 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Attention Mechanism Meets with Hybrid Dense Network for Hyperspectral Image Classification
Jan 04, 2022
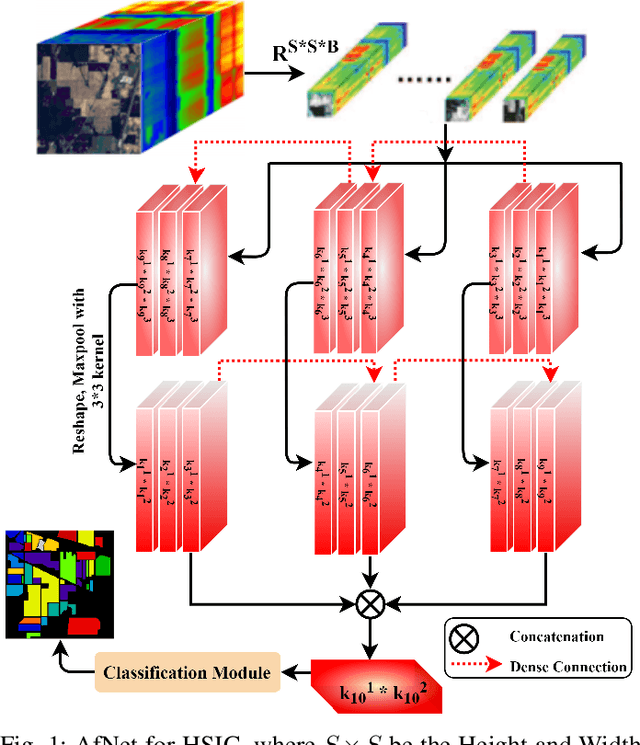
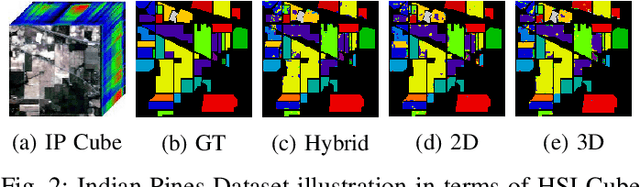
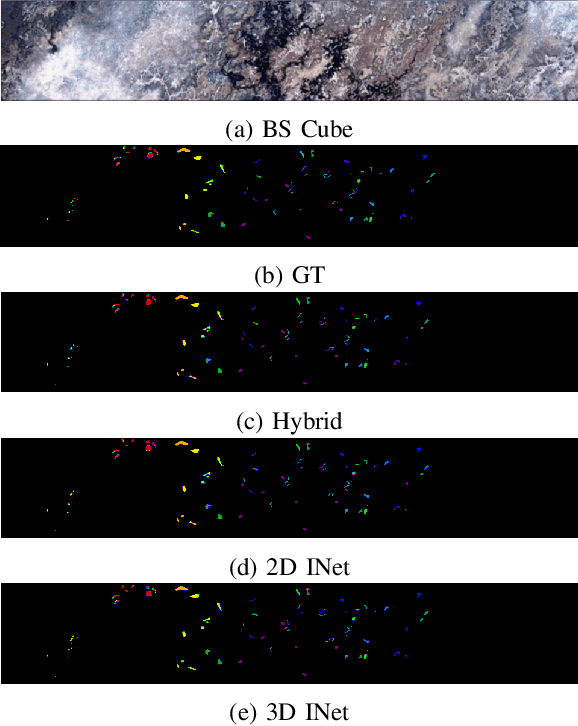
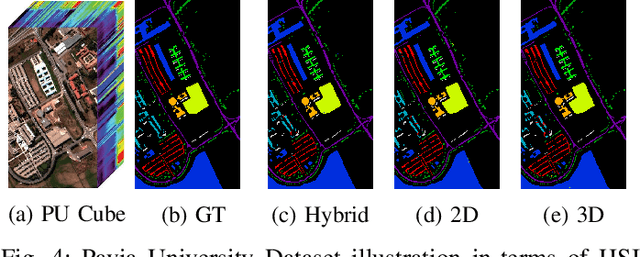
Convolutional Neural Networks (CNN) are more suitable, indeed. However, fixed kernel sizes make traditional CNN too specific, neither flexible nor conducive to feature learning, thus impacting on the classification accuracy. The convolution of different kernel size networks may overcome this problem by capturing more discriminating and relevant information. In light of this, the proposed solution aims at combining the core idea of 3D and 2D Inception net with the Attention mechanism to boost the HSIC CNN performance in a hybrid scenario. The resulting \textit{attention-fused hybrid network} (AfNet) is based on three attention-fused parallel hybrid sub-nets with different kernels in each block repeatedly using high-level features to enhance the final ground-truth maps. In short, AfNet is able to selectively filter out the discriminative features critical for classification. Several tests on HSI datasets provided competitive results for AfNet compared to state-of-the-art models. The proposed pipeline achieved, indeed, an overall accuracy of 97\% for the Indian Pines, 100\% for Botswana, 99\% for Pavia University, Pavia Center, and Salinas datasets.
