 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unsupervised Temporal Video Grounding with Deep Semantic Clustering
Jan 14, 2022

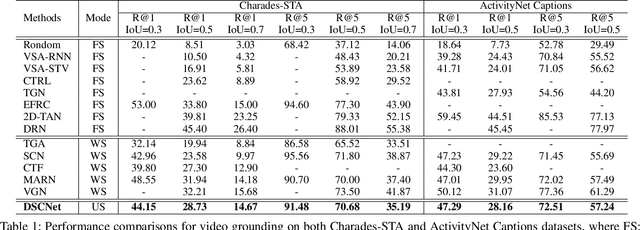
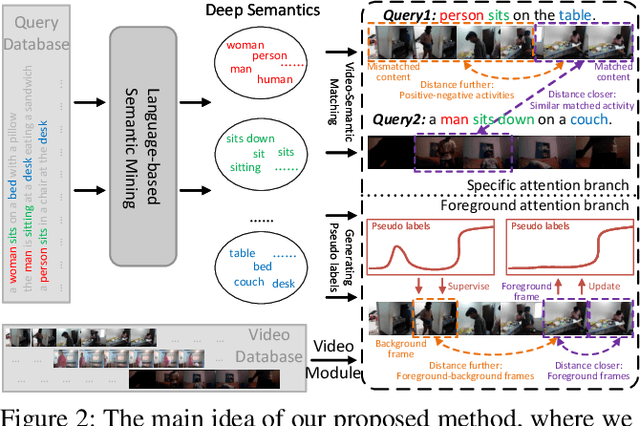

Temporal video grounding (TVG) aims to localize a target segment in a video according to a given sentence query. Though respectable works have made decent achievements in this task, they severely rely on abundant video-query paired data, which is expensive and time-consuming to collect in real-world scenarios. In this paper, we explore whether a video grounding model can be learned without any paired annotations. To the best of our knowledge, this paper is the first work trying to address TVG in an unsupervised setting. Considering there is no paired supervision, we propose a novel Deep Semantic Clustering Network (DSCNet) to leverage all semantic information from the whole query set to compose the possible activity in each video for grounding. Specifically, we first develop a language semantic mining module, which extracts implicit semantic features from the whole query set. Then, these language semantic features serve as the guidance to compose the activity in video via a video-based semantic aggregation module. Finally, we utilize a foreground attention branch to filter out the redundant background activities and refine the grounding results. To validate the effectiveness of our DSCNet, we conduct experiments on both ActivityNet Captions and Charades-STA datasets. The results demonstrate that DSCNet achieves competitive performance, and even outperforms most weakly-supervised approaches.
Multi-Trigger-Key: Towards Multi-Task Privacy Preserving In Deep Learning
Oct 06, 2021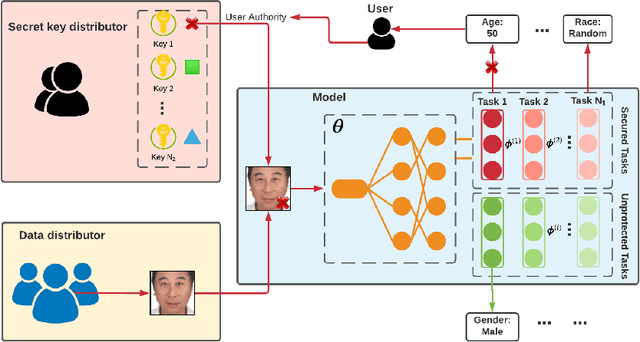
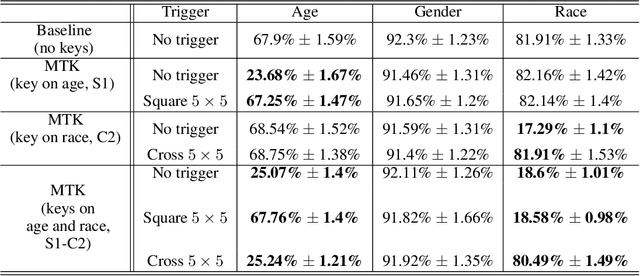

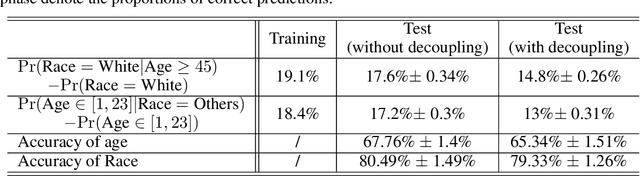
Deep learning-based Multi-Task Classification (MTC) is widely used in applications like facial attributes and healthcare that warrant strong privacy guarantees. In this work, we aim to protect sensitive information in the inference phase of MTC and propose a novel Multi-Trigger-Key (MTK) framework to achieve the privacy-preserving objective. MTK associates each secured task in the multi-task dataset with a specifically designed trigger-key. The true information can be revealed by adding the trigger-key if the user is authorized. We obtain such an MTK model by training it with a newly generated training set. To address the information leakage malaise resulting from correlations among different tasks, we generalize the training process by incorporating an MTK decoupling process with a controllable trade-off between the protective efficacy and the model performance. Theoretical guarantees and experimental results demonstrate the effectiveness of the privacy protection without appreciable hindering on the model performance.
