 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generating Diverse and Consistent QA pairs from Contexts with Information-Maximizing Hierarchical Conditional VAEs
Jun 02, 2020

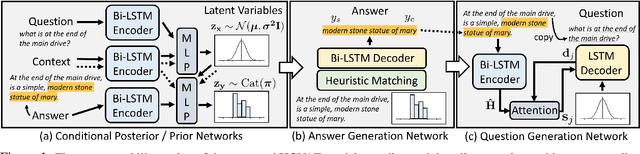
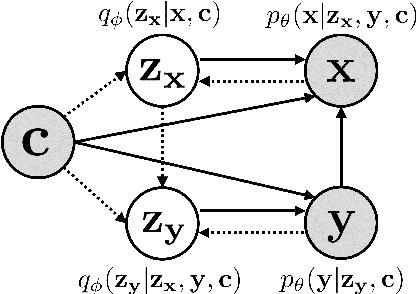
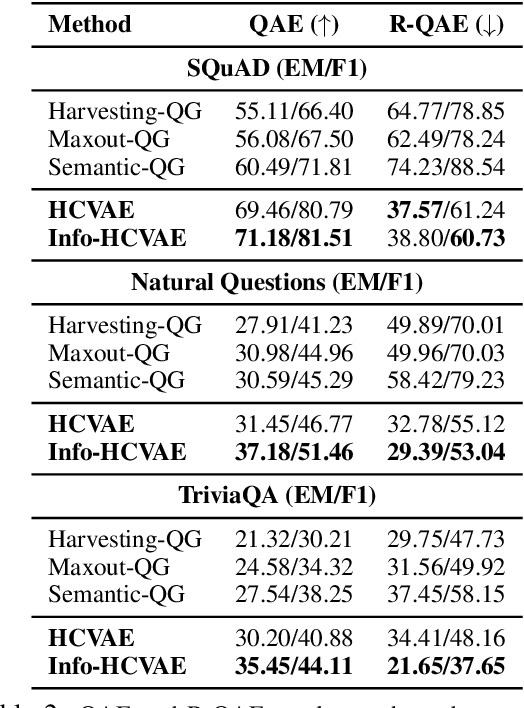
One of the most crucial challenges in question answering (QA) is the scarcity of labeled data, since it is costly to obtain question-answer (QA) pairs for a target text domain with human annotation. An alternative approach to tackle the problem is to use automatically generated QA pairs from either the problem context or from large amount of unstructured texts (e.g. Wikipedia). In this work, we propose a hierarchical conditional variational autoencoder (HCVAE) for generating QA pairs given unstructured texts as contexts, while maximizing the mutual information between generated QA pairs to ensure their consistency. We validate our Information Maximizing Hierarchical Conditional Variational AutoEncoder (Info-HCVAE) on several benchmark datasets by evaluating the performance of the QA model (BERT-base) using only the generated QA pairs (QA-based evaluation) or by using both the generated and human-labeled pairs (semi-supervised learning) for training, against state-of-the-art baseline models. The results show that our model obtains impressive performance gains over all baselines on both tasks, using only a fraction of data for training.
Topic Aware Contextualized Embeddings for High Quality Phrase Extraction
Jan 17, 2022Keyphrase extraction from a given document is the task of automatically extracting salient phrases that best describe the document. This paper proposes a novel unsupervised graph-based ranking method to extract high-quality phrases from a given document. We obtain the contextualized embeddings from pre-trained language models enriched with topic vectors from Latent Dirichlet Allocation (LDA) to represent the candidate phrases and the document. We introduce a scoring mechanism for the phrases using the information obtained from contextualized embeddings and the topic vectors. The salient phrases are extracted using a ranking algorithm on an undirected graph constructed for the given document. In the undirected graph, the nodes represent the phrases, and the edges between the phrases represent the semantic relatedness between them, weighted by a score obtained from the scoring mechanism. To demonstrate the efficacy of our proposed method, we perform several experiments on open source datasets in the science domain and observe that our novel method outperforms existing unsupervised embedding based keyphrase extraction methods. For instance, on the SemEval2017 dataset, our method advances the F1 score from 0.2195 (EmbedRank) to 0.2819 at the top 10 extracted keyphrases. Several variants of the proposed algorithm are investigated to determine their effect on the quality of keyphrases. We further demonstrate the ability of our proposed method to collect additional high-quality keyphrases that are not present in the document from external knowledge bases like Wikipedia for enriching the document with newly discovered keyphrases. We evaluate this step on a collection of annotated documents. The F1-score at the top 10 expanded keyphrases is 0.60, indicating that our algorithm can also be used for 'concept' expansion using external knowledge.
