 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Contrastive Learning for Local and Global Learning MRI Reconstruction
Nov 30, 2021
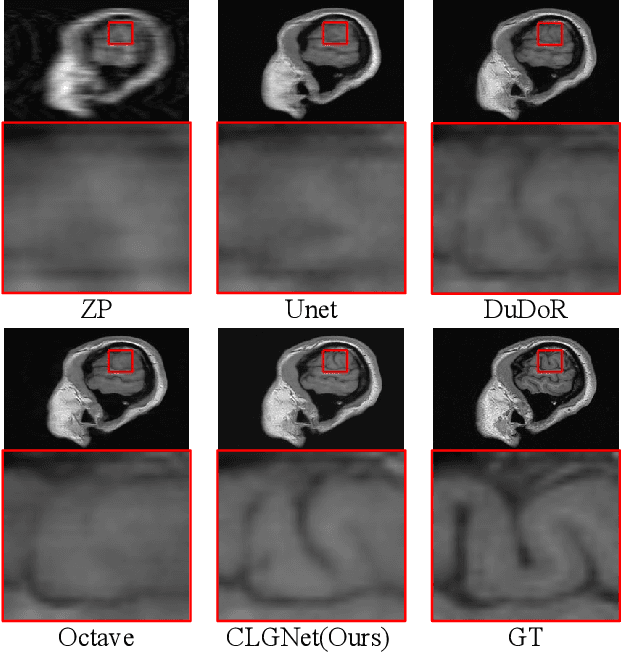
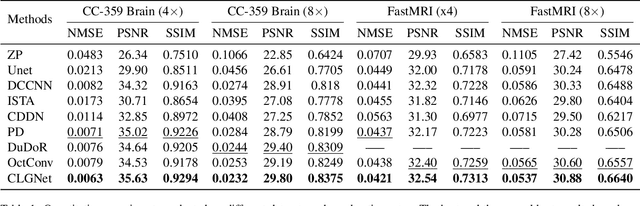
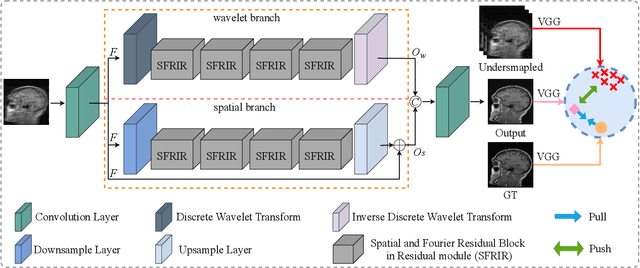
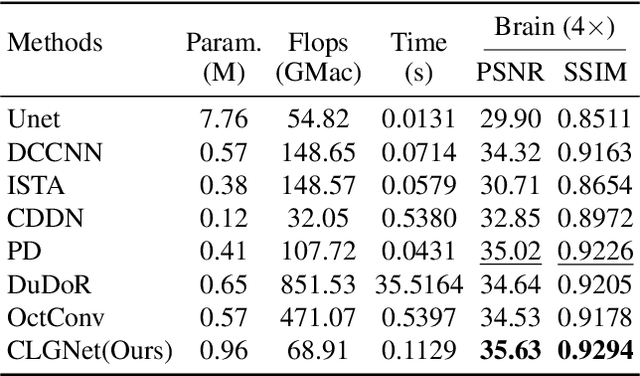
Magnetic Resonance Imaging (MRI) is an important medical imaging modality, while it requires a long acquisition time. To reduce the acquisition time, various methods have been proposed. However, these methods failed to reconstruct images with a clear structure for two main reasons. Firstly, similar patches widely exist in MR images, while most previous deep learning-based methods ignore this property and only adopt CNN to learn local information. Secondly, the existing methods only use clear images to constrain the upper bound of the solution space, while the lower bound is not constrained, so that a better parameter of the network cannot be obtained. To address these problems, we propose a Contrastive Learning for Local and Global Learning MRI Reconstruction Network (CLGNet). Specifically, according to the Fourier theory, each value in the Fourier domain is calculated from all the values in Spatial domain. Therefore, we propose a Spatial and Fourier Layer (SFL) to simultaneously learn the local and global information in Spatial and Fourier domains. Moreover, compared with self-attention and transformer, the SFL has a stronger learning ability and can achieve better performance in less time. Based on the SFL, we design a Spatial and Fourier Residual block as the main component of our model. Meanwhile, to constrain the lower bound and upper bound of the solution space, we introduce contrastive learning, which can pull the result closer to the clear image and push the result further away from the undersampled image. Extensive experimental results on different datasets and acceleration rates demonstrate that the proposed CLGNet achieves new state-of-the-art results.
