 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TEACh: Task-driven Embodied Agents that Chat
Oct 15, 2021
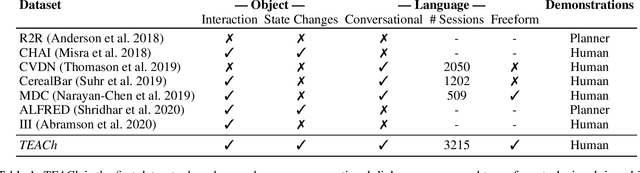
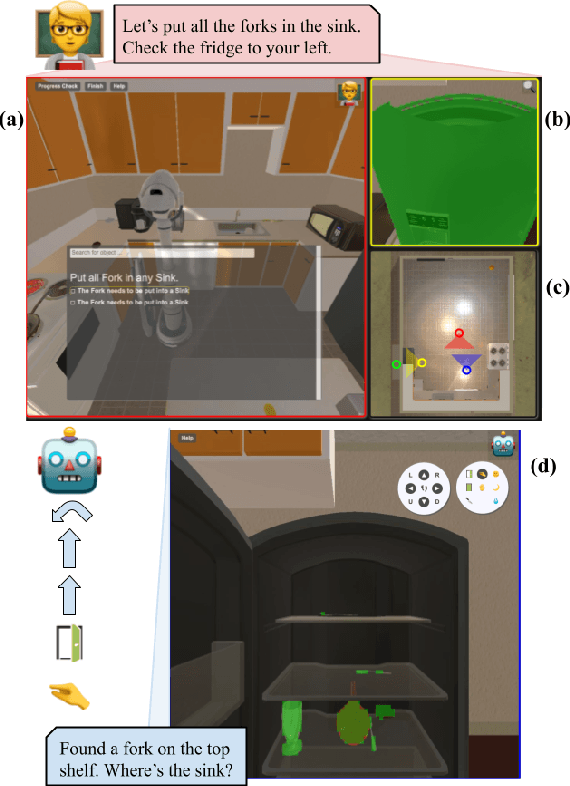
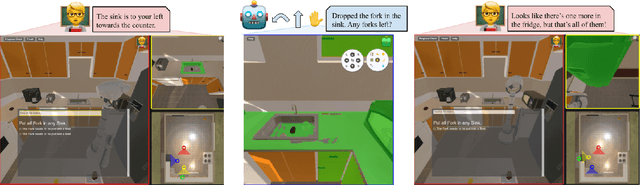
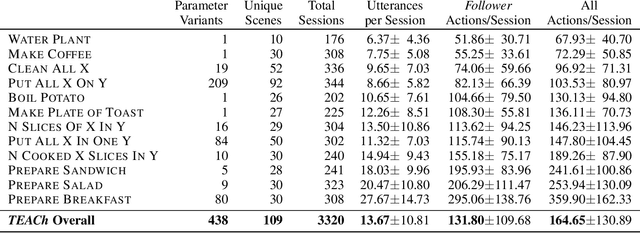
Robots operating in human spaces must be able to engage in natural language interaction with people, both understanding and executing instructions, and using conversation to resolve ambiguity and recover from mistakes. To study this, we introduce TEACh, a dataset of over 3,000 human--human, interactive dialogues to complete household tasks in simulation. A Commander with access to oracle information about a task communicates in natural language with a Follower. The Follower navigates through and interacts with the environment to complete tasks varying in complexity from "Make Coffee" to "Prepare Breakfast", asking questions and getting additional information from the Commander. We propose three benchmarks using TEACh to study embodied intelligence challenges, and we evaluate initial models' abilities in dialogue understanding, language grounding, and task execution.
