 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GroupIM: A Mutual Information Maximization Framework for Neural Group Recommendation
Jun 09, 2020
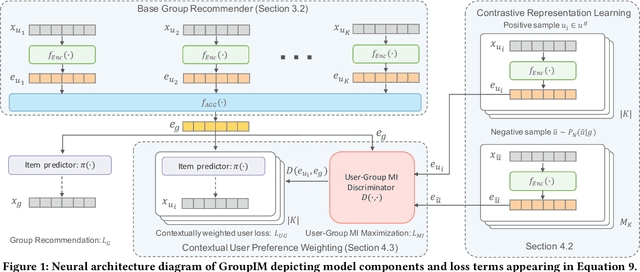
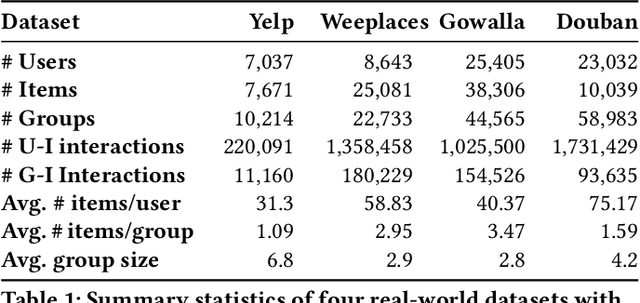
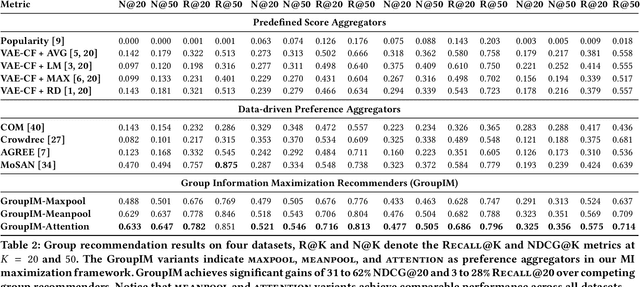
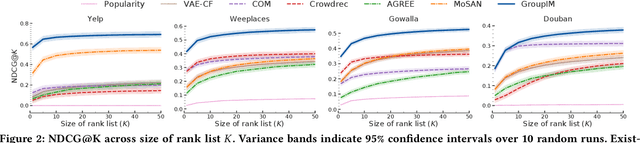
We study the problem of making item recommendations to ephemeral groups, which comprise users with limited or no historical activities together. Existing studies target persistent groups with substantial activity history, while ephemeral groups lack historical interactions. To overcome group interaction sparsity, we propose data-driven regularization strategies to exploit both the preference covariance amongst users who are in the same group, as well as the contextual relevance of users' individual preferences to each group. We make two contributions. First, we present a recommender architecture-agnostic framework GroupIM that can integrate arbitrary neural preference encoders and aggregators for ephemeral group recommendation. Second, we regularize the user-group latent space to overcome group interaction sparsity by: maximizing mutual information between representations of groups and group members; and dynamically prioritizing the preferences of highly informative members through contextual preference weighting. Our experimental results on several real-world datasets indicate significant performance improvements (31-62% relative NDCG@20) over state-of-the-art group recommendation techniques.
Transfer Learning Based Multi-Objective Genetic Algorithm for Dynamic Community Detection
Oct 09, 2021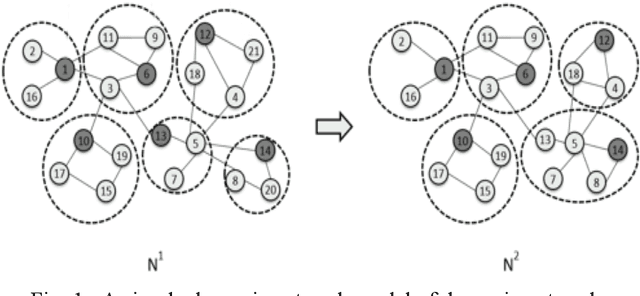


Dynamic community detection is the hotspot and basic problem of complex network and artificial intelligence research in recent years. It is necessary to maximize the accuracy of clustering as the network structure changes, but also to minimize the two consecutive clustering differences between the two results. There is a trade-off relationship between these two objectives. In this paper, we propose a Feature Transfer Based Multi-Objective Optimization Genetic Algorithm (TMOGA) based on transfer learning and traditional multi-objective evolutionary algorithm framework. The main idea is to extract stable features from past community structures, retain valuable feature information, and integrate this feature information into current optimization processes to improve the evolutionary algorithms. Additionally, a new theoretical framework is proposed in this paper to analyze community detection problem based on information theory. Then, we exploit this framework to prove the rationality of TMOGA. Finally, the experimental results show that our algorithm can achieve better clustering effects compared with the state-of-the-art dynamic network community detection algorithms in diverse test problems.
