 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Inclusive Speaker Verification with Adaptive thresholding
Nov 10, 2021
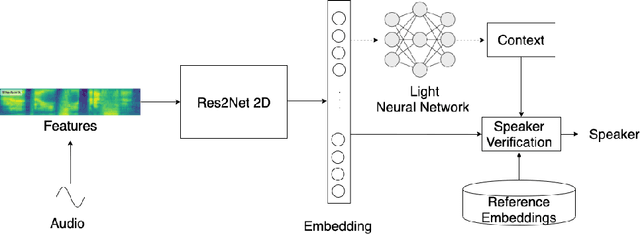
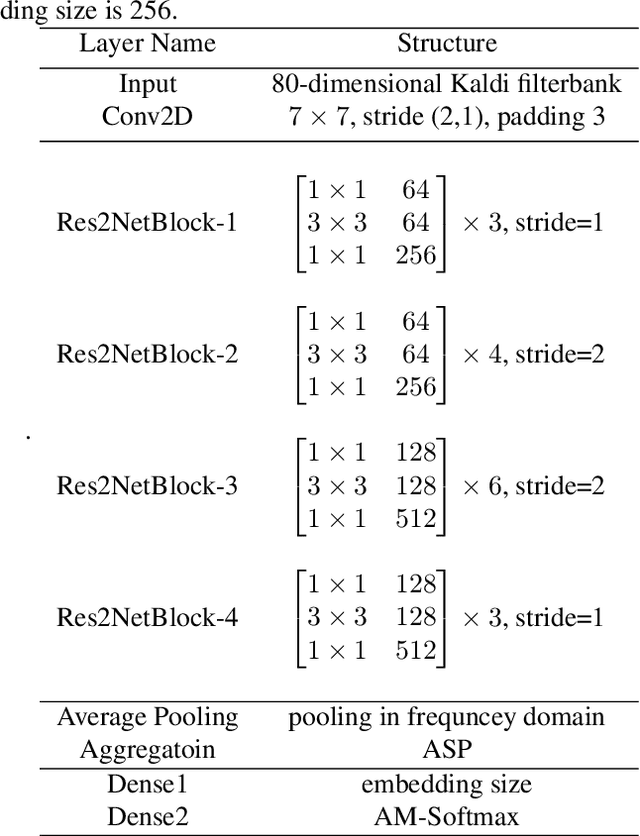
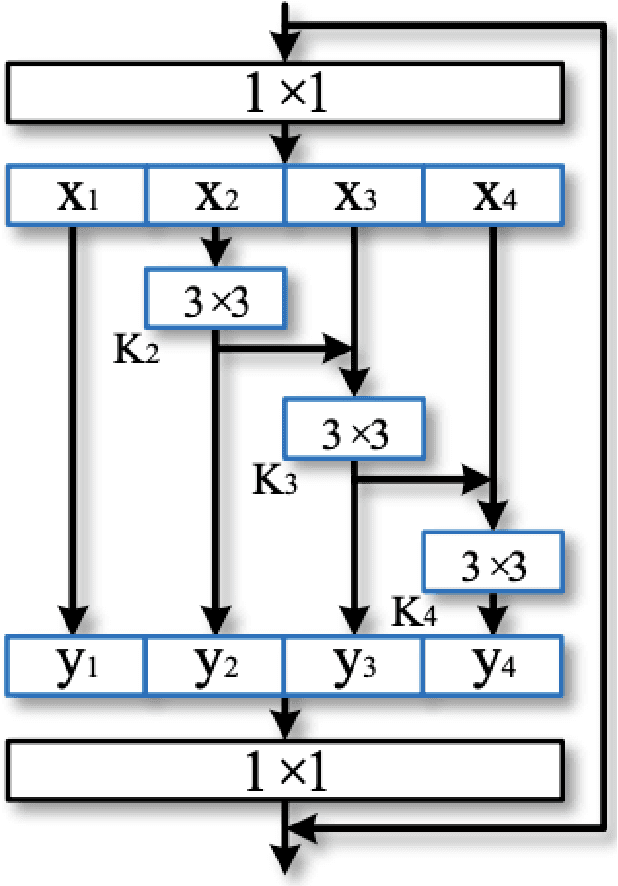
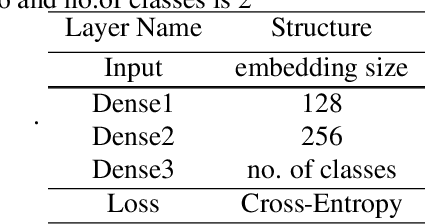
While using a speaker verification (SV) based system in a commercial application, it is important that customers have an inclusive experience irrespective of their gender, age, or ethnicity. In this paper, we analyze the impact of gender and age on SV and find that for a desired common False Acceptance Rate (FAR) across different gender and age groups, the False Rejection Rate (FRR) is different for different gender and age groups. To optimize FRR for all users for a desired FAR, we propose a context (e.g. gender, age) adaptive thresholding framework for SV. The context can be available as prior information for many practical applications. We also propose a concatenated gender/age detection model to algorithmically derive the context in absence of such prior information. We experimentally show that our context-adaptive thresholding method is effective in building a more efficient inclusive SV system. Specifically, we show that we can reduce FRR for specific gender for a desired FAR on the voxceleb1 test set by using gender-specific thresholds. Similar analysis on OGI kids' speech corpus shows that by using an age-specific threshold, we can significantly reduce FRR for certain age groups for desired FAR.