SymbioLCD: Ensemble-Based Loop Closure Detection using CNN-Extracted Objects and Visual Bag-of-Words
Oct 21, 2021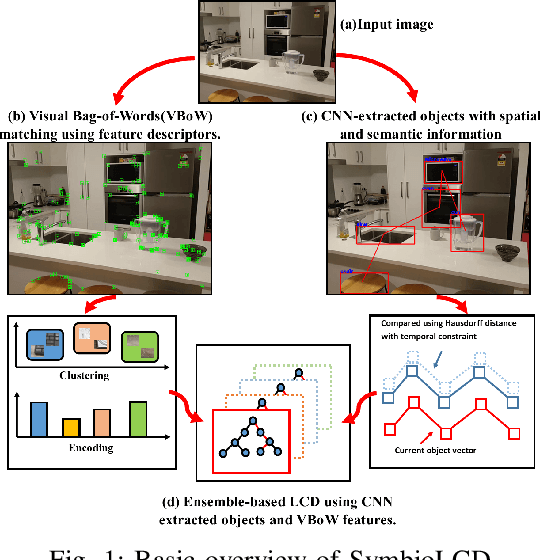
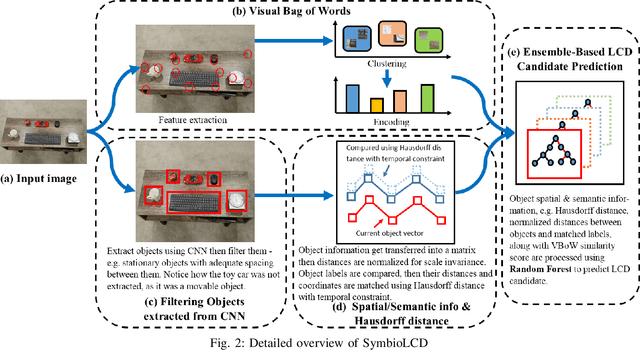

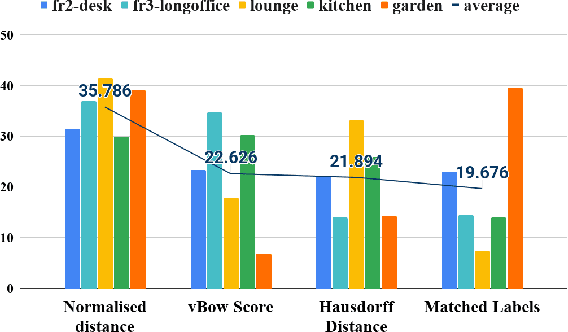
Loop closure detection is an essential tool of Simultaneous Localization and Mapping (SLAM) to minimize drift in its localization. Many state-of-the-art loop closure detection (LCD) algorithms use visual Bag-of-Words (vBoW), which is robust against partial occlusions in a scene but cannot perceive the semantics or spatial relationships between feature points. CNN object extraction can address those issues, by providing semantic labels and spatial relationships between objects in a scene. Previous work has mainly focused on replacing vBoW with CNN-derived features. In this paper, we propose SymbioLCD, a novel ensemble-based LCD that utilizes both CNN-extracted objects and vBoW features for LCD candidate prediction. When used in tandem, the added elements of object semantics and spatial-awareness create a more robust and symbiotic loop closure detection system. The proposed SymbioLCD uses scale-invariant spatial and semantic matching, Hausdorff distance with temporal constraints, and a Random Forest that utilizes combined information from both CNN-extracted objects and vBoW features for predicting accurate loop closure candidates. Evaluation of the proposed method shows it outperforms other Machine Learning (ML) algorithms - such as SVM, Decision Tree and Neural Network, and demonstrates that there is a strong symbiosis between CNN-extracted object information and vBoW features which assists accurate LCD candidate prediction. Furthermore, it is able to perceive loop closure candidates earlier than state-of-the-art SLAM algorithms, utilizing added spatial and semantic information from CNN-extracted objects.
