 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Web Search via an Efficient and Effective Brain-Machine Interface
Oct 15, 2021
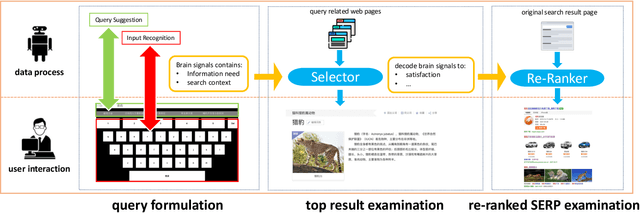

While search technologies have evolved to be robust and ubiquitous, the fundamental interaction paradigm has remained relatively stable for decades. With the maturity of the Brain-Machine Interface, we build an efficient and effective communication system between human beings and search engines based on electroencephalogram(EEG) signals, called Brain-Machine Search Interface(BMSI) system. The BMSI system provides functions including query reformulation and search result interaction. In our system, users can perform search tasks without having to use the mouse and keyboard. Therefore, it is useful for application scenarios in which hand-based interactions are infeasible, e.g, for users with severe neuromuscular disorders. Besides, based on brain signals decoding, our system can provide abundant and valuable user-side context information(e.g., real-time satisfaction feedback, extensive context information, and a clearer description of information needs) to the search engine, which is hard to capture in the previous paradigm. In our implementation, the system can decode user satisfaction from brain signals in real-time during the interaction process and re-rank the search results list based on user satisfaction feedback. The demo video is available at http://www.thuir.cn/group/YQLiu/datasets/BMSISystem.mp4.
Learning Cross-Lingual IR from an English Retriever
Dec 15, 2021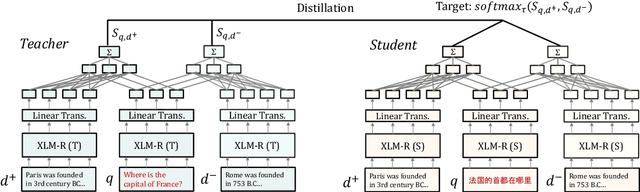
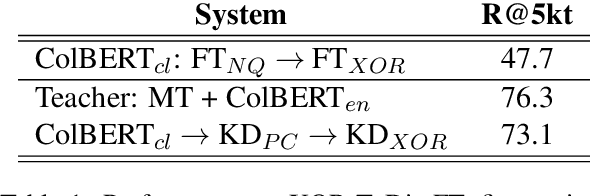
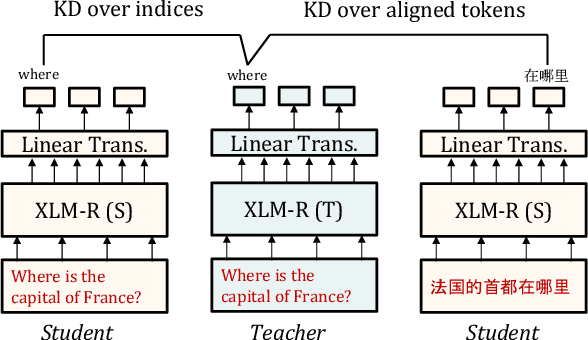
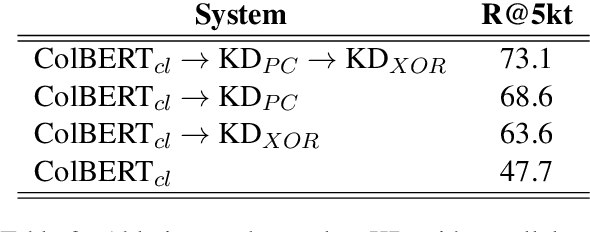
We present a new cross-lingual information retrieval (CLIR) model trained using multi-stage knowledge distillation (KD). The teacher and the student are heterogeneous systems-the former is a pipeline that relies on machine translation and monolingual IR, while the latter executes a single CLIR operation. We show that the student can learn both multilingual representations and CLIR by optimizing two corresponding KD objectives. Learning multilingual representations from an English-only retriever is accomplished using a novel cross-lingual alignment algorithm that greedily re-positions the teacher tokens for alignment. Evaluation on the XOR-TyDi benchmark shows that the proposed model is far more effective than the existing approach of fine-tuning with cross-lingual labeled IR data, with a gain in accuracy of 25.4 Recall@5kt.
