 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the Efficiency of Subclass Knowledge Distillation in Classification Tasks
Sep 12, 2021

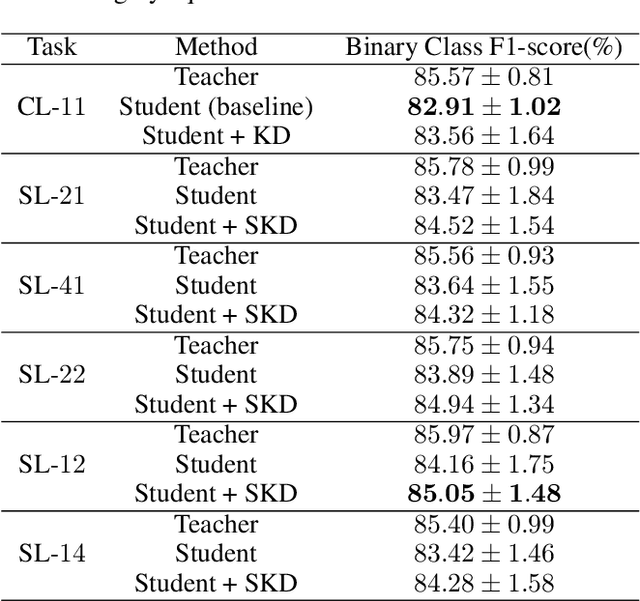


This work introduces a novel knowledge distillation framework for classification tasks where information on existing subclasses is available and taken into consideration. In classification tasks with a small number of classes or binary detection (two classes) the amount of information transferred from the teacher to the student network is restricted, thus limiting the utility of knowledge distillation. Performance can be improved by leveraging information about possible subclasses within the available classes in the classification task. To that end, we propose the so-called Subclass Knowledge Distillation (SKD) framework, which is the process of transferring the subclasses' prediction knowledge from a large teacher model into a smaller student one. Through SKD, additional meaningful information which is not in the teacher's class logits but exists in subclasses (e.g., similarities inside classes) will be conveyed to the student and boost its performance. Mathematically, we measure how many extra information bits the teacher can provide for the student via SKD framework. The framework developed is evaluated in clinical application, namely colorectal polyp binary classification. In this application, clinician-provided annotations are used to define subclasses based on the annotation label's variability in a curriculum style of learning. A lightweight, low complexity student trained with the proposed framework achieves an F1-score of 85.05%, an improvement of 2.14% and 1.49% gain over the student that trains without and with conventional knowledge distillation, respectively. These results show that the extra subclasses' knowledge (i.e., 0.4656 label bits per training sample in our experiment) can provide more information about the teacher generalization, and therefore SKD can benefit from using more information to increase the student performance.
Long Short-Term Memory Neural Network for Financial Time Series
Jan 20, 2022

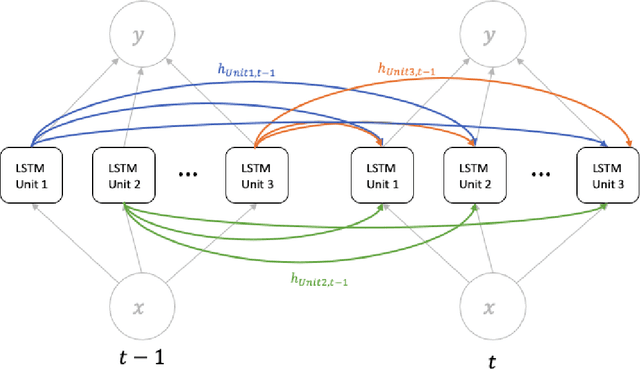
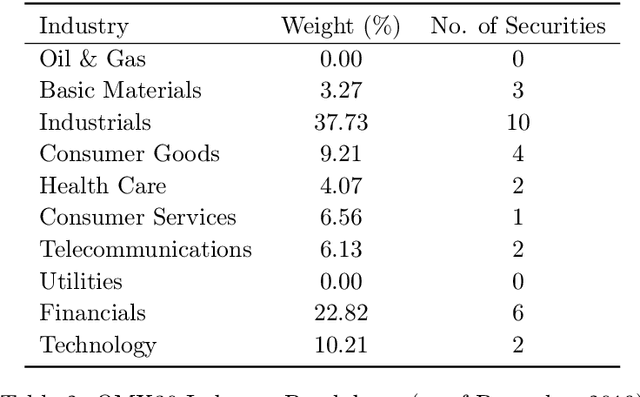
