 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Digital RIS (DRIS): The Future of Digital Beam Management in RIS-Assisted OWC Systems
Dec 18, 2021
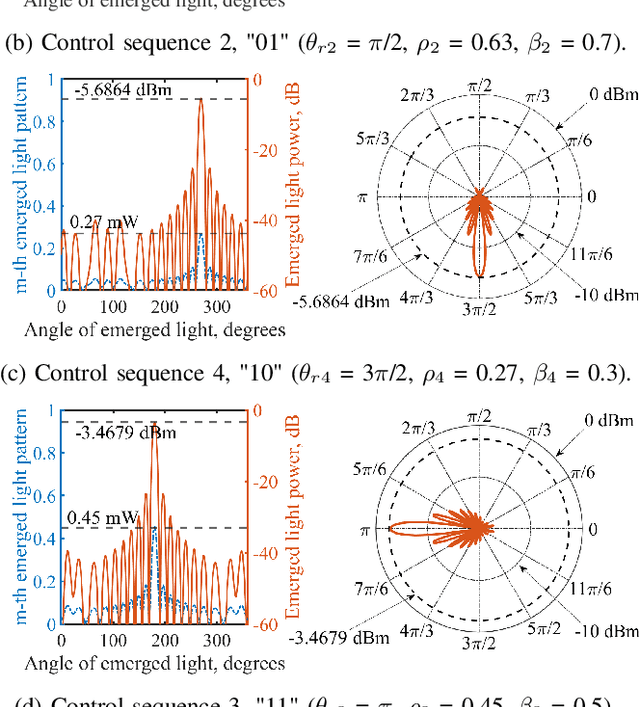
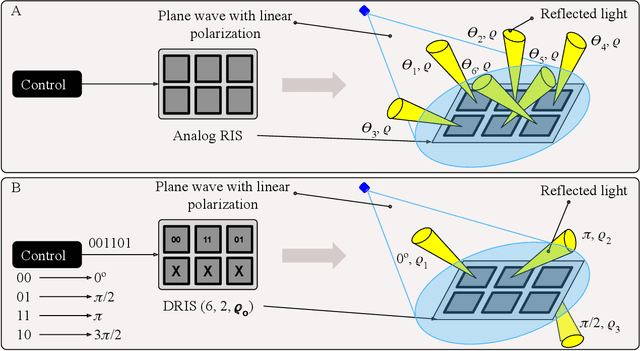
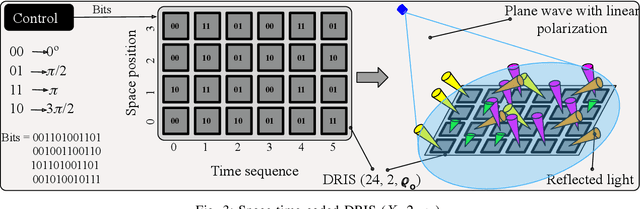
Reconfigurable intelligent surfaces (RIS) have been recently introduced to optical wireless communication (OWC) networks to resolve skip areas and improve the signal-to-noise ratio at the user's end. In OWC networks, RIS are based on mirrors or metasurfaces. Metasurfaces have evolved significantly over the last few years. As a result, coding, digital, programmable, and information metamaterials have been developed. The advantage of these materials is that they can enable digital signal processing (DSP) techniques. For the first time, this paper proposes the use of digital RIS (DRIS) in OWC systems. We discuss the concept of DRIS and the application of DSP methods to the physical material. In addition, we examine metamaterials for optical DRIS with liquid crystals serving as the front row material. Finally, we present a design example and discuss future research directions.
