 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FaSS-MVS -- Fast Multi-View Stereo with Surface-Aware Semi-Global Matching from UAV-borne Monocular Imagery
Dec 01, 2021
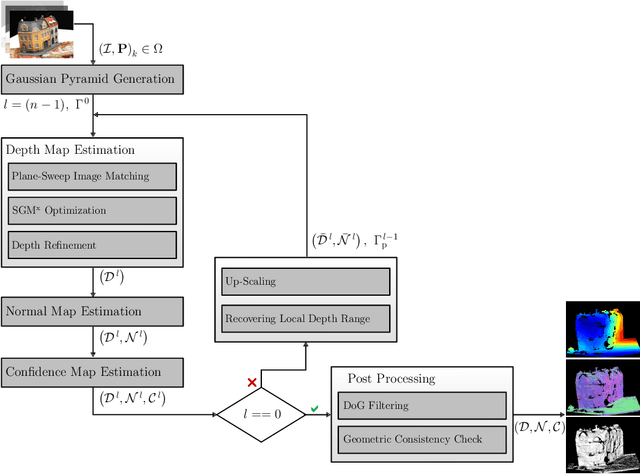
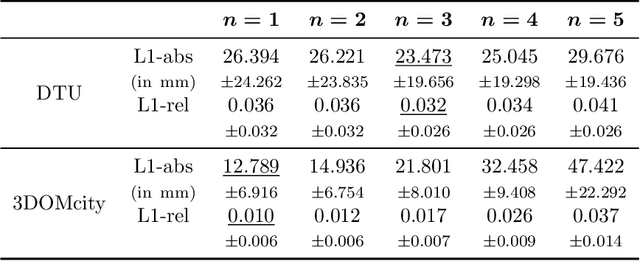
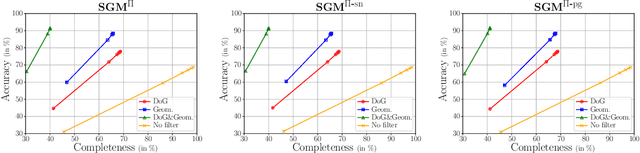
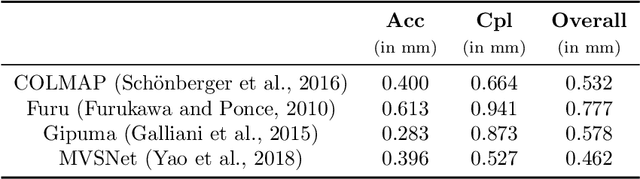
With FaSS-MVS, we present an approach for fast multi-view stereo with surface-aware Semi-Global Matching that allows for rapid depth and normal map estimation from monocular aerial video data captured by UAVs. The data estimated by FaSS-MVS, in turn, facilitates online 3D mapping, meaning that a 3D map of the scene is immediately and incrementally generated while the image data is acquired or being received. FaSS-MVS is comprised of a hierarchical processing scheme in which depth and normal data, as well as corresponding confidence scores, are estimated in a coarse-to-fine manner, allowing to efficiently process large scene depths which are inherent to oblique imagery captured by low-flying UAVs. The actual depth estimation employs a plane-sweep algorithm for dense multi-image matching to produce depth hypotheses from which the actual depth map is extracted by means of a surface-aware semi-global optimization, reducing the fronto-parallel bias of SGM. Given the estimated depth map, the pixel-wise surface normal information is then computed by reprojecting the depth map into a point cloud and calculating the normal vectors within a confined local neighborhood. In a thorough quantitative and ablative study we show that the accuracies of the 3D information calculated by FaSS-MVS is close to that of state-of-the-art approaches for offline multi-view stereo, with the error not even being one magnitude higher than that of COLMAP. At the same time, however, the average run-time of FaSS-MVS to estimate a single depth and normal map is less than 14 % of that of COLMAP, allowing to perform an online and incremental processing of Full-HD imagery at 1-2 Hz.