PROVES: Establishing Image Provenance using Semantic Signatures
Oct 21, 2021
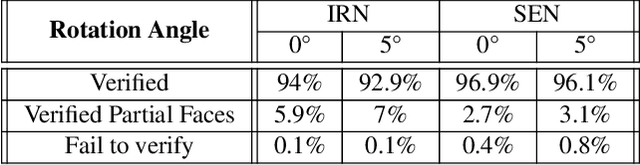
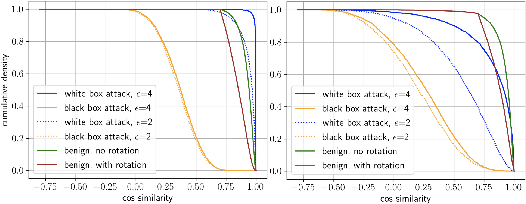
Modern AI tools, such as generative adversarial networks, have transformed our ability to create and modify visual data with photorealistic results. However, one of the deleterious side-effects of these advances is the emergence of nefarious uses in manipulating information in visual data, such as through the use of deep fakes. We propose a novel architecture for preserving the provenance of semantic information in images to make them less susceptible to deep fake attacks. Our architecture includes semantic signing and verification steps. We apply this architecture to verifying two types of semantic information: individual identities (faces) and whether the photo was taken indoors or outdoors. Verification accounts for a collection of common image transformation, such as translation, scaling, cropping, and small rotations, and rejects adversarial transformations, such as adversarially perturbed or, in the case of face verification, swapped faces. Experiments demonstrate that in the case of provenance of faces in an image, our approach is robust to black-box adversarial transformations (which are rejected) as well as benign transformations (which are accepted), with few false negatives and false positives. Background verification, on the other hand, is susceptible to black-box adversarial examples, but becomes significantly more robust after adversarial training.
