 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ExClus: Explainable Clustering on Low-dimensional Data Representations
Nov 04, 2021
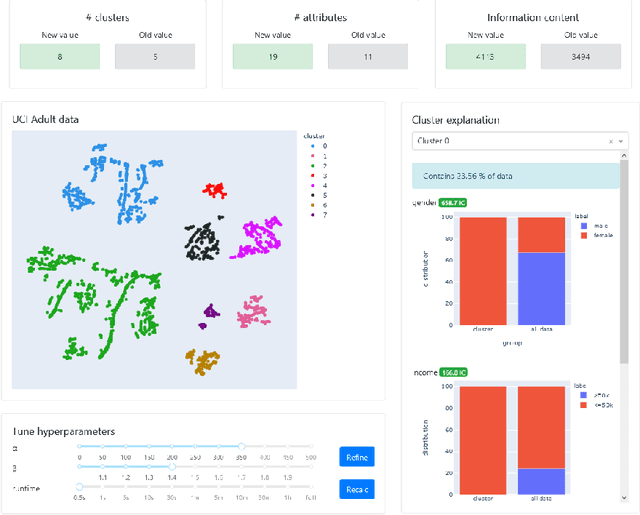
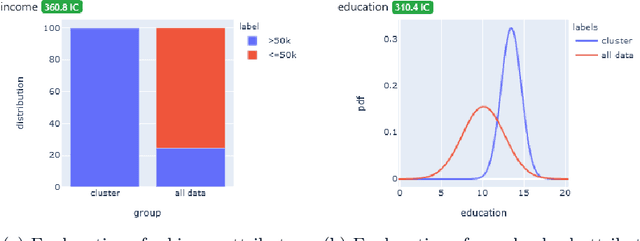
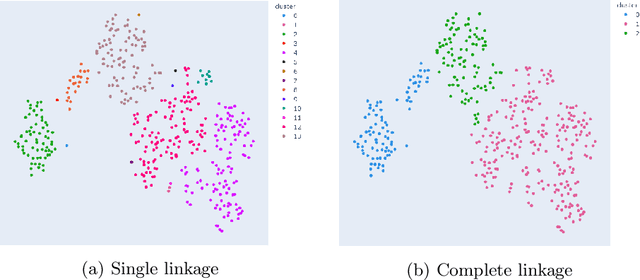
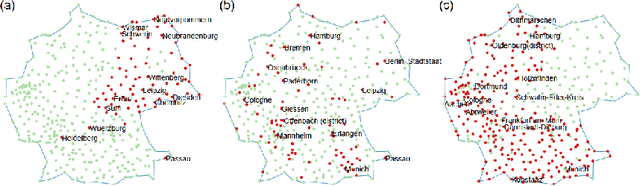
Dimensionality reduction and clustering techniques are frequently used to analyze complex data sets, but their results are often not easy to interpret. We consider how to support users in interpreting apparent cluster structure on scatter plots where the axes are not directly interpretable, such as when the data is projected onto a two-dimensional space using a dimensionality-reduction method. Specifically, we propose a new method to compute an interpretable clustering automatically, where the explanation is in the original high-dimensional space and the clustering is coherent in the low-dimensional projection. It provides a tunable balance between the complexity and the amount of information provided, through the use of information theory. We study the computational complexity of this problem and introduce restrictions on the search space of solutions to arrive at an efficient, tunable, greedy optimization algorithm. This algorithm is furthermore implemented in an interactive tool called ExClus. Experiments on several data sets highlight that ExClus can provide informative and easy-to-understand patterns, and they expose where the algorithm is efficient and where there is room for improvement considering tunability and scalability.