Dual Path Structural Contrastive Embeddings for Learning Novel Objects
Jan 04, 2022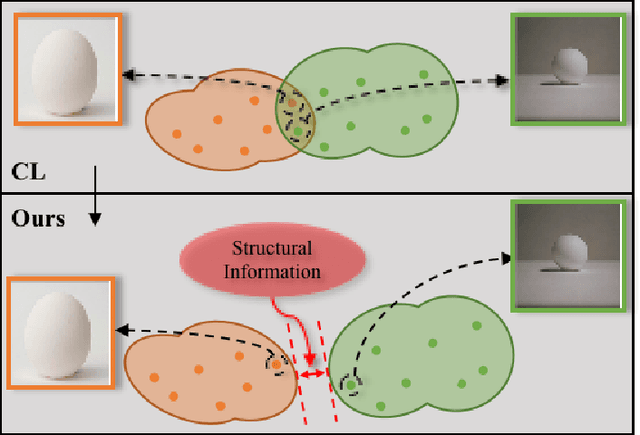
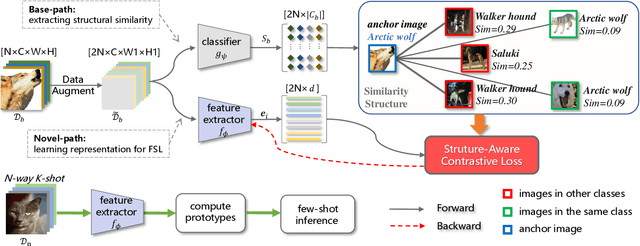
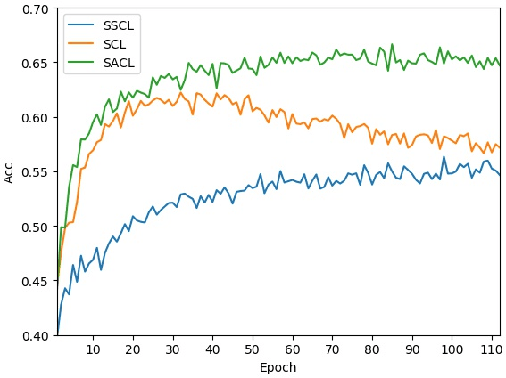

Learning novel classes from a very few labeled samples has attracted increasing attention in machine learning areas. Recent research on either meta-learning based or transfer-learning based paradigm demonstrates that gaining information on a good feature space can be an effective solution to achieve favorable performance on few-shot tasks. In this paper, we propose a simple but effective paradigm that decouples the tasks of learning feature representations and classifiers and only learns the feature embedding architecture from base classes via the typical transfer-learning training strategy. To maintain both the generalization ability across base and novel classes and discrimination ability within each class, we propose a dual path feature learning scheme that effectively combines structural similarity with contrastive feature construction. In this way, both inner-class alignment and inter-class uniformity can be well balanced, and result in improved performance. Experiments on three popular benchmarks show that when incorporated with a simple prototype based classifier, our method can still achieve promising results for both standard and generalized few-shot problems in either an inductive or transductive inference setting.
