 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Traffic Event Detection as a Slot Filling Problem
Sep 13, 2021
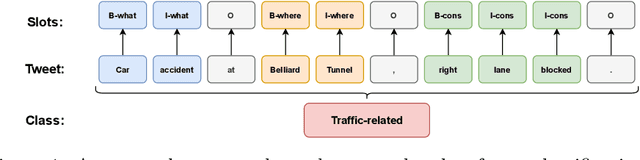
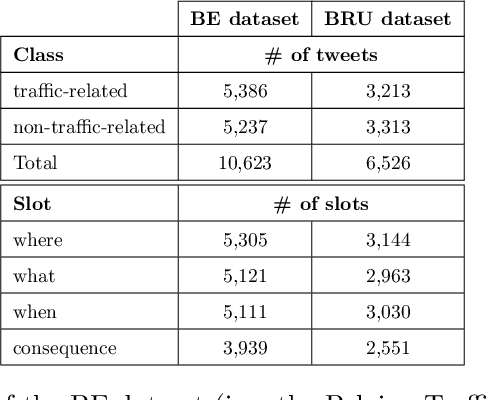
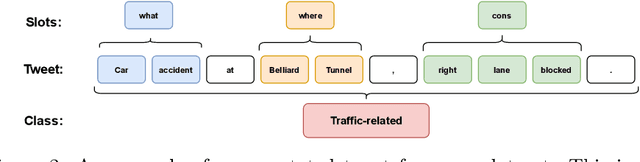
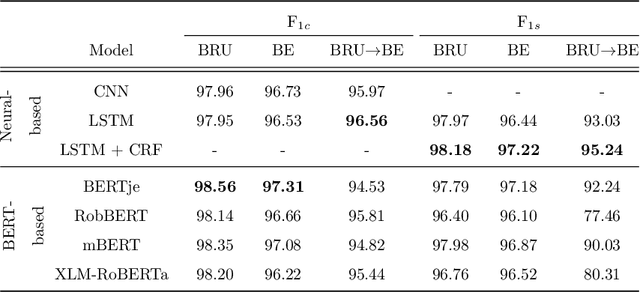
In this paper, we introduce the new problem of extracting fine-grained traffic information from Twitter streams by also making publicly available the two (constructed) traffic-related datasets from Belgium and the Brussels capital region. In particular, we experiment with several models to identify (i) whether a tweet is traffic-related or not, and (ii) in the case that the tweet is traffic-related to identify more fine-grained information regarding the event (e.g., the type of the event, where the event happened). To do so, we frame (i) the problem of identifying whether a tweet is a traffic-related event or not as a text classification subtask, and (ii) the problem of identifying more fine-grained traffic-related information as a slot filling subtask, where fine-grained information (e.g., where an event has happened) is represented as a slot/entity of a particular type. We propose the use of several methods that process the two subtasks either separately or in a joint setting, and we evaluate the effectiveness of the proposed methods for solving the traffic event detection problem. Experimental results indicate that the proposed architectures achieve high performance scores (i.e., more than 95% in terms of F$_{1}$ score) on the constructed datasets for both of the subtasks (i.e., text classification and slot filling) even in a transfer learning scenario. In addition, by incorporating tweet-level information in each of the tokens comprising the tweet (for the BERT-based model) can lead to a performance improvement for the joint setting.