A Vision-based Irregular Obstacle Avoidance Framework via Deep Reinforcement Learning
Aug 23, 2021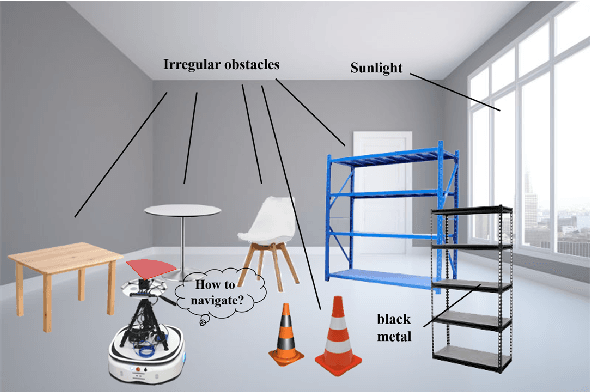
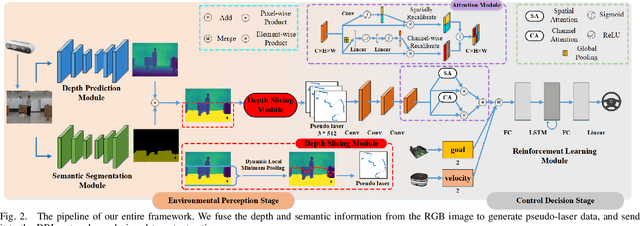

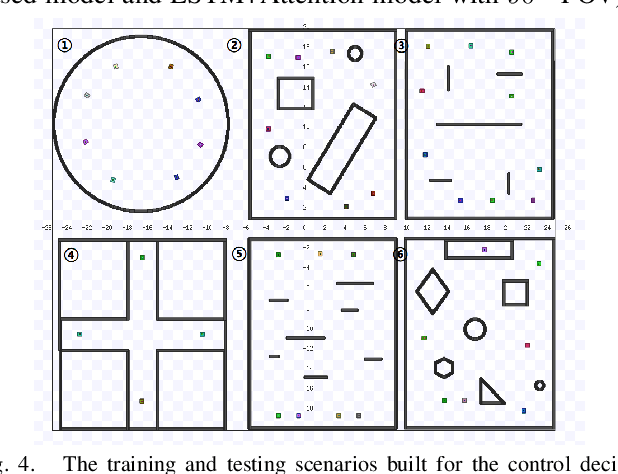
Deep reinforcement learning has achieved great success in laser-based collision avoidance work because the laser can sense accurate depth information without too much redundant data, which can maintain the robustness of the algorithm when it is migrated from the simulation environment to the real world. However, high-cost laser devices are not only difficult to apply on a large scale but also have poor robustness to irregular objects, e.g., tables, chairs, shelves, etc. In this paper, we propose a vision-based collision avoidance framework to solve the challenging problem. Our method attempts to estimate the depth and incorporate the semantic information from RGB data to obtain a new form of data, pseudo-laser data, which combines the advantages of visual information and laser information. Compared to traditional laser data that only contains the one-dimensional distance information captured at a certain height, our proposed pseudo-laser data encodes the depth information and semantic information within the image, which makes our method more effective for irregular obstacles. Besides, we adaptively add noise to the laser data during the training stage to increase the robustness of our model in the real world, due to the estimated depth information is not accurate. Experimental results show that our framework achieves state-of-the-art performance in several unseen virtual and real-world scenarios.