Challenge Dataset of Cognates and False Friend Pairs from Indian Languages
Dec 17, 2021
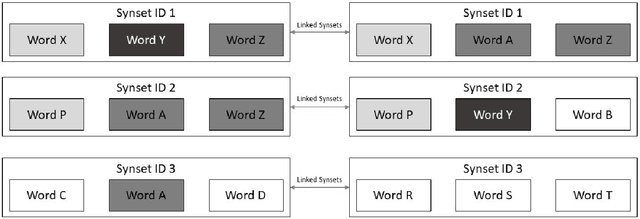


Cognates are present in multiple variants of the same text across different languages (e.g., "hund" in German and "hound" in English language mean "dog"). They pose a challenge to various Natural Language Processing (NLP) applications such as Machine Translation, Cross-lingual Sense Disambiguation, Computational Phylogenetics, and Information Retrieval. A possible solution to address this challenge is to identify cognates across language pairs. In this paper, we describe the creation of two cognate datasets for twelve Indian languages, namely Sanskrit, Hindi, Assamese, Oriya, Kannada, Gujarati, Tamil, Telugu, Punjabi, Bengali, Marathi, and Malayalam. We digitize the cognate data from an Indian language cognate dictionary and utilize linked Indian language Wordnets to generate cognate sets. Additionally, we use the Wordnet data to create a False Friends' dataset for eleven language pairs. We also evaluate the efficacy of our dataset using previously available baseline cognate detection approaches. We also perform a manual evaluation with the help of lexicographers and release the curated gold-standard dataset with this paper.
Decoupling Speaker-Independent Emotions for Voice Conversion Via Source-Filter Networks
Oct 04, 2021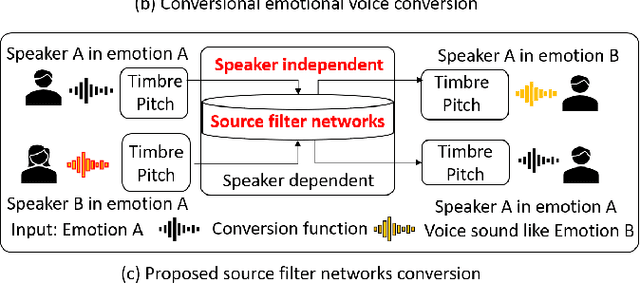
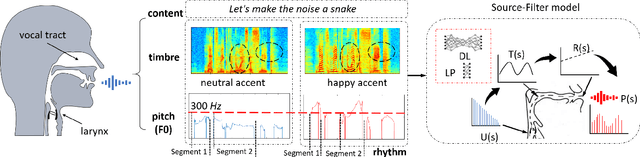
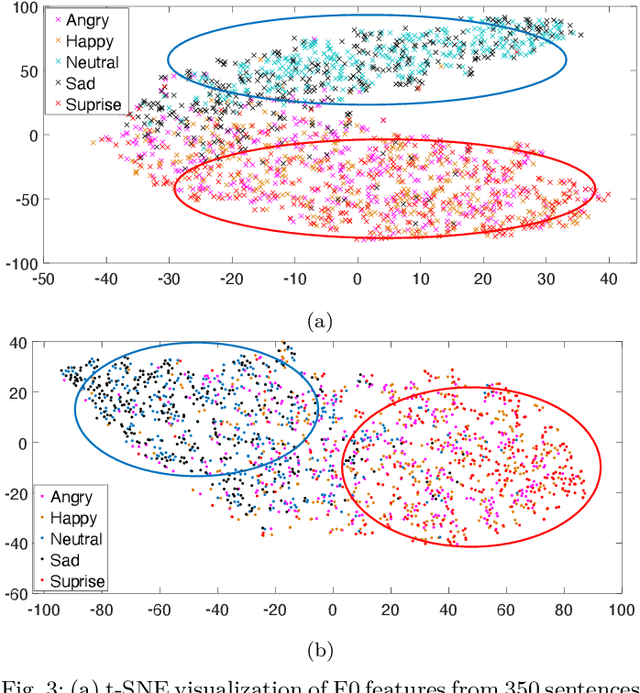
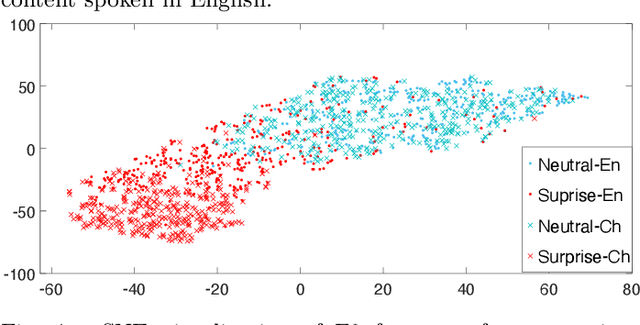