Dynamic Temporal Reconciliation by Reinforcement learning
Jan 28, 2022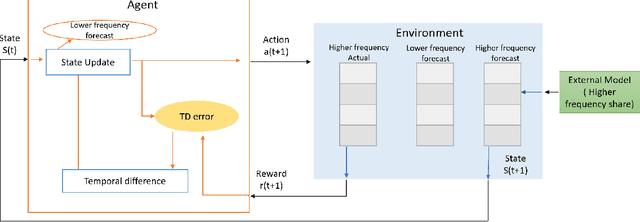
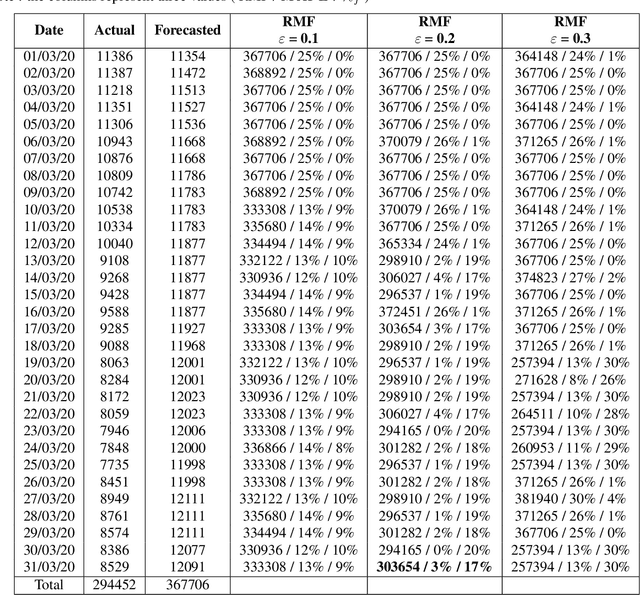
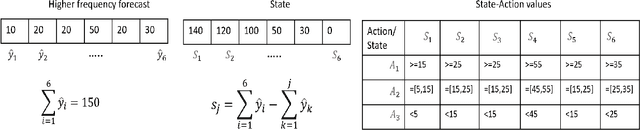
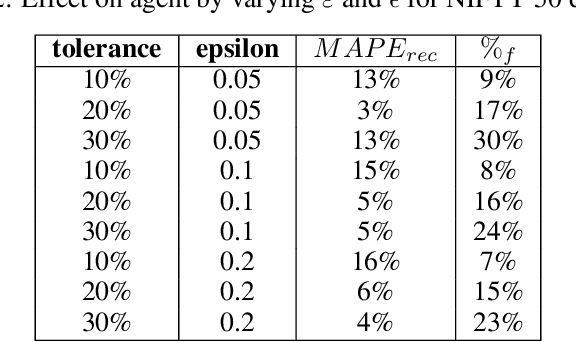
Planning based on long and short term time series forecasts is a common practice across many industries. In this context, temporal aggregation and reconciliation techniques have been useful in improving forecasts, reducing model uncertainty, and providing a coherent forecast across different time horizons. However, an underlying assumption spanning all these techniques is the complete availability of data across all levels of the temporal hierarchy, while this offers mathematical convenience but most of the time low frequency data is partially completed and it is not available while forecasting. On the other hand, high frequency data can significantly change in a scenario like the COVID pandemic and this change can be used to improve forecasts that will otherwise significantly diverge from long term actuals. We propose a dynamic reconciliation method whereby we formulate the problem of informing low frequency forecasts based on high frequency actuals as a Markov Decision Process (MDP) allowing for the fact that we do not have complete information about the dynamics of the process. This allows us to have the best long term estimates based on the most recent data available even if the low frequency cycles have only been partially completed. The MDP has been solved using a Time Differenced Reinforcement learning (TDRL) approach with customizable actions and improves the long terms forecasts dramatically as compared to relying solely on historical low frequency data. The result also underscores the fact that while low frequency forecasts can improve the high frequency forecasts as mentioned in the temporal reconciliation literature (based on the assumption that low frequency forecasts have lower noise to signal ratio) the high frequency forecasts can also be used to inform the low frequency forecasts.
