 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Neural Networks for Rank-Consistent Ordinal Regression Based On Conditional Probabilities
Nov 17, 2021
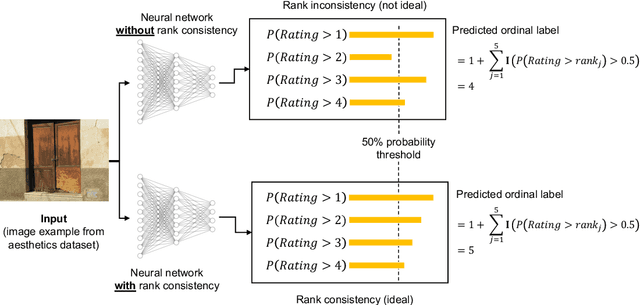
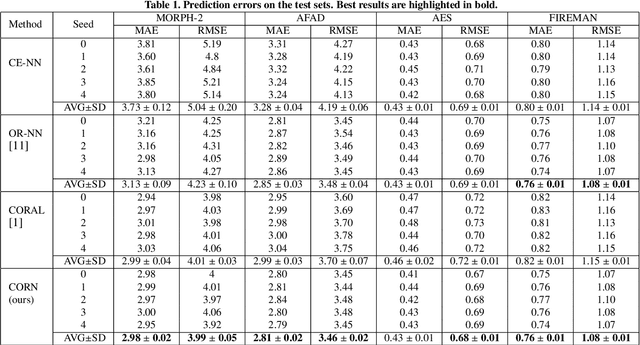
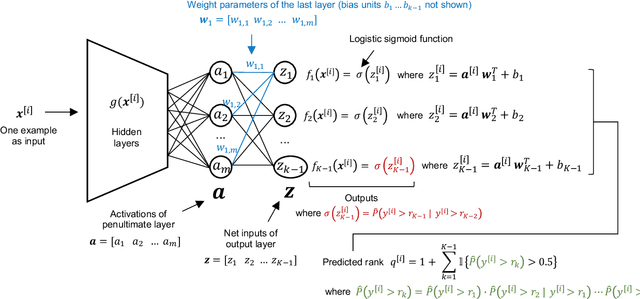
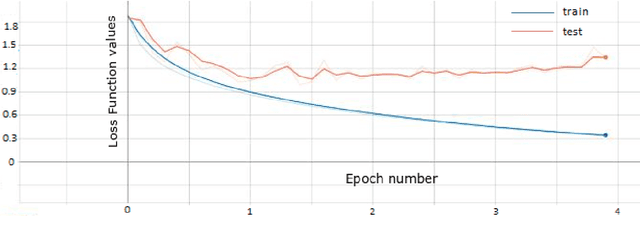
In recent times, deep neural networks achieved outstanding predictive performance on various classification and pattern recognition tasks. However, many real-world prediction problems have ordinal response variables, and this ordering information is ignored by conventional classification losses such as the multi-category cross-entropy. Ordinal regression methods for deep neural networks address this. One such method is the CORAL method, which is based on an earlier binary label extension framework and achieves rank consistency among its output layer tasks by imposing a weight-sharing constraint. However, while earlier experiments showed that CORAL's rank consistency is beneficial for performance, the weight-sharing constraint could severely restrict the expressiveness of a deep neural network. In this paper, we propose an alternative method for rank-consistent ordinal regression that does not require a weight-sharing constraint in a neural network's fully connected output layer. We achieve this rank consistency by a novel training scheme using conditional training sets to obtain the unconditional rank probabilities through applying the chain rule for conditional probability distributions. Experiments on various datasets demonstrate the efficacy of the proposed method to utilize the ordinal target information, and the absence of the weight-sharing restriction improves the performance substantially compared to the CORAL reference approach.
