 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Patent Data for Engineering Design: A Review
Nov 15, 2021
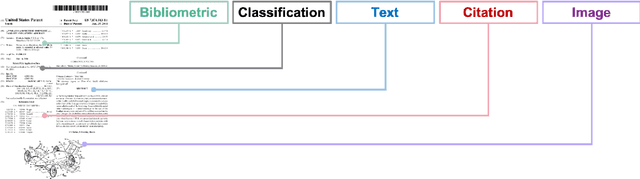

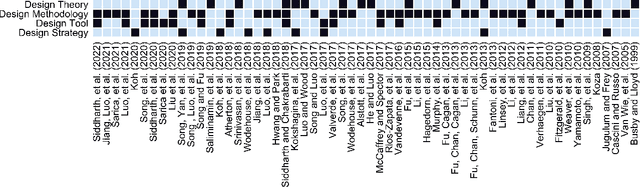
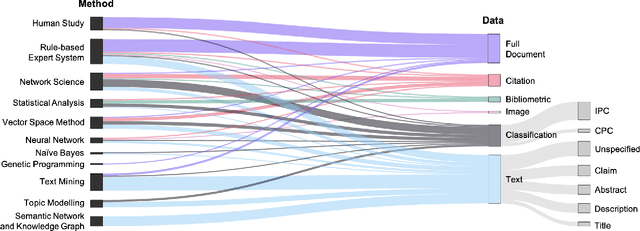
Patent data have been utilized for engineering design research for long because it contains massive amount of design information. Recent advances in artificial intelligence and data science present unprecedented opportunities to mine, analyse and make sense of patent data to develop design theory and methodology. Herein, we survey the patent-for-design literature by their contributions to design theories, methods, tools, and strategies, as well as different forms of patent data and various methods. Our review sheds light on promising future research directions for the field.
DVS: Deep Visibility Series and its Application in Construction Cost Index Forecasting
Nov 07, 2021
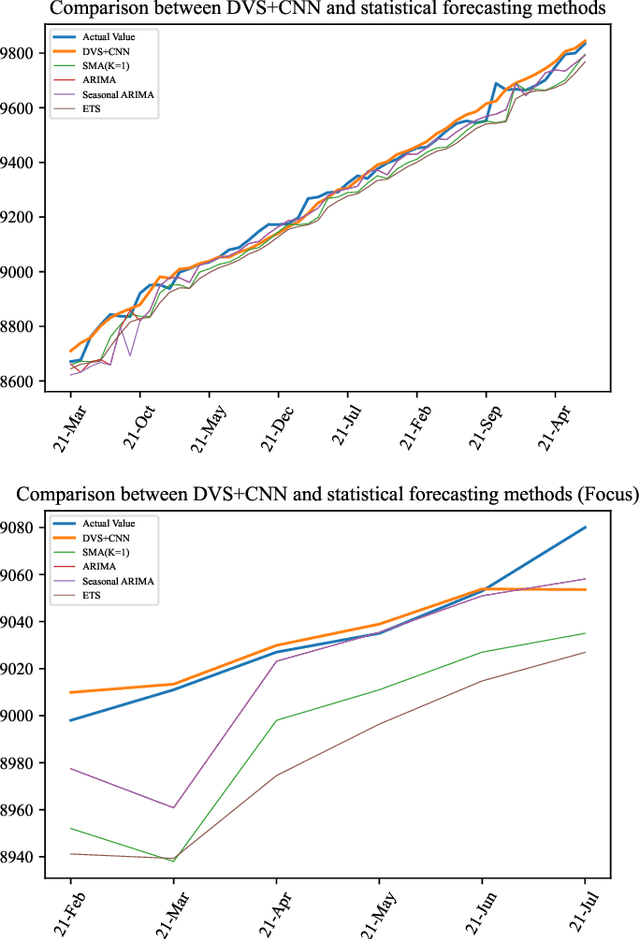
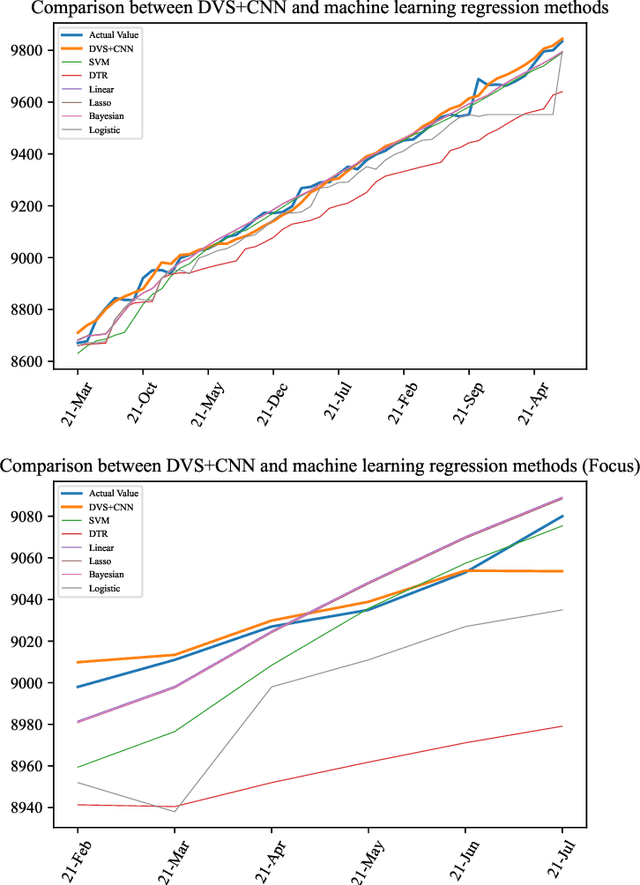
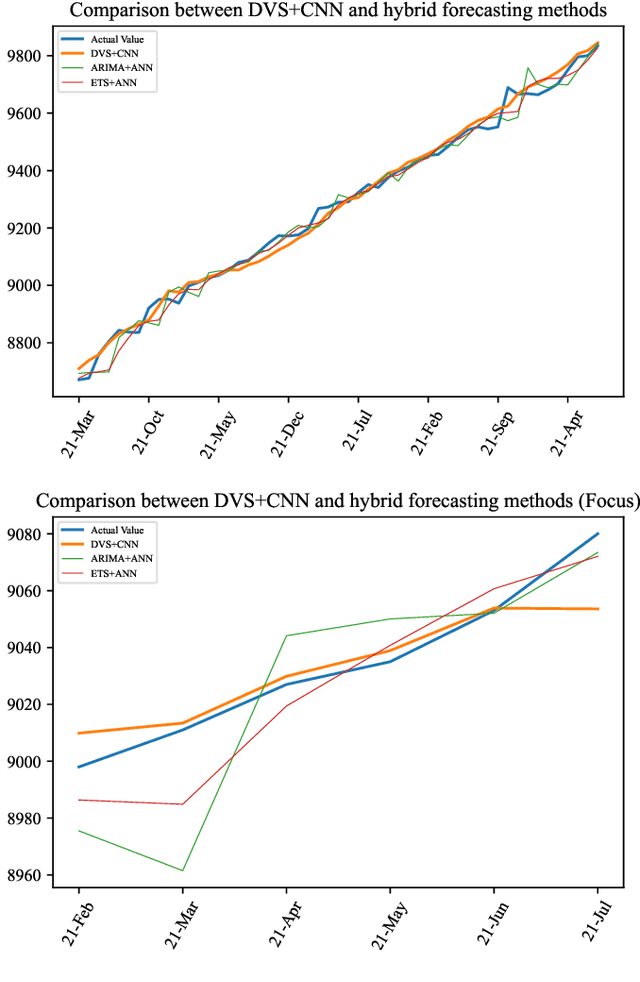
Time series forecasting has always been a hot spot in scientific research. With the development of artificial intelligence, new time series forecasting methods have obtained better forecasting effects and forecasting performance through bionic research and improvements to the past methods. Visibility Graph (VG) algorithm is often used for time series prediction in previous research, but the prediction effect is not as good as deep learning prediction methods such as Artificial Neural Network (ANN), Convolutional Neural Network (CNN) and Long Short-Term Memory Network (LSTM) prediction. The VG algorithm contains a wealth of network information, but previous studies did not effectively use the network information to make predictions, resulting in relatively large prediction errors. In order to solve this problem, this paper proposes the Deep Visibility Series (DVS) module through the bionic design of VG and the expansion of the past research, which is the first time to combine VG with bionic design and deep network. By applying the bionic design of biological vision to VG, the time series of DVS has obtained superior forecast accuracy, which has made a contribution to time series forecasting. At the same time, this paper applies the DVS forecasting method to the construction cost index forecast, which has practical significance.