Performance forecasting is an age-old problem in economics and finance. Recently, developments in machine learning and neural networks have given rise to non-linear time series models that provide modern and promising alternatives to traditional methods of analysis. In this paper, we present an ensemble of independent and parallel long short-term memory (LSTM) neural networks for the prediction of stock price movement. LSTMs have been shown to be especially suited for time series data due to their ability to incorporate past information, while neural network ensembles have been found to reduce variability in results and improve generalization. A binary classification problem based on the median of returns is used, and the ensemble's forecast depends on a threshold value, which is the minimum number of LSTMs required to agree upon the result. The model is applied to the constituents of the smaller, less efficient Stockholm OMX30 instead of other major market indices such as the DJIA and S&P500 commonly found in literature. With a straightforward trading strategy, comparisons with a randomly chosen portfolio and a portfolio containing all the stocks in the index show that the portfolio resulting from the LSTM ensemble provides better average daily returns and higher cumulative returns over time. Moreover, the LSTM portfolio also exhibits less volatility, leading to higher risk-return ratios.
COTReg:Coupled Optimal Transport based Point Cloud Registration
Dec 29, 2021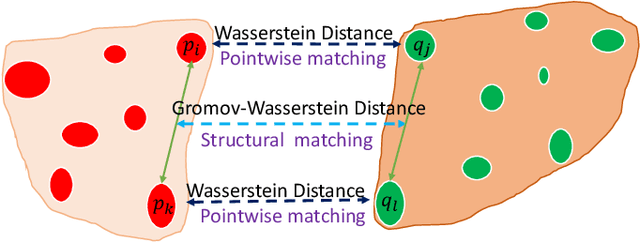

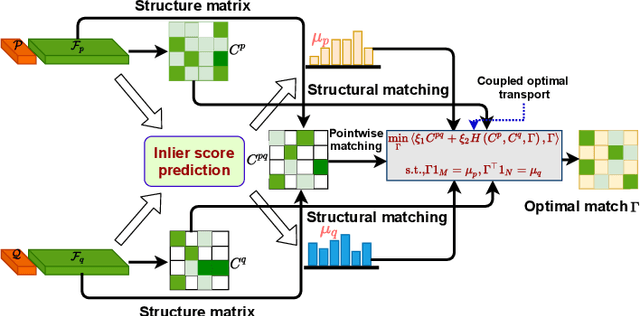
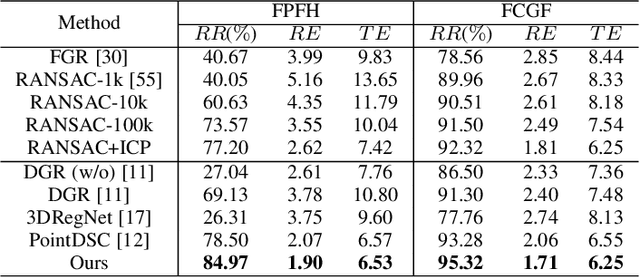
Generating a set of high-quality correspondences or matches is one of the most critical steps in point cloud registration. This paper proposes a learning framework COTReg by jointly considering the pointwise and structural matchings to predict correspondences of 3D point cloud registration. Specifically, we transform the two matchings into a Wasserstein distance-based and a Gromov-Wasserstein distance-based optimizations, respectively. Thus the task of establishing the correspondences can be naturally reshaped to a coupled optimal transport problem. Furthermore, we design a network to predict the confidence score of being an inlier for each point of the point clouds, which provides the overlap region information to generate correspondences. Our correspondence prediction pipeline can be easily integrated into either learning-based features like FCGF or traditional descriptors like FPFH. We conducted comprehensive experiments on 3DMatch, KITTI, 3DCSR, and ModelNet40 benchmarks, showing the state-of-art performance of the proposed method.
