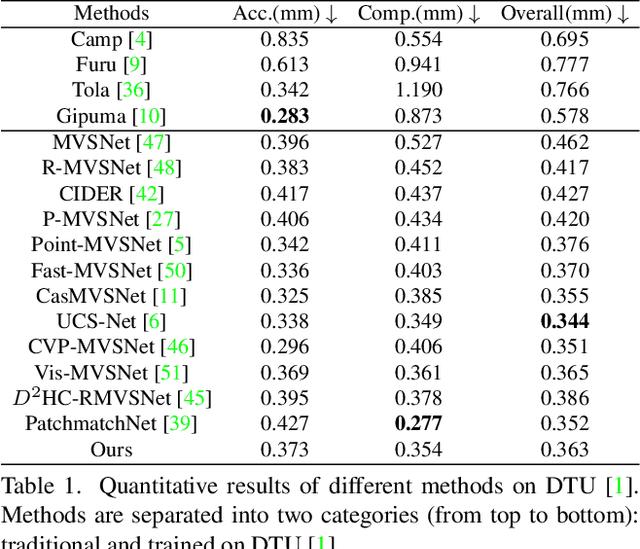

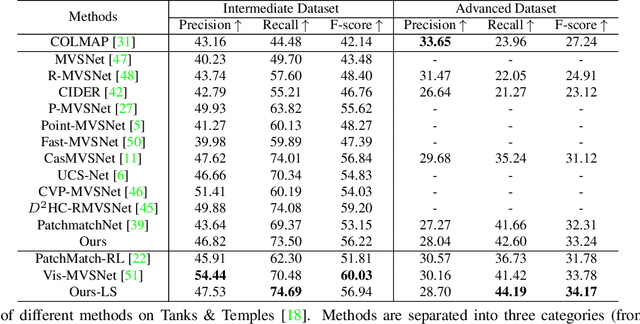
We present IterMVS, a new data-driven method for high-resolution multi-view stereo. We propose a novel GRU-based estimator that encodes pixel-wise probability distributions of depth in its hidden state. Ingesting multi-scale matching information, our model refines these distributions over multiple iterations and infers depth and confidence. To extract the depth maps, we combine traditional classification and regression in a novel manner. We verify the efficiency and effectiveness of our method on DTU, Tanks&Temples and ETH3D. While being the most efficient method in both memory and run-time, our model achieves competitive performance on DTU and better generalization ability on Tanks&Temples as well as ETH3D than most state-of-the-art methods. Code is available at https://github.com/FangjinhuaWang/IterMVS.
A Multi-band Solution for Interacting with Energy-Neutral Devices
Dec 16, 2021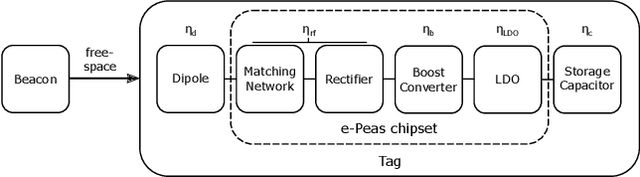
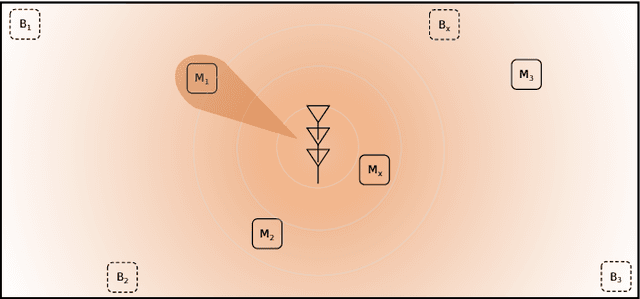
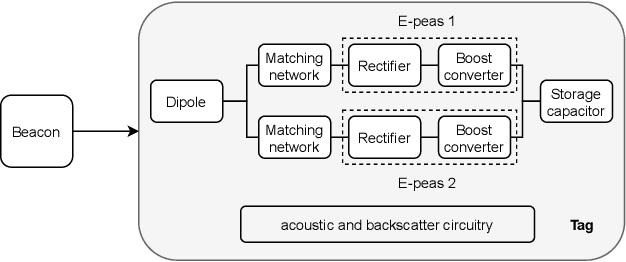
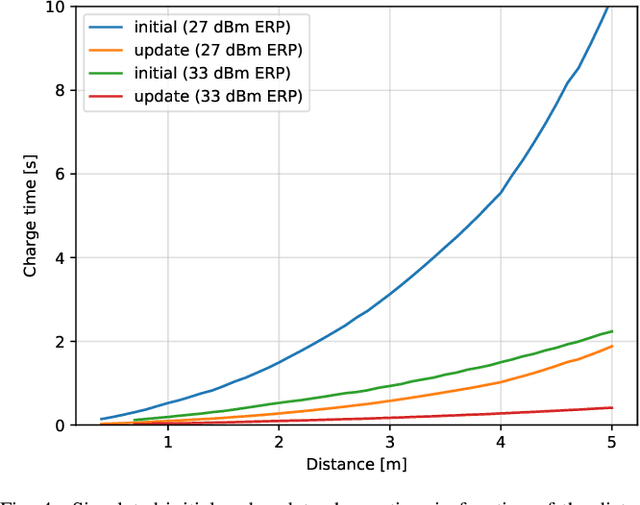
RF Wireless Power Transfer (WPT) emerges as a technology for charging autonomous devices, enabling simultaneous power and information transfer. However, with increasing distance, single-input, single-channel rectenna systems are not able to meet the power requirements of large scale IoT applications. In this paper, we tackle this problem on two levels. First, we minimize the energy consumption at the energy-constrained device on three levels. Second, we evolve to a dual-band solution increasing RF WPT. One frequency band is used to provide a base charge to many nodes in a shared transmission. Beam steering, on the other hand, allows for more power hungry operations while introducing as minimal interference as possible. We showcase this method for a hybrid RF-acoustic positioning system. Practical measurements conducted in a multi-antenna indoor testbed (Techtile) show the additional power gain and positioning rate.