LioNets: A Neural-Specific Local Interpretation Technique Exploiting Penultimate Layer Information
Apr 13, 2021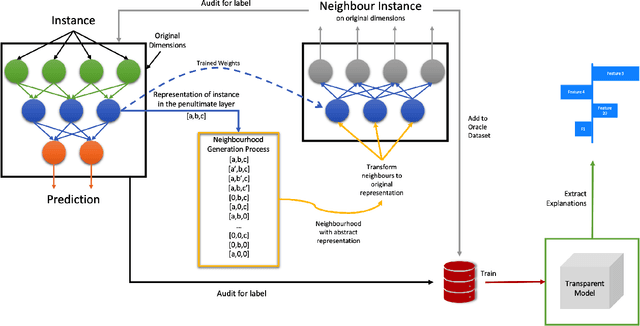
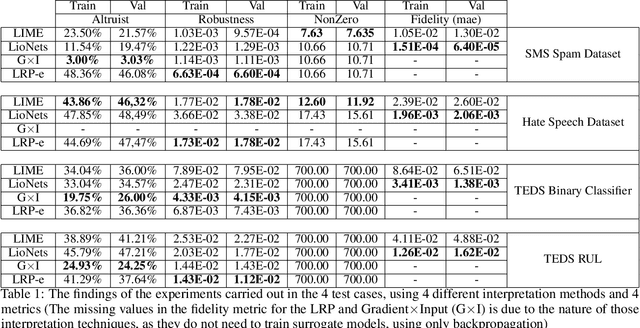
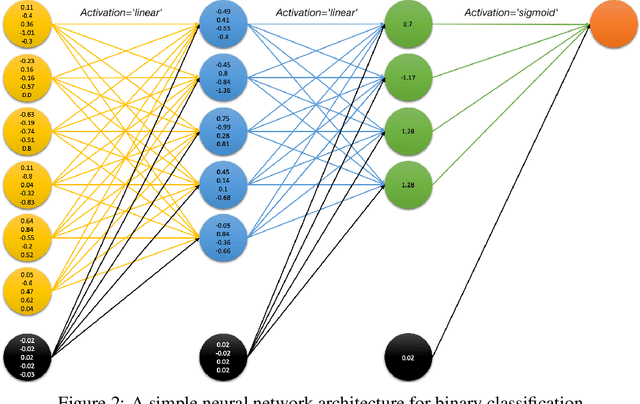

Artificial Intelligence (AI) has a tremendous impact on the unexpected growth of technology in almost every aspect. AI-powered systems are monitoring and deciding about sensitive economic and societal issues. The future is towards automation, and it must not be prevented. However, this is a conflicting viewpoint for a lot of people, due to the fear of uncontrollable AI systems. This concern could be reasonable if it was originating from considerations associated with social issues, like gender-biased, or obscure decision-making systems. Explainable AI (XAI) is recently treated as a huge step towards reliable systems, enhancing the trust of people to AI. Interpretable machine learning (IML), a subfield of XAI, is also an urgent topic of research. This paper presents a small but significant contribution to the IML community, focusing on a local-based, neural-specific interpretation process applied to textual and time-series data. The proposed methodology introduces new approaches to the presentation of feature importance based interpretations, as well as the production of counterfactual words on textual datasets. Eventually, an improved evaluation metric is introduced for the assessment of interpretation techniques, which supports an extensive set of qualitative and quantitative experiments.
Emotion Recognition System from Speech and Visual Information based on Convolutional Neural Networks
Feb 29, 2020
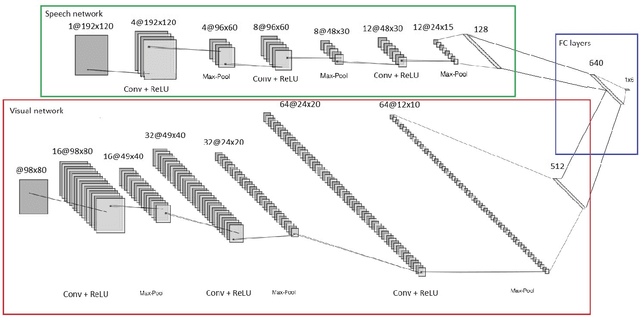
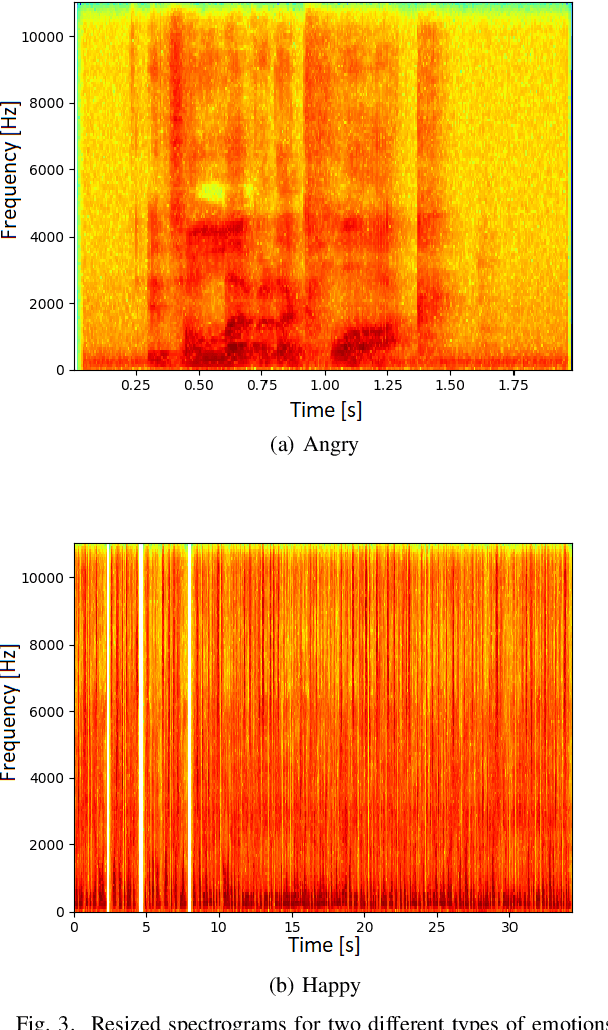
Emotion recognition has become an important field of research in the human-computer interactions domain. The latest advancements in the field show that combining visual with audio information lead to better results if compared to the case of using a single source of information separately. From a visual point of view, a human emotion can be recognized by