 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Traffic Event Detection as a Slot Filling Problem
Sep 13, 2021
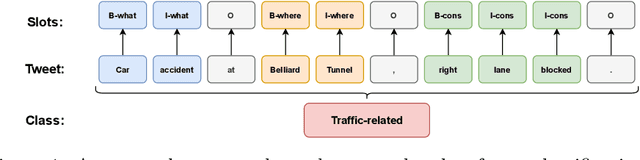
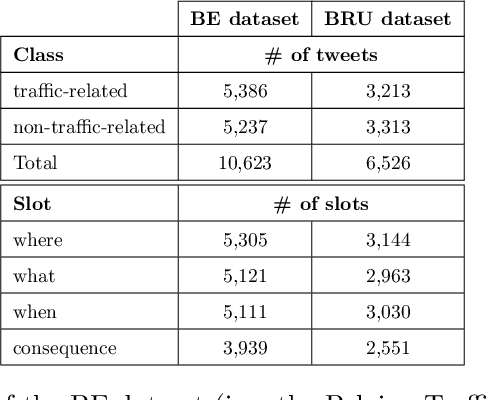
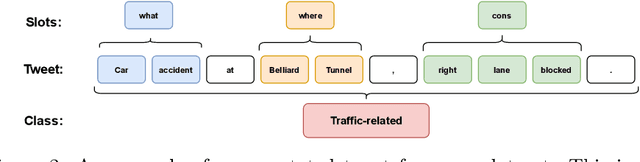
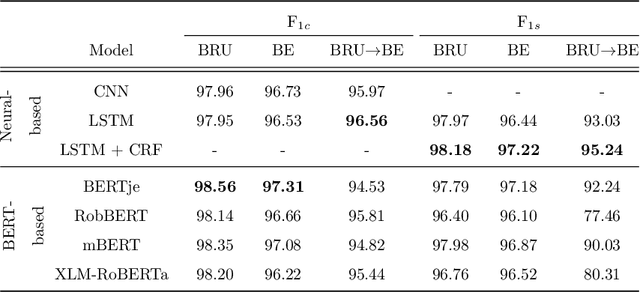
In this paper, we introduce the new problem of extracting fine-grained traffic information from Twitter streams by also making publicly available the two (constructed) traffic-related datasets from Belgium and the Brussels capital region. In particular, we experiment with several models to identify (i) whether a tweet is traffic-related or not, and (ii) in the case that the tweet is traffic-related to identify more fine-grained information regarding the event (e.g., the type of the event, where the event happened). To do so, we frame (i) the problem of identifying whether a tweet is a traffic-related event or not as a text classification subtask, and (ii) the problem of identifying more fine-grained traffic-related information as a slot filling subtask, where fine-grained information (e.g., where an event has happened) is represented as a slot/entity of a particular type. We propose the use of several methods that process the two subtasks either separately or in a joint setting, and we evaluate the effectiveness of the proposed methods for solving the traffic event detection problem. Experimental results indicate that the proposed architectures achieve high performance scores (i.e., more than 95% in terms of F$_{1}$ score) on the constructed datasets for both of the subtasks (i.e., text classification and slot filling) even in a transfer learning scenario. In addition, by incorporating tweet-level information in each of the tokens comprising the tweet (for the BERT-based model) can lead to a performance improvement for the joint setting.