Learning of Frequency-Time Attention Mechanism for Automatic Modulation Recognition
Nov 05, 2021
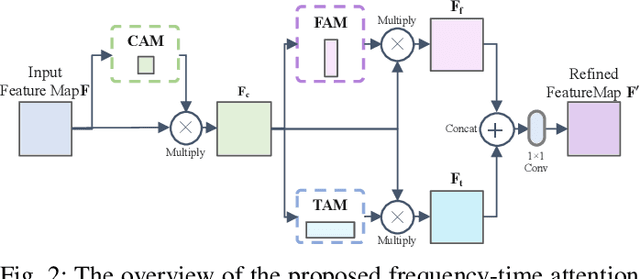
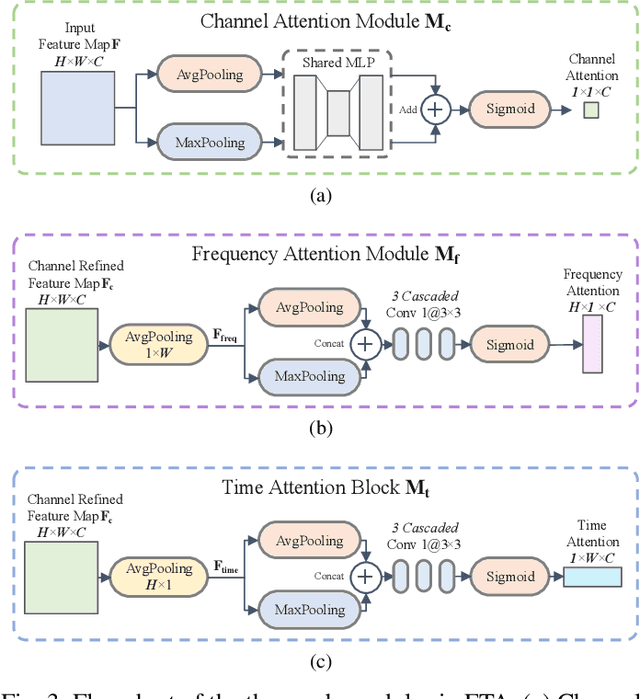
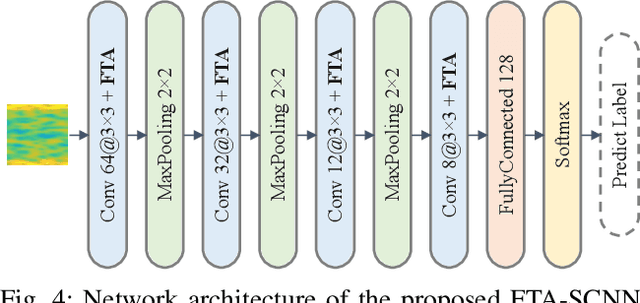
Recent learning-based image classification and speech recognition approaches make extensive use of attention mechanisms to achieve state-of-the-art recognition power, which demonstrates the effectiveness of attention mechanisms. Motivated by the fact that the frequency and time information of modulated radio signals are crucial for modulation mode recognition, this paper proposes a frequency-time attention mechanism for a convolutional neural network (CNN)-based modulation recognition framework. The proposed frequency-time attention module is designed to learn which channel, frequency and time information is more meaningful in CNN for modulation recognition. We analyze the effectiveness of the proposed frequency-time attention mechanism and compare the proposed method with two existing learning-based methods. Experiments on an open-source modulation recognition dataset show that the recognition performance of the proposed framework is better than those of the framework without frequency-time attention and existing learning-based methods.