analyzing the facial expression of the person. More precisely, the human emotion can be described through a combination of several Facial Action Units. In this paper, we propose a system that is able to recognize emotions with a high accuracy rate and in real time, based on deep Convolutional Neural Networks. In order to increase the accuracy of the recognition system, we analyze also the speech data and fuse the information coming from both sources, i.e., visual and audio. Experimental results show the effectiveness of the proposed scheme for emotion recognition and the importance of combining visual with audio data.
GroupIM: A Mutual Information Maximization Framework for Neural Group Recommendation
Jun 05, 2020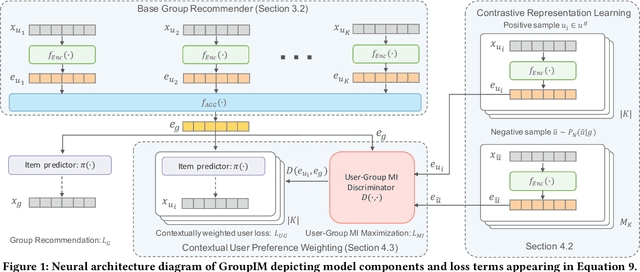
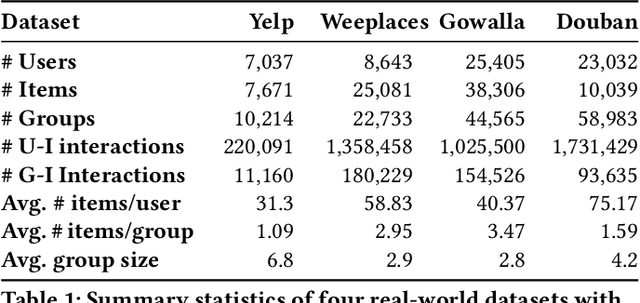
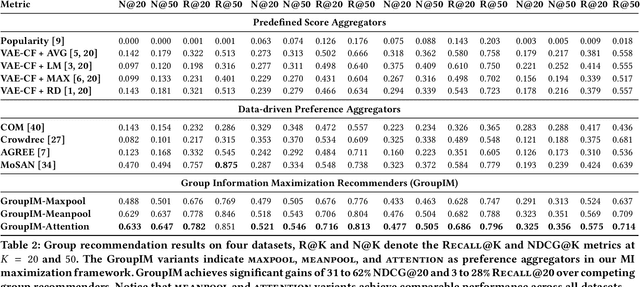
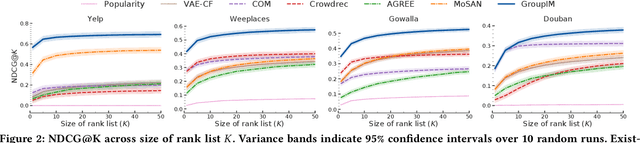
We study the problem of making item recommendations to ephemeral groups, which comprise users with limited or no historical activities together. Existing studies target persistent groups with substantial activity history, while ephemeral groups lack historical interactions. To overcome group interaction sparsity, we propose data-driven regularization strategies to exploit both the preference covariance amongst users who are in the same group, as well as the contextual relevance of users' individual preferences to each group. We make two contributions. First, we present a recommender architecture-agnostic framework GroupIM that can integrate arbitrary neural preference encoders and aggregators for ephemeral group recommendation. Second, we regularize the user-group latent space to overcome group interaction sparsity by: maximizing mutual information between representations of groups and group members; and dynamically prioritizing the preferences of highly informative members through contextual preference weighting. Our experimental results on several real-world datasets indicate significant performance improvements (31-62% relative NDCG@20) over state-of-the-art group recommendation techniques.