Towards Automatic Clustering Analysis using Traces of Information Gain: The InfoGuide Method
Jan 23, 2020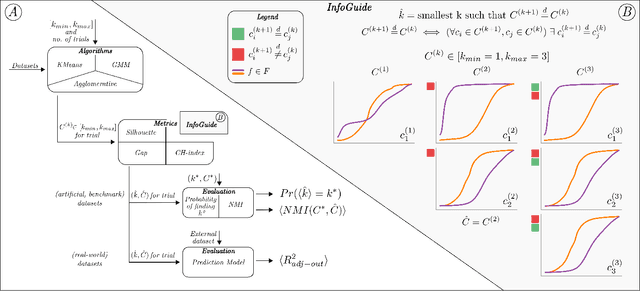
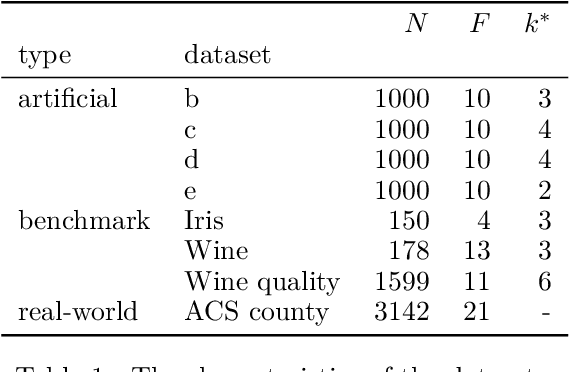
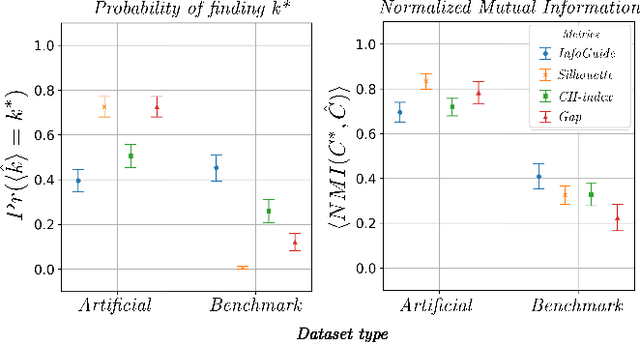
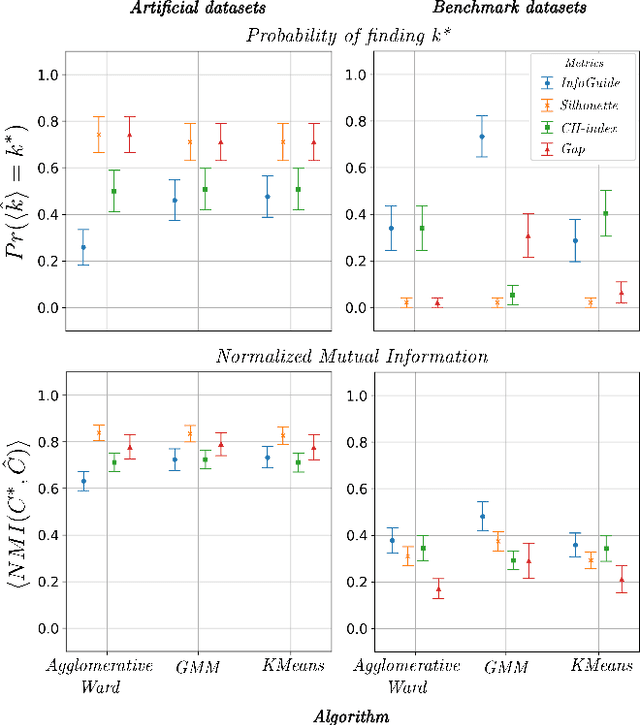
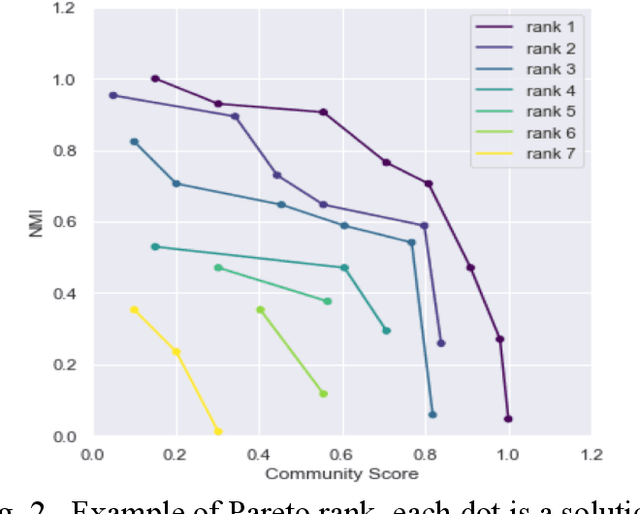
Clustering analysis has become a ubiquitous information retrieval tool in a wide range of domains, but a more automatic framework is still lacking. Though internal metrics are the key players towards a successful retrieval of clusters, their effectiveness on real-world datasets remains not fully understood, mainly because of their unrealistic assumptions underlying datasets. We hypothesized that capturing {\it traces of information gain} between increasingly complex clustering retrievals---{\it InfoGuide}---enables an automatic clustering analysis with improved clustering retrievals. We validated the {\it InfoGuide} hypothesis by capturing the traces of information gain using the Kolmogorov-Smirnov statistic and comparing the clusters retrieved by {\it InfoGuide} against those retrieved by other commonly used internal metrics in artificially-generated, benchmarks, and real-world datasets. Our results suggested that {\it InfoGuide} can enable a more automatic clustering analysis and may be more suitable for retrieving clusters in real-world datasets displaying nontrivial statistical properties.
