 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Simple Fair Power Allocation for NOMA-Based Visible Light Communication Systems
Dec 08, 2021
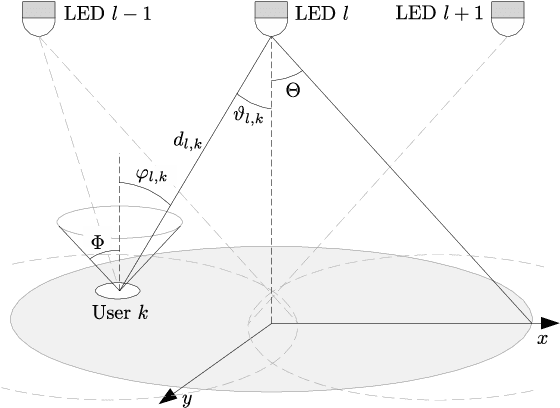
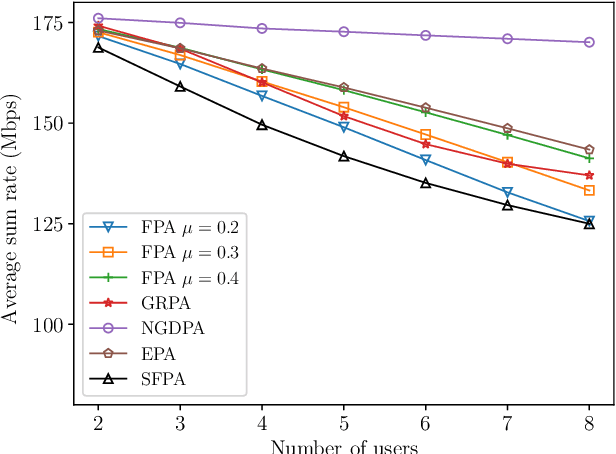
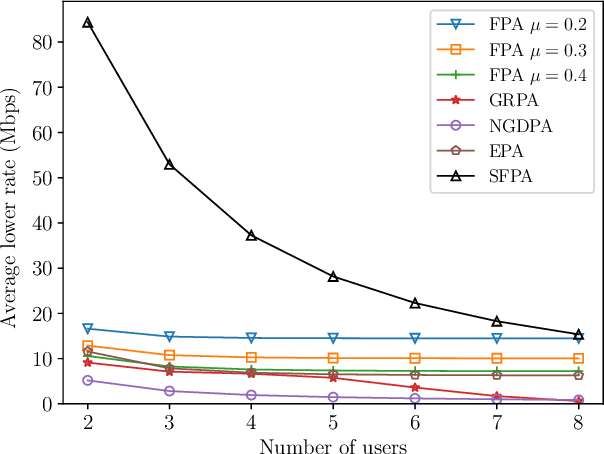
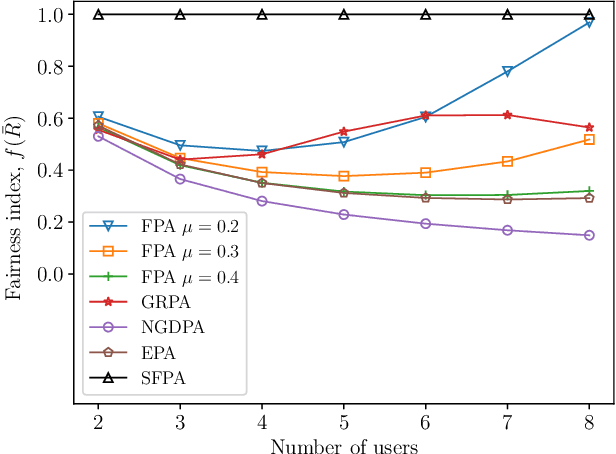
Non-orthogonal multiple access (NOMA) in the power-domain has been recognized as a promising technique to overcome the bandwidth limitations of current visible light communication (VLC) systems. In this letter, we investigate the power allocation (PA) problem in an NOMA-VLC system under high signal-to-noise-ratio (SNR) regime. A simple fair power allocation strategy (SFPA) is proposed to ensure equitable allocation of transmission resources in a multi-user scenario. SFPA requires minimal channel state information (CSI), making it less prone to channel estimation errors. Results show that NOMA with SFPA provides fairer and higher achievable rates per user (up to 79.5\% higher in the studied setup), without significantly compromising the overall system performance.
