 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mention Memory: incorporating textual knowledge into Transformers through entity mention attention
Oct 12, 2021
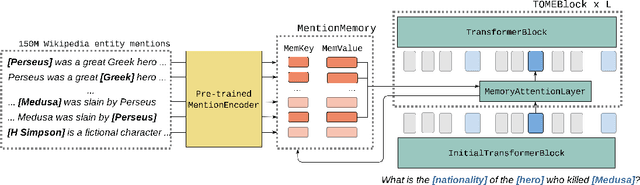
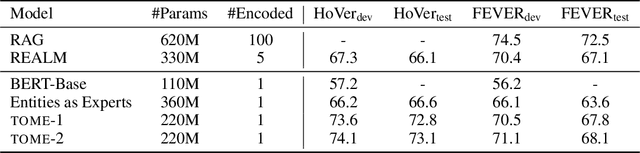
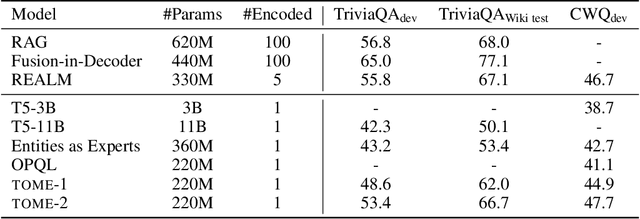
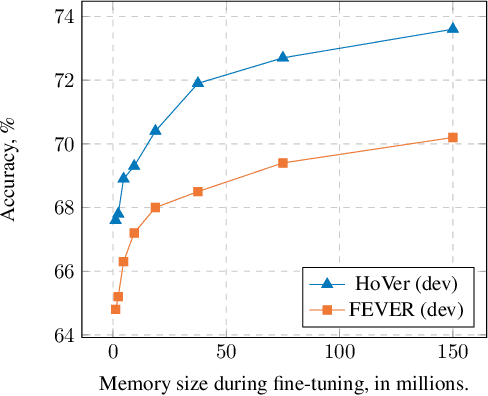
Natural language understanding tasks such as open-domain question answering often require retrieving and assimilating factual information from multiple sources. We propose to address this problem by integrating a semi-parametric representation of a large text corpus into a Transformer model as a source of factual knowledge. Specifically, our method represents knowledge with `mention memory', a table of dense vector representations of every entity mention in a corpus. The proposed model - TOME - is a Transformer that accesses the information through internal memory layers in which each entity mention in the input passage attends to the mention memory. This approach enables synthesis of and reasoning over many disparate sources of information within a single Transformer model. In experiments using a memory of 150 million Wikipedia mentions, TOME achieves strong performance on several open-domain knowledge-intensive tasks, including the claim verification benchmarks HoVer and FEVER and several entity-based QA benchmarks. We also show that the model learns to attend to informative mentions without any direct supervision. Finally we demonstrate that the model can generalize to new unseen entities by updating the memory without retraining.
