 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Speaker-Oriented Latent Structures for Dialogue-Based Relation Extraction
Sep 11, 2021

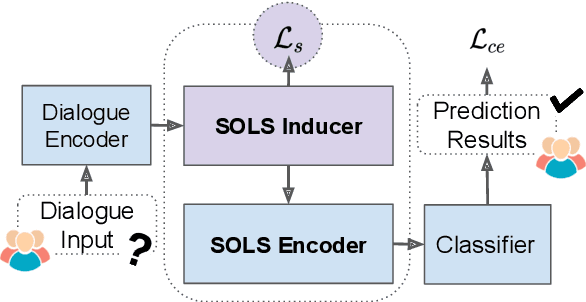
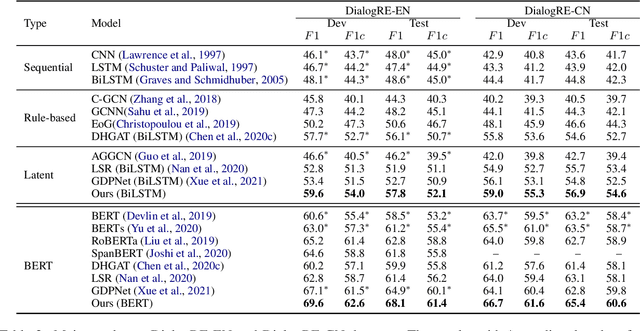
Dialogue-based relation extraction (DiaRE) aims to detect the structural information from unstructured utterances in dialogues. Existing relation extraction models may be unsatisfactory under such a conversational setting, due to the entangled logic and information sparsity issues in utterances involving multiple speakers. To this end, we introduce SOLS, a novel model which can explicitly induce speaker-oriented latent structures for better DiaRE. Specifically, we learn latent structures to capture the relationships among tokens beyond the utterance boundaries, alleviating the entangled logic issue. During the learning process, our speaker-specific regularization method progressively highlights speaker-related key clues and erases the irrelevant ones, alleviating the information sparsity issue. Experiments on three public datasets demonstrate the effectiveness of our proposed approach.
Visual Microfossil Identification via Deep Metric Learning
Jan 04, 2022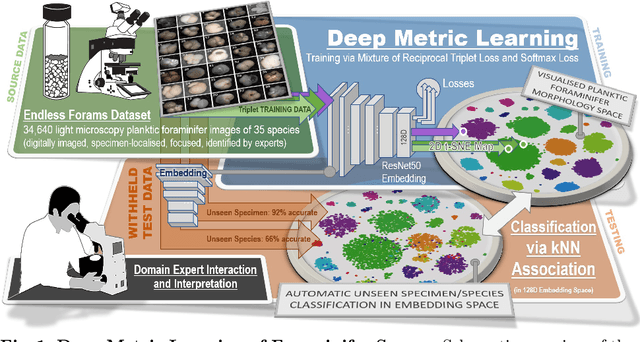
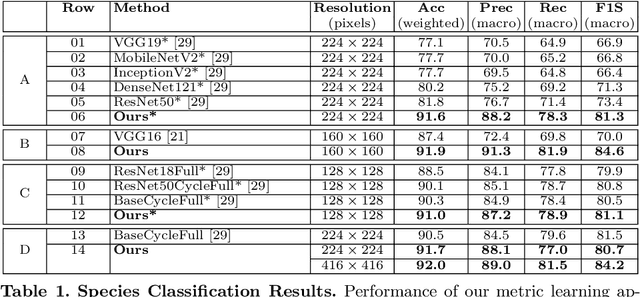
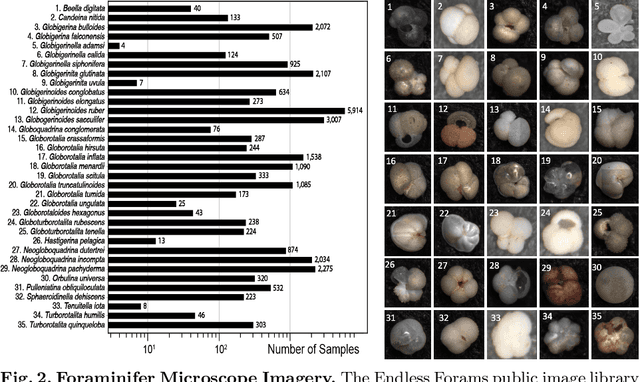
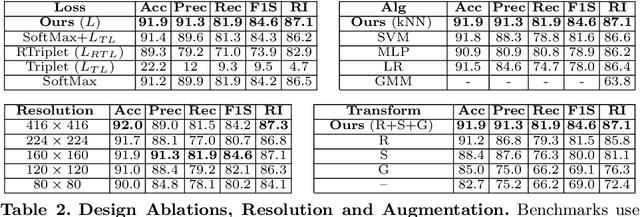
We apply deep metric learning for the first time to the prob-lem of classifying planktic foraminifer shells on microscopic images. This species recognition task is an important information source and scientific pillar for reconstructing past climates. All foraminifer CNN recognition pipelines in the literature produce black-box classifiers that lack visualisation options for human experts and cannot be applied to open set problems. Here, we benchmark metric learning against these pipelines, produce the first scientific visualisation of the phenotypic planktic foraminifer morphology space, and demonstrate that metric learning can be used to cluster species unseen during training. We show that metric learning out-performs all published CNN-based state-of-the-art benchmarks in this