AutoTransfer: Subject Transfer Learning with Censored Representations on Biosignals Data
Dec 17, 2021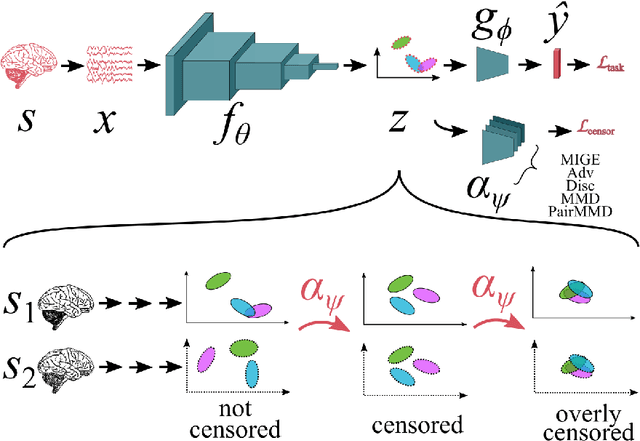
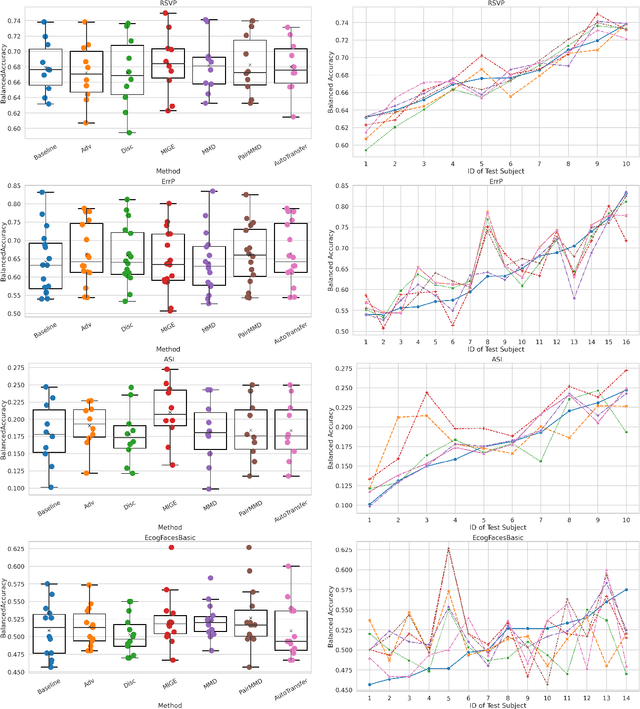


We provide a regularization framework for subject transfer learning in which we seek to train an encoder and classifier to minimize classification loss, subject to a penalty measuring independence between the latent representation and the subject label. We introduce three notions of independence and corresponding penalty terms using mutual information or divergence as a proxy for independence. For each penalty term, we provide several concrete estimation algorithms, using analytic methods as well as neural critic functions. We provide a hands-off strategy for applying this diverse family of regularization algorithms to a new dataset, which we call "AutoTransfer". We evaluate the performance of these individual regularization strategies and our AutoTransfer method on EEG, EMG, and ECoG datasets, showing that these approaches can improve subject transfer learning for challenging real-world datasets.