Reconstructing Training Data from Diverse ML Models by Ensemble Inversion
Nov 05, 2021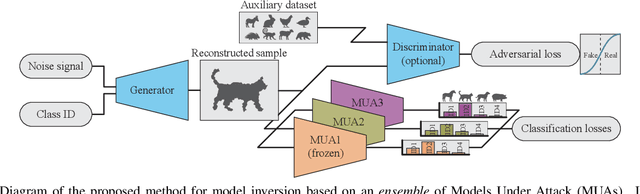
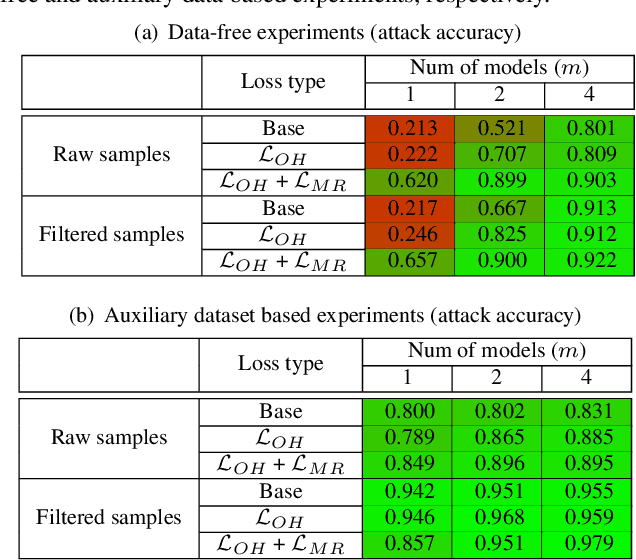

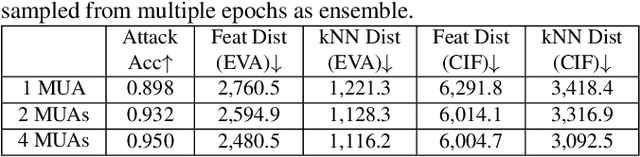
Model Inversion (MI), in which an adversary abuses access to a trained Machine Learning (ML) model attempting to infer sensitive information about its original training data, has attracted increasing research attention. During MI, the trained model under attack (MUA) is usually frozen and used to guide the training of a generator, such as a Generative Adversarial Network (GAN), to reconstruct the distribution of the original training data of that model. This might cause leakage of original training samples, and if successful, the privacy of dataset subjects will be at risk if the training data contains Personally Identifiable Information (PII). Therefore, an in-depth investigation of the potentials of MI techniques is crucial for the development of corresponding defense techniques. High-quality reconstruction of training data based on a single model is challenging. However, existing MI literature does not explore targeting multiple models jointly, which may provide additional information and diverse perspectives to the adversary. We propose the ensemble inversion technique that estimates the distribution of original training data by training a generator constrained by an ensemble (or set) of trained models with shared subjects or entities. This technique leads to noticeable improvements of the quality of the generated samples with distinguishable features of the dataset entities compared to MI of a single ML model. We achieve high quality results without any dataset and show how utilizing an auxiliary dataset that's similar to the presumed training data improves the results. The impact of model diversity in the ensemble is thoroughly investigated and additional constraints are utilized to encourage sharp predictions and high activations for the reconstructed samples, leading to more accurate reconstruction of training images.