Attention-based Bidirectional LSTM for Deceptive Opinion Spam Classification
Dec 29, 2021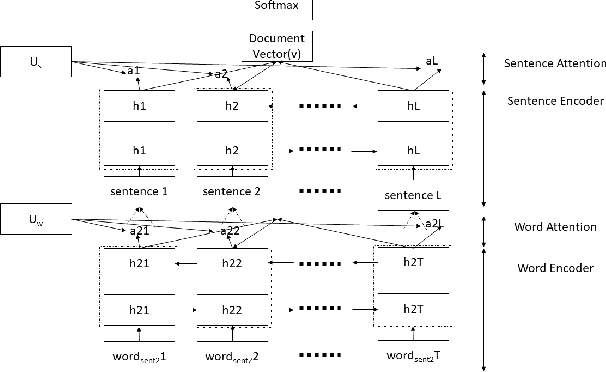
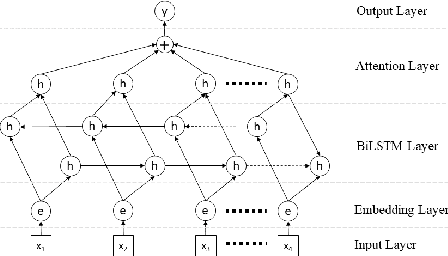
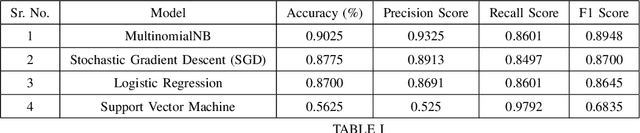
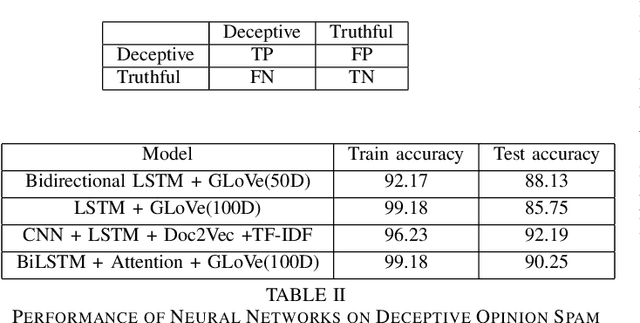
Online Reviews play a vital role in e commerce for decision making. Much of the population makes the decision of which places, restaurant to visit, what to buy and from where to buy based on the reviews posted on the respective platforms. A fraudulent review or opinion spam is categorized as an untruthful or deceptive review. Positive reviews of a product or a restaurant helps attract customers and thereby lead to an increase in sales whereas negative reviews may hamper the progress of a restaurant or sales of a product and thereby lead to defamed reputation and loss. Fraudulent reviews are deliberately posted on various online review platforms to trick customers to buy, visit or distract against a product or a restaurant. They are also written to commend or discredit the product's repute. The work aims at detecting and classifying the reviews as deceptive or truthful. It involves use of various deep learning techniques for classifying the reviews and an overview of proposed approach involving Attention based Bidirectional LSTM to tackle issues related to semantic information in reviews and a comparative study over baseline machine learning techniques for review classification.
Integration of Vehicular Clouds and Autonomous Driving: Survey and Future Perspectives
Jan 15, 2022
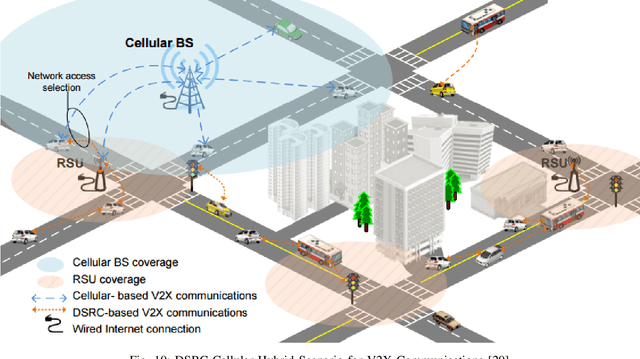
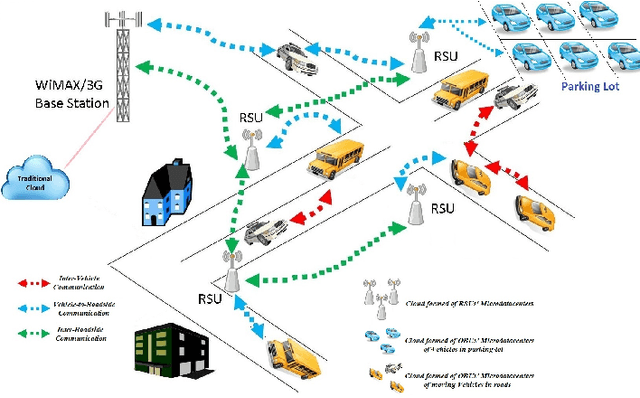
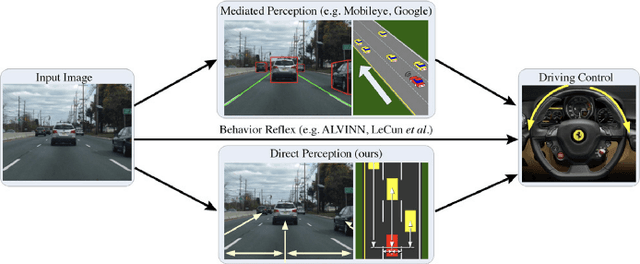
For decades, researchers on Vehicular Ad-hoc Networks (VANETs) and autonomous vehicles presented various solutions for vehicular safety and autonomy, respectively. Yet, the developed work in these two areas has been mostly conducted in their own separate worlds, and barely affect one-another despite the obvious relationships. In the coming years, the Internet of Vehicles (IoV), encompassing sensing, communications, connectivity, processing, networking, and computation is expected to bridge many technologies to offer value-added information for the navigation of self-driving vehicles, to reduce vehicle on board computation, and to deliver desired functionalities. Potentials for bridging the gap between these two worlds and creating synergies of these two technologies have recently started to attract significant