 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Construction Cost Index Forecasting: A Multi-feature Fusion Approach
Aug 18, 2021

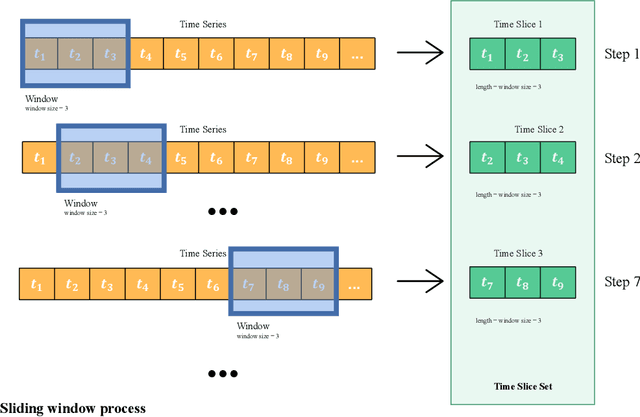

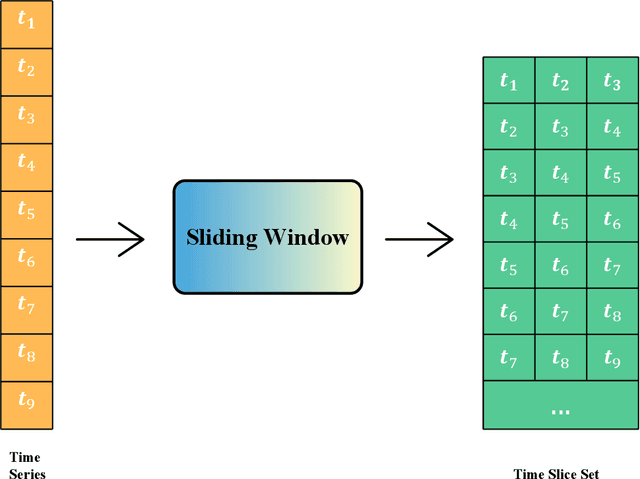
The construction cost index is an important indicator in the construction industry. Predicting CCI has great practical significance. This paper combines information fusion with machine learning, and proposes a Multi-feature Fusion framework for time series forecasting. MFF uses a sliding window algorithm and proposes a function sequence to convert the time sequence into a feature sequence for information fusion. MFF replaces the traditional information method with machine learning to achieve information fusion, which greatly improves the CCI prediction effect. MFF is of great significance to CCI and time series forecasting.
OTB-morph: One-Time Biometrics via Morphing applied to Face Templates
Nov 25, 2021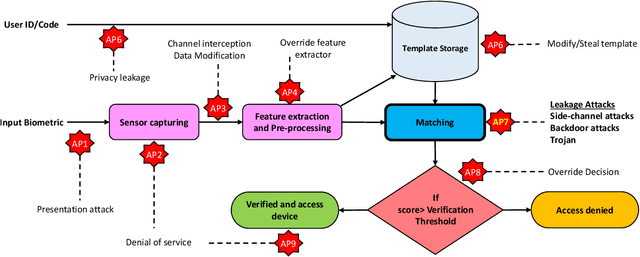

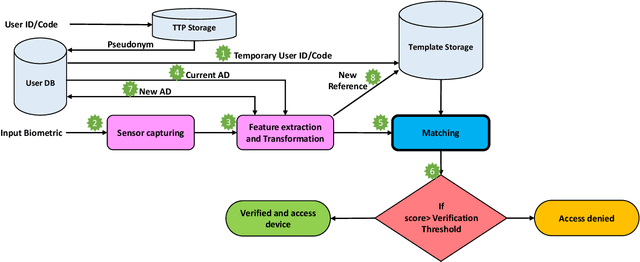
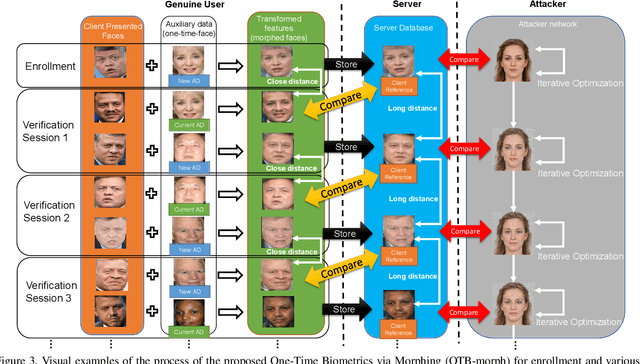
Cancelable biometrics refers to a group of techniques in which the biometric inputs are transformed intentionally using a key before processing or storage. This transformation is repeatable enabling subsequent biometric comparisons. This paper introduces a new scheme for cancelable biometrics aimed at protecting the templates against potential attacks, applicable to any biometric-based recognition system. Our proposed scheme is based on time-varying keys obtained from morphing random biometric information. An experimental implementation of the proposed scheme is given for face biometrics. The results confirm that the proposed approach is able to withstand against leakage attacks while improving the recognition performance.