Automatic Fact-Checking Using Context and Discourse Information
Aug 04, 2019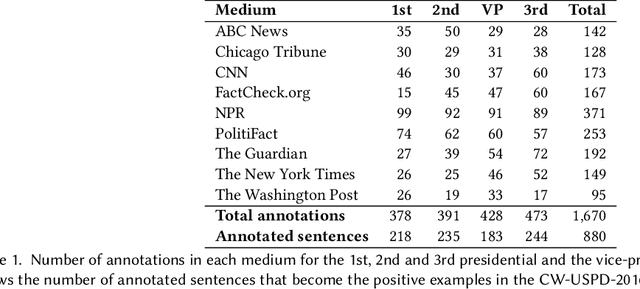
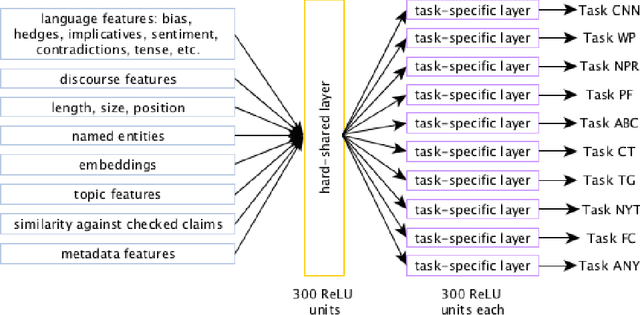

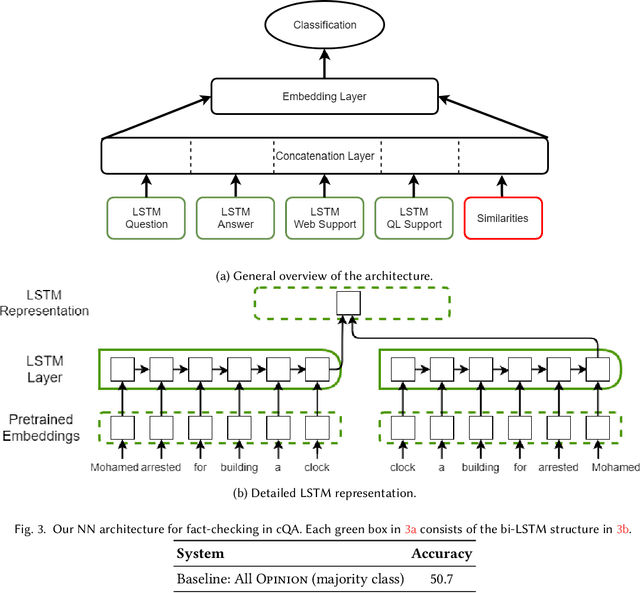
We study the problem of automatic fact-checking, paying special attention to the impact of contextual and discourse information. We address two related tasks: (i) detecting check-worthy claims, and (ii) fact-checking claims. We develop supervised systems based on neural networks, kernel-based support vector machines, and combinations thereof, which make use of rich input representations in terms of discourse cues and contextual features. For the check-worthiness estimation task, we focus on political debates, and we model the target claim in the context of the full intervention of a participant and the previous and the following turns in the debate, taking into account contextual meta information. For the fact-checking task, we focus on answer verification in a community forum, and we model the veracity of the answer with respect to the entire question--answer thread in which it occurs as well as with respect to other related posts from the entire forum. We develop annotated datasets for both tasks and we run extensive experimental evaluation, confirming that both types of information ---but especially contextual features--- play an important role.
