 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An algorithm for the selection of route dependent orientation information
Jun 28, 2019
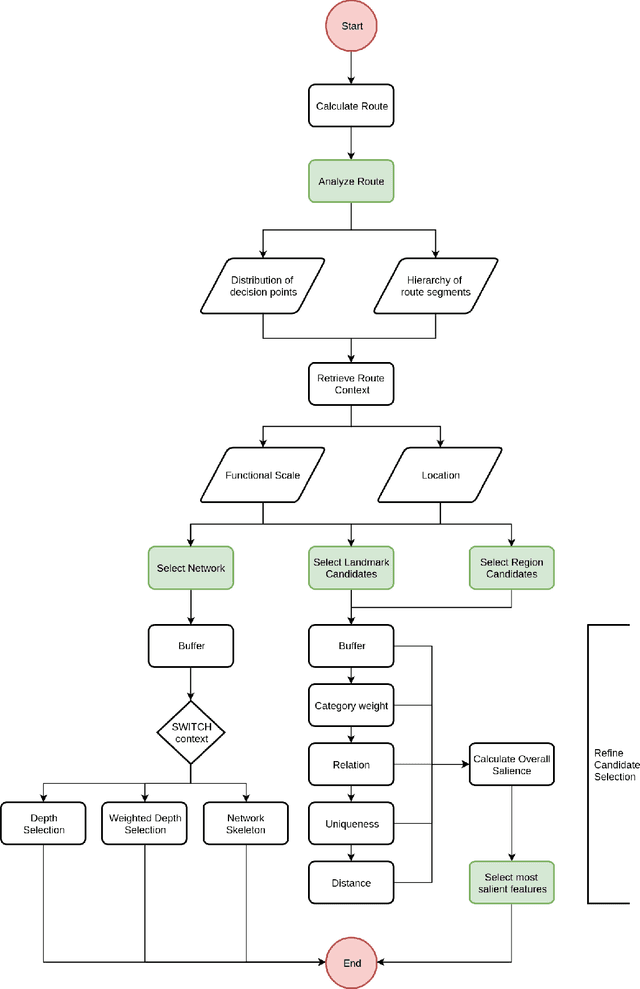


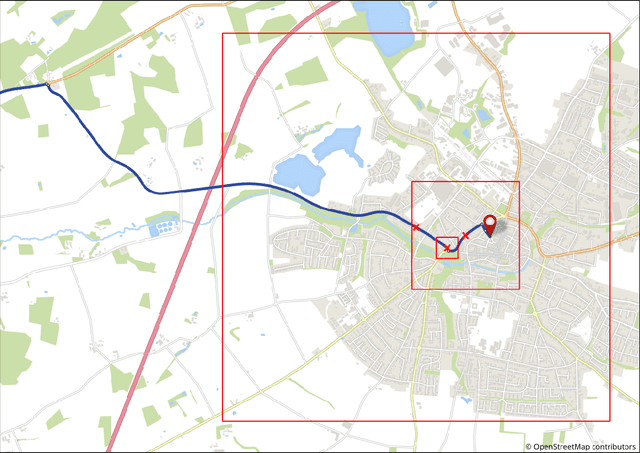
Landmarks are important features of spatial cognition. Landmarks are naturally included in human route descriptions and in the past algorithms were developed to select the most salient landmarks at decision points and automatically incorporate them in route instructions. Moreover, it was shown that human route descriptions contain a significant amount of orientation information and that these orientation information support the acquisition of survey knowledge. Thus, there is a need to extend the landmarks selection in order to automatically select orientation information. In this work we present an algorithm for the computational selection of route dependent orientation information, which extends previous algorithms and includes a salience evaluation of orientation information for any location along the route. We implemented the algorithm and demonstrate the functionality on the basis of OpenStreetMap data.