CoSEM: Contextual and Semantic Embedding for App Usage Prediction
Aug 26, 2021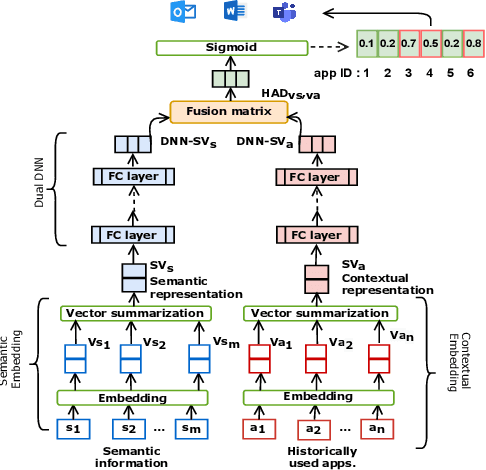
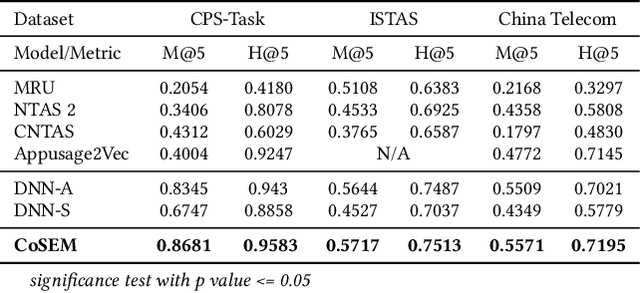
App usage prediction is important for smartphone system optimization to enhance user experience. Existing modeling approaches utilize historical app usage logs along with a wide range of semantic information to predict the app usage; however, they are only effective in certain scenarios and cannot be generalized across different situations. This paper address this problem by developing a model called Contextual and Semantic Embedding model for App Usage Prediction (CoSEM) for app usage prediction that leverages integration of 1) semantic information embedding and 2) contextual information embedding based on historical app usage of individuals. Extensive experiments show that the combination of semantic information and history app usage information enables our model to outperform the baselines on three real-world datasets, achieving an MRR score over 0.55,0.57,0.86 and Hit rate scores of more than 0.71, 0.75, and 0.95, respectively.
Simple Fair Power Allocation for NOMA-Based Visible Light Communication Systems
Dec 08, 2021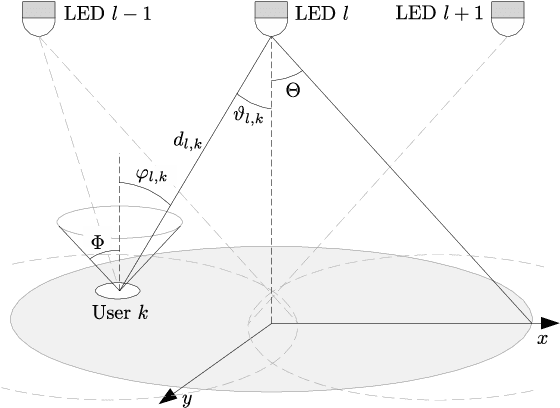
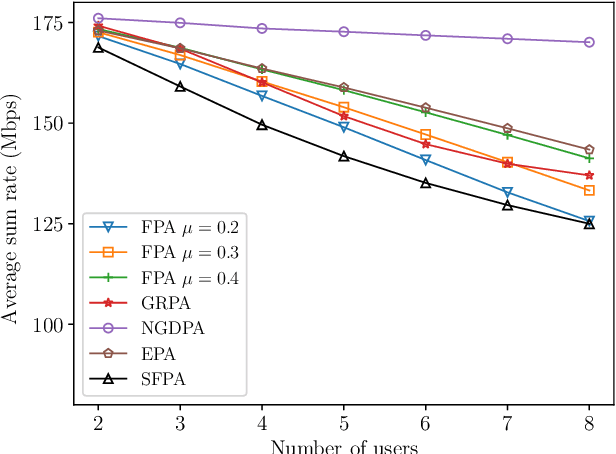
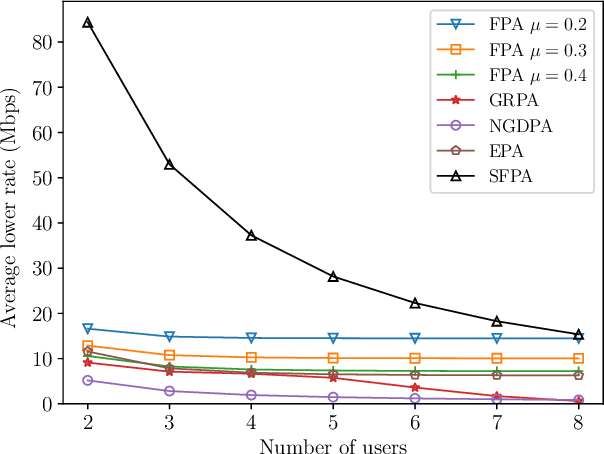
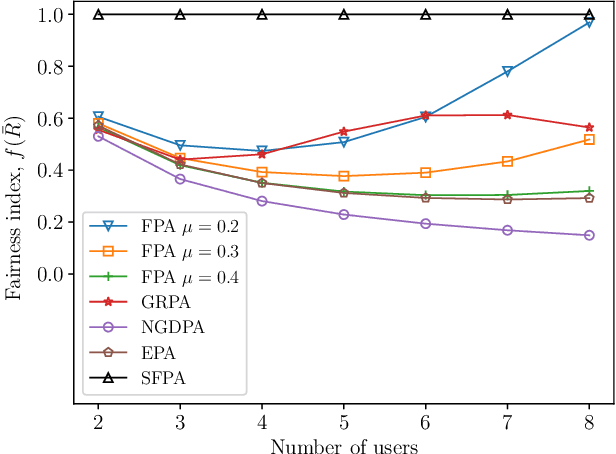
Non-orthogonal multiple access (NOMA) in the power-domain has been recognized as a promising technique to overcome the bandwidth limitations of current visible light communication (VLC) systems. In this letter, we investigate the power allocation (PA) problem in an NOMA-VLC system under high signal-to-noise-ratio (SNR) regime. A simple fair power allocation strategy (SFPA) is proposed to ensure equitable allocation of transmission resources in a multi-user scenario. SFPA requires minimal channel state information (CSI), making it less prone to channel estimation errors. Results show that NOMA with SFPA provides fairer and higher achievable rates per user (up to 79.5\% higher in the studied setup), without significantly compromising the overall system performance.
Utilizing Wordnets for Cognate Detection among Indian Languages
Dec 30, 2021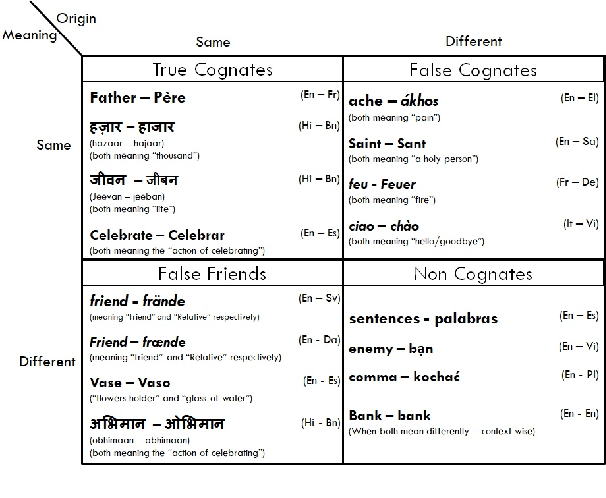
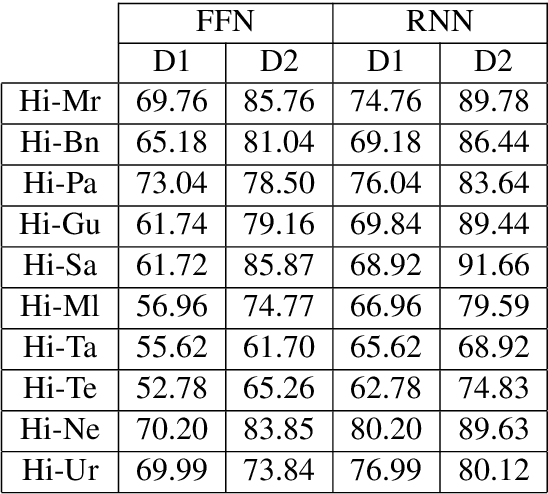
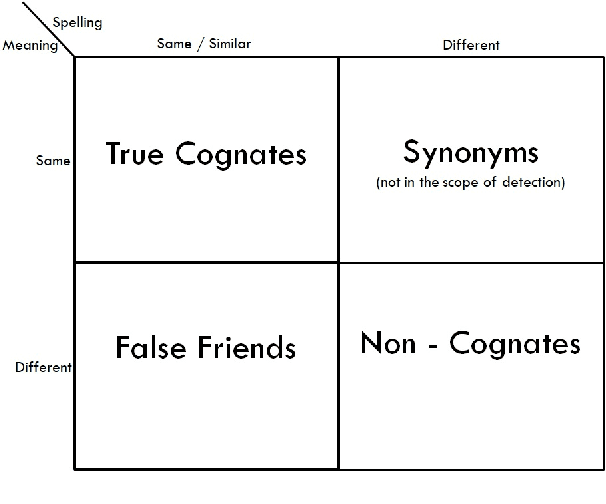
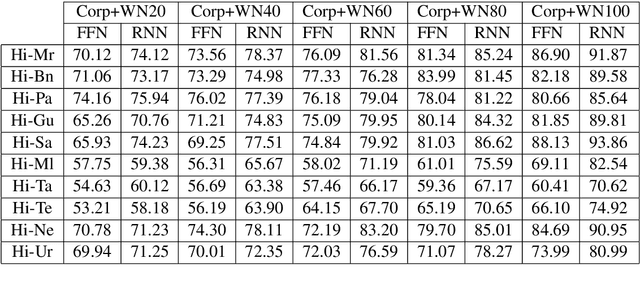
Automatic Cognate Detection (ACD) is a challenging task which has been utilized to help NLP applications like Machine Translation, Information Retrieval and Computational Phylogenetics. Unidentified cognate pairs can pose a challenge to these applications and result in a degradation of performance. In this paper, we detect cognate word pairs among ten Indian languages with Hindi and use deep learning methodologies to predict whether a word pair is cognate or not. We identify IndoWordnet as a potential resource to detect cognate word pairs based on orthographic similarity-based methods and train neural network models using the data obtained from it. We identify parallel corpora as another potential resource and perform the same experiments for them. We also validate the contribution of Wordnets through further experimentation and report improved performance of up to 26%. We discuss the nuances of cognate detection among closely related Indian languages and release the lists of detected cognates as a dataset. We also observe the behaviour of, to an extent, unrelated Indian language pairs and release the lists of detected cognates among them as well.