* JDIQ,Special Issue on Combating Digital Misinformation and Disinformation
Utilizing Wordnets for Cognate Detection among Indian Languages
Dec 30, 2021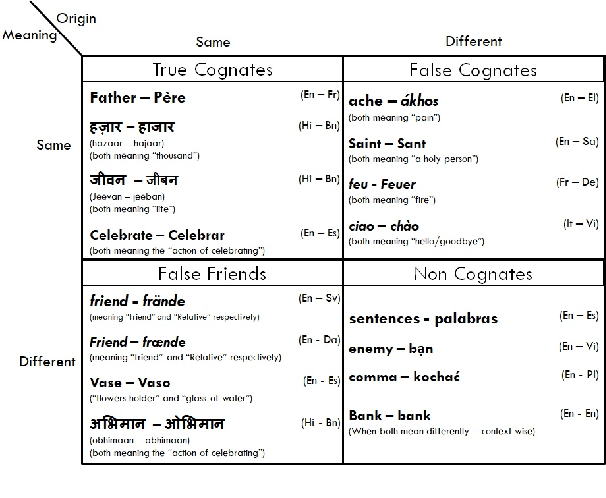
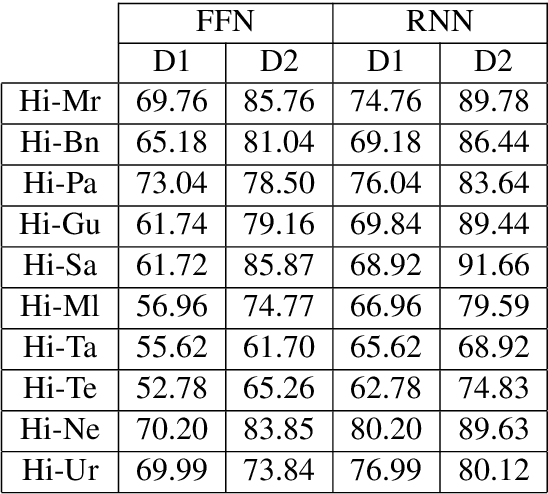
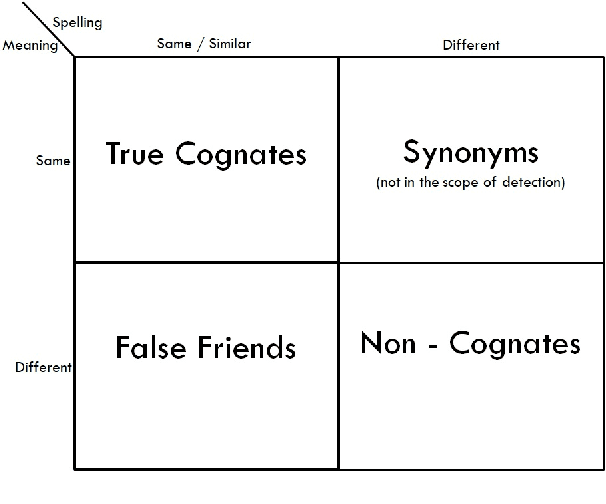
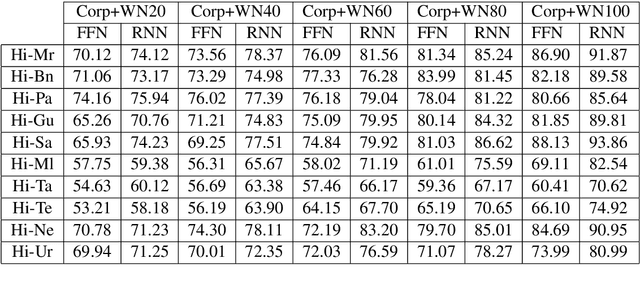
Automatic Cognate Detection (ACD) is a challenging task which has been utilized to help NLP applications like Machine Translation, Information Retrieval and Computational Phylogenetics. Unidentified cognate pairs can pose a challenge to these applications and result in a degradation of performance. In this paper, we detect cognate word pairs among ten Indian languages with Hindi and use deep learning methodologies to predict whether a word pair is cognate or not. We identify IndoWordnet as a potential resource to detect cognate word pairs based on orthographic similarity-based methods and train neural network models using the data obtained from it. We identify parallel corpora as another potential resource and perform the same experiments for them. We also validate the contribution of Wordnets through further experimentation and report improved performance of up to 26%. We discuss the nuances of cognate detection among closely related Indian languages and release the lists of detected cognates as a dataset. We also observe the behaviour of, to an extent, unrelated Indian language pairs and release the lists of detected cognates among them as well.