PrognoseNet: A Generative Probabilistic Framework for Multimodal Position Prediction given Context Information
Oct 02, 2020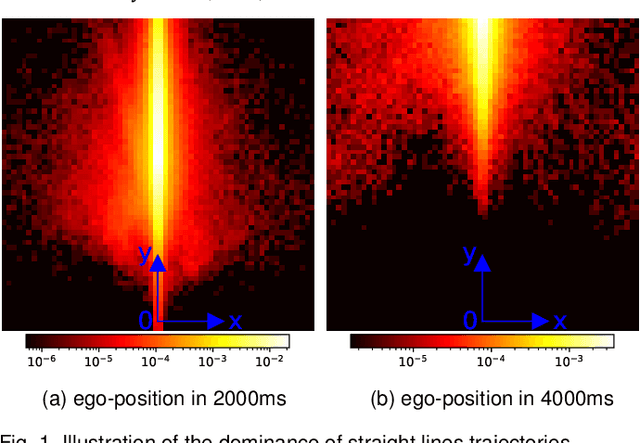
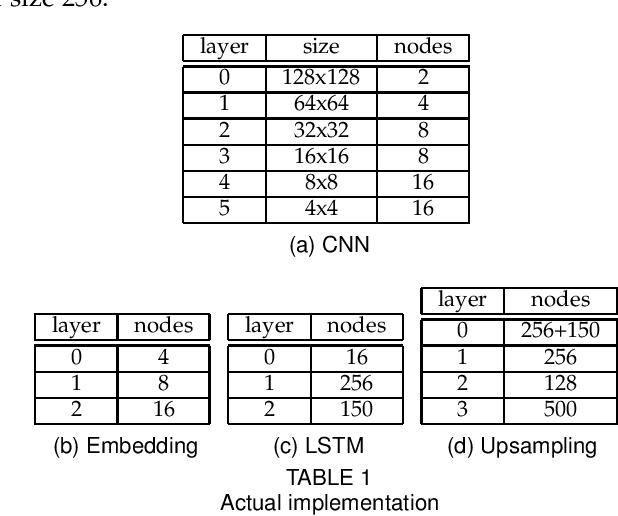

The ability to predict multiple possible future positions of the ego-vehicle given the surrounding context while also estimating their probabilities is key to safe autonomous driving. Most of the current state-of-the-art Deep Learning approaches are trained on trajectory data to achieve this task. However trajectory data captured by sensor systems is highly imbalanced, since by far most of the trajectories follow straight lines with an approximately constant velocity. This poses a huge challenge for the task of predicting future positions, which is inherently a regression problem. Current state-of-the-art approaches alleviate this problem only by major preprocessing of the training data, e.g. resampling, clustering into anchors etc. In this paper we propose an approach which reformulates the prediction problem as a classification task, allowing for powerful tools, e.g. focal loss, to combat the imbalance. To this end we design a generative probabilistic model consisting of a deep neural network with a Mixture of Gaussian head. A smart choice of the latent variable allows for the reformulation of the log-likelihood function as a combination of a classification problem and a much simplified regression problem. The output of our model is an estimate of the probability density function of future positions, hence allowing for prediction of multiple possible positions while also estimating their probabilities. The proposed approach can easily incorporate context information and does not require any preprocessing of the data.