Quantifying Uncertainty in Deep Learning Approaches to Radio Galaxy Classification
Jan 24, 2022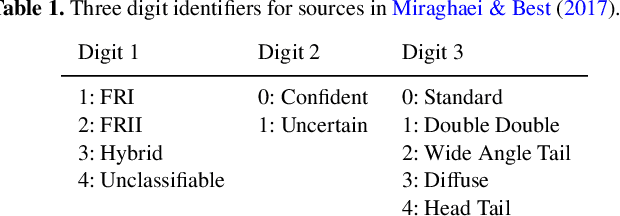
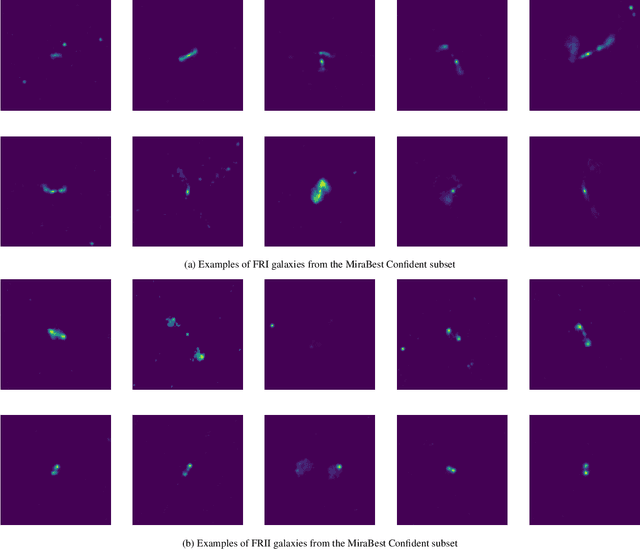
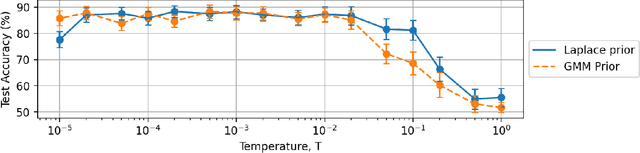
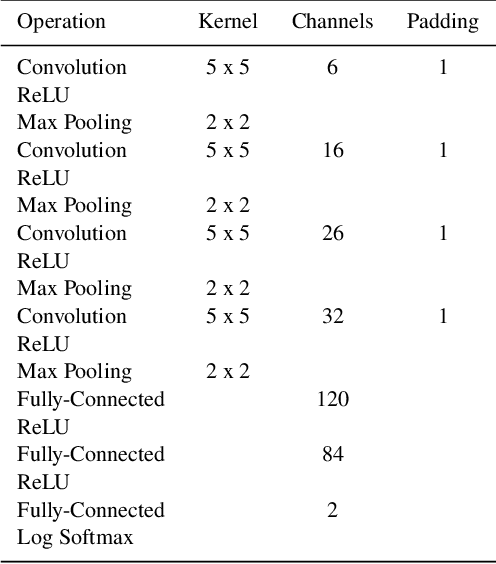
In this work we use variational inference to quantify the degree of uncertainty in deep learning model predictions of radio galaxy classification. We show that the level of model posterior variance for individual test samples is correlated with human uncertainty when labelling radio galaxies. We explore the model performance and uncertainty calibration for different weight priors and suggest that a sparse prior produces more well-calibrated uncertainty estimates. Using the posterior distributions for individual weights, we demonstrate that we can prune 30% of the fully-connected layer weights without significant loss of performance by removing the weights with the lowest signal-to-noise ratio. A larger degree of pruning can be achieved using a Fisher information based ranking, but both pruning methods affect the uncertainty calibration for Fanaroff-Riley type I and type II radio galaxies differently. Like other work in this field, we experience a cold posterior effect, whereby the posterior must be down-weighted to achieve good predictive performance. We examine whether adapting the cost function to accommodate model misspecification can compensate for this effect, but find that it does not make a significant difference. We also examine the effect of principled data augmentation and find that this improves upon the baseline but also does not compensate for the observed effect. We interpret this as the cold posterior effect being due to the overly effective curation of our training sample leading to likelihood misspecification, and raise this as a potential issue for Bayesian deep learning approaches to radio galaxy classification in future.