Emotional voice conversion (VC) aims to convert a neutral voice to an emotional (e.g. happy) one while retaining the linguistic information and speaker identity. We note that the decoupling of emotional features from other speech information (such as speaker, content, etc.) is the key to achieving remarkable performance. Some recent attempts about speech representation decoupling on the neutral speech can not work well on the emotional speech, due to the more complex acoustic properties involved in the latter. To address this problem, here we propose a novel Source-Filter-based Emotional VC model (SFEVC) to achieve proper filtering of speaker-independent emotion features from both the timbre and pitch features. Our SFEVC model consists of multi-channel encoders, emotion separate encoders, and one decoder. Note that all encoder modules adopt a designed information bottlenecks auto-encoder. Additionally, to further improve the conversion quality for various emotions, a novel two-stage training strategy based on the 2D Valence-Arousal (VA) space was proposed. Experimental results show that the proposed SFEVC along with a two-stage training strategy outperforms all baselines and achieves the state-of-the-art performance in speaker-independent emotional VC with nonparallel data.
Globally convergent visual-feature range estimation with biased inertial measurements
Dec 23, 2021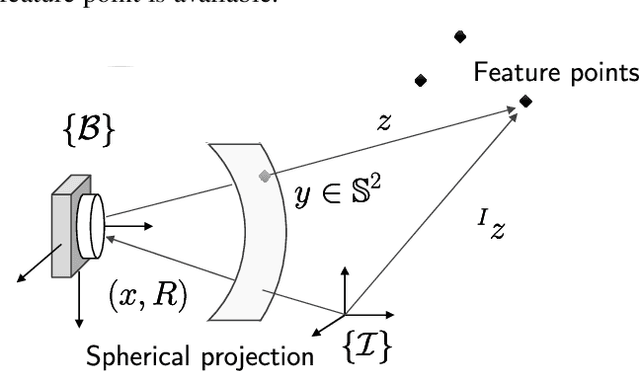
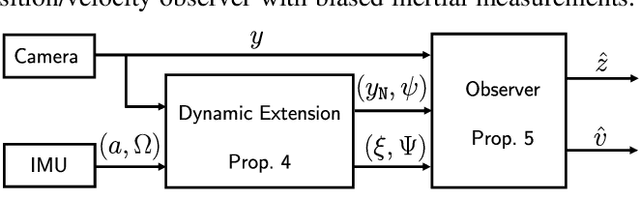
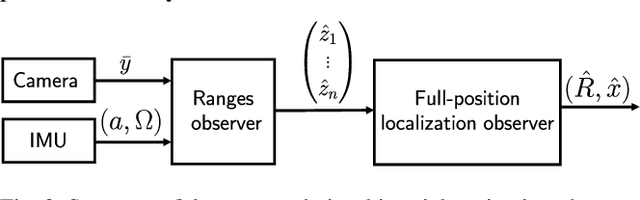
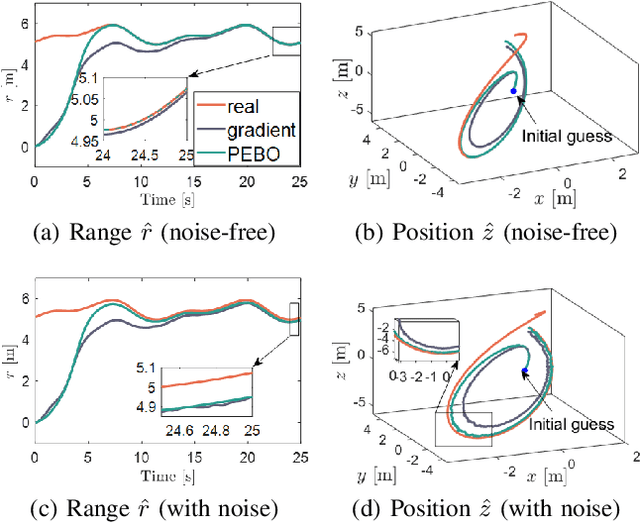