Large-scale Building Height Retrieval from Single SAR Imagery based on Bounding Box Regression Networks
Nov 18, 2021

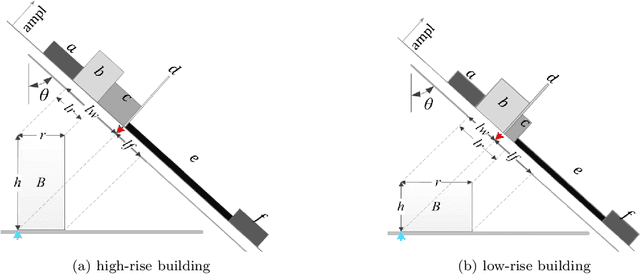

Building height retrieval from synthetic aperture radar (SAR) imagery is of great importance for urban applications, yet highly challenging owing to the complexity of SAR data. This paper addresses the issue of building height retrieval in large-scale urban areas from a single TerraSAR-X spotlight or stripmap image. Based on the radar viewing geometry, we propose that this problem can be formulated as a bounding box regression problem and therefore allows for integrating height data from multiple data sources in generating ground truth on a larger scale. We introduce building footprints from geographic information system (GIS) data as complementary information and propose a bounding box regression network that exploits the location relationship between a building's footprint and its bounding box, allowing for fast computation. This is important for large-scale applications. The method is validated on four urban data sets using TerraSAR-X images in both high-resolution spotlight and stripmap modes. Experimental results show that the proposed network can reduce the computation cost significantly while keeping the height accuracy of individual buildings compared to a Faster R-CNN based method. Moreover, we investigate the impact of inaccurate GIS data on our proposed network, and this study shows that the bounding box regression network is robust against positioning errors in GIS data. The proposed method has great potential to be applied to regional or even global scales.
A Regression Approach to Certain Information Transmission Problems
Jun 10, 2019
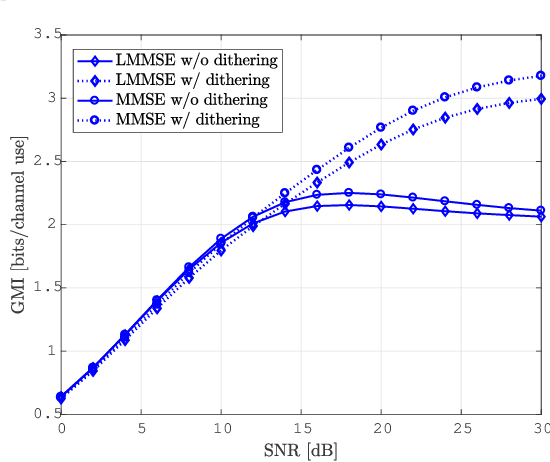
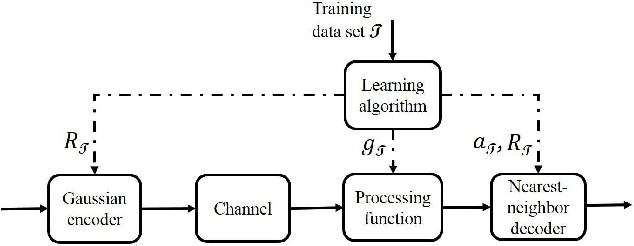
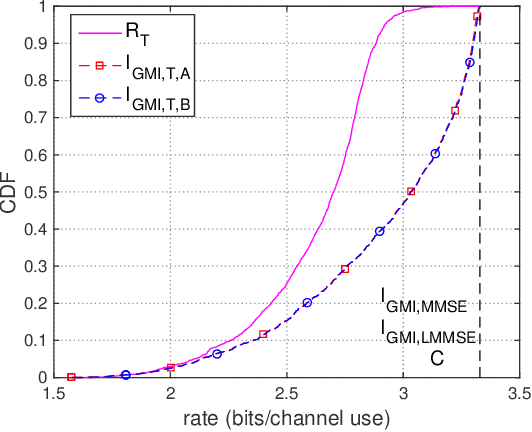
A general information transmission model, under independent and identically distributed Gaussian codebook and nearest neighbor decoding rule with processed channel output, is investigated using the performance metric of generalized mutual information. When the encoder and the decoder know the statistical channel model, it is found that the optimal channel output processing function is the conditional expectation operator, thus hinting a potential role of regression, a classical topic in machine learning, for this model. Without utilizing the statistical channel model, a problem formulation inspired by machine learning principles is established, with suitable performance metrics introduced. A data-driven inference algorithm is proposed to solve the problem, and the effectiveness of the algorithm is validated via numerical experiments. Extensions to more general information transmission models are also discussed.