EPNet++: Cascade Bi-directional Fusion for Multi-Modal 3D Object Detection
Jan 12, 2022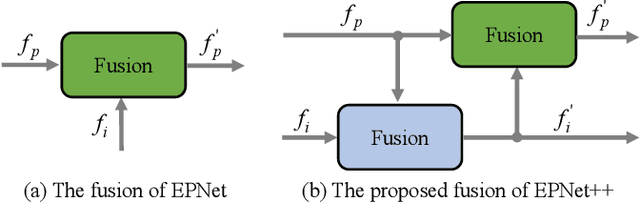
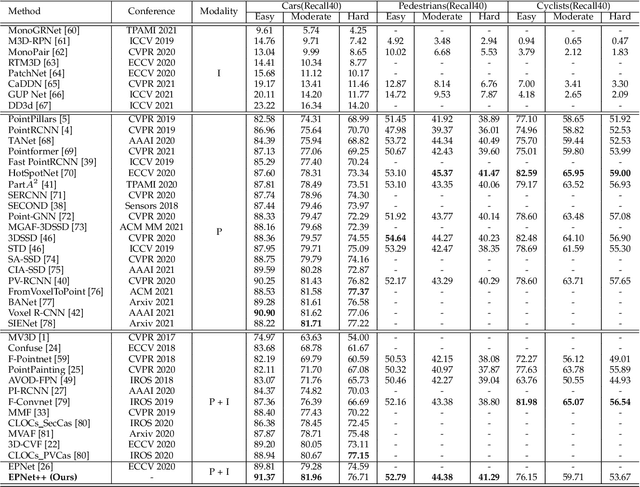
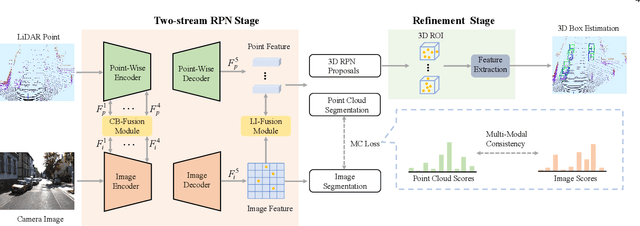
Recently, fusing the LiDAR point cloud and camera image to improve the performance and robustness of 3D object detection has received more and more attention, as these two modalities naturally possess strong complementarity. In this paper, we propose EPNet++ for multi-modal 3D object detection by introducing a novel Cascade Bi-directional Fusion~(CB-Fusion) module and a Multi-Modal Consistency~(MC) loss. More concretely, the proposed CB-Fusion module boosts the plentiful semantic information of point features with the image features in a cascade bi-directional interaction fusion manner, leading to more comprehensive and discriminative feature representations. The MC loss explicitly guarantees the consistency between predicted scores from two modalities to obtain more comprehensive and reliable confidence scores. The experiment results on the KITTI, JRDB and SUN-RGBD datasets demonstrate the superiority of EPNet++ over the state-of-the-art methods. Besides, we emphasize a critical but easily overlooked problem, which is to explore the performance and robustness of a 3D detector in a sparser scene. Extensive experiments present that EPNet++ outperforms the existing SOTA methods with remarkable margins in highly sparse point cloud cases, which might be an available direction to reduce the expensive cost of LiDAR sensors. Code will be released in the future.
Improving Dietary Assessment Via Integrated Hierarchy Food Classification
Sep 06, 2021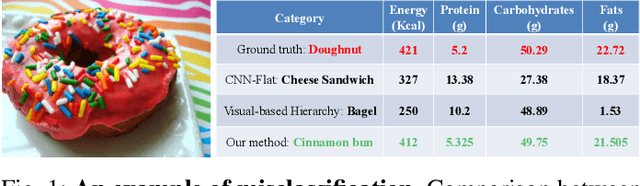
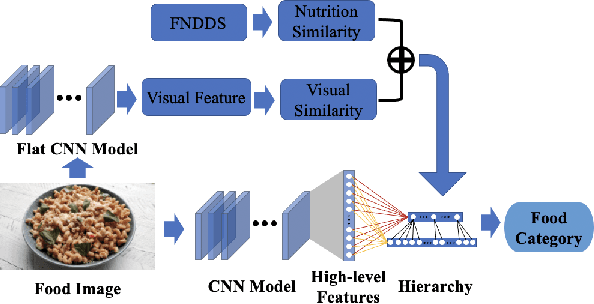
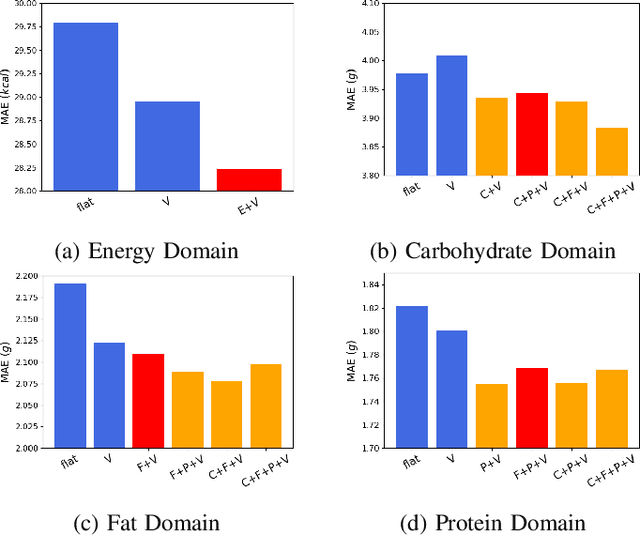

Image-based dietary assessment refers to the process of determining what someone eats and how much energy and nutrients are consumed from visual data. Food classification is the first and most crucial step. Existing methods focus on improving accuracy measured by the rate of correct classification based on visual information alone, which