attention of many companies and government agencies. In this article, we first present a comprehensive survey and an overview of the emerging key challenges related to the two worlds of Vehicular Clouds (VCs) including communications, networking, traffic modelling, medium access, VC Computing (VCC), VC collation strategies, security issues, and autonomous driving (AD) including 3D environment learning approaches and AD enabling deep-learning, computer vision and Artificial Intelligence (AI) techniques. We then discuss the recent related work and potential trends on merging these two worlds in order to enrich vehicle cognition of its surroundings, and enable safer and more informed and coordinated AD systems. Compared to other survey papers, this work offers more detailed summaries of the most relevant VCs and ADs systems in the literature, along with some key challenges and insights on how different technologies fit together to deliver safety, autonomy and infotainment services.
ExClus: Explainable Clustering on Low-dimensional Data Representations
Nov 04, 2021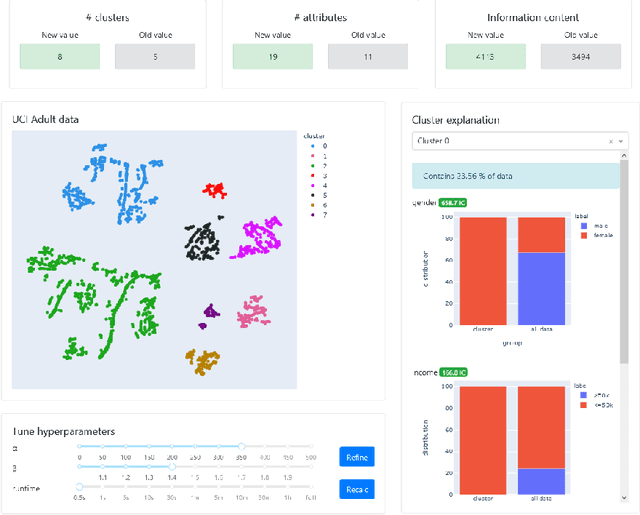
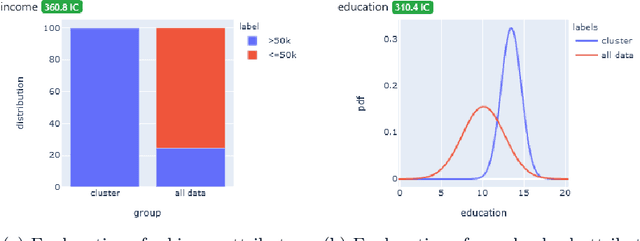
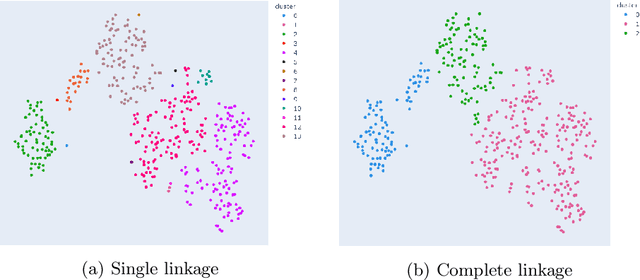
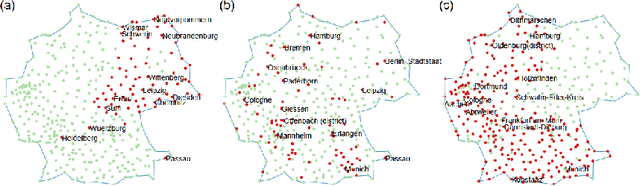
Dimensionality reduction and clustering techniques are frequently used to analyze complex data sets, but their results are often not easy to interpret. We consider how to support users in interpreting apparent cluster structure on scatter plots where the axes are not directly interpretable, such as when the data is projected onto a two-dimensional space using a dimensionality-reduction method. Specifically, we propose a new method to compute an interpretable clustering automatically, where the explanation is in the original high-dimensional space and the clustering is coherent in the low-dimensional projection. It provides a tunable balance between the complexity and the amount of information provided, through the use of information theory. We study the computational complexity of this problem and introduce restrictions on the search space of solutions to arrive at an efficient, tunable, greedy optimization algorithm. This algorithm is furthermore implemented in an interactive tool called ExClus. Experiments on several data sets highlight that ExClus can provide informative and easy-to-understand patterns, and they expose where the algorithm is efficient and where there is room for improvement considering tunability and scalability.