A Geometric Perspective towards Neural Calibration via Sensitivity Decomposition
Oct 28, 2021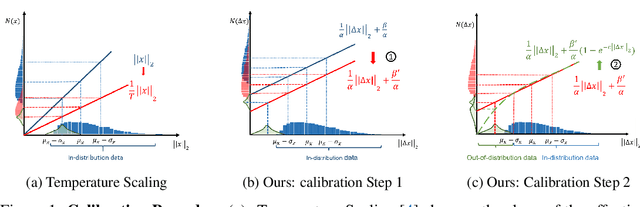
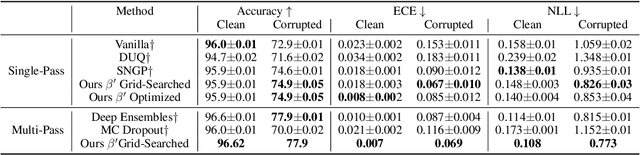
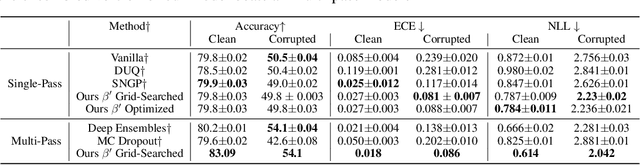
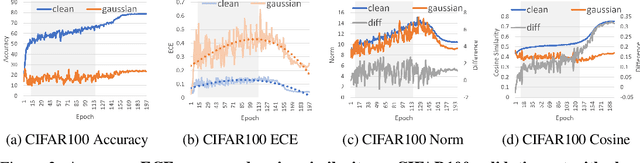
It is well known that vision classification models suffer from poor calibration in the face of data distribution shifts. In this paper, we take a geometric approach to this problem. We propose Geometric Sensitivity Decomposition (GSD) which decomposes the norm of a sample feature embedding and the angular similarity to a target classifier into an instance-dependent and an instance-independent component. The instance-dependent component captures the sensitive information about changes in the input while the instance-independent component represents the insensitive information serving solely to minimize the loss on the training dataset. Inspired by the decomposition, we analytically derive a simple extension to current softmax-linear models, which learns to disentangle the two components during training. On several common vision models, the disentangled model outperforms other calibration methods on standard calibration metrics in the face of out-of-distribution (OOD) data and corruption with significantly less complexity. Specifically, we surpass the current state of the art by 30.8% relative improvement on corrupted CIFAR100 in Expected Calibration Error. Code available at https://github.com/GT-RIPL/Geometric-Sensitivity-Decomposition.git.
Sign Language Recognition System using TensorFlow Object Detection API
Jan 05, 2022
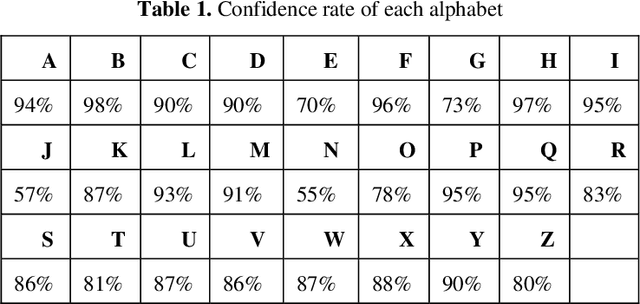


Communication is defined as the act of sharing or exchanging information, ideas or feelings. To establish communication between two people, both of them are required to have knowledge and understanding of a common language. But in the case of deaf and dumb people, the means of communication are different. Deaf is the inability to hear and dumb is the inability to speak. They communicate using sign language among themselves and with normal people but normal people do not take seriously the importance of sign language. Not everyone possesses the knowledge and understanding of sign language which makes communication difficult between a normal person and a deaf and dumb person. To overcome this barrier, one can build a model based on machine learning. A model can be trained to recognize different gestures of sign language and translate them into English. This will help a lot of people in communicating and conversing with deaf and dumb people. The existing Indian Sing Language Recognition systems are designed using machine learning algorithms with single and double-handed gestures but they are not real-time. In this paper, we propose a method to create an Indian Sign Language dataset using a webcam and then using transfer learning, train a TensorFlow model to create a real-time Sign Language Recognition system. The system achieves a good level of accuracy even with a limited size dataset.