Learning Deep Semantic Model for Code Search using CodeSearchNet Corpus
Jan 27, 2022Semantic code search is the task of retrieving relevant code snippet given a natural language query. Different from typical information retrieval tasks, code search requires to bridge the semantic gap between the programming language and natural language, for better describing intrinsic concepts and semantics. Recently, deep neural network for code search has been a hot research topic. Typical methods for neural code search first represent the code snippet and query text as separate embeddings, and then use vector distance (e.g. dot-product or cosine) to calculate the semantic similarity between them. There exist many different ways for aggregating the variable length of code or query tokens into a learnable embedding, including bi-encoder, cross-encoder, and poly-encoder. The goal of the query encoder and code encoder is to produce embeddings that are close with each other for a related pair of query and the corresponding desired code snippet, in which the choice and design of encoder is very significant. In this paper, we propose a novel deep semantic model which makes use of the utilities of not only the multi-modal sources, but also feature extractors such as self-attention, the aggregated vectors, combination of the intermediate representations. We apply the proposed model to tackle the CodeSearchNet challenge about semantic code search. We align cross-lingual embedding for multi-modality learning with large batches and hard example mining, and combine different learned representations for better enhancing the representation learning. Our model is trained on CodeSearchNet corpus and evaluated on the held-out data, the final model achieves 0.384 NDCG and won the first place in this benchmark. Models and code are available at https://github.com/overwindows/SemanticCodeSearch.git.
Optimal and Myopic Information Acquisition
May 14, 2018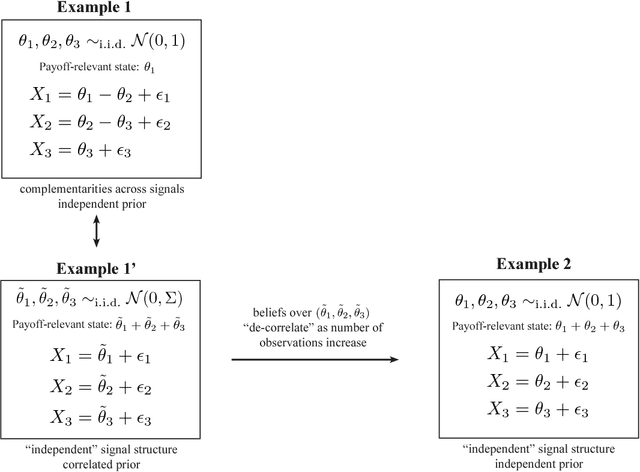

We consider the problem of optimal dynamic information acquisition from many correlated information sources. Each period, the decision-maker jointly takes an action and allocates a fixed number of observations across the available sources. His payoff depends on the actions taken and on an unknown state. In the canonical setting of jointly normal information sources, we show that the optimal dynamic information acquisition rule proceeds myopically after finitely many periods. If signals are acquired in large blocks each period, then the optimal rule turns out to be myopic from period 1. These results demonstrate the possibility of robust and "simple" optimal information acquisition, and simplify the analysis of dynamic information acquisition in a widely used informational environment.