Generative Adversarial Network (GAN) and Enhanced Root Mean Square Error (ERMSE): Deep Learning for Stock Price Movement Prediction
Nov 30, 2021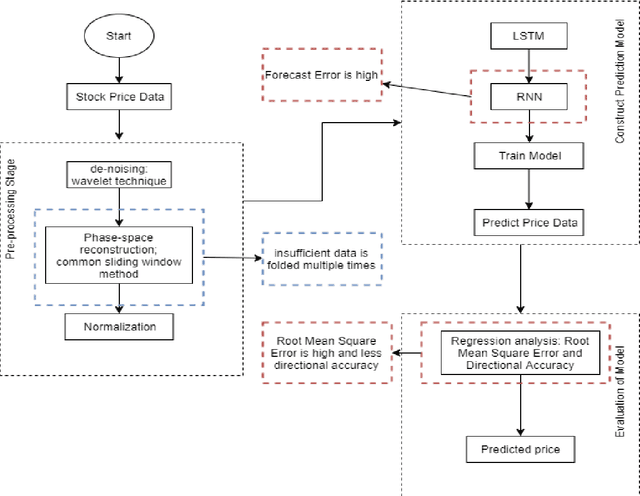
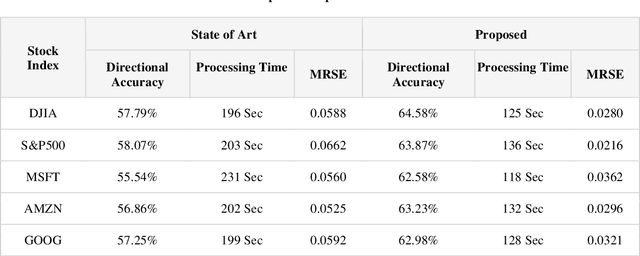
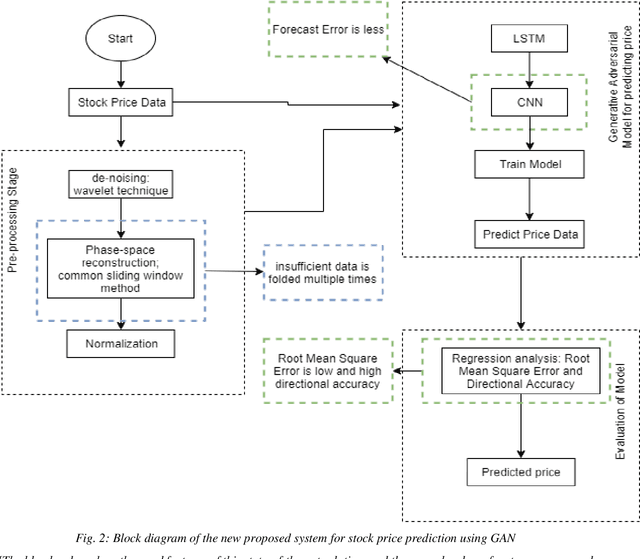
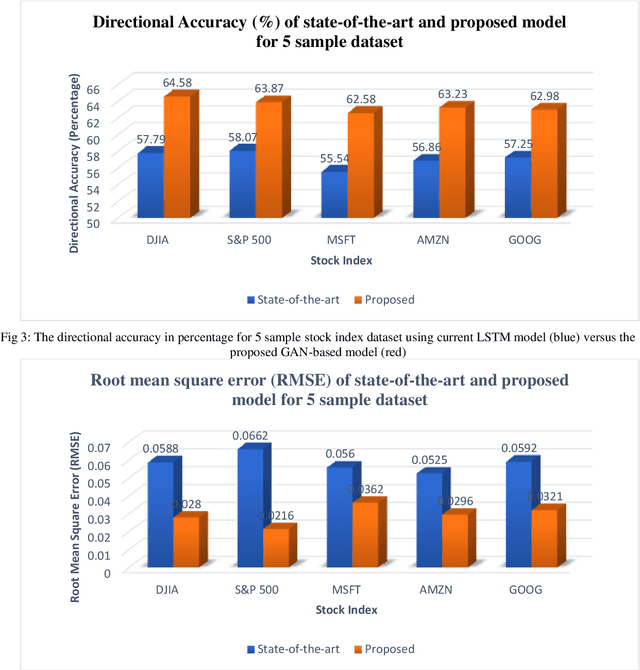
The prediction of stock price movement direction is significant in financial circles and academic. Stock price contains complex, incomplete, and fuzzy information which makes it an extremely difficult task to predict its development trend. Predicting and analysing financial data is a nonlinear, time-dependent problem. With rapid development in machine learning and deep learning, this task can be performed more effectively by a purposely designed network. This paper aims to improve prediction accuracy and minimizing forecasting error loss through deep learning architecture by using Generative Adversarial Networks. It was proposed a generic model consisting of Phase-space Reconstruction (PSR) method for reconstructing price series and Generative Adversarial Network (GAN) which is a combination of two neural networks which are Long Short-Term Memory (LSTM) as Generative model and Convolutional Neural Network (CNN) as Discriminative model for adversarial training to forecast the stock market. LSTM will generate new instances based on historical basic indicators information and then CNN will estimate whether the data is predicted by LSTM or is real. It was found that the Generative Adversarial Network (GAN) has performed well on the enhanced root mean square error to LSTM, as it was 4.35% more accurate in predicting the direction and reduced processing time and RMSE by 78 secs and 0.029, respectively. This study provides a better result in the accuracy of the stock index. It seems that the proposed system concentrates on minimizing the root mean square error and processing time and improving the direction prediction accuracy, and provides a better result in the accuracy of the stock index.