Function Computation Under Privacy, Secrecy, Distortion, and Communication Constraints
Jan 11, 2022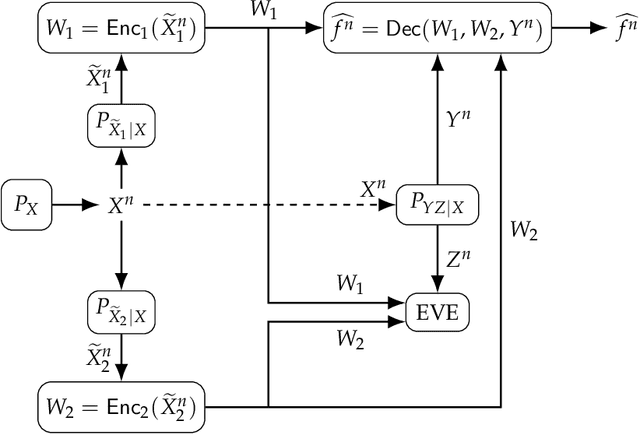
The problem of reliable function computation is extended by imposing privacy, secrecy, and storage constraints on a remote source whose noisy measurements are observed by multiple parties. The main additions to the classic function computation problem include 1) privacy leakage to an eavesdropper is measured with respect to the remote source rather than the transmitting terminals' observed sequences; 2) the information leakage to a fusion center with respect to the remote source is considered as a new privacy leakage metric; 3) the function computed is allowed to be a distorted version of the target function, which allows to reduce the storage rate as compared to a reliable function computation scenario in addition to reducing secrecy and privacy leakages; 4) two transmitting node observations are used to compute a function. Inner and outer bounds on the rate regions are derived for lossless and lossy single-function computation with two transmitting nodes, which recover previous results in the literature. For special cases that include invertible and partially-invertible functions, and degraded measurement channels, exact lossless and lossy rate regions are characterized, and one exact region is evaluated for an example scenario.
Spatial Data Mining of Public Transport Incidents reported in Social Media
Oct 11, 2021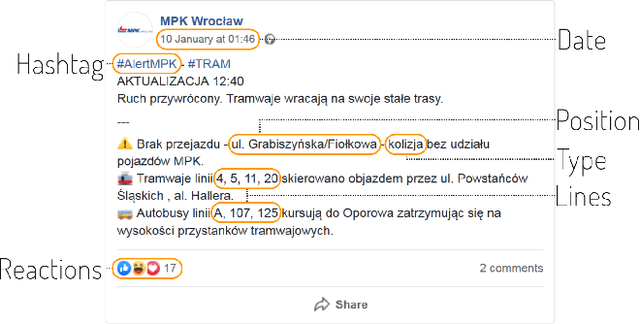
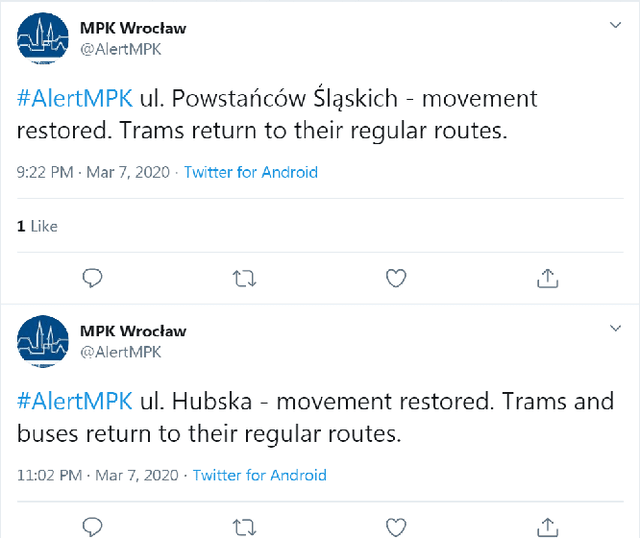
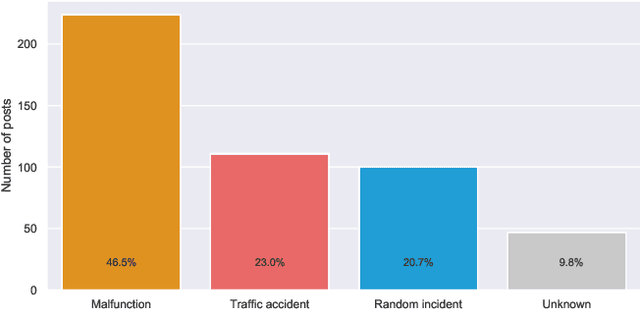
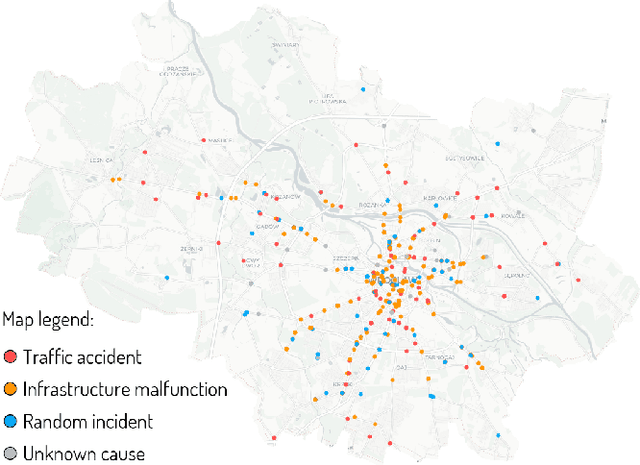
Public transport agencies use social media as an essential tool for communicating mobility incidents to passengers. However, while the short term, day-to-day information about transport phenomena is usually posted in social media with low latency, its availability is short term as the content is rarely made an aggregated form. Social media communication of transport phenomena usually lacks GIS annotations as most social media platforms do not allow attaching non-POI GPS coordinates to posts. As a result, the analysis of transport phenomena information is minimal. We collected three years of social media posts of a polish public transport company with user comments. Through exploration, we infer a six-class transport