 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Computer-Assisted Creation of Boolean Search Rules for Text Classification in the Legal Domain
Dec 10, 2021
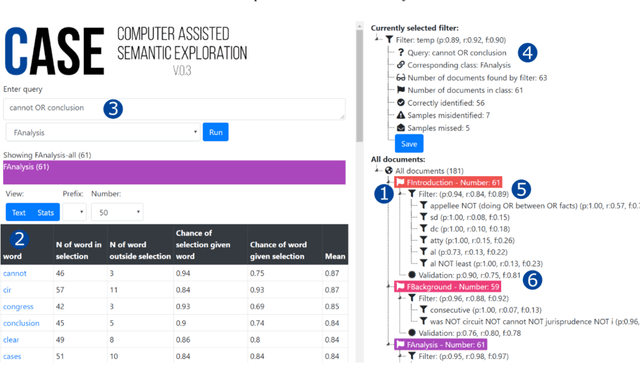
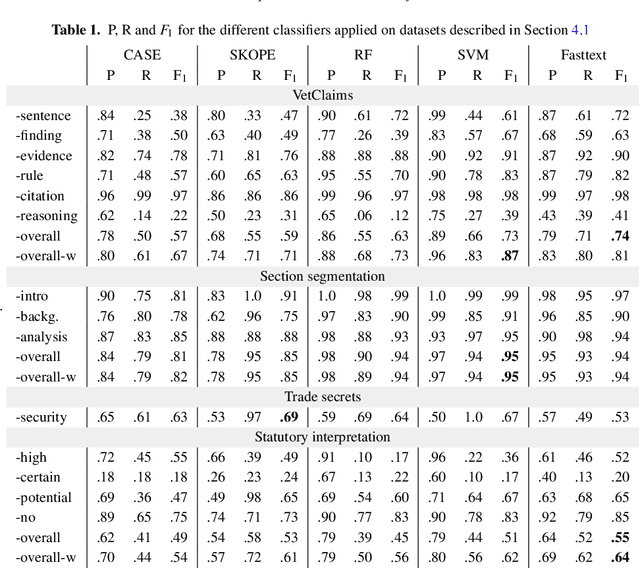

In this paper, we present a method of building strong, explainable classifiers in the form of Boolean search rules. We developed an interactive environment called CASE (Computer Assisted Semantic Exploration) which exploits word co-occurrence to guide human annotators in selection of relevant search terms. The system seamlessly facilitates iterative evaluation and improvement of the classification rules. The process enables the human annotators to leverage the benefits of statistical information while incorporating their expert intuition into the creation of such rules. We evaluate classifiers created with our CASE system on 4 datasets, and compare the results to machine learning methods, including SKOPE rules, Random forest, Support Vector Machine, and fastText classifiers. The results drive the discussion on trade-offs between superior compactness, simplicity, and intuitiveness of the Boolean search rules versus the better performance of state-of-the-art machine learning models for text classification.