S-multi-SNE: Semi-Supervised Classification and Visualisation of Multi-View Data
Nov 05, 2021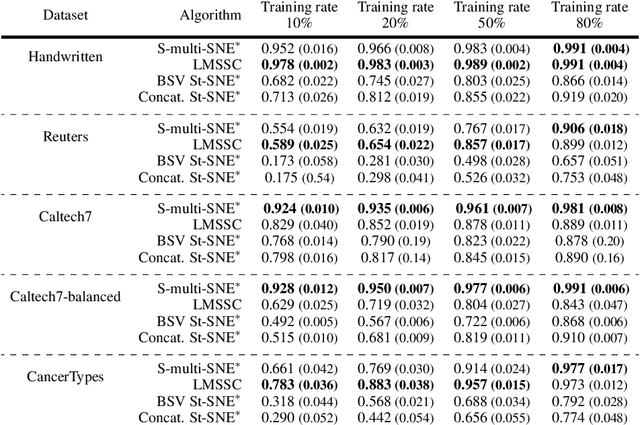
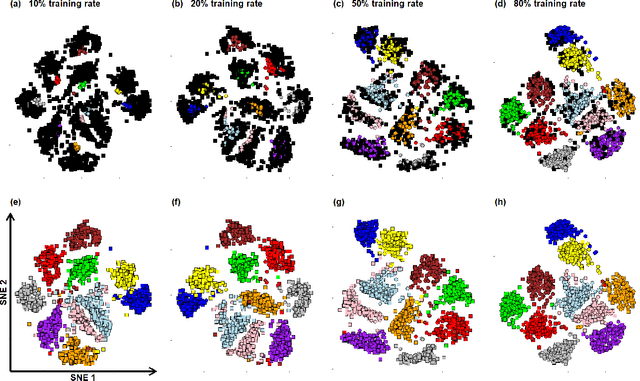
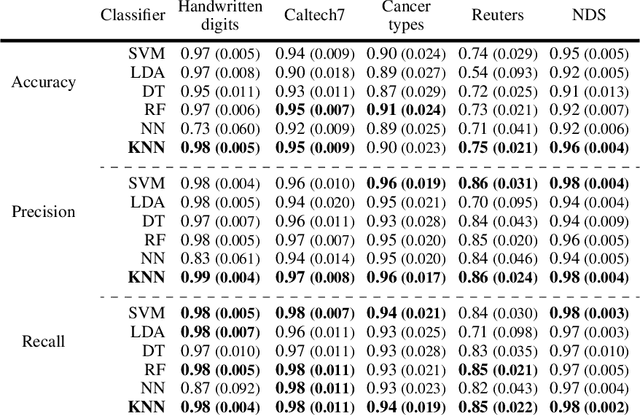
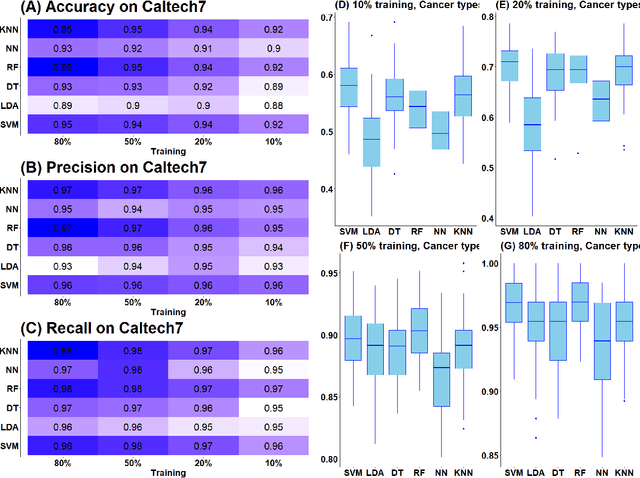
An increasing number of multi-view data are being published by studies in several fields. This type of data corresponds to multiple data-views, each representing a different aspect of the same set of samples. We have recently proposed multi-SNE, an extension of t-SNE, that produces a single visualisation of multi-view data. The multi-SNE approach provides low-dimensional embeddings of the samples, produced by being updated iteratively through the different data-views. Here, we further extend multi-SNE to a semi-supervised approach, that classifies unlabelled samples by regarding the labelling information as an extra data-view. We look deeper into the performance, limitations and strengths of multi-SNE and its extension, S-multi-SNE, by applying the two methods on various multi-view datasets with different challenges. We show that by including the labelling information, the projection of the samples improves drastically and it is accompanied by a strong classification performance.
Towards Handling Unconstrained User Preferences in Dialogue
Sep 17, 2021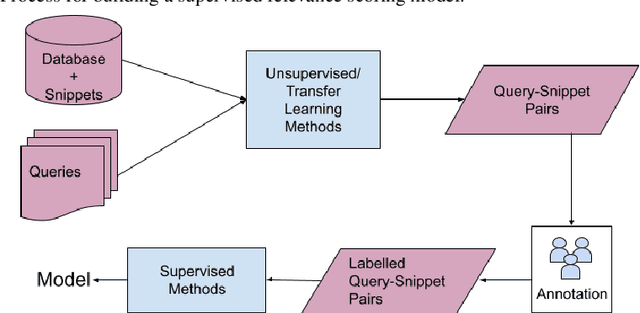

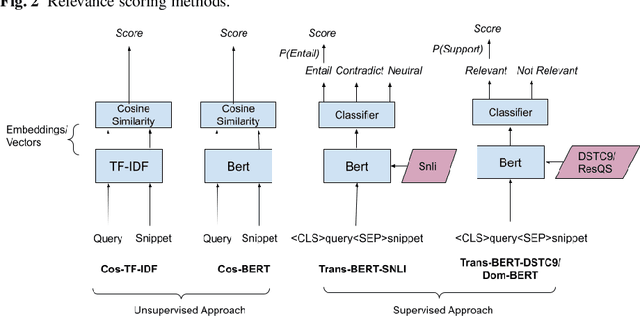
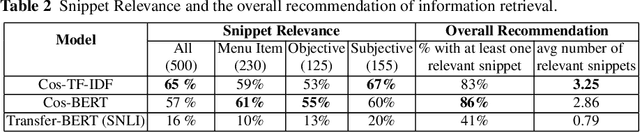
A user input to a schema-driven dialogue information navigation system, such as venue search, is typically constrained by the underlying database which restricts the user to specify a predefined set of preferences, or slots, corresponding to the database fields. We envision a more natural information navigation dialogue interface where a user has flexibility to specify unconstrained preferences that may not match a predefined schema. We propose to use information retrieval from unstructured knowledge to identify entities relevant to a user request. We update the Cambridge restaurants database with unstructured knowledge snippets (reviews and information from the web) for each of the restaurants and annotate a set of query-snippet pairs with a relevance label. We use the annotated dataset to train and evaluate snippet relevance classifiers, as a proxy to evaluating recommendation accuracy. We show that with a pretrained transformer model as an encoder, an unsupervised/supervised classifier achieves a weighted F1 of .661/.856.