Continually Learning Self-Supervised Representations with Projected Functional Regularization
Dec 30, 2021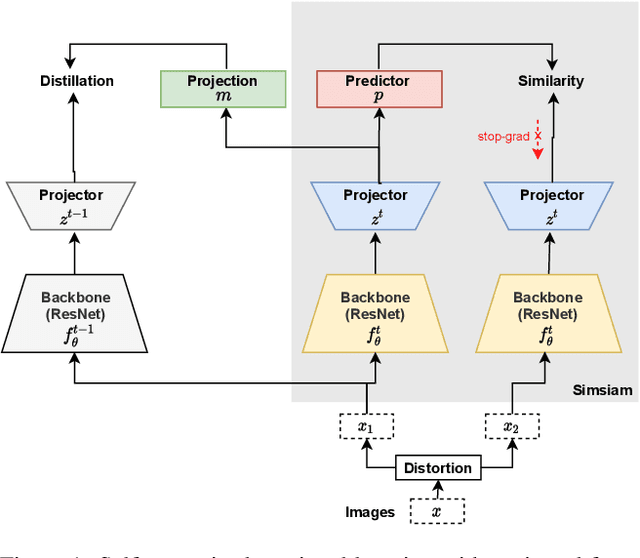
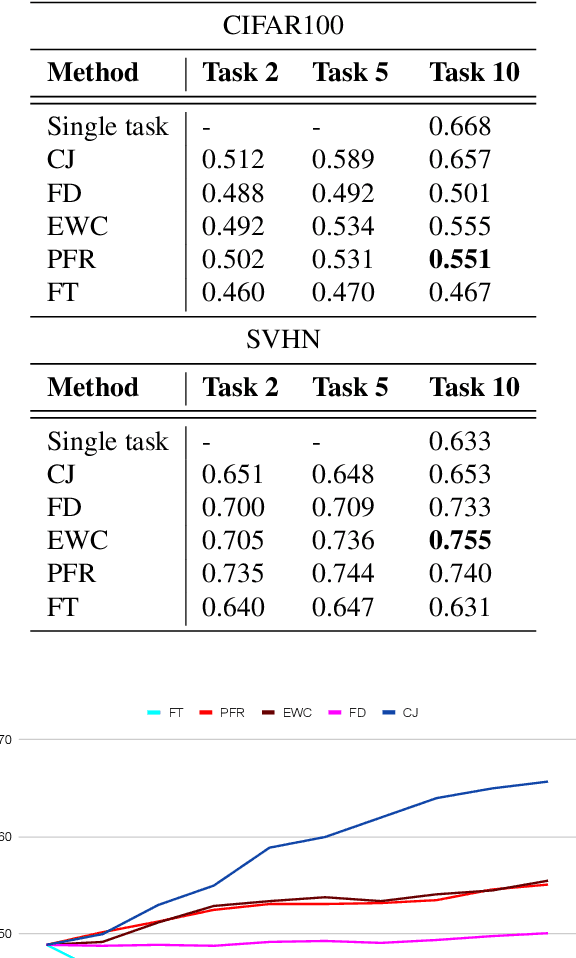
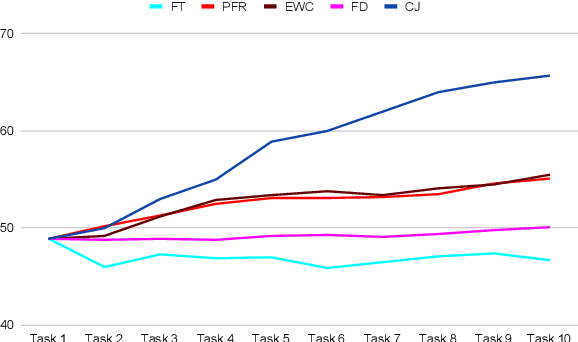
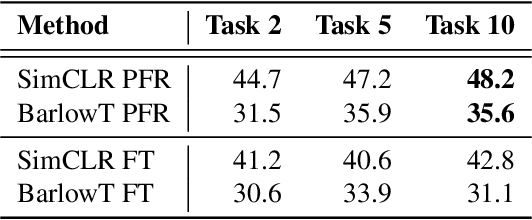
Recent self-supervised learning methods are able to learn high-quality image representations and are closing the gap with supervised methods. However, these methods are unable to acquire new knowledge incrementally -- they are, in fact, mostly used only as a pre-training phase with IID data. In this work we investigate self-supervised methods in continual learning regimes without additional memory or replay. To prevent forgetting of previous knowledge, we propose the usage of functional regularization. We will show that naive functional regularization, also known as feature distillation, leads to low plasticity and therefore seriously limits continual learning performance. To address this problem, we propose Projected Functional Regularization where a separate projection network ensures that the newly learned feature space preserves information of the previous feature space, while allowing for the learning of new features. This allows us to prevent forgetting while maintaining the plasticity of the learner. Evaluation against other incremental learning approaches applied to self-supervision demonstrates that our method obtains competitive performance in different scenarios and on multiple datasets.