Improving Knowledge Graph Representation Learning by Structure Contextual Pre-training
Dec 08, 2021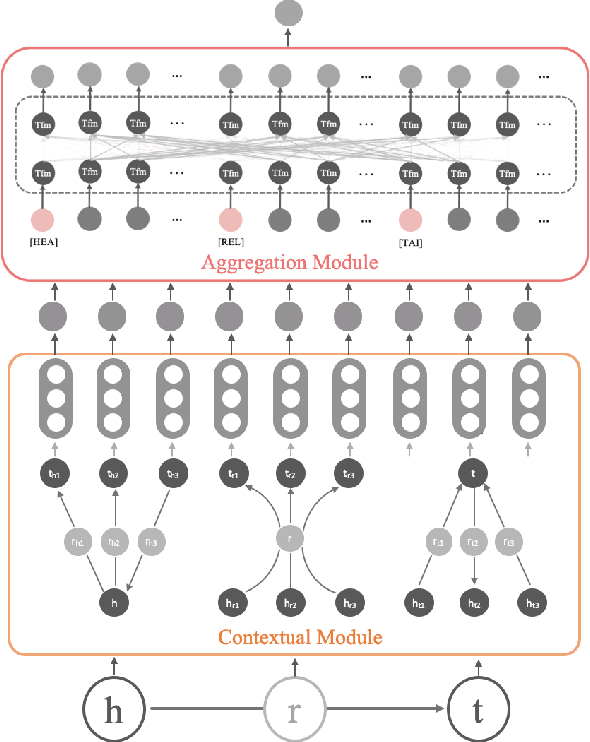
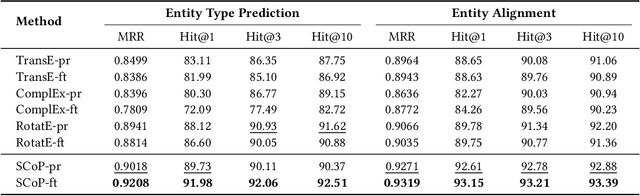
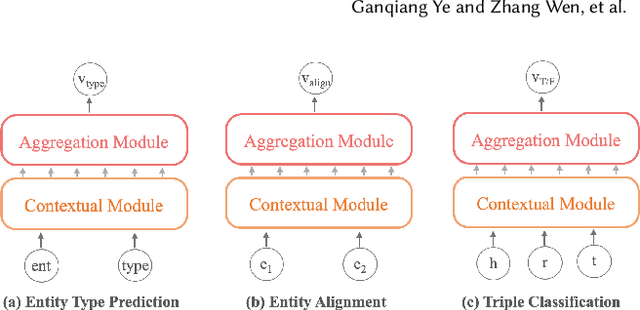
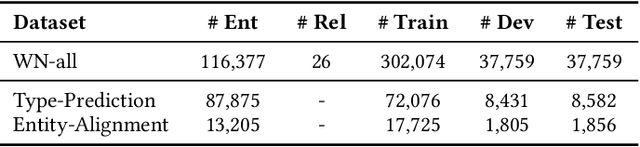
Representation learning models for Knowledge Graphs (KG) have proven to be effective in encoding structural information and performing reasoning over KGs. In this paper, we propose a novel pre-training-then-fine-tuning framework for knowledge graph representation learning, in which a KG model is firstly pre-trained with triple classification task, followed by discriminative fine-tuning on specific downstream tasks such as entity type prediction and entity alignment. Drawing on the general ideas of learning deep contextualized word representations in typical pre-trained language models, we propose SCoP to learn pre-trained KG representations with structural and contextual triples of the target triple encoded. Experimental results demonstrate that fine-tuning SCoP not only outperforms results of baselines on a portfolio of downstream tasks but also avoids tedious task-specific model design and parameter training.