domain. We evaluate our approach on the 34,640 expert-annotated images of the Endless Forams public library of 35 modern planktic foraminifera species. Our results on this data show leading 92% accuracy (at 0.84 F1-score) in reproducing expert labels on withheld test data, and 66.5% accuracy (at 0.70 F1-score) when clustering species never encountered in training. We conclude that metric learning is highly effective for this domain and serves as an important tool towards expert-in-the-loop automation of microfossil identification. Key code, network weights, and data splits are published with this paper for full reproducibility.
AMMASurv: Asymmetrical Multi-Modal Attention for Accurate Survival Analysis with Whole Slide Images and Gene Expression Data
Aug 28, 2021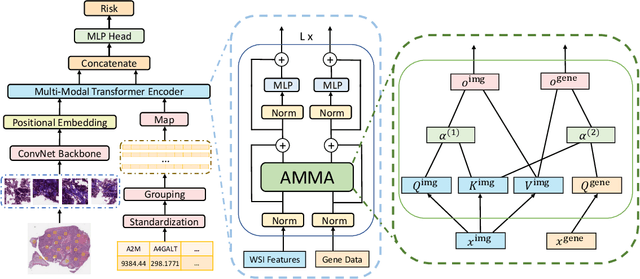
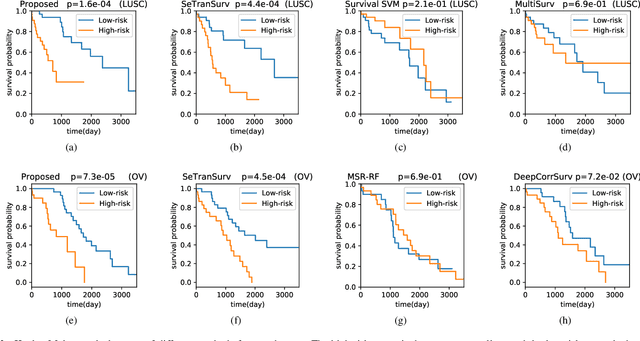
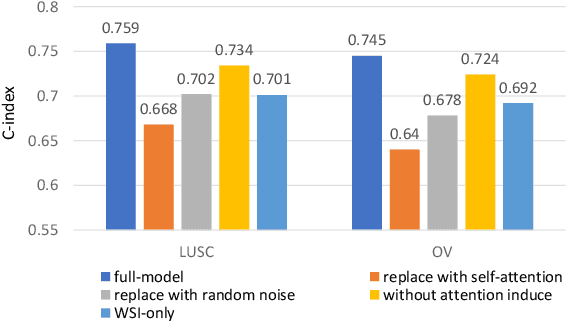
The use of multi-modal data such as the combination of whole slide images (WSIs) and gene expression data for survival analysis can lead to more accurate survival predictions. Previous multi-modal survival models are not able to efficiently excavate the intrinsic information within each modality. Moreover, despite experimental results show that WSIs provide more effective information than gene expression data, previous methods regard the information from different modalities as similarly important so they cannot flexibly utilize the potential connection between the modalities. To address the above problems, we propose a new asymmetrical multi-modal method, termed as AMMASurv. Specifically, we design an asymmetrical multi-modal attention mechanism (AMMA) in Transformer encoder for multi-modal data to enable a more flexible multi-modal information fusion for survival prediction. Different from previous works, AMMASurv can effectively utilize the intrinsic information within every modality and flexibly adapts to the modalities of different importance. Extensive experiments are conducted to validate the effectiveness of the proposed model. Encouraging results demonstrate the superiority of our method over other state-of-the-art methods.