Hidden Effects of COVID-19 on Healthcare Workers: A Machine Learning Analysis
Dec 12, 2021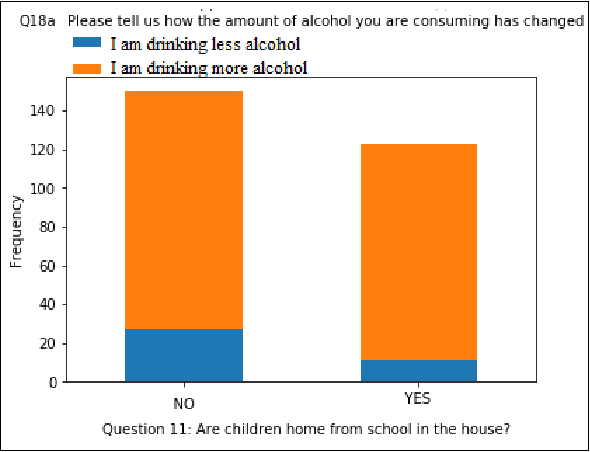
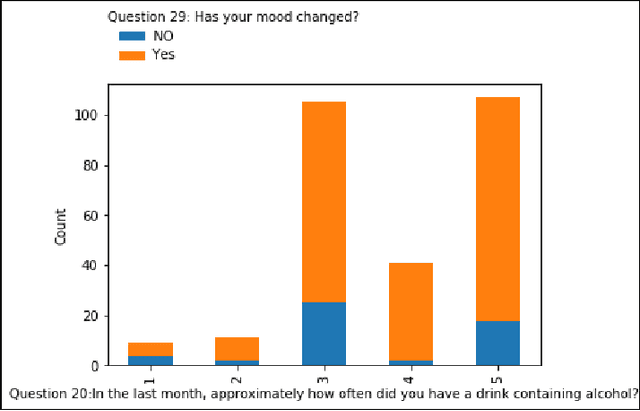
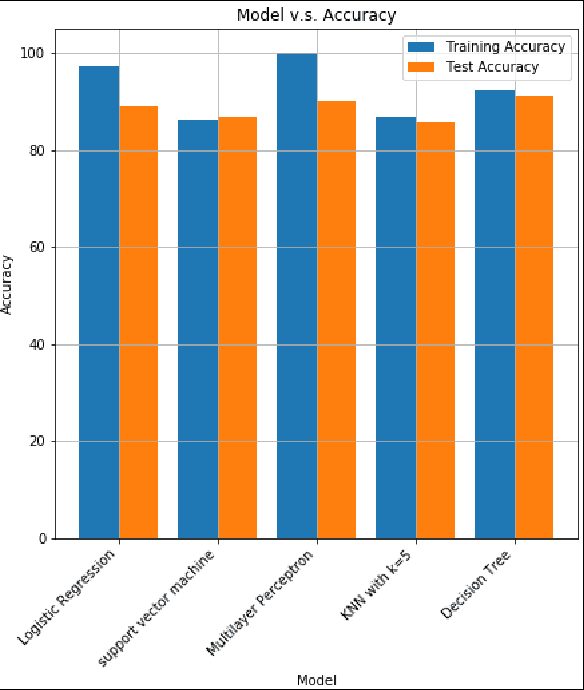

In this paper, we analyze some effects of the COVID-19 pandemic on healthcare workers. We specifically focus on alcohol consumption habit changes among healthcare workers using a mental health survey data obtained from the University of Michigan Inter-University Consortium for Political and Social Research. We use supervised and unsupervised machine learning methods and models such as Decision Trees, Logistic Regression, Naive Bayes classifier, k-Nearest Neighbors, Support Vector Machines, Multilayer perceptron, Random Forests, XGBoost, CatBoost, LightGBM, Synthetic Minority Oversampling, Chi-Squared Test and mutual information method to find out relationships between COVID-19 related negative effects and alcohol use changes in healthcare workers. Our findings suggest that some effects of the COVID-19 pandemic such as school closure, work schedule change and COVID-related news exposure may lead to an increase in alcohol use.