Force control of grinding process based on frequency analysis
Dec 08, 2021
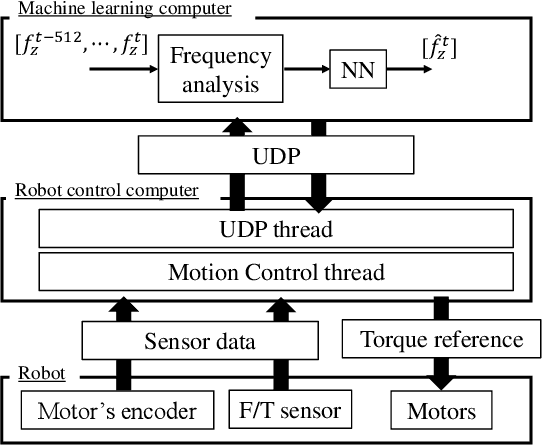
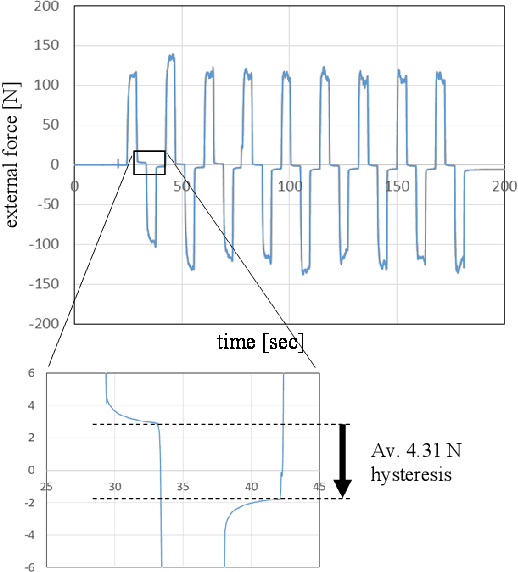
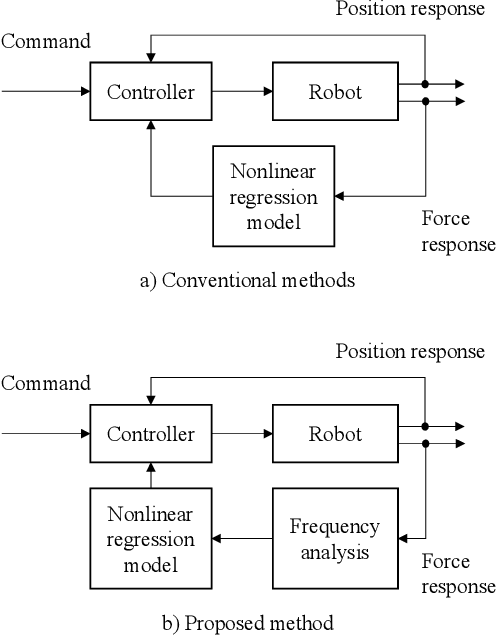
Hysteresis-induced drift is a major issue in the detection of force induced during grinding and cutting operations. In this paper, we propose an external force estimation method based on the Mel spectrogram of the force obtained from a force sensor. We focus on the frequent strong correlation between the vibration frequency and the external force in operations with periodic vibrations. The frequency information is found to be more effective for an accurate force estimation than the amplitude in cases with large noise caused by vibration. We experimentally demonstrate that the force estimation method that combines the Mel spectrogram with a neural network is robust against drift.
Multilayer Graph Contrastive Clustering Network
Dec 28, 2021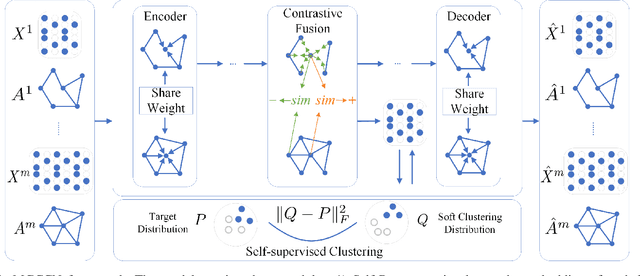
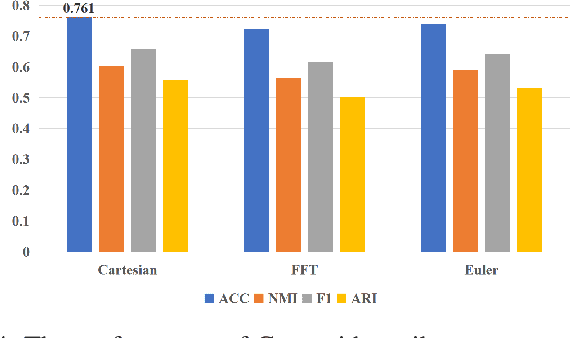
Multilayer graph has garnered plenty of research attention in many areas due to their high utility in modeling interdependent systems. However, clustering of multilayer graph, which aims at dividing the graph nodes into categories or communities, is still at a nascent stage. Existing methods are often limited to exploiting the multiview attributes or multiple networks and ignoring more complex and richer network frameworks. To this end, we propose a generic and effective autoencoder framework for multilayer graph clustering named Multilayer Graph Contrastive Clustering Network (MGCCN). MGCCN consists of three modules: (1)Attention mechanism is applied to better capture the relevance between nodes and neighbors for better node embeddings. (2)To better explore the consistent information in different networks, a contrastive fusion strategy is introduced. (3)MGCCN employs a self-supervised component that iteratively strengthens the node embedding and clustering. Extensive experiments on different types of real-world graph data indicate that our proposed method outperforms state-of-the-art techniques.
