 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The University of Texas at Dallas HLTRI's Participation in EPIC-QA: Searching for Entailed Questions Revealing Novel Answer Nuggets
Dec 28, 2021
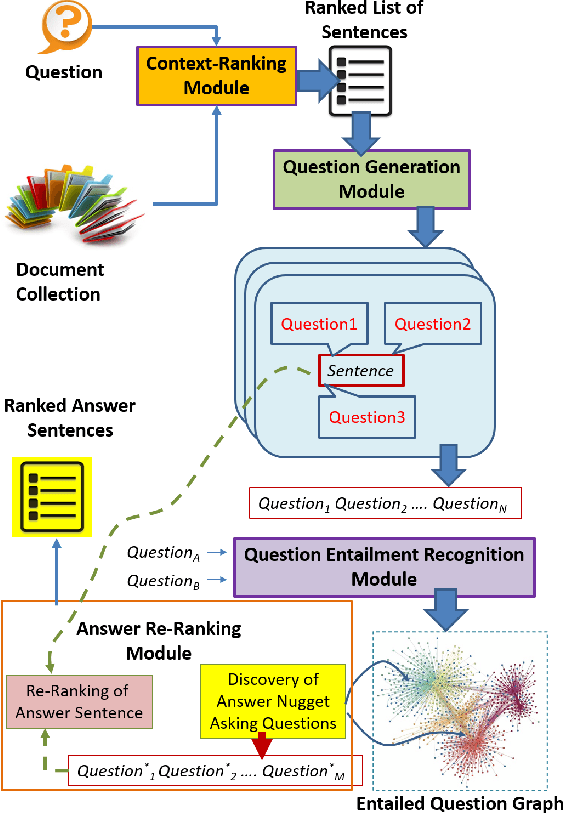
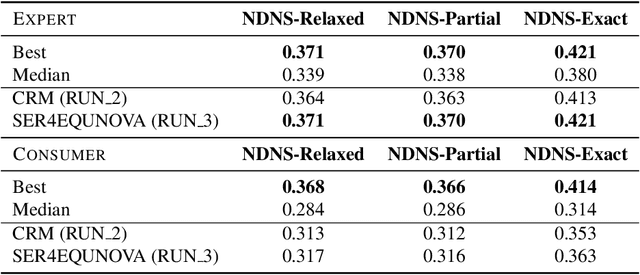
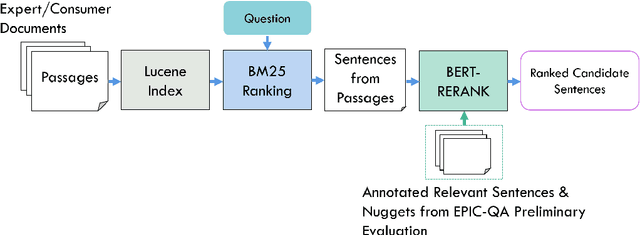

The Epidemic Question Answering (EPIC-QA) track at the Text Analysis Conference (TAC) is an evaluation of methodologies for answering ad-hoc questions about the COVID-19 disease. This paper describes our participation in both tasks of EPIC-QA, targeting: (1) Expert QA and (2) Consumer QA. Our methods used a multi-phase neural Information Retrieval (IR) system based on combining BM25, BERT, and T5 as well as the idea of considering entailment relations between the original question and questions automatically generated from answer candidate sentences. Moreover, because entailment relations were also considered between all generated questions, we were able to re-rank the answer sentences based on the number of novel answer nuggets they contained, as indicated by the processing of a question entailment graph. Our system, called SEaRching for Entailed QUestions revealing NOVel nuggets of Answers (SER4EQUNOVA), produced promising results in both EPIC-QA tasks, excelling in the Expert QA task.