PAANet: Progressive Alternating Attention for Automatic Medical Image Segmentation
Nov 20, 2021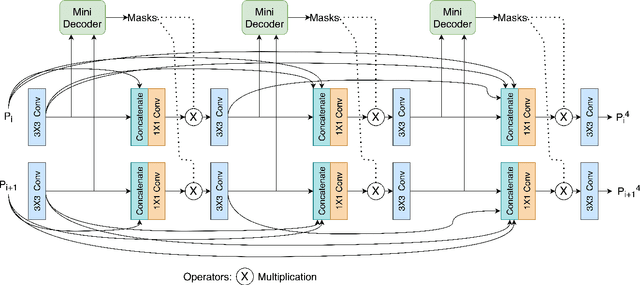
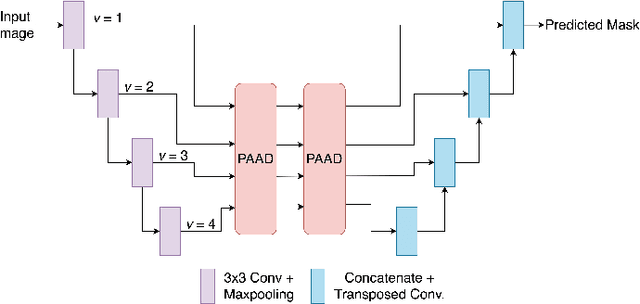
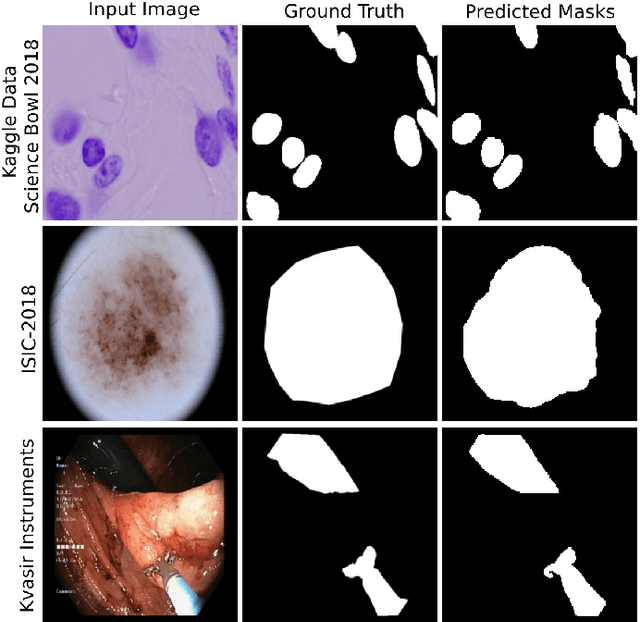
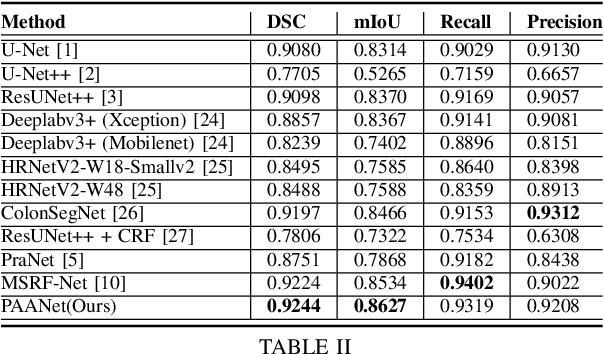
Medical image segmentation can provide detailed information for clinical analysis which can be useful for scenarios where the detailed location of a finding is important. Knowing the location of disease can play a vital role in treatment and decision-making. Convolutional neural network (CNN) based encoder-decoder techniques have advanced the performance of automated medical image segmentation systems. Several such CNN-based methodologies utilize techniques such as spatial- and channel-wise attention to enhance performance. Another technique that has drawn attention in recent years is residual dense blocks (RDBs). The successive convolutional layers in densely connected blocks are capable of extracting diverse features with varied receptive fields and thus, enhancing performance. However, consecutive stacked convolutional operators may not necessarily generate features that facilitate the identification of the target structures. In this paper, we propose a progressive alternating attention network (PAANet). We develop progressive alternating attention dense (PAAD) blocks, which construct a guiding attention map (GAM) after every convolutional layer in the dense blocks using features from all scales. The GAM allows the following layers in the dense blocks to focus on the spatial locations relevant to the target region. Every alternate PAAD block inverts the GAM to generate a reverse attention map which guides ensuing layers to extract boundary and edge-related information, refining the segmentation process. Our experiments on three different biomedical image segmentation datasets exhibit that our PAANet achieves favourable performance when compared to other state-of-the-art methods.
