 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Per-link Parallel and Distributed Hybrid Beamforming for Multi-Cell Massive MIMO Millimeter Wave Full Duplex
Jan 09, 2022
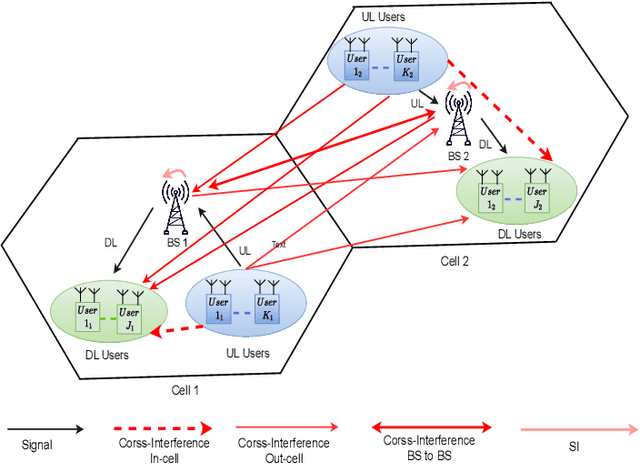
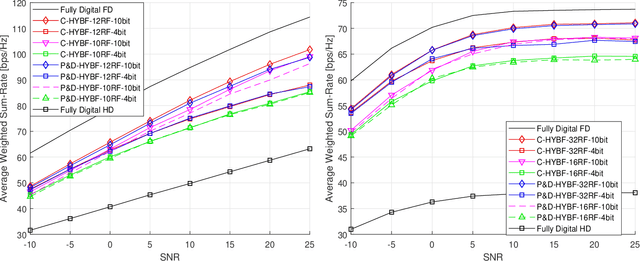
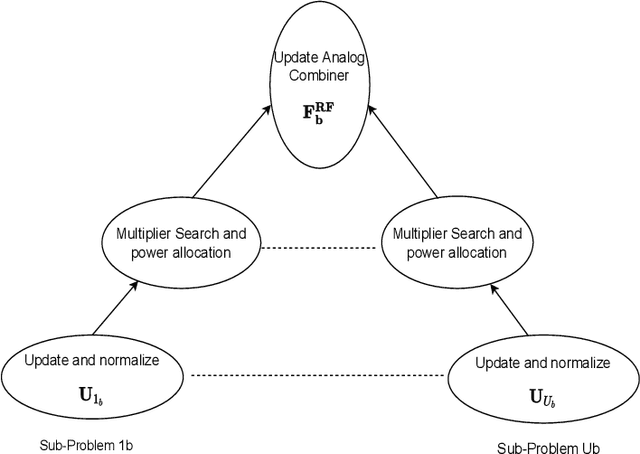
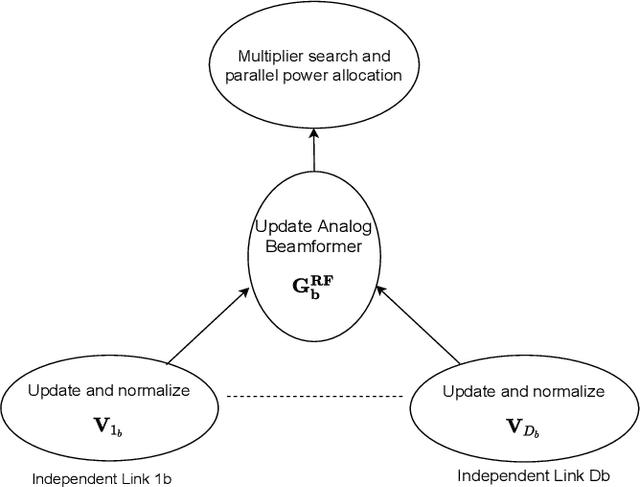
This paper presents two novel hybrid beamforming (HYBF) designs for a multi-cell massive multiple-input-multiple-output (mMIMO) millimeter wave (mmWave) full duplex (FD) system under limited dynamic range (LDR). Firstly, we present a novel centralized HYBF (C-HYBF) scheme based on alternating optimization. In general, the complexity of C-HYBF schemes scales quadratically as a function of the number of users and cells, which may limit their scalability. Moreover, they require significant communication overhead to transfer complete channel state information (CSI) to the central node every channel coherence time for optimization. The central node also requires very high computational power to jointly optimize many variables for the uplink (UL) and downlink (DL) users in FD systems. To overcome these drawbacks, we propose a very low-complexity and scalable cooperative per-link parallel and distributed (P$\&$D)-HYBF scheme. It allows each mmWave FD base station (BS) to update the beamformers for its users in a distributed fashion and independently in parallel on different computational processors. The complexity of P$\&$D-HYBF scales only linearly as the network size grows, making it desirable for the next generation of large and dense mmWave FD networks. Simulation results show that both designs significantly outperform the fully digital half duplex (HD) system with only a few radio-frequency (RF) chains, achieve similar performance, and the P$\&$D-HYBF design requires considerably less execution time.