Learning Cooperative Multi-Agent Policies with Partial Reward Decoupling
Dec 23, 2021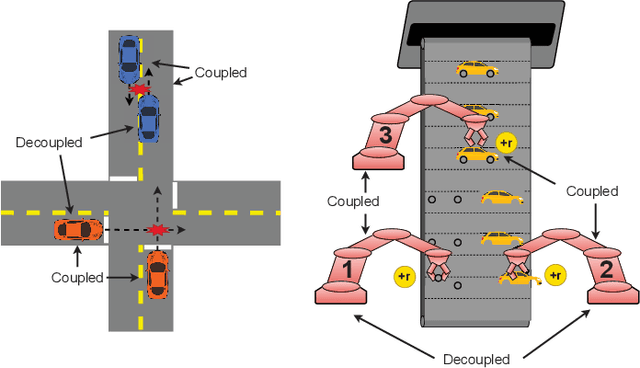
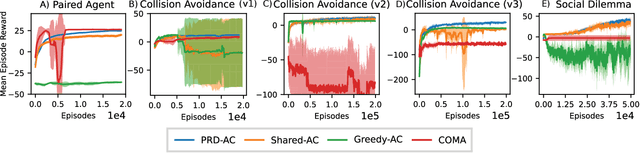
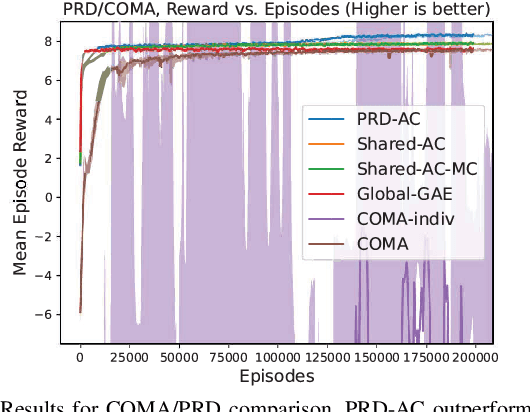
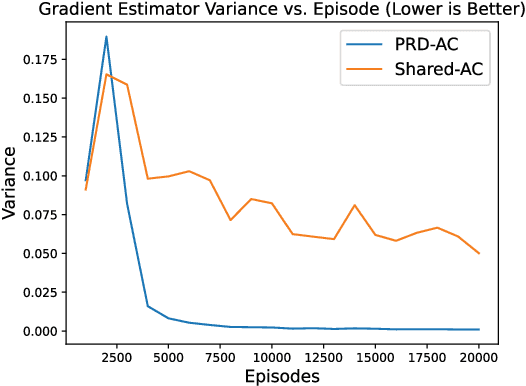
One of the preeminent obstacles to scaling multi-agent reinforcement learning to large numbers of agents is assigning credit to individual agents' actions. In this paper, we address this credit assignment problem with an approach that we call \textit{partial reward decoupling} (PRD), which attempts to decompose large cooperative multi-agent RL problems into decoupled subproblems involving subsets of agents, thereby simplifying credit assignment. We empirically demonstrate that decomposing the RL problem using PRD in an actor-critic algorithm results in lower variance policy gradient estimates, which improves data efficiency, learning stability, and asymptotic performance across a wide array of multi-agent RL tasks, compared to various other actor-critic approaches. Additionally, we relate our approach to counterfactual multi-agent policy gradient (COMA), a state-of-the-art MARL algorithm, and empirically show that our approach outperforms COMA by making better use of information in agents' reward streams, and by enabling recent advances in advantage estimation to be used.