Class-Aware Generative Adversarial Transformers for Medical Image Segmentation
Jan 26, 2022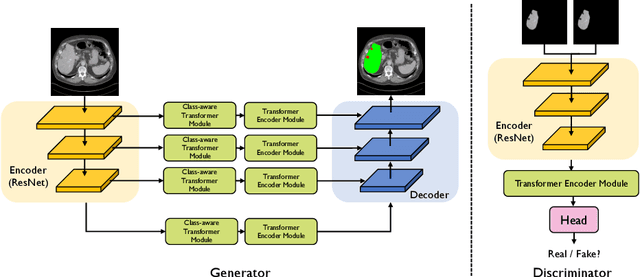
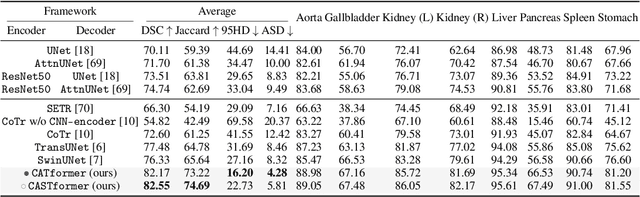
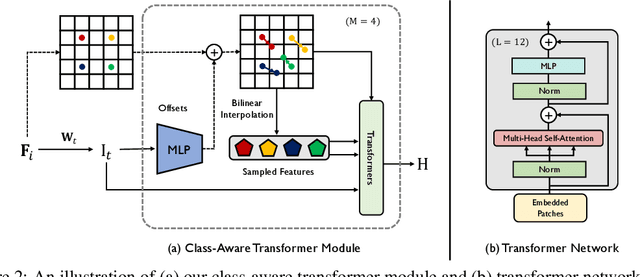
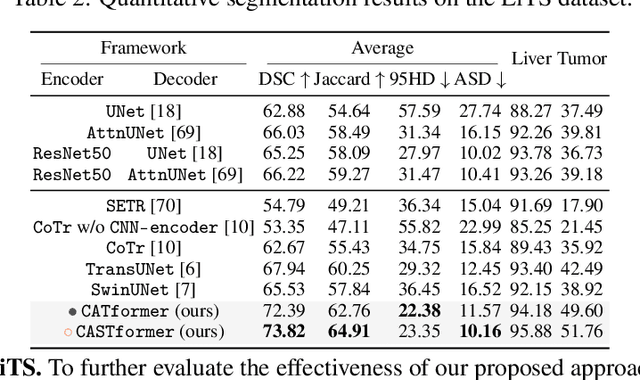
Transformers have made remarkable progress towards modeling long-range dependencies within the medical image analysis domain. However, current transformer-based models suffer from several disadvantages: 1) existing methods fail to capture the important features of the images due to the naive tokenization scheme; 2) the models suffer from information loss because they only consider single-scale feature representations; and 3) the segmentation label maps generated by the models are not accurate enough without considering rich semantic contexts and anatomical textures. In this work, we present CA-GANformer, a novel type of generative adversarial transformers, for medical image segmentation. First, we take advantage of the pyramid structure to construct multi-scale representations and handle multi-scale variations. We then design a novel class-aware transformer module to better learn the discriminative regions of objects with semantic structures. Lastly, we utilize an adversarial training strategy that boosts segmentation accuracy and correspondingly allows a transformer-based discriminator to capture high-level semantically correlated contents and low-level anatomical features. Our experiments demonstrate that CA-GANformer dramatically outperforms previous state-of-the-art transformer-based approaches on three benchmarks, obtaining absolute 2.54%-5.88% improvements in Dice over previous models. Further qualitative experiments provide a more detailed picture of the model's inner workings, shed light on the challenges in improved transparency, and demonstrate that transfer learning can greatly improve performance and reduce the size of medical image datasets in training, making CA-GANformer a strong starting point for downstream medical image analysis tasks. Codes and models will be available to the public.
Critical configurations for two projective views, a new approach
Dec 09, 2021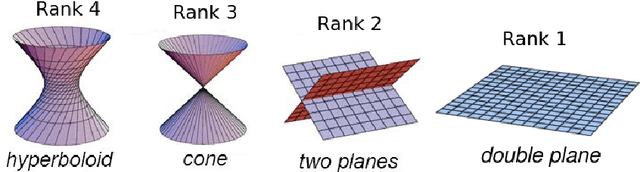
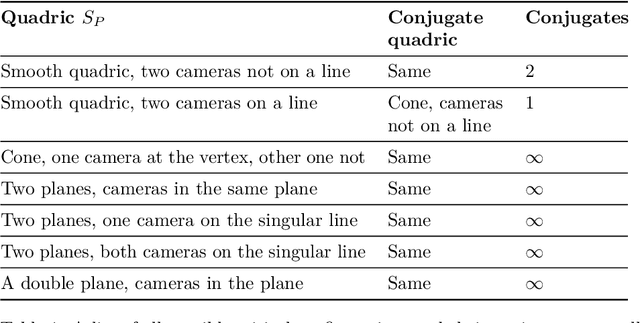
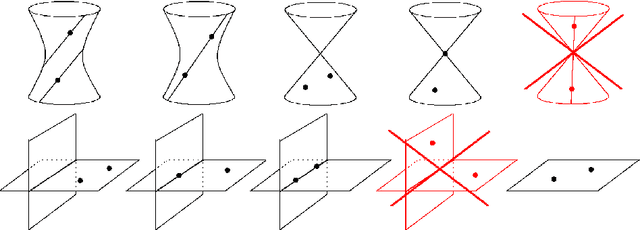

The problem of structure from motion is concerned with recovering 3-dimensional structure of an object from a set of 2-dimensional images. Generally, all information can be uniquely recovered if enough images and image points are provided, but there are certain cases where unique recovery is impossible; these are called critical configurations. In this paper we use an algebraic approach to study the critical configurations for two projective cameras. We show that all critical configurations lie on quadric surfaces, and classify exactly which quadrics constitute a critical configuration. The paper also describes the relation between the different reconstructions when unique reconstruction is impossible.