Traffic Event Detection as a Slot Filling Problem
Sep 13, 2021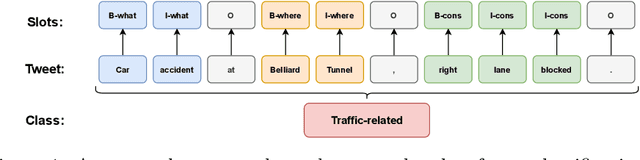
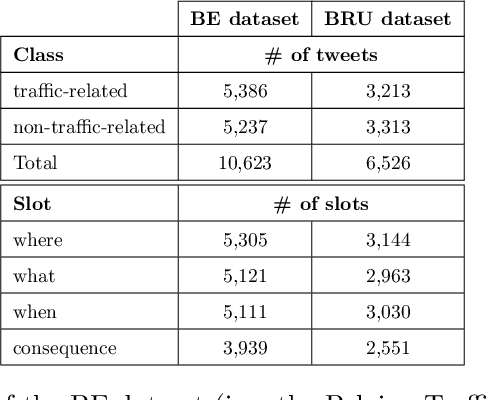
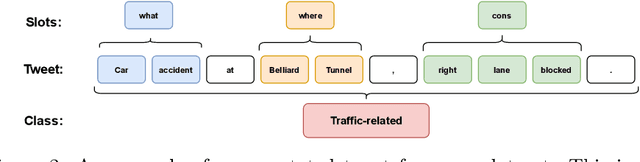
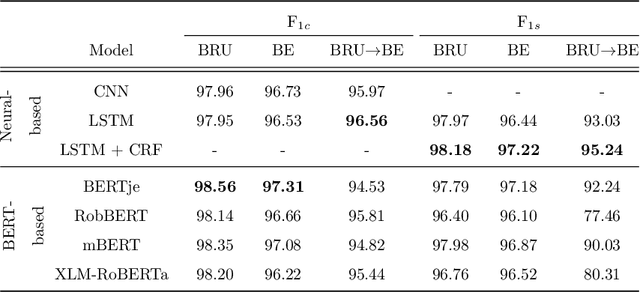
In this paper, we introduce the new problem of extracting fine-grained traffic information from Twitter streams by also making publicly available the two (constructed) traffic-related datasets from Belgium and the Brussels capital region. In particular, we experiment with several models to identify (i) whether a tweet is traffic-related or not, and (ii) in the case that the tweet is traffic-related to identify more fine-grained information regarding the event (e.g., the type of the event, where the event happened). To do so, we frame (i) the problem of identifying whether a tweet is a traffic-related event or not as a text classification subtask, and (ii) the problem of identifying more fine-grained traffic-related information as a slot filling subtask, where fine-grained information (e.g., where an event has happened) is represented as a slot/entity of a particular type. We propose the use of several methods that process the two subtasks either separately or in a joint setting, and we evaluate the effectiveness of the proposed methods for solving the traffic event detection problem. Experimental results indicate that the proposed architectures achieve high performance scores (i.e., more than 95% in terms of F$_{1}$ score) on the constructed datasets for both of the subtasks (i.e., text classification and slot filling) even in a transfer learning scenario. In addition, by incorporating tweet-level information in each of the tokens comprising the tweet (for the BERT-based model) can lead to a performance improvement for the joint setting.
