 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unsupervised Graph Representation by Periphery and Hierarchical Information Maximization
Jun 08, 2020

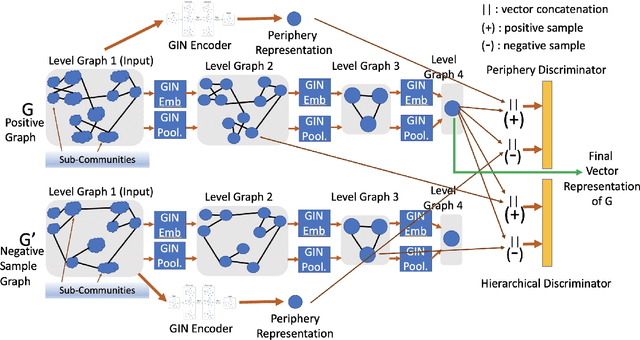
Deep representation learning on non-Euclidean data types, such as graphs, has gained significant attention in recent years. Invent of graph neural networks has improved the state-of-the-art for both node and the entire graph representation in a vector space. However, for the entire graph representation, most of the existing graph neural networks are trained on a graph classification loss in a supervised way. But obtaining labels of a large number of graphs is expensive for real world applications. Thus, we aim to propose an unsupervised graph neural network to generate a vector representation of an entire graph in this paper. For this purpose, we combine the idea of hierarchical graph neural networks and mutual information maximization into a single framework. We also propose and use the concept of periphery representation of a graph and show its usefulness in the proposed algorithm which is referred as GraPHmax. We conduct thorough experiments on several real-world graph datasets and compare the performance of GraPHmax with a diverse set of both supervised and unsupervised baseline algorithms. Experimental results show that we are able to improve the state-of-the-art for multiple graph level tasks on several real-world datasets, while remain competitive on the others.
Alleviating the Transit Timing Variations bias in transit surveys. II. RIVERS: Twin resonant Earth-sized planets around Kepler-1972 recovered from Kepler's false positive
Jan 27, 2022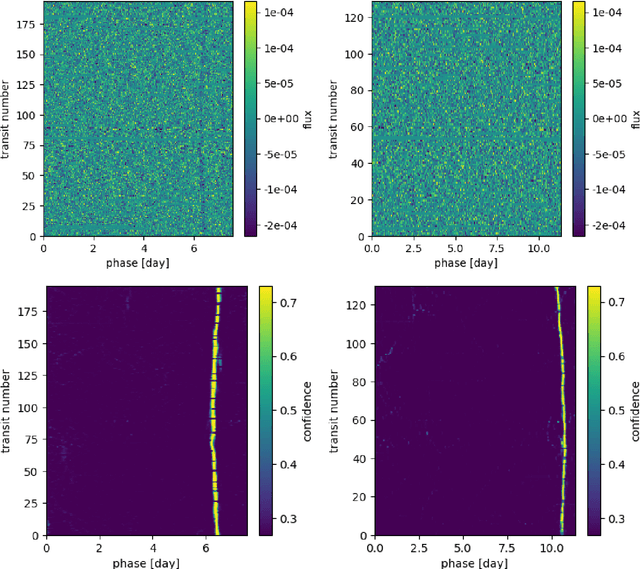
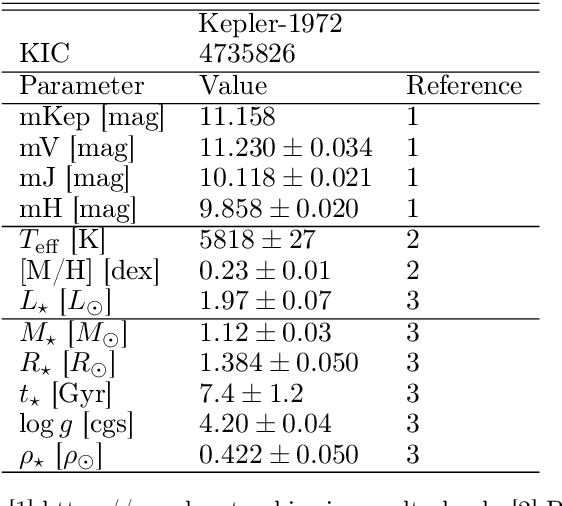
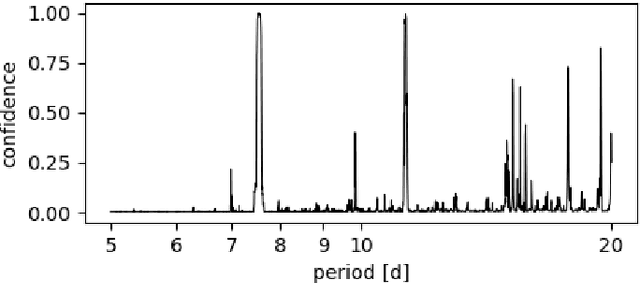
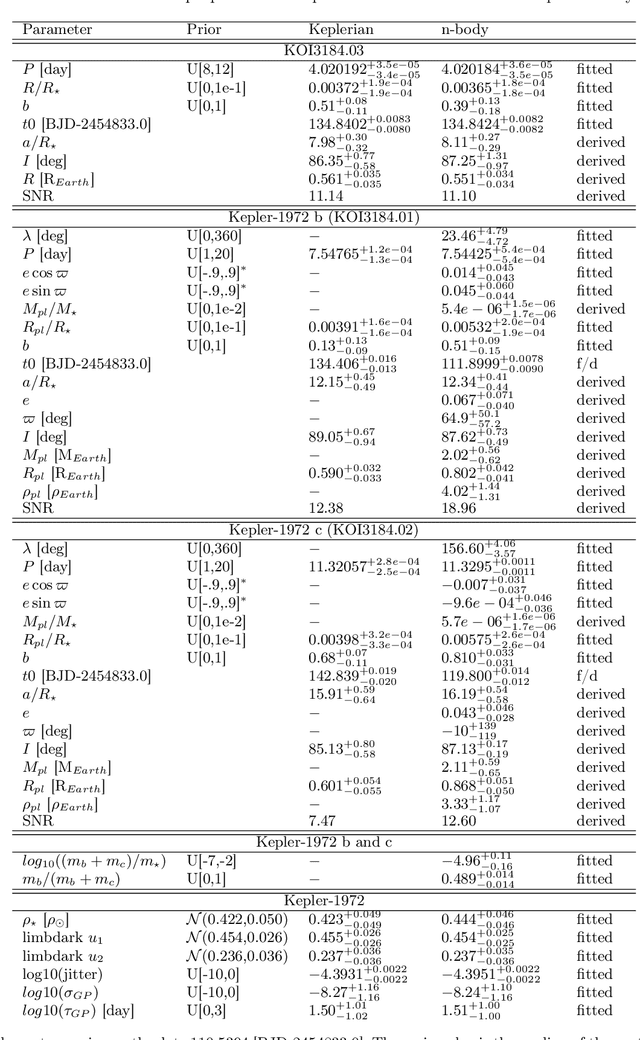
Transit Timing Variations (TTVs) can provide useful information for systems observed by transit, by putting constraints on the masses and eccentricities of the observed planets, or even constrain the existence of non-transiting companions. However, TTVs can also prevent the detection of small planets in transit surveys, or bias the recovered planetary and transit parameters. Here we show that Kepler-1972 c, initially the "not transit-like" false positive KOI-3184.02, is an Earth-sized planet whose orbit is perturbed by Kepler-1972 b (initially KOI-3184.01). The pair is locked in a 3:2 Mean-motion resonance, each planet displaying TTVs of more than 6h hours of amplitude over the duration of the Kepler mission. The two planets have similar masses $m_b/m_c =0.956_{-0.051}^{+0.056}$ and radii $R_b=0.802_{-0.041}^{+0.042}R_{Earth}$, $R_c=0.868_{-0.050}^{+0.051}R_{Earth}$, and the whole system, including the inner candidate KOI-3184.03, appear to be