Named Entity Recognition in Unstructured Medical Text Documents
Oct 15, 2021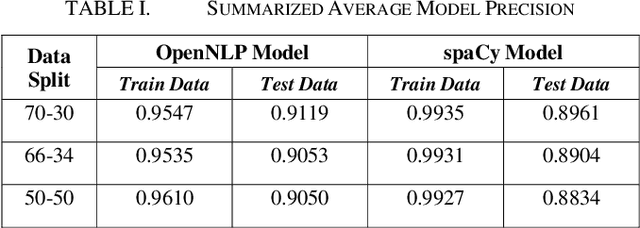
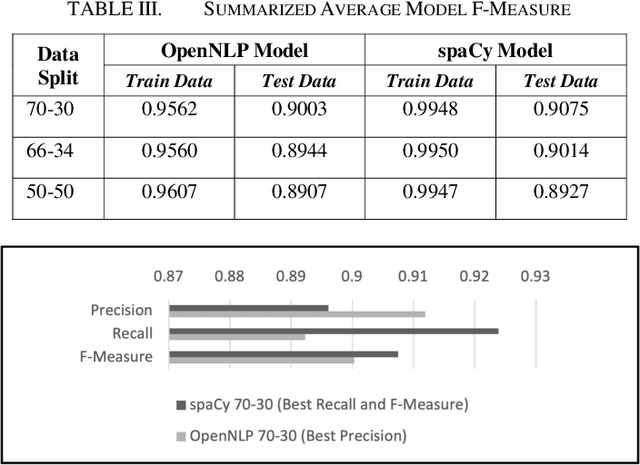
Physicians provide expert opinion to legal courts on the medical state of patients, including determining if a patient is likely to have permanent or non-permanent injuries or ailments. An independent medical examination (IME) report summarizes a physicians medical opinion about a patients health status based on the physicians expertise. IME reports contain private and sensitive information (Personally Identifiable Information or PII) that needs to be removed or randomly encoded before further research work can be conducted. In our study the IME is an orthopedic surgeon from a private practice in the United States. The goal of this research is to perform named entity recognition (NER) to identify and subsequently remove/encode PII information from IME reports prepared by the physician. We apply the NER toolkits of OpenNLP and spaCy, two freely available natural language processing platforms, and compare their precision, recall, and f-measure performance at identifying five categories of PII across trials of randomly selected IME reports using each models common default parameters. We find that both platforms achieve high performance (f-measure > 0.9) at de-identification and that a spaCy model trained with a 70-30 train-test data split is most performant.
A Vision-based Irregular Obstacle Avoidance Framework via Deep Reinforcement Learning
Aug 23, 2021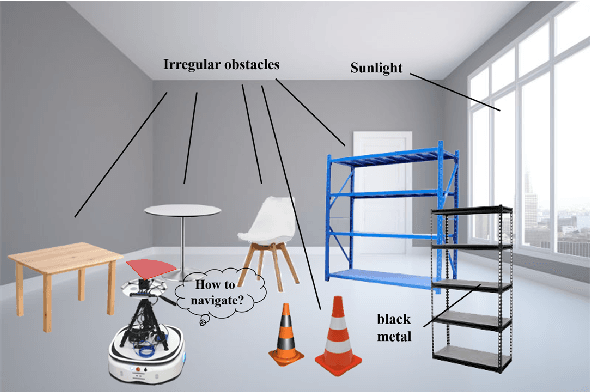
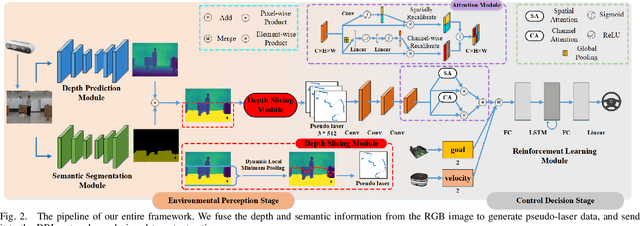

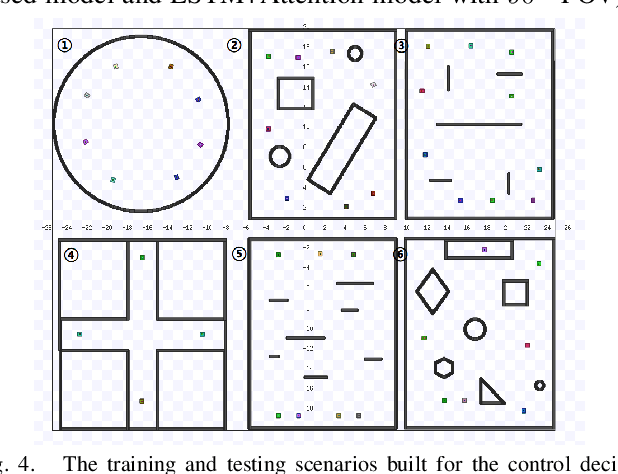
Deep reinforcement learning has achieved great success in laser-based collision avoidance work because the laser can sense accurate depth information without too much redundant data, which can maintain the robustness of the algorithm when it is migrated from the simulation environment to the real world. However, high-cost laser devices are not only difficult to apply on a large scale but also have poor robustness to irregular objects, e.g., tables, chairs, shelves, etc. In this paper, we propose a vision-based collision avoidance framework to solve the challenging problem. Our method