DocAMR: Multi-Sentence AMR Representation and Evaluation
Dec 15, 2021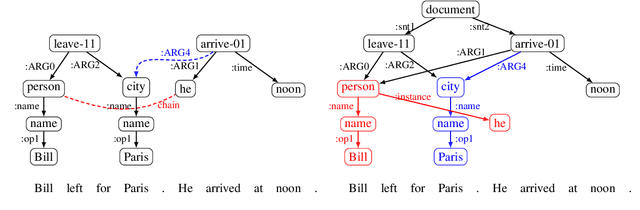
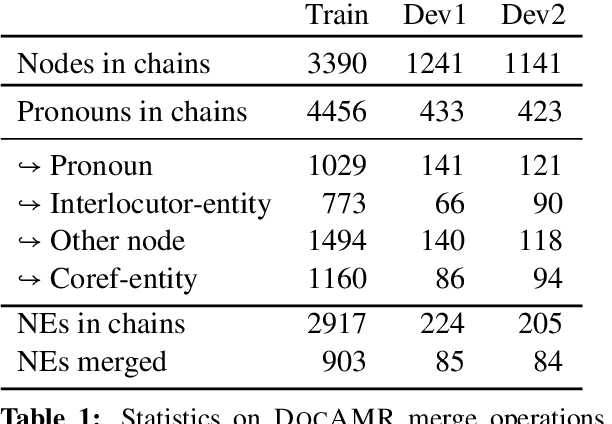
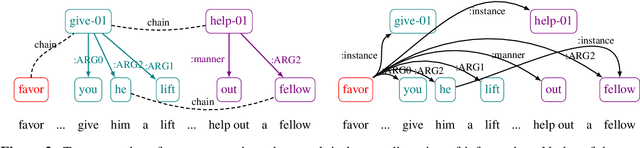
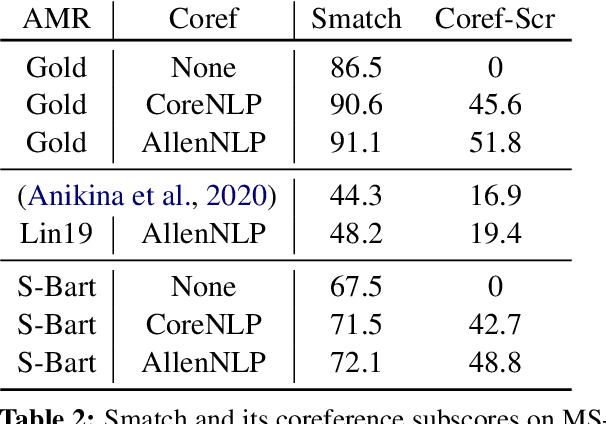
Despite extensive research on parsing of English sentences into Abstraction Meaning Representation (AMR) graphs, which are compared to gold graphs via the Smatch metric, full-document parsing into a unified graph representation lacks well-defined representation and evaluation. Taking advantage of a super-sentential level of coreference annotation from previous work, we introduce a simple algorithm for deriving a unified graph representation, avoiding the pitfalls of information loss from over-merging and lack of coherence from under-merging. Next, we describe improvements to the Smatch metric to make it tractable for comparing document-level graphs, and use it to re-evaluate the best published document-level AMR parser. We also present a pipeline approach combining the top performing AMR parser and coreference resolution systems, providing a strong baseline for future research.