is very challenging due to the high complexity and inter-class similarity of foods. Further, accuracy in food classification is conceptual as description of a food can always be improved. In this work, we introduce a new food classification framework to improve the quality of predictions by integrating the information from multiple domains while maintaining the classification accuracy. We apply a multi-task network based on a hierarchical structure that uses both visual and nutrition domain specific information to cluster similar foods. Our method is validated on the modified VIPER-FoodNet (VFN) food image dataset by including associated energy and nutrient information. We achieve comparable classification accuracy with existing methods that use visual information only, but with less error in terms of energy and nutrient values for the wrong predictions.
Block Modeling-Guided Graph Convolutional Neural Networks
Dec 28, 2021
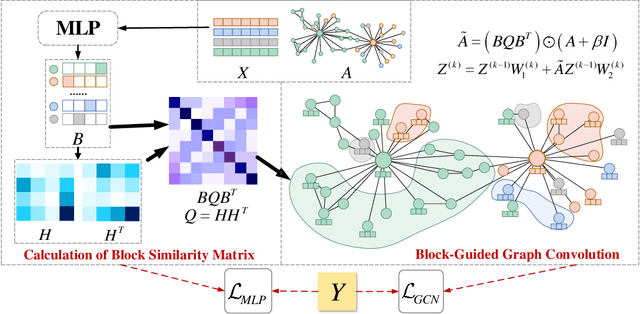
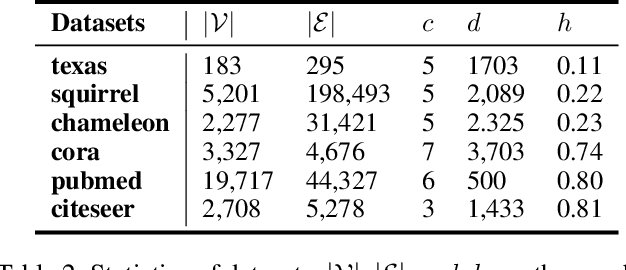
Graph Convolutional Network (GCN) has shown remarkable potential of exploring graph representation. However, the GCN aggregating mechanism fails to generalize to networks with heterophily where most nodes have neighbors from different classes, which commonly exists in real-world networks. In order to make the propagation and aggregation mechanism of GCN suitable for both homophily and heterophily (or even their mixture), we introduce block modeling into the framework of GCN so that it can realize "block-guided classified aggregation", and automatically learn the corresponding aggregation rules for neighbors of different classes. By incorporating block modeling into the aggregation process, GCN is able to aggregate information from homophilic and heterophilic neighbors discriminately according to their homophily degree. We compared our algorithm with state-of-art methods which deal with the heterophily problem. Empirical results demonstrate the superiority of our new approach over existing methods in heterophilic datasets while maintaining a competitive performance in homophilic datasets.