C2-CRS: Coarse-to-Fine Contrastive Learning for Conversational Recommender System
Jan 04, 2022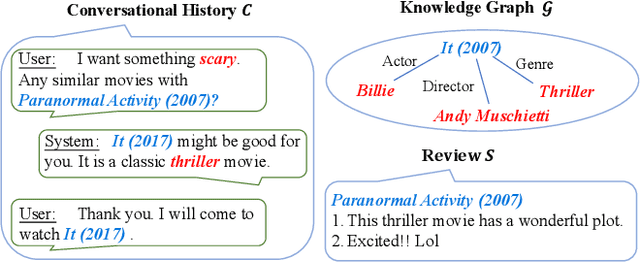
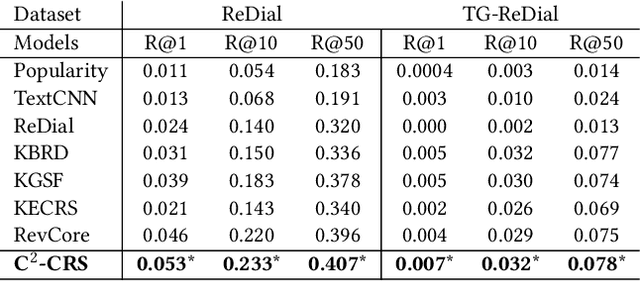
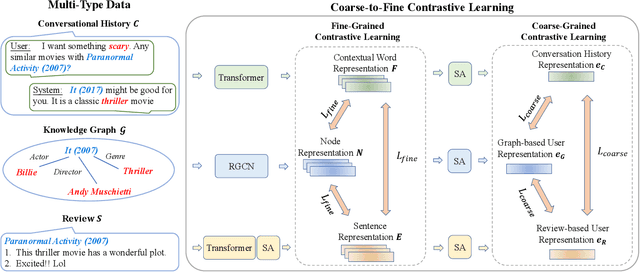
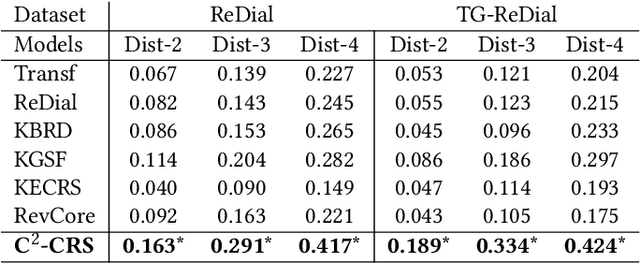
Conversational recommender systems (CRS) aim to recommend suitable items to users through natural language conversations. For developing effective CRSs, a major technical issue is how to accurately infer user preference from very limited conversation context. To address issue, a promising solution is to incorporate external data for enriching the context information. However, prior studies mainly focus on designing fusion models tailored for some specific type of external data, which is not general to model and utilize multi-type external data. To effectively leverage multi-type external data, we propose a novel coarse-to-fine contrastive learning framework to improve data semantic fusion for CRS. In our approach, we first extract and represent multi-grained semantic units from different data signals, and then align the associated multi-type semantic units in a coarse-to-fine way. To implement this framework, we design both coarse-grained and fine-grained procedures for modeling user preference, where the former focuses on more general, coarse-grained semantic fusion and the latter focuses on more specific, fine-grained semantic fusion. Such an approach can be extended to incorporate more kinds of external data. Extensive experiments on two public CRS datasets have demonstrated the effectiveness of our approach in both recommendation and conversation tasks.