Permuted and Unlinked Monotone Regression in $\mathbb{R}^d$: an approach based on mixture modeling and optimal transport
Jan 10, 2022

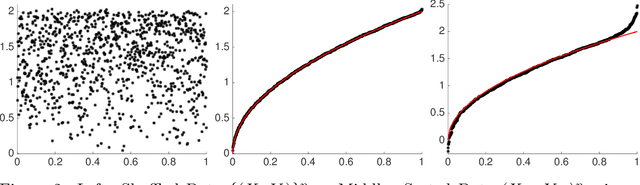
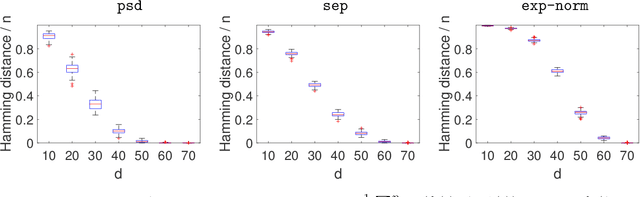
Suppose that we have a regression problem with response variable Y in $\mathbb{R}^d$ and predictor X in $\mathbb{R}^d$, for $d \geq 1$. In permuted or unlinked regression we have access to separate unordered data on X and Y, as opposed to data on (X,Y)-pairs in usual regression. So far in the literature the case $d=1$ has received attention, see e.g., the recent papers by Rigollet and Weed [Information & Inference, 8, 619--717] and Balabdaoui et al. [J. Mach. Learn. Res., 22(172), 1--60]. In this paper, we consider the general multivariate setting with $d \geq 1$. We show that the notion of cyclical monotonicity of the regression function is sufficient for identification and estimation in the permuted/unlinked regression model. We study permutation recovery in the permuted regression setting and develop a computationally efficient and easy-to-use algorithm for denoising based on the Kiefer-Wolfowitz [Ann. Math. Statist., 27, 887--906] nonparametric maximum likelihood estimator and techniques from the theory of optimal transport. We provide explicit upper bounds on the associated mean squared denoising error for Gaussian noise. As in previous work on the case $d = 1$, the permuted/unlinked setting involves slow (logarithmic) rates of convergence rooting in the underlying deconvolution problem. Numerical studies corroborate our theoretical analysis and show that the proposed approach performs at least on par with the methods in the aforementioned prior work in the case $d = 1$ while achieving substantial reductions in terms of computational complexity.
A Review on Graph Neural Network Methods in Financial Applications
Nov 27, 2021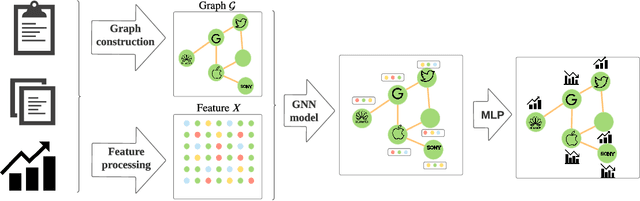

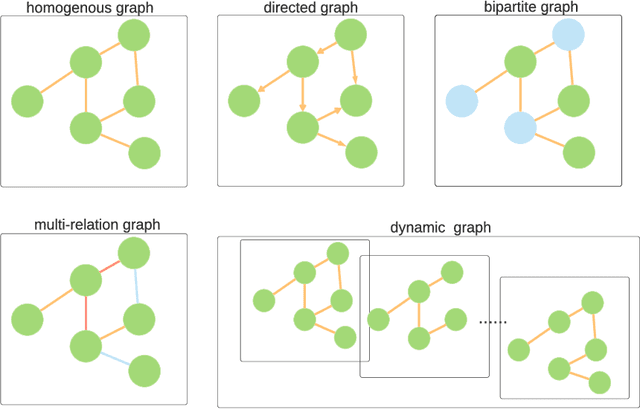
Keeping the individual features and the complicated relations, graph data are widely utilized and investigated. Being able to capture the structural information by updating and aggregating nodes' representations, graph neural network (GNN) models are gaining popularity. In the financial context, the graph is constructed based on real-world data, which leads to complex graph structure and thus requires sophisticated methodology. In this work, we provide a comprehensive review of GNN models in recent financial context. We first categorize the commonly-used financial graphs and summarize the feature processing step for each node. Then we summarize the GNN methodology for each graph type, application in each area, and propose some potential research areas.