Attributed Network Embedding for Incomplete Structure Information
Nov 28, 2018
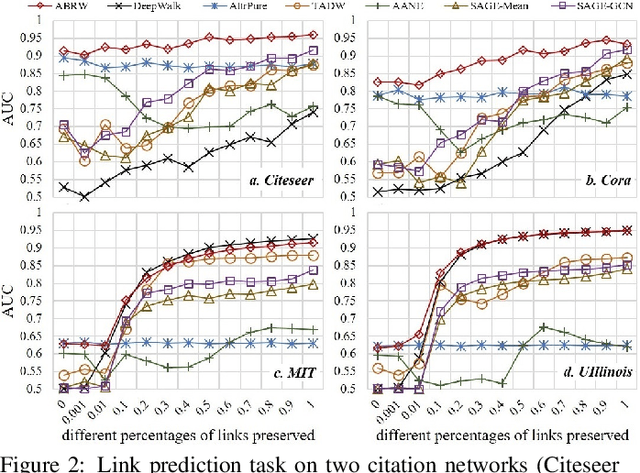
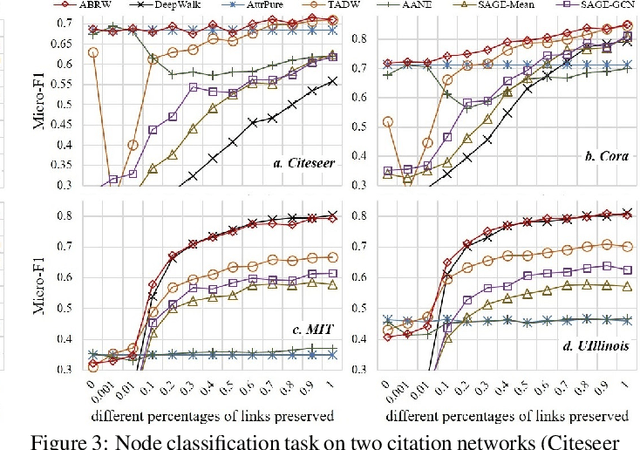
An attributed network enriches a pure network by encoding a part of widely accessible node auxiliary information into node attributes. Learning vector representation of each node a.k.a. Network Embedding (NE) for such an attributed network by considering both structure and attribute information has recently attracted considerable attention, since each node embedding is simply a unified low-dimension vector representation that makes downstream tasks e.g. link prediction more efficient and much easier to realize. Most of previous works have not considered the significant case of a network with incomplete structure information, which however, would often appear in our real-world scenarios e.g. the abnormal users in a social network who intentionally hide their friendships. And different networks obviously have different levels of incomplete structure information, which imposes more challenges to balance two sources of information. To tackle that, we propose a robust NE method called Attributed Biased Random Walks (ABRW) to employ attribute information for compensating incomplete structure information by using transition matrices. The experiments of link prediction and node classification tasks on real-world datasets confirm the robustness and effectiveness of our method to the different levels of the incomplete structure information.
MoCaNet: Motion Retargeting in-the-wild via Canonicalization Networks
Dec 21, 2021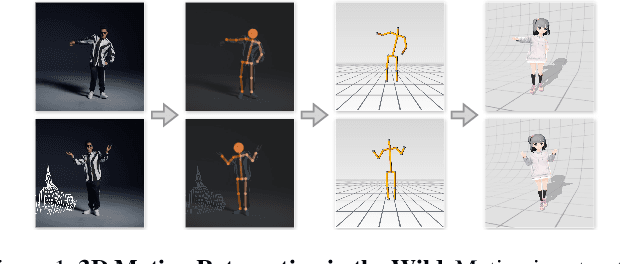

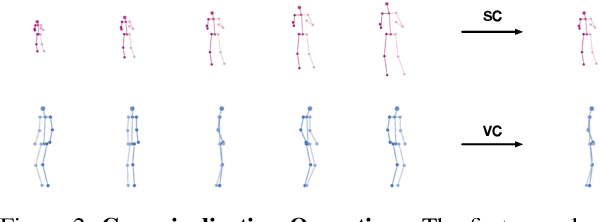

We present a novel framework that brings the 3D motion retargeting task from controlled environments to in-the-wild scenarios. In particular, our method is capable of retargeting body motion from a character in a 2D monocular video to a 3D character without using any motion capture system or 3D reconstruction procedure. It is designed to leverage massive online videos for unsupervised training, needless of 3D annotations or motion-body pairing information. The proposed method is built upon two novel canonicalization operations, structure canonicalization and view canonicalization. Trained with the canonicalization operations and the derived regularizations, our method learns to factorize a skeleton sequence into three independent semantic subspaces, i.e., motion, structure, and view angle. The disentangled representation enables motion retargeting from 2D to 3D with high precision. Our method achieves superior performance on motion transfer benchmarks with large body variations and challenging actions. Notably, the canonicalized skeleton sequence could serve as a disentangled and interpretable representation of human motion that benefits action analysis and motion retrieval.