MAP-CSI: Single-site Map-Assisted Localization Using Massive MIMO CSI
Oct 01, 2021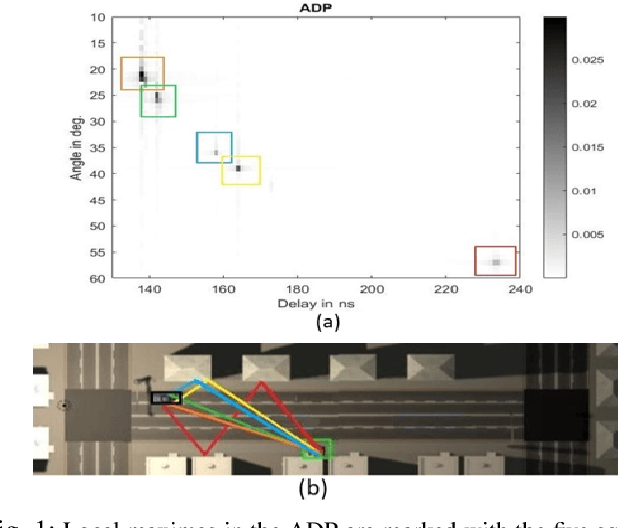
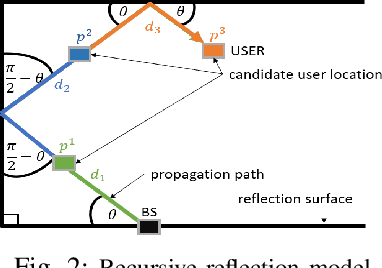

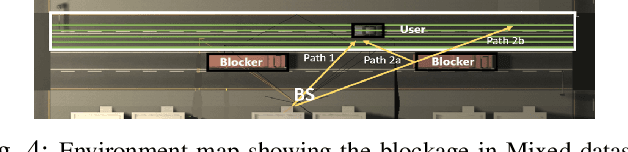
This paper presents a new map-assisted localization approach utilizing Chanel State Information (CSI) in Massive Multiple-Input Multiple-Output (MIMO) systems. Map-assisted localization is an environment-aware approach in which the communication system has information regarding the surrounding environment. By combining radio frequency ray tracing parameters of the multipath components (MPC) with the environment map, it is possible to accomplish localization. Unfortunately, in real-world scenarios, ray tracing parameters are typically not explicitly available. Thus, additional complexity is added at a base station to obtain this information. On the other hand, CSI is a common communication parameter, usually estimated for any communication channel. In this work, we leverage the already available CSI data to propose a novel map-assisted CSI localization approach, referred to as MAP-CSI. We show that Angle-of-Departure (AoD) and Time-of-Arrival (ToA) can be extracted from CSI and then be used in combination with the environment map to localize the user. We perform simulations on a public MIMO dataset and show that our method works for both line-of-sight (LOS) and non-line-of-sight (NLOS) scenarios. We compare our method to the state-of-the-art (SoA) method that uses the ray tracing data. Using MAP-CSI, we accomplish an average localization error of 1.8 m in LOS and 2.8 m in mixed (combination of LOS and NLOS samples) scenarios. On the other hand, SoA ray tracing has an average error of 1.0 m and 2.2 m, respectively, but requires explicit AoD and ToA information to perform the localization task.