Semi-Local Convolutions for LiDAR Scan Processing
Nov 30, 2021
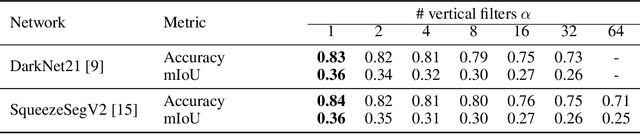

A number of applications, such as mobile robots or automated vehicles, use LiDAR sensors to obtain detailed information about their three-dimensional surroundings. Many methods use image-like projections to efficiently process these LiDAR measurements and use deep convolutional neural networks to predict semantic classes for each point in the scan. The spatial stationary assumption enables the usage of convolutions. However, LiDAR scans exhibit large differences in appearance over the vertical axis. Therefore, we propose semi local convolution (SLC), a convolution layer with reduced amount of weight-sharing along the vertical dimension. We are first to investigate the usage of such a layer independent of any other model changes. Our experiments did not show any improvement over traditional convolution layers in terms of segmentation IoU or accuracy.
* arXiv admin note: text overlap with arXiv:2004.11803
A model of semantic completion in generative episodic memory
Nov 26, 2021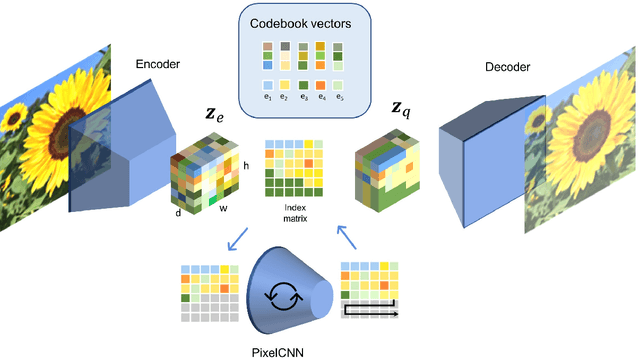
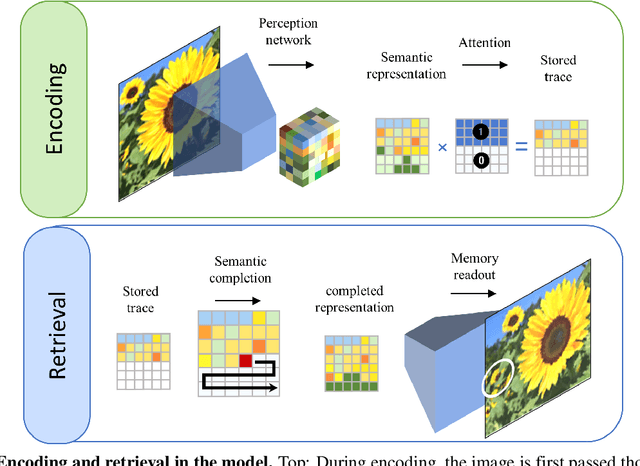
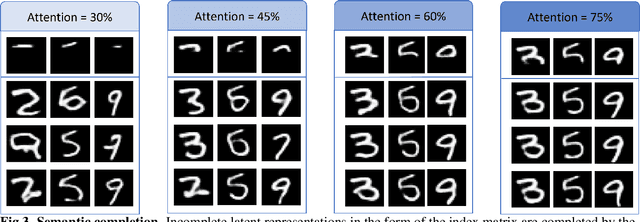
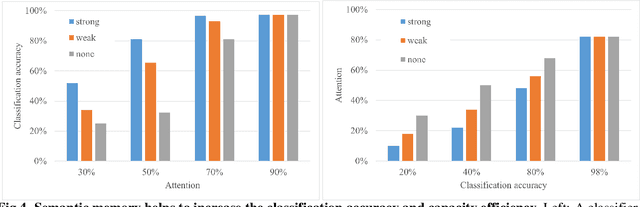
Many different studies have suggested that episodic memory is a generative process, but most computational models adopt a storage view. In this work, we propose a computational model for generative episodic memory. It is based on the central hypothesis that the hippocampus stores and retrieves selected aspects of an episode as a memory trace, which is necessarily incomplete. At recall, the neocortex reasonably fills in the missing information based on general semantic information in a process we call semantic completion. As episodes we use images of digits (MNIST) augmented by different backgrounds representing context. Our model is based on a VQ-VAE which generates a compressed latent representation in form of an index matrix, which still has some spatial resolution. We assume that attention selects some part of the index matrix while others are discarded, this then represents the gist of the episode and is stored as a memory trace. At recall the missing parts are filled in by a PixelCNN, modeling semantic completion, and the completed index matrix is then decoded into a full image by the VQ-VAE. The model is able to complete missing parts of a memory trace in a semantically plausible way up to the point where it can generate plausible images from scratch. Due to the combinatorics in the index matrix, the model generalizes well to images not trained on. Compression as well as semantic completion contribute to a strong reduction in memory requirements and robustness to noise. Finally we also model an episodic memory experiment and can reproduce that semantically congruent contexts are always recalled better than incongruent ones, high attention levels improve memory accuracy in both cases, and contexts that are not remembered correctly are more often remembered semantically congruently than completely wrong.