attempts to estimate the depth and incorporate the semantic information from RGB data to obtain a new form of data, pseudo-laser data, which combines the advantages of visual information and laser information. Compared to traditional laser data that only contains the one-dimensional distance information captured at a certain height, our proposed pseudo-laser data encodes the depth information and semantic information within the image, which makes our method more effective for irregular obstacles. Besides, we adaptively add noise to the laser data during the training stage to increase the robustness of our model in the real world, due to the estimated depth information is not accurate. Experimental results show that our framework achieves state-of-the-art performance in several unseen virtual and real-world scenarios.
Improving Dietary Assessment Via Integrated Hierarchy Food Classification
Sep 06, 2021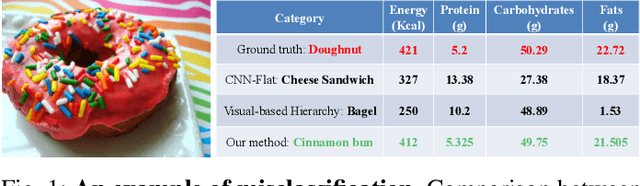
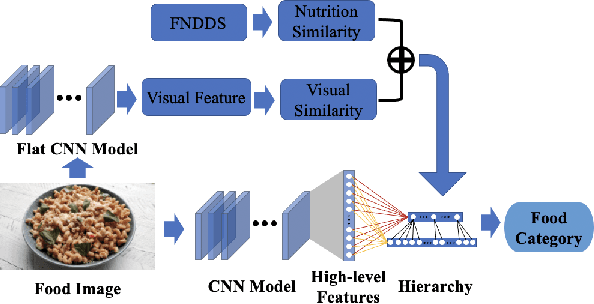
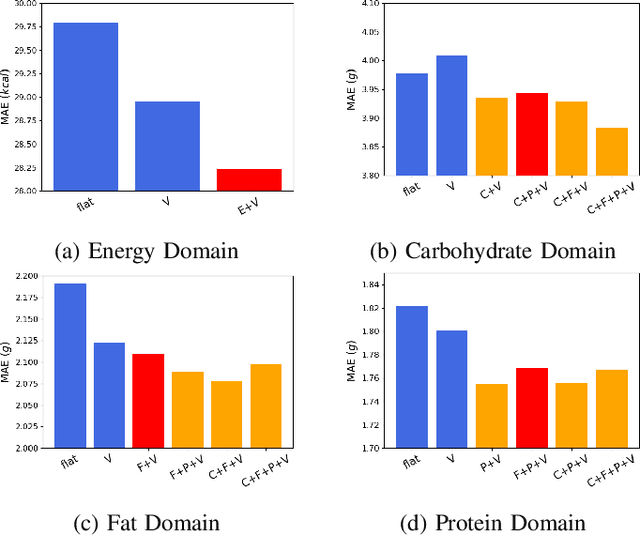

Image-based dietary assessment refers to the process of determining what someone eats and how much energy and nutrients are consumed from visual data. Food classification is the first and most crucial step. Existing methods focus on improving accuracy measured by the rate of correct classification based on visual information alone, which is very challenging due to the high complexity and inter-class similarity of foods. Further, accuracy in food classification is conceptual as description of a food can always be improved. In this work, we introduce a new food classification framework to improve the quality of predictions by integrating the information from multiple domains while maintaining the classification accuracy. We apply a multi-task network based on a hierarchical structure that uses both visual and nutrition domain specific information to cluster similar foods. Our method is validated on the modified VIPER-FoodNet (VFN) food image dataset by including associated energy and nutrient information. We achieve comparable classification accuracy with existing methods that use visual information only, but with less error in terms of energy and nutrient values for the wrong predictions.