Nearly Optimal Policy Optimization with Stable at Any Time Guarantee
Dec 22, 2021
Policy optimization methods are one of the most widely used classes of Reinforcement Learning (RL) algorithms. However, theoretical understanding of these methods remains insufficient. Even in the episodic (time-inhomogeneous) tabular setting, the state-of-the-art theoretical result of policy-based method in \citet{shani2020optimistic} is only $\tilde{O}(\sqrt{S^2AH^4K})$ where $S$ is the number of states, $A$ is the number of actions, $H$ is the horizon, and $K$ is the number of episodes, and there is a $\sqrt{SH}$ gap compared with the information theoretic lower bound $\tilde{\Omega}(\sqrt{SAH^3K})$. To bridge such a gap, we propose a novel algorithm Reference-based Policy Optimization with Stable at Any Time guarantee (\algnameacro), which features the property "Stable at Any Time". We prove that our algorithm achieves $\tilde{O}(\sqrt{SAH^3K} + \sqrt{AH^4K})$ regret. When $S > H$, our algorithm is minimax optimal when ignoring logarithmic factors. To our best knowledge, RPO-SAT is the first computationally efficient, nearly minimax optimal policy-based algorithm for tabular RL.
Gradient-based Bit Encoding Optimization for Noise-Robust Binary Memristive Crossbar
Jan 05, 2022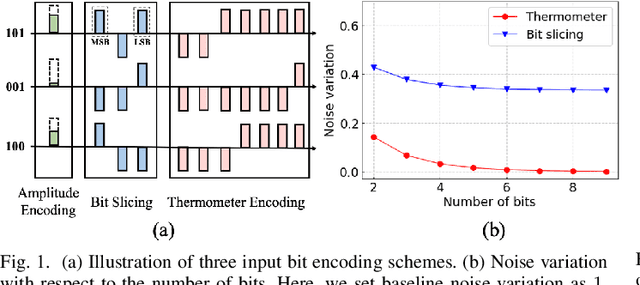
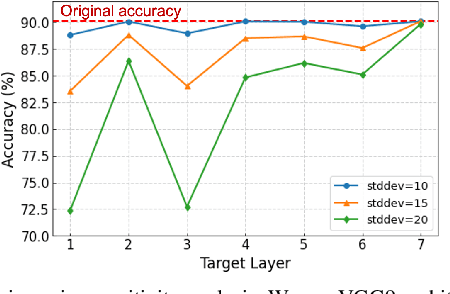
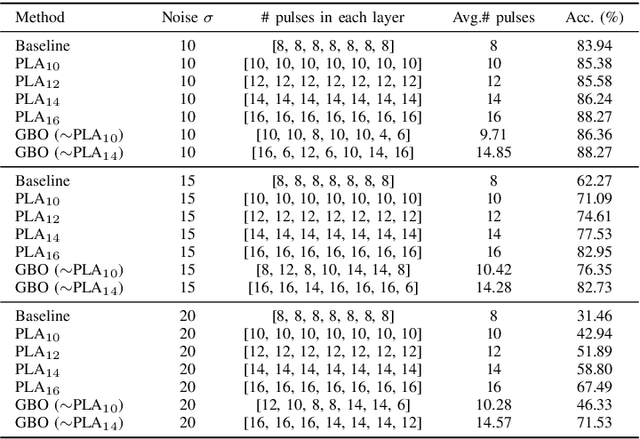
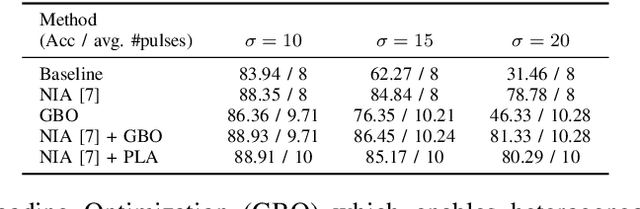
Binary memristive crossbars have gained huge attention as an energy-efficient deep learning hardware accelerator. Nonetheless, they suffer from various noises due to the analog nature of the crossbars. To overcome such limitations, most previous works train weight parameters with noise data obtained from a crossbar. These methods are, however, ineffective because it is difficult to collect noise data in large-volume manufacturing environment where each crossbar has a large device/circuit level variation. Moreover, we argue that there is still room for improvement even though these methods somewhat improve accuracy. This paper explores a new perspective on mitigating crossbar noise in a more generalized way by manipulating input binary bit encoding rather than training the weight of networks with respect to noise data. We first mathematically show that the noise decreases as the number of binary bit encoding pulses increases when representing the same amount of information. In addition, we propose Gradient-based Bit Encoding Optimization (GBO) which optimizes a different number of pulses at each layer, based on our in-depth analysis that each layer has a different level of noise sensitivity. The proposed heterogeneous layer-wise bit encoding scheme achieves high noise robustness with low computational cost. Our experimental results on public benchmark datasets show that GBO improves the classification accuracy by ~5-40% in severe noise scenarios.