Challenge Dataset of Cognates and False Friend Pairs from Indian Languages
Dec 17, 2021
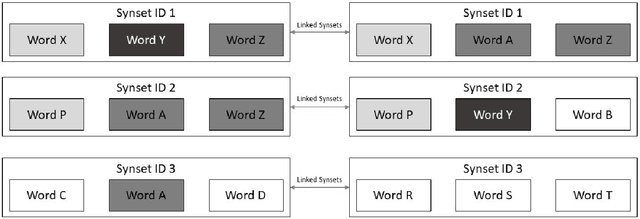


Cognates are present in multiple variants of the same text across different languages (e.g., "hund" in German and "hound" in English language mean "dog"). They pose a challenge to various Natural Language Processing (NLP) applications such as Machine Translation, Cross-lingual Sense Disambiguation, Computational Phylogenetics, and Information Retrieval. A possible solution to address this challenge is to identify cognates across language pairs. In this paper, we describe the creation of two cognate datasets for twelve Indian languages, namely Sanskrit, Hindi, Assamese, Oriya, Kannada, Gujarati, Tamil, Telugu, Punjabi, Bengali, Marathi, and Malayalam. We digitize the cognate data from an Indian language cognate dictionary and utilize linked Indian language Wordnets to generate cognate sets. Additionally, we use the Wordnet data to create a False Friends' dataset for eleven language pairs. We also evaluate the efficacy of our dataset using previously available baseline cognate detection approaches. We also perform a manual evaluation with the help of lexicographers and release the curated gold-standard dataset with this paper.
A Russian Jeopardy! Data Set for Question-Answering Systems
Dec 04, 2021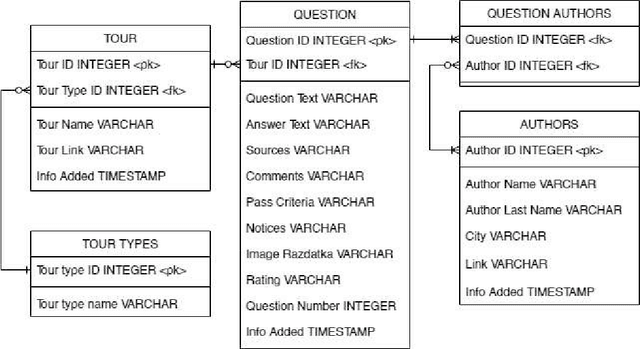
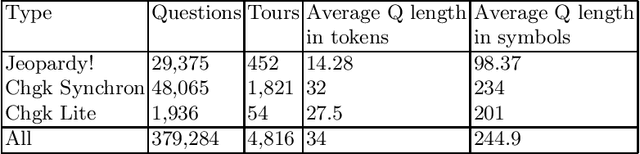
Question answering (QA) is one of the most common NLP tasks that relates to named entity recognition, fact extraction, semantic search and some other fields. In industry, it is much appreciated in chatbots and corporate information systems. It is also a challenging task that attracted the attention of a very general audience at the quiz show Jeopardy! In this article we describe a Jeopardy!-like Russian QA data set collected from the official Russian quiz database Chgk (che ge ka). The data set includes 379,284 quiz-like questions with 29,375 from the Russian analogue of Jeopardy! - "Own Game". We observe its linguistic features and the related QA-task. We conclude about perspectives of a QA competition based on the data set collected from this database.