3DVSR: 3D EPI Volume-based Approach for Angular and Spatial Light field Image Super-resolution
Jan 04, 2022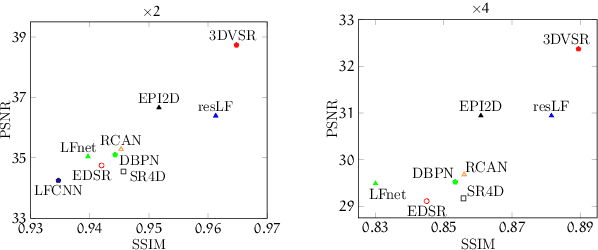
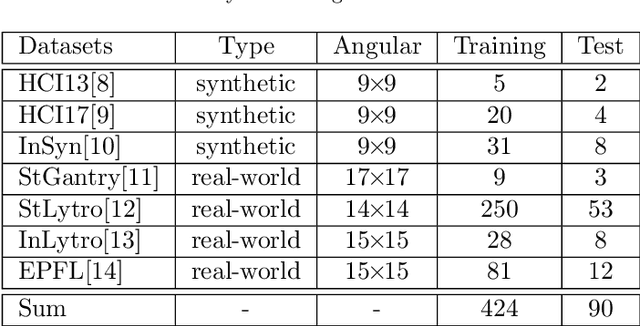
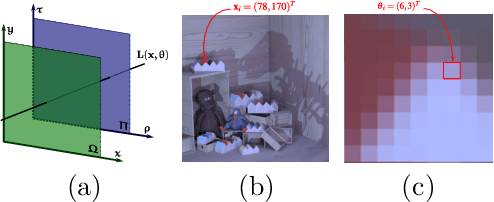

Light field (LF) imaging, which captures both spatial and angular information of a scene, is undoubtedly beneficial to numerous applications. Although various techniques have been proposed for LF acquisition, achieving both angularly and spatially high-resolution LF remains a technology challenge. In this paper, a learning-based approach applied to 3D epipolar image (EPI) is proposed to reconstruct high-resolution LF. Through a 2-stage super-resolution framework, the proposed approach effectively addresses various LF super-resolution (SR) problems, i.e., spatial SR, angular SR, and angular-spatial SR. While the first stage provides flexible options to up-sample EPI volume to the desired resolution, the second stage, which consists of a novel EPI volume-based refinement network (EVRN), substantially enhances the quality of the high-resolution EPI volume. An extensive evaluation on 90 challenging synthetic and real-world light field scenes from 7 published datasets shows that the proposed approach outperforms state-of-the-art methods to a large extend for both spatial and angular super-resolution problem, i.e., an average peak signal to noise ratio improvement of more than 2.0 dB, 1.4 dB, and 3.14 dB in spatial SR $\times 2$, spatial SR $\times 4$, and angular SR respectively. The reconstructed 4D light field demonstrates a balanced performance distribution across all perspective images and presents superior visual quality compared to the previous works.
LiMuSE: Lightweight Multi-modal Speaker Extraction
Nov 07, 2021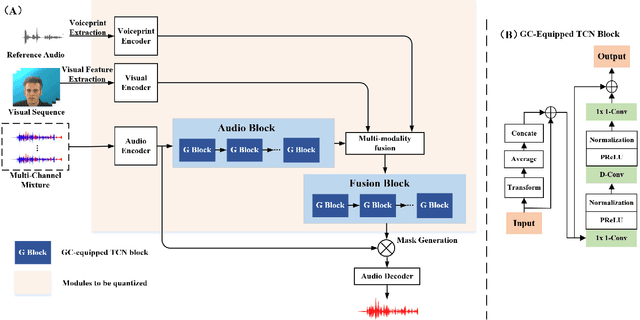

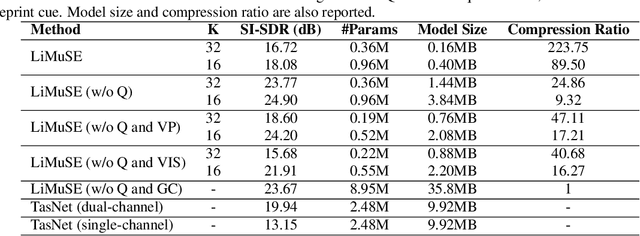
The past several years have witnessed significant progress in modeling the Cocktail Party Problem in terms of speech separation and speaker extraction. In recent years, multi-modal cues, including spatial information, facial expression and voiceprint, are introduced to speaker extraction task to serve as complementary information to each other to achieve better performance. However, the front-end model, for speaker extraction, become large and hard to deploy on a resource-constrained device. In this paper, we address the aforementioned problem with novel model architectures and model compression techniques, and propose a lightweight multi-modal framework for speaker extraction (dubbed LiMuSE), which adopts group communication (GC) to split multi-modal high-dimension features into groups of low-dimension features with smaller width which could be run in parallel, and further uses an ultra-low bit quantization strategy to achieve lower model size. The experiments on the GRID dataset show that incorporating GC into the multi-modal framework achieves on par or better performance with 24.86 times fewer parameters, and applying the quantization strategy to the GC-equipped model further obtains about 9 times compression ratio while maintaining a comparable performance compared with baselines. Our code will be available at https://github.com/aispeech-lab/LiMuSE.