Robust 3D Scene Segmentation through Hierarchical and Learnable Part-Fusion
Nov 16, 2021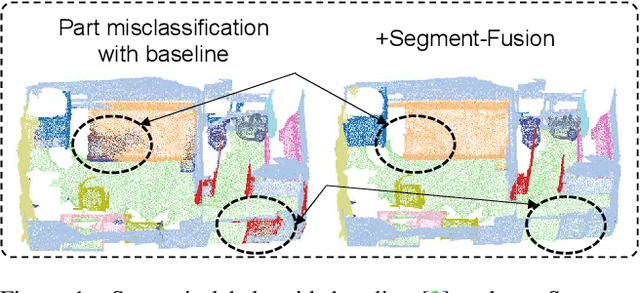
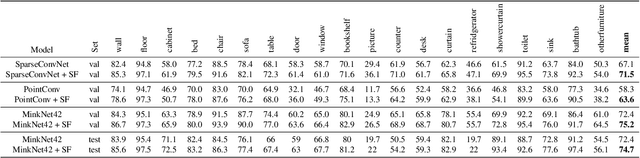
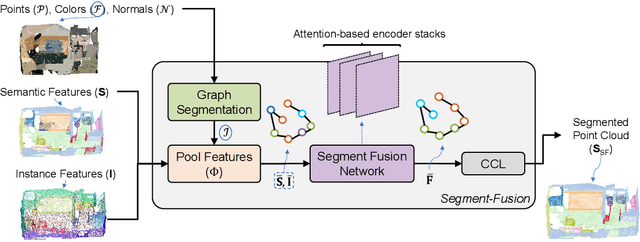
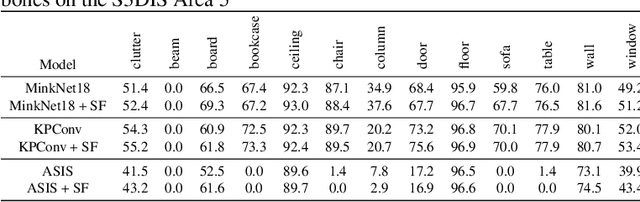
3D semantic segmentation is a fundamental building block for several scene understanding applications such as autonomous driving, robotics and AR/VR. Several state-of-the-art semantic segmentation models suffer from the part misclassification problem, wherein parts of the same object are labelled incorrectly. Previous methods have utilized hierarchical, iterative methods to fuse semantic and instance information, but they lack learnability in context fusion, and are computationally complex and heuristic driven. This paper presents Segment-Fusion, a novel attention-based method for hierarchical fusion of semantic and instance information to address the part misclassifications. The presented method includes a graph segmentation algorithm for grouping points into segments that pools point-wise features into segment-wise features, a learnable attention-based network to fuse these segments based on their semantic and instance features, and followed by a simple yet effective connected component labelling algorithm to convert segment features to instance labels. Segment-Fusion can be flexibly employed with any network architecture for semantic/instance segmentation. It improves the qualitative and quantitative performance of several semantic segmentation backbones by upto 5% when evaluated on the ScanNet and S3DIS datasets.