Sensor Fusion of Camera and Cloud Digital Twin Information for Intelligent Vehicles
Jul 08, 2020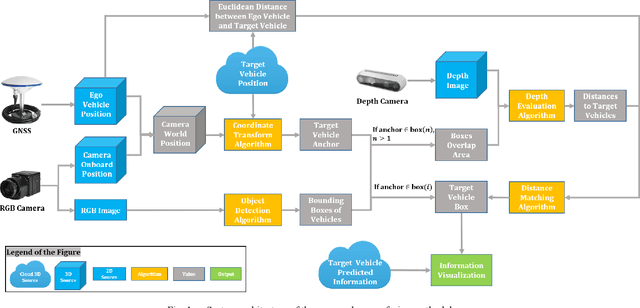
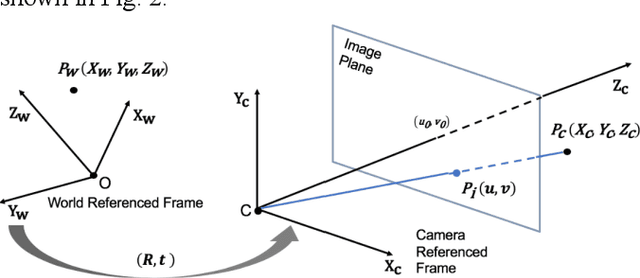
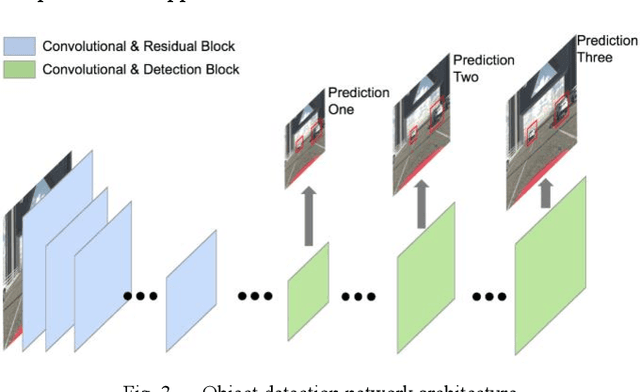
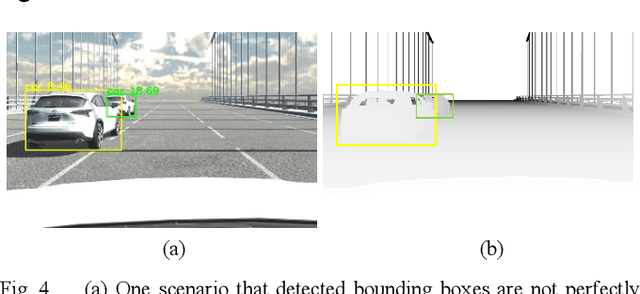
With the rapid development of intelligent vehicles and Advanced Driving Assistance Systems (ADAS), a mixed level of human driver engagements is involved in the transportation system. Visual guidance for drivers is essential under this situation to prevent potential risks. To advance the development of visual guidance systems, we introduce a novel sensor fusion methodology, integrating camera image and Digital Twin knowledge from the cloud. Target vehicle bounding box is drawn and matched by combining results of object detector running on ego vehicle and position information from the cloud. The best matching result, with a 79.2% accuracy under 0.7 Intersection over Union (IoU) threshold, is obtained with depth image served as an additional feature source. Game engine-based simulation results also reveal that the visual guidance system could improve driving safety significantly cooperate with the cloud Digital Twin system.
Observing a group to infer individual characteristics
Oct 12, 2021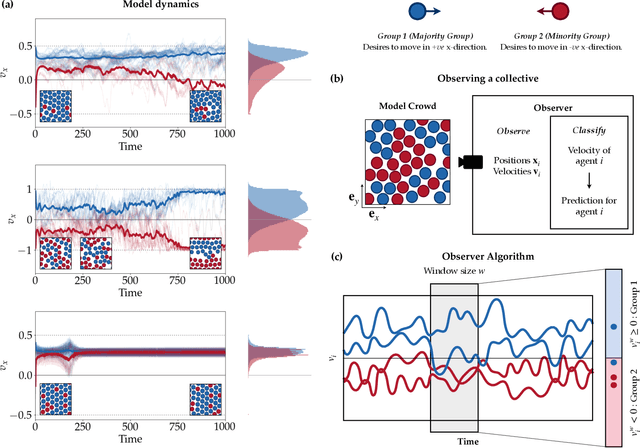
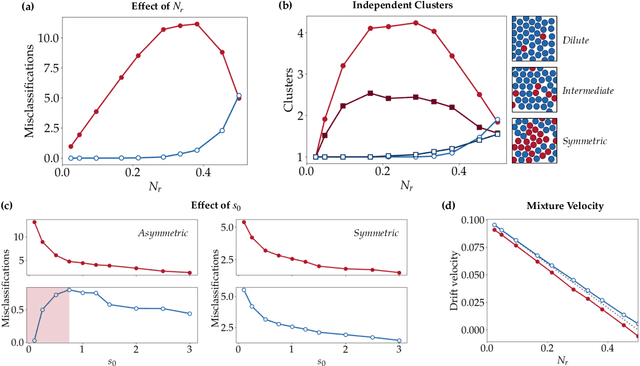
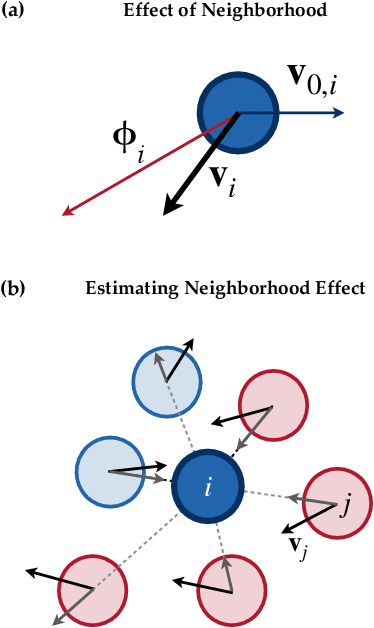
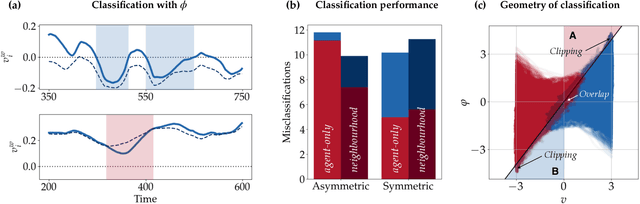