GraphPAS: Parallel Architecture Search for Graph Neural Networks
Dec 07, 2021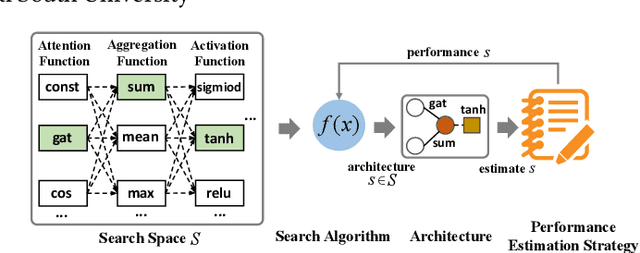

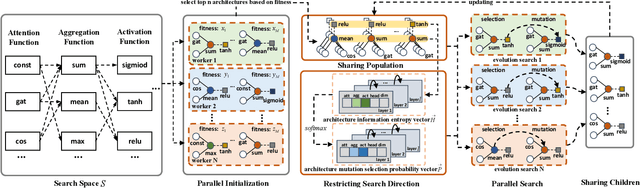
Graph neural architecture search has received a lot of attention as Graph Neural Networks (GNNs) has been successfully applied on the non-Euclidean data recently. However, exploring all possible GNNs architectures in the huge search space is too time-consuming or impossible for big graph data. In this paper, we propose a parallel graph architecture search (GraphPAS) framework for graph neural networks. In GraphPAS, we explore the search space in parallel by designing a sharing-based evolution learning, which can improve the search efficiency without losing the accuracy. Additionally, architecture information entropy is adopted dynamically for mutation selection probability, which can reduce space exploration. The experimental result shows that GraphPAS outperforms state-of-art models with efficiency and accuracy simultaneously.
Continual Learning for Unsupervised Anomaly Detection in Continuous Auditing of Financial Accounting Data
Dec 25, 2021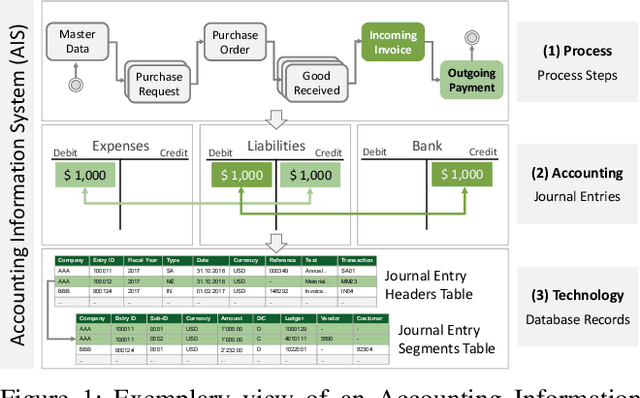

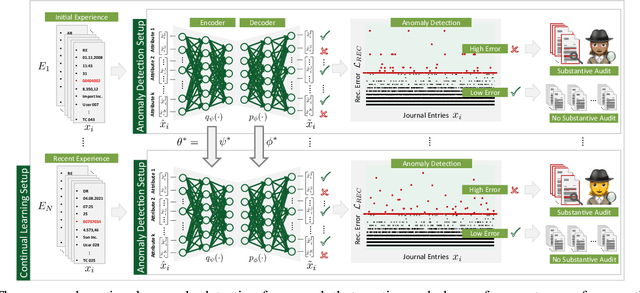
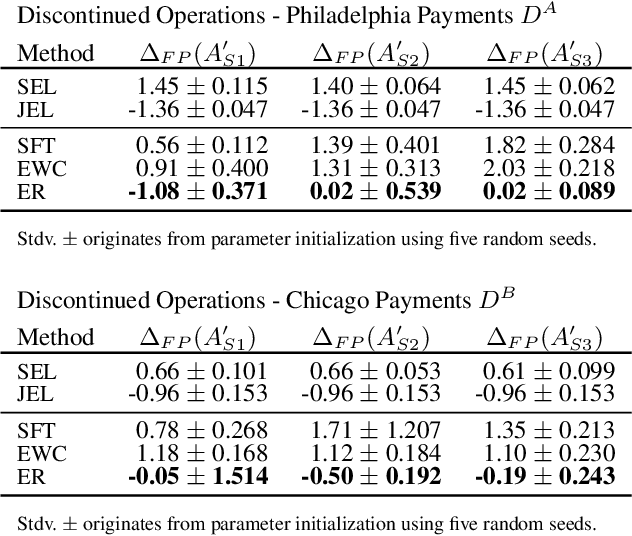
International audit standards require the direct assessment of a financial statement's underlying accounting journal entries. Driven by advances in artificial intelligence, deep-learning inspired audit techniques emerged to examine vast quantities of journal entry data. However, in regular audits, most of the proposed methods are applied to learn from a comparably stationary journal entry population, e.g., of a financial quarter or year. Ignoring situations where audit relevant distribution changes are not evident in the training data or become incrementally available over time. In contrast, in continuous auditing, deep-learning models are continually trained on a stream of recorded journal entries, e.g., of the last hour. Resulting in situations where previous knowledge interferes with new information and will be entirely overwritten. This work proposes a continual anomaly detection framework to overcome both challenges and designed to learn from a stream of journal entry data experiences. The framework is evaluated based on deliberately designed audit scenarios and two real-world datasets. Our experimental results provide initial evidence that such a learning scheme offers the ability to reduce false-positive alerts and false-negative decisions.