coplanar. Despite the faintness of the signals (SNR of 1.35 for each transit of Kepler-1972 b and 1.10 for Kepler-1972 c), we recovered the transits of the planets using the RIVERS method, based on the recognition of the tracks of planets in river diagrams using machine learning, and a photo-dynamic fit of the lightcurve. Recovering the correct ephemerides of the planets is essential to have a complete picture of the observed planetary systems. In particular, we show that in Kepler-1972, not taking into account planet-planet interactions yields an error of $\sim 30\%$ on the radii of planets b and c, in addition to generating in-transit scatter, which leads to mistake KOI3184.02 for a false positive. Alleviating this bias is essential for an unbiased view of Kepler systems, some of the TESS stars, and the upcoming PLATO mission.
A novel attention model for salient structure detection in seismic volumes
Jan 17, 2022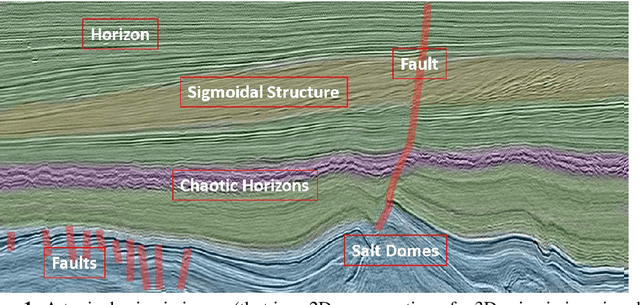
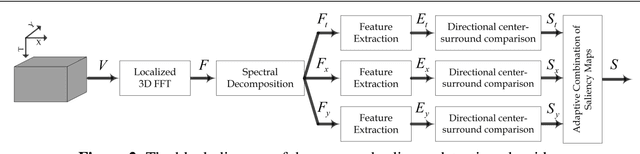
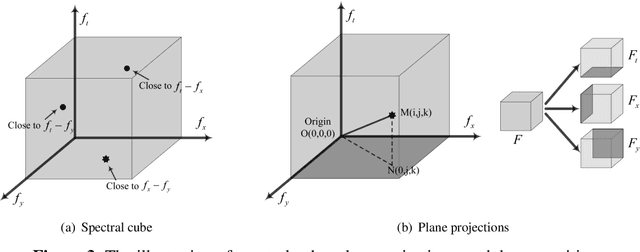
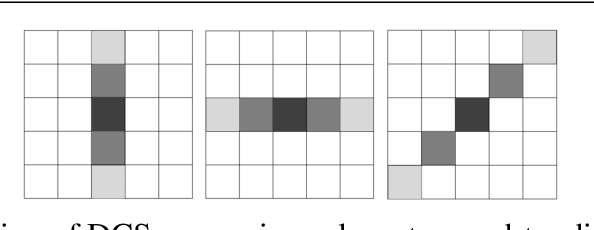
A new approach to seismic interpretation is proposed to leverage visual perception and human visual system modeling. Specifically, a saliency detection algorithm based on a novel attention model is proposed for identifying subsurface structures within seismic data volumes. The algorithm employs 3D-FFT and a multi-dimensional spectral projection, which decomposes local spectra into three distinct components, each depicting variations along different dimensions of the data. Subsequently, a novel directional center-surround attention model is proposed to incorporate directional comparisons around each voxel for saliency detection within each projected dimension. Next, the resulting saliency maps along each dimension are combined adaptively to yield a consolidated saliency map, which highlights various structures characterized by subtle variations and relative motion with respect to their neighboring sections. A priori information about the seismic data can be either embedded into the proposed attention model in the directional comparisons, or incorporated into the algorithm by specifying a template when combining saliency maps adaptively. Experimental results on two real seismic datasets from the North Sea, Netherlands and Great South Basin, New Zealand demonstrate the effectiveness of the proposed algorithm for detecting salient seismic structures of different natures and appearances in one shot, which differs significantly from traditional seismic interpretation algorithms. The results further demonstrate that the proposed method outperforms comparable state-of-the-art saliency detection algorithms for natural images and videos, which are inadequate for seismic imaging data.