Temporal Shuffling for Defending Deep Action Recognition Models against Adversarial Attacks
Dec 15, 2021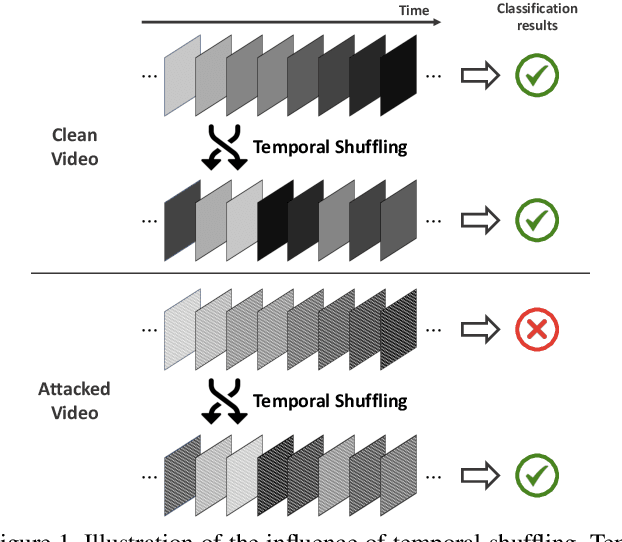
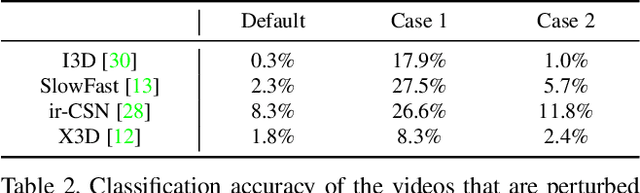

Recently, video-based action recognition methods using convolutional neural networks (CNNs) achieve remarkable recognition performance. However, there is still lack of understanding about the generalization mechanism of action recognition models. In this paper, we suggest that action recognition models rely on the motion information less than expected, and thus they are robust to randomization of frame orders. Based on this observation, we develop a novel defense method using temporal shuffling of input videos against adversarial attacks for action recognition models. Another observation enabling our defense method is that adversarial perturbations on videos are sensitive to temporal destruction. To the best of our knowledge, this is the first attempt to design a defense method specific to video-based action recognition models.
Learning with latent group sparsity via heat flow dynamics on networks
Jan 20, 2022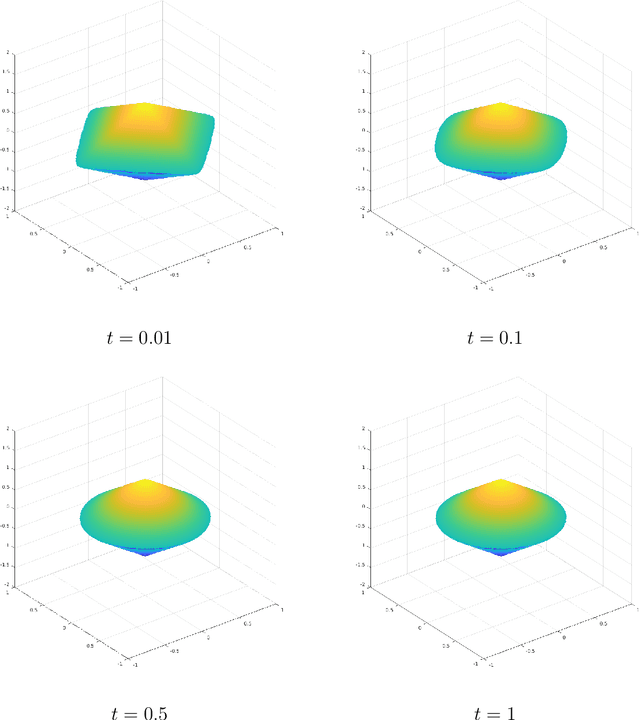
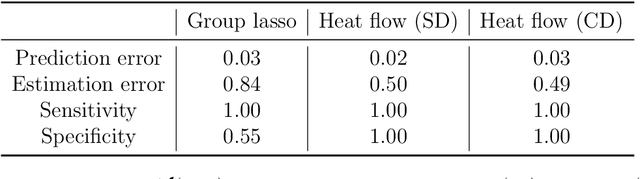
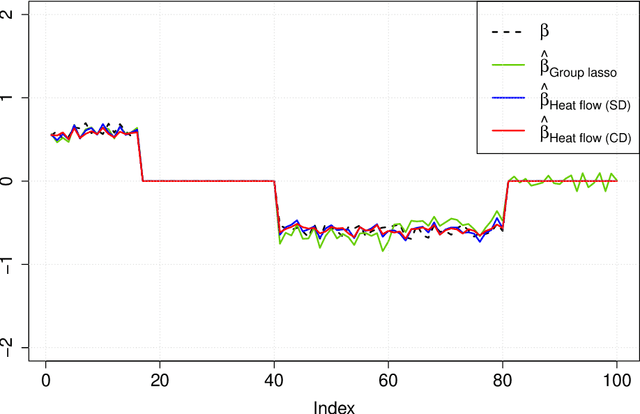
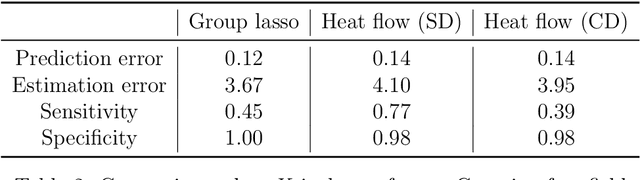
Group or cluster structure on explanatory variables in machine learning problems is a very general phenomenon, which has attracted broad interest from practitioners and theoreticians alike. In this work we contribute an approach to learning under such group structure, that does not require prior information on the group identities. Our paradigm is motivated by the Laplacian geometry of an underlying network with a related community structure, and proceeds by directly incorporating this into a penalty that is effectively computed via a heat flow-based local network dynamics. In fact, we demonstrate a procedure to construct such a network based on the available data. Notably, we dispense with computationally intensive pre-processing involving clustering of variables, spectral or otherwise. Our technique is underpinned by rigorous theorems that guarantee its effective performance and provide bounds on its sample complexity. In particular, in a wide range of settings, it provably suffices to run the heat flow