The design of a globally convergent position observer for feature points from visual information is a challenging problem, especially for the case with only inertial measurements and without assumptions of uniform observability, which remained open for a long time. We give a solution to the problem in this paper assuming that only the bearing of a feature point, and biased linear acceleration and rotational velocity of a robot -- all in the body-fixed frame -- are available. Further, in contrast to existing related results, we do not need the value of the gravitational constant either. The proposed approach builds upon the parameter estimation-based observer recently developed in (Ortega et al., Syst. Control. Lett., vol.85, 2015) and its extension to matrix Lie groups in our previous work. Conditions on the robot trajectory under which the observer converges are given, and these are strictly weaker than the standard persistency of excitation and uniform complete observability conditions. Finally, we apply the proposed design to the visual inertial navigation problem. Simulation results are also presented to illustrate our observer design.
Improving Knowledge Graph Representation Learning by Structure Contextual Pre-training
Dec 08, 2021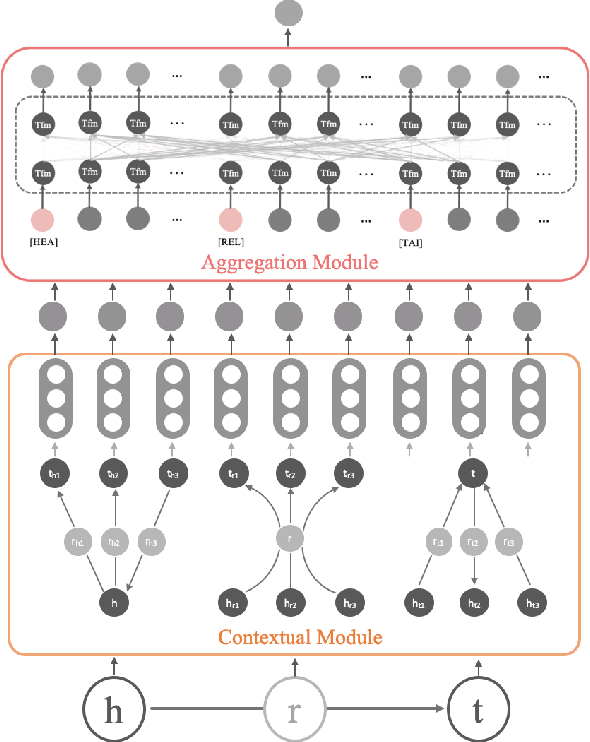
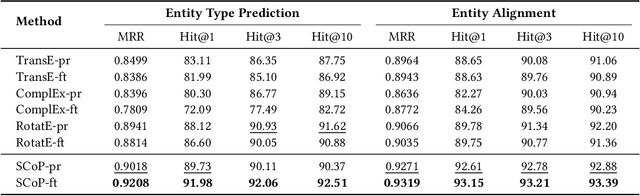
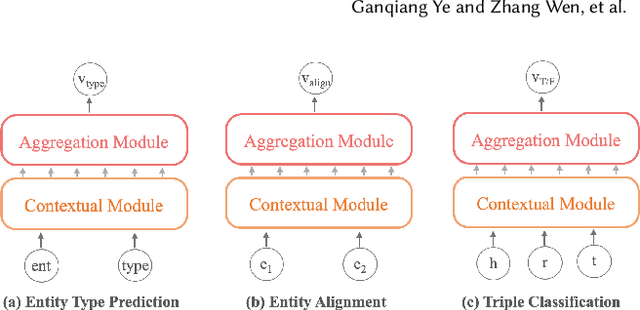
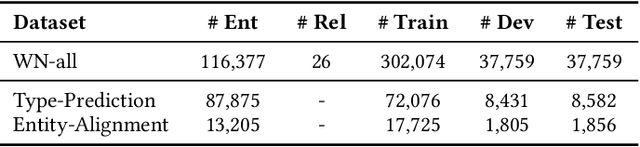
Representation learning models for Knowledge Graphs (KG) have proven to be effective in encoding structural information and performing reasoning over KGs. In this paper, we propose a novel pre-training-then-fine-tuning framework for knowledge graph representation learning, in which a KG model is firstly pre-trained with triple classification task, followed by discriminative fine-tuning on specific downstream tasks such as entity type