Digital RIS (DRIS): The Future of Digital Beam Management in RIS-Assisted OWC Systems
Dec 18, 2021
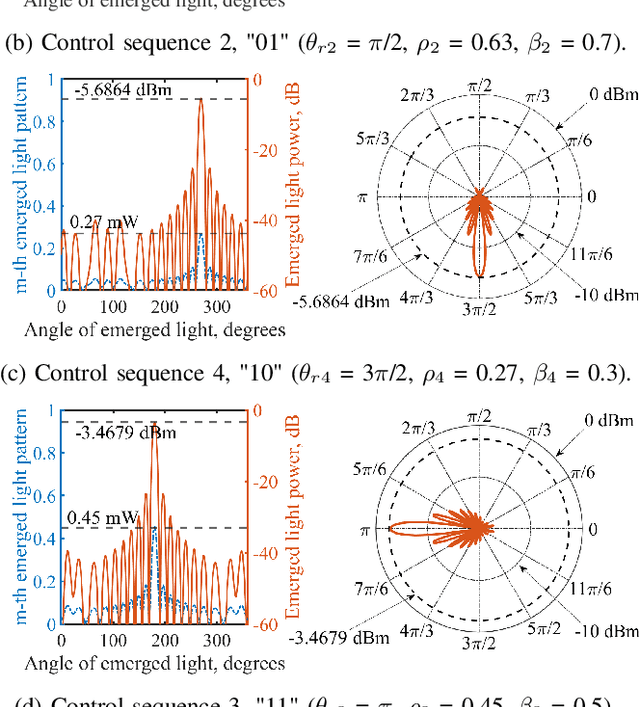
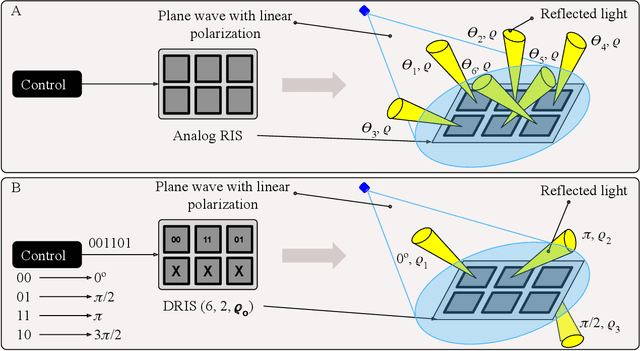
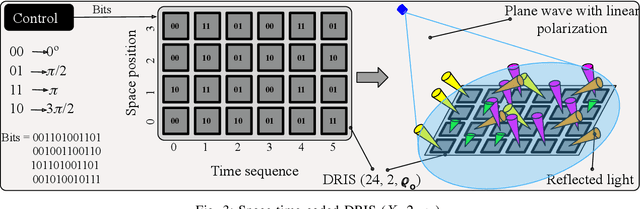
Reconfigurable intelligent surfaces (RIS) have been recently introduced to optical wireless communication (OWC) networks to resolve skip areas and improve the signal-to-noise ratio at the user's end. In OWC networks, RIS are based on mirrors or metasurfaces. Metasurfaces have evolved significantly over the last few years. As a result, coding, digital, programmable, and information metamaterials have been developed. The advantage of these materials is that they can enable digital signal processing (DSP) techniques. For the first time, this paper proposes the use of digital RIS (DRIS) in OWC systems. We discuss the concept of DRIS and the application of DSP methods to the physical material. In addition, we examine metamaterials for optical DRIS with liquid crystals serving as the front row material. Finally, we present a design example and discuss future research directions.