CLASP: Constrained Latent Shape Projection for Refining Object Shape from Robot Contact
Oct 17, 2021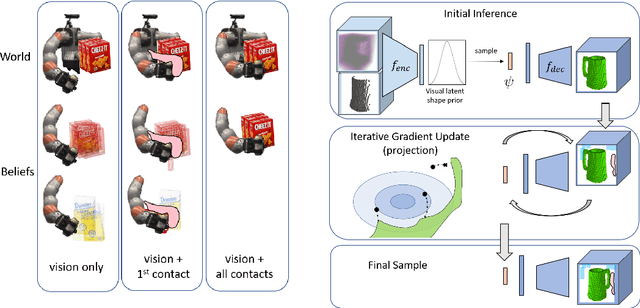
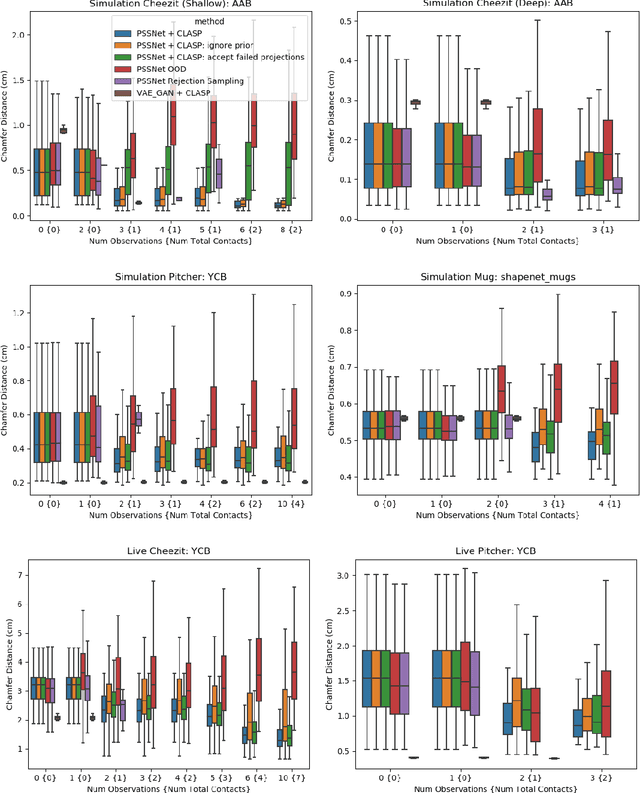
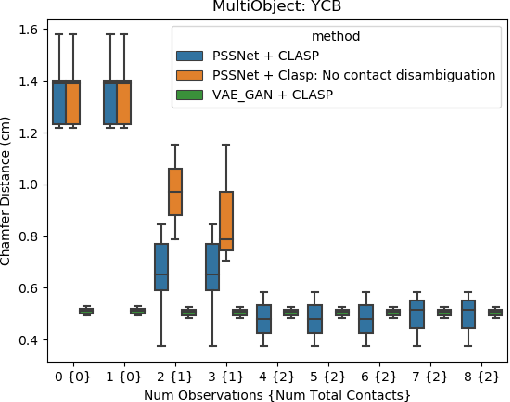

Robots need both visual and contact sensing to effectively estimate the state of their environment. Camera RGBD data provides rich information of the objects surrounding the robot, and shape priors can help correct noise and fill in gaps and occluded regions. However, when the robot senses unexpected contact, the estimate should be updated to explain the contact. To address this need, we propose CLASP: Constrained Latent Shape Projection. This approach consists of a shape completion network that generates a prior from RGBD data and a procedure to generate shapes consistent with both the network prior and robot contact observations. We find CLASP consistently decreases the Chamfer Distance between the predicted and ground truth scenes, while other approaches do not benefit from contact information.