Diagnosing BERT with Retrieval Heuristics
Jan 12, 2022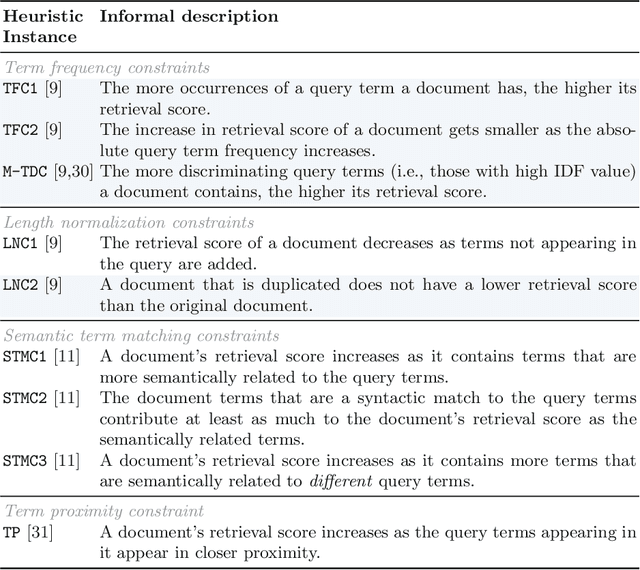
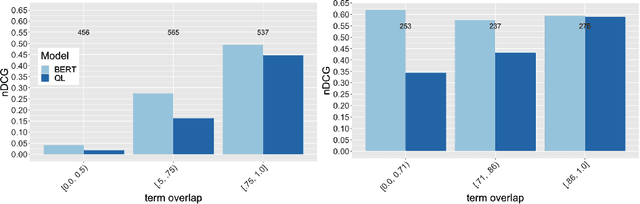


Word embeddings, made widely popular in 2013 with the release of word2vec, have become a mainstay of NLP engineering pipelines. Recently, with the release of BERT, word embeddings have moved from the term-based embedding space to the contextual embedding space -- each term is no longer represented by a single low-dimensional vector but instead each term and \emph{its context} determine the vector weights. BERT's setup and architecture have been shown to be general enough to be applicable to many natural language tasks. Importantly for Information Retrieval (IR), in contrast to prior deep learning solutions to IR problems which required significant tuning of neural net architectures and training regimes, "vanilla BERT" has been shown to outperform existing retrieval algorithms by a wide margin, including on tasks and corpora that have long resisted retrieval effectiveness gains over traditional IR baselines (such as Robust04). In this paper, we employ the recently proposed axiomatic dataset analysis technique -- that is, we create diagnostic datasets that each fulfil a retrieval heuristic (both term matching and semantic-based) -- to explore what BERT is able to learn. In contrast to our expectations, we find BERT, when applied to a recently released large-scale web corpus with ad-hoc topics, to \emph{not} adhere to any of the explored axioms. At the same time, BERT outperforms the traditional query likelihood retrieval model by 40\%. This means that the axiomatic approach to IR (and its extension of diagnostic datasets created for retrieval heuristics) may in its current form not be applicable to large-scale corpora. Additional -- different -- axioms are needed.