Neural Piecewise-Constant Delay Differential Equations
Jan 04, 2022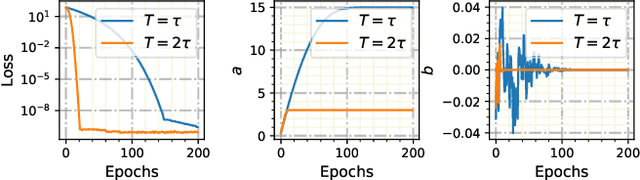
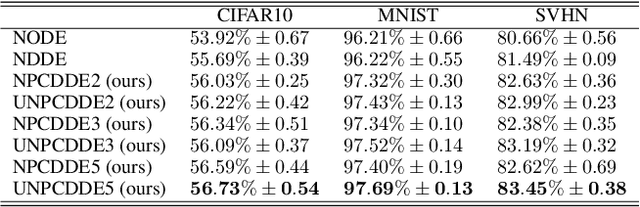
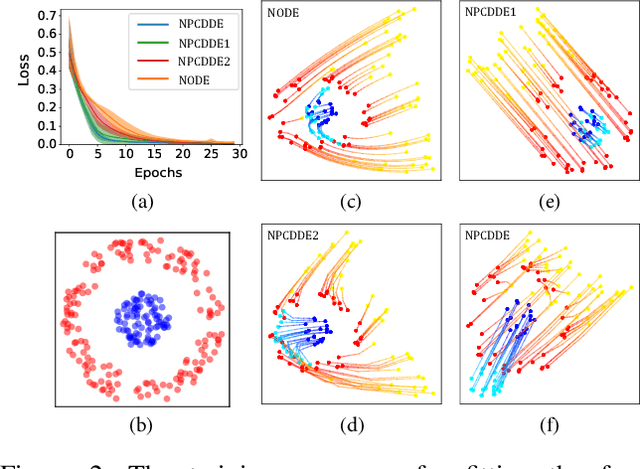
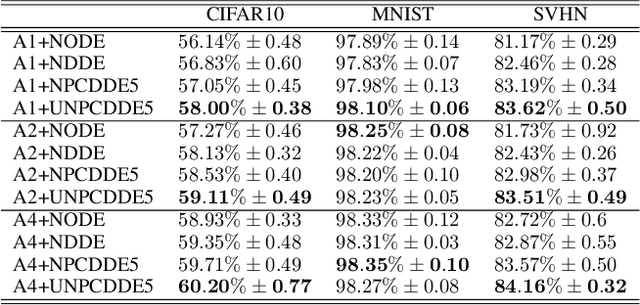
Continuous-depth neural networks, such as the Neural Ordinary Differential Equations (ODEs), have aroused a great deal of interest from the communities of machine learning and data science in recent years, which bridge the connection between deep neural networks and dynamical systems. In this article, we introduce a new sort of continuous-depth neural network, called the Neural Piecewise-Constant Delay Differential Equations (PCDDEs). Here, unlike the recently proposed framework of the Neural Delay Differential Equations (DDEs), we transform the single delay into the piecewise-constant delay(s). The Neural PCDDEs with such a transformation, on one hand, inherit the strength of universal approximating capability in Neural DDEs. On the other hand, the Neural PCDDEs, leveraging the contributions of the information from the multiple previous time steps, further promote the modeling capability without augmenting the network dimension. With such a promotion, we show that the Neural PCDDEs do outperform the several existing continuous-depth neural frameworks on the one-dimensional piecewise-constant delay population dynamics and real-world datasets, including MNIST, CIFAR10, and SVHN.
DSSL: Deep Surroundings-person Separation Learning for Text-based Person Retrieval
Sep 12, 2021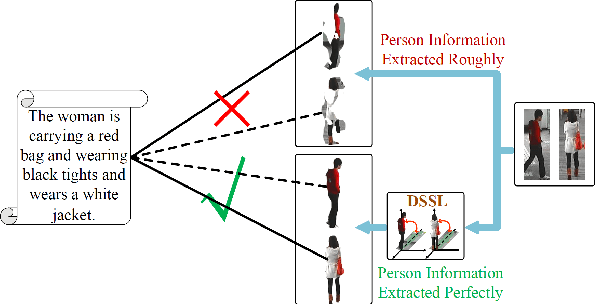

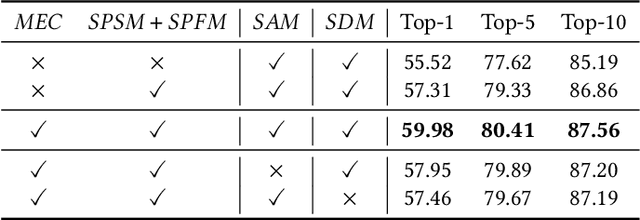
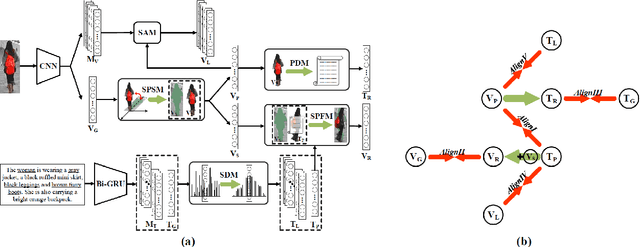
Many previous methods on text-based person retrieval tasks are devoted to learning a latent common space mapping, with the purpose of extracting modality-invariant features from both visual and textual modality. Nevertheless, due to the complexity of high-dimensional data, the unconstrained mapping paradigms are not able to properly catch discriminative clues about the corresponding person while drop the misaligned information. Intuitively, the information contained in visual data can be divided into person information (PI) and surroundings information (SI), which are mutually exclusive from each other. To this end, we propose a novel Deep Surroundings-person Separation Learning (DSSL) model in this paper to effectively extract and match person information, and hence achieve a superior retrieval accuracy. A surroundings-person separation and fusion mechanism plays the key role to realize an accurate and effective surroundings-person separation under a mutually exclusion constraint. In order to adequately utilize multi-modal and multi-granular information for a higher retrieval accuracy, five diverse alignment paradigms are adopted. Extensive experiments are carried out to evaluate the proposed DSSL on CUHK-PEDES, which is currently the only accessible dataset for text-base person retrieval task. DSSL achieves the state-of-the-art performance on CUHK-PEDES. To properly evaluate our proposed DSSL in the real scenarios, a Real Scenarios Text-based Person Reidentification (RSTPReid) dataset is constructed to benefit future research on text-based person retrieval, which will be publicly available.