Attention Mechanism Meets with Hybrid Dense Network for Hyperspectral Image Classification
Jan 04, 2022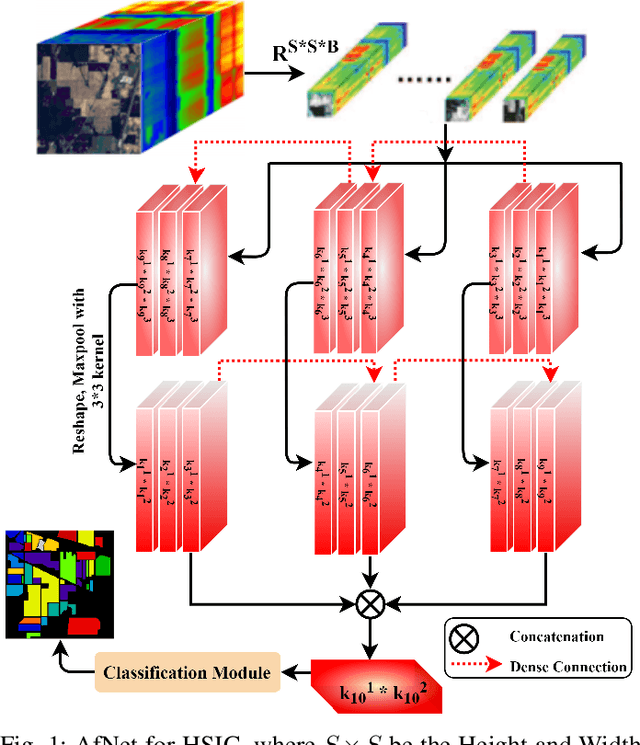
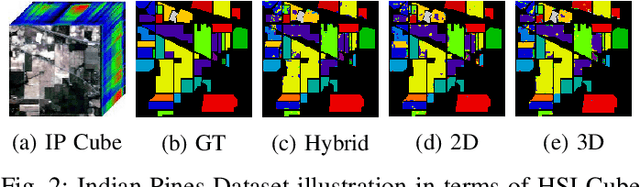
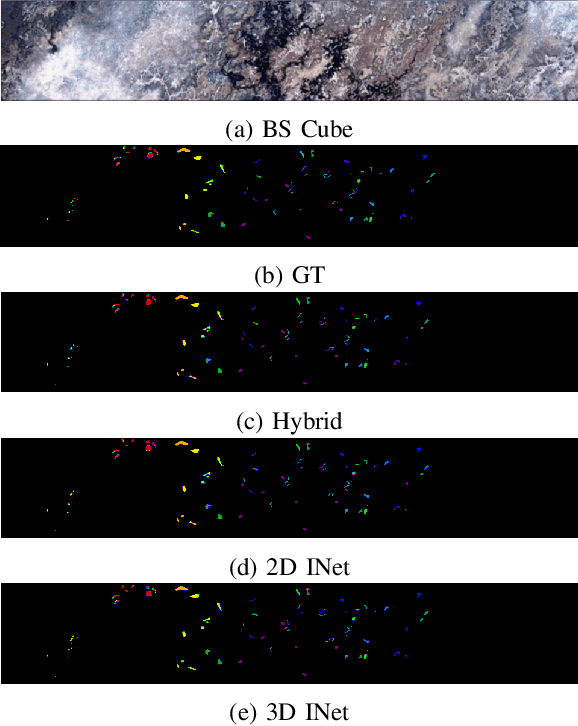
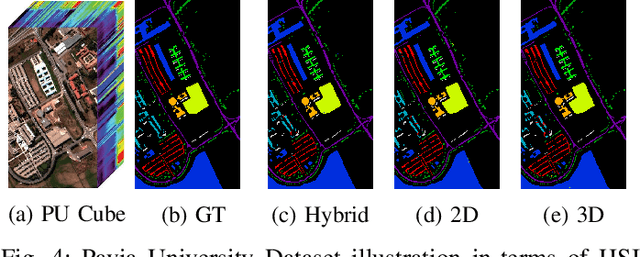
Convolutional Neural Networks (CNN) are more suitable, indeed. However, fixed kernel sizes make traditional CNN too specific, neither flexible nor conducive to feature learning, thus impacting on the classification accuracy. The convolution of different kernel size networks may overcome this problem by capturing more discriminating and relevant information. In light of this, the proposed solution aims at combining the core idea of 3D and 2D Inception net with the Attention mechanism to boost the HSIC CNN performance in a hybrid scenario. The resulting \textit{attention-fused hybrid network} (AfNet) is based on three attention-fused parallel hybrid sub-nets with different kernels in each block repeatedly using high-level features to enhance the final ground-truth maps. In short, AfNet is able to selectively filter out the discriminative features critical for classification. Several tests on HSI datasets provided competitive results for AfNet compared to state-of-the-art models. The proposed pipeline achieved, indeed, an overall accuracy of 97\% for the Indian Pines, 100\% for Botswana, 99\% for Pavia University, Pavia Center, and Salinas datasets.