GenReg: Deep Generative Method for Fast Point Cloud Registration
Nov 23, 2021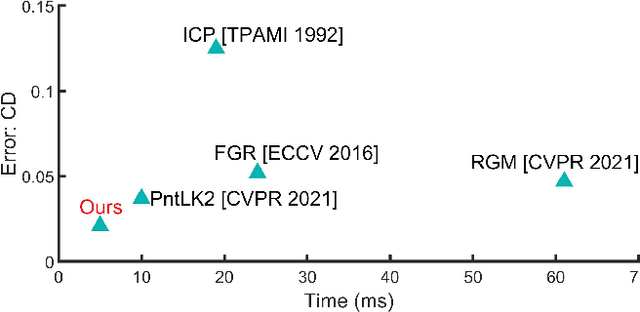
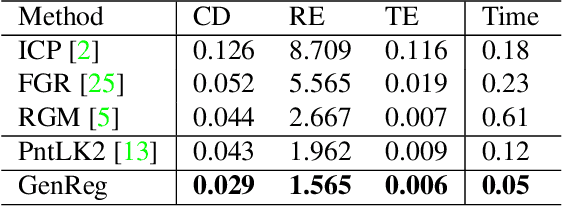


Accurate and efficient point cloud registration is a challenge because the noise and a large number of points impact the correspondence search. This challenge is still a remaining research problem since most of the existing methods rely on correspondence search. To solve this challenge, we propose a new data-driven registration algorithm by investigating deep generative neural networks to point cloud registration. Given two point clouds, the motivation is to generate the aligned point clouds directly, which is very useful in many applications like 3D matching and search. We design an end-to-end generative neural network for aligned point clouds generation to achieve this motivation, containing three novel components. Firstly, a point multi-perception layer (MLP) mixer (PointMixer) network is proposed to efficiently maintain both the global and local structure information at multiple levels from the self point clouds. Secondly, a feature interaction module is proposed to fuse information from cross point clouds. Thirdly, a parallel and differential sample consensus method is proposed to calculate the transformation matrix of the input point clouds based on the generated registration results. The proposed generative neural network is trained in a GAN framework by maintaining the data distribution and structure similarity. The experiments on both ModelNet40 and 7Scene datasets demonstrate that the proposed algorithm achieves state-of-the-art accuracy and efficiency. Notably, our method reduces $2\times$ in registration error (CD) and $12\times$ running time compared to the state-of-the-art correspondence-based algorithm.