Towards Optimal Correlational Object Search
Oct 19, 2021
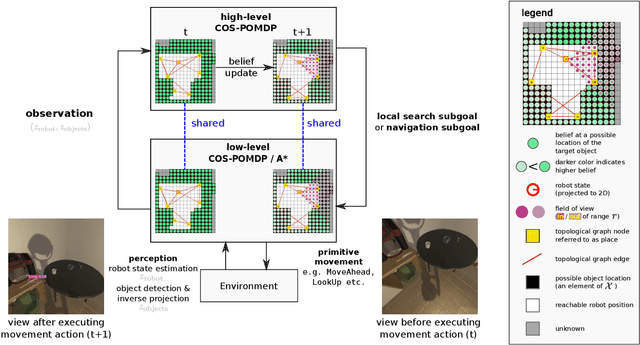


In realistic applications of object search, robots will need to locate target objects in complex environments while coping with unreliable sensors, especially for small or hard-to-detect objects. In such settings, correlational information can be valuable for planning efficiently: when looking for a fork, the robot could start by locating the easier-to-detect refrigerator, since forks would probably be found nearby. Previous approaches to object search with correlational information typically resort to ad-hoc or greedy search strategies. In this paper, we propose the Correlational Object Search POMDP (COS-POMDP), which can be solved to produce search strategies that use correlational information. COS-POMDPs contain a correlation-based observation model that allows us to avoid the exponential blow-up of maintaining a joint belief about all objects, while preserving the optimal solution to this naive, exponential POMDP formulation. We propose a hierarchical planning algorithm to scale up COS-POMDP for practical domains. We conduct experiments using AI2-THOR, a realistic simulator of household environments, as well as YOLOv5, a widely-used object detector. Our results show that, particularly for hard-to-detect objects, such as scrub brush and remote control, our method offers the most robust performance compared to baselines that ignore correlations as well as a greedy, next-best view approach.
A sinusoidal signal reconstruction method for the inversion of the mel-spectrogram
Jan 07, 2022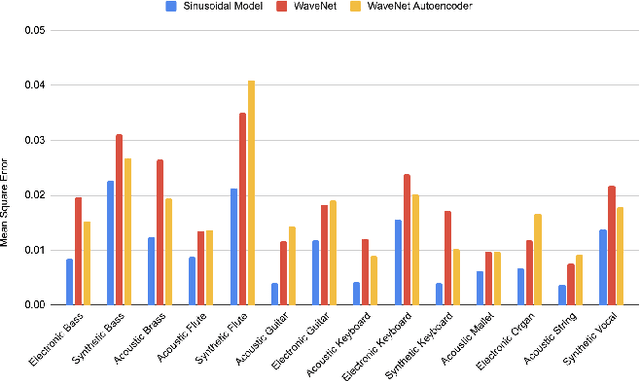
The synthesis of sound via deep learning methods has recently received much attention. Some problems for deep learning approaches to sound synthesis relate to the amount of data needed to specify an audio signal and the necessity of preserving both the long and short time coherence of the synthesised signal. Visual time-frequency representations such as the log-mel-spectrogram have gained in popularity. The log-mel-spectrogram is a perceptually informed representation of audio that greatly compresses the amount of information required for the description of the sound. However, because of this compression, this representation is not directly invertible. Both signal processing and machine learning techniques have previously been applied to the inversion of the log-mel-spectrogram but they both caused audible distortions in the synthesized sounds due to issues of temporal and spectral coherence. In this paper, we outline the application of a sinusoidal model to the inversion of the log-mel-spectrogram for pitched musical instrument sounds outperforming state-of-the-art deep learning methods. The approach could be later used as a general decoding step from spectral to time intervals in neural applications.