Enhanced Performance of Pre-Trained Networks by Matched Augmentation Distributions
Jan 19, 2022
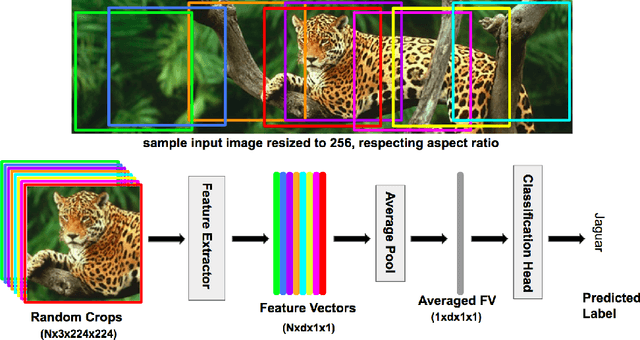
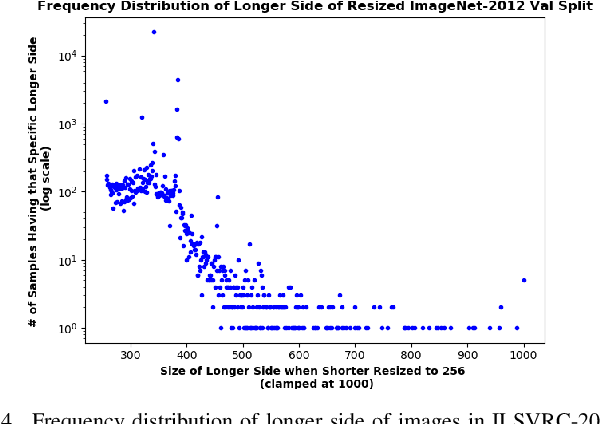
There exists a distribution discrepancy between training and testing, in the way images are fed to modern CNNs. Recent work tried to bridge this gap either by fine-tuning or re-training the network at different resolutions. However re-training a network is rarely cheap and not always viable. To this end, we propose a simple solution to address the train-test distributional shift and enhance the performance of pre-trained models -- which commonly ship as a package with deep learning platforms \eg, PyTorch. Specifically, we demonstrate that running inference on the center crop of an image is not always the best as important discriminatory information may be cropped-off. Instead we propose to combine results for multiple random crops for a test image. This not only matches the train time augmentation but also provides the full coverage of the input image. We explore combining representation of random crops through averaging at different levels \ie, deep feature level, logit level, and softmax level. We demonstrate that, for various families of modern deep networks, such averaging results in better validation accuracy compared to using a single central crop per image. The softmax averaging results in the best performance for various pre-trained networks without requiring any re-training or fine-tuning whatsoever. On modern GPUs with batch processing, the paper's approach to inference of pre-trained networks, is essentially free as all images in a batch can all be processed at once.
Block Modeling-Guided Graph Convolutional Neural Networks
Dec 27, 2021
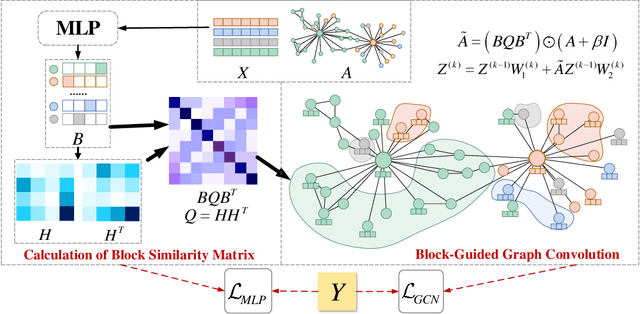
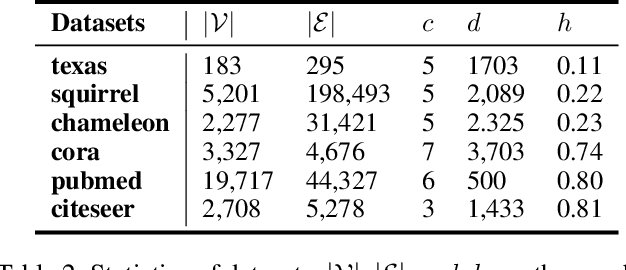
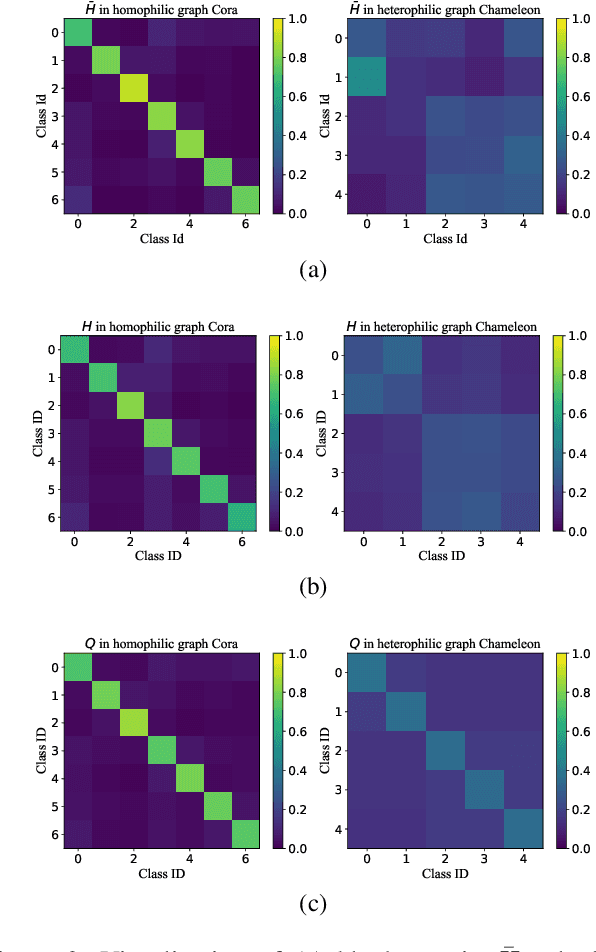
Graph Convolutional Network (GCN) has shown remarkable potential of exploring graph representation. However, the GCN aggregating mechanism fails to generalize to networks with heterophily where most nodes have neighbors from different classes, which commonly exists in real-world networks. In order to make the propagation and aggregation mechanism of