Time-Aware Neighbor Sampling for Temporal Graph Networks
Dec 18, 2021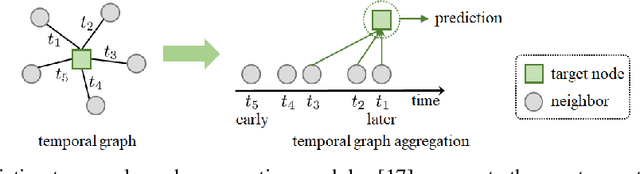


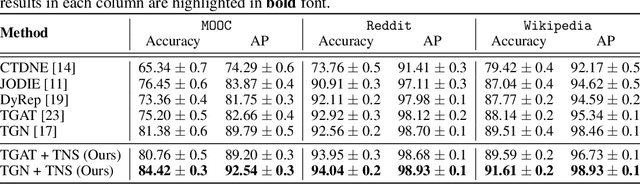
We present a new neighbor sampling method on temporal graphs. In a temporal graph, predicting different nodes' time-varying properties can require the receptive neighborhood of various temporal scales. In this work, we propose the TNS (Time-aware Neighbor Sampling) method: TNS learns from temporal information to provide an adaptive receptive neighborhood for every node at any time. Learning how to sample neighbors is non-trivial, since the neighbor indices in time order are discrete and not differentiable. To address this challenge, we transform neighbor indices from discrete values to continuous ones by interpolating the neighbors' messages. TNS can be flexibly incorporated into popular temporal graph networks to improve their effectiveness without increasing their time complexity. TNS can be trained in an end-to-end manner. It needs no extra supervision and is automatically and implicitly guided to sample the neighbors that are most beneficial for prediction. Empirical results on multiple standard datasets show that TNS yields significant gains on edge prediction and node classification.
TYolov5: A Temporal Yolov5 Detector Based on Quasi-Recurrent Neural Networks for Real-Time Handgun Detection in Video
Nov 19, 2021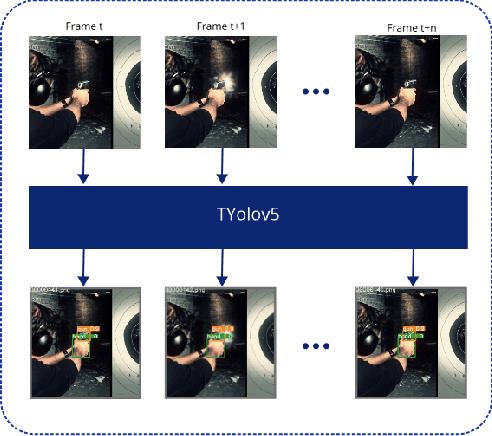
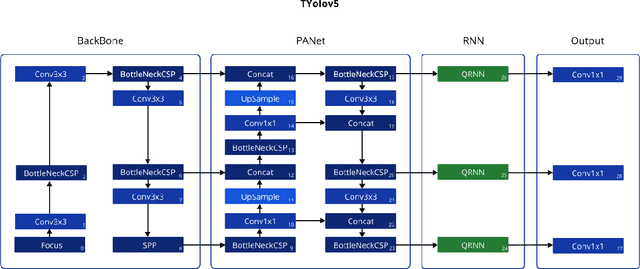
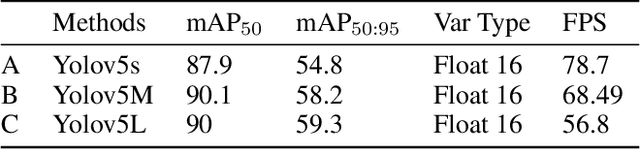
Timely handgun detection is a crucial problem to improve public safety; nevertheless, the effectiveness of many surveillance systems still depends of finite human attention. Much of the previous research on handgun detection is based on static image detectors, leaving aside valuable temporal information that could be used to improve object detection in videos. To improve the performance of surveillance systems, a real-time temporal handgun detection system should be built. Using Temporal Yolov5, an architecture based on Quasi-Recurrent Neural Networks, temporal information is extracted from video to improve the results of handgun detection. Moreover, two publicly available datasets are proposed, labeled with hands, guns, and phones. One containing 2199 static images to train static detectors, and another with 5960 frames of videos to train temporal modules. Additionally, we explore two temporal data augmentation techniques based on Mosaic and Mixup. The resulting systems are three temporal architectures: one focused in reducing inference with a mAP$_{50:95}$ of 55.9, another in having a good balance between inference and accuracy with a mAP$_{50:95}$ of 59, and a last one specialized in accuracy with a mAP$_{50:95}$ of 60.2. Temporal Yolov5 achieves real-time detection in the small and medium architectures. Moreover, it takes advantage of temporal features contained in videos to perform better than Yolov5 in our temporal dataset, making TYolov5 suitable for real-world applications. The source code is publicly available at https://github.com/MarioDuran/TYolov5.