Few-Shot Object Detection by Attending to Per-Sample-Prototype
Sep 16, 2021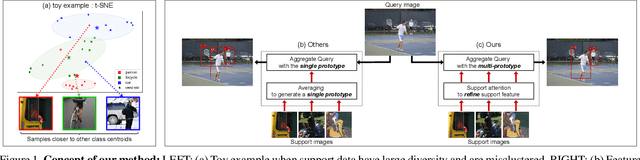


Few-shot object detection aims to detect instances of specific categories in a query image with only a handful of support samples. Although this takes less effort than obtaining enough annotated images for supervised object detection, it results in a far inferior performance compared to the conventional object detection methods. In this paper, we propose a meta-learning-based approach that considers the unique characteristics of each support sample. Rather than simply averaging the information of the support samples to generate a single prototype per category, our method can better utilize the information of each support sample by treating each support sample as an individual prototype. Specifically, we introduce two types of attention mechanisms for aggregating the query and support feature maps. The first is to refine the information of few-shot samples by extracting shared information between the support samples through attention. Second, each support sample is used as a class code to leverage the information by comparing similarities between each support feature and query features. Our proposed method is complementary to the previous methods, making it easy to plug and play for further improvement. We have evaluated our method on PASCAL VOC and COCO benchmarks, and the results verify the effectiveness of our method. In particular, the advantages of our method are maximized when there is more diversity among support data.
Functional Anomaly Detection: a Benchmark Study
Jan 13, 2022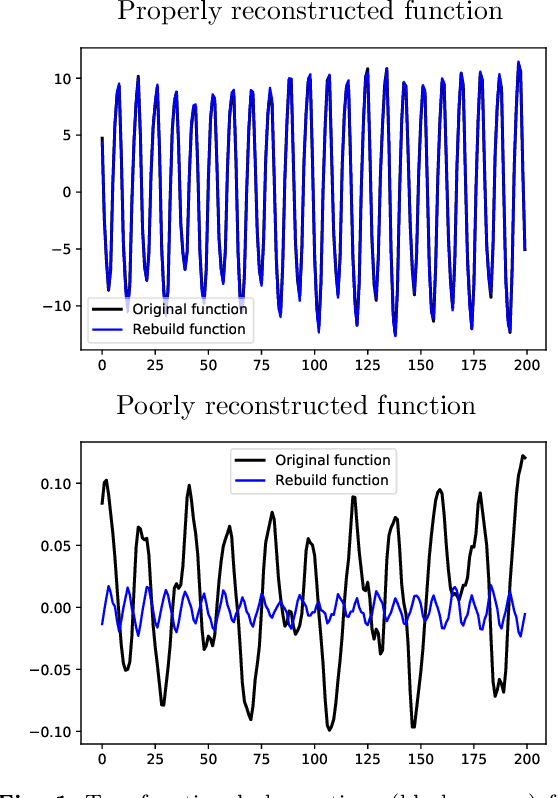
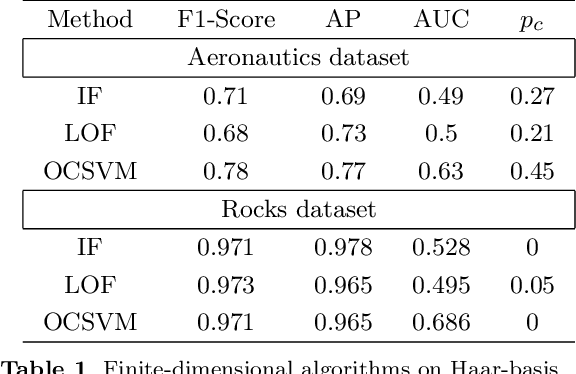
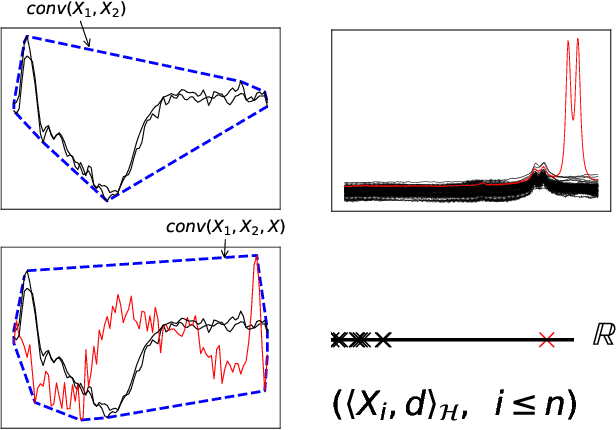
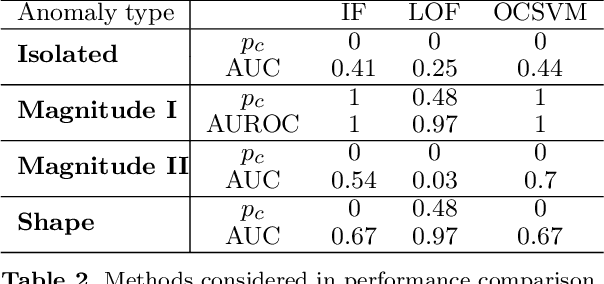
The increasing automation in many areas of the Industry expressly demands to design efficient machine-learning solutions for the detection of abnormal events. With the ubiquitous deployment of sensors monitoring nearly continuously the health of complex infrastructures, anomaly detection can now rely on measurements sampled at a very high frequency, providing a very rich representation of the phenomenon under surveillance. In order to exploit fully the information thus collected, the observations cannot be treated