GateFormer: Speeding Up News Feed Recommendation with Input Gated Transformers
Jan 12, 2022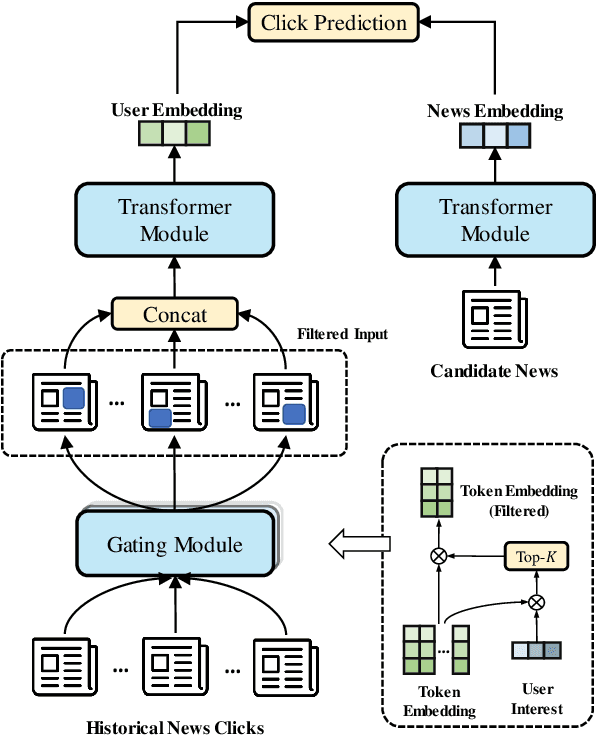
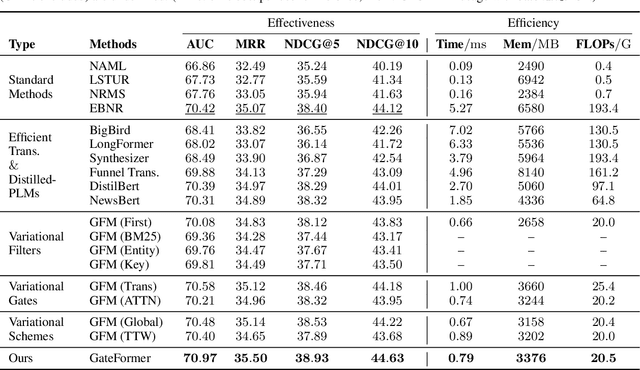
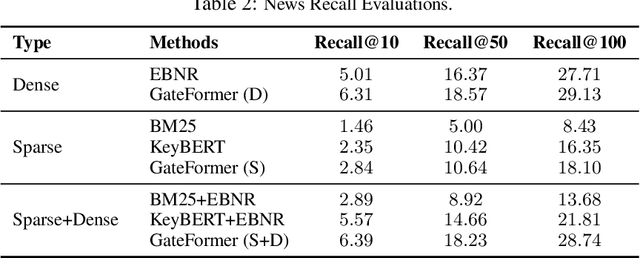

News feed recommendation is an important web service. In recent years, pre-trained language models (PLMs) have been intensively applied to improve the recommendation quality. However, the utilization of these deep models is limited in many aspects, such as lack of explainability and being incompatible with the existing inverted index systems. Above all, the PLMs based recommenders are inefficient, as the encoding of user-side information will take huge computation costs. Although the computation can be accelerated with efficient transformers or distilled PLMs, it is still not enough to make timely recommendations for the active users, who are associated with super long news browsing histories. In this work, we tackle the efficient news recommendation problem from a distinctive perspective. Instead of relying on the entire input (i.e., the collection of news articles a user ever browsed), we argue that the user's interest can be fully captured merely with those representative keywords. Motivated by this, we propose GateFormer, where the input data is gated before feeding into transformers. The gating module is made personalized, lightweight and end-to-end learnable, such that it may perform accurate and efficient filtering of informative user input. GateFormer achieves highly impressive performances in experiments, where it notably outperforms the existing acceleration approaches in both accuracy and efficiency. We also surprisingly find that even with over 10-fold compression of the original input, GateFormer is still able to maintain on-par performances with the SOTA methods.