AIS: A nonlinear activation function for industrial safety engineering
Nov 27, 2021
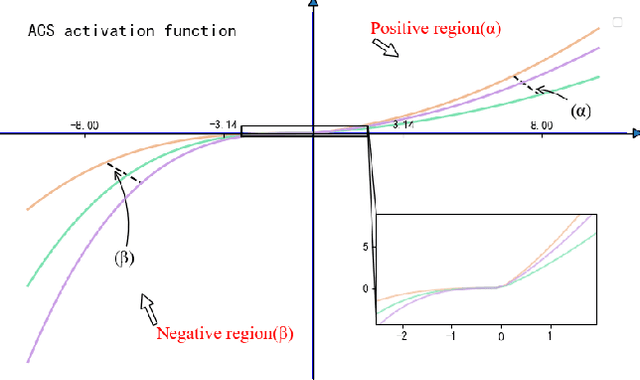
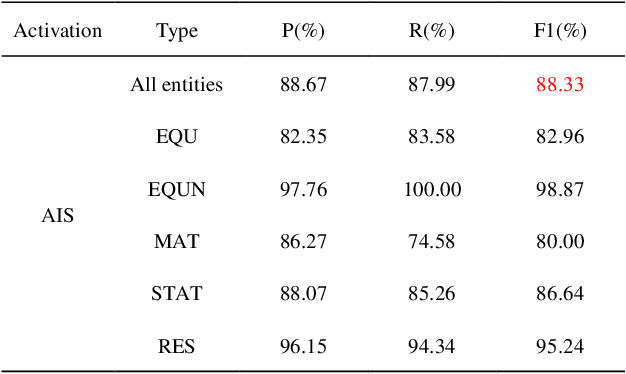
In the task of Chinese named entity recognition based on deep learning, activation function plays an irreplaceable role, it introduces nonlinear characteristics into neural network, so that the fitted model can be applied to various tasks. However, the information density of industrial safety analysis text is relatively high, and the correlation and similarity between the information are large, which is easy to cause the problem of high deviation and high standard deviation of the model, no specific activation function has been designed in previous studies, and the traditional activation function has the problems of gradient vanishing and negative region, which also lead to the recognition accuracy of the model can not be further improved. To solve these problems, a novel activation function AIS is proposed in this paper. AIS is an activation function applied in industrial safety engineering, which is composed of two piecewise nonlinear functions. In the positive region, the structure combining exponential function and quadratic function is used to alleviate the problem of deviation and standard deviation, and the linear function is added to modify it, which makes the whole activation function smoother and overcomes the problem of gradient vanishing. In the negative region, the cubic function structure is used to solve the negative region problem and accelerate the convergence of the model. Based on the deep learning model of BERT-BiLSTM-CRF, the performance of AIS is evaluated. The results show that, compared with other activation functions, AIS overcomes the problems of gradient vanishing and negative region, reduces the deviation of the model, speeds up the model fitting, and improves the extraction ability of the model for industrial entities.