Task Oriented Channel State Information Quantization
Apr 02, 2019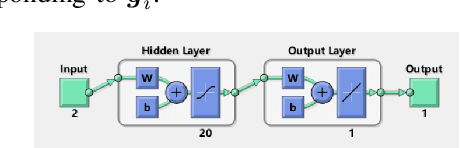
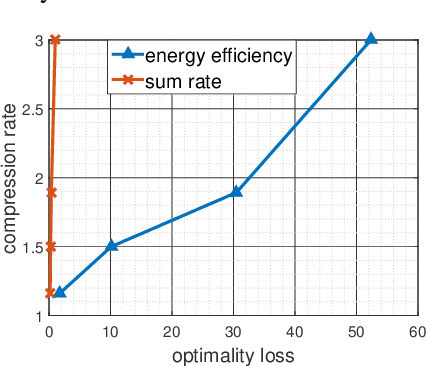
In this paper, we propose a new perspective for quantizing a signal and more specifically the channel state information (CSI). The proposed point of view is fully relevant for a receiver which has to send a quantized version of the channel state to the transmitter. Roughly, the key idea is that the receiver sends the right amount of information to the transmitter so that the latter be able to take its (resource allocation) decision. More formally, the decision task of the transmitter is to maximize an utility function u(x;g) with respect to x (e.g., a power allocation vector) given the knowledge of a quantized version of the function parameters g. We exhibit a special case of an energy-efficient power control (PC) problem for which the optimal task oriented CSI quantizer (TOCQ) can be found analytically. For more general utility functions, we propose to use neural networks (NN) based learning. Simulations show that the compression rate obtained by adapting the feedback information rate to the function to be optimized may be significantly increased.