Paradigms of Computational Agency
Dec 10, 2021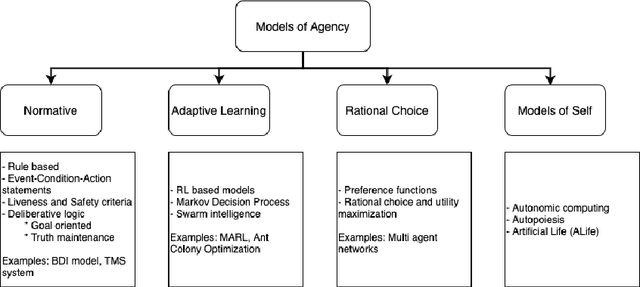
Agent-based models have emerged as a promising paradigm for addressing ever increasing complexity of information systems. In its initial days in the 1990s when object-oriented modeling was at its peak, an agent was treated as a special kind of "object" that had a persistent state and its own independent thread of execution. Since then, agent-based models have diversified enormously to even open new conceptual insights about the nature of systems in general. This paper presents a perspective on the disparate ways in which our understanding of agency, as well as computational models of agency have evolved. Advances in hardware like GPUs, that brought neural networks back to life, may also similarly infuse new life into agent-based models, as well as pave the way for advancements in research on Artificial General Intelligence (AGI).
* Earlier version of this paper was published as a book chapter in the book titled Novel Approaches to Information Systems Design
3D Siamese Voxel-to-BEV Tracker for Sparse Point Clouds
Nov 17, 2021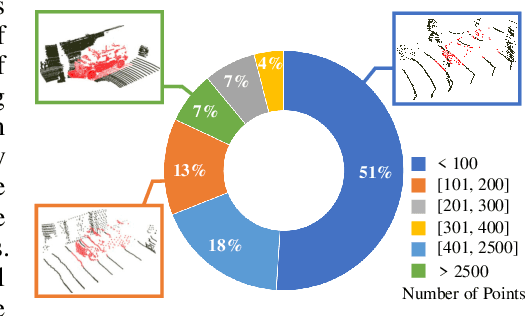
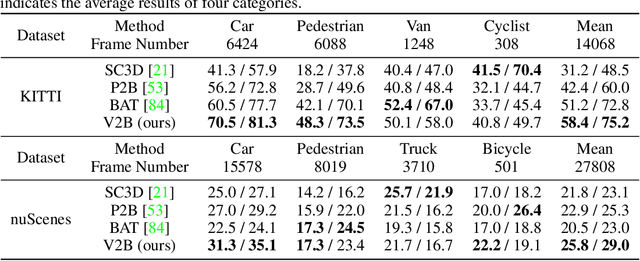
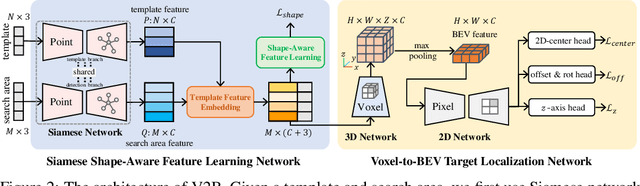
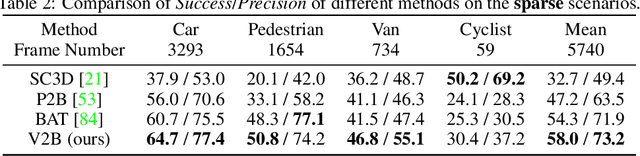
3D object tracking in point clouds is still a challenging problem due to the sparsity of LiDAR points in dynamic environments. In this work, we propose a Siamese voxel-to-BEV tracker, which can significantly improve the tracking performance in sparse 3D point clouds. Specifically, it consists of a Siamese shape-aware feature learning network and a voxel-to-BEV target localization network. The Siamese shape-aware feature learning network can capture 3D shape information of the object to learn the discriminative features of the object so that the potential target from the background in sparse point clouds can be identified. To this end, we first perform template feature embedding to embed the template's feature into the potential target and then generate a dense 3D shape to characterize the shape information of the potential target. For localizing the tracked target, the voxel-to-BEV target localization network regresses the target's 2D center and the $z$-axis center from the dense bird's eye view (BEV) feature map in an anchor-free manner. Concretely, we compress the voxelized point cloud along $z$-axis through max pooling to obtain a dense BEV feature map, where the regression of the 2D center and the $z$-axis center can be performed more effectively. Extensive evaluation on the KITTI and nuScenes datasets shows that our method significantly outperforms the current state-of-the-art methods by a large margin.