In the study of collective motion, it is common practice to collect movement information at the level of the group to infer the characteristics of the individual agents and their interactions. However, it is not clear whether one can always correctly infer individual characteristics from movement data of the collective. We investigate this question in the context of a composite crowd with two groups of agents, each with its own desired direction of motion. A simple observer attempts to classify an agent into its group based on its movement information. However, collective effects such as collisions, entrainment of agents, formation of lanes and clusters, etc. render the classification problem non-trivial, and lead to misclassifications. Based on our understanding of these effects, we propose a new observer algorithm that infers, based only on observed movement information, how the local neighborhood aids or hinders agent movement. Unlike a traditional supervised learning approach, this algorithm is based on physical insights and scaling arguments, and does not rely on training-data. This new observer improves classification performance and is able to differentiate agents belonging to different groups even when their motion is identical. Data-agnostic approaches like this have relevance to a large class of real-world problems where clean, labeled data is difficult to obtain, and is a step towards hybrid approaches that integrate both data and domain knowledge.
Information-Theoretic Free Energy as Emotion Potential: Emotional Valence as a Function of Complexity and Novelty
Mar 23, 2020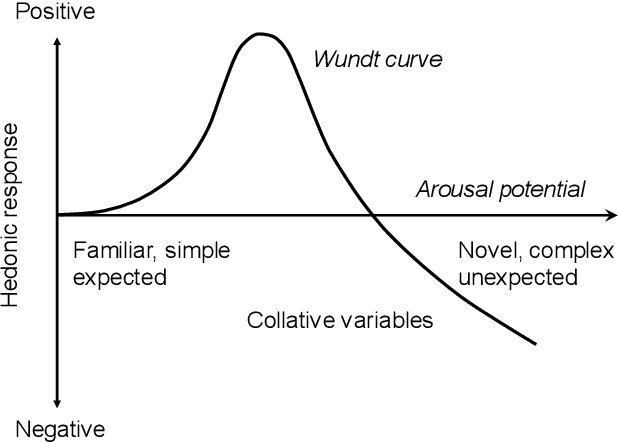
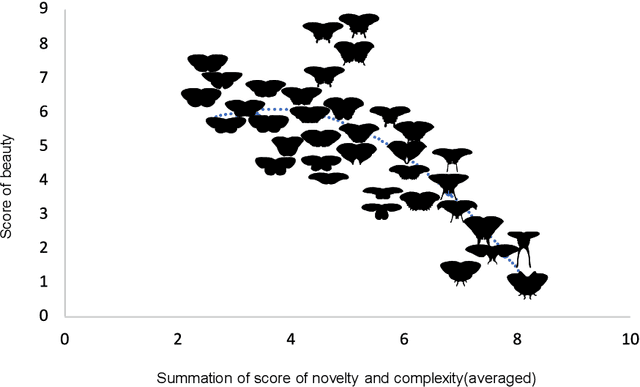
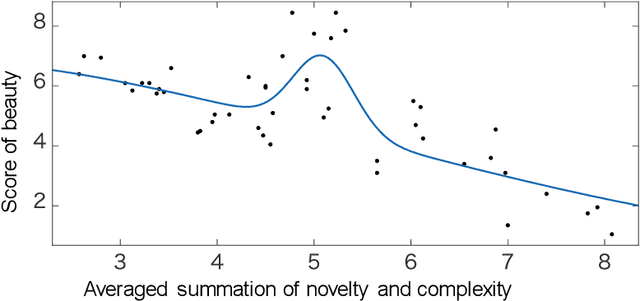
This study extends the mathematical model of emotion dimensions that we previously proposed (Yanagisawa, et al. 2019, Front Comput Neurosci) to consider perceived complexity as well as novelty, as a source of arousal potential. Berlyne's hedonic function of arousal potential (or the inverse U-shaped curve, the so-called Wundt curve) is assumed. We modeled the arousal potential as information contents to be processed in