as multivariate data anymore and a functional analysis approach is required. It is the purpose of this paper to investigate the performance of recent techniques for anomaly detection in the functional setup on real datasets. After an overview of the state-of-the-art and a visual-descriptive study, a variety of anomaly detection methods are compared. While taxonomies of abnormalities (e.g. shape, location) in the functional setup are documented in the literature, assigning a specific type to the identified anomalies appears to be a challenging task. Thus, strengths and weaknesses of the existing approaches are benchmarked in view of these highlighted types in a simulation study. Anomaly detection methods are next evaluated on two datasets, related to the monitoring of helicopters in flight and to the spectrometry of construction materials namely. The benchmark analysis is concluded by recommendation guidance for practitioners.
Utilizing Wordnets for Cognate Detection among Indian Languages
Dec 30, 2021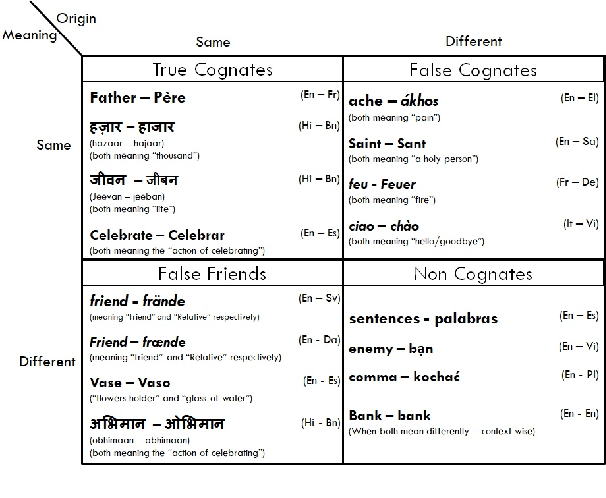
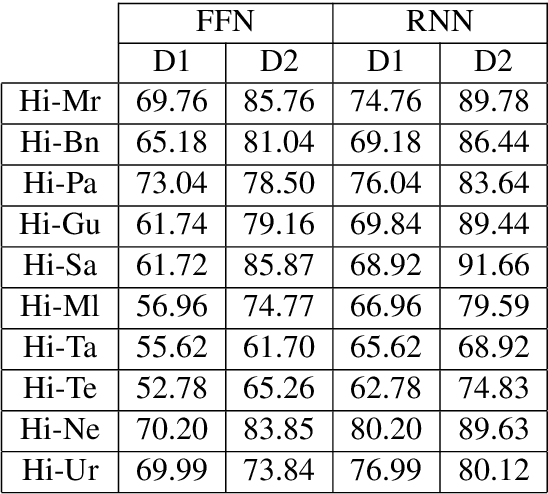
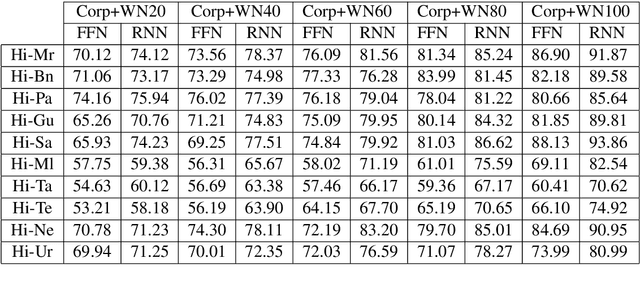
Automatic Cognate Detection (ACD) is a challenging task which has been utilized to help NLP applications like Machine Translation, Information Retrieval and Computational Phylogenetics. Unidentified cognate pairs can pose a challenge to these applications and result in a degradation of performance. In this paper, we detect cognate word pairs among ten Indian languages with Hindi and use deep learning methodologies to predict whether a word pair is cognate or not. We identify IndoWordnet as a potential resource to detect cognate word pairs based on orthographic similarity-based methods and train neural network models using the data obtained from it. We identify parallel corpora as another potential resource and perform the same experiments for them. We also validate the contribution of Wordnets through further experimentation and report improved performance of up to 26%. We discuss the nuances of cognate detection among closely related Indian languages and release the lists of detected cognates as a dataset. We also observe the behaviour of, to an extent, unrelated Indian language pairs and release the lists of detected cognates among them as well.