Streamlining Evaluation with ir-measures
Nov 26, 2021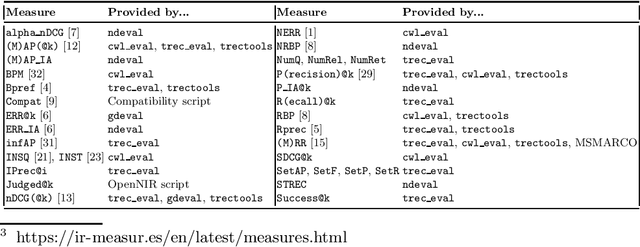
We present ir-measures, a new tool that makes it convenient to calculate a diverse set of evaluation measures used in information retrieval. Rather than implementing its own measure calculations, ir-measures provides a common interface to a handful of evaluation tools. The necessary tools are automatically invoked (potentially multiple times) to calculate all the desired metrics, simplifying the evaluation process for the user. The tool also makes it easier for researchers to use recently-proposed measures (such as those from the C/W/L framework) alongside traditional measures, potentially encouraging their adoption.
Forgetting Outside the Box: Scrubbing Deep Networks of Information Accessible from Input-Output Observations
Mar 16, 2020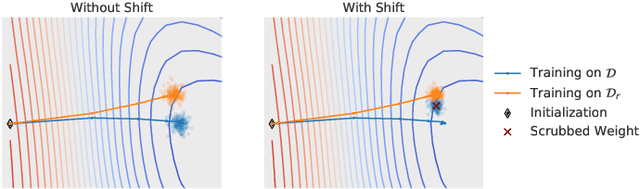
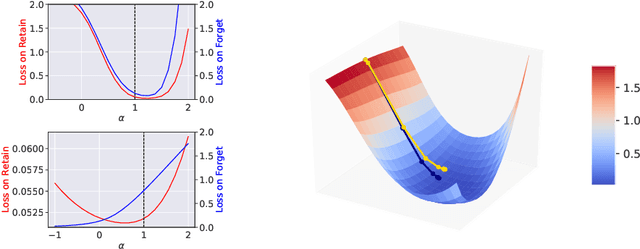
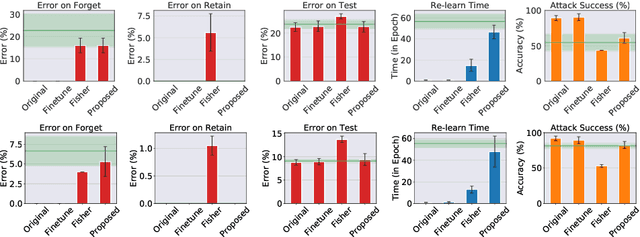
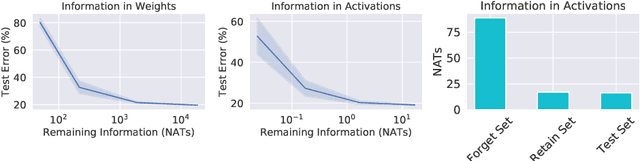
We describe a procedure for removing dependency on a cohort of training data from a trained deep network that improves upon and generalizes previous methods to different readout functions and can be extended to ensure forgetting in the activations of the network. We introduce a new bound on how much information can be extracted per query about the forgotten cohort from a black-box network for which only the input-output behavior is observed. The proposed forgetting procedure has a deterministic part derived from the differential equations of a linearized version of the model, and a stochastic part that ensures information destruction by adding noise tailored to the geometry of the loss landscape. We exploit the connections between the activation and weight dynamics of a DNN inspired by Neural Tangent Kernels to compute the information in the activations.