* Published in Applied Computing and Intelligence, Nov. 2021
Radar Aided Proactive Blockage Prediction in Real-World Millimeter Wave Systems
Nov 29, 2021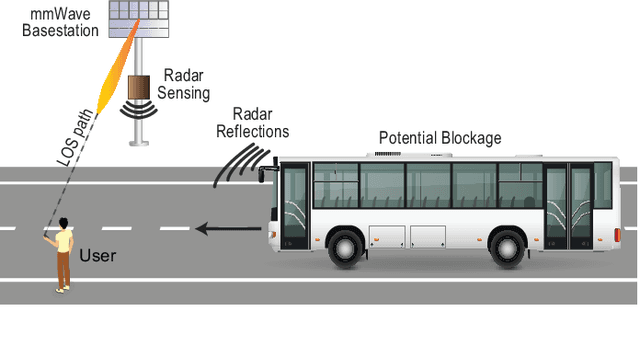
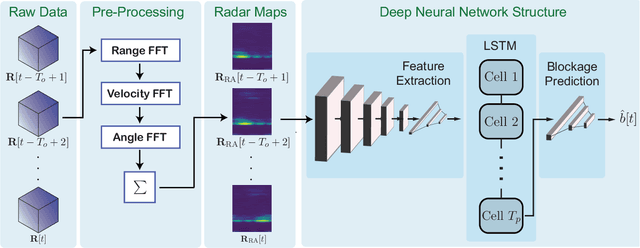
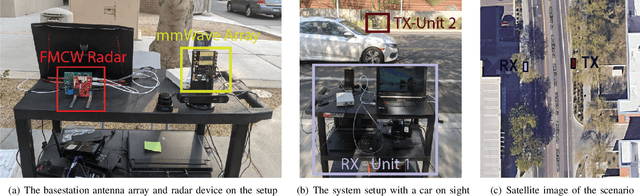
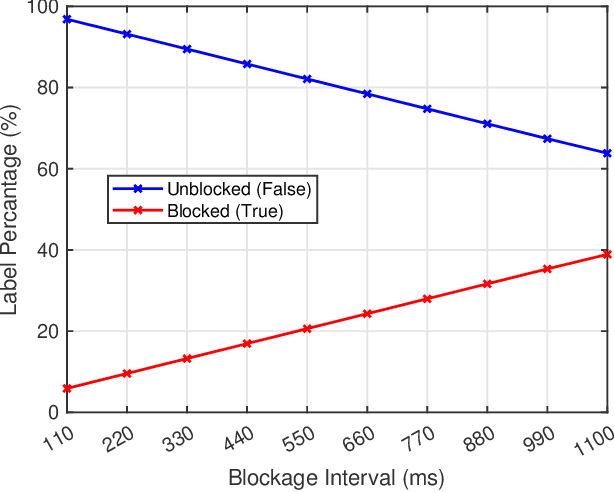
Millimeter wave (mmWave) and sub-terahertz communication systems rely mainly on line-of-sight (LOS) links between the transmitters and receivers. The sensitivity of these high-frequency LOS links to blockages, however, challenges the reliability and latency requirements of these communication networks. In this paper, we propose to utilize radar sensors to provide sensing information about the surrounding environment and moving objects, and leverage this information to proactively predict future link blockages before they happen. This is motivated by the low cost of the radar sensors, their ability to efficiently capture important features such as the range, angle, velocity of the moving scatterers (candidate blockages), and their capability to capture radar frames at relatively high speed. We formulate the radar-aided proactive blockage prediction problem and develop two solutions for this problem based on classical radar object tracking and deep neural networks. The two solutions are designed to leverage domain knowledge and the understanding of the blockage prediction problem. To accurately evaluate the proposed solutions, we build a large-scale real-world dataset, based on the DeepSense framework, gathering co-existing radar and mmWave communication measurements of more than $10$ thousand data points and various blockage objects (vehicles, bikes, humans, etc.). The evaluation results, based on this dataset, show that the proposed approaches can predict future blockages $1$ second before they happen with more than $90\%$ $F_1$ score (and more than $90\%$ accuracy). These results, among others, highlight a promising solution for blockage prediction and reliability enhancement in future wireless mmWave and terahertz communication systems.