* 2 pages, 2 figures
Dual Path Structural Contrastive Embeddings for Learning Novel Objects
Jan 04, 2022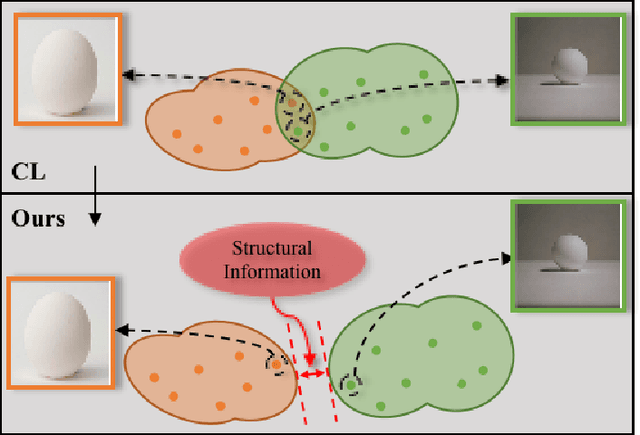
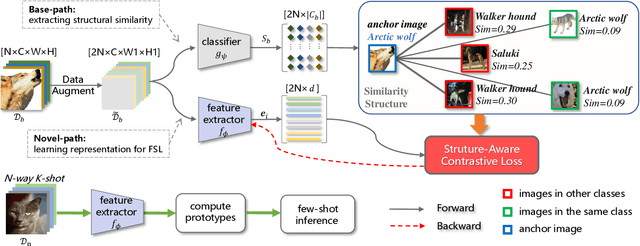
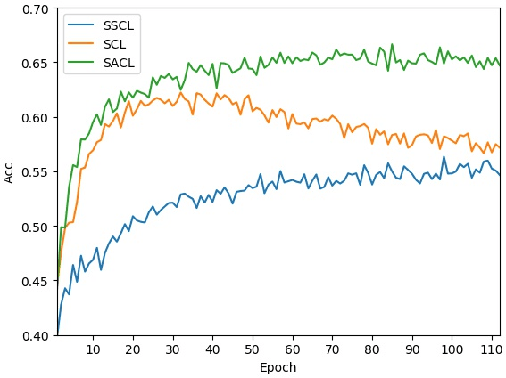

Learning novel classes from a very few labeled samples has attracted increasing attention in machine learning areas. Recent research on either meta-learning based or transfer-learning based paradigm demonstrates that gaining information on a good feature space can be an effective solution to achieve favorable performance on few-shot tasks. In this paper, we propose a simple but effective paradigm that decouples the tasks of learning feature representations and classifiers and only learns the feature embedding architecture from base classes via the typical transfer-learning training strategy. To maintain both the generalization ability across base and novel classes and discrimination ability within each class, we propose a dual path feature learning scheme that effectively combines structural similarity with contrastive feature construction. In this way, both inner-class alignment and inter-class uniformity can be well balanced, and result in improved performance. Experiments on three popular benchmarks show that when incorporated with a simple prototype based classifier, our method can still achieve promising results for both standard and generalized few-shot problems in either an inductive or transductive inference setting.
A novel approach to sentiment analysis in Persian using discourse and external semantic information