* Published at ECIR 2020
Conditional Generative Data-Free Knowledge Distillation based on Attention Transfer
Dec 31, 2021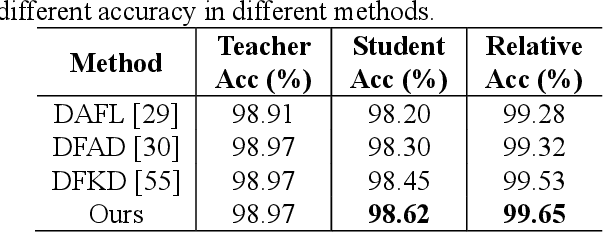

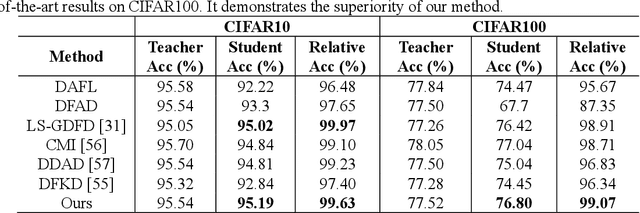
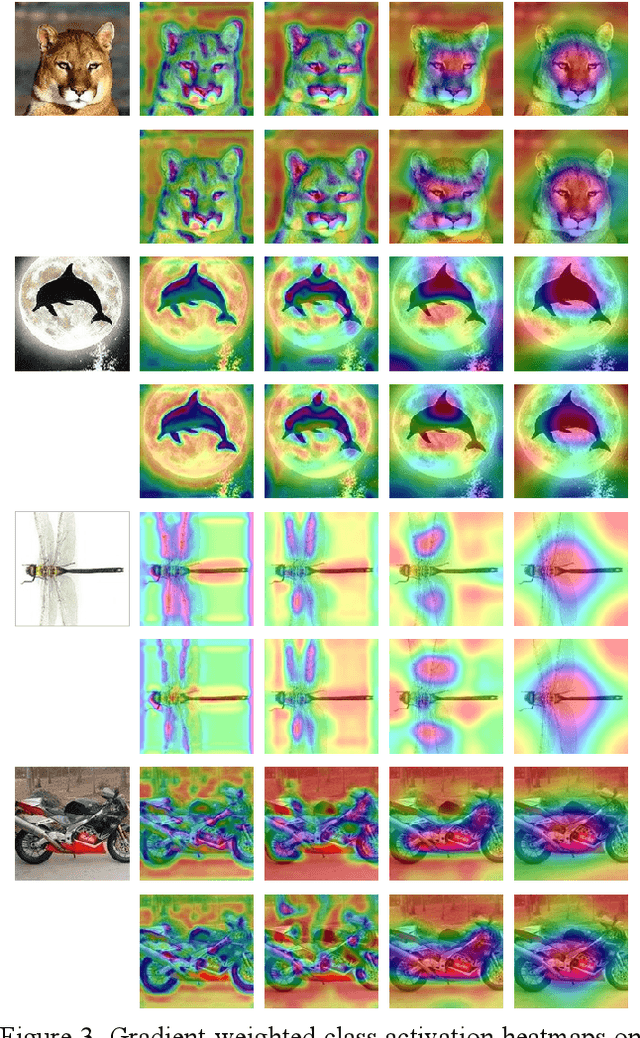
Knowledge distillation has made remarkable achievements in model compression. However, most existing methods demand original training data, while real data in practice are often unavailable due to privacy, security and transmission limitation. To address this problem, we propose a conditional generative data-free knowledge distillation (CGDD) framework to train efficient portable network without any real data. In this framework, except using the knowledge extracted from teacher model, we introduce preset labels as additional auxiliary information to train the generator. Then, the trained generator can produce meaningful training samples of specified category as required. In order to promote distillation process, except using conventional distillation loss, we treat preset label as ground truth label so that student network is directly supervised by the category of synthetic training sample. Moreover, we force student network to mimic the attention maps of teacher model and further improve its performance. To verify the superiority of our method, we design a new evaluation metric is called as relative accuracy to directly compare the effectiveness of different distillation methods. Trained portable network learned with proposed data-free distillation method obtains 99.63%, 99.07% and 99.84% relative accuracy on CIFAR10, CIFAR100 and Caltech101, respectively. The experimental results demonstrate the superiority of proposed method.