BLINC: Lightweight Bimodal Learning for Low-Complexity VVC Intra Coding
Jan 19, 2022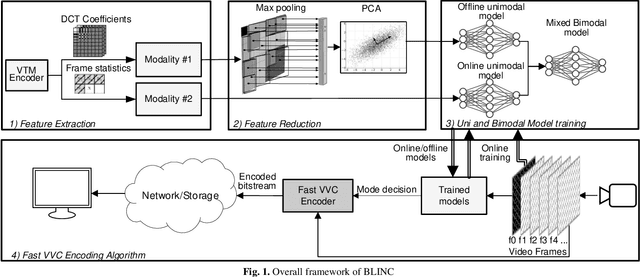

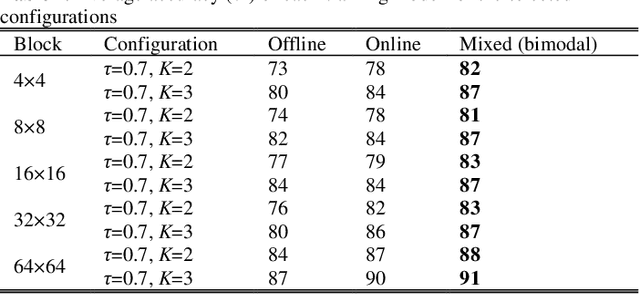
The latest video coding standard, Versatile Video Coding (VVC), achieves almost twice coding efficiency compared to its predecessor, the High Efficiency Video Coding (HEVC). However, achieving this efficiency (for intra coding) requires 31x computational complexity compared to HEVC, making it challenging for low power and real-time applications. This paper, proposes a novel machine learning approach that jointly and separately employs two modalities of features, to simplify the intra coding decision. First a set of features are extracted that use the existing DCT core of VVC, to assess the texture characteristics, and forms the first modality of data. This produces high quality features with almost no overhead. The distribution of intra modes at the neighboring blocks is also used to form the second modality of data, which provides statistical information about the frame. Second, a two-step feature reduction method is designed that reduces the size of feature set, such that a lightweight model with a limited number of parameters can be used to learn the intra mode decision task. Third, three separate training strategies are proposed (1) an offline training strategy using the first (single) modality of data, (2) an online training strategy that uses the second (single) modality, and (3) a mixed online-offline strategy that uses bimodal learning. Finally, a low-complexity encoding algorithms is proposed based on the proposed learning strategies. Extensive experimental results show that the proposed methods can reduce up to 24% of encoding time, with a negligible loss of coding efficiency. Moreover, it is demonstrated how a bimodal learning strategy can boost the performance of learning. Lastly, the proposed method has a very low computational overhead (0.2%), and uses existing components of a VVC encoder, which makes it much more practical compared to competing solutions.