Distribution Knowledge Embedding for Graph Pooling
Oct 14, 2021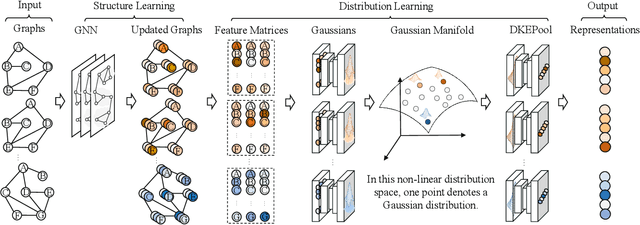
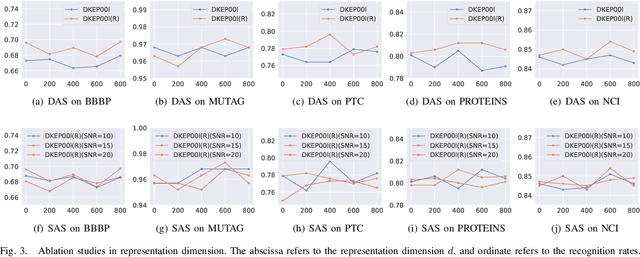
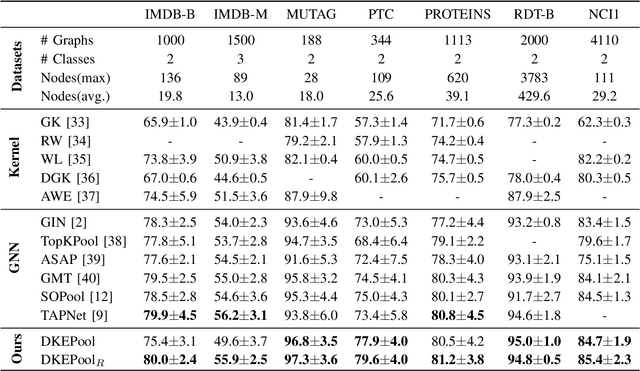
Graph-level representation learning is the pivotal step for downstream tasks that operate on the whole graph. The most common approach to this problem heretofore is graph pooling, where node features are typically averaged or summed to obtain the graph representations. However, pooling operations like averaging or summing inevitably cause massive information missing, which may severely downgrade the final performance. In this paper, we argue what is crucial to graph-level downstream tasks includes not only the topological structure but also the distribution from which nodes are sampled. Therefore, powered by existing Graph Neural Networks (GNN), we propose a new plug-and-play pooling module, termed as Distribution Knowledge Embedding (DKEPool), where graphs are rephrased as distributions on top of GNNs and the pooling goal is to summarize the entire distribution information instead of retaining a certain feature vector by simple predefined pooling operations. A DKEPool network de facto disassembles representation learning into two stages, structure learning and distribution learning. Structure learning follows a recursive neighborhood aggregation scheme to update node features where structure information is obtained. Distribution learning, on the other hand, omits node interconnections and focuses more on the distribution depicted by all the nodes. Extensive experiments demonstrate that the proposed DKEPool significantly and consistently outperforms the state-of-the-art methods.