Testing for Causal Influence using a Partial Coherence Statistic
Dec 07, 2021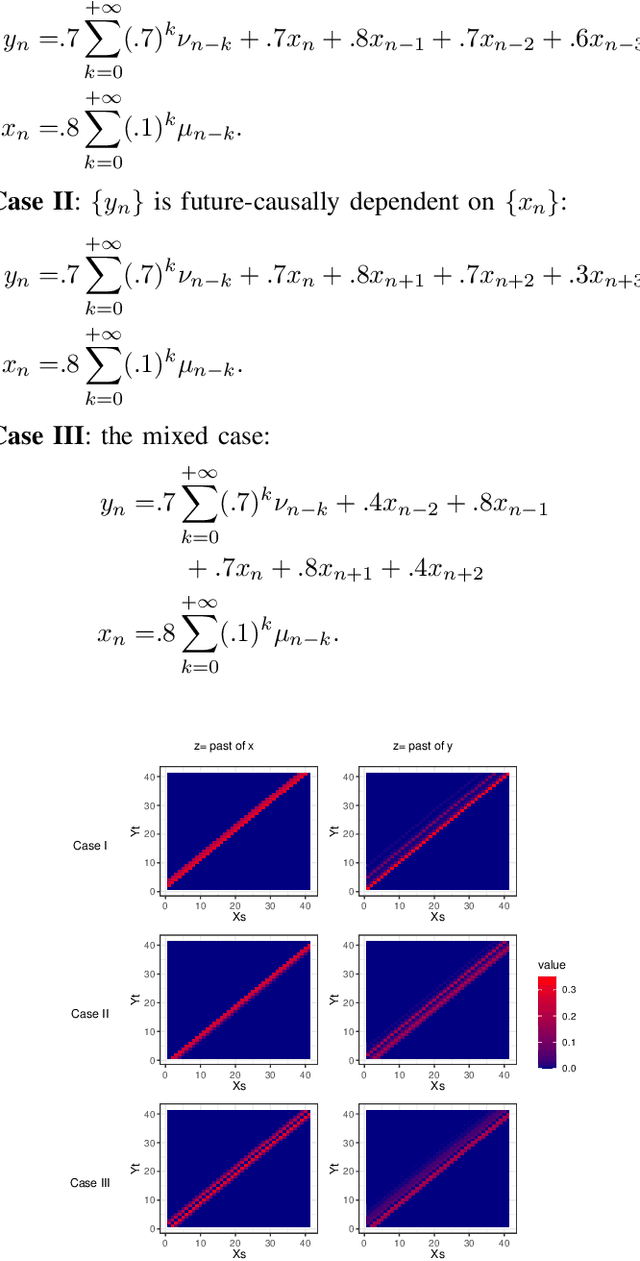
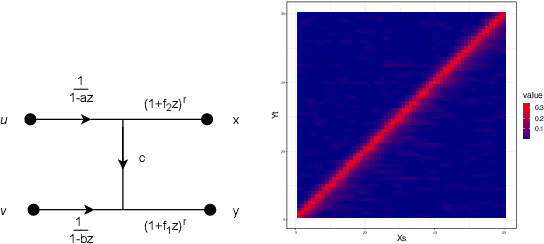
In this paper we explore partial coherence as a tool for evaluating causal influence of one signal sequence on another. In some cases the signal sequence is sampled from a time- or space-series. The key idea is to establish a connection between questions of causality and questions of partial coherence. Once this connection is established, then a scale-invariant partial coherence statistic is used to resolve the question of causality. This coherence statistic is shown to be a likelihood ratio, and its null distribution is shown to be a Wilks Lambda. It may be computed from a composite covariance matrix or from its inverse, the information matrix. Numerical experiments demonstrate the application of partial coherence to the resolution of causality. Importantly, the method is model-free, depending on no generative model for causality.