Towards Automatic Clustering Analysis using Traces of Information Gain: The InfoGuide Method
Jan 23, 2020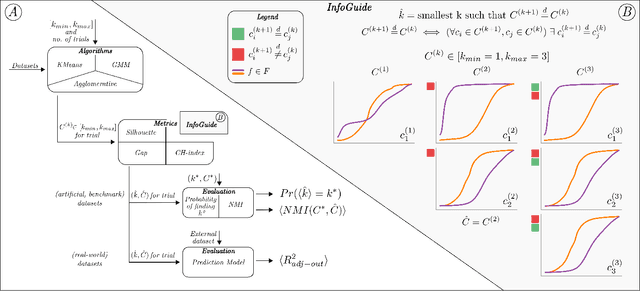
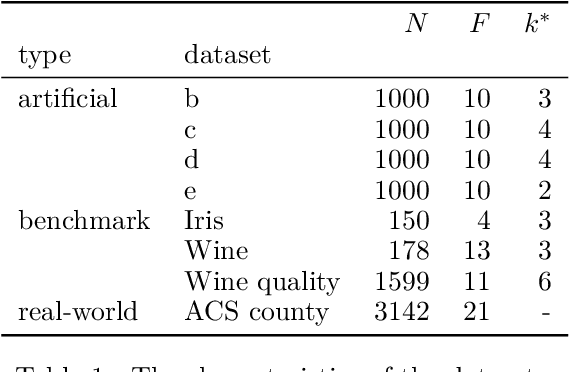
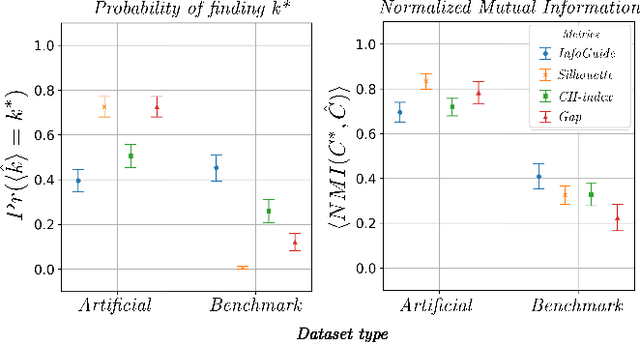
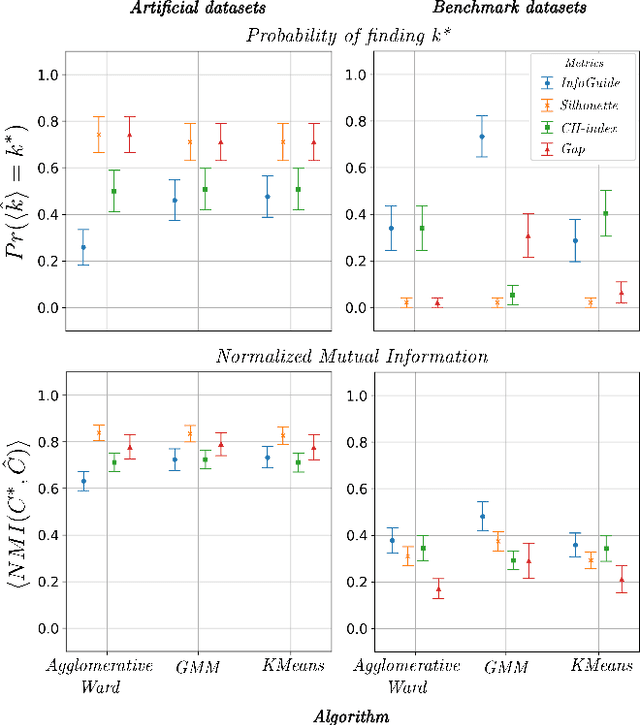
Clustering analysis has become a ubiquitous information retrieval tool in a wide range of domains, but a more automatic framework is still lacking. Though internal metrics are the key players towards a successful retrieval of clusters, their effectiveness on real-world datasets remains not fully understood, mainly because of their unrealistic assumptions underlying datasets. We hypothesized that capturing {\it traces of information gain} between increasingly complex clustering retrievals---{\it InfoGuide}---enables an automatic clustering analysis with improved clustering retrievals. We validated the {\it InfoGuide} hypothesis by capturing the traces of information gain using the Kolmogorov-Smirnov statistic and comparing the clusters retrieved by {\it InfoGuide} against those retrieved by other commonly used internal metrics in artificially-generated, benchmarks, and real-world datasets. Our results suggested that {\it InfoGuide} can enable a more automatic clustering analysis and may be more suitable for retrieving clusters in real-world datasets displaying nontrivial statistical properties.