Contrastive Learning for Local and Global Learning MRI Reconstruction
Nov 30, 2021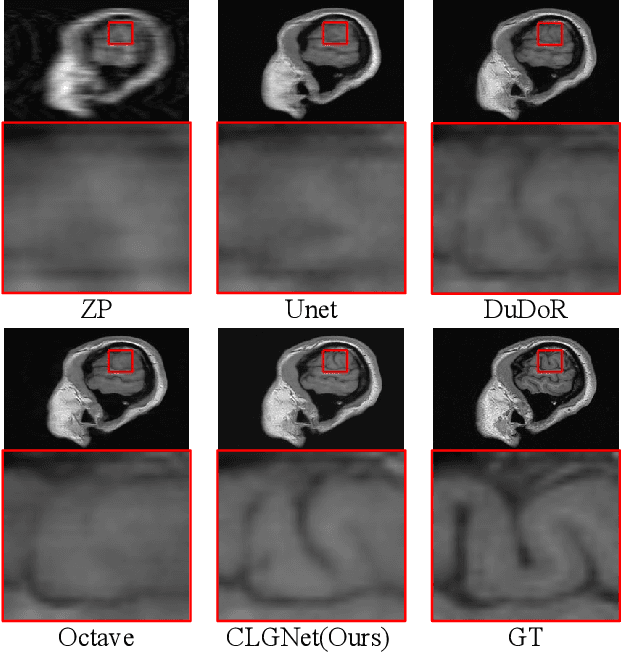
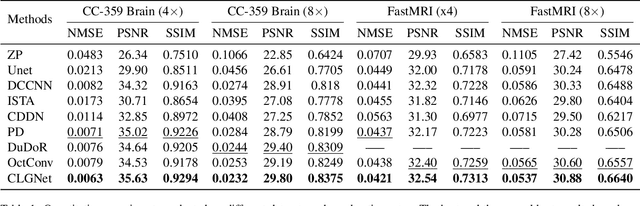
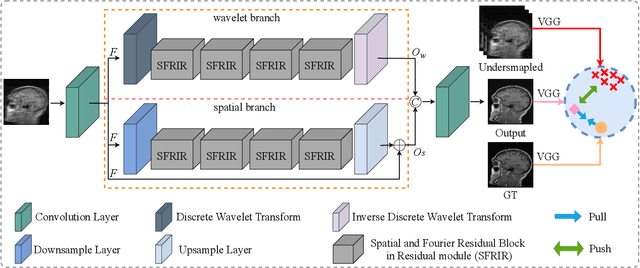
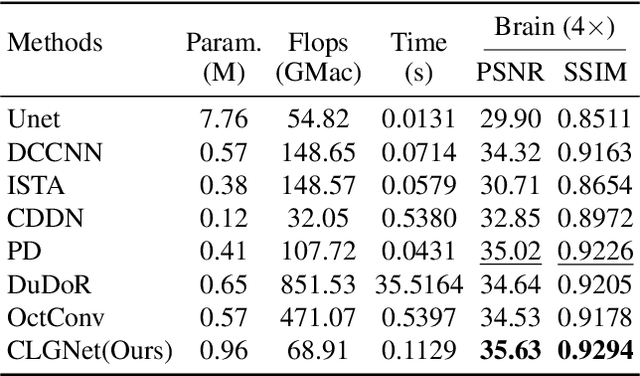
Magnetic Resonance Imaging (MRI) is an important medical imaging modality, while it requires a long acquisition time. To reduce the acquisition time, various methods have been proposed. However, these methods failed to reconstruct images with a clear structure for two main reasons. Firstly, similar patches widely exist in MR images, while most previous deep learning-based methods ignore this property and only adopt CNN to learn local information. Secondly, the existing methods only use clear images to constrain the upper bound of the solution space, while the lower bound is not constrained, so that a better parameter of the network cannot be obtained. To address these problems, we propose a Contrastive Learning for Local and Global Learning MRI Reconstruction Network (CLGNet). Specifically, according to the Fourier theory, each value in the Fourier domain is calculated from all the values in Spatial domain. Therefore, we propose a Spatial and Fourier Layer (SFL) to simultaneously learn the local and global information in Spatial and Fourier domains. Moreover, compared with self-attention and transformer, the SFL has a stronger learning ability and can achieve better performance in less time. Based on the SFL, we design a Spatial and Fourier