Memotion Analysis through the Lens of Joint Embedding
Dec 03, 2021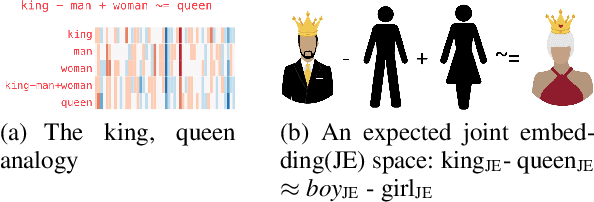
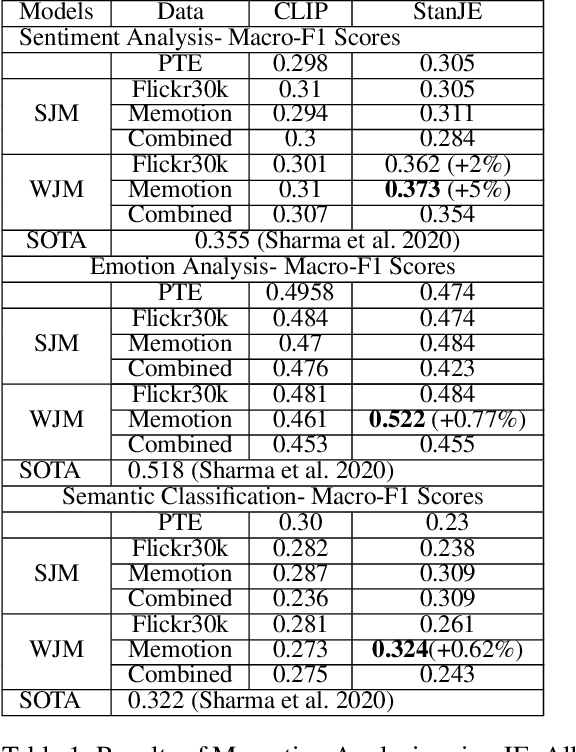
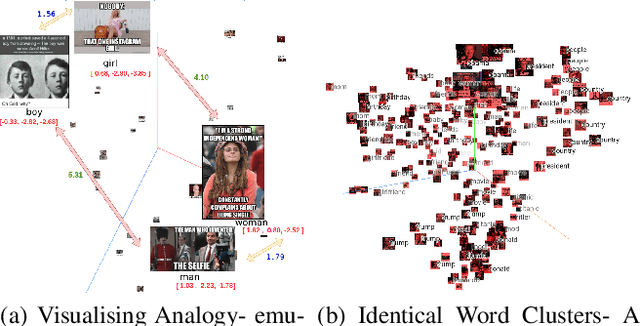
Joint embedding (JE) is a way to encode multi-modal data into a vector space where text remains as the grounding key and other modalities like image are to be anchored with such keys. Meme is typically an image with embedded text onto it. Although, memes are commonly used for fun, they could also be used to spread hate and fake information. That along with its growing ubiquity over several social platforms has caused automatic analysis of memes to become a widespread topic of research. In this paper, we report our initial experiments on Memotion Analysis problem through joint embeddings. Results are marginally yielding SOTA.