MinkLoc3D-SI: 3D LiDAR place recognition with sparse convolutions, spherical coordinates, and intensity
Dec 27, 2021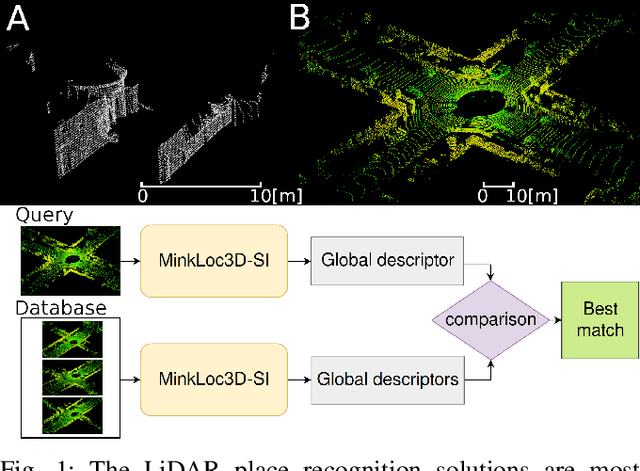
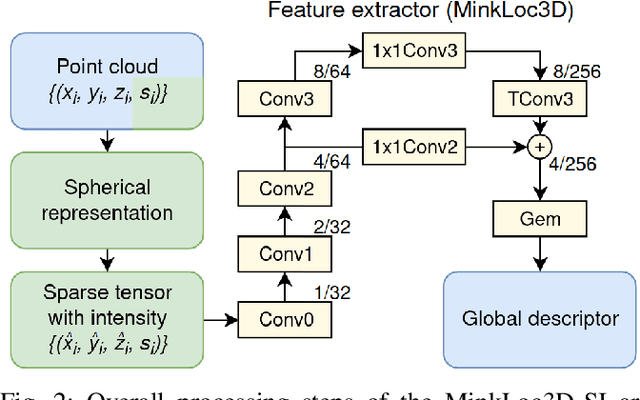
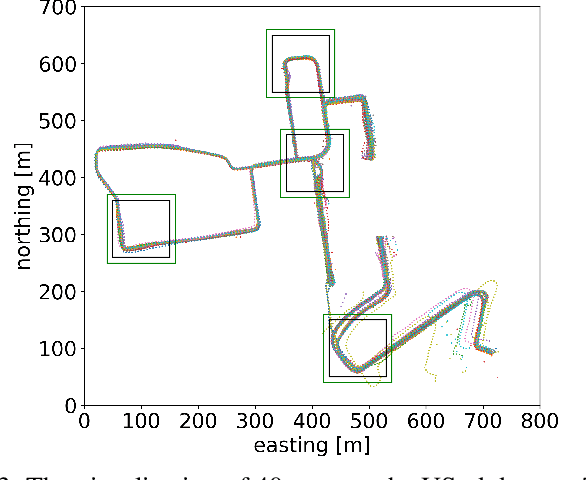
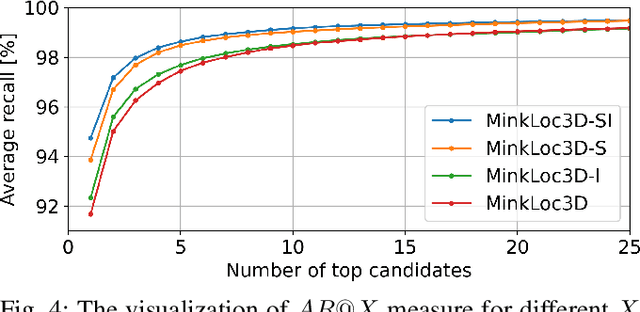
The 3D LiDAR place recognition aims to estimate a coarse localization in a previously seen environment based on a single scan from a rotating 3D LiDAR sensor. The existing solutions to this problem include hand-crafted point cloud descriptors (e.g., ScanContext, M2DP, LiDAR IRIS) and deep learning-based solutions (e.g., PointNetVLAD, PCAN, LPDNet, DAGC, MinkLoc3D), which are often only evaluated on accumulated 2D scans from the Oxford RobotCar dataset. We introduce MinkLoc3D-SI, a sparse convolution-based solution that utilizes spherical coordinates of 3D points and processes the intensity of 3D LiDAR measurements, improving the performance when a single 3D LiDAR scan is used. Our method integrates the improvements typical for hand-crafted descriptors (like ScanContext) with the most efficient 3D sparse convolutions (MinkLoc3D). Our experiments show improved results on single scans from 3D LiDARs (USyd Campus dataset) and great generalization ability (KITTI dataset). Using intensity information on accumulated 2D scans (RobotCar Intensity dataset) improves the performance, even though spherical representation doesn't produce a noticeable improvement. As a result, MinkLoc3D-SI is suited for single scans obtained from a 3D LiDAR, making it applicable in autonomous vehicles.