Information in Infinite Ensembles of Infinitely-Wide Neural Networks
Nov 23, 2019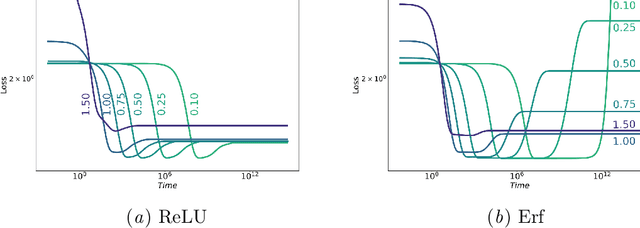
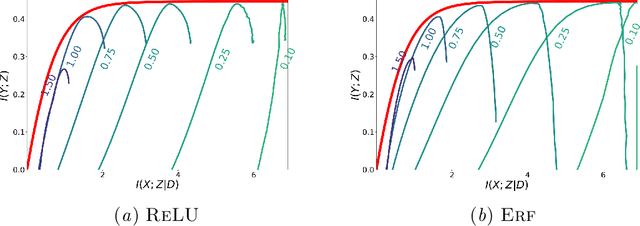
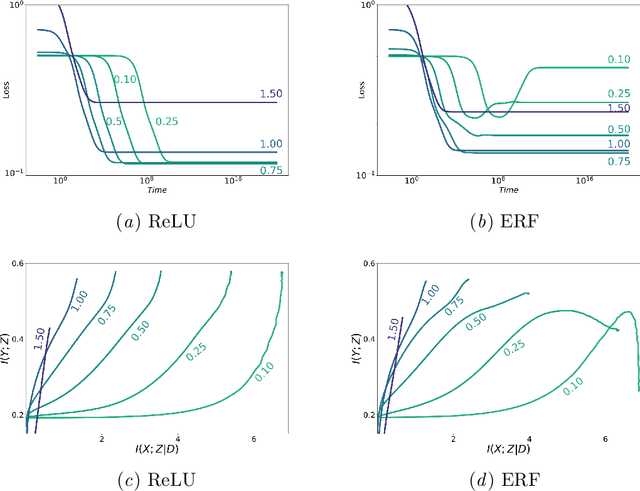
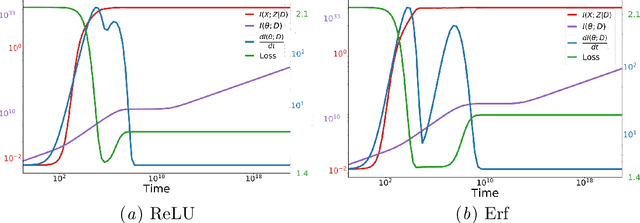
In this preliminary work, we study the generalization properties of infinite ensembles of infinitely-wide neural networks. Amazingly, this model family admits tractable calculations for many information-theoretic quantities. We report analytical and empirical investigations in the search for signals that correlate with generalization.