Image-free multi-character recognition
Dec 20, 2021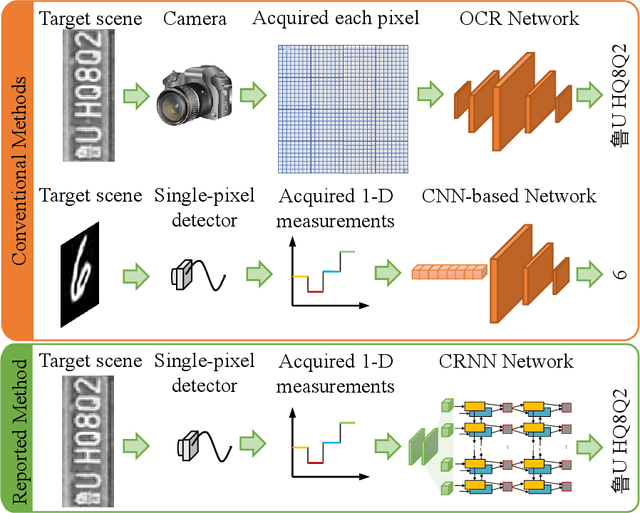
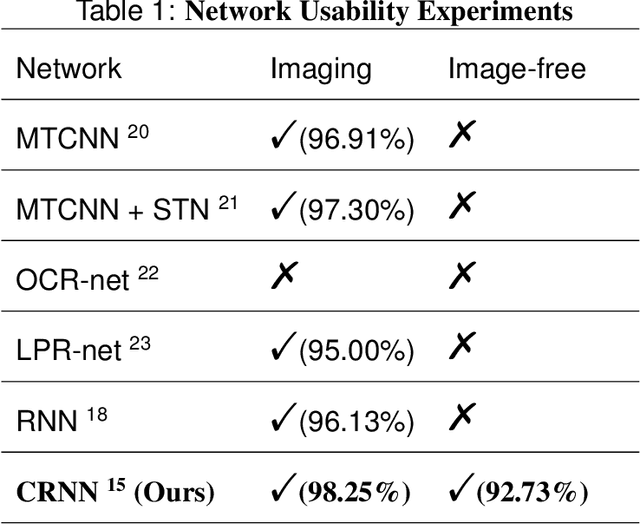
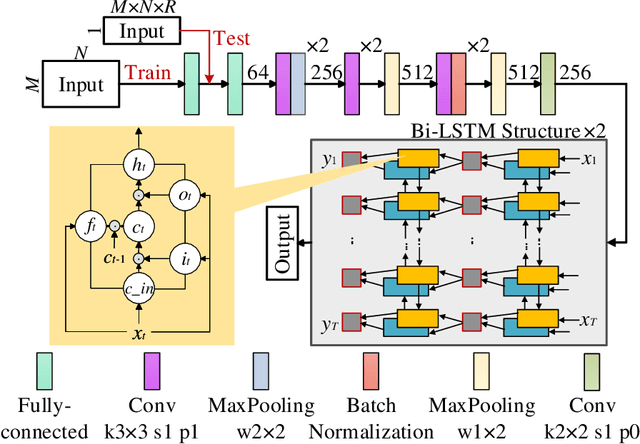
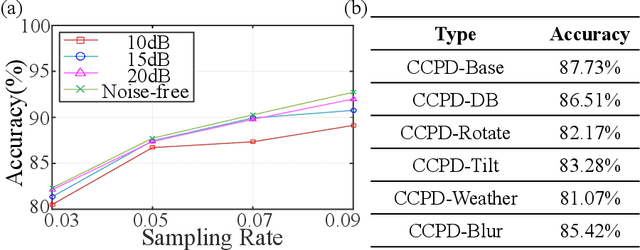
The recently developed image-free sensing technique maintains the advantages of both the light hardware and software, which has been applied in simple target classification and motion tracking. In practical applications, however, there usually exist multiple targets in the field of view, where existing trials fail to produce multi-semantic information. In this letter, we report a novel image-free sensing technique to tackle the multi-target recognition challenge for the first time. Different from the convolutional layer stack of image-free single-pixel networks, the reported CRNN network utilities the bidirectional LSTM architecture to predict the distribution of multiple characters simultaneously. The framework enables to capture the long-range dependencies, providing a high recognition accuracy of multiple characters. We demonstrated the technique's effectiveness in license plate detection, which achieved 87.60% recognition accuracy at a 5% sampling rate with a higher than 100 FPS refresh rate.