Stochastic One-Sided Full-Information Bandit
Jun 20, 2019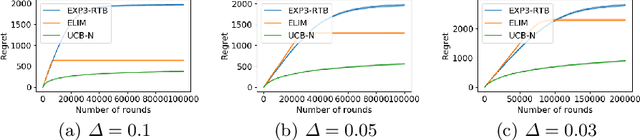
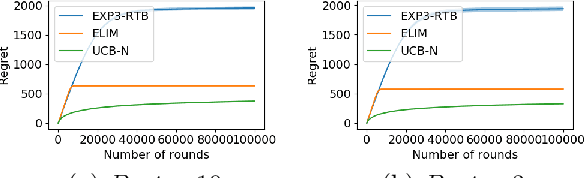
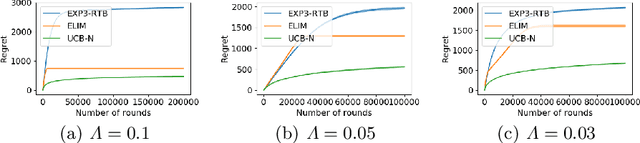
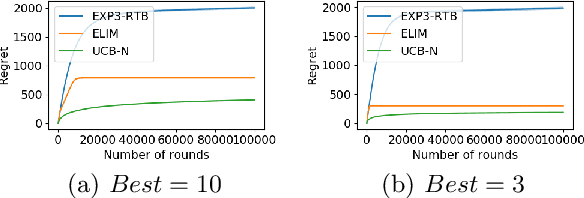
In this paper, we study the stochastic version of the one-sided full information bandit problem, where we have $K$ arms $[K] = \{1, 2, \ldots, K\}$, and playing arm $i$ would gain reward from an unknown distribution for arm $i$ while obtaining reward feedback for all arms $j \ge i$. One-sided full information bandit can model the online repeated second-price auctions, where the auctioneer could select the reserved price in each round and the bidders only reveal their bids when their bids are higher than the reserved price. In this paper, we present an elimination-based algorithm to solve the problem. Our elimination based algorithm achieves distribution independent regret upper bound $O(\sqrt{T\cdot\log (TK)})$, and distribution dependent bound $O((\log T + \log K)f(\Delta))$, where $T$ is the time horizon, $\Delta$ is a vector of gaps between the mean reward of arms and the mean reward of the best arm, and $f(\Delta)$ is a formula depending on the gap vector that we will specify in detail. Our algorithm has the best theoretical regret upper bound so far. We also validate our algorithm empirically against other possible alternatives.
Deep Domain Adaptation for Pavement Crack Detection
Nov 19, 2021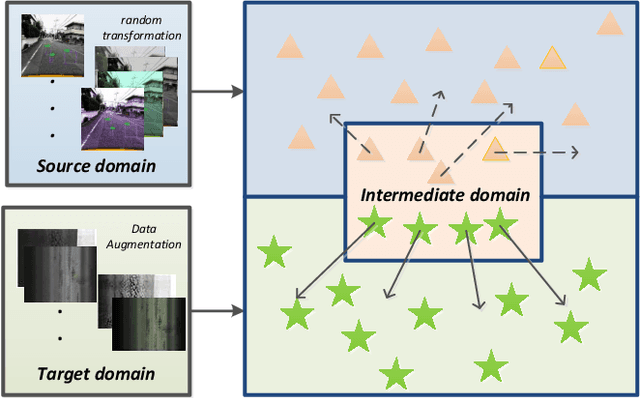

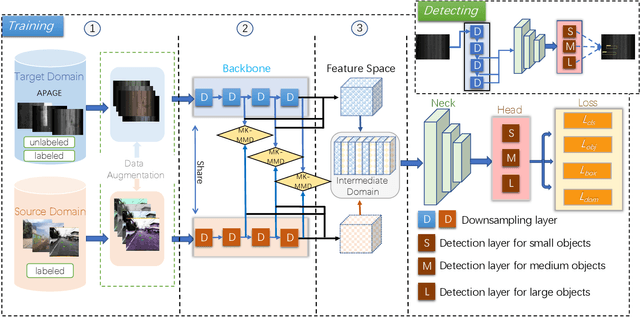
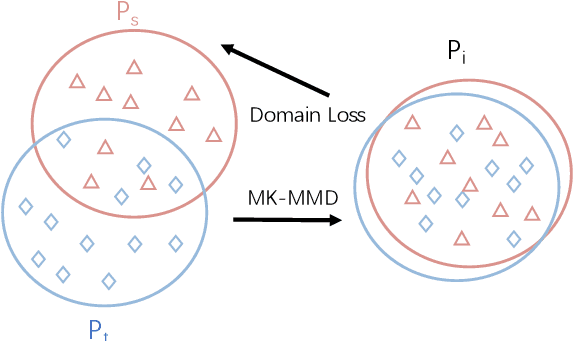
Deep learning-based pavement cracks detection methods often require large-scale labels with detailed crack location information to learn accurate predictions. In practice, however, crack locations are very difficult to be manually annotated due to various visual patterns of pavement crack. In this paper, we propose a Deep Domain Adaptation-based Crack Detection Network (DDACDN), which learns to take advantage of the source domain knowledge to predict the multi-category crack location information in the target domain, where only image-level labels are available. Specifically, DDACDN first extracts crack features from both the source and target domain by a two-branch weights-shared backbone network. And in an effort to achieve the