information typology. We successfully build an information type classifier for social media posts, detect stop names in posts, and relate them to GPS coordinates, obtaining a spatial understanding of long-term aggregated phenomena. We show that our approach enables citizen science and use it to analyze the impact of three years of infrastructure incidents on passenger mobility, and the sentiment and reaction scale towards each of the events. All these results are achieved for Polish, an under-resourced language when it comes to spatial language understanding, especially in social media contexts. To improve the situation, we released two of our annotated data sets: social media posts with incident type labels and matched stop names and social media comments with the annotated sentiment. We also opensource the experimental codebase.
Class-Aware Generative Adversarial Transformers for Medical Image Segmentation
Jan 28, 2022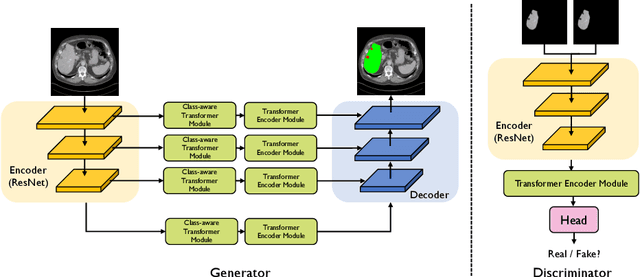
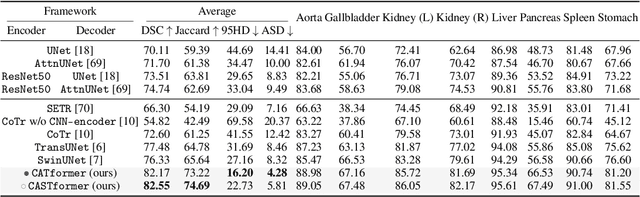
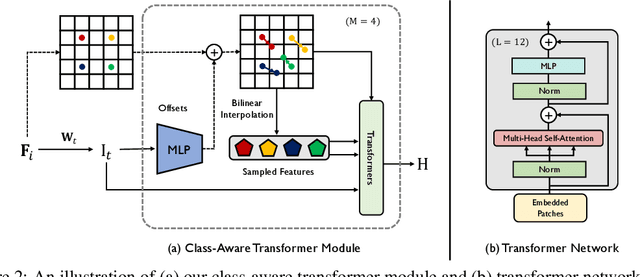
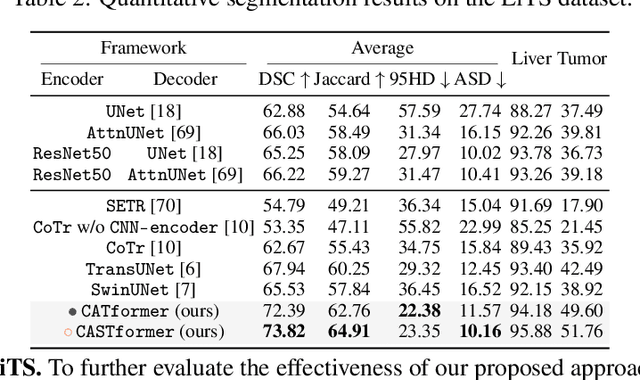
Transformers have made remarkable progress towards modeling long-range dependencies within the medical image analysis domain. However, current transformer-based models suffer from several disadvantages: (1) existing methods fail to capture the important features of the images due to the naive tokenization scheme; (2) the models suffer from information loss because they only consider single-scale feature representations; and (3) the segmentation label maps generated by the models are not accurate enough without considering rich semantic contexts and anatomical textures. In this work, we present CA-GANformer, a novel type of generative adversarial transformers, for medical image segmentation. First, we take advantage of the pyramid structure to construct multi-scale representations and handle multi-scale variations. We then design a novel class-aware transformer module to better learn the discriminative regions of objects with semantic structures. Lastly, we utilize an adversarial training strategy that boosts segmentation accuracy and correspondingly allows a transformer-based discriminator to capture high-level semantically correlated contents and low-level anatomical features. Our experiments demonstrate that CA-GANformer dramatically outperforms previous