Information in Infinite Ensembles of Infinitely-Wide Neural Networks
Nov 23, 2019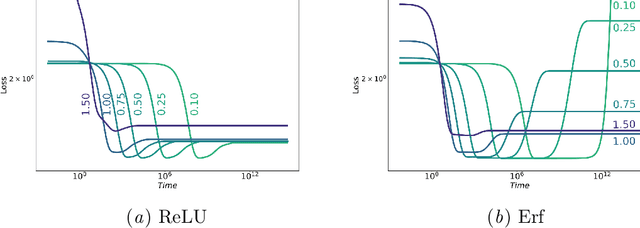
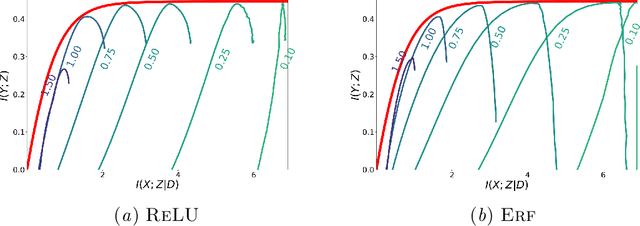
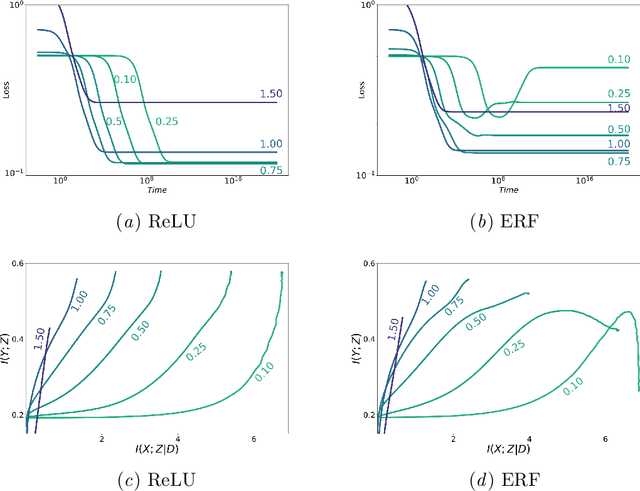
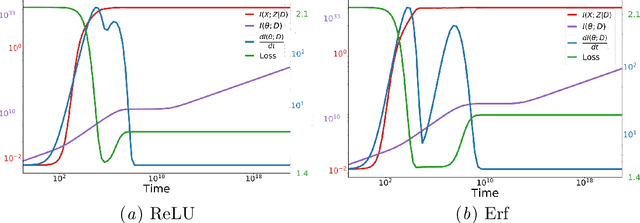
In this preliminary work, we study the generalization properties of infinite ensembles of infinitely-wide neural networks. Amazingly, this model family admits tractable calculations for many information-theoretic quantities. We report analytical and empirical investigations in the search for signals that correlate with generalization.
Search Strategy Formulation for Systematic Reviews: issues, challenges and opportunities
Dec 17, 2021
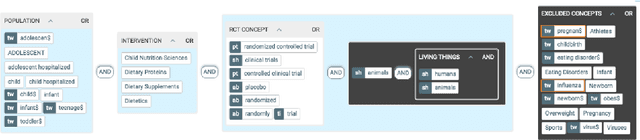
Systematic literature reviews play a vital role in identifying the best available evidence for health and social care policy. The resources required to produce systematic reviews can be significant, and a key to the success of any review is the search strategy used to identify relevant literature. However, the methods used to construct search strategies can be complex, time consuming, resource intensive and error prone. In this review, we examine the state of the art in resolving complex structured information needs, focusing primarily on the healthcare context. We analyse the literature to identify key challenges and issues and explore appropriate solutions and workarounds. From this analysis we propose a way forward to facilitate trust and transparency and to aid explainability, reproducibility and replicability through a set of key design principles for tools to support the development of search strategies in systematic literature reviews.