The Devil is in the Task: Exploiting Reciprocal Appearance-Localization Features for Monocular 3D Object Detection
Dec 28, 2021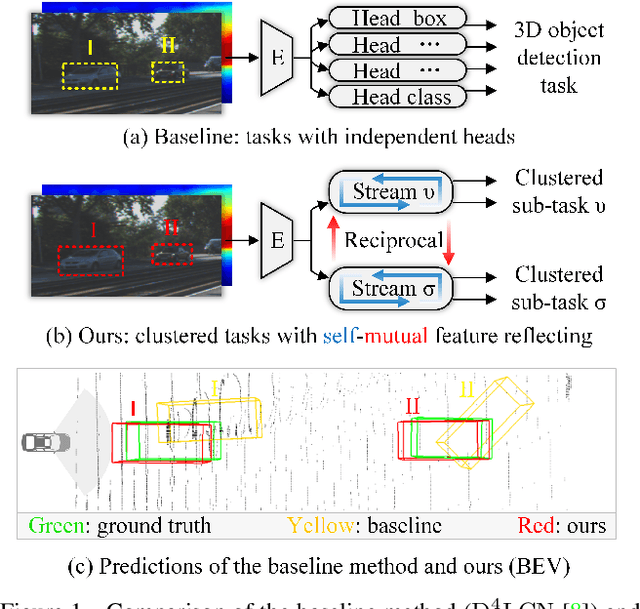
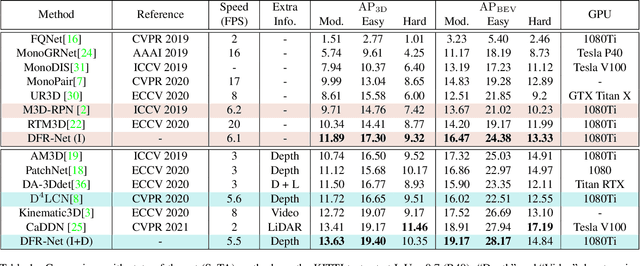
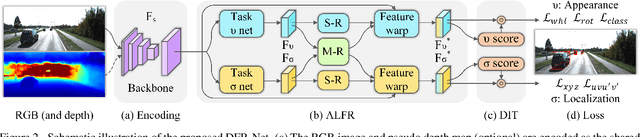
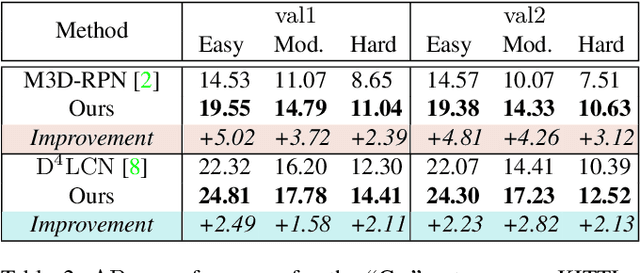
Low-cost monocular 3D object detection plays a fundamental role in autonomous driving, whereas its accuracy is still far from satisfactory. In this paper, we dig into the 3D object detection task and reformulate it as the sub-tasks of object localization and appearance perception, which benefits to a deep excavation of reciprocal information underlying the entire task. We introduce a Dynamic Feature Reflecting Network, named DFR-Net, which contains two novel standalone modules: (i) the Appearance-Localization Feature Reflecting module (ALFR) that first separates taskspecific features and then self-mutually reflects the reciprocal features; (ii) the Dynamic Intra-Trading module (DIT) that adaptively realigns the training processes of various sub-tasks via a self-learning manner. Extensive experiments on the challenging KITTI dataset demonstrate the effectiveness and generalization of DFR-Net. We rank 1st among all the monocular 3D object detectors in the KITTI test set (till March 16th, 2021). The proposed method is also easy to be plug-and-play in many cutting-edge 3D detection frameworks at negligible cost to boost performance. The code will be made publicly available.