Functional Anomaly Detection: a Benchmark Study
Jan 13, 2022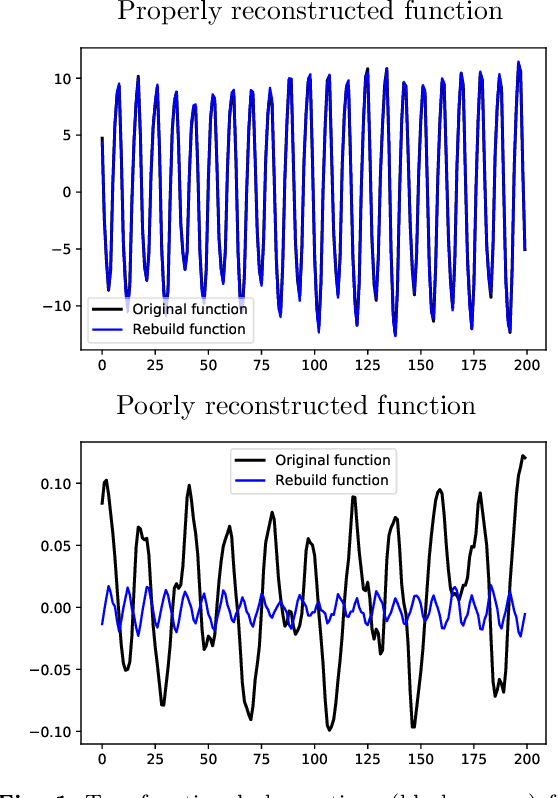
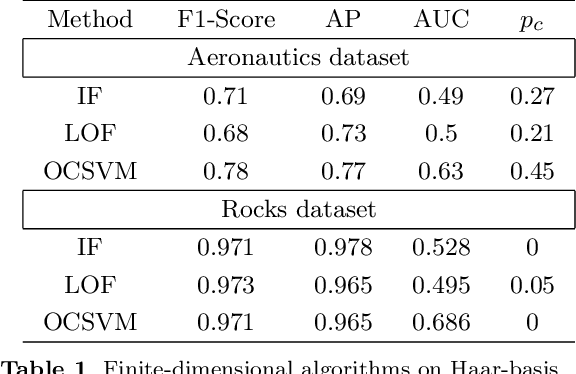
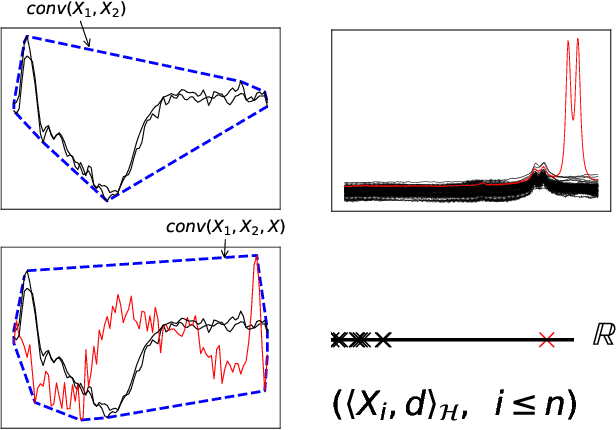
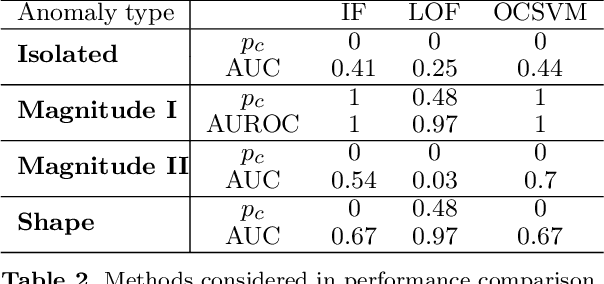
The increasing automation in many areas of the Industry expressly demands to design efficient machine-learning solutions for the detection of abnormal events. With the ubiquitous deployment of sensors monitoring nearly continuously the health of complex infrastructures, anomaly detection can now rely on measurements sampled at a very high frequency, providing a very rich representation of the phenomenon under surveillance. In order to exploit fully the information thus collected, the observations cannot be treated as multivariate data anymore and a functional analysis approach is required. It is the purpose of this paper to investigate the performance of recent techniques for anomaly detection in the functional setup on real datasets. After an overview of the state-of-the-art and a visual-descriptive study, a variety of anomaly detection methods are compared. While taxonomies of abnormalities (e.g. shape, location) in the functional setup are documented in the literature, assigning a specific type to the identified anomalies appears to be a challenging task. Thus, strengths and weaknesses of the existing approaches are benchmarked in view of these highlighted types in a simulation study. Anomaly detection methods are next evaluated on two datasets, related to the monitoring of helicopters in flight and to the spectrometry of construction materials namely. The benchmark analysis is concluded by recommendation guidance for practitioners.