Jul 18, 2020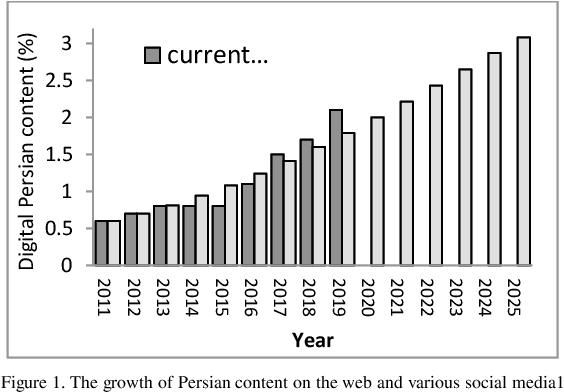
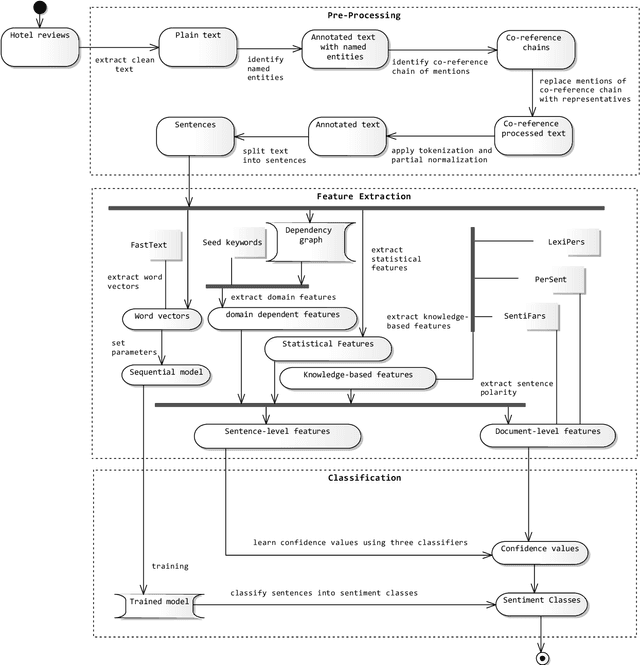
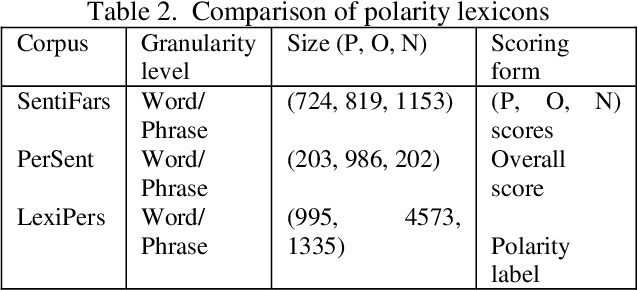
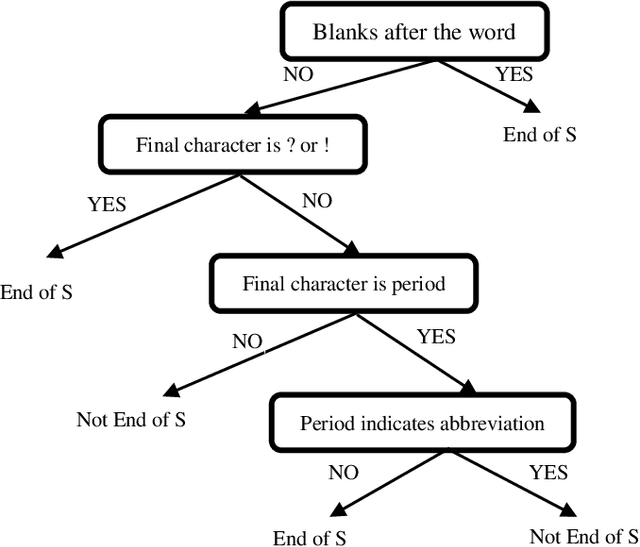
Sentiment analysis attempts to identify, extract and quantify affective states and subjective information from various types of data such as text, audio, and video. Many approaches have been proposed to extract the sentiment of individuals from documents written in natural languages in recent years. The majority of these approaches have focused on English, while resource-lean languages such as Persian suffer from the lack of research work and language resources. Due to this gap in Persian, the current work is accomplished to introduce new methods for sentiment analysis which have been applied on Persian. The proposed approach in this paper is two-fold: The first one is based on classifier combination, and the second one is based on deep neural networks which benefits from word embedding vectors. Both approaches takes advantage of local discourse information and external knowledge bases, and also cover several language issues such as negation and intensification, andaddresses different granularity levels, namely word, aspect, sentence, phrase and document-levels. To evaluate the performance of the proposed approach, a Persian dataset is collected from Persian hotel reviews referred as hotel reviews. The proposed approach has been compared to counterpart methods based on the benchmark dataset. The experimental results approve the effectiveness of the proposed approach when compared to related works.