Quaternion-Valued Convolutional Neural Network Applied for Acute Lymphoblastic Leukemia Diagnosis
Dec 13, 2021
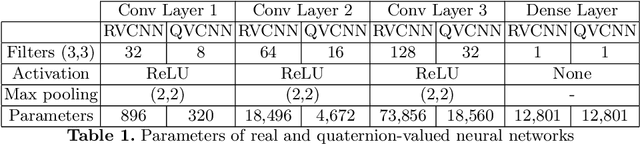
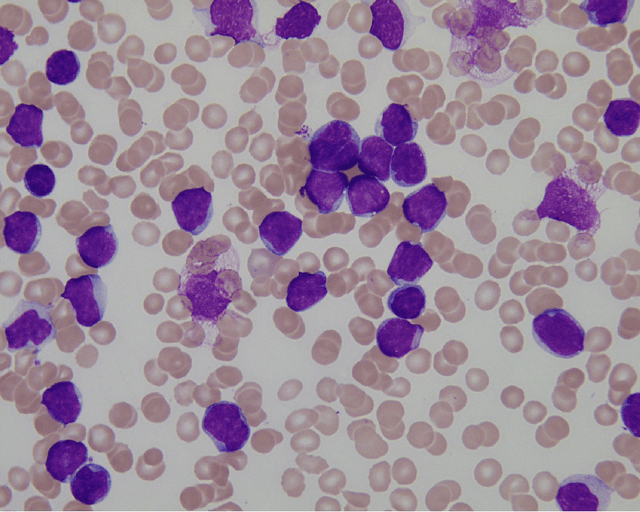

The field of neural networks has seen significant advances in recent years with the development of deep and convolutional neural networks. Although many of the current works address real-valued models, recent studies reveal that neural networks with hypercomplex-valued parameters can better capture, generalize, and represent the complexity of multidimensional data. This paper explores the quaternion-valued convolutional neural network application for a pattern recognition task from medicine, namely, the diagnosis of acute lymphoblastic leukemia. Precisely, we compare the performance of real-valued and quaternion-valued convolutional neural networks to classify lymphoblasts from the peripheral blood smear microscopic images. The quaternion-valued convolutional neural network achieved better or similar performance than its corresponding real-valued network but using only 34% of its parameters. This result confirms that quaternion algebra allows capturing and extracting information from a color image with fewer parameters.
Adaptive Gaussian Process based Stochastic Trajectory Optimization for Motion Planning
Dec 30, 2021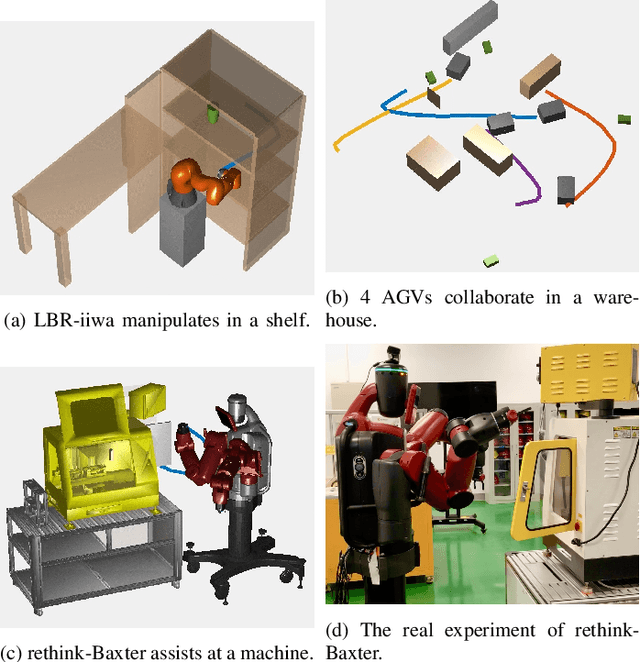
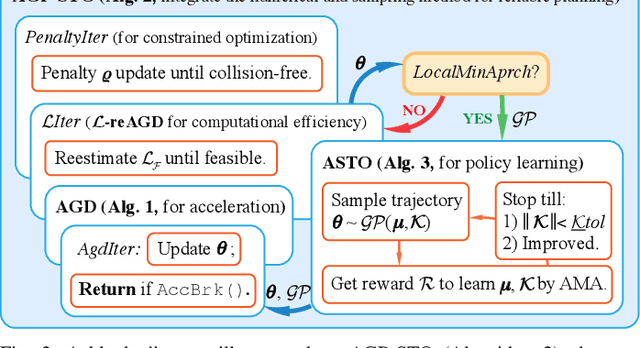
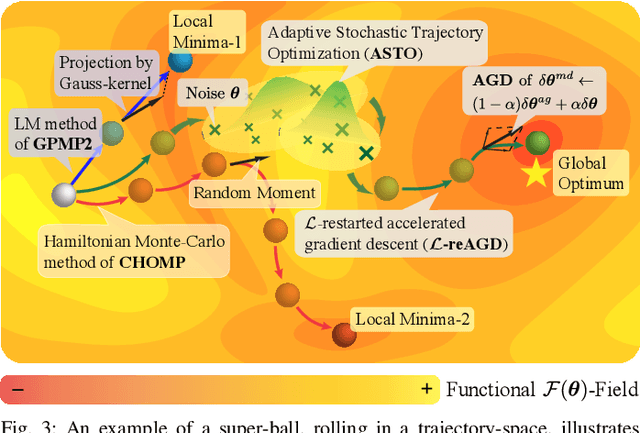