Learning Estimates At The Edge Using Intermittent And Aged Measurement Updates
Jan 20, 2022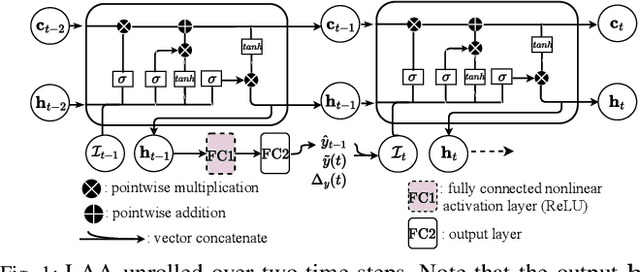
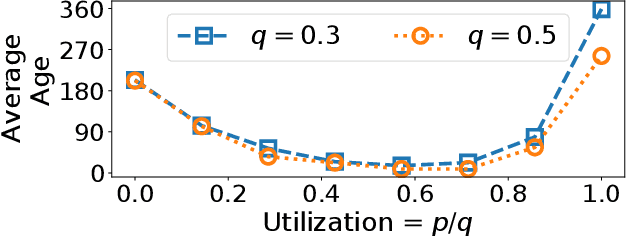
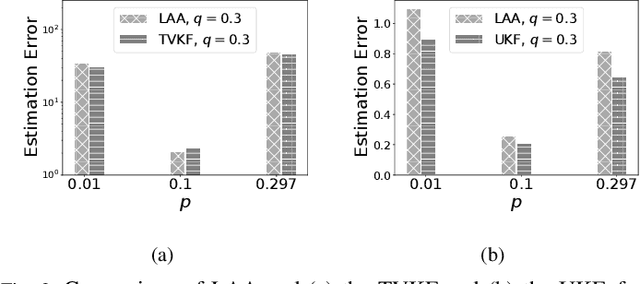
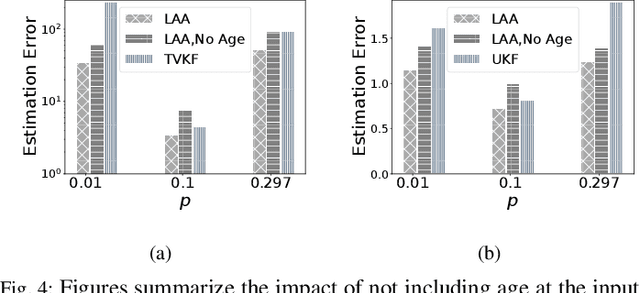
Cyber Physical Systems (CPS) applications have agents that actuate in their local vicinity, while requiring measurements that capture the state of their larger environment to make actuation choices. These measurements are made by sensors and communicated over a network as update packets. Network resource constraints dictate that updates arrive at an agent intermittently and be aged on their arrival. This can be alleviated by providing an agent with a fast enough rate of estimates of the measurements. Often works on estimation assume knowledge of the dynamic model of the system being measured. However, as CPS applications become pervasive, such information may not be available in practice. In this work, we propose a novel deep neural network architecture that leverages Long Short Term Memory (LSTM) networks to learn estimates in a model-free setting using only updates received over the network. We detail an online algorithm that enables training of our architecture. The architecture is shown to provide good estimates of measurements of both a linear and a non-linear dynamic system. It learns good estimates even when the learning proceeds over a generic network setting in which the distributions that govern the rate and age of received measurements may change significantly over time. We demonstrate the efficacy of the architecture by comparing it with the baselines of the Time-varying Kalman Filter and the Unscented Kalman Filter. The architecture enables empirical insights with regards to maintaining the ages of updates at the estimator, which are used by it and also the baselines.
Improving random walk rankings with feature selection and imputation
Nov 29, 2021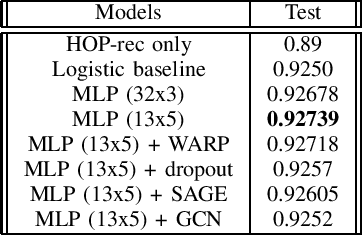
The Science4cast Competition consists of predicting new links in a semantic network, with each node representing a concept and each edge representing a link proposed by a paper relating two concepts. This network contains information from 1994-2017, with a discretization of days (which represents the publication date of the underlying papers). Team Hash Brown's final submission, \emph{ee5a}, achieved a score of 0.92738 on the test set. Our team's score ranks \emph{second place}, 0.01 below the winner's score. This paper details our model, its intuition, and the performance of its variations in the test set.