Evaluating Deep Music Generation Methods Using Data Augmentation
Dec 31, 2021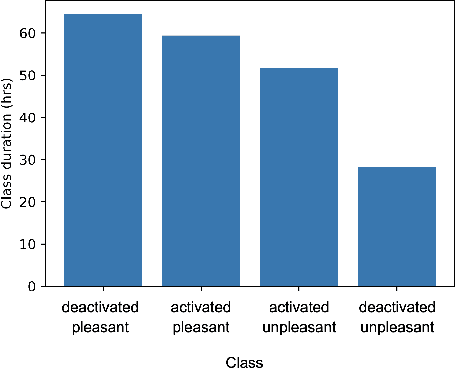
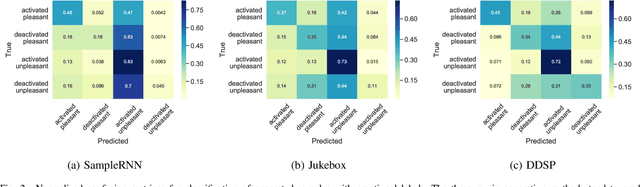
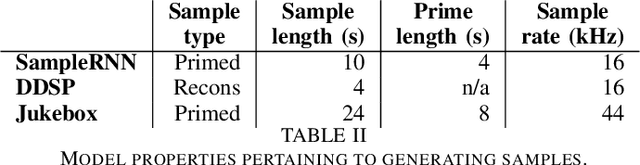
Despite advances in deep algorithmic music generation, evaluation of generated samples often relies on human evaluation, which is subjective and costly. We focus on designing a homogeneous, objective framework for evaluating samples of algorithmically generated music. Any engineered measures to evaluate generated music typically attempt to define the samples' musicality, but do not capture qualities of music such as theme or mood. We do not seek to assess the musical merit of generated music, but instead explore whether generated samples contain meaningful information pertaining to emotion or mood/theme. We achieve this by measuring the change in predictive performance of a music mood/theme classifier after augmenting its training data with generated samples. We analyse music samples generated by three models -- SampleRNN, Jukebox, and DDSP -- and employ a homogeneous framework across all methods to allow for objective comparison. This is the first attempt at augmenting a music genre classification dataset with conditionally generated music. We investigate the classification performance improvement using deep music generation and the ability of the generators to make emotional music by using an additional, emotion annotation of the dataset. Finally, we use a classifier trained on real data to evaluate the label validity of class-conditionally generated samples.
Producing augmentation-invariant embeddings from real-life imagery
Dec 06, 2021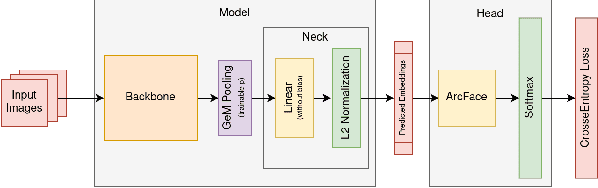
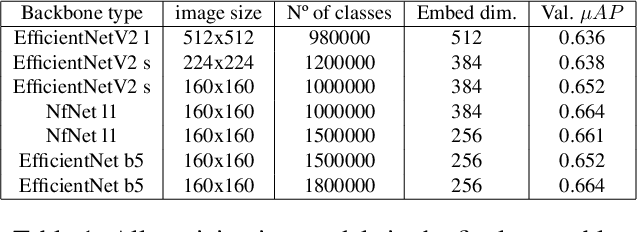


This article presents an efficient way to produce feature-rich, high-dimensionality embedding spaces from real-life images. The features produced are designed to be independent from augmentations used in real-life cases which appear on social media. Our approach uses convolutional neural networks (CNN) to produce an embedding space. An ArcFace head was used to train the model by employing automatically produced augmentations. Additionally, we present a way to make an ensemble out of different embeddings containing the same semantic information, a way to normalize the resulting embedding using an external dataset, and a novel way to perform quick training of these models with a high number of classes in the ArcFace head. Using this approach we achieved the 2nd place in the 2021 Facebook AI Image Similarity Challenge: Descriptor Track.