cross-domain adaptation, an intermediate domain is constructed by aggregating the three-scale features from the feature space of each domain to adapt the crack features from the source domain to the target domain. Finally, the network involves the knowledge of both domains and is trained to recognize and localize pavement cracks. To facilitate accurate training and validation for domain adaptation, we use two challenging pavement crack datasets CQU-BPDD and RDD2020. Furthermore, we construct a new large-scale Bituminous Pavement Multi-label Disease Dataset named CQU-BPMDD, which contains 38994 high-resolution pavement disease images to further evaluate the robustness of our model. Extensive experiments demonstrate that DDACDN outperforms state-of-the-art pavement crack detection methods in predicting the crack location on the target domain.
Dual Path Structural Contrastive Embeddings for Learning Novel Objects
Dec 24, 2021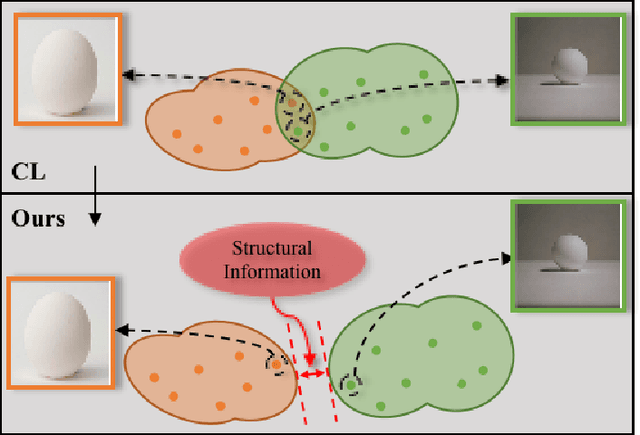
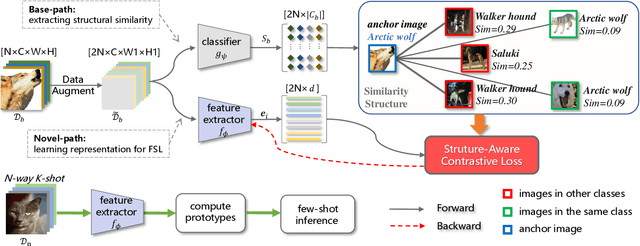
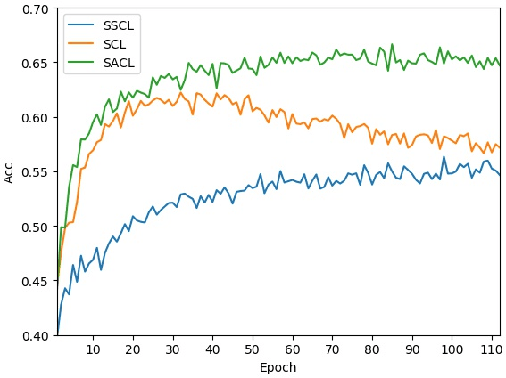

Learning novel classes from a very few labeled samples has attracted increasing attention in machine learning areas. Recent research on either meta-learning based or transfer-learning based paradigm demonstrates that gaining information on a good feature space can be an effective solution to achieve favorable performance on few-shot tasks. In this paper, we propose a simple but effective paradigm that decouples the tasks of learning feature representations and classifiers and only learns the feature embedding architecture from base classes via the typical transfer-learning training strategy. To maintain both the generalization ability across base and novel classes and discrimination ability within each class, we propose a dual path feature learning scheme that effectively combines structural similarity with contrastive feature construction. In this way, both inner-class alignment and inter-class uniformity can be well balanced, and result in improved performance. Experiments on three popular benchmarks show that when incorporated with a simple prototype based classifier, our method can still achieve promising results for both standard and generalized few-shot problems in either an inductive or transductive inference setting.