Modelling Cournot Games as Multi-agent Multi-armed Bandits
Jan 01, 2022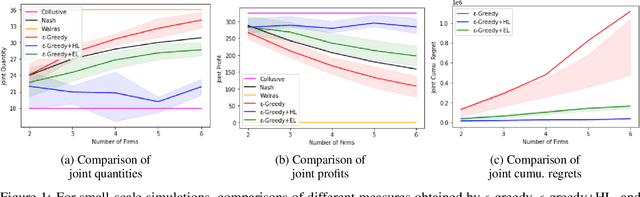
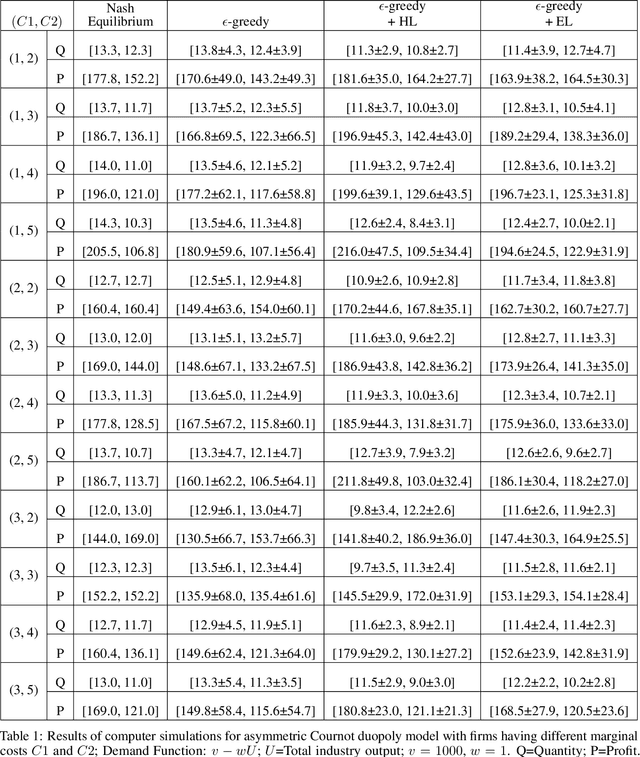
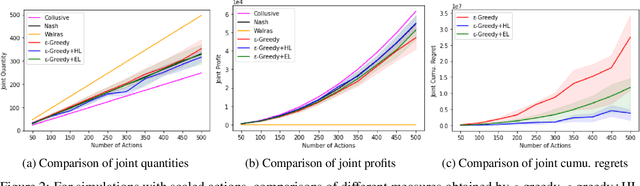
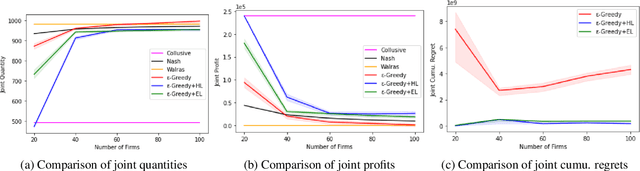
We investigate the use of a multi-agent multi-armed bandit (MA-MAB) setting for modeling repeated Cournot oligopoly games, where the firms acting as agents choose from the set of arms representing production quantity (a discrete value). Agents interact with separate and independent bandit problems. In this formulation, each agent makes sequential choices among arms to maximize its own reward. Agents do not have any information about the environment; they can only see their own rewards after taking an action. However, the market demand is a stationary function of total industry output, and random entry or exit from the market is not allowed. Given these assumptions, we found that an $\epsilon$-greedy approach offers a more viable learning mechanism than other traditional MAB approaches, as it does not require any additional knowledge of the system to operate. We also propose two novel approaches that take advantage of the ordered action space: $\epsilon$-greedy+HL and $\epsilon$-greedy+EL. These new approaches help firms to focus on more profitable actions by eliminating less profitable choices and hence are designed to optimize the exploration. We use computer simulations to study the emergence of various equilibria in the outcomes and do the empirical analysis of joint cumulative regrets.
Shannon entropy for intuitionistic fuzzy information
Jul 06, 2018
The paper presents an extension of Shannon fuzzy entropy for intuitionistic fuzzy one. Firstly, we presented a new formula for calculating the distance and similarity of intuitionistic fuzzy information. Then, we constructed measures for information features like score, certainty and uncertainty. Also, a new concept was introduced, namely escort fuzzy information. Then, using the escort fuzzy information, Shannon's formula for intuitionistic fuzzy information was obtained. It should be underlined that Shannon's entropy for intuitionistic fuzzy information verifies the four defining conditions of intuitionistic fuzzy uncertainty. The measures of its two components were also identified: fuzziness (ambiguity) and incompleteness (ignorance).