Query-augmented Active Metric Learning
Nov 08, 2021
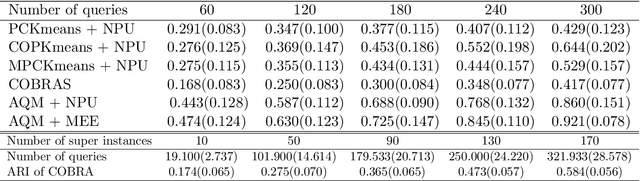
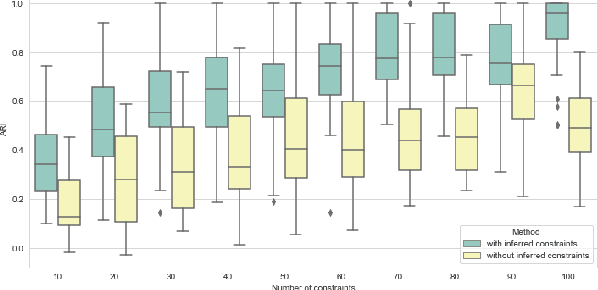
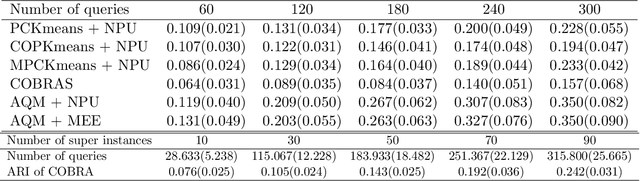
In this paper we propose an active metric learning method for clustering with pairwise constraints. The proposed method actively queries the label of informative instance pairs, while estimating underlying metrics by incorporating unlabeled instance pairs, which leads to a more accurate and efficient clustering process. In particular, we augment the queried constraints by generating more pairwise labels to provide additional information in learning a metric to enhance clustering performance. Furthermore, we increase the robustness of metric learning by updating the learned metric sequentially and penalizing the irrelevant features adaptively. In addition, we propose a novel active query strategy that evaluates the information gain of instance pairs more accurately by incorporating the neighborhood structure, which improves clustering efficiency without extra labeling cost. In theory, we provide a tighter error bound of the proposed metric learning method utilizing augmented queries compared with methods using existing constraints only. Furthermore, we also investigate the improvement using the active query strategy instead of random selection. Numerical studies on simulation settings and real datasets indicate that the proposed method is especially advantageous when the signal-to-noise ratio between significant features and irrelevant features is low.
Knowledge Graph-enhanced Sampling for Conversational Recommender System
Oct 13, 2021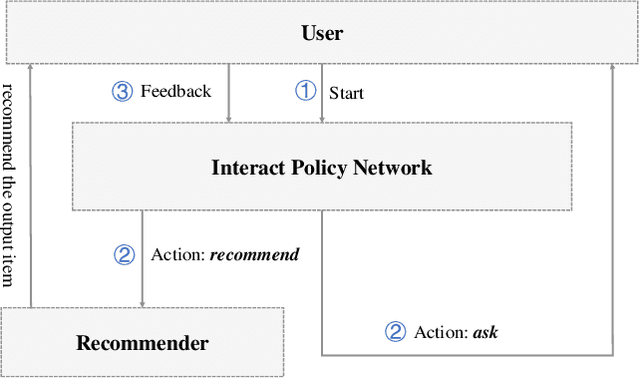
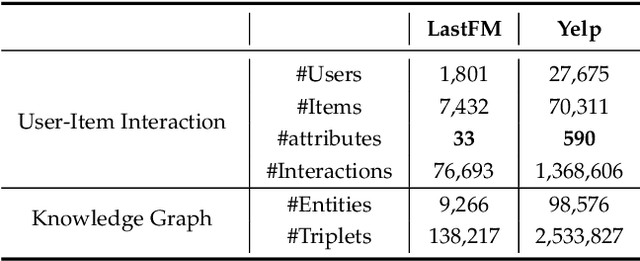
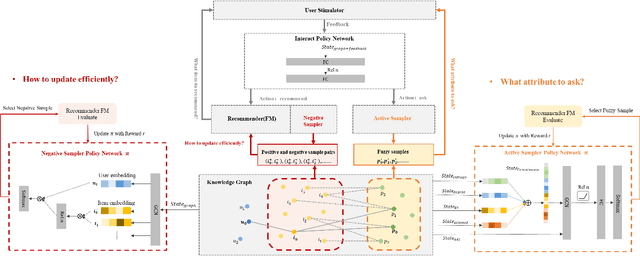
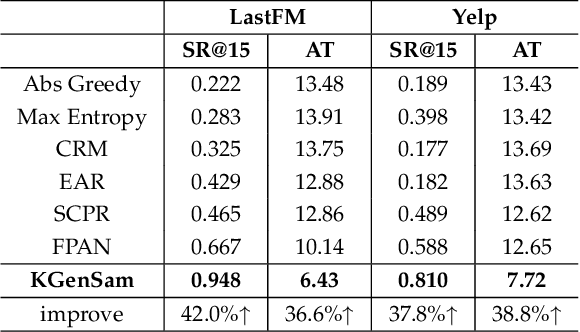
The traditional recommendation systems mainly use offline user data to train offline models, and then recommend items for online users, thus suffering from the unreliable estimation of user preferences based on sparse and noisy historical data. Conversational Recommendation System (CRS) uses the interactive form of the dialogue systems to solve the intrinsic problems of traditional recommendation systems. However, due to the lack of contextual information modeling, the existing CRS models are unable to deal with the exploitation and exploration (E&E) problem well, resulting