Residual block as the main component of our model. Meanwhile, to constrain the lower bound and upper bound of the solution space, we introduce contrastive learning, which can pull the result closer to the clear image and push the result further away from the undersampled image. Extensive experimental results on different datasets and acceleration rates demonstrate that the proposed CLGNet achieves new state-of-the-art results.
Data-Centric Semi-Supervised Learning
Oct 06, 2021

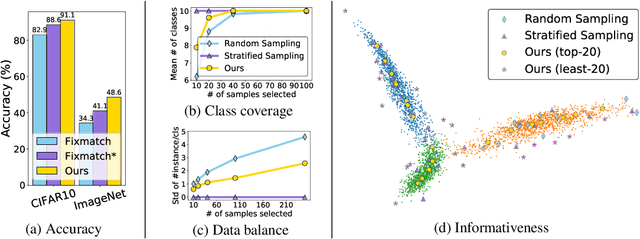

We study unsupervised data selection for semi-supervised learning (SSL), where a large-scale unlabeled data is available and a small subset of data is budgeted for label acquisition. Existing SSL methods focus on learning a model that effectively integrates information from given small labeled data and large unlabeled data, whereas we focus on selecting the right data for SSL without any label or task information, in an also stark contrast to supervised data selection for active learning. Intuitively, instances to be labeled shall collectively have maximum diversity and coverage for downstream tasks, and individually have maximum information propagation utility for SSL. We formalize these concepts in a three-step data-centric SSL method that improves FixMatch in stability and accuracy by 8% on CIFAR-10 (0.08% labeled) and 14% on ImageNet-1K (0.2% labeled). Our work demonstrates that a small compute spent on careful labeled data selection brings big annotation efficiency and model performance gain without changing the learning pipeline. Our completely unsupervised data selection can be easily extended to other weakly supervised learning settings.