InfoLM: A New Metric to Evaluate Summarization & Data2Text Generation
Dec 13, 2021
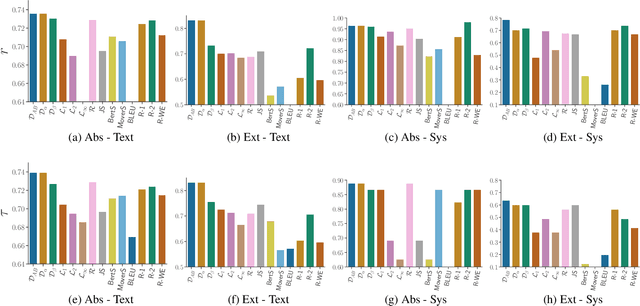
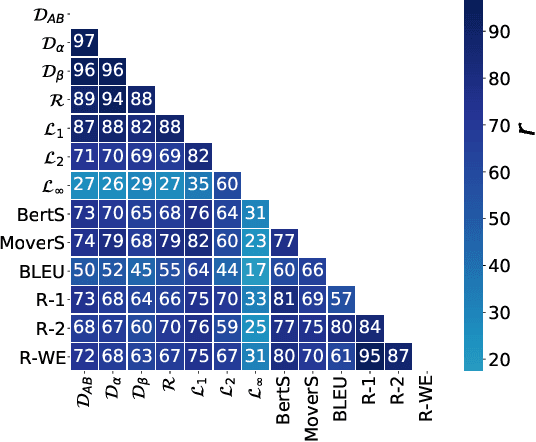
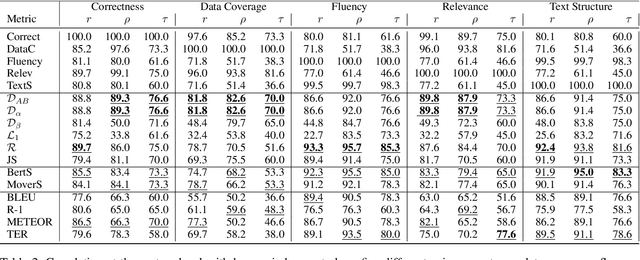
Assessing the quality of natural language generation systems through human annotation is very expensive. Additionally, human annotation campaigns are time-consuming and include non-reusable human labour. In practice, researchers rely on automatic metrics as a proxy of quality. In the last decade, many string-based metrics (e.g., BLEU) have been introduced. However, such metrics usually rely on exact matches and thus, do not robustly handle synonyms. In this paper, we introduce InfoLM a family of untrained metrics that can be viewed as a string-based metric that addresses the aforementioned flaws thanks to a pre-trained masked language model. This family of metrics also makes use of information measures allowing the adaptation of InfoLM to various evaluation criteria. Using direct assessment, we demonstrate that InfoLM achieves statistically significant improvement and over $10$ points of correlation gains in many configurations on both summarization and data2text generation.