S-multi-SNE: Semi-Supervised Classification and Visualisation of Multi-View Data
Nov 05, 2021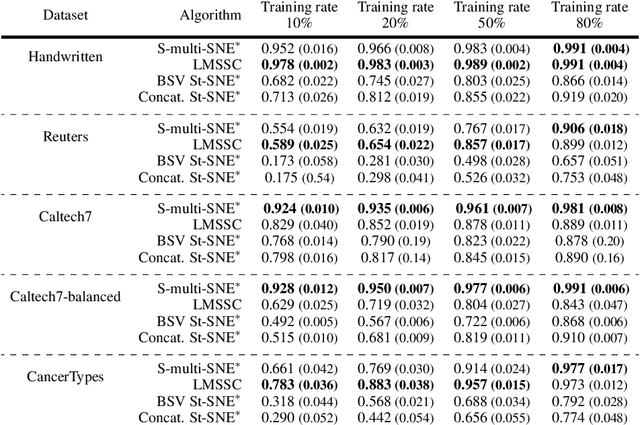
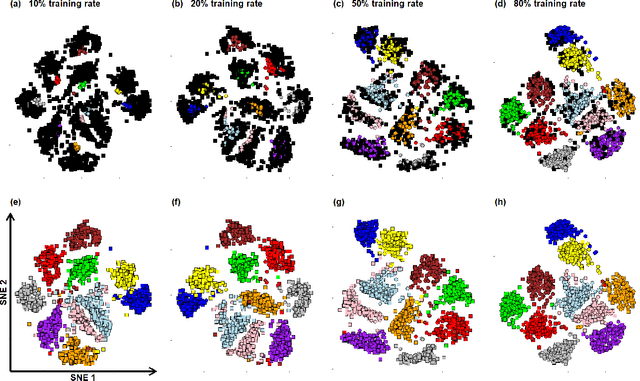
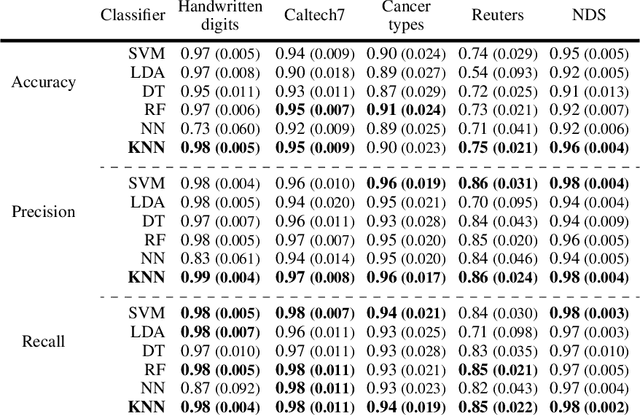
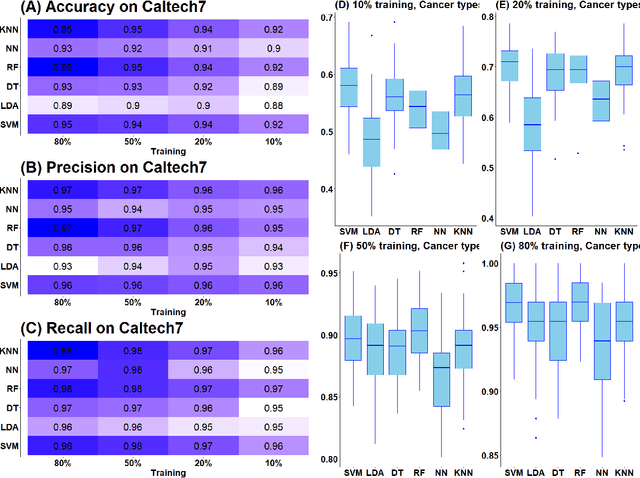
An increasing number of multi-view data are being published by studies in several fields. This type of data corresponds to multiple data-views, each representing a different aspect of the same set of samples. We have recently proposed multi-SNE, an extension of t-SNE, that produces a single visualisation of multi-view data. The multi-SNE approach provides low-dimensional embeddings of the samples, produced by being updated iteratively through the different data-views. Here, we further extend multi-SNE to a semi-supervised approach, that classifies unlabelled samples by regarding the labelling information as an extra data-view. We look deeper into the performance, limitations and strengths of multi-SNE and its extension, S-multi-SNE, by applying the two methods on various multi-view datasets with different challenges. We show that by including the labelling information, the projection of the samples improves drastically and it is accompanied by a strong classification performance.