A unified software/hardware scalable architecture for brain-inspired computing based on self-organizing neural models
Jan 06, 2022
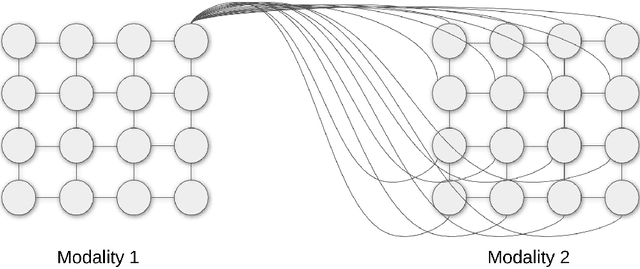
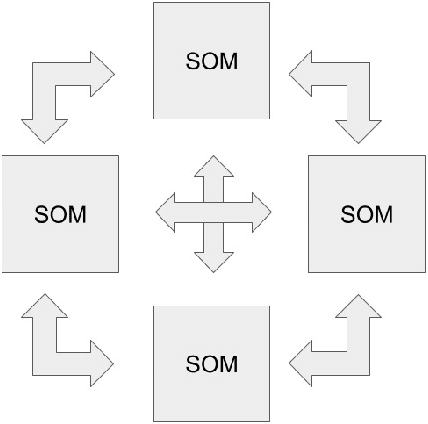

The field of artificial intelligence has significantly advanced over the past decades, inspired by discoveries from the fields of biology and neuroscience. The idea of this work is inspired by the process of self-organization of cortical areas in the human brain from both afferent and lateral/internal connections. In this work, we develop an original brain-inspired neural model associating Self-Organizing Maps (SOM) and Hebbian learning in the Reentrant SOM (ReSOM) model. The framework is applied to multimodal classification problems. Compared to existing methods based on unsupervised learning with post-labeling, the model enhances the state-of-the-art results. This work also demonstrates the distributed and scalable nature of the model through both simulation results and hardware execution on a dedicated FPGA-based platform named SCALP (Self-configurable 3D Cellular Adaptive Platform). SCALP boards can be interconnected in a modular way to support the structure of the neural model. Such a unified software and hardware approach enables the processing to be scaled and allows information from several modalities to be merged dynamically. The deployment on hardware boards provides performance results of parallel execution on several devices, with the communication between each board through dedicated serial links. The proposed unified architecture, composed of the ReSOM model and the SCALP hardware platform, demonstrates a significant increase in accuracy thanks to multimodal association, and a good trade-off between latency and power consumption compared to a centralized GPU implementation.