Long-tail Recognition via Compositional Knowledge Transfer
Dec 13, 2021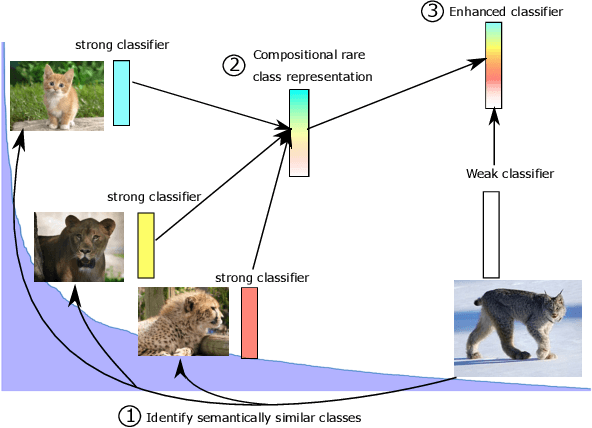
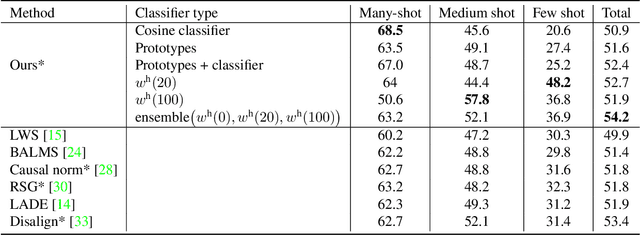
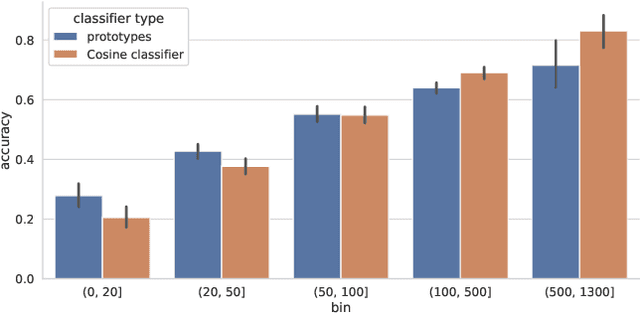
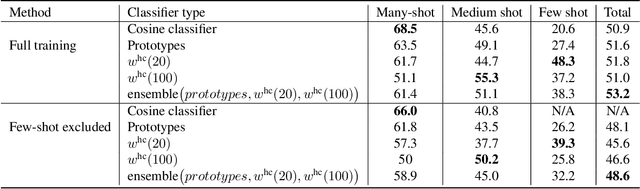
In this work, we introduce a novel strategy for long-tail recognition that addresses the tail classes' few-shot problem via training-free knowledge transfer. Our objective is to transfer knowledge acquired from information-rich common classes to semantically similar, and yet data-hungry, rare classes in order to obtain stronger tail class representations. We leverage the fact that class prototypes and learned cosine classifiers provide two different, complementary representations of class cluster centres in feature space, and use an attention mechanism to select and recompose learned classifier features from common classes to obtain higher quality rare class representations. Our knowledge transfer process is training free, reducing overfitting risks, and can afford continual extension of classifiers to new classes. Experiments show that our approach can achieve significant performance boosts on rare classes while maintaining robust common class performance, outperforming directly comparable state-of-the-art models.