Generating Diverse and Consistent QA pairs from Contexts with Information-Maximizing Hierarchical Conditional VAEs
Jun 15, 2020
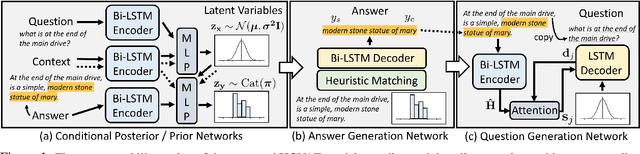
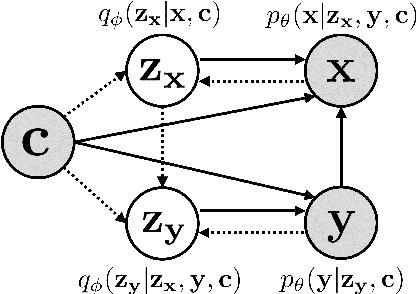
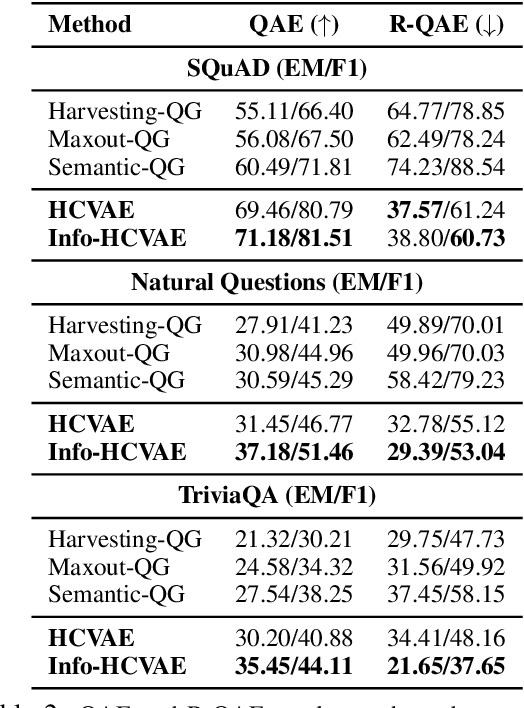
One of the most crucial challenges in question answering (QA) is the scarcity of labeled data, since it is costly to obtain question-answer (QA) pairs for a target text domain with human annotation. An alternative approach to tackle the problem is to use automatically generated QA pairs from either the problem context or from large amount of unstructured texts (e.g. Wikipedia). In this work, we propose a hierarchical conditional variational autoencoder (HCVAE) for generating QA pairs given unstructured texts as contexts, while maximizing the mutual information between generated QA pairs to ensure their consistency. We validate our Information Maximizing Hierarchical Conditional Variational AutoEncoder (Info-HCVAE) on several benchmark datasets by evaluating the performance of the QA model (BERT-base) using only the generated QA pairs (QA-based evaluation) or by using both the generated and human-labeled pairs (semi-supervised learning) for training, against state-of-the-art baseline models. The results show that our model obtains impressive performance gains over all baselines on both tasks, using only a fraction of data for training.
Continually Learning Self-Supervised Representations with Projected Functional Regularization
Dec 30, 2021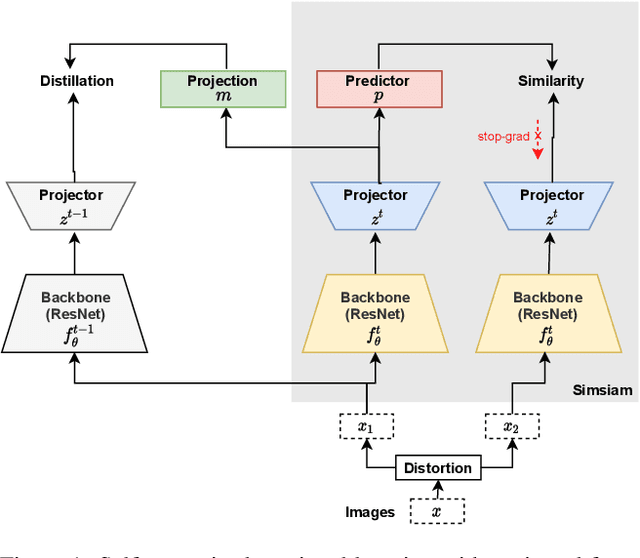
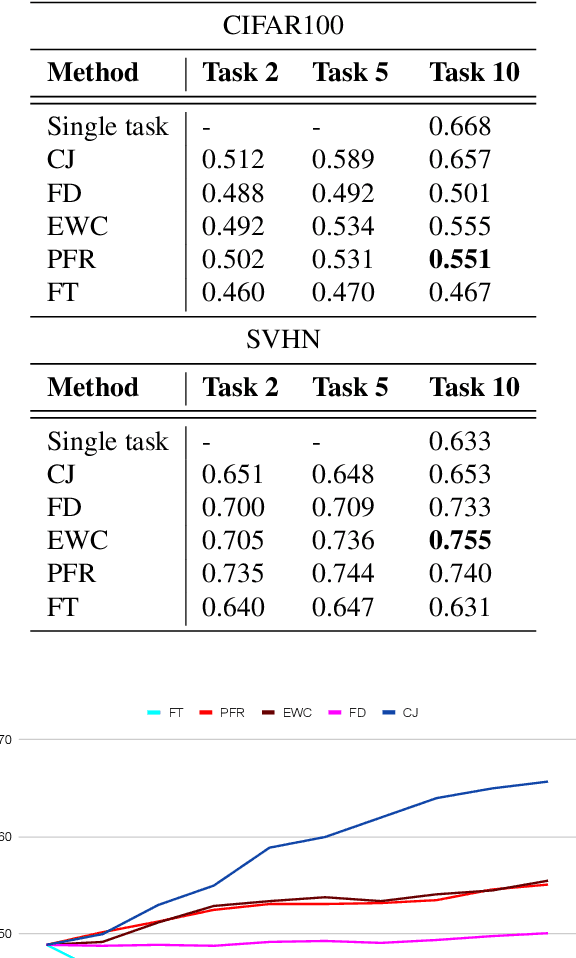
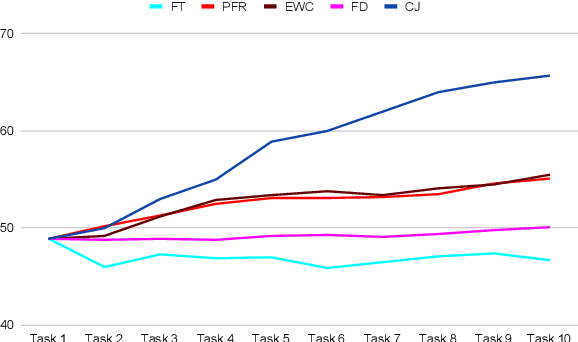
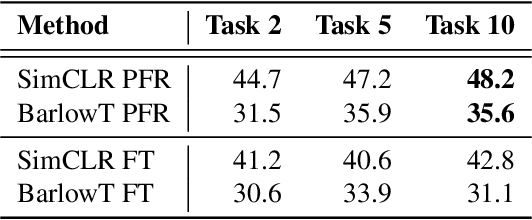