prediction and entity alignment. Drawing on the general ideas of learning deep contextualized word representations in typical pre-trained language models, we propose SCoP to learn pre-trained KG representations with structural and contextual triples of the target triple encoded. Experimental results demonstrate that fine-tuning SCoP not only outperforms results of baselines on a portfolio of downstream tasks but also avoids tedious task-specific model design and parameter training.
Modelling Cournot Games as Multi-agent Multi-armed Bandits
Jan 01, 2022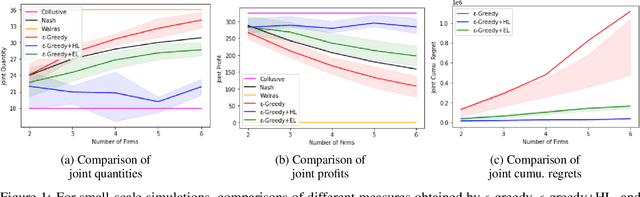
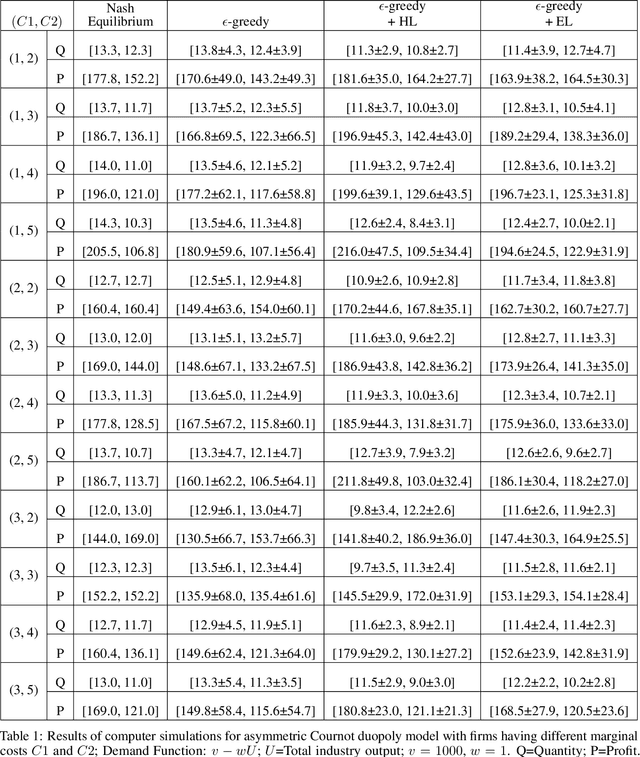
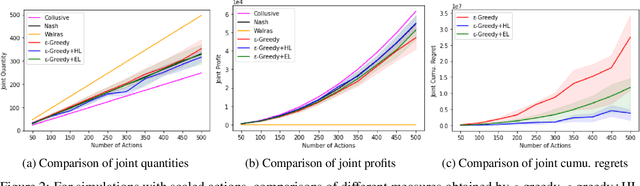
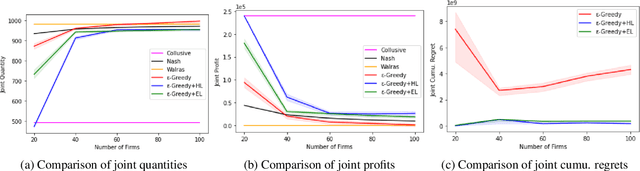
We investigate the use of a multi-agent multi-armed bandit (MA-MAB) setting for modeling repeated Cournot oligopoly games, where the firms acting as agents choose from the set of arms representing production quantity (a discrete value). Agents interact with separate and independent bandit problems. In this formulation, each agent makes sequential choices among arms to maximize its own reward. Agents do not have any information about the environment; they can only see their own rewards after taking an action. However, the market demand is a stationary function of total industry output, and random entry or exit from the market is not allowed. Given these assumptions, we found that an $\epsilon$-greedy approach offers a more viable learning mechanism than other traditional MAB approaches, as it does not require any additional knowledge of the system to operate. We also propose two novel approaches that take advantage