Are You Smarter Than a Random Expert? The Robust Aggregation of Substitutable Signals
Nov 04, 2021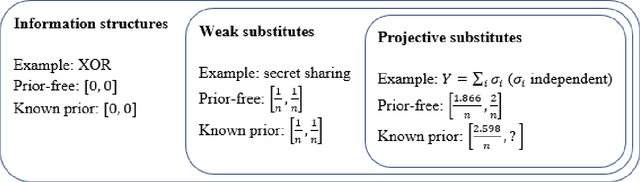
The problem of aggregating expert forecasts is ubiquitous in fields as wide-ranging as machine learning, economics, climate science, and national security. Despite this, our theoretical understanding of this question is fairly shallow. This paper initiates the study of forecast aggregation in a context where experts' knowledge is chosen adversarially from a broad class of information structures. While in full generality it is impossible to achieve a nontrivial performance guarantee, we show that doing so is possible under a condition on the experts' information structure that we call \emph{projective substitutes}. The projective substitutes condition is a notion of informational substitutes: that there are diminishing marginal returns to learning the experts' signals. We show that under the projective substitutes condition, taking the average of the experts' forecasts improves substantially upon the strategy of trusting a random expert. We then consider a more permissive setting, in which the aggregator has access to the prior. We show that by averaging the experts' forecasts and then \emph{extremizing} the average by moving it away from the prior by a constant factor, the aggregator's performance guarantee is substantially better than is possible without knowledge of the prior. Our results give a theoretical grounding to past empirical research on extremization and help give guidance on the appropriate amount to extremize.
Spatial-Temporal Transformer for 3D Point Cloud Sequences
Oct 19, 2021Effective learning of spatial-temporal information within a point cloud sequence is highly important for many down-stream tasks such as 4D semantic segmentation and 3D action recognition. In this paper, we propose a novel framework named Point Spatial-Temporal Transformer (PST2) to learn spatial-temporal representations from dynamic 3D point cloud sequences. Our PST2 consists of two major modules: a Spatio-Temporal Self-Attention (STSA) module and a Resolution Embedding (RE) module. Our STSA module is introduced to capture the spatial-temporal context information across adjacent frames, while the RE module is proposed to aggregate features across neighbors to enhance the resolution of feature maps. We test the effectiveness our PST2 with two different tasks on point cloud sequences, i.e., 4D semantic segmentation and 3D action recognition. Extensive experiments on three benchmarks show that our PST2 outperforms existing methods on all datasets. The effectiveness of our STSA and RE modules have also been justified with ablation experiments.
Generating Fluent Fact Checking Explanations with Unsupervised Post-Editing
Dec 13, 2021
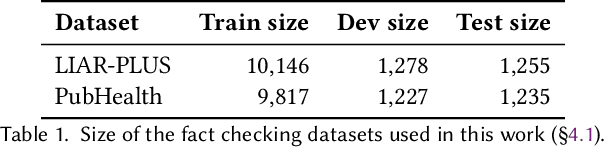