Wav-BERT: Cooperative Acoustic and Linguistic Representation Learning for Low-Resource Speech Recognition
Oct 09, 2021
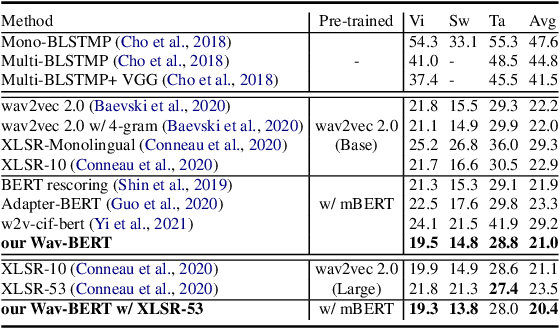
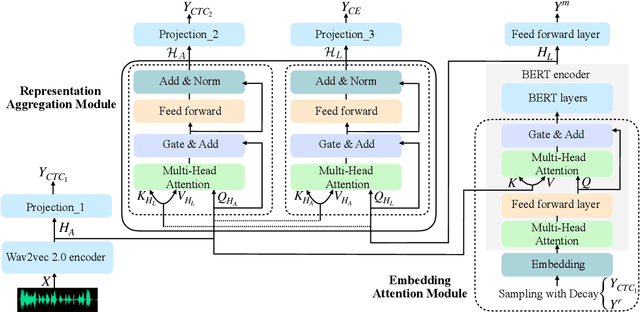
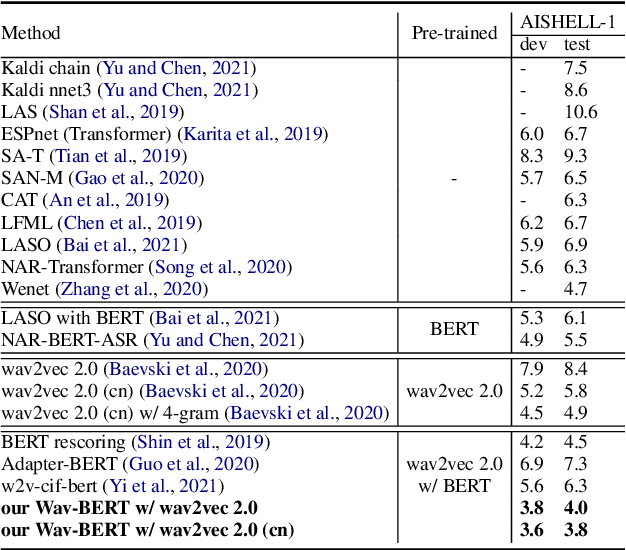
Unifying acoustic and linguistic representation learning has become increasingly crucial to transfer the knowledge learned on the abundance of high-resource language data for low-resource speech recognition. Existing approaches simply cascade pre-trained acoustic and language models to learn the transfer from speech to text. However, how to solve the representation discrepancy of speech and text is unexplored, which hinders the utilization of acoustic and linguistic information. Moreover, previous works simply replace the embedding layer of the pre-trained language model with the acoustic features, which may cause the catastrophic forgetting problem. In this work, we introduce Wav-BERT, a cooperative acoustic and linguistic representation learning method to fuse and utilize the contextual information of speech and text. Specifically, we unify a pre-trained acoustic model (wav2vec 2.0) and a language model (BERT) into an end-to-end trainable framework. A Representation Aggregation Module is designed to aggregate acoustic and linguistic representation, and an Embedding Attention Module is introduced to incorporate acoustic information into BERT, which can effectively facilitate the cooperation of two pre-trained models and thus boost the representation learning. Extensive experiments show that our Wav-BERT significantly outperforms the existing approaches and achieves state-of-the-art performance on low-resource speech recognition.
Data-Efficient Learning of High-Quality Controls for Kinodynamic Planning used in Vehicular Navigation
Jan 06, 2022
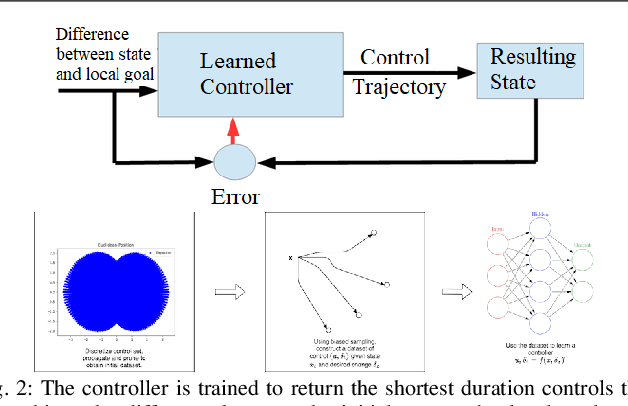
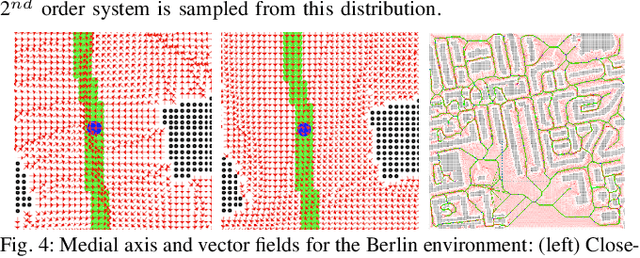
This paper aims to improve the path quality and computational efficiency of kinodynamic planners used for vehicular systems. It proposes a learning framework for identifying promising controls during the expansion process of sampling-based motion planners for systems with dynamics. Offline, the learning process is trained to return the highest-quality control that reaches a local goal state (i.e., a waypoint) in the absence of obstacles from an input difference vector between its current state and a local goal state. The data generation scheme provides bounds on the target dispersion and uses state space pruning to ensure high-quality controls. By focusing on the system's dynamics, this process is data efficient and takes place once for a dynamical system, so that it can be used for different environments with modular expansion functions. This work integrates the proposed learning process with a) an exploratory expansion function that generates waypoints with biased coverage over the reachable space, and b) proposes an exploitative expansion function for mobile robots, which generates waypoints using medial axis information. This paper evaluates the learning process and the corresponding planners for a first and second-order differential drive systems. The results show that the proposed integration of learning and planning can produce better quality paths than kinodynamic planning with random controls in fewer iterations and computation time.