Deep Domain Adversarial Adaptation for Photon-efficient Imaging Based on Spatiotemporal Inception Network
Jan 07, 2022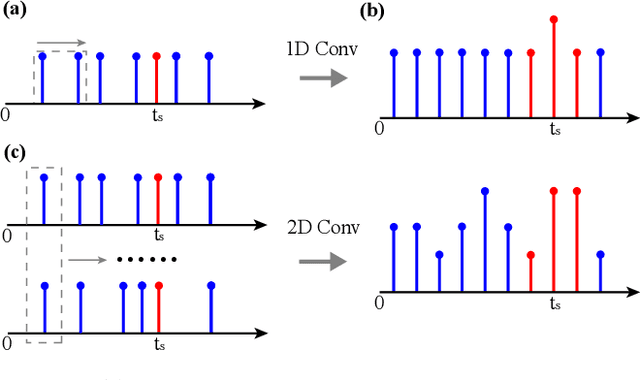
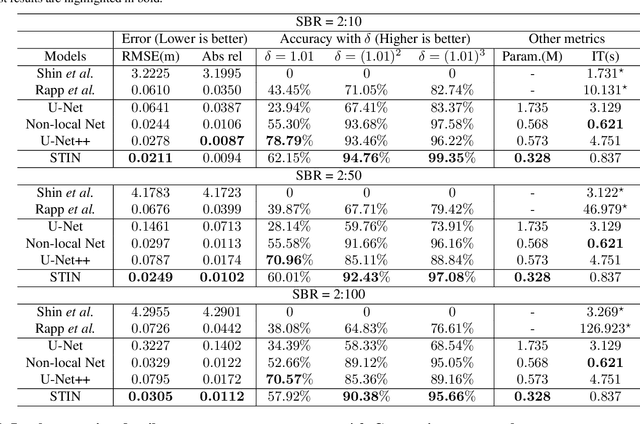
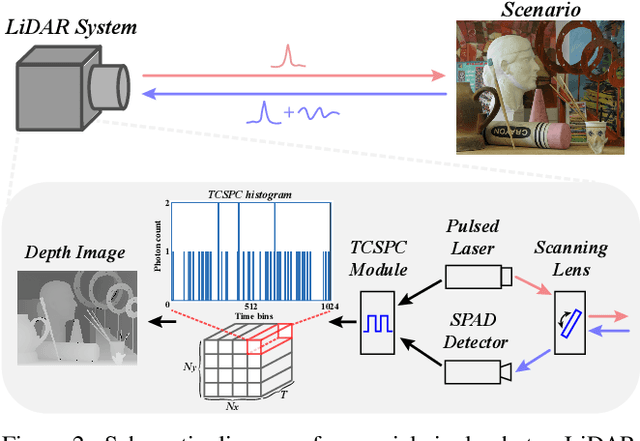
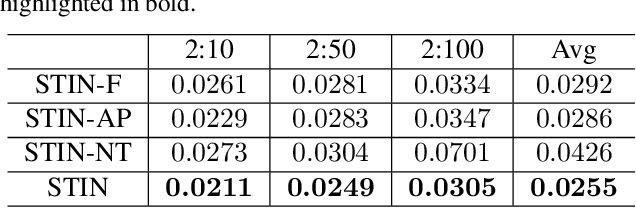
In single-photon LiDAR, photon-efficient imaging captures the 3D structure of a scene by only several detected signal photons per pixel. The existing deep learning models for this task are trained on simulated datasets, which poses the domain shift challenge when applied to realistic scenarios. In this paper, we propose a spatiotemporal inception network (STIN) for photon-efficient imaging, which is able to precisely predict the depth from a sparse and high-noise photon counting histogram by fully exploiting spatial and temporal information. Then the domain adversarial adaptation frameworks, including domain-adversarial neural network and adversarial discriminative domain adaptation, are effectively applied to STIN to alleviate the domain shift problem for realistic applications. Comprehensive experiments on the simulated data generated from the NYU~v2 and the Middlebury datasets demonstrate that STIN outperforms the state-of-the-art models at low signal-to-background ratios from 2:10 to 2:100. Moreover, experimental results on the real-world dataset captured by the single-photon imaging prototype show that the STIN with domain adversarial training achieves better generalization performance compared with the state-of-the-arts as well as the baseline STIN trained by simulated data.
Entity-Based Knowledge Conflicts in Question Answering
Sep 10, 2021

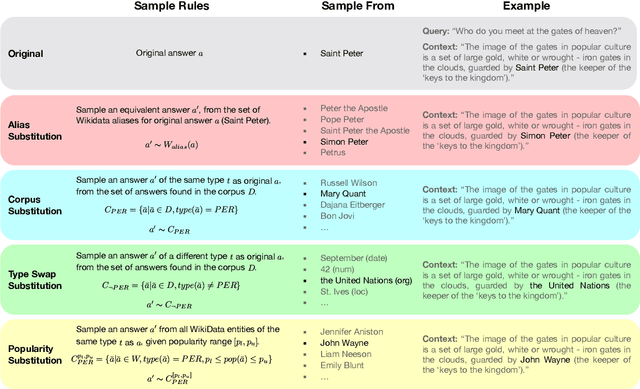
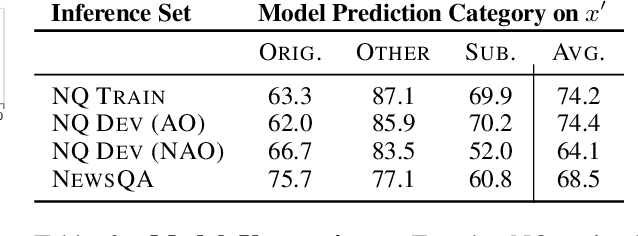
Knowledge-dependent tasks typically use two sources of knowledge: parametric, learned at training time, and contextual, given as a passage at inference time. To understand how models use these sources together, we formalize the problem of knowledge conflicts, where the contextual information contradicts the learned information. Analyzing the behaviour of popular models, we measure their over-reliance on memorized information (the cause of hallucinations), and uncover important factors that exacerbate this behaviour. Lastly, we propose a simple method to mitigate over-reliance on parametric knowledge, which minimizes hallucination, and improves out-of-distribution generalization by 4%-7%. Our findings demonstrate the importance for practitioners to evaluate model tendency to hallucinate rather than read, and show that our mitigation strategy encourages generalization to evolving information (i.e., time-dependent queries). To encourage these practices, we have released our framework for generating knowledge conflicts.