the brain after sensory stimuli are perceived (or recognized), which we termed sensory surprisal. We mathematically demonstrated that sensory surprisal represents free energy, and it is equivalent to a summation of information gain (or information from novelty) and perceived complexity (or information from complexity), which are the collative variables forming the arousal potential. We demonstrated empirical evidence with visual stimuli (profile shapes of butterfly) supporting the hypothesis that the summation of perceived novelty and complexity shapes the inverse U-shaped beauty function. We discussed the potential of free energy as a mathematical principle explaining emotion initiators.
Globally convergent visual-feature range estimation with biased inertial measurements
Dec 23, 2021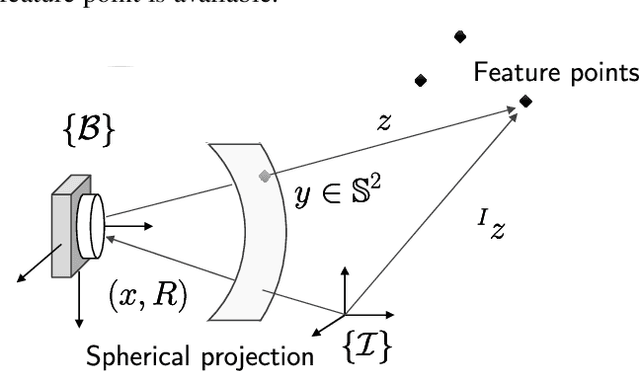
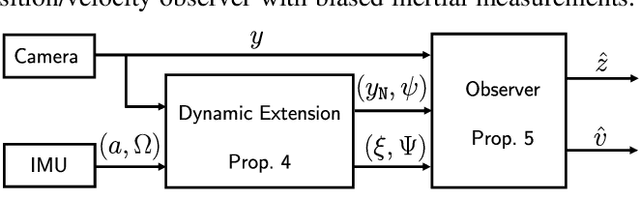
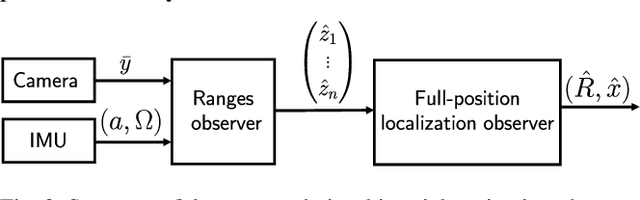
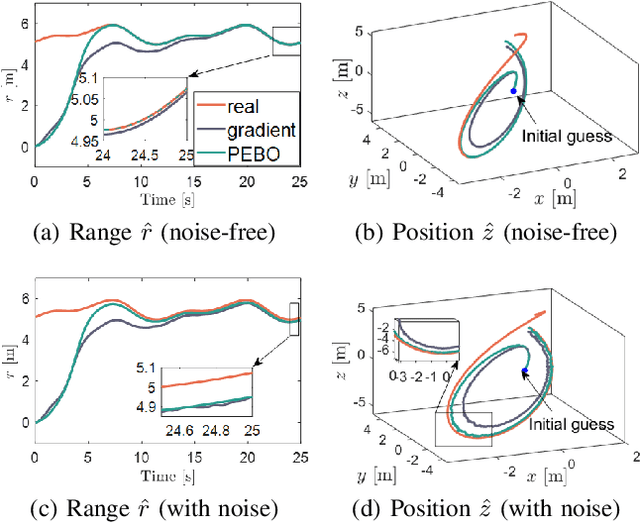
The design of a globally convergent position observer for feature points from visual information is a challenging problem, especially for the case with only inertial measurements and without assumptions of uniform observability, which remained open for a long time. We give a solution to the problem in this paper assuming that only the bearing of a feature point, and biased linear acceleration and rotational velocity of a robot -- all in the body-fixed frame -- are available. Further, in contrast to existing related results, we do not need the value of the gravitational constant either. The proposed approach builds upon the parameter estimation-based observer recently developed in (Ortega et al., Syst. Control. Lett., vol.85, 2015) and its extension to matrix Lie groups in our previous work. Conditions on the robot trajectory under which the observer converges are given, and these are strictly weaker than the standard persistency of excitation and uniform complete observability conditions. Finally, we apply the proposed design to the visual inertial navigation problem. Simulation results are also presented to illustrate our observer design.