* Presented at the Machine Learning for Motion Planning (MLMP) Workshop at ICRA 2021, Xi'an, China
Deep Synoptic Monte Carlo Planning in Reconnaissance Blind Chess
Oct 05, 2021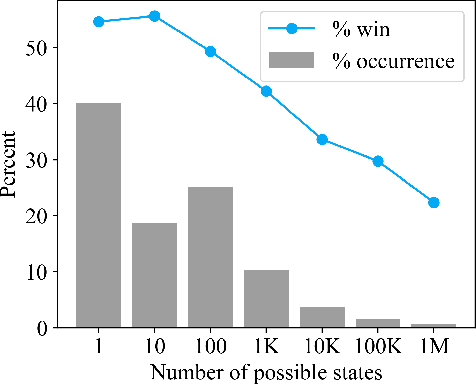
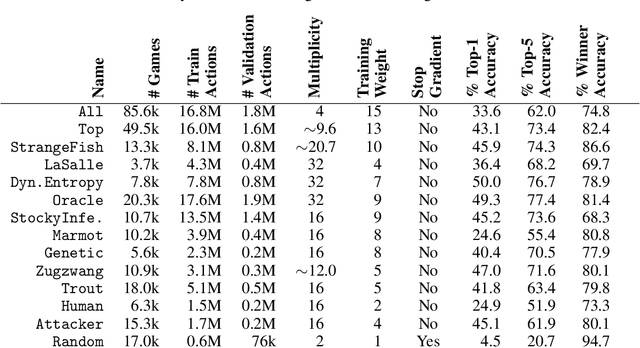
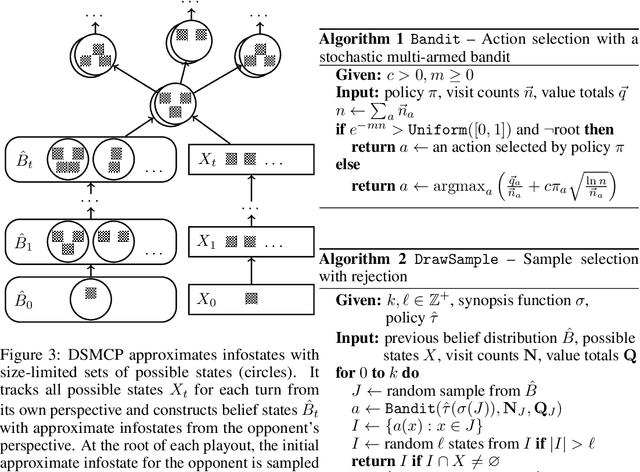
This paper introduces deep synoptic Monte Carlo planning (DSMCP) for large imperfect information games. The algorithm constructs a belief state with an unweighted particle filter and plans via playouts that start at samples drawn from the belief state. The algorithm accounts for uncertainty by performing inference on "synopses," a novel stochastic abstraction of information states. DSMCP is the basis of the program Penumbra, which won the official 2020 reconnaissance blind chess competition versus 33 other programs. This paper also evaluates algorithm variants that incorporate caution, paranoia, and a novel bandit algorithm. Furthermore, it audits the synopsis features used in Penumbra with per-bit saliency statistics.