Recent self-supervised learning methods are able to learn high-quality image representations and are closing the gap with supervised methods. However, these methods are unable to acquire new knowledge incrementally -- they are, in fact, mostly used only as a pre-training phase with IID data. In this work we investigate self-supervised methods in continual learning regimes without additional memory or replay. To prevent forgetting of previous knowledge, we propose the usage of functional regularization. We will show that naive functional regularization, also known as feature distillation, leads to low plasticity and therefore seriously limits continual learning performance. To address this problem, we propose Projected Functional Regularization where a separate projection network ensures that the newly learned feature space preserves information of the previous feature space, while allowing for the learning of new features. This allows us to prevent forgetting while maintaining the plasticity of the learner. Evaluation against other incremental learning approaches applied to self-supervision demonstrates that our method obtains competitive performance in different scenarios and on multiple datasets.
Efficient Multi-Modal Embeddings from Structured Data
Oct 06, 2021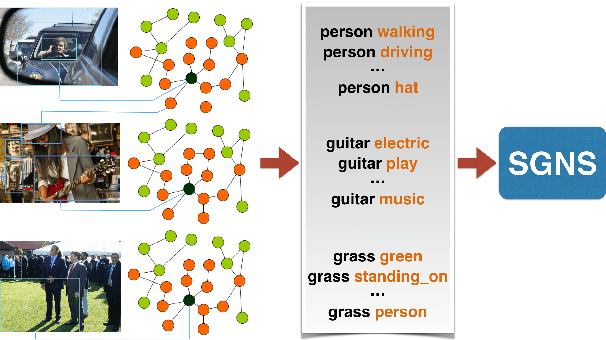
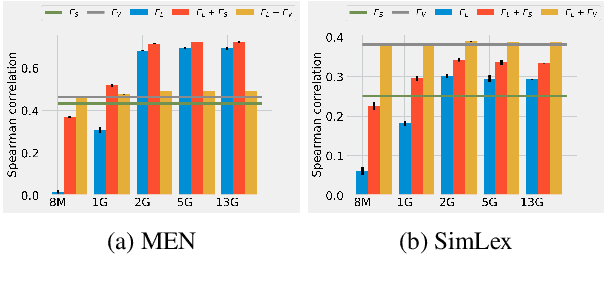
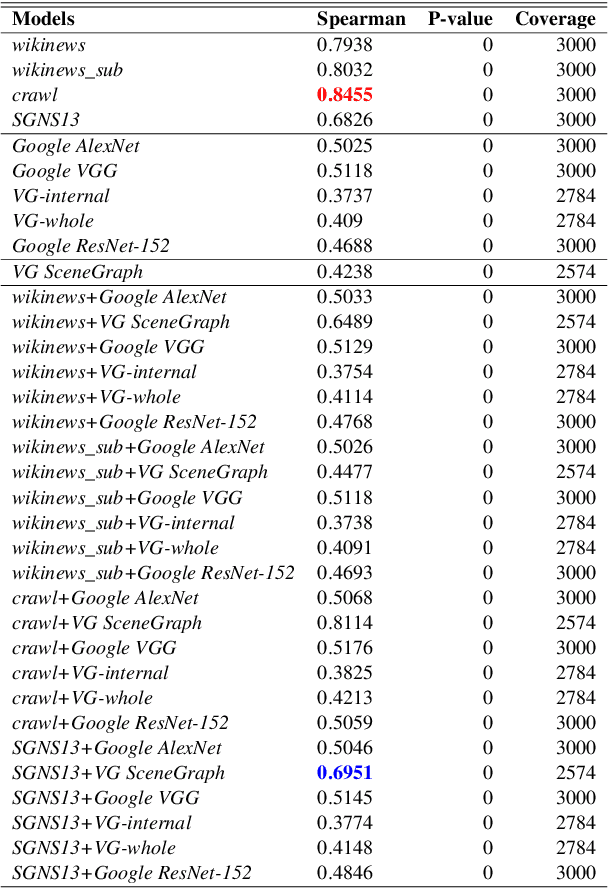
Multi-modal word semantics aims to enhance embeddings with perceptual input, assuming that human meaning representation is grounded in sensory experience. Most research focuses on evaluation involving direct visual input, however, visual grounding can contribute to linguistic applications as well. Another motivation for this paper is the growing need for more interpretable models and for evaluating model efficiency regarding size and performance. This work explores the impact of visual information for semantics when the evaluation involves no direct visual input, specifically semantic similarity and relatedness. We investigate a new embedding type in-between linguistic and visual modalities, based on the structured annotations of Visual Genome. We compare uni- and multi-modal models