Contrastive Learning for Local and Global Learning MRI Reconstruction
Nov 30, 2021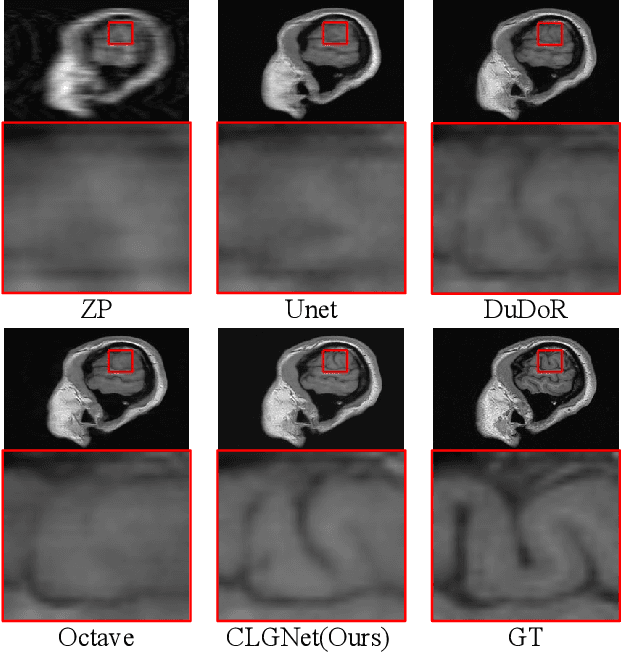
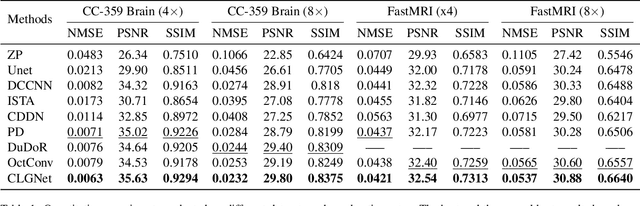
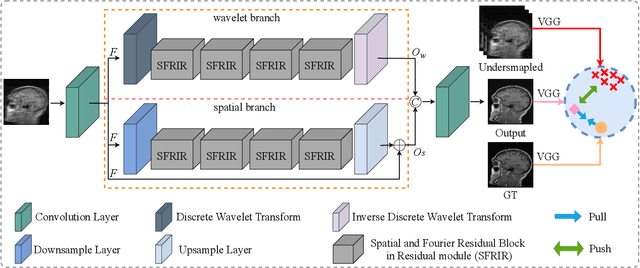
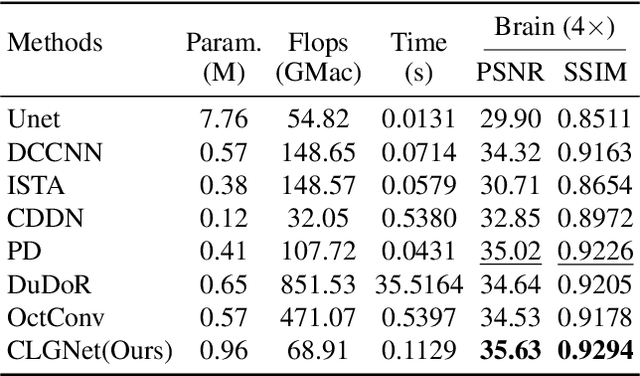
Magnetic Resonance Imaging (MRI) is an important medical imaging modality, while it requires a long acquisition time. To reduce the acquisition time, various methods have been proposed. However, these methods failed to reconstruct images with a clear structure for two main reasons. Firstly, similar patches widely exist in MR images, while most previous deep learning-based methods ignore this property and only adopt CNN to learn local information. Secondly, the existing methods only use clear images to constrain the upper bound of the solution space, while the lower bound is not constrained, so that a better parameter of the network cannot be obtained. To address these problems, we propose a Contrastive Learning for Local and Global Learning MRI Reconstruction Network (CLGNet). Specifically, according to the Fourier theory, each value in the Fourier domain is calculated from all the values in Spatial domain. Therefore, we propose a Spatial and Fourier Layer (SFL) to simultaneously learn the local and global information in Spatial and Fourier domains. Moreover, compared with self-attention and transformer, the SFL has a stronger learning ability and can achieve better performance in less time. Based on the SFL, we design a Spatial and Fourier Residual block as the main component of our model. Meanwhile, to constrain the lower bound and upper bound of the solution space, we introduce contrastive learning, which can pull the result closer to the clear image and push the result further away from the undersampled image. Extensive experimental results on different datasets and acceleration rates demonstrate that the proposed CLGNet achieves new state-of-the-art results.