in the heavy burden on users. To address the aforementioned issue, this work proposes a contextual information enhancement model tailored for CRS, called Knowledge Graph-enhanced Sampling (KGenSam). KGenSam integrates the dynamic graph of user interaction data with the external knowledge into one heterogeneous Knowledge Graph (KG) as the contextual information environment. Then, two samplers are designed to enhance knowledge by sampling fuzzy samples with high uncertainty for obtaining user preferences and reliable negative samples for updating recommender to achieve efficient acquisition of user preferences and model updating, and thus provide a powerful solution for CRS to deal with E&E problem. Experimental results on two real-world datasets demonstrate the superiority of KGenSam with significant improvements over state-of-the-art methods.
V-LinkNet: Learning Contextual Inpainting Across Latent Space of Generative Adversarial Network
Jan 02, 2022
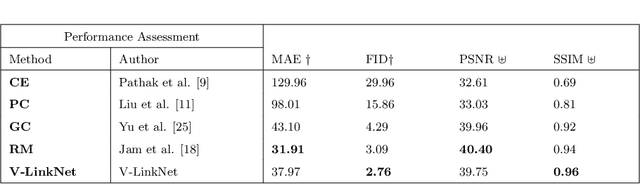

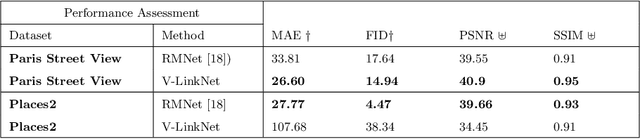
Deep learning methods outperform traditional methods in image inpainting. In order to generate contextual textures, researchers are still working to improve on existing methods and propose models that can extract, propagate, and reconstruct features similar to ground-truth regions. Furthermore, the lack of a high-quality feature transfer mechanism in deeper layers contributes to persistent aberrations on generated inpainted regions. To address these limitations, we propose the V-LinkNet cross-space learning strategy network. To improve learning on contextualised features, we design a loss model that employs both encoders. In addition, we propose a recursive residual transition layer (RSTL). The RSTL extracts high-level semantic information and propagates it down layers. Finally, we compare inpainting performance on the same face with different masks and on different faces with the same masks. To improve image inpainting reproducibility, we propose a standard protocol to overcome biases with various masks and images. We investigate the V-LinkNet components using experimental methods. Our result surpasses the state of the art when evaluated on the CelebA-HQ with the standard protocol. In addition, our model can generalise well when evaluated on Paris Street View, and Places2 datasets with the standard protocol.