A 3D 2D convolutional Neural Network Model for Hyperspectral Image Classification
Nov 19, 2021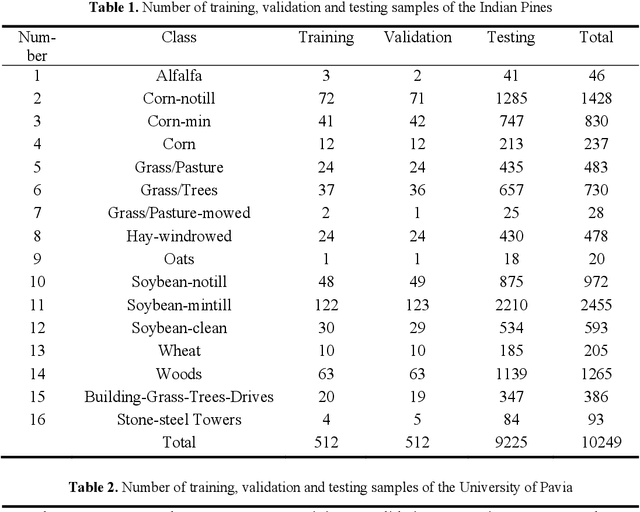
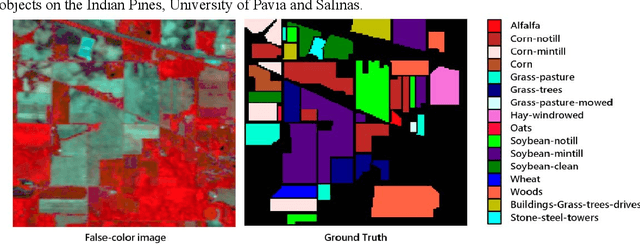
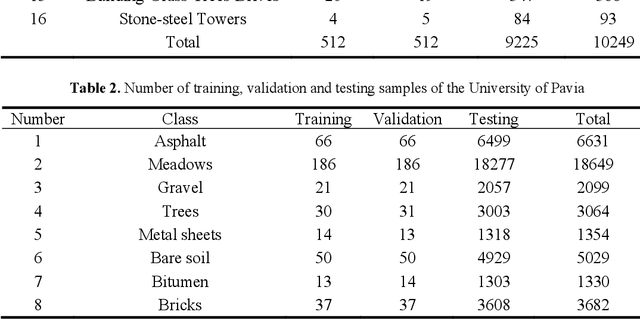
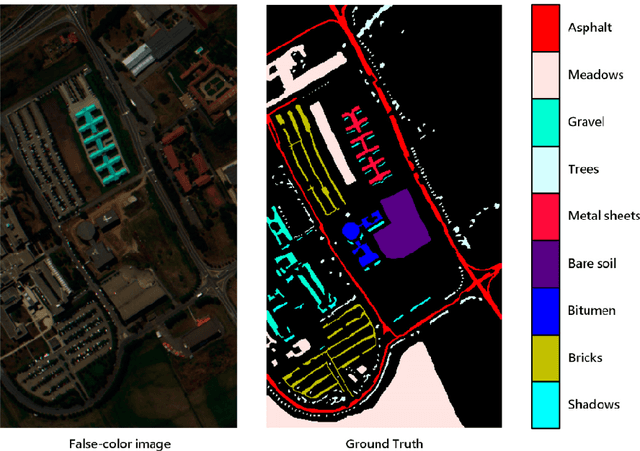
In the proposed SEHybridSN model, a dense block was used to reuse shallow feature and aimed at better exploiting hierarchical spatial spectral feature. Subsequent depth separable convolutional layers were used to discriminate the spatial information. Further refinement of spatial spectral features was realized by the channel attention method, which were performed behind every 3D convolutional layer and every 2D convolutional layer. Experiment results indicate that our proposed model learn more discriminative spatial spectral features using very few training data. SEHybridSN using only 0.05 and 0.01 labeled data for training, a very satisfactory performance is obtained.