Streamlining Evaluation with ir-measures
Nov 26, 2021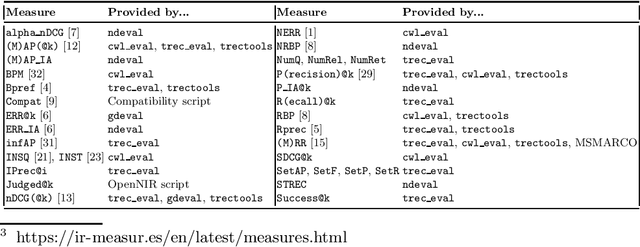
We present ir-measures, a new tool that makes it convenient to calculate a diverse set of evaluation measures used in information retrieval. Rather than implementing its own measure calculations, ir-measures provides a common interface to a handful of evaluation tools. The necessary tools are automatically invoked (potentially multiple times) to calculate all the desired metrics, simplifying the evaluation process for the user. The tool also makes it easier for researchers to use recently-proposed measures (such as those from the C/W/L framework) alongside traditional measures, potentially encouraging their adoption.
What You See is Not What the Network Infers: Detecting Adversarial Examples Based on Semantic Contradiction
Jan 24, 2022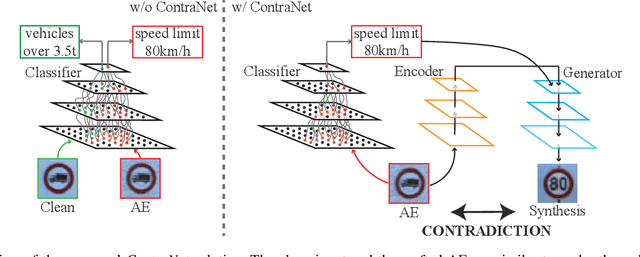

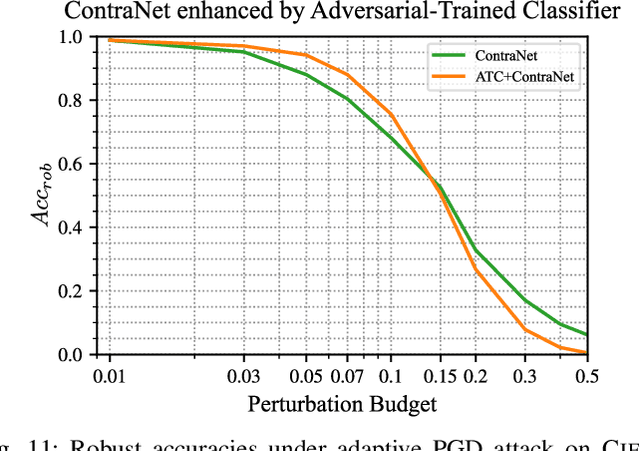

Adversarial examples (AEs) pose severe threats to the applications of deep neural networks (DNNs) to safety-critical domains, e.g., autonomous driving. While there has been a vast body of AE defense solutions, to the best of our knowledge, they all suffer from some weaknesses, e.g., defending against only a subset of AEs or causing a relatively high accuracy loss for legitimate inputs. Moreover, most existing solutions cannot defend against adaptive attacks, wherein attackers are knowledgeable about the defense mechanisms and craft AEs accordingly. In this paper, we propose a novel AE detection framework based on the very nature of AEs, i.e., their semantic information is inconsistent with the discriminative features extracted by the target DNN model. To be specific, the proposed solution, namely ContraNet, models such contradiction by first taking both the input and the inference result to a generator to obtain a synthetic output and then comparing it against the original input. For legitimate inputs that are correctly inferred, the synthetic output tries to reconstruct the input. On the contrary, for AEs, instead of reconstructing the input, the synthetic output would be created to conform to the wrong label whenever possible. Consequently, by measuring the distance between the input and the synthetic output with metric learning, we can differentiate AEs from legitimate inputs. We perform comprehensive evaluations under various AE attack scenarios, and experimental results show that ContraNet outperforms existing solutions by a large margin, especially under adaptive attacks. Moreover, our analysis shows that successful AEs that can bypass ContraNet tend to have much-weakened adversarial semantics. We have also shown that ContraNet can be easily combined with adversarial training techniques to achieve further improved AE defense capabilities.