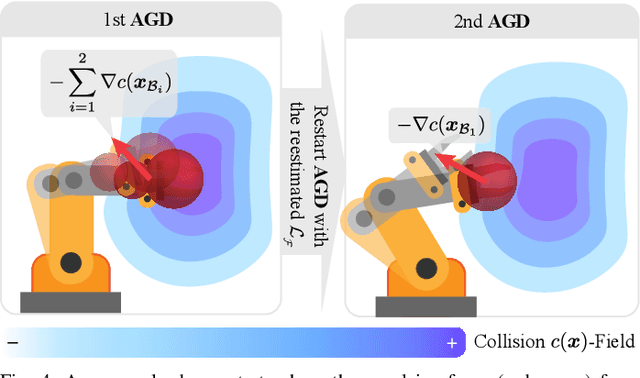
We propose a new formulation of optimal motion planning (OMP) algorithm for robots operating in a hazardous environment, called adaptive Gaussian-process based stochastic trajectory optimization (AGP-STO). It first restarts the accelerated gradient descent with the reestimated Lipschitz constant (L-reAGD) to improve the computation efficiency, only requiring 1st-order momentum. However, it still cannot infer a global optimum of the nonconvex problem, informed by the prior information of Gaussian-process (GP) and obstacles. So it then integrates the adaptive stochastic trajectory optimization (ASTO) in the L-reestimation process to learn the GP-prior rewarded by the important samples via accelerated moving averaging (AMA). Moreover, we introduce the incremental optimal motion planning (iOMP) to upgrade AGP-STO to iAGP-STO. It interpolates the trajectory incrementally among the previously optimized waypoints to ensure time-continuous safety. Finally, we benchmark iAGP-STO against the numerical (CHOMP, TrajOpt, GPMP) and sampling (STOMP, RRT-Connect) methods and conduct the tuning experiment of key parameters to show how the integration of L-reAGD, ASTO, and iOMP elevates computation efficiency and reliability. Moreover, the implementation of iAGP- STO on LBR-iiwa, multi-AGV, and rethink-Baxter demonstrates its application in manipulation, collaboration, and assistance.
PIETS: Parallelised Irregularity Encoders for Forecasting with Heterogeneous Time-Series