Ghost-dil-NetVLAD: A Lightweight Neural Network for Visual Place Recognition
Dec 22, 2021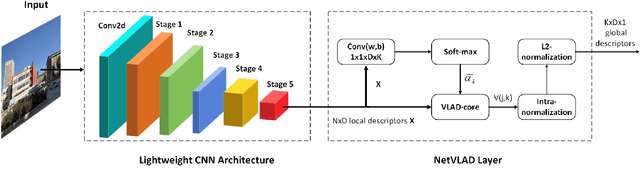
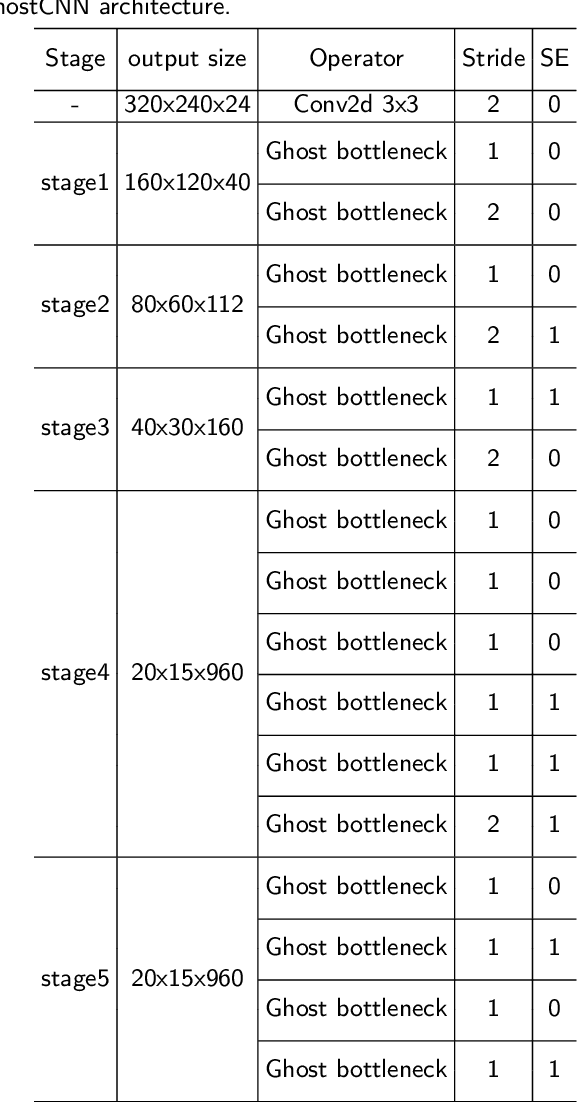
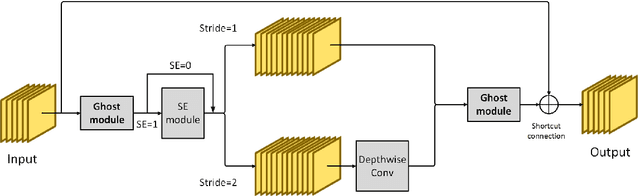
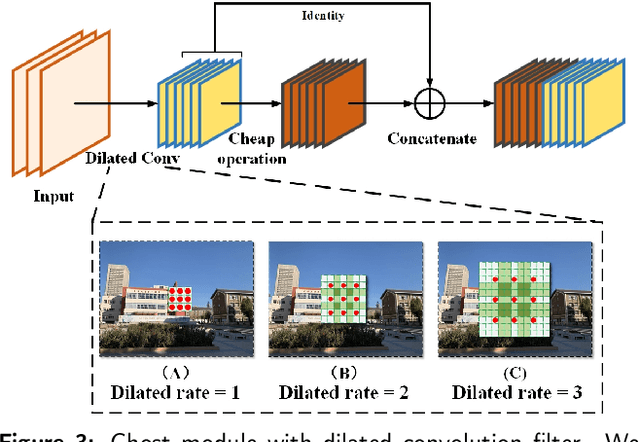
Visual place recognition (VPR) is a challenging task with the unbalance between enormous computational cost and high recognition performance. Thanks to the practical feature extraction ability of the lightweight convolution neural networks (CNNs) and the train-ability of the vector of locally aggregated descriptors (VLAD) layer, we propose a lightweight weakly supervised end-to-end neural network consisting of a front-ended perception model called GhostCNN and a learnable VLAD layer as a back-end. GhostCNN is based on Ghost modules that are lightweight CNN-based architectures. They can generate redundant feature maps using linear operations instead of the traditional convolution process, making a good trade-off between computation resources and recognition accuracy. To enhance our proposed lightweight model further, we add dilated convolutions to the Ghost module to get features containing more spatial semantic information, improving accuracy. Finally, rich experiments conducted on a commonly used public benchmark and our private dataset validate that the proposed neural network reduces the FLOPs and parameters of VGG16-NetVLAD by 99.04% and 80.16%, respectively. Besides, both models achieve similar accuracy.
How Should Pre-Trained Language Models Be Fine-Tuned Towards Adversarial Robustness?