SAPNet: Segmentation-Aware Progressive Network for Perceptual Contrastive Deraining
Nov 26, 2021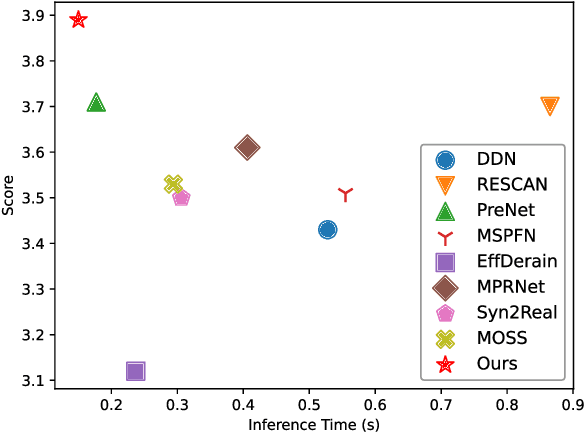
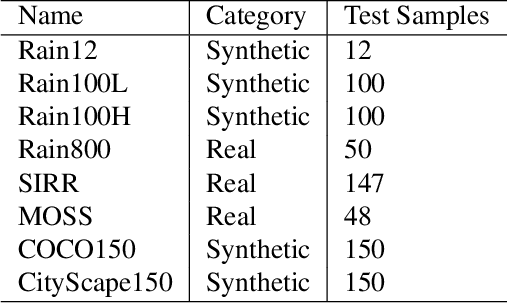
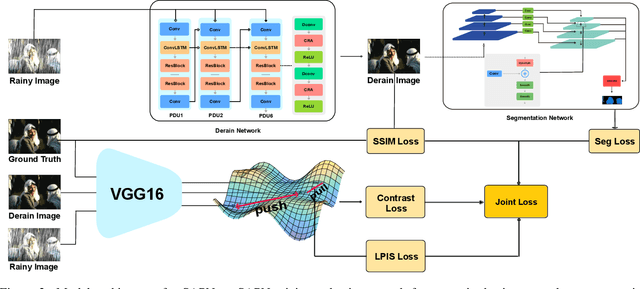
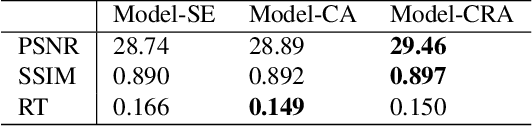
Deep learning algorithms have recently achieved promising deraining performances on both the natural and synthetic rainy datasets. As an essential low-level pre-processing stage, a deraining network should clear the rain streaks and preserve the fine semantic details. However, most existing methods only consider low-level image restoration. That limits their performances at high-level tasks requiring precise semantic information. To address this issue, in this paper, we present a segmentation-aware progressive network (SAPNet) based upon contrastive learning for single image deraining. We start our method with a lightweight derain network formed with progressive dilated units (PDU). The PDU can significantly expand the receptive field and characterize multi-scale rain streaks without the heavy computation on multi-scale images. A fundamental aspect of this work is an unsupervised background segmentation (UBS) network initialized with ImageNet and Gaussian weights. The UBS can faithfully preserve an image's semantic information and improve the generalization ability to unseen photos. Furthermore, we introduce a perceptual contrastive loss (PCL) and a learned perceptual image similarity loss (LPISL) to regulate model learning. By exploiting the rainy image and groundtruth as the negative and the positive sample in the VGG-16 latent space, we bridge the fine semantic details between the derained image and the groundtruth in a fully constrained manner. Comprehensive experiments on synthetic and real-world rainy images show our model surpasses top-performing methods and aids object detection and semantic segmentation with considerable efficacy. A Pytorch Implementation is available at https://github.com/ShenZheng2000/SAPNet-for-image-deraining.