Actionable Approaches to Promote Ethical AI in Libraries
Sep 20, 2021The widespread use of artificial intelligence (AI) in many domains has revealed numerous ethical issues from data and design to deployment. In response, countless broad principles and guidelines for ethical AI have been published, and following those, specific approaches have been proposed for how to encourage ethical outcomes of AI. Meanwhile, library and information services too are seeing an increase in the use of AI-powered and machine learning-powered information systems, but no practical guidance currently exists for libraries to plan for, evaluate, or audit the ethics of intended or deployed AI. We therefore report on several promising approaches for promoting ethical AI that can be adapted from other contexts to AI-powered information services and in different stages of the software lifecycle.
DRBANET: A Lightweight Dual-Resolution Network for Semantic Segmentation with Boundary Auxiliary
Oct 31, 2021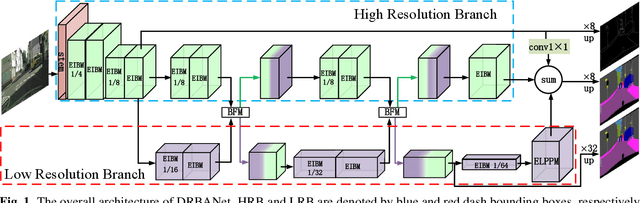
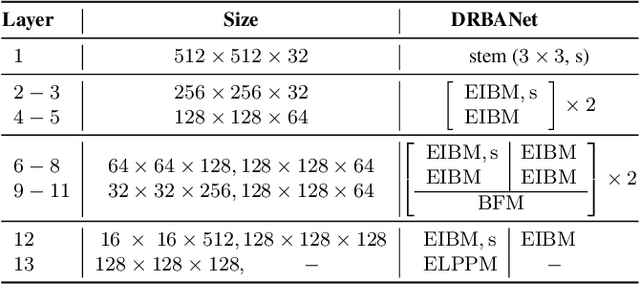
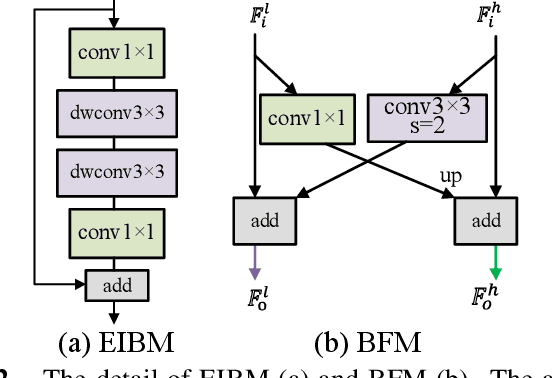
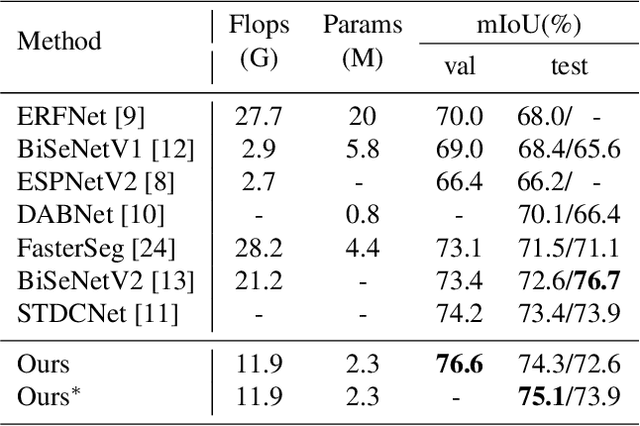
Due to the powerful ability to encode image details and semantics, many lightweight dual-resolution networks have been proposed in recent years. However, most of them ignore the benefit of boundary information. This paper introduces a lightweight dual-resolution network, called DRBANet, aiming to refine semantic segmentation results with the aid of boundary information. DRBANet adopts dual parallel architecture, including: high resolution branch (HRB) and low resolution branch (LRB). Specifically, HRB mainly consists of a set of Efficient Inverted Bottleneck Modules (EIBMs), which learn feature representations with larger receptive fields. LRB is composed of a series of EIBMs and an Extremely Lightweight Pyramid Pooling Module (ELPPM), where ELPPM is utilized to capture multi-scale context through hierarchical residual connections. Finally, a boundary supervision head is designed to capture object boundaries in HRB. Extensive experiments on Cityscapes and CamVid datasets demonstrate that our method achieves promising trade-off between segmentation accuracy and running efficiency.