Distributed Online Optimization with Byzantine Adversarial Agents
Sep 25, 2021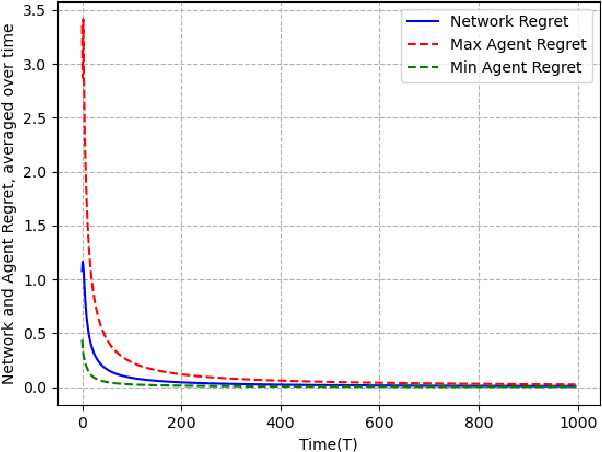
We study the problem of non-constrained, discrete-time, online distributed optimization in a multi-agent system where some of the agents do not follow the prescribed update rule either due to failures or malicious intentions. None of the agents have prior information about the identities of the faulty agents and any agent can communicate only with its immediate neighbours. At each time step, a Lipschitz strongly convex cost function is revealed locally to all the agents and the non-faulty agents update their states using their local information and the information obtained from their neighbours. We measure the performance of the online algorithm by comparing it to its offline version when the cost functions are known apriori. The difference between the same is termed as regret. Under sufficient conditions on the graph topology, the number and location of the adversaries, the defined regret grows sublinearly. We further conduct numerical experiments to validate our theoretical results.
Transfer Learning Based Multi-Objective Evolutionary Algorithm for Community Detection of Dynamic Complex Networks
Sep 30, 2021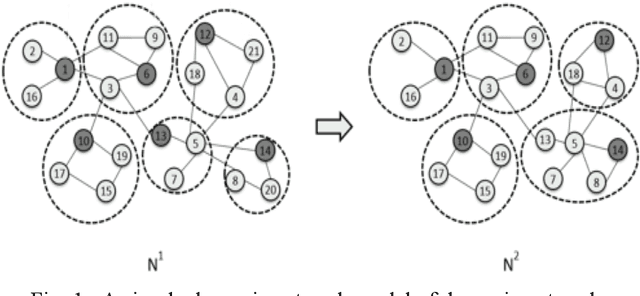

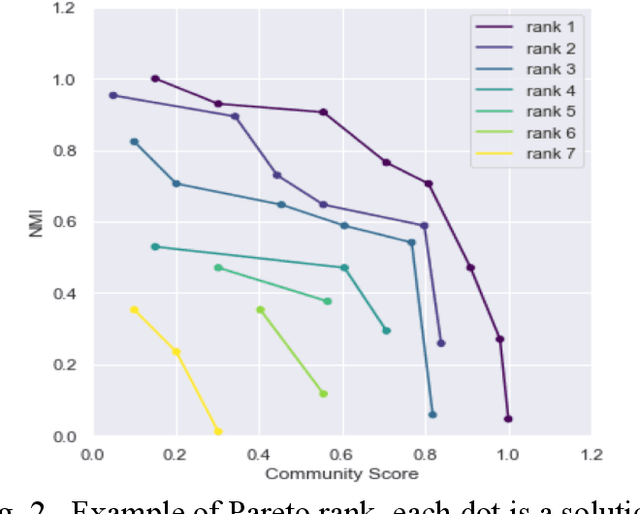

Dynamic community detection is the hotspot and basic problem of complex network and artificial intelligence research in recent years. It is necessary to maximize the accuracy of clustering as the network structure changes, but also to minimize the two consecutive clustering differences between the two results. There is a trade-off relationship between these two objectives. In this paper, we propose a Feature Transfer Based Multi-Objective Optimization Genetic Algorithm (TMOGA) based on transfer learning and traditional multi-objective evolutionary algorithm framework. The main idea is to extract stable features from past community structures, retain valuable feature information, and integrate this feature information into current optimization processes to improve the evolutionary algorithms. Additionally, a new theoretical framework is proposed in this paper to analyze community detection problem based on information theory. Then, we exploit this framework to prove the rationality of TMOGA. Finally, the experimental results show that our algorithm can achieve better clustering effects compared with the state-of-the-art dynamic network community detection algorithms in diverse test problems.