Active Sampling for Pairwise Comparisons via Approximate Message Passing and Information Gain Maximization
Apr 12, 2020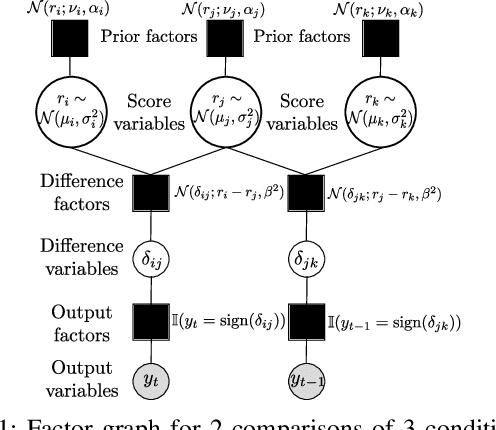
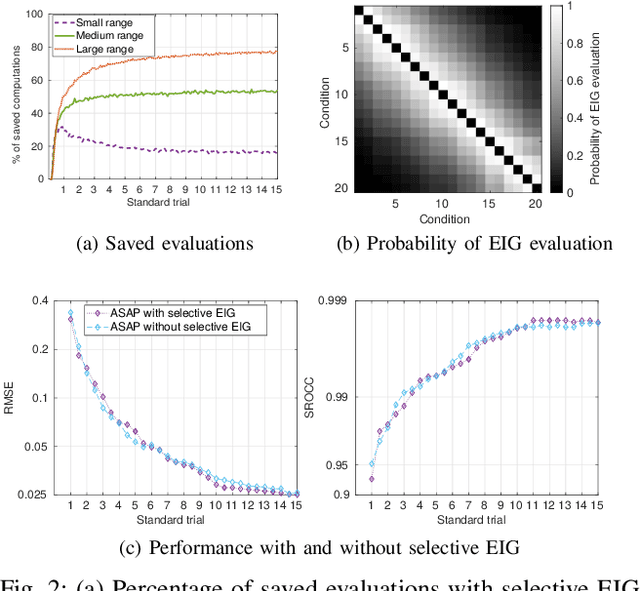
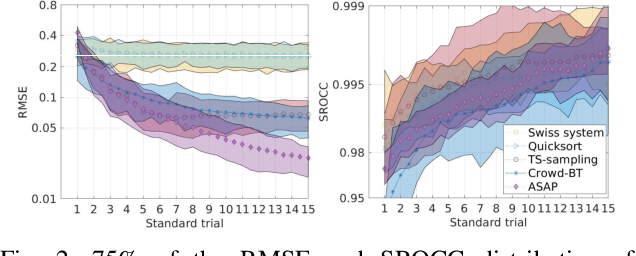
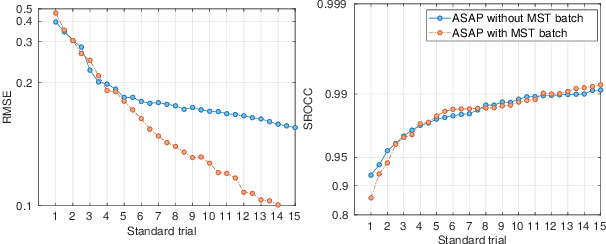
Pairwise comparison data arise in many domains with subjective assessment experiments, for example in image and video quality assessment. In these experiments observers are asked to express a preference between two conditions. However, many pairwise comparison protocols require a large number of comparisons to infer accurate scores, which may be unfeasible when each comparison is time-consuming (e.g. videos) or expensive (e.g. medical imaging). This motivates the use of an active sampling algorithm that chooses only the most informative pairs for comparison. In this paper we propose ASAP, an active sampling algorithm based on approximate message passing and expected information gain maximization. Unlike most existing methods, which rely on partial updates of the posterior distribution, we are able to perform full updates and therefore much improve the accuracy of the inferred scores. The algorithm relies on three techniques for reducing computational cost: inference based on approximate message passing, selective evaluations of the information gain, and selecting pairs in a batch that forms a minimum spanning tree of the inverse of information gain. We demonstrate, with real and synthetic data, that ASAP offers the highest accuracy of inferred scores compared to the existing methods. We also provide an open-source GPU implementation of ASAP for large-scale experiments.