dynamics for time that is only logarithmic in the problem dimensions. We explore in detail the interfaces of our approach with key statistical physics models in network science, such as the Gaussian Free Field and the Stochastic Block Model. We validate our approach by successful applications to real-world data from a wide array of application domains, including computer science, genetics, climatology and economics. Our work raises the possibility of applying similar diffusion-based techniques to classical learning tasks, exploiting the interplay between geometric, dynamical and stochastic structures underlying the data.
Doing More with Less: Overcoming Data Scarcity for POI Recommendation via Cross-Region Transfer
Jan 16, 2022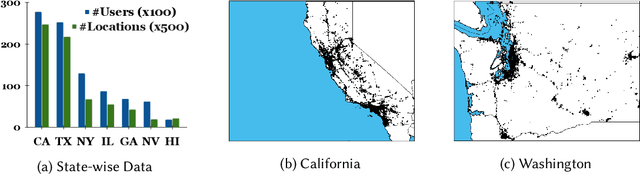
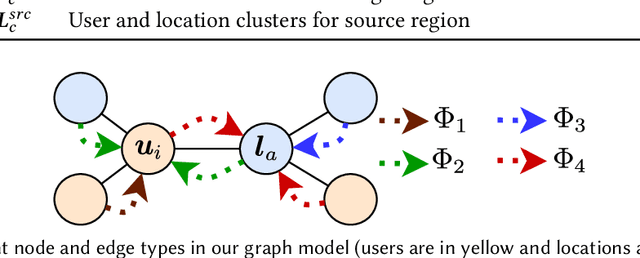

Variability in social app usage across regions results in a high skew of the quantity and the quality of check-in data collected, which in turn is a challenge for effective location recommender systems. In this paper, we present Axolotl (Automated cross Location-network Transfer Learning), a novel method aimed at transferring location preference models learned in a data-rich region to significantly boost the quality of recommendations in a data-scarce region. Axolotl predominantly deploys two channels for information transfer, (1) a meta-learning based procedure learned using location recommendation as well as social predictions, and (2) a lightweight unsupervised cluster-based transfer across users and locations with similar preferences. Both of these work together synergistically to achieve improved accuracy of recommendations in data-scarce regions without any prerequisite of overlapping users and with minimal fine-tuning. We build Axolotl on top of a twin graph-attention neural network model used for capturing the user- and location-conditioned influences in a user-mobility graph for each region. We conduct extensive experiments on 12 user mobility datasets across the U.S., Japan, and Germany, using 3 as source regions and 9 of them (that have much sparsely recorded mobility data) as target regions. Empirically, we show that Axolotl achieves up to 18% better recommendation performance than the existing state-of-the-art methods across all metrics.