Homoscatter: Towards efficient connectivity for ZigBee backscatter system
Nov 03, 2021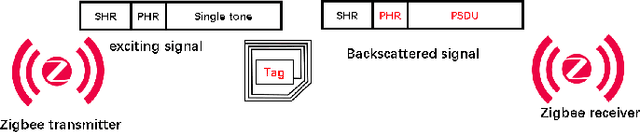
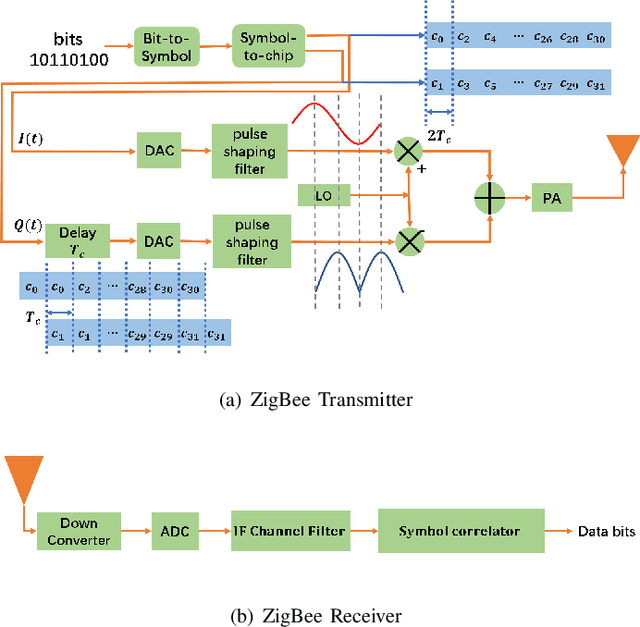
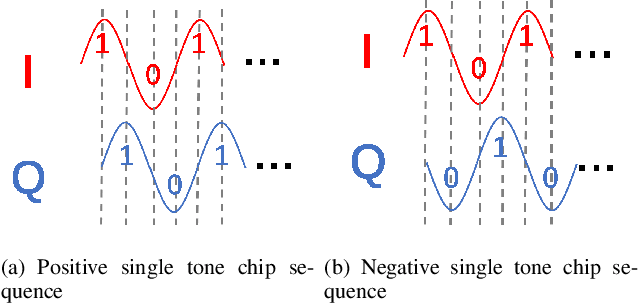
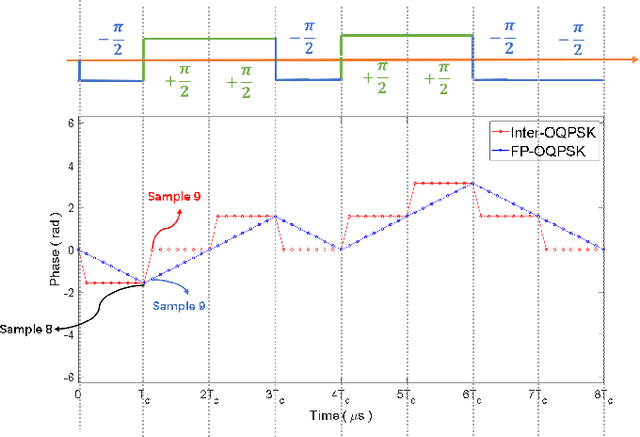
Recent advances in backscatter open a promising direction for ultra-low power communication. However, the state-of-art ZigBee backscatter system, Interscatter, has several drawbacks to deploy. Its backscatter tag and exciting source, Bluetooth, can hardly decode packets from other ZigBee nodes, which left Interscatter one-way communication. Besides, it adopts instantaneous phase change to modulate information, producing obvious sidelobes and interfering devices working on neighboring channels severely. To address the problems mentioned above, we introduce Homoscatter, a novel ZigBee backscatter system that adopts specific ZigBee devices to generate a single tone and leverages continuous phase change to modulate information, which eliminates spectral leakage. It also does codeword translation on the packet header of exciting packets, improving the utilization of ambient signal. The prototype of Homoscatter consists of a microchip radio, a backscatter tag, and a commodity receiver. The evaluations show that the occupied bandwidth of Homoscatter achieves 3x smaller than Interscatter. When the channel capacity is 17.5 kbps, the continuous phase change modulation achieves 13 kbps with the codeword translation on the excitation header. Based on the widely spread IoT devices, Homoscatter is a practical way to build an efficient connection between IoT devices.
HyperPCA: a Powerful Tool to Extract Elemental Maps from Noisy Data Obtained in LIBS Mapping of Materials