Parameter identifiability of a deep feedforward ReLU neural network
Dec 24, 2021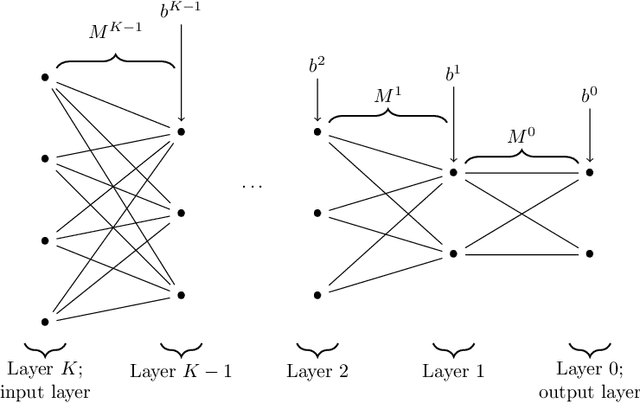
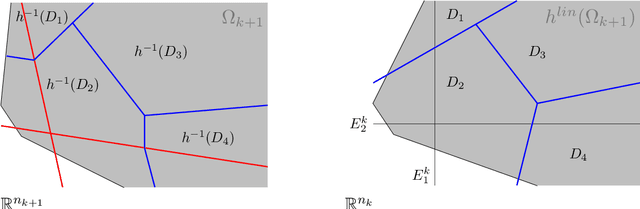
The possibility for one to recover the parameters-weights and biases-of a neural network thanks to the knowledge of its function on a subset of the input space can be, depending on the situation, a curse or a blessing. On one hand, recovering the parameters allows for better adversarial attacks and could also disclose sensitive information from the dataset used to construct the network. On the other hand, if the parameters of a network can be recovered, it guarantees the user that the features in the latent spaces can be interpreted. It also provides foundations to obtain formal guarantees on the performances of the network. It is therefore important to characterize the networks whose parameters can be identified and those whose parameters cannot. In this article, we provide a set of conditions on a deep fully-connected feedforward ReLU neural network under which the parameters of the network are uniquely identified-modulo permutation and positive rescaling-from the function it implements on a subset of the input space.
DM-VIO: Delayed Marginalization Visual-Inertial Odometry
Jan 11, 2022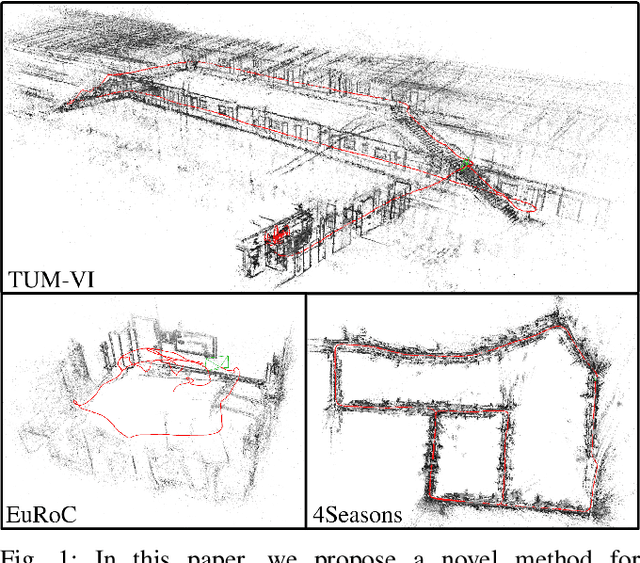
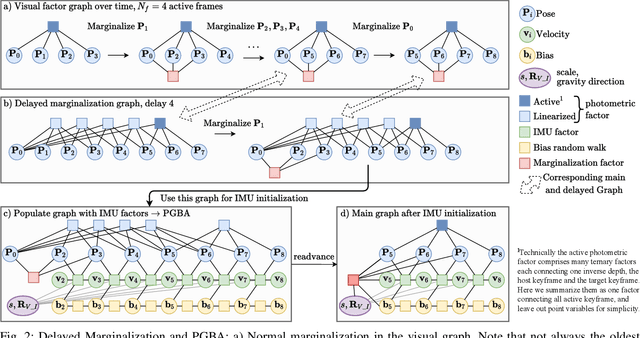
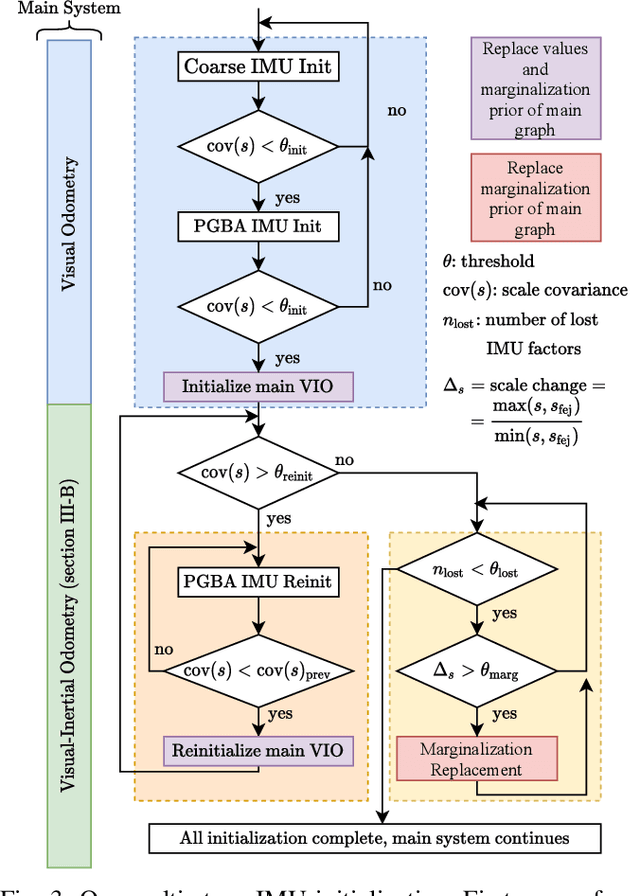
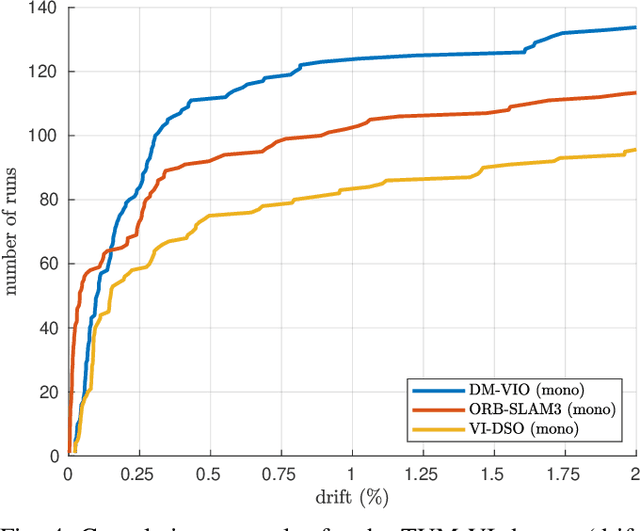