Unsupervised Spiking Instance Segmentation on Event Data using STDP
Nov 09, 2021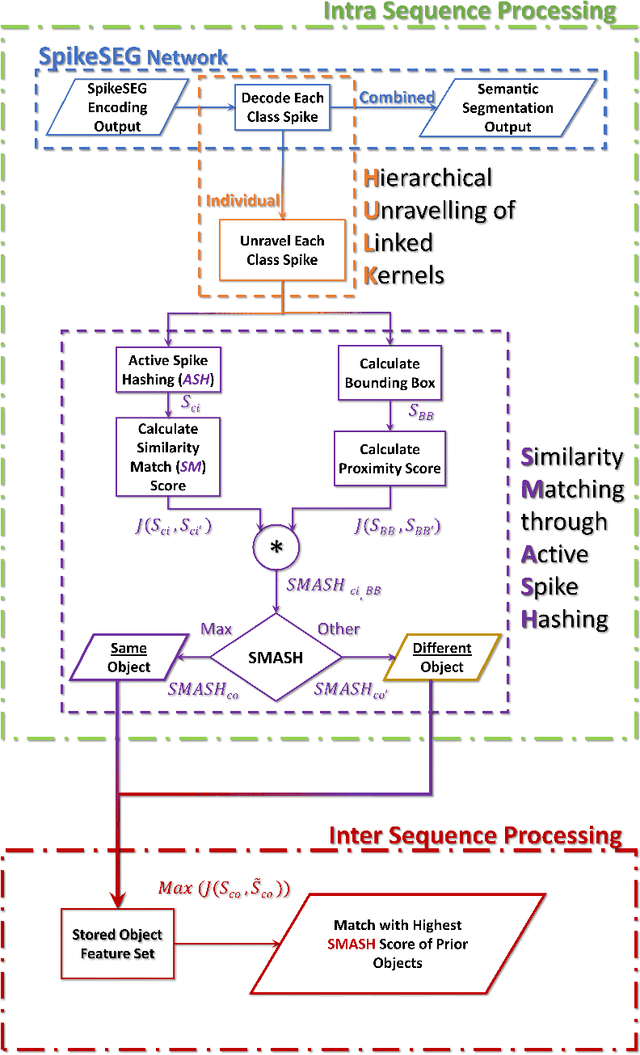
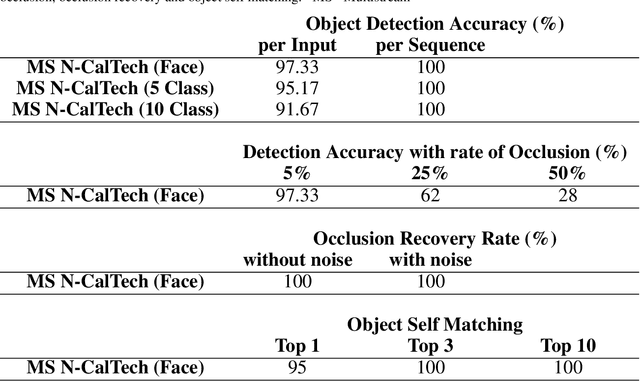
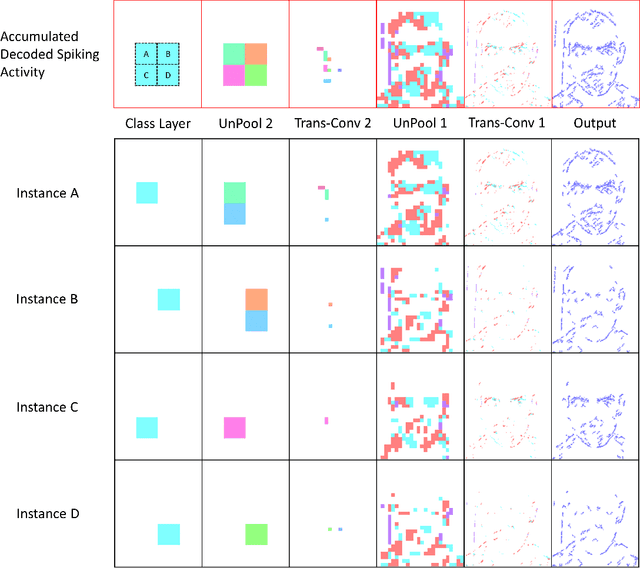
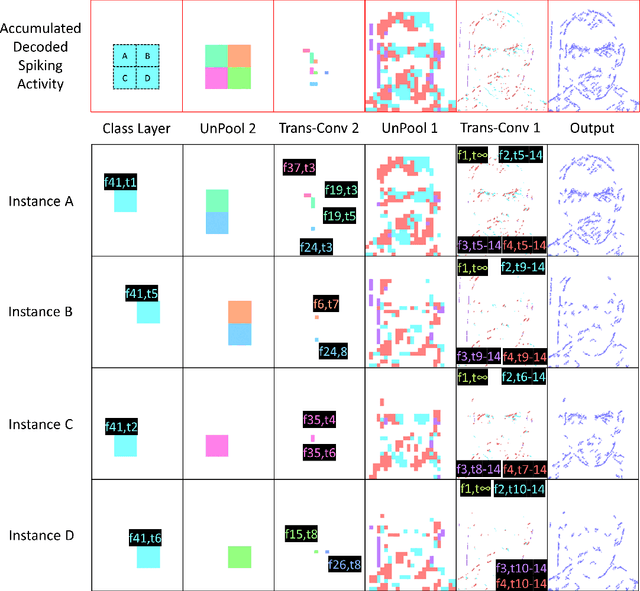
Spiking Neural Networks (SNN) and the field of Neuromorphic Engineering has brought about a paradigm shift in how to approach Machine Learning (ML) and Computer Vision (CV) problem. This paradigm shift comes from the adaption of event-based sensing and processing. An event-based vision sensor allows for sparse and asynchronous events to be produced that are dynamically related to the scene. Allowing not only the spatial information but a high-fidelity of temporal information to be captured. Meanwhile avoiding the extra overhead and redundancy of conventional high frame rate approaches. However, with this change in paradigm, many techniques from traditional CV and ML are not applicable to these event-based spatial-temporal visual streams. As such a limited number of recognition, detection and segmentation approaches exist. In this paper, we present a novel approach that can perform instance segmentation using just the weights of a Spike Time Dependent Plasticity trained Spiking Convolutional Neural Network that was trained for object