Multiscale Principle of Relevant Information for Hyperspectral Image Classification
Jul 13, 2019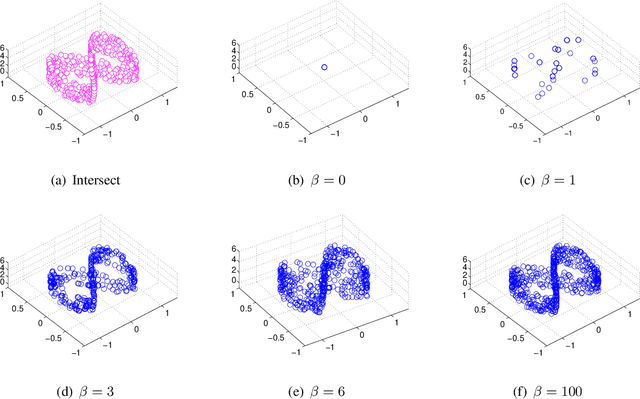
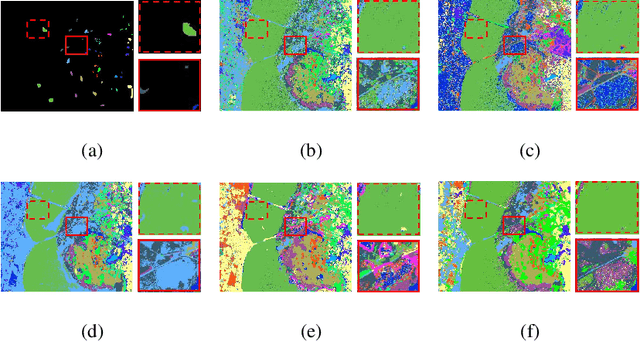
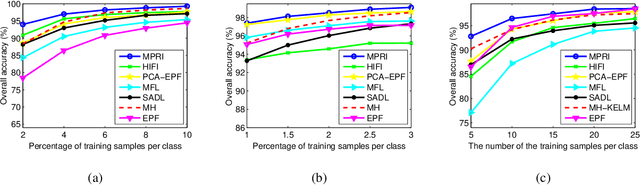
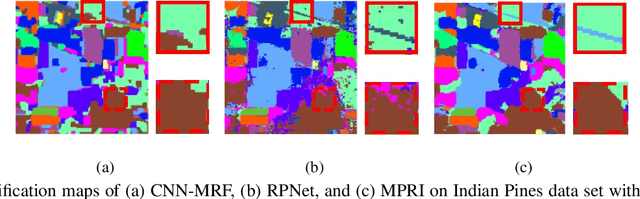
This paper proposes a novel architecture, termed multiscale principle of relevant information (MPRI), to learn discriminative spectral-spatial features for hyperspectral image (HSI) classification. MPRI inherits the merits of the principle of relevant information (PRI) to effectively extract multiscale information embedded in the given data, and also takes advantage of the multilayer structure to learn representations in a coarse-to-fine manner. Specifically, MPRI performs spectral-spatial pixel characterization (using PRI) and feature dimensionality reduction (using regularized linear discriminant analysis) iteratively and successively. Extensive experiments on four benchmark data sets demonstrate that MPRI outperforms existing state-of-the-art HSI classification methods (including deep learning based ones) qualitatively and quantitatively, especially in the scenario of limited training samples.