Polarimetric Pose Prediction
Dec 07, 2021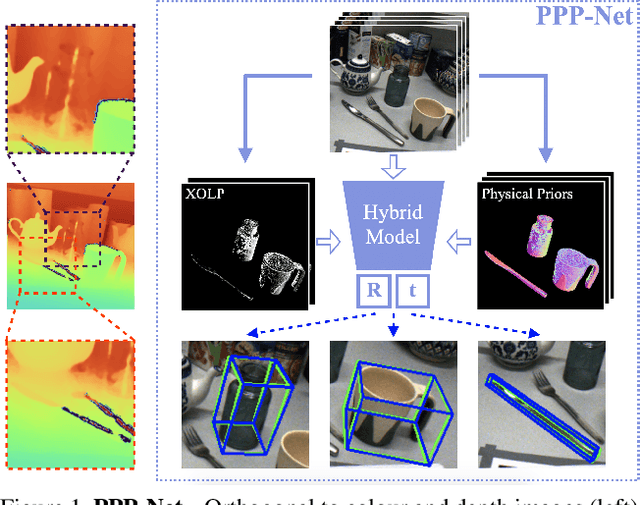
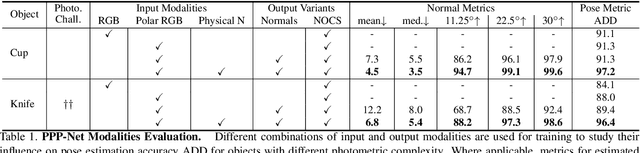
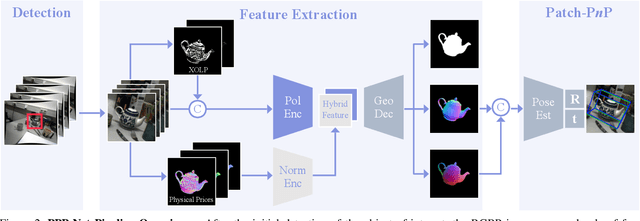
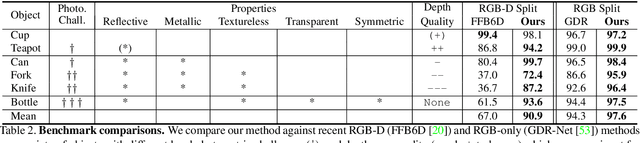
Light has many properties that can be passively measured by vision sensors. Colour-band separated wavelength and intensity are arguably the most commonly used ones for monocular 6D object pose estimation. This paper explores how complementary polarisation information, i.e. the orientation of light wave oscillations, can influence the accuracy of pose predictions. A hybrid model that leverages physical priors jointly with a data-driven learning strategy is designed and carefully tested on objects with different amount of photometric complexity. Our design not only significantly improves the pose accuracy in relation to photometric state-of-the-art approaches, but also enables object pose estimation for highly reflective and transparent objects.