Skeleton-Based Mutually Assisted Interacted Object Localization and Human Action Recognition
Oct 28, 2021
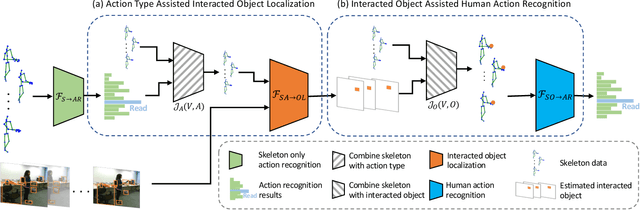

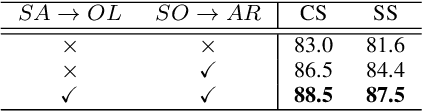
Skeleton data carries valuable motion information and is widely explored in human action recognition. However, not only the motion information but also the interaction with the environment provides discriminative cues to recognize the action of persons. In this paper, we propose a joint learning framework for mutually assisted "interacted object localization" and "human action recognition" based on skeleton data. The two tasks are serialized together and collaborate to promote each other, where preliminary action type derived from skeleton alone helps improve interacted object localization, which in turn provides valuable cues for the final human action recognition. Besides, we explore the temporal consistency of interacted object as constraint to better localize the interacted object with the absence of ground-truth labels. Extensive experiments on the datasets of SYSU-3D, NTU60 RGB+D and Northwestern-UCLA show that our method achieves the best or competitive performance with the state-of-the-art methods for human action recognition. Visualization results show that our method can also provide reasonable interacted object localization results.
Reframing Human-AI Collaboration for Generating Free-Text Explanations
Dec 16, 2021
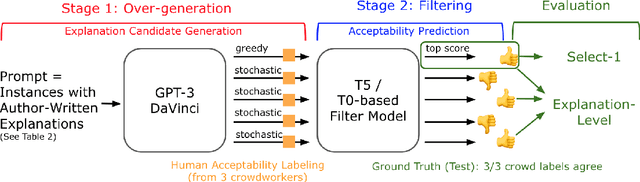

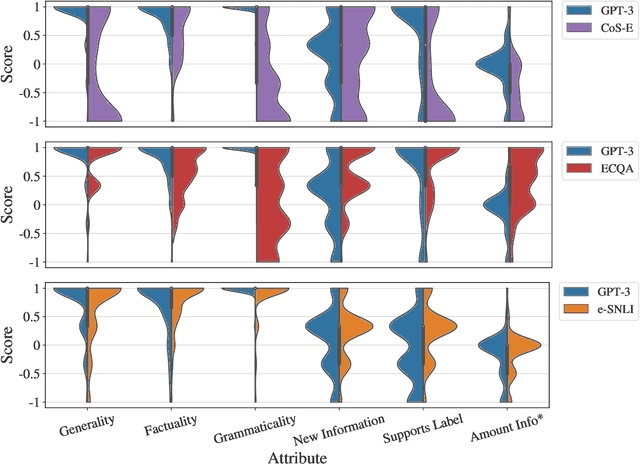
Large language models are increasingly capable of generating fluent-appearing text with relatively little task-specific supervision. But can these models accurately explain classification decisions? We consider the task of generating free-text explanations using a small number of human-written examples (i.e., in a few-shot manner). We find that (1) authoring higher-quality examples for prompting results in higher quality generations; and (2) surprisingly, in a head-to-head comparison, crowdworkers often prefer explanations generated by GPT-3 to crowdsourced human-written explanations contained within existing datasets. Crowdworker ratings also show, however, that while models produce factual, grammatical, and sufficient explanations, they have room to improve, e.g., along axes such as providing novel information and supporting the label. We create a pipeline that combines GPT-3 with a supervised filter that incorporates humans-in-the-loop via binary acceptability judgments. Despite significant subjectivity intrinsic to judging acceptability, our approach is able to consistently filter GPT-3 generated explanations deemed acceptable by humans.