Powered Hawkes-Dirichlet Process: Challenging Textual Clustering using a Flexible Temporal Prior
Sep 15, 2021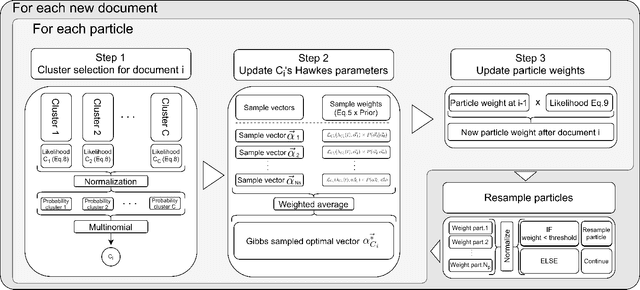

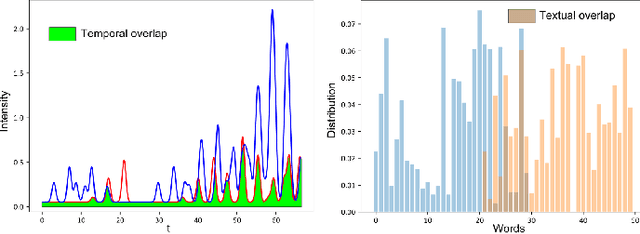

The textual content of a document and its publication date are intertwined. For example, the publication of a news article on a topic is influenced by previous publications on similar issues, according to underlying temporal dynamics. However, it can be challenging to retrieve meaningful information when textual information conveys little information or when temporal dynamics are hard to unveil. Furthermore, the textual content of a document is not always linked to its temporal dynamics. We develop a flexible method to create clusters of textual documents according to both their content and publication time, the Powered Dirichlet-Hawkes process (PDHP). We show PDHP yields significantly better results than state-of-the-art models when temporal information or textual content is weakly informative. The PDHP also alleviates the hypothesis that textual content and temporal dynamics are always perfectly correlated. PDHP allows retrieving textual clusters, temporal clusters, or a mixture of both with high accuracy when they are not. We demonstrate that PDHP generalizes previous work --such as the Dirichlet-Hawkes process (DHP) and Uniform process (UP). Finally, we illustrate the changes induced by PDHP over DHP and UP in a real-world application using Reddit data.
MarkupLM: Pre-training of Text and Markup Language for Visually-rich Document Understanding
Oct 16, 2021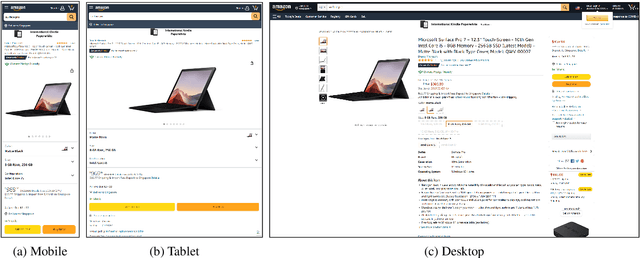

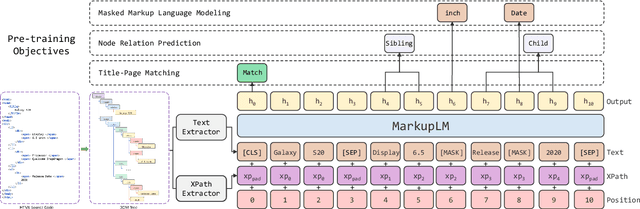
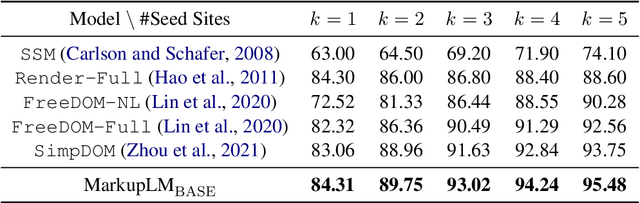
Multimodal pre-training with text, layout, and image has made significant progress for Visually-rich Document Understanding (VrDU), especially the fixed-layout documents such as scanned document images. While, there are still a large number of digital documents where the layout information is not fixed and needs to be interactively and dynamically rendered for visualization, making existing layout-based pre-training approaches not easy to apply. In this paper, we propose MarkupLM for document understanding tasks with markup languages as the backbone such as HTML/XML-based documents, where text and markup information is jointly pre-trained. Experiment results show that the pre-trained MarkupLM significantly outperforms the existing strong baseline models on several document understanding tasks. The pre-trained model and code will be publicly available at https://aka.ms/markuplm.