state-of-the-art transformer-based approaches on three benchmarks, obtaining 2.54%-5.88% absolute improvements in Dice over previous models. Further qualitative experiments provide a more detailed picture of the model's inner workings, shed light on the challenges in improved transparency, and demonstrate that transfer learning can greatly improve performance and reduce the size of medical image datasets in training, making CA-GANformer a strong starting point for downstream medical image analysis tasks. Codes and models will be available to the public.
CMA-CLIP: Cross-Modality Attention CLIP for Image-Text Classification
Dec 07, 2021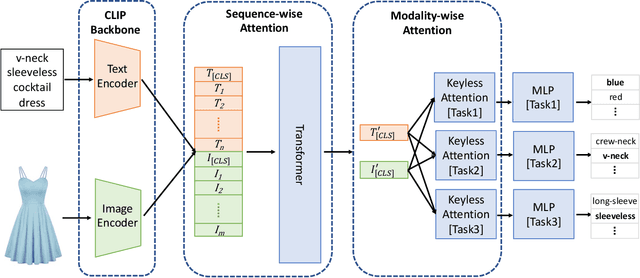

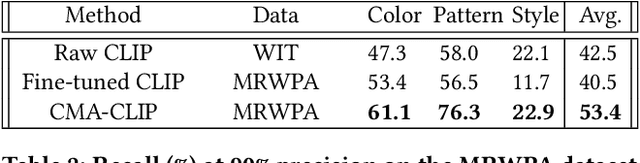

Modern Web systems such as social media and e-commerce contain rich contents expressed in images and text. Leveraging information from multi-modalities can improve the performance of machine learning tasks such as classification and recommendation. In this paper, we propose the Cross-Modality Attention Contrastive Language-Image Pre-training (CMA-CLIP), a new framework which unifies two types of cross-modality attentions, sequence-wise attention and modality-wise attention, to effectively fuse information from image and text pairs. The sequence-wise attention enables the framework to capture the fine-grained relationship between image patches and text tokens, while the modality-wise attention weighs each modality by its relevance to the downstream tasks. In addition, by adding task specific modality-wise attentions and multilayer perceptrons, our proposed framework is capable of performing multi-task classification with multi-modalities. We conduct experiments on a Major Retail Website Product Attribute (MRWPA) dataset and two public datasets, Food101 and Fashion-Gen. The results show that CMA-CLIP outperforms the pre-trained and fine-tuned CLIP by an average of 11.9% in recall at the same level of precision on the MRWPA dataset for multi-task classification. It also surpasses the state-of-the-art method on Fashion-Gen Dataset by 5.5% in accuracy and achieves competitive performance on Food101 Dataset. Through detailed ablation studies, we further demonstrate the effectiveness of both cross-modality attention modules and our method's robustness against noise in image and text inputs, which is a common challenge in practice.