Nov 30, 2021Laser-induced breakdown spectroscopy is a preferred technique for fast and direct multi-elemental mapping of samples under ambient pressure, without any limitation on the targeted element. However, LIBS mapping data have two peculiarities: an intrinsically low signal-to-noise ratio due to single-shot measurements, and a high dimensionality due to the high number of spectra acquired for imaging. This is all the truer as lateral resolution gets higher: in this case, the ablation spot diameter is reduced, as well as the ablated mass and the emission signal, while the number of spectra for a given surface increases. Therefore, efficient extraction of physico-chemical information from a noisy and large dataset is a major issue. Multivariate approaches were introduced by several authors as a means to cope with such data, particularly Principal Component Analysis. Yet, PCA is known to present theoretical constraints for the consistent reconstruction of the dataset, and has therefore limitations to efficient interpretation of LIBS mapping data. In this paper, we introduce HyperPCA, a new analysis tool for hyperspectral images based on a sparse representation of the data using Discrete Wavelet Transform and kernel-based sparse PCA to reduce the impact of noise on the data and to consistently reconstruct the spectroscopic signal, with a particular emphasis on LIBS data. The method is first illustrated using simulated LIBS mapping datasets to emphasize its performances with highly noisy and/or highly interfered spectra. Comparisons to standard PCA and to traditional univariate data analyses are provided. Finally, it is used to process real data in two cases that clearly illustrate the potential of the proposed algorithm. We show that the method presents advantages both in quantity and quality of the information recovered, thus improving the physico-chemical characterisation of analysed surfaces.