Self-Supervised Predictive Convolutional Attentive Block for Anomaly Detection
Nov 19, 2021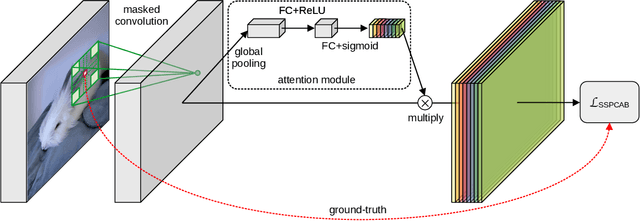
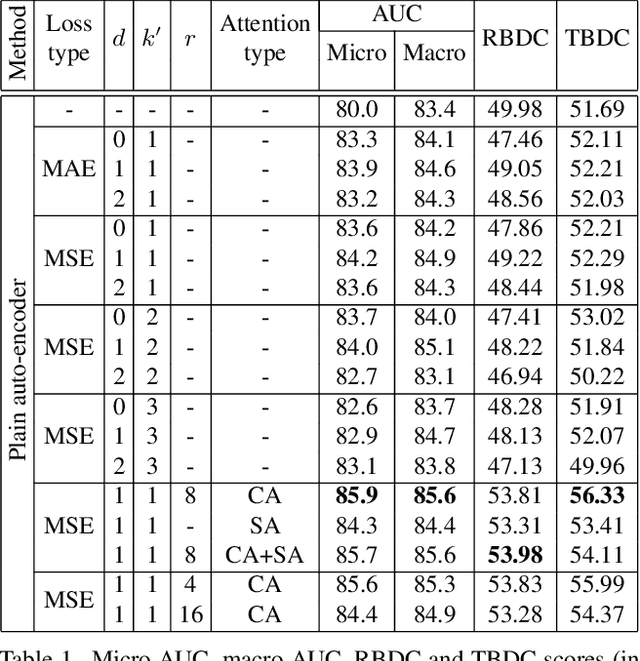
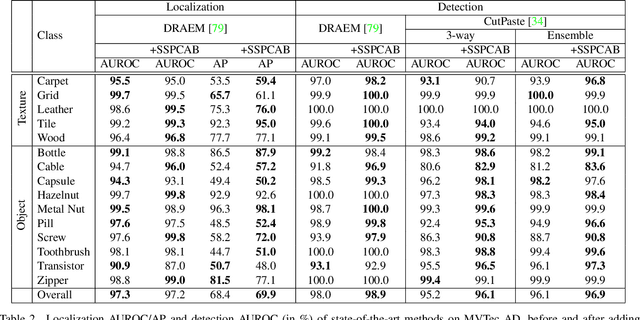
Anomaly detection is commonly pursued as a one-class classification problem, where models can only learn from normal training samples, while being evaluated on both normal and abnormal test samples. Among the successful approaches for anomaly detection, a distinguished category of methods relies on predicting masked information (e.g. patches, future frames, etc.) and leveraging the reconstruction error with respect to the masked information as an abnormality score. Different from related methods, we propose to integrate the reconstruction-based functionality into a novel self-supervised predictive architectural building block. The proposed self-supervised block is generic and can easily be incorporated into various state-of-the-art anomaly detection methods. Our block starts with a convolutional layer with dilated filters, where the center area of the receptive field is masked. The resulting activation maps are passed through a channel attention module. Our block is equipped with a loss that minimizes the reconstruction error with respect to the masked area in the receptive field. We demonstrate the generality of our block by integrating it into several state-of-the-art frameworks for anomaly detection on image and video, providing empirical evidence that shows considerable performance improvements on MVTec AD, Avenue, and ShanghaiTech.
Relative Distributed Formation and Obstacle Avoidance with Multi-agent Reinforcement Learning
Nov 14, 2021
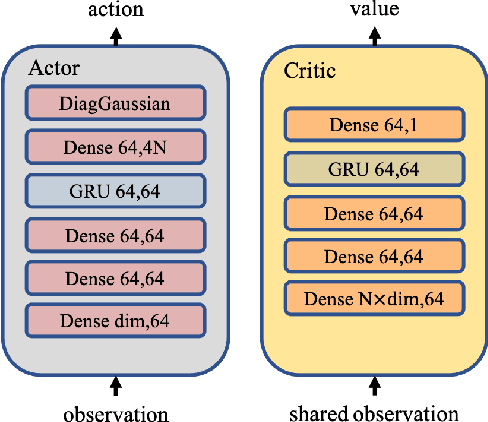

Multi-agent formation as well as obstacle avoidance is one of the most actively studied topics in the field of multi-agent systems. Although some classic controllers like model predictive control (MPC) and fuzzy control achieve a certain measure of success, most of them require precise global information which is not accessible in harsh environments. On the other hand, some reinforcement learning (RL) based approaches adopt the leader-follower structure to organize different agents' behaviors, which sacrifices the collaboration between agents thus suffering from bottlenecks in maneuverability and robustness. In this paper, we propose a distributed formation and obstacle avoidance method based on multi-agent reinforcement learning (MARL). Agents in our system only utilize local and relative information to make decisions and control themselves distributively. Agent in the multi-agent system will reorganize themselves into a new topology quickly in case that any of them is disconnected. Our method achieves better performance regarding formation error, formation convergence rate and on-par success rate of obstacle avoidance compared with baselines (both classic control methods and another RL-based method). The feasibility of our method is verified by both simulation and hardware implementation with Ackermann-steering vehicles.