Page Segmentation using Visual Adjacency Analysis
Dec 11, 2021
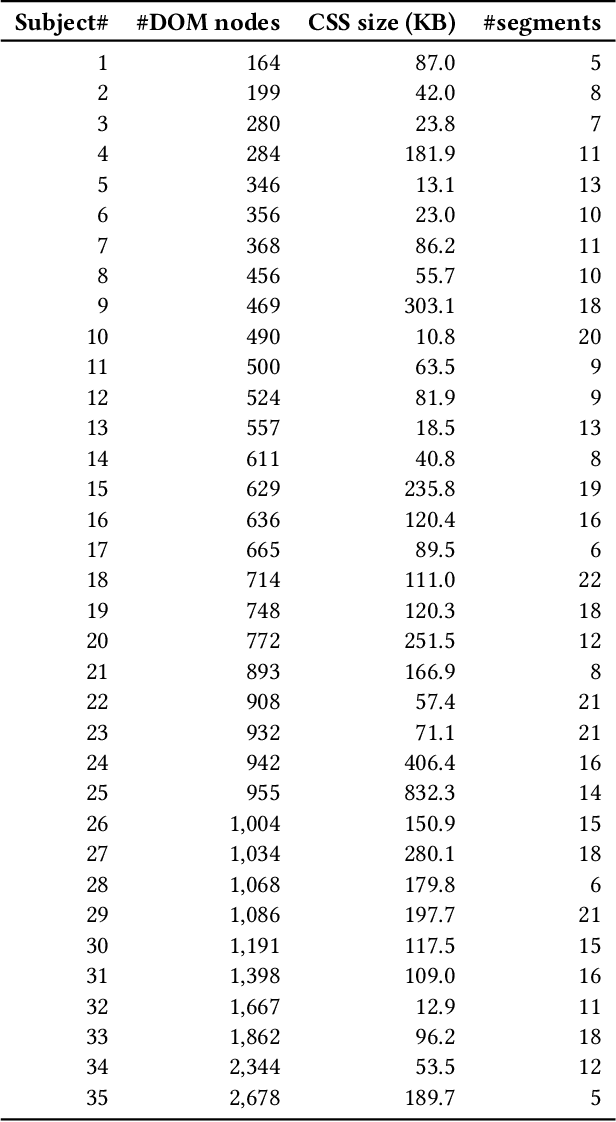
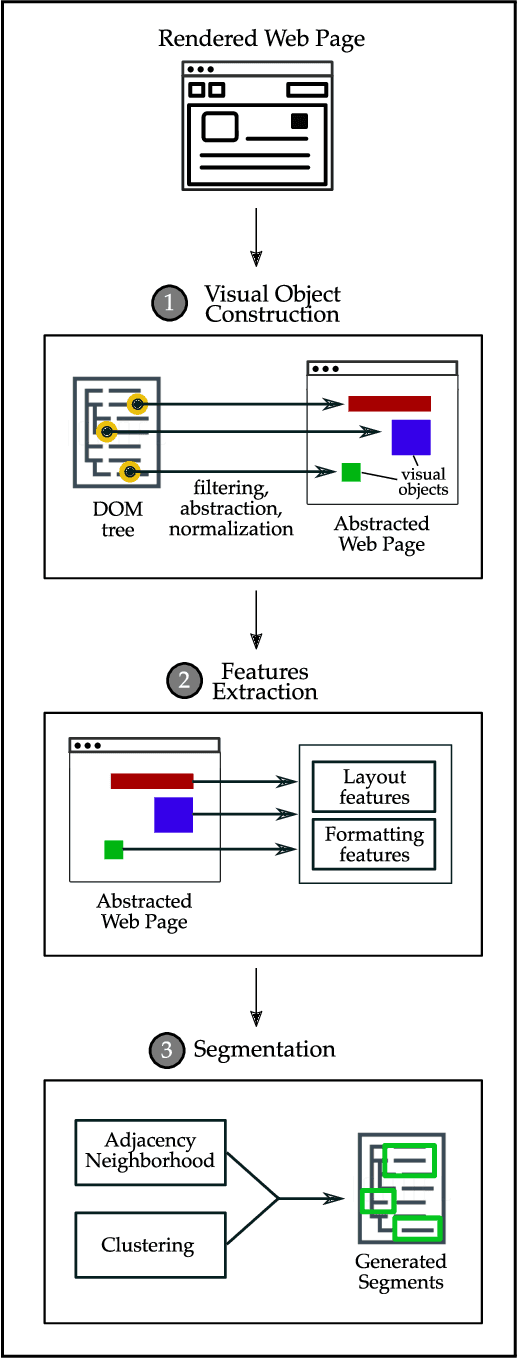
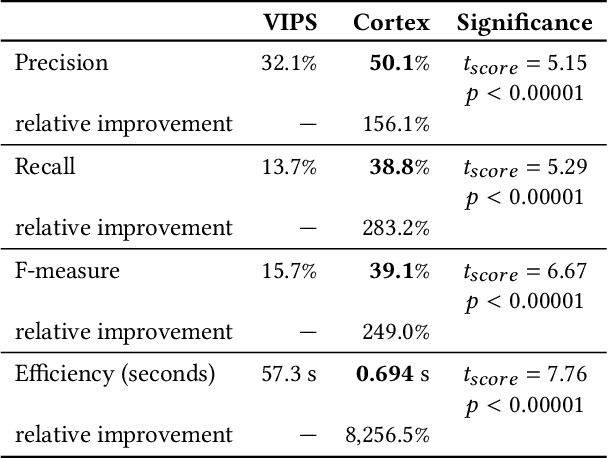
Page segmentation is a web page analysis process that divides a page into cohesive segments, such as sidebars, headers, and footers. Current page segmentation approaches use either the DOM, textual content, or rendering style information of the page. However, these approaches have a number of drawbacks, such as a large number of parameters and rigid assumptions about the page, which negatively impact their segmentation accuracy. We propose a novel page segmentation approach based on visual analysis of localized adjacency regions. It combines DOM attributes and visual analysis to build features of a given page and guide an unsupervised clustering. We evaluate our approach on 35 real-world web pages, and examine the effectiveness and efficiency of segmentation. The results show that, compared with state-of-the-art, our approach achieves an average of 156% increase in precision and 249% improvement in F-measure.
Topic Aware Contextualized Embeddings for High Quality Phrase Extraction
Jan 17, 2022Keyphrase extraction from a given document is the task of automatically extracting salient phrases that best describe the document. This paper proposes a novel unsupervised graph-based ranking method to extract high-quality phrases from a given document. We obtain the contextualized embeddings from pre-trained language models enriched with topic vectors from Latent Dirichlet Allocation (LDA) to represent the candidate phrases and the document. We introduce a scoring mechanism for the phrases using the information obtained from contextualized embeddings and the topic vectors. The salient phrases are extracted using a ranking algorithm on an undirected graph constructed for the given document. In the undirected graph, the nodes represent the phrases, and the edges between the phrases represent the semantic relatedness between them, weighted by a score obtained from the scoring mechanism. To demonstrate the efficacy of our proposed method, we perform several experiments on open source datasets in the science domain and observe that our novel method outperforms existing unsupervised embedding based keyphrase extraction methods. For instance, on the SemEval2017 dataset, our method advances the F1 score from 0.2195 (EmbedRank) to 0.2819 at the top 10 extracted keyphrases. Several variants of the proposed algorithm are investigated to determine their effect on the quality of keyphrases. We further demonstrate the ability of our proposed method to collect additional high-quality keyphrases that are not present in the document from external knowledge bases like Wikipedia for enriching the document with newly discovered keyphrases. We evaluate this step on a collection of annotated documents. The F1-score at the top 10 expanded keyphrases is 0.60, indicating that our algorithm can also be used for 'concept' expansion using external knowledge.