RetroComposer: Discovering Novel Reactions by Composing Templates for Retrosynthesis Prediction
Dec 20, 2021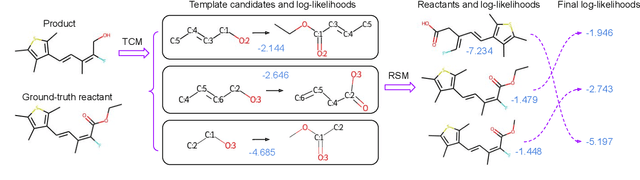
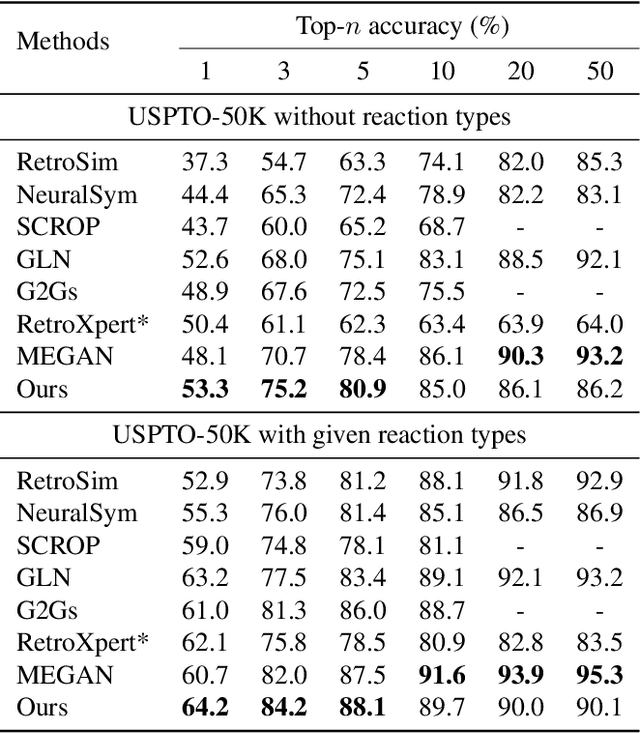
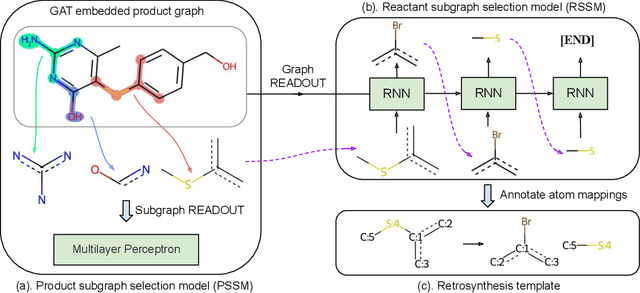
The main target of retrosynthesis is to recursively decompose desired molecules into available building blocks. Existing template-based retrosynthesis methods follow a template selection stereotype and suffer from the limited training templates, which prevents them from discovering novel reactions. To overcome the limitation, we propose an innovative retrosynthesis prediction framework that can compose novel templates beyond training templates. So far as we know, this is the first method that can find novel templates for retrosynthesis prediction. Besides, we propose an effective reactant candidates scoring model that can capture atom-level transformation information, and it helps our method outperform existing methods by a large margin. Experimental results show that our method can produce novel templates for 328 test reactions in the USPTO-50K dataset, including 21 test reactions that are not covered by the training templates.