Occlusion-aware Visual Tracker using Spatial Structural Information and Dominant Features
Apr 16, 2021
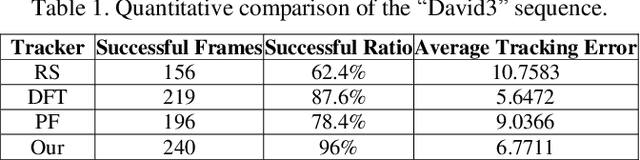

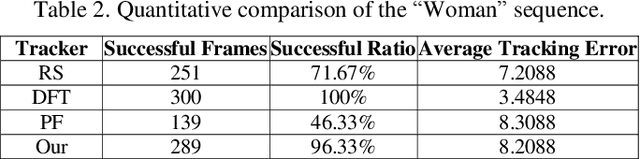
To overcome the problem of occlusion in visual tracking, this paper proposes an occlusion-aware tracking algorithm. The proposed algorithm divides the object into discrete image patches according to the pixel distribution of the object by means of clustering. To avoid the drifting of the tracker to false targets, the proposed algorithm extracts the dominant features, such as color histogram or histogram of oriented gradient orientation, from these image patches, and uses them as cues for tracking. To enhance the robustness of the tracker, the proposed algorithm employs an implicit spatial structure between these patches as another cue for tracking; Afterwards, the proposed algorithm incorporates these components into the particle filter framework, which results in a robust and precise tracker. Experimental results on color image sequences with different resolutions show that the proposed tracker outperforms the comparison algorithms on handling occlusion in visual tracking.
* 8 pages, 5 figures, Journal
Kleister: A novel task for Information Extraction involving Long Documents with Complex Layout
Mar 04, 2020
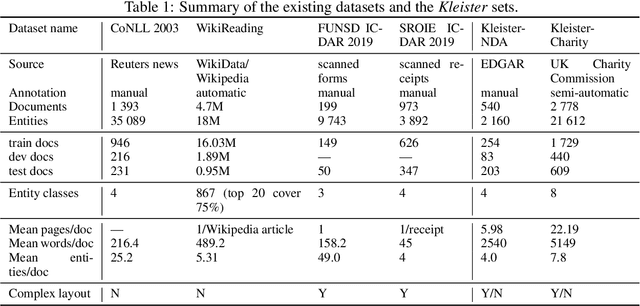

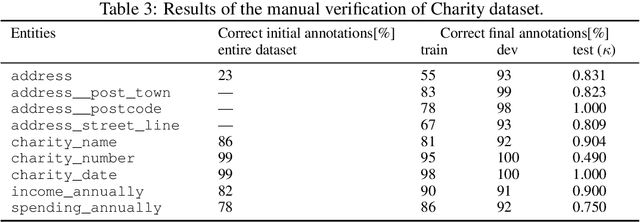
State-of-the-art solutions for Natural Language Processing (NLP) are able to capture a broad range of contexts, like the sentence level context or document level context for short documents. But these solutions are still struggling when it comes to real-world longer documents with information encoded in the spatial structure of the document, in elements like tables, forms, headers, openings or footers, or the complex layout of pages or multiple pages. To encourage progress on deeper and more complex information extraction, we present a new task (named Kleister) with two new datasets. Based on textual and structural layout features, an NLP system must find the most important information, about various types of entities, in formal long documents. These entities are not only classes from standard named entity recognition (NER) systems (e.g. location, date, or amount) but also the roles of the entities in the whole documents (e.g. company town address, report date, income amount).