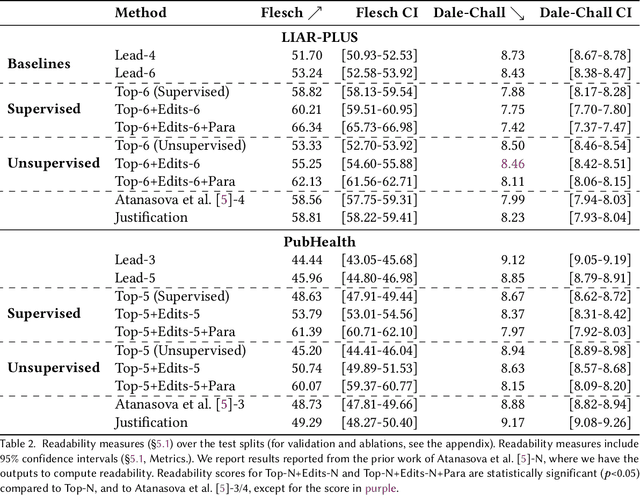
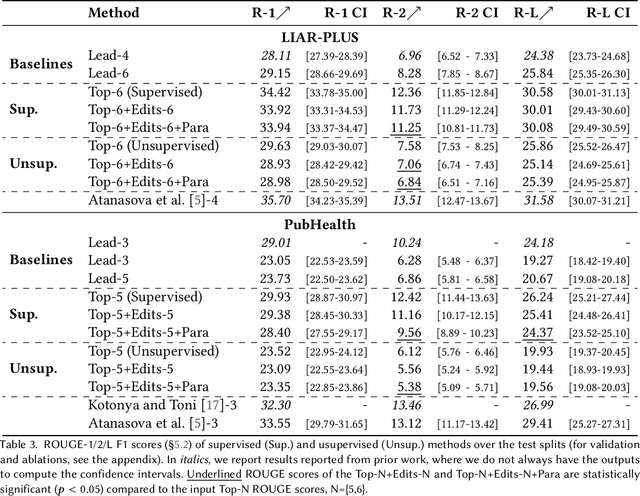
Fact-checking systems have become important tools to verify fake and misguiding news. These systems become more trustworthy when human-readable explanations accompany the veracity labels. However, manual collection of such explanations is expensive and time-consuming. Recent works frame explanation generation as extractive summarization, and propose to automatically select a sufficient subset of the most important facts from the ruling comments (RCs) of a professional journalist to obtain fact-checking explanations. However, these explanations lack fluency and sentence coherence. In this work, we present an iterative edit-based algorithm that uses only phrase-level edits to perform unsupervised post-editing of disconnected RCs. To regulate our editing algorithm, we use a scoring function with components including fluency and semantic preservation. In addition, we show the applicability of our approach in a completely unsupervised setting. We experiment with two benchmark datasets, LIAR-PLUS and PubHealth. We show that our model generates explanations that are fluent, readable, non-redundant, and cover important information for the fact check.
Nondestructive Testing of Composite Fibre Materials with Hyperspectral Imaging : Evaluative Studies in the EU H2020 FibreEUse Project
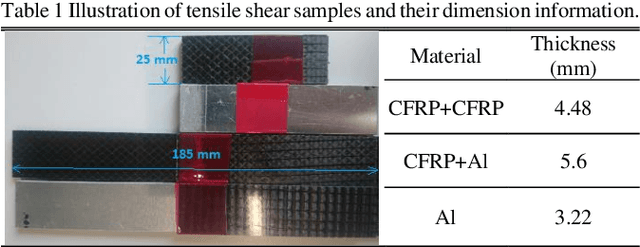
Nov 04, 2021
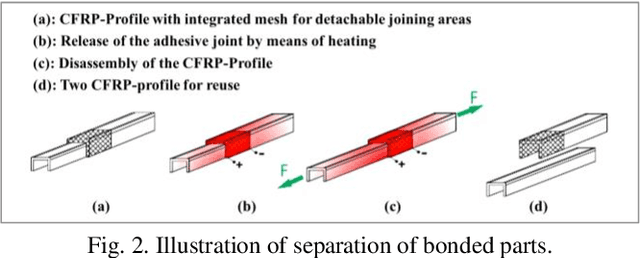

Through capturing spectral data from a wide frequency range along with the spatial information, hyperspectral imaging (HSI) can detect minor differences in terms of temperature, moisture and chemical composition. Therefore, HSI has been successfully applied in various applications, including remote sensing for security and defense, precision agriculture for vegetation and crop monitoring, food/drink, and pharmaceuticals quality control. However, for condition monitoring and damage detection in carbon fibre reinforced polymer (CFRP), the use of HSI is a relatively untouched area, as existing non-destructive testing (NDT) techniques focus mainly on delivering information about physical integrity of structures but not on material composition. To this end, HSI can provide a unique way to tackle this challenge. In this paper, with the use of a near-infrared HSI camera, applications of HSI for the non-destructive inspection of CFRP products are introduced, taking the EU H2020 FibreEUse project as the background. Technical challenges and solutions on three case studies are presented in detail, including adhesive residues detection, surface damage detection and Cobot based automated inspection. Experimental results have fully demonstrated the great potential of HSI and related vision techniques for NDT of CFRP, especially the potential to satisfy the industrial manufacturing environment.