of the ordered action space: $\epsilon$-greedy+HL and $\epsilon$-greedy+EL. These new approaches help firms to focus on more profitable actions by eliminating less profitable choices and hence are designed to optimize the exploration. We use computer simulations to study the emergence of various equilibria in the outcomes and do the empirical analysis of joint cumulative regrets.
Multimodal Image Super-resolution via Deep Unfolding with Side Information
Oct 18, 2019
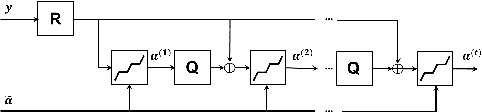
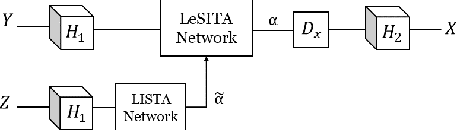
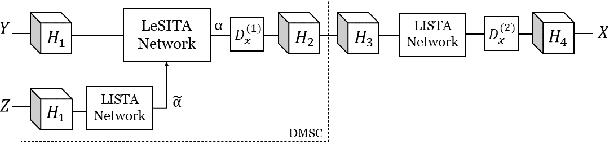
Deep learning methods have been successfully applied to various computer vision tasks. However, existing neural network architectures do not per se incorporate domain knowledge about the addressed problem, thus, understanding what the model has learned is an open research topic. In this paper, we rely on the unfolding of an iterative algorithm for sparse approximation with side information, and design a deep learning architecture for multimodal image super-resolution that incorporates sparse priors and effectively utilizes information from another image modality. We develop two deep models performing reconstruction of a high-resolution image of a target image modality from its low-resolution variant with the aid of a high-resolution image from a second modality. We apply the proposed models to super-resolve near-infrared images using as side information high-resolution RGB\ images. Experimental results demonstrate the superior performance of the proposed models against state-of-the-art methods including unimodal and multimodal approaches.