Multi-Scale Feature Fusion: Learning Better Semantic Segmentation for Road Pothole Detection
Dec 24, 2021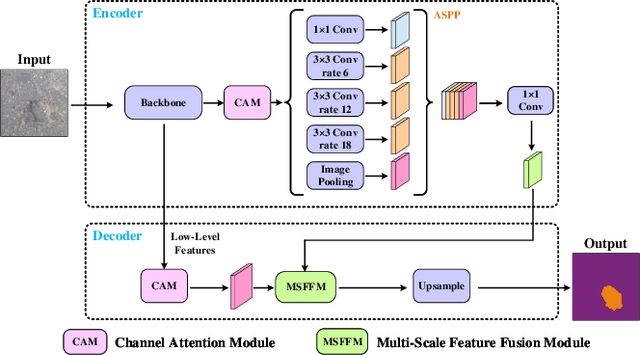
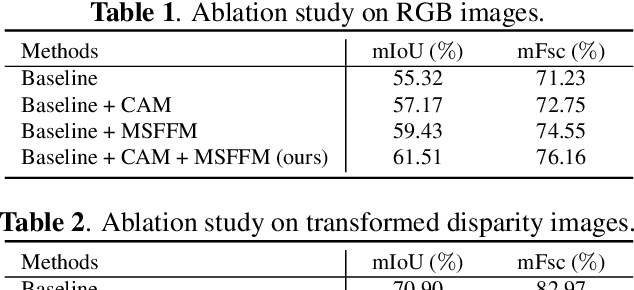
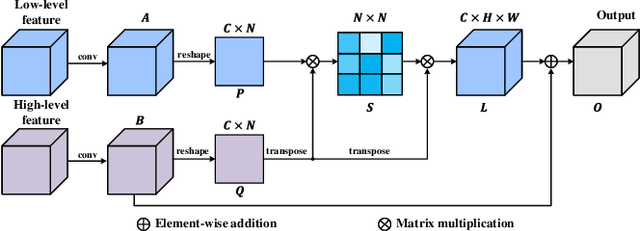
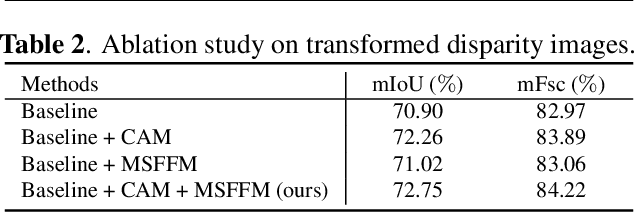
This paper presents a novel pothole detection approach based on single-modal semantic segmentation. It first extracts visual features from input images using a convolutional neural network. A channel attention module then reweighs the channel features to enhance the consistency of different feature maps. Subsequently, we employ an atrous spatial pyramid pooling module (comprising of atrous convolutions in series, with progressive rates of dilation) to integrate the spatial context information. This helps better distinguish between potholes and undamaged road areas. Finally, the feature maps in the adjacent layers are fused using our proposed multi-scale feature fusion module. This further reduces the semantic gap between different feature channel layers. Extensive experiments were carried out on the Pothole-600 dataset to demonstrate the effectiveness of our proposed method. The quantitative comparisons suggest that our method achieves the state-of-the-art (SoTA) performance on both RGB images and transformed disparity images, outperforming three SoTA single-modal semantic segmentation networks.