Functional Anomaly Detection: a Benchmark Study
Jan 13, 2022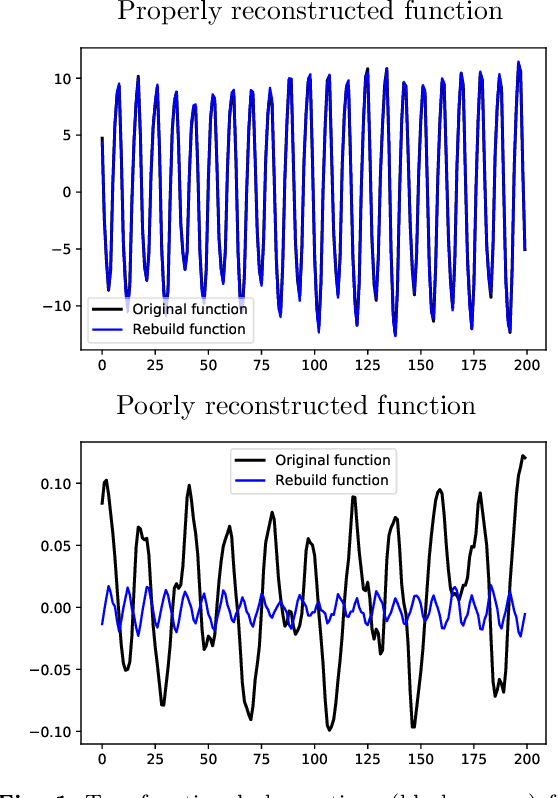
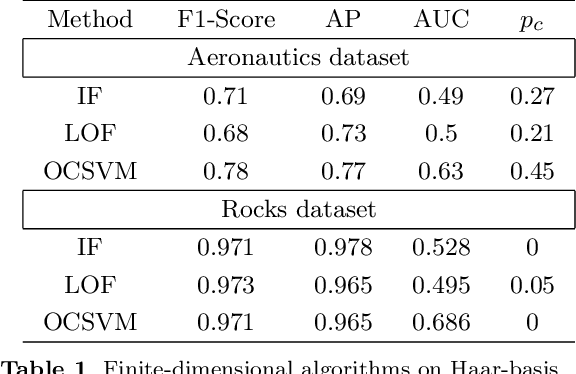
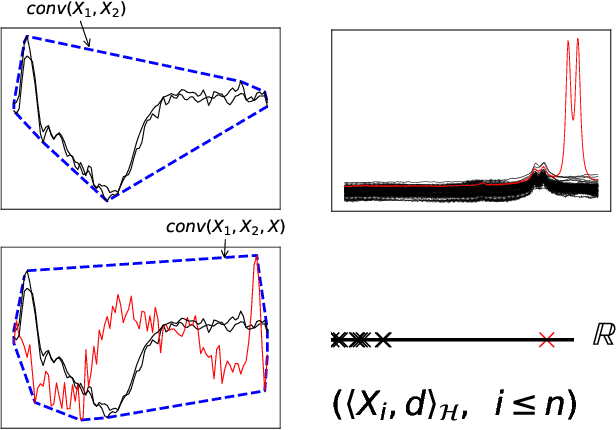
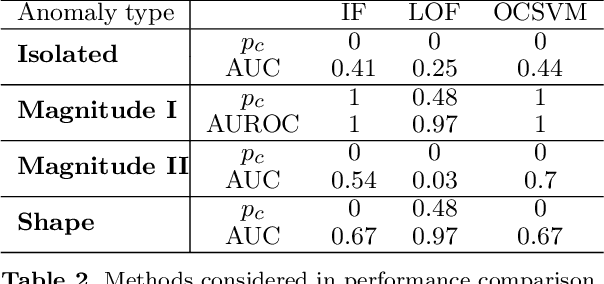
The increasing automation in many areas of the Industry expressly demands to design efficient machine-learning solutions for the detection of abnormal events. With the ubiquitous deployment of sensors monitoring nearly continuously the health of complex infrastructures, anomaly detection can now rely on measurements sampled at a very high frequency, providing a very rich representation of the phenomenon under surveillance. In order to exploit fully the information thus collected, the observations cannot be treated as multivariate data anymore and a functional analysis approach is required. It is the purpose of this paper to investigate the performance of recent techniques for anomaly detection in the functional setup on real datasets. After an overview of the state-of-the-art and a visual-descriptive study, a variety of anomaly detection methods are compared. While taxonomies of abnormalities (e.g. shape, location) in the functional setup are documented in the literature, assigning a specific type to the identified anomalies appears to be a challenging task. Thus, strengths and weaknesses of the existing approaches are benchmarked in view of these highlighted types in a simulation study. Anomaly detection methods are next evaluated on two datasets, related to the monitoring of helicopters in flight and to the spectrometry of construction materials namely. The benchmark analysis is concluded by recommendation guidance for practitioners.