Agricultural Plant Cataloging and Establishment of a Data Framework from UAV-based Crop Images by Computer Vision
Jan 11, 2022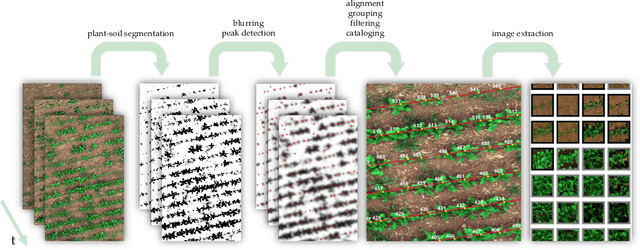


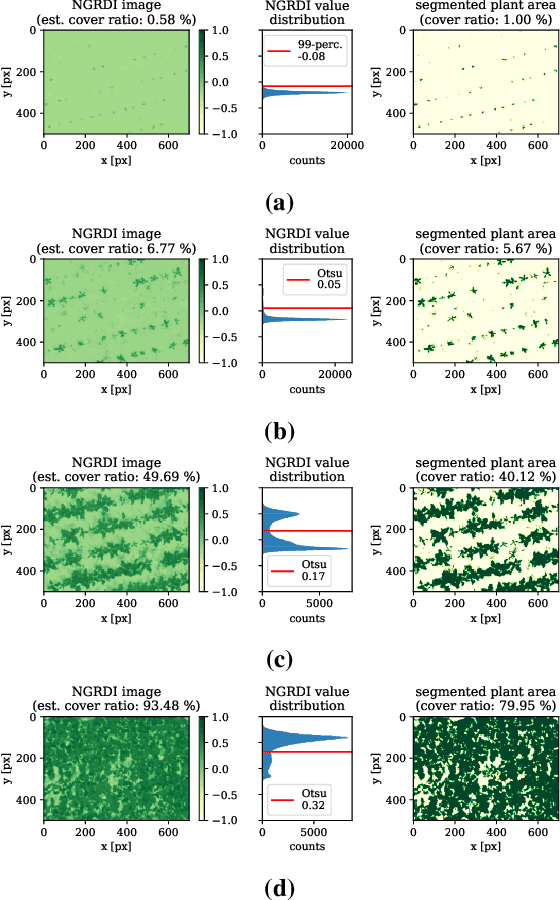
UAV-based image retrieval in modern agriculture enables gathering large amounts of spatially referenced crop image data. In large-scale experiments, however, UAV images suffer from containing a multitudinous amount of crops in a complex canopy architecture. Especially for the observation of temporal effects, this complicates the recognition of individual plants over several images and the extraction of relevant information tremendously. In this work, we present a hands-on workflow for the automatized temporal and spatial identification and individualization of crop images from UAVs abbreviated as "cataloging" based on comprehensible computer vision methods. We evaluate the workflow on two real-world datasets. One dataset is recorded for observation of Cercospora leaf spot - a fungal disease - in sugar beet over an entire growing cycle. The other one deals with harvest prediction of cauliflower plants. The plant catalog is utilized for the extraction of single plant images seen over multiple time points. This gathers large-scale spatio-temporal image dataset that in turn can be applied to train further machine learning models including various data layers. The presented approach improves analysis and interpretation of UAV data in agriculture significantly. By validation with some reference data, our method shows an accuracy that is similar to more complex deep learning-based recognition techniques. Our workflow is able to automatize plant cataloging and training image extraction, especially for large datasets.