Hybrid Reflection Modulation
Nov 16, 2021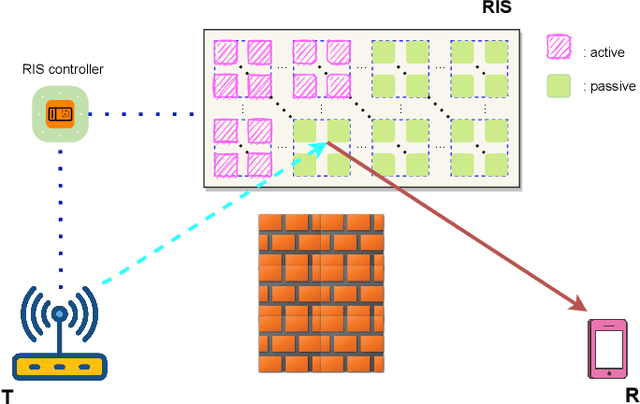
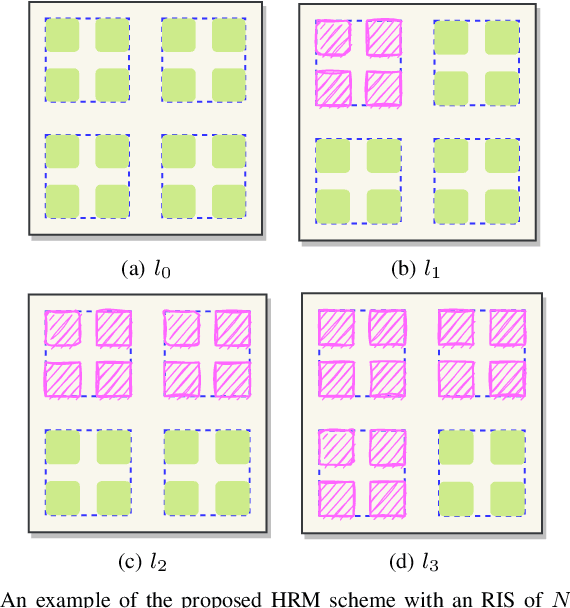
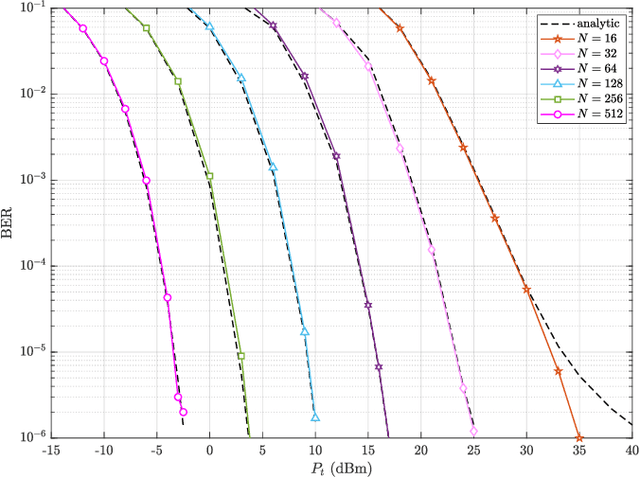
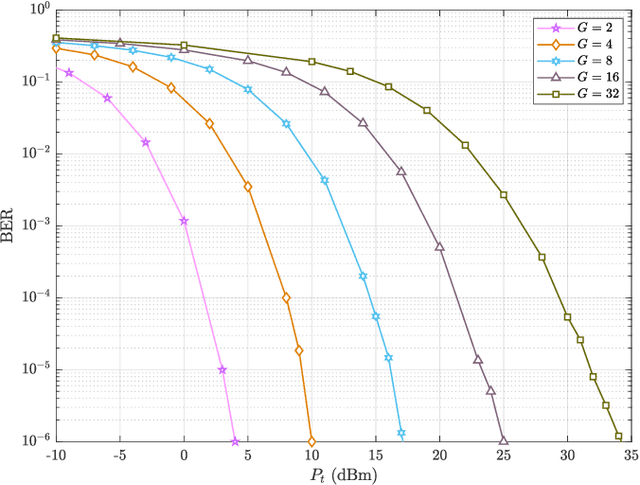
Reconfigurable intelligent surface (RIS)-empowered communication has emerged as a novel concept for customizing future wireless environments in a cost- and energy-efficient way. However, due to double path loss, existing fully passive RIS systems that purely reflect the incident signals into preferred directions attain an unsatisfactory performance improvement over the traditional wireless networks in certain conditions. To overcome this bottleneck, we propose a novel transmission scheme, named hybrid reflection modulation (HRM), exploiting both active and passive reflecting elements at the RIS and their combinations, which enables to convey information without using any radio frequency (RF) chains. In the HRM scheme, the active reflecting elements using additional power amplifiers are able to amplify and reflect the incoming signal, while the remaining passive elements can simply reflect the signals with appropriate phase shifts. Based on this novel transmission model, we obtain an upper bound for the average bit error probability (ABEP), and derive achievable rate of the system using an information theoretic approach. Moreover, comprehensive computer simulations are performed to prove the superiority of the proposed HRM scheme over existing fully passive, fully active and reflection modulation (RM) systems.