recognition. This exploits the spatial and temporal aspects of the network's internal feature representations adding this new discriminative capability. We highlight the new capability by successfully transforming a single class unsupervised network for face detection into a multi-person face recognition and instance segmentation network.
Track Boosting and Synthetic Data Aided Drone Detection
Dec 01, 2021
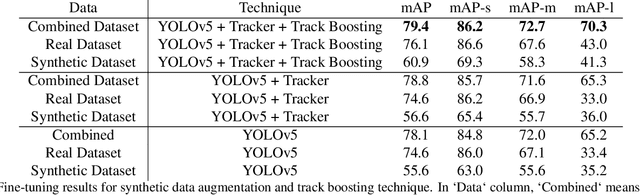

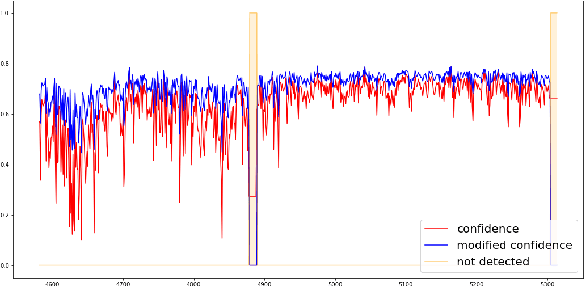
This is the paper for the first place winning solution of the Drone vs. Bird Challenge, organized by AVSS 2021. As the usage of drones increases with lowered costs and improved drone technology, drone detection emerges as a vital object detection task. However, detecting distant drones under unfavorable conditions, namely weak contrast, long-range, low visibility, requires effective algorithms. Our method approaches the drone detection problem by fine-tuning a YOLOv5 model with real and synthetically generated data using a Kalman-based object tracker to boost detection confidence. Our results indicate that augmenting the real data with an optimal subset of synthetic data can increase the performance. Moreover, temporal information gathered by object tracking methods can increase performance further.