Transfer learning of phase transitions in percolation and directed percolation
Jan 06, 2022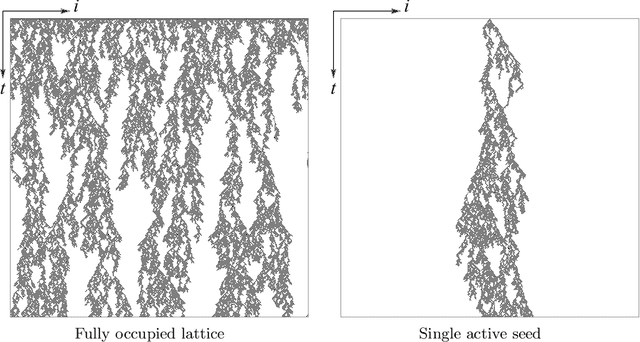
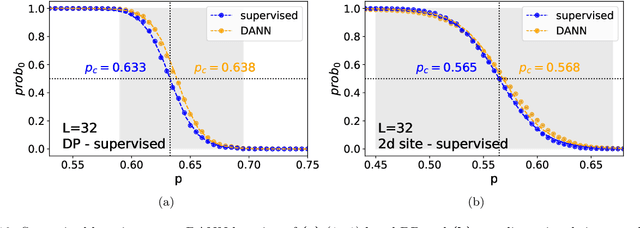

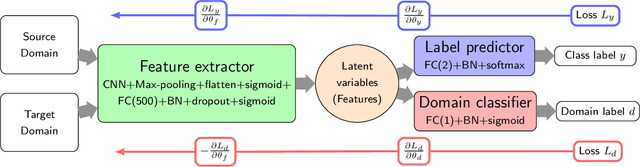
The latest advances of statistical physics have shown remarkable performance of machine learning in identifying phase transitions. In this paper, we apply domain adversarial neural network (DANN) based on transfer learning to studying non-equilibrium and equilibrium phase transition models, which are percolation model and directed percolation (DP) model, respectively. With the DANN, only a small fraction of input configurations (2d images) needs to be labeled, which is automatically chosen, in order to capture the critical point. To learn the DP model, the method is refined by an iterative procedure in determining the critical point, which is a prerequisite for the data collapse in calculating the critical exponent $\nu_{\perp}$. We then apply the DANN to a two-dimensional site percolation with configurations filtered to include only the largest cluster which may contain the information related to the order parameter. The DANN learning of both models yields reliable results which are comparable to the ones from Monte Carlo simulations. Our study also shows that the DANN can achieve quite high accuracy at much lower cost, compared to the supervised learning.
Who says like a style of Vitamin: Towards Syntax-Aware DialogueSummarization using Multi-task Learning
Sep 29, 2021
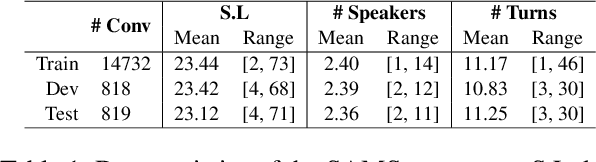
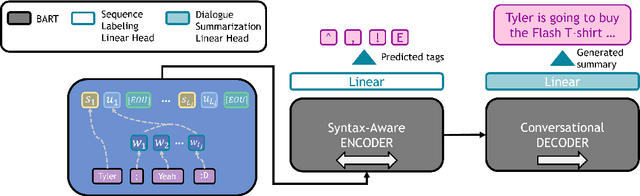
Abstractive dialogue summarization is a challenging task for several reasons. First, most of the important pieces of information in a conversation are scattered across utterances through multi-party interactions with different textual styles. Second, dialogues are often informal structures, wherein different individuals express personal perspectives, unlike text summarization, tasks that usually target formal documents such as news articles. To address these issues, we focused on the association between utterances from individual speakers and unique syntactic structures. Speakers have unique textual styles that can contain linguistic information, such as voiceprint. Therefore, we constructed a syntax-aware model by leveraging linguistic information (i.e., POS tagging), which alleviates the above issues by inherently distinguishing sentences uttered from individual speakers. We employed multi-task learning of both syntax-aware information and dialogue summarization. To the best of our knowledge, our approach is the first method to apply multi-task learning to the dialogue summarization task. Experiments on a SAMSum corpus (a large-scale dialogue summarization corpus) demonstrated that our method improved upon the vanilla model. We further analyze the costs and benefits of our approach relative to baseline models.