GCN suitable for both homophily and heterophily (or even their mixture), we introduce block modeling into the framework of GCN so that it can realize "block-guided classified aggregation", and automatically learn the corresponding aggregation rules for neighbors of different classes. By incorporating block modeling into the aggregation process, GCN is able to aggregate information from homophilic and heterophilic neighbors discriminately according to their homophily degree. We compared our algorithm with state-of-art methods which deal with the heterophily problem. Empirical results demonstrate the superiority of our new approach over existing methods in heterophilic datasets while maintaining a competitive performance in homophilic datasets.
Unsupervised Graph Representation by Periphery and Hierarchical Information Maximization
Jun 08, 2020
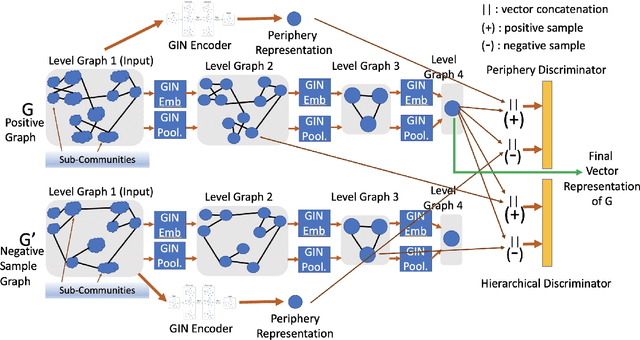
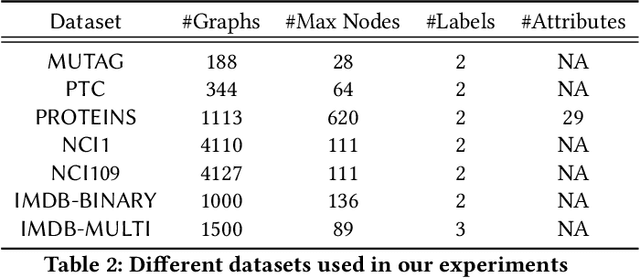
Deep representation learning on non-Euclidean data types, such as graphs, has gained significant attention in recent years. Invent of graph neural networks has improved the state-of-the-art for both node and the entire graph representation in a vector space. However, for the entire graph representation, most of the existing graph neural networks are trained on a graph classification loss in a supervised way. But obtaining labels of a large number of graphs is expensive for real world applications. Thus, we aim to propose an unsupervised graph neural network to generate a vector representation of an entire graph in this paper. For this purpose, we combine the idea of hierarchical graph neural networks and mutual information maximization into a single framework. We also propose and use the concept of periphery representation of a graph and show its usefulness in the proposed algorithm which is referred as GraPHmax. We conduct thorough experiments on several real-world graph datasets and compare the performance of GraPHmax with a diverse set of both supervised and unsupervised baseline algorithms. Experimental results show that we are able to improve the state-of-the-art for multiple graph level tasks on several real-world datasets, while remain competitive on the others.