Oct 06, 2021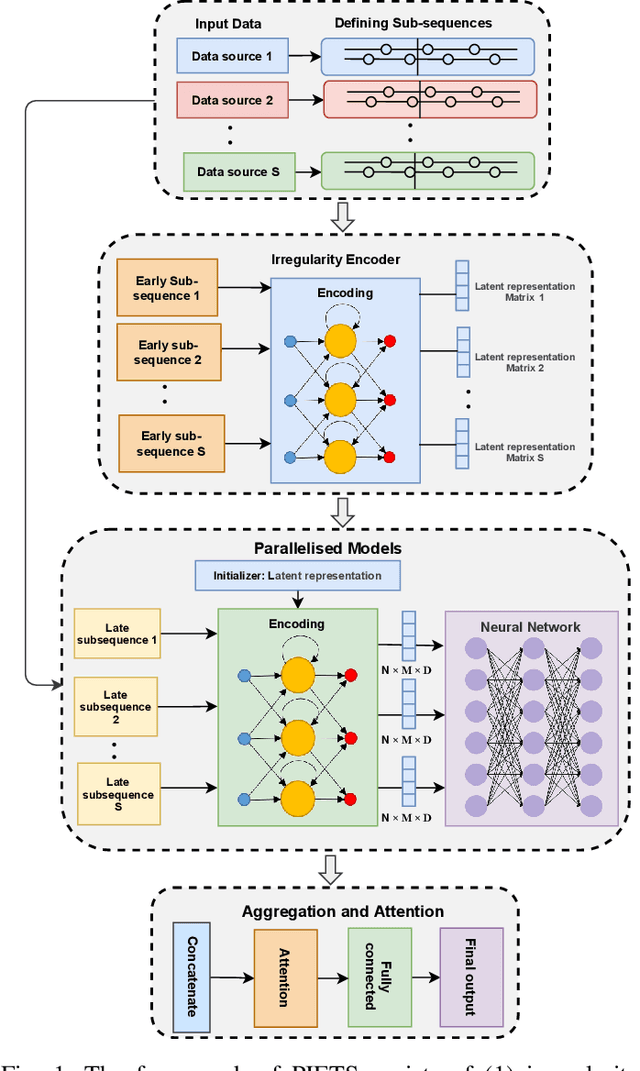
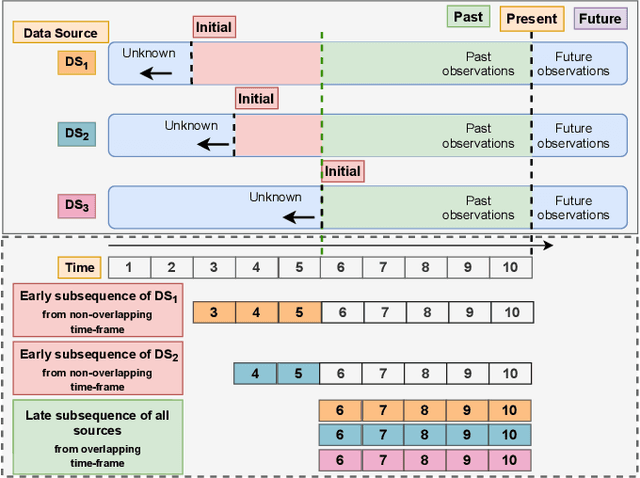
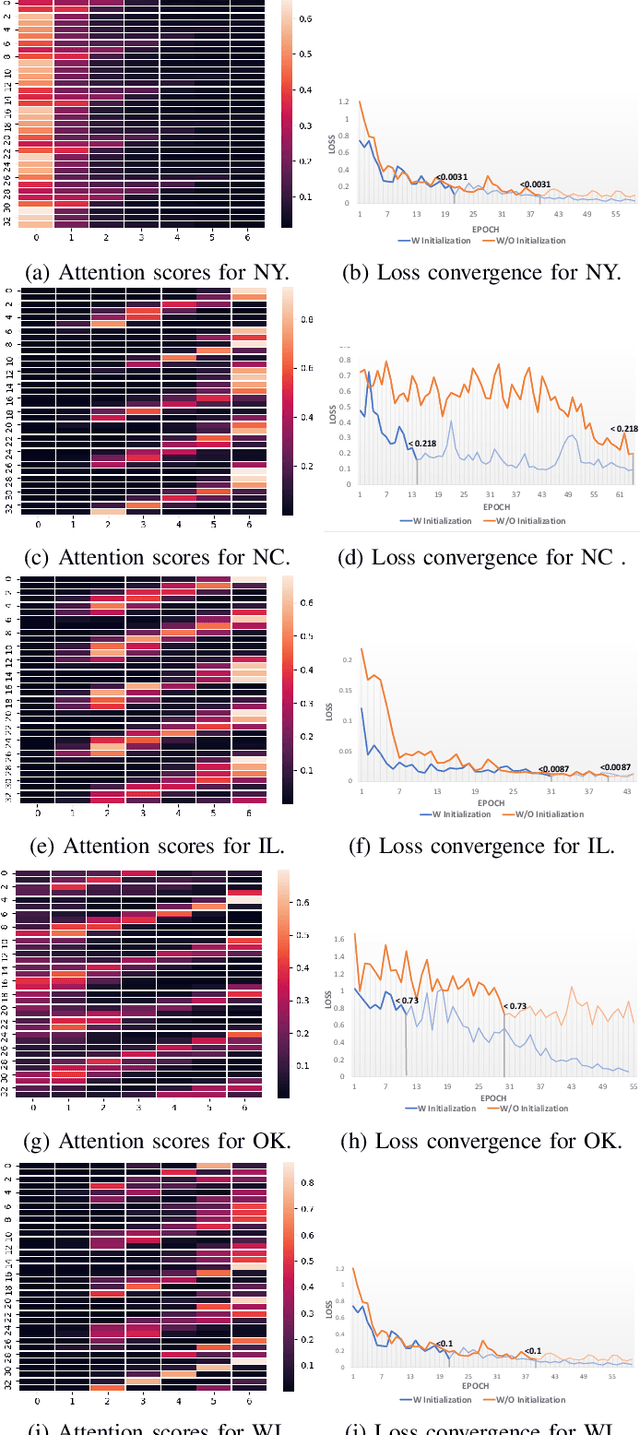
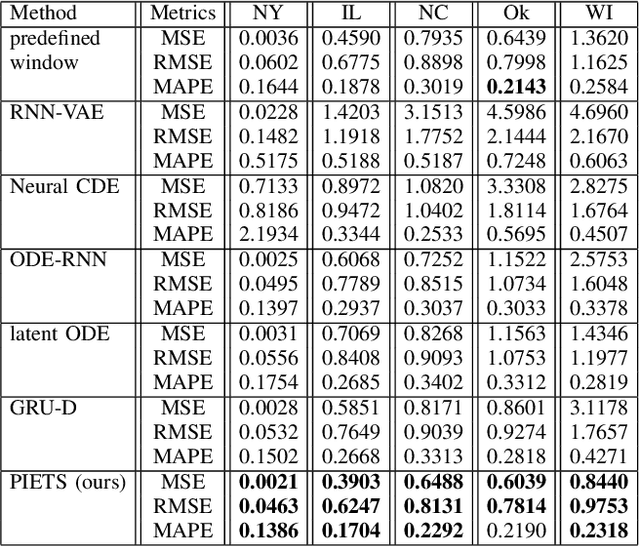
Heterogeneity and irregularity of multi-source data sets present a significant challenge to time-series analysis. In the literature, the fusion of multi-source time-series has been achieved either by using ensemble learning models which ignore temporal patterns and correlation within features or by defining a fixed-size window to select specific parts of the data sets. On the other hand, many studies have shown major improvement to handle the irregularity of time-series, yet none of these studies has been applied to multi-source data. In this work, we design a novel architecture, PIETS, to model heterogeneous time-series. PIETS has the following characteristics: (1) irregularity encoders for multi-source samples that can leverage all available information and accelerate the convergence of the model; (2) parallelised neural networks to enable flexibility and avoid information overwhelming; and (3) attention mechanism that highlights different information and gives high importance to the most related data. Through extensive experiments on real-world data sets related to COVID-19, we show that the proposed architecture is able to effectively model heterogeneous temporal data and outperforms other state-of-the-art approaches in the prediction task.