Inferential SIR-GN: Scalable Graph Representation Learning
Nov 08, 2021


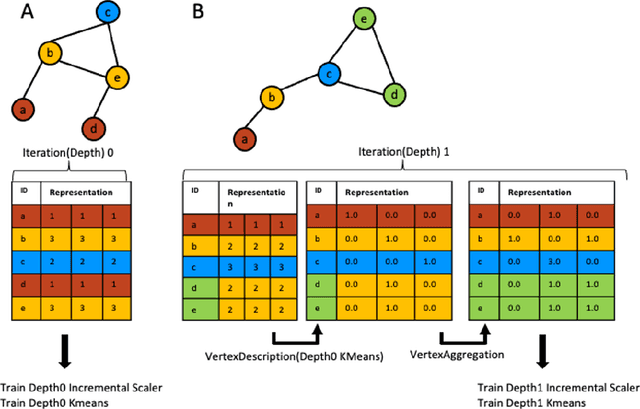
Graph representation learning methods generate numerical vector representations for the nodes in a network, thereby enabling their use in standard machine learning models. These methods aim to preserve relational information, such that nodes that are similar in the graph are found close to one another in the representation space. Similarity can be based largely on one of two notions: connectivity or structural role. In tasks where node structural role is important, connectivity based methods show poor performance. Recent work has begun to focus on scalability of learning methods to massive graphs of millions to billions of nodes and edges. Many unsupervised node representation learning algorithms are incapable of scaling to large graphs, and are unable to generate node representations for unseen nodes. In this work, we propose Inferential SIR-GN, a model which is pre-trained on random graphs, then computes node representations rapidly, including for very large networks. We demonstrate that the model is able to capture node's structural role information, and show excellent performance at node and graph classification tasks, on unseen networks. Additionally, we observe the scalability of Inferential SIR-GN is comparable to the fastest current approaches for massive graphs.
4D-Net for Learned Multi-Modal Alignment
Sep 02, 2021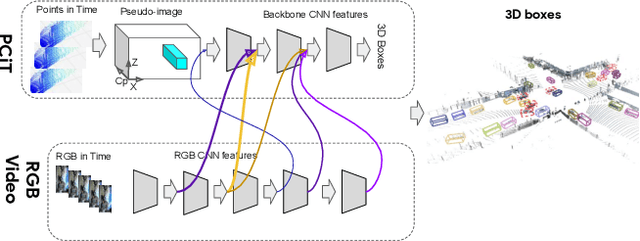
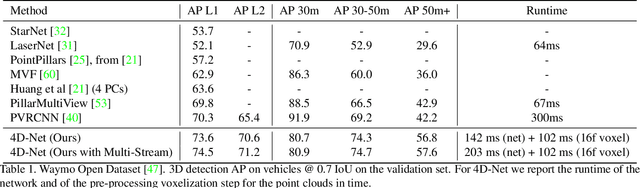
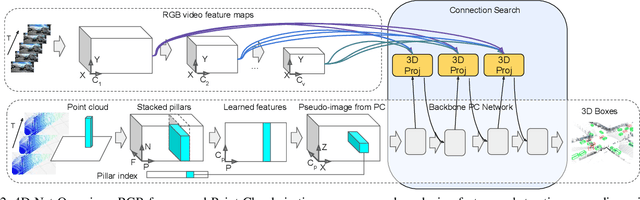
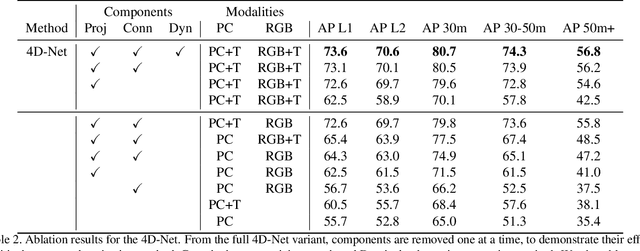
We present 4D-Net, a 3D object detection approach, which utilizes 3D Point Cloud and RGB sensing information, both in time. We are able to incorporate the 4D information by performing a novel dynamic connection learning across various feature representations and levels of abstraction, as well as by observing geometric constraints. Our approach outperforms the state-of-the-art and strong baselines on the Waymo Open Dataset. 4D-Net is better able to use motion cues and dense image information to detect distant objects more successfully.