Efficiently Maintaining Next Basket Recommendations under Additions and Deletions of Baskets and Items
Jan 27, 2022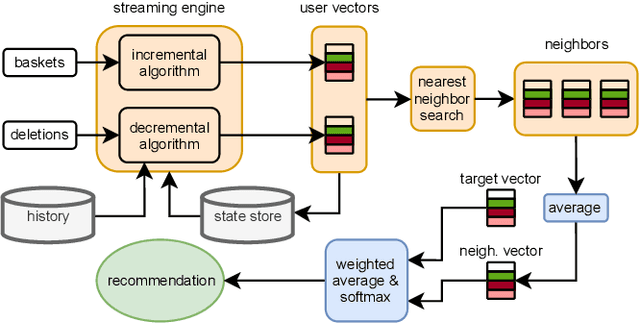

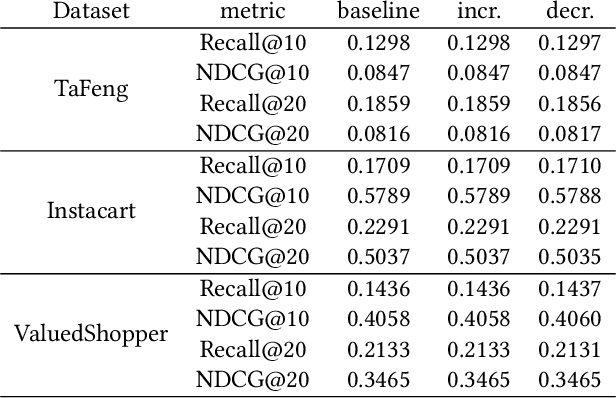
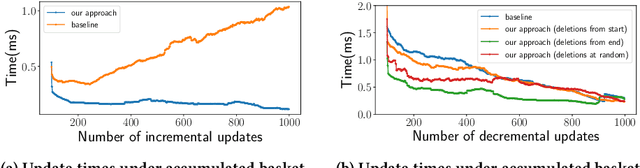
Recommender systems play an important role in helping people find information and make decisions in today's increasingly digitalized societies. However, the wide adoption of such machine learning applications also causes concerns in terms of data privacy. These concerns are addressed by the recent "General Data Protection Regulation" (GDPR) in Europe, which requires companies to delete personal user data upon request when users enforce their "right to be forgotten". Many researchers argue that this deletion obligation does not only apply to the data stored in primary data stores such as relational databases but also requires an update of machine learning models whose training set included the personal data to delete. We explore this direction in the context of a sequential recommendation task called Next Basket Recommendation (NBR), where the goal is to recommend a set of items based on a user's purchase history. We design efficient algorithms for incrementally and decrementally updating a state-of-the-art next basket recommendation model in response to additions and deletions of user baskets and items. Furthermore, we discuss an efficient, data-parallel implementation of our method in the Spark Structured Streaming system. We evaluate our implementation on a variety of real-world datasets, where we investigate the impact of our update techniques on several ranking metrics and measure the time to perform model updates. Our results show that our method provides constant update time efficiency with respect to an additional user basket in the incremental case, and linear efficiency in the decremental case where we delete existing baskets. With modest computational resources, we are able to update models with a latency of around 0.2~milliseconds regardless of the history size in the incremental case, and less than one millisecond in the decremental case.
Self-Gated Memory Recurrent Network for Efficient Scalable HDR Deghosting
Dec 24, 2021

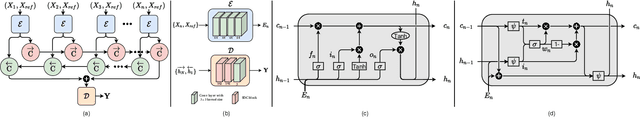

We propose a novel recurrent network-based HDR deghosting method for fusing arbitrary length dynamic sequences. The proposed method uses convolutional and recurrent architectures to generate visually pleasing, ghosting-free HDR images. We introduce a new recurrent cell architecture, namely Self-Gated Memory (SGM) cell, that outperforms the standard LSTM cell while containing fewer parameters and having faster running times. In the SGM cell, the information flow through a gate is controlled by multiplying the gate's output by a function of itself. Additionally, we use two SGM cells in a bidirectional setting to improve output quality. The proposed approach achieves state-of-the-art performance compared to existing HDR deghosting methods quantitatively across three publicly available datasets while simultaneously achieving scalability to fuse variable-length input sequence without necessitating re-training. Through extensive ablations, we demonstrate the importance of individual components in our proposed approach. The code is available at https://val.cds.iisc.ac.in/HDR/HDRRNN/index.html.
* 12 pages