PAANet: Progressive Alternating Attention for Automatic Medical Image Segmentation
Nov 20, 2021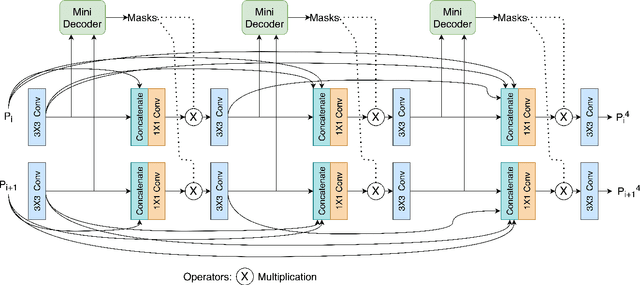
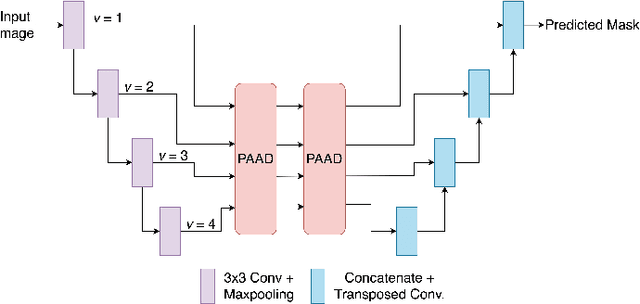
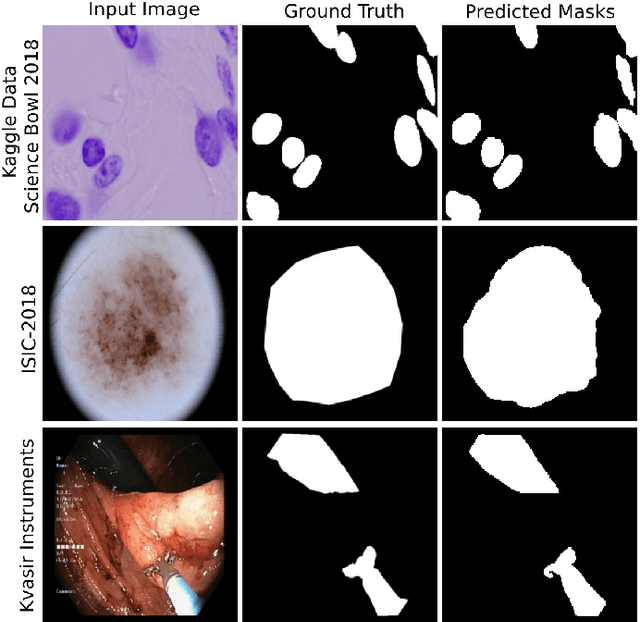
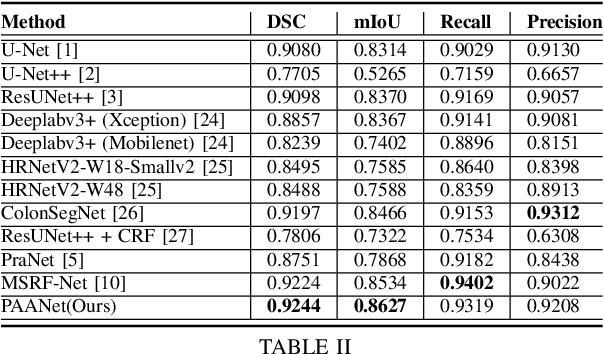
Medical image segmentation can provide detailed information for clinical analysis which can be useful for scenarios where the detailed location of a finding is important. Knowing the location of disease can play a vital role in treatment and decision-making. Convolutional neural network (CNN) based encoder-decoder techniques have advanced the performance of automated medical image segmentation systems. Several such CNN-based methodologies utilize techniques such as spatial- and channel-wise attention to enhance performance. Another technique that has drawn attention in recent years is residual dense blocks (RDBs). The successive convolutional layers in densely connected blocks are capable of extracting diverse features with varied receptive fields and thus, enhancing performance. However, consecutive stacked convolutional operators may not necessarily generate features that facilitate the identification of the target structures. In this paper, we propose a progressive alternating attention network (PAANet). We develop progressive alternating attention dense (PAAD) blocks, which construct a guiding attention map (GAM) after every convolutional layer in the dense blocks using features from all scales. The GAM allows the following layers in the dense blocks to focus on the spatial locations relevant to the target region. Every alternate PAAD block inverts the GAM to generate a reverse attention map which guides ensuing layers to extract boundary and edge-related information, refining the segmentation process. Our experiments on three different biomedical image segmentation datasets exhibit that our PAANet achieves favourable performance when compared to other state-of-the-art methods.