Text Information Aggregation with Centrality Attention
Nov 16, 2020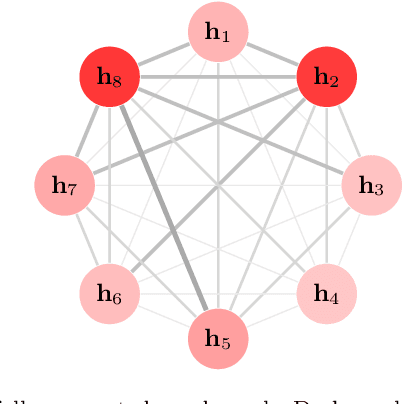
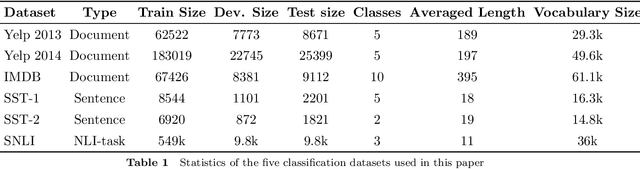
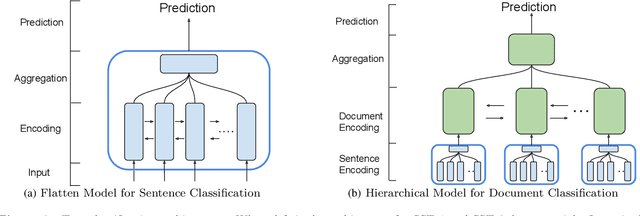
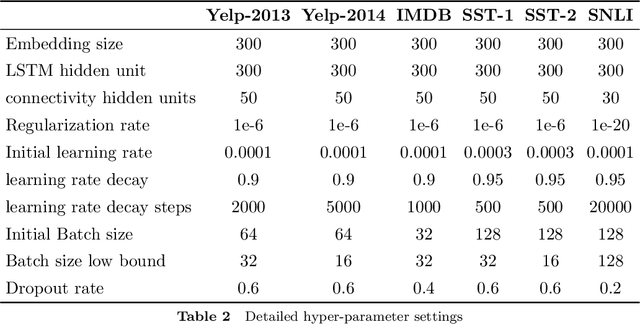
A lot of natural language processing problems need to encode the text sequence as a fix-length vector, which usually involves aggregation process of combining the representations of all the words, such as pooling or self-attention. However, these widely used aggregation approaches did not take higher-order relationship among the words into consideration. Hence we propose a new way of obtaining aggregation weights, called eigen-centrality self-attention. More specifically, we build a fully-connected graph for all the words in a sentence, then compute the eigen-centrality as the attention score of each word. The explicit modeling of relationships as a graph is able to capture some higher-order dependency among words, which helps us achieve better results in 5 text classification tasks and one SNLI task than baseline models such as pooling, self-attention and dynamic routing. Besides, in order to compute the dominant eigenvector of the graph, we adopt power method algorithm to get the eigen-centrality measure. Moreover, we also derive an iterative approach to get the gradient for the power method process to reduce both memory consumption and computation requirement.}
Integrating Physics-Based Modeling with Machine Learning for Lithium-Ion Batteries
Dec 24, 2021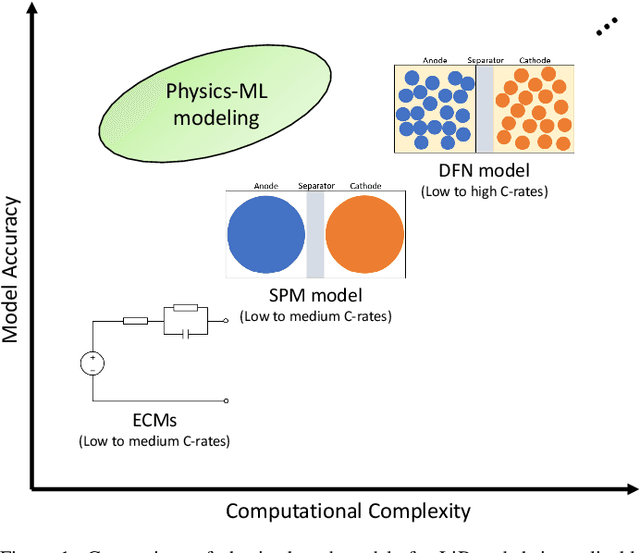
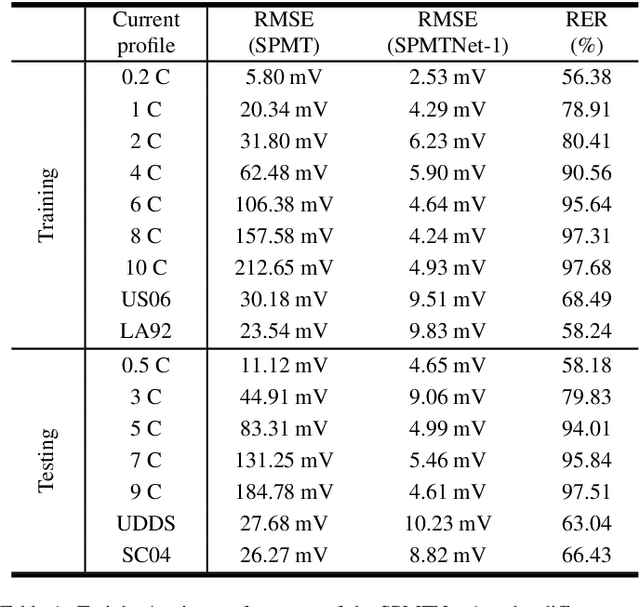
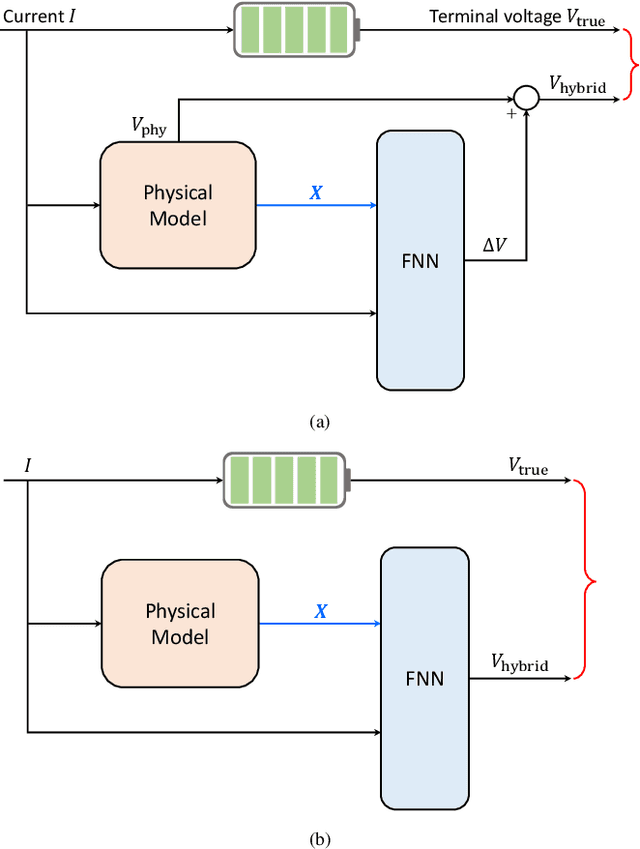
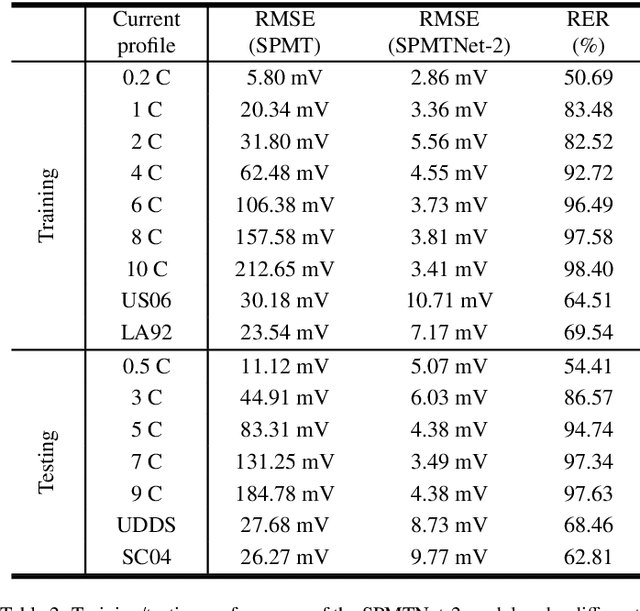