We present DM-VIO, a monocular visual-inertial odometry system based on two novel techniques called delayed marginalization and pose graph bundle adjustment. DM-VIO performs photometric bundle adjustment with a dynamic weight for visual residuals. We adopt marginalization, which is a popular strategy to keep the update time constrained, but it cannot easily be reversed, and linearization points of connected variables have to be fixed. To overcome this we propose delayed marginalization: The idea is to maintain a second factor graph, where marginalization is delayed. This allows us to later readvance this delayed graph, yielding an updated marginalization prior with new and consistent linearization points. In addition, delayed marginalization enables us to inject IMU information into already marginalized states. This is the foundation of the proposed pose graph bundle adjustment, which we use for IMU initialization. In contrast to prior works on IMU initialization, it is able to capture the full photometric uncertainty, improving the scale estimation. In order to cope with initially unobservable scale, we continue to optimize scale and gravity direction in the main system after IMU initialization is complete. We evaluate our system on the EuRoC, TUM-VI, and 4Seasons datasets, which comprise flying drone, large-scale handheld, and automotive scenarios. Thanks to the proposed IMU initialization, our system exceeds the state of the art in visual-inertial odometry, even outperforming stereo-inertial methods while using only a single camera and IMU. The code will be published at http://vision.in.tum.de/dm-vio