3D Scene Understanding at Urban Intersection using Stereo Vision and Digital Map
Dec 10, 2021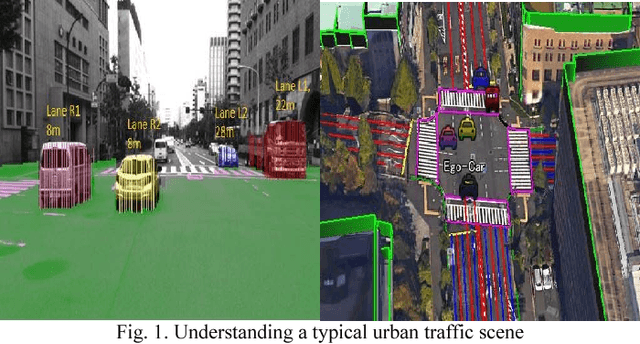
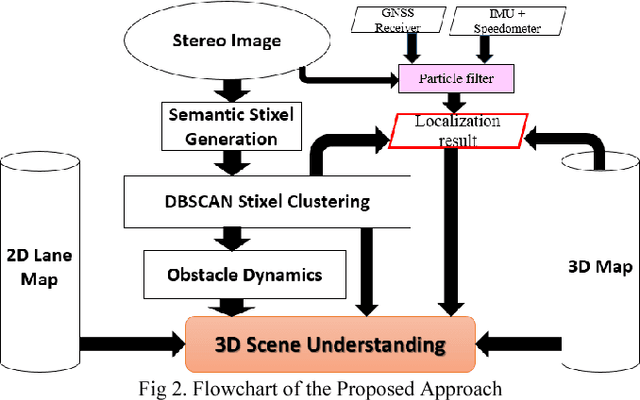
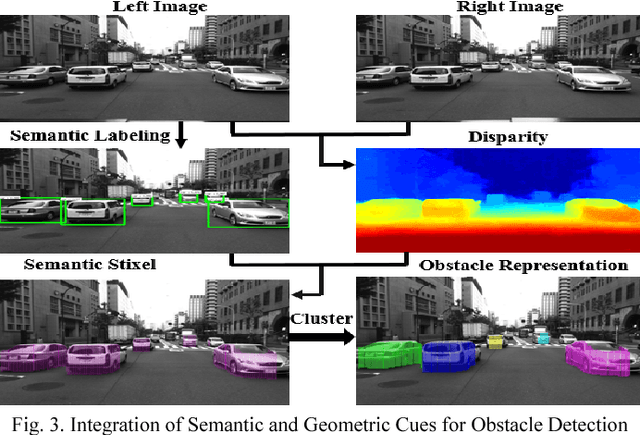
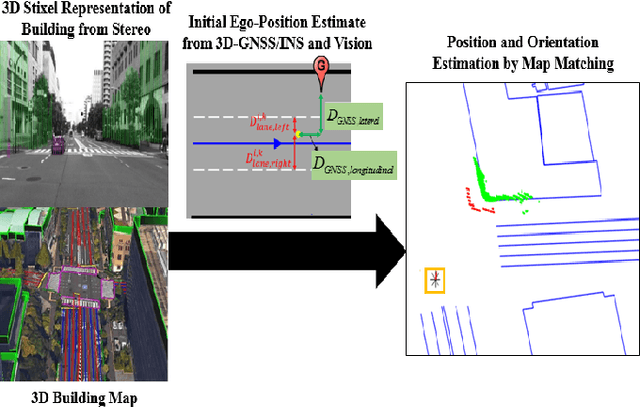
The driving behavior at urban intersections is very complex. It is thus crucial for autonomous vehicles to comprehensively understand challenging urban traffic scenes in order to navigate intersections and prevent accidents. In this paper, we introduce a stereo vision and 3D digital map based approach to spatially and temporally analyze the traffic situation at urban intersections. Stereo vision is used to detect, classify and track obstacles, while a 3D digital map is used to improve ego-localization and provide context in terms of road-layout information. A probabilistic approach that temporally integrates these geometric, semantic, dynamic and contextual cues is presented. We qualitatively and quantitatively evaluate our proposed technique on real traffic data collected at an urban canyon in Tokyo to demonstrate the efficacy of the system in providing comprehensive awareness of the traffic surroundings.
* 6 pages, 6 figures