The University of Texas at Dallas HLTRI's Participation in EPIC-QA: Searching for Entailed Questions Revealing Novel Answer Nuggets
Dec 28, 2021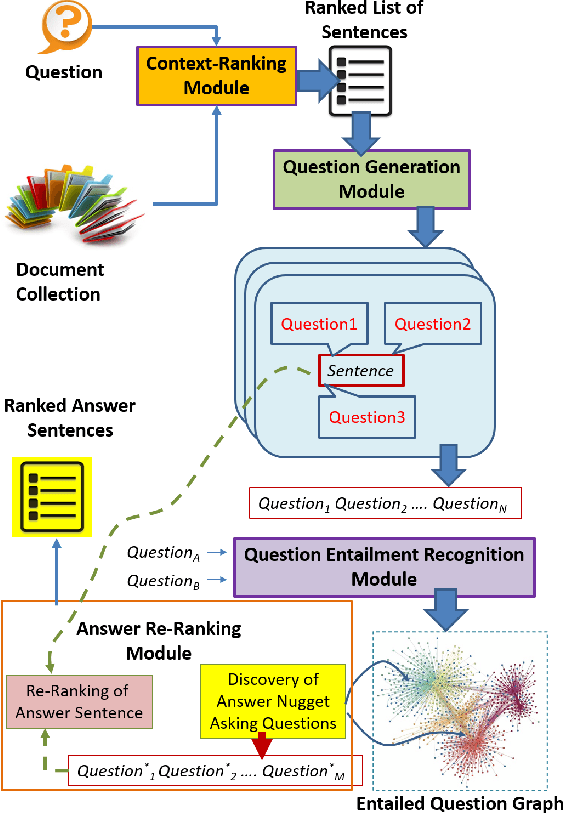
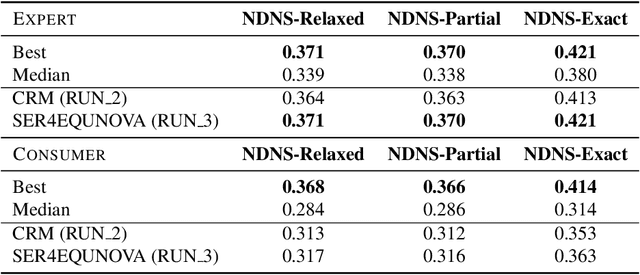
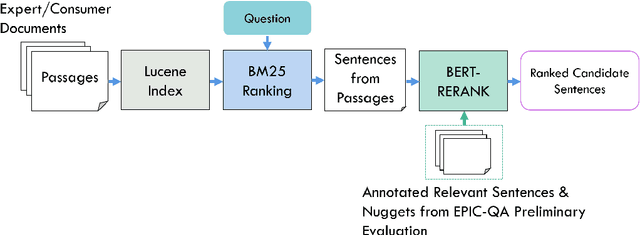

The Epidemic Question Answering (EPIC-QA) track at the Text Analysis Conference (TAC) is an evaluation of methodologies for answering ad-hoc questions about the COVID-19 disease. This paper describes our participation in both tasks of EPIC-QA, targeting: (1) Expert QA and (2) Consumer QA. Our methods used a multi-phase neural Information Retrieval (IR) system based on combining BM25, BERT, and T5 as well as the idea of considering entailment relations between the original question and questions automatically generated from answer candidate sentences. Moreover, because entailment relations were also considered between all generated questions, we were able to re-rank the answer sentences based on the number of novel answer nuggets they contained, as indicated by the processing of a question entailment graph. Our system, called SEaRching for Entailed QUestions revealing NOVel nuggets of Answers (SER4EQUNOVA), produced promising results in both EPIC-QA tasks, excelling in the Expert QA task.