A Geometric Perspective towards Neural Calibration via Sensitivity Decomposition
Oct 28, 2021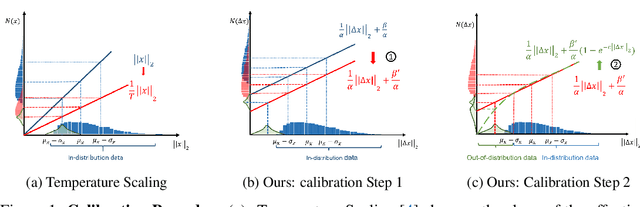
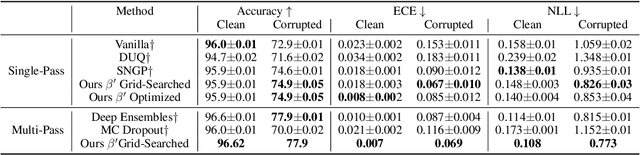
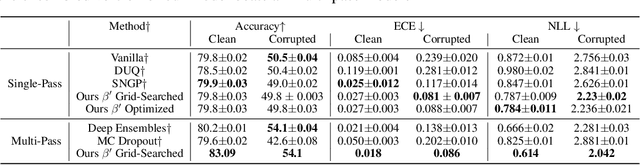
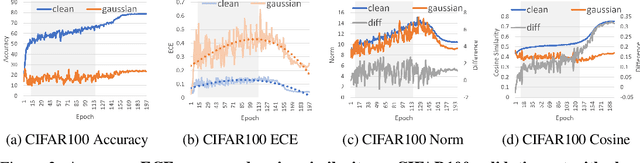
It is well known that vision classification models suffer from poor calibration in the face of data distribution shifts. In this paper, we take a geometric approach to this problem. We propose Geometric Sensitivity Decomposition (GSD) which decomposes the norm of a sample feature embedding and the angular similarity to a target classifier into an instance-dependent and an instance-independent component. The instance-dependent component captures the sensitive information about changes in the input while the instance-independent component represents the insensitive information serving solely to minimize the loss on the training dataset. Inspired by the decomposition, we analytically derive a simple extension to current softmax-linear models, which learns to disentangle the two components during training. On several common vision models, the disentangled model outperforms other calibration methods on standard calibration metrics in the face of out-of-distribution (OOD) data and corruption with significantly less complexity. Specifically, we surpass the current state of the art by 30.8% relative improvement on corrupted CIFAR100 in Expected Calibration Error. Code available at https://github.com/GT-RIPL/Geometric-Sensitivity-Decomposition.git.
Collaborative Reflection-Augmented Autoencoder Network for Recommender Systems
Jan 10, 2022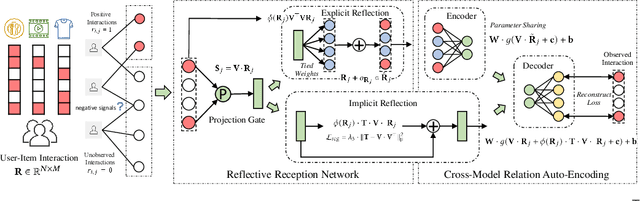


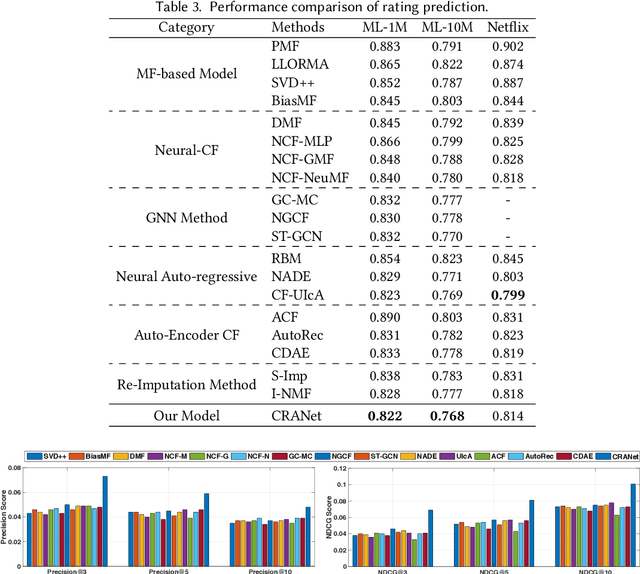
As the deep learning techniques have expanded to real-world recommendation tasks, many deep neural network based Collaborative Filtering (CF) models have been developed to project user-item interactions into latent feature space, based on various neural architectures, such as multi-layer perceptron, auto-encoder and graph neural networks. However, the majority of existing collaborative filtering systems are not well designed to handle missing data. Particularly, in order to inject the negative signals in the training phase, these solutions largely rely on negative sampling from unobserved user-item interactions and simply treating them as negative instances, which brings the recommendation performance degradation. To address the issues, we develop a Collaborative Reflection-Augmented Autoencoder Network (CRANet), that is capable of exploring transferable knowledge from observed and unobserved user-item interactions. The network architecture of CRANet is formed of an integrative structure with a reflective receptor network and an information fusion autoencoder module, which endows our recommendation framework with the ability of encoding implicit user's pairwise preference on both interacted and non-interacted items. Additionally, a parametric regularization-based tied-weight scheme is designed to perform robust joint training of the two-stage CRANet model. We finally experimentally validate CRANet on four diverse benchmark datasets corresponding to two recommendation tasks, to show that debiasing the negative signals of user-item interactions improves the performance as compared to various state-of-the-art recommendation techniques. Our source code is available at https://github.com/akaxlh/CRANet.