Collaborative Reflection-Augmented Autoencoder Network for Recommender Systems
Jan 10, 2022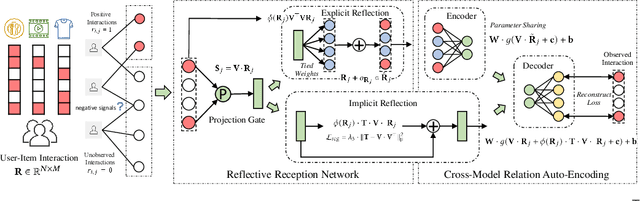


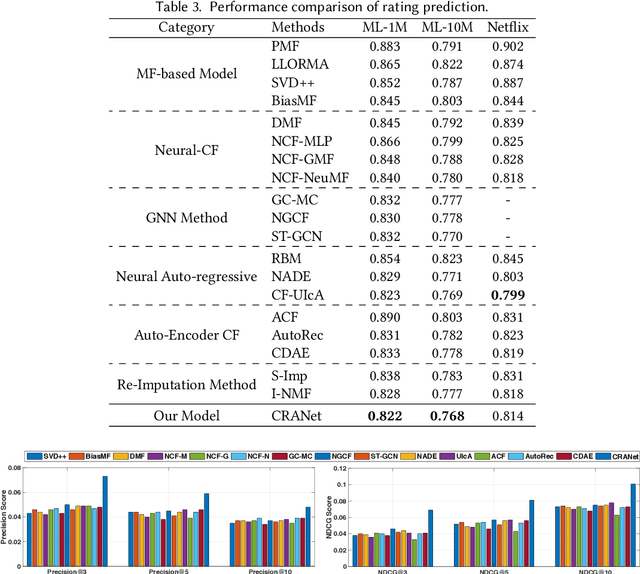
As the deep learning techniques have expanded to real-world recommendation tasks, many deep neural network based Collaborative Filtering (CF) models have been developed to project user-item interactions into latent feature space, based on various neural architectures, such as multi-layer perceptron, auto-encoder and graph neural networks. However, the majority of existing collaborative filtering systems are not well designed to handle missing data. Particularly, in order to inject the negative signals in the training phase, these solutions largely rely on negative sampling from unobserved user-item interactions and simply treating them as negative instances, which brings the recommendation performance degradation. To address the issues, we develop a Collaborative Reflection-Augmented Autoencoder Network (CRANet), that is capable of exploring transferable knowledge from observed and unobserved user-item interactions. The network architecture of CRANet is formed of an integrative structure with a reflective receptor network and an information fusion autoencoder module, which endows our recommendation framework with the ability of encoding implicit user's pairwise preference on both interacted and non-interacted items. Additionally, a parametric regularization-based tied-weight scheme is designed to perform robust joint training of the two-stage CRANet model. We finally experimentally validate CRANet on four diverse benchmark datasets corresponding to two recommendation tasks, to show that debiasing the negative signals of user-item interactions improves the performance as compared to various state-of-the-art recommendation techniques. Our source code is available at https://github.com/akaxlh/CRANet.
A Russian Jeopardy! Data Set for Question-Answering Systems
Dec 04, 2021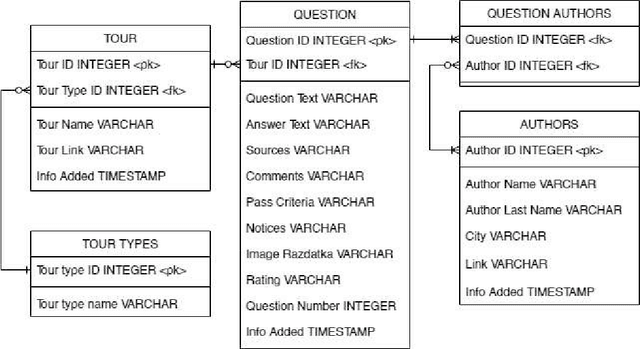
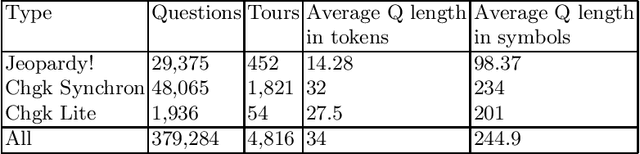
Question answering (QA) is one of the most common NLP tasks that relates to named entity recognition, fact extraction, semantic search and some other fields. In industry, it is much appreciated in chatbots and corporate information systems. It is also a challenging task that attracted the attention of a very general audience at the quiz show Jeopardy! In this article we describe a Jeopardy!-like Russian QA data set collected from the official Russian quiz database Chgk (che ge ka). The data set includes 379,284 quiz-like questions with 29,375 from the Russian analogue of Jeopardy! - "Own Game". We observe its linguistic features and the related QA-task. We conclude about perspectives of a QA competition based on the data set collected from this database.