Implicit Data Augmentation Using Feature Interpolation for Diversified Low-Shot Image Generation
Dec 04, 2021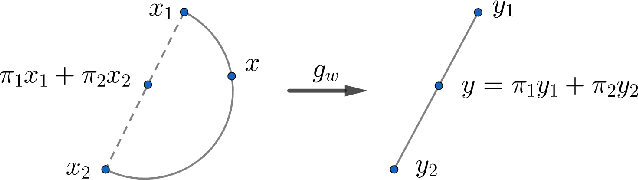
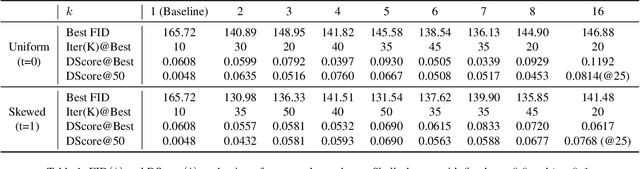
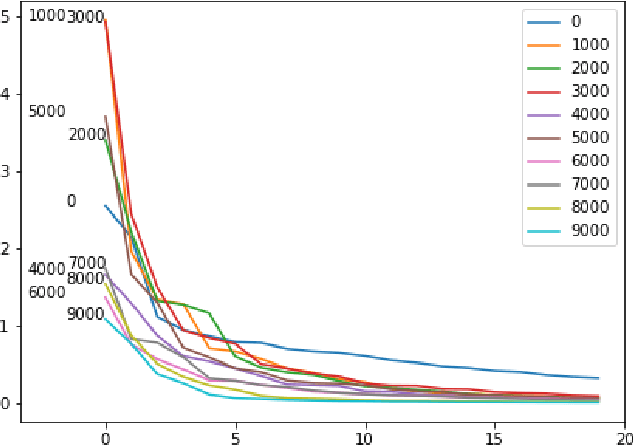
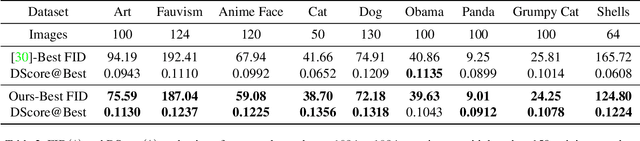
Training of generative models especially Generative Adversarial Networks can easily diverge in low-data setting. To mitigate this issue, we propose a novel implicit data augmentation approach which facilitates stable training and synthesize diverse samples. Specifically, we view the discriminator as a metric embedding of the real data manifold, which offers proper distances between real data points. We then utilize information in the feature space to develop a data-driven augmentation method. We further bring up a simple metric to evaluate the diversity of synthesized samples. Experiments on few-shot generation tasks show our method improves FID and diversity of results compared to current methods, and allows generating high-quality and diverse images with less than 100 training samples.
Neural network is heterogeneous: Phase matters more
Nov 27, 2021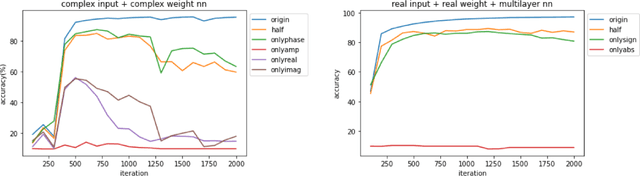
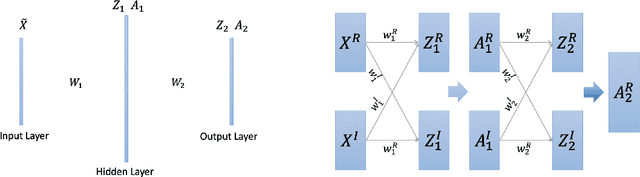
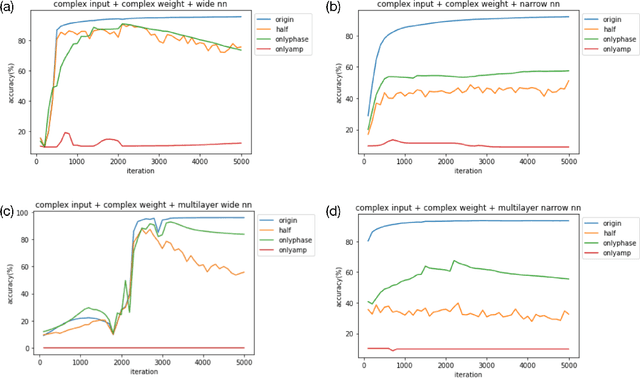

We find a heterogeneity in both complex and real valued neural networks with the insight from wave optics, claiming a much more important role of phase than its amplitude counterpart in the weight matrix. In complex-valued neural networks, we show that among different types of pruning, the weight matrix with only phase information preserved achieves the best accuracy, which holds robustly under various settings of depth and width. The conclusion can be generalized to real-valued neural networks, where signs take the place of phases. These inspiring findings enrich the techniques of network pruning and binary computation.