3D Siamese Voxel-to-BEV Tracker for Sparse Point Clouds
Nov 17, 2021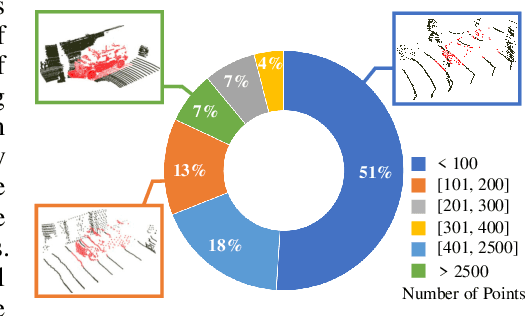
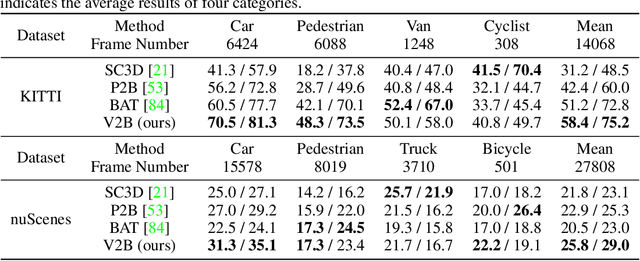
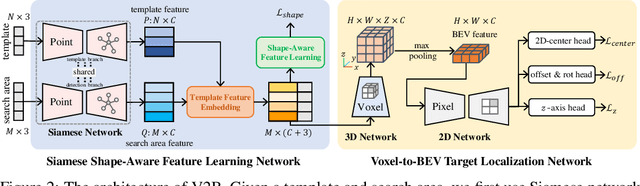
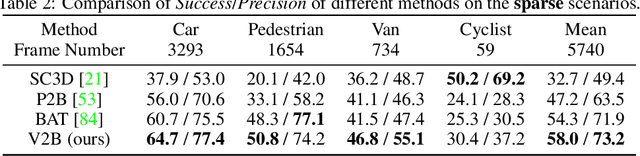
3D object tracking in point clouds is still a challenging problem due to the sparsity of LiDAR points in dynamic environments. In this work, we propose a Siamese voxel-to-BEV tracker, which can significantly improve the tracking performance in sparse 3D point clouds. Specifically, it consists of a Siamese shape-aware feature learning network and a voxel-to-BEV target localization network. The Siamese shape-aware feature learning network can capture 3D shape information of the object to learn the discriminative features of the object so that the potential target from the background in sparse point clouds can be identified. To this end, we first perform template feature embedding to embed the template's feature into the potential target and then generate a dense 3D shape to characterize the shape information of the potential target. For localizing the tracked target, the voxel-to-BEV target localization network regresses the target's 2D center and the $z$-axis center from the dense bird's eye view (BEV) feature map in an anchor-free manner. Concretely, we compress the voxelized point cloud along $z$-axis through max pooling to obtain a dense BEV feature map, where the regression of the 2D center and the $z$-axis center can be performed more effectively. Extensive evaluation on the KITTI and nuScenes datasets shows that our method significantly outperforms the current state-of-the-art methods by a large margin.