Improving Pneumonia Localization via Cross-Attention on Medical Images and Reports
Oct 06, 2021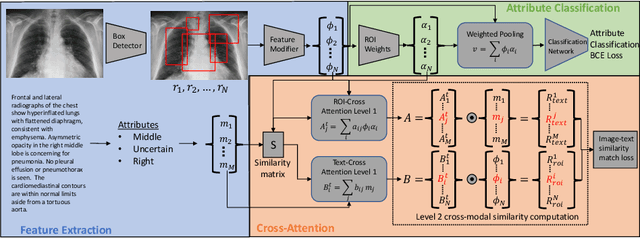
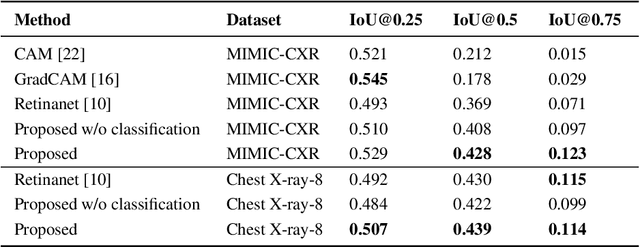
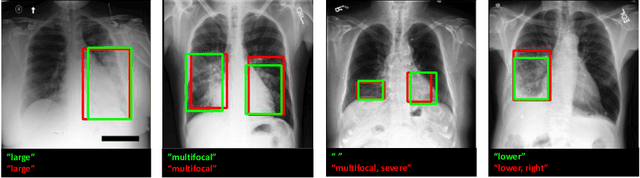

Localization and characterization of diseases like pneumonia are primary steps in a clinical pipeline, facilitating detailed clinical diagnosis and subsequent treatment planning. Additionally, such location annotated datasets can provide a pathway for deep learning models to be used for downstream tasks. However, acquiring quality annotations is expensive on human resources and usually requires domain expertise. On the other hand, medical reports contain a plethora of information both about pneumonia characteristics and its location. In this paper, we propose a novel weakly-supervised attention-driven deep learning model that leverages encoded information in medical reports during training to facilitate better localization. Our model also performs classification of attributes that are associated to pneumonia and extracted from medical reports for supervision. Both the classification and localization are trained in conjunction and once trained, the model can be utilized for both the localization and characterization of pneumonia using only the input image. In this paper, we explore and analyze the model using chest X-ray datasets and demonstrate qualitatively and quantitatively that the introduction of textual information improves pneumonia localization. We showcase quantitative results on two datasets, MIMIC-CXR and Chest X-ray-8, and we also showcase severity characterization on the COVID-19 dataset.
Design Challenges for a Multi-Perspective Search Engine
Dec 15, 2021
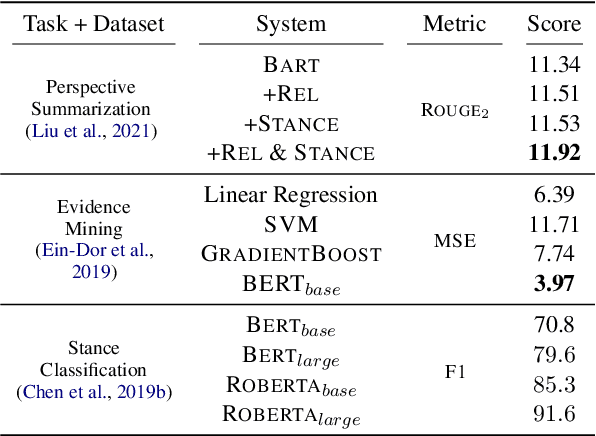

Many users turn to document retrieval systems (e.g. search engines) to seek answers to controversial questions. Answering such user queries usually require identifying responses within web documents, and aggregating the responses based on their different perspectives. Classical document retrieval systems fall short at delivering a set of direct and diverse responses to the users. Naturally, identifying such responses within a document is a natural language understanding task. In this paper, we examine the challenges of synthesizing such language understanding objectives with document retrieval, and study a new perspective-oriented document retrieval paradigm. We discuss and assess the inherent natural language understanding challenges in order to achieve the goal. Following the design challenges and principles, we demonstrate and evaluate a practical prototype pipeline system. We use the prototype system to conduct a user survey in order to assess the utility of our paradigm, as well as understanding the user information needs for controversial queries.