including structured, linguistic and image based representations. We measure the efficiency of each model with regard to data and model size, modality / data distribution and information gain. The analysis includes an interpretation of embedding structures. We found that this new embedding conveys complementary information for text based embeddings. It achieves comparable performance in an economic way, using orders of magnitude less resources than visual models.
Model Reduction of Shallow CNN Model for Reliable Deployment of Information Extraction from Medical Reports
Jul 31, 2020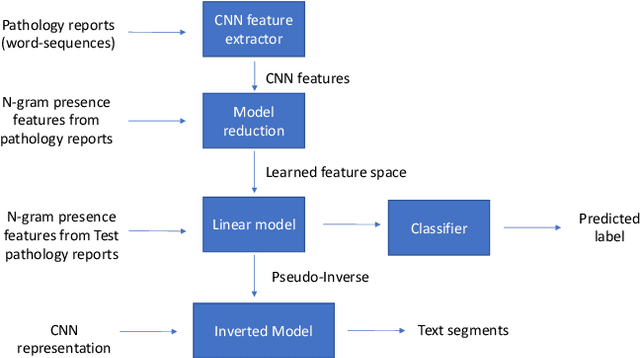

Shallow Convolution Neural Network (CNN) is a time-tested tool for the information extraction from cancer pathology reports. Shallow CNN performs competitively on this task to other deep learning models including BERT, which holds the state-of-the-art for many NLP tasks. The main insight behind this eccentric phenomenon is that the information extraction from cancer pathology reports require only a small number of domain-specific text segments to perform the task, thus making the most of the texts and contexts excessive for the task. Shallow CNN model is well-suited to identify these key short text segments from the labeled training set; however, the identified text segments remain obscure to humans. In this study, we fill this gap by developing a model reduction tool to make a reliable connection between CNN filters and relevant text segments by discarding the spurious connections. We reduce the complexity of shallow CNN representation by approximating it with a linear transformation of n-gram presence representation with a non-negativity and sparsity prior on the transformation weights to obtain an interpretable model. Our approach bridge the gap between the conventionally perceived trade-off boundary between accuracy on the one side and explainability on the other by model reduction.