Mathematical modeling of lithium-ion batteries (LiBs) is a primary challenge in advanced battery management. This paper proposes two new frameworks to integrate a physics-based model with machine learning to achieve high-precision modeling for LiBs. The frameworks are characterized by informing the machine learning model of the state information of the physical model, enabling a deep integration between physics and machine learning. Based on the frameworks, a series of hybrid models are constructed, through combining an electrochemical model and an equivalent circuit model, respectively, with a feedforward neural network. The hybrid models are relatively parsimonious in structure and can provide considerable predictive accuracy under a broad range of C-rates, as shown by extensive simulations and experiments. The study further expands to conduct aging-aware hybrid modeling, leading to the design of a hybrid model conscious of the state-of-health to make prediction. Experiments show that the model has high predictive accuracy throughout a LiB's cycle life.
Efficient Multi-Modal Embeddings from Structured Data
Oct 06, 2021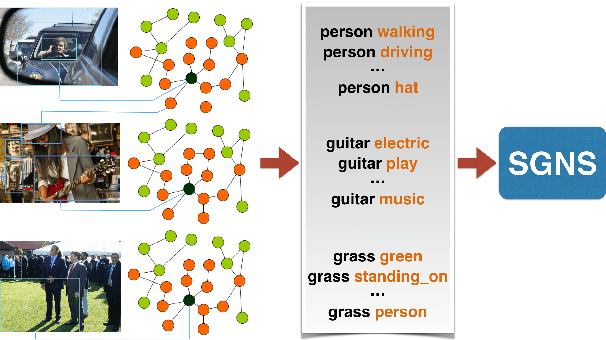
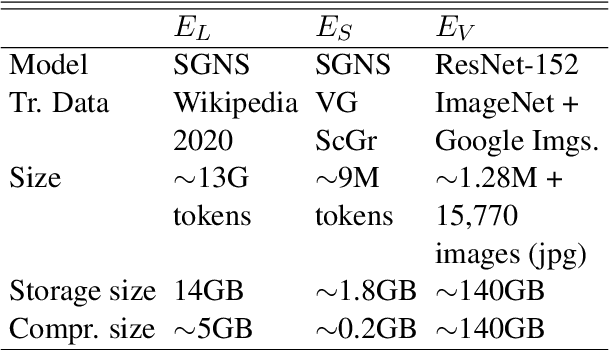
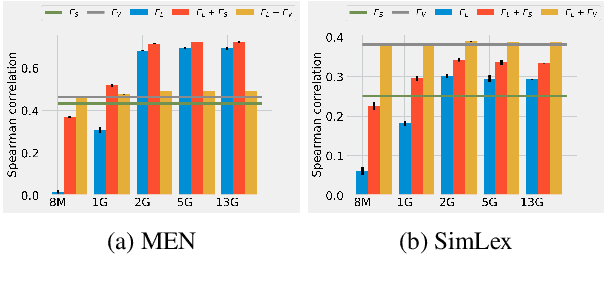
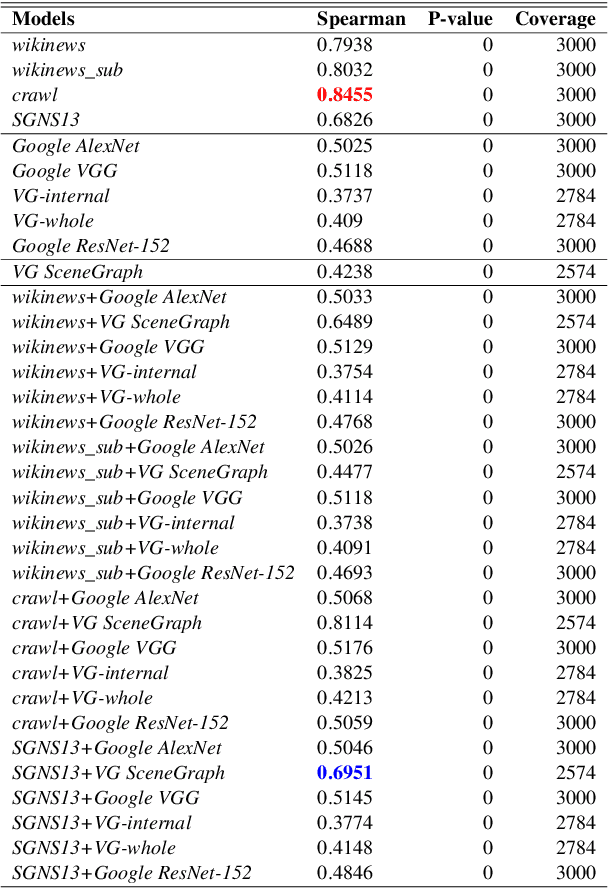
Multi-modal word semantics aims to enhance embeddings with perceptual input, assuming that human meaning representation is grounded in sensory experience. Most research focuses on evaluation involving direct visual input, however, visual grounding can contribute to linguistic applications as well. Another motivation for this paper is the growing need for more interpretable models and for evaluating model efficiency regarding size and performance. This work explores the impact of visual information for semantics when the evaluation involves no direct visual input, specifically semantic similarity and relatedness. We investigate a new embedding type in-between linguistic and visual modalities, based on the structured annotations of Visual Genome. We compare uni- and multi-modal models including