Bayesian Optimization of Function Networks
Dec 31, 2021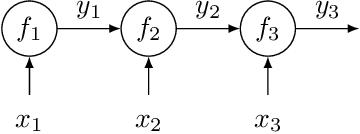
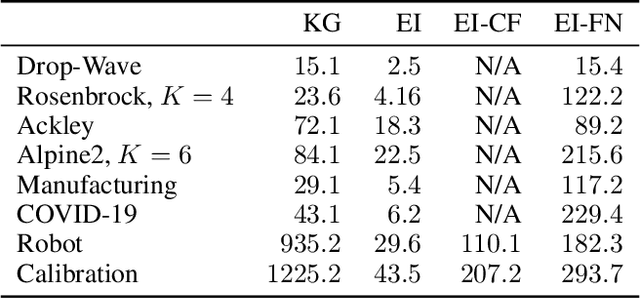
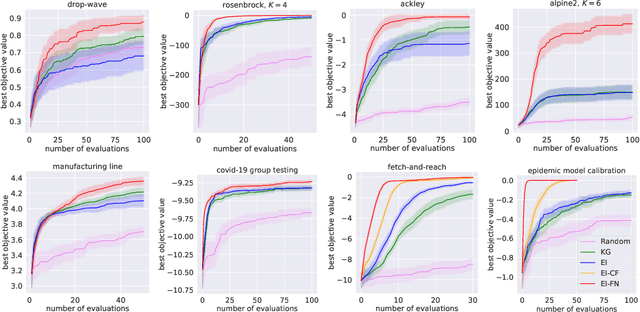
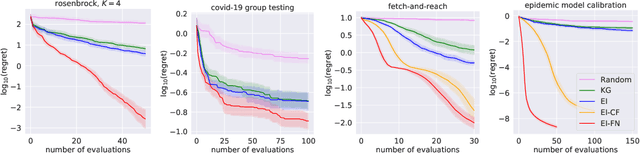
We consider Bayesian optimization of the output of a network of functions, where each function takes as input the output of its parent nodes, and where the network takes significant time to evaluate. Such problems arise, for example, in reinforcement learning, engineering design, and manufacturing. While the standard Bayesian optimization approach observes only the final output, our approach delivers greater query efficiency by leveraging information that the former ignores: intermediate output within the network. This is achieved by modeling the nodes of the network using Gaussian processes and choosing the points to evaluate using, as our acquisition function, the expected improvement computed with respect to the implied posterior on the objective. Although the non-Gaussian nature of this posterior prevents computing our acquisition function in closed form, we show that it can be efficiently maximized via sample average approximation. In addition, we prove that our method is asymptotically consistent, meaning that it finds a globally optimal solution as the number of evaluations grows to infinity, thus generalizing previously known convergence results for the expected improvement. Notably, this holds even though our method might not evaluate the domain densely, instead leveraging problem structure to leave regions unexplored. Finally, we show that our approach dramatically outperforms standard Bayesian optimization methods in several synthetic and real-world problems.
Long-range medical image registration through generalized mutual information (GMI): toward a fully automatic volumetric alignment
Nov 30, 2020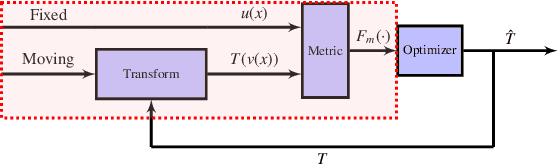
Image registration is a key operation in medical image processing, allowing a plethora of applications. Mutual information (MI) is consolidated as a robust similarity metric often used for medical image registration. Although MI provides a robust medical image registration, it usually fails when the needed image transform is too big due to MI local maxima traps. In this paper, we propose and evaluate a generalized parametric MI as an affine registration cost function. We assessed the generalized MI (GMI) functions for separable affine transforms and exhaustively evaluated the GMI mathematical image seeking the maximum registration range through a gradient descent simulation. We also employed Monte Carlo simulation essays for testing translation registering of randomized T1 versus T2 images. GMI functions showed to have smooth isosurfaces driving the algorithm to the global maxima. Results show significantly prolonged registration ranges, avoiding the traps of local maxima. We evaluated a range of [-150mm,150mm] for translations, [-180{\deg},180{\deg}] for rotations, [0.5,2] for scales, and [-1,1] for skew with a success rate of 99.99%, 97.58%, 99.99%, and 99.99% respectively for the transforms in the simulated gradient descent. We also obtained 99.75% success in Monte Carlo simulation from 2,000 randomized translations trials with 1,113 subjects T1 and T2 MRI images. The findings point towards the reliability of GMI for long-range registration with enhanced speed performance