Dec 22, 2021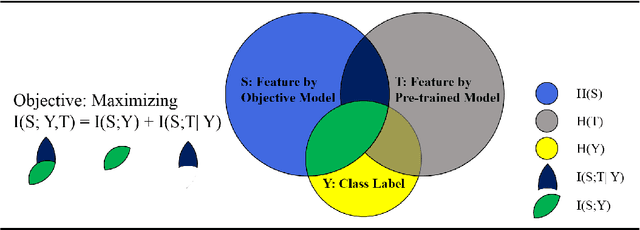

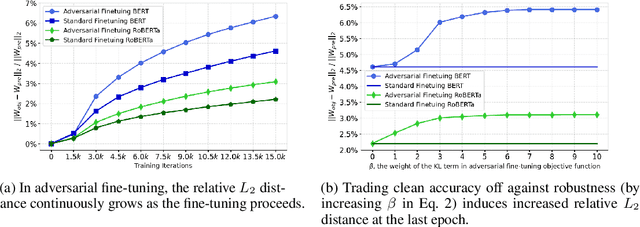

The fine-tuning of pre-trained language models has a great success in many NLP fields. Yet, it is strikingly vulnerable to adversarial examples, e.g., word substitution attacks using only synonyms can easily fool a BERT-based sentiment analysis model. In this paper, we demonstrate that adversarial training, the prevalent defense technique, does not directly fit a conventional fine-tuning scenario, because it suffers severely from catastrophic forgetting: failing to retain the generic and robust linguistic features that have already been captured by the pre-trained model. In this light, we propose Robust Informative Fine-Tuning (RIFT), a novel adversarial fine-tuning method from an information-theoretical perspective. In particular, RIFT encourages an objective model to retain the features learned from the pre-trained model throughout the entire fine-tuning process, whereas a conventional one only uses the pre-trained weights for initialization. Experimental results show that RIFT consistently outperforms the state-of-the-arts on two popular NLP tasks: sentiment analysis and natural language inference, under different attacks across various pre-trained language models.
A Geometric Perspective towards Neural Calibration via Sensitivity Decomposition
Oct 28, 2021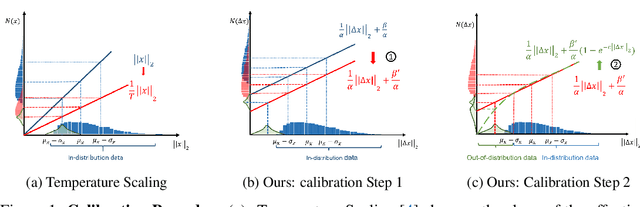
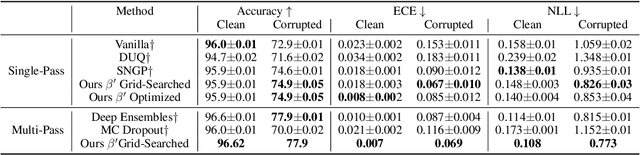
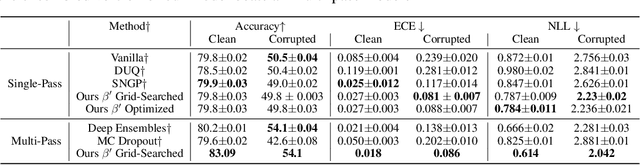
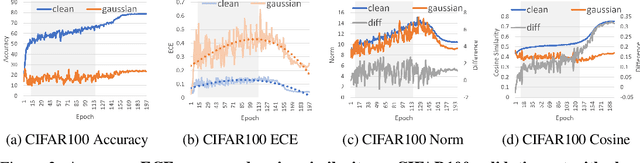
It is well known that vision classification models suffer from poor calibration in the face of data distribution shifts. In this paper, we take a geometric approach to this problem. We propose Geometric Sensitivity Decomposition (GSD) which decomposes the norm of a sample feature embedding and the angular similarity to a target classifier into an instance-dependent and an instance-independent component. The instance-dependent component captures the sensitive information about changes in the input while the instance-independent component represents the insensitive information serving solely to minimize the loss on the training dataset. Inspired by the decomposition, we analytically derive a simple extension to current softmax-linear models, which learns to disentangle the two components during training. On several common vision models, the disentangled model outperforms other calibration methods on standard calibration metrics in the face of out-of-distribution (OOD) data and corruption with significantly less complexity. Specifically, we surpass the current state of the art by 30.8% relative improvement on corrupted CIFAR100 in Expected Calibration Error. Code available at https://github.com/GT-RIPL/Geometric-Sensitivity-Decomposition.git.