structured, linguistic and image based representations. We measure the efficiency of each model with regard to data and model size, modality / data distribution and information gain. The analysis includes an interpretation of embedding structures. We found that this new embedding conveys complementary information for text based embeddings. It achieves comparable performance in an economic way, using orders of magnitude less resources than visual models.
NomMer: Nominate Synergistic Context in Vision Transformer for Visual Recognition
Nov 25, 2021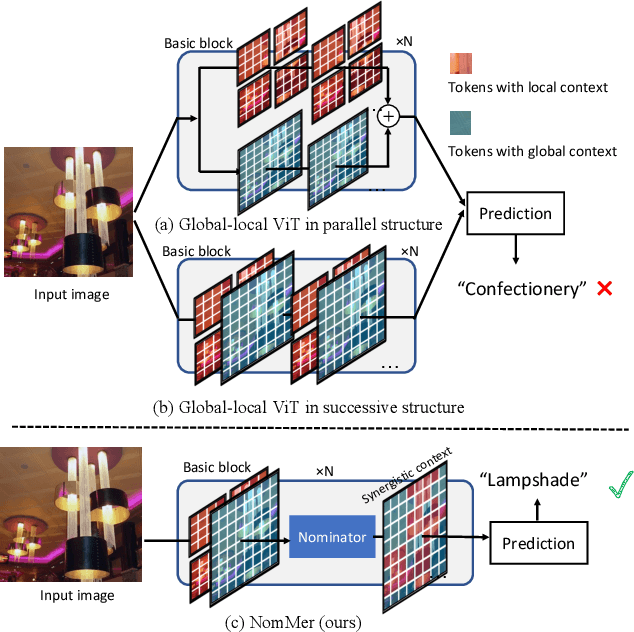
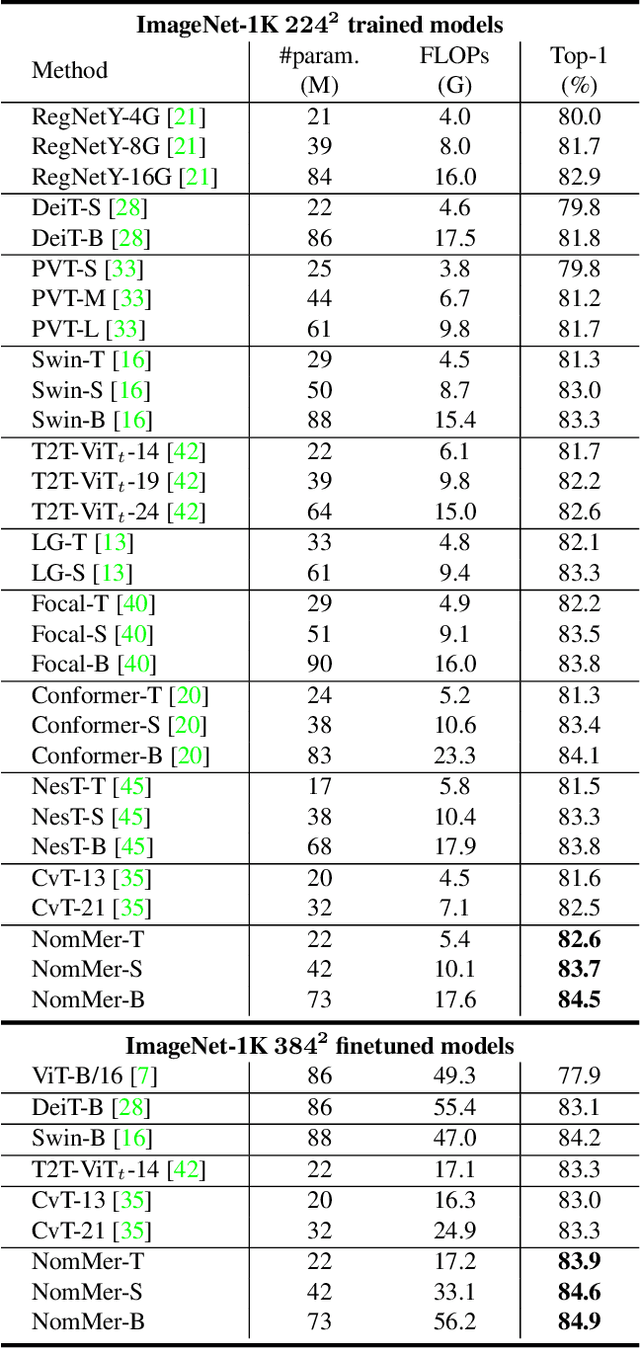
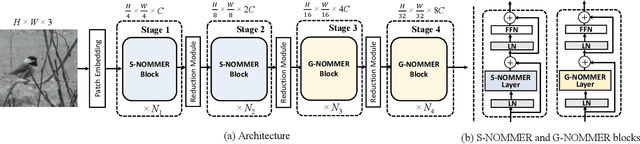
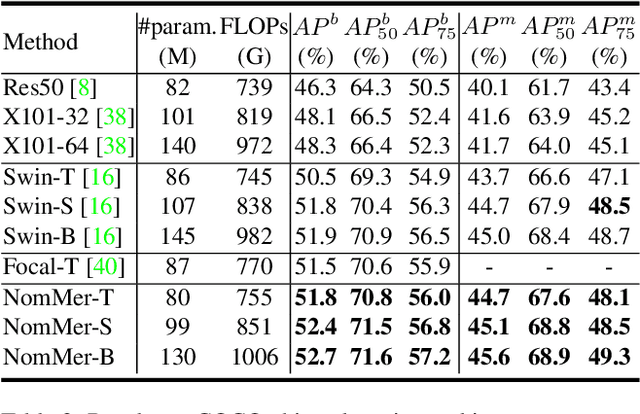
Recently, Vision Transformers (ViT), with the self-attention (SA) as the de facto ingredients, have demonstrated great potential in the computer vision community. For the sake of trade-off between efficiency and performance, a group of works merely perform SA operation within local patches, whereas the global contextual information is abandoned, which would be indispensable for visual recognition tasks. To solve the issue, the subsequent global-local ViTs take a stab at marrying local SA with global one in parallel or alternative way in the model. Nevertheless, the exhaustively combined local and global context may exist redundancy for various visual data, and the receptive field within each layer is fixed. Alternatively, a more graceful way is that global and local context can adaptively contribute per se to accommodate different visual data. To achieve this goal, we in this paper propose a novel ViT architecture, termed NomMer, which can dynamically Nominate the synergistic global-local context in vision transforMer. By investigating the working pattern of our proposed NomMer, we further explore what context information is focused. Beneficial from this "dynamic nomination" mechanism, without bells and whistles, the NomMer can not only achieve 84.5% Top-1 classification accuracy on ImageNet with only 73M parameters, but also show promising performance on dense prediction tasks, i.e., object detection and semantic segmentation. The code and models will be made publicly available at~\url{https://github.com/NomMer1125/NomMer.
Importance Estimation from Multiple Perspectives for Keyphrase Extraction
Nov 11, 2021
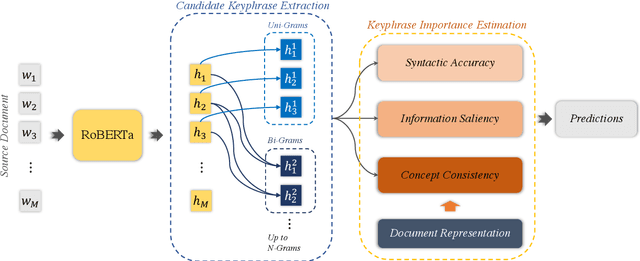

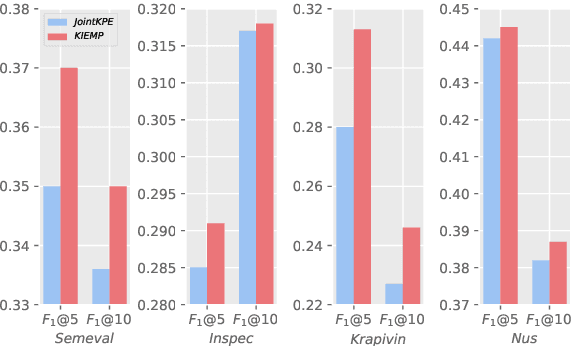
Keyphrase extraction is a fundamental task in Natural Language Processing, which usually contains two main parts: candidate keyphrase extraction and keyphrase importance estimation. From the view of human understanding documents, we typically measure the importance of phrase according to its syntactic accuracy, information saliency, and concept consistency simultaneously. However, most existing keyphrase extraction approaches only focus on the part of them, which leads to biased results. In this paper, we propose a new approach to estimate the importance of keyphrase from multiple perspectives (called as \textit{KIEMP}) and further improve the performance of keyphrase extraction. Specifically, \textit{KIEMP} estimates the importance of phrase with three modules: a chunking module to measure its syntactic accuracy, a ranking module to check its information saliency, and a matching module to judge the concept (i.e., topic) consistency between phrase and the whole document. These three modules are seamlessly jointed together via an end-to-end multi-task learning model, which is helpful for three parts to enhance each other and balance the effects of three perspectives. Experimental results on six benchmark datasets show that \textit{KIEMP} outperforms the existing state-of-the-art keyphrase extraction approaches in most cases.