MGH: Metadata Guided Hypergraph Modeling for Unsupervised Person Re-identification
Oct 12, 2021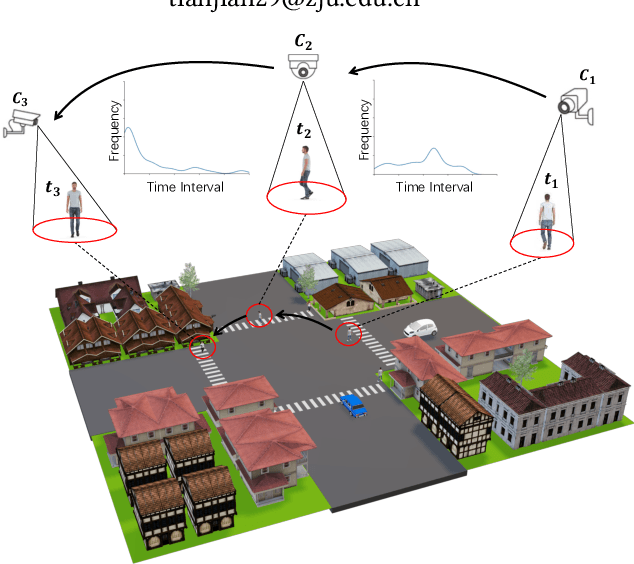

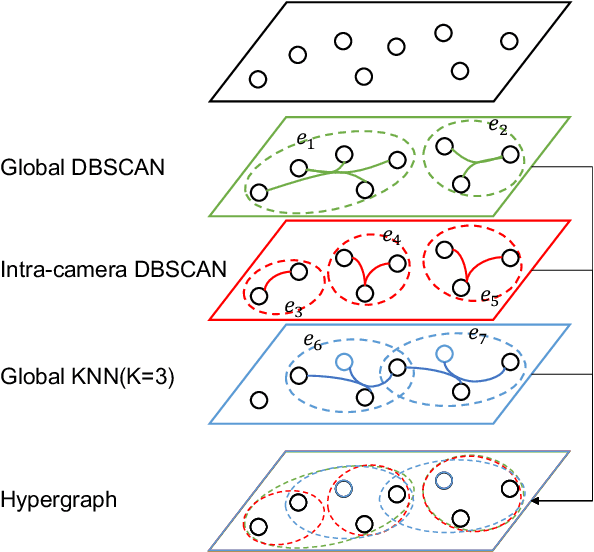
As a challenging task, unsupervised person ReID aims to match the same identity with query images which does not require any labeled information. In general, most existing approaches focus on the visual cues only, leaving potentially valuable auxiliary metadata information (e.g., spatio-temporal context) unexplored. In the real world, such metadata is normally available alongside captured images, and thus plays an important role in separating several hard ReID matches. With this motivation in mind, we propose~\textbf{MGH}, a novel unsupervised person ReID approach that uses meta information to construct a hypergraph for feature learning and label refinement. In principle, the hypergraph is composed of camera-topology-aware hyperedges, which can model the heterogeneous data correlations across cameras. Taking advantage of label propagation on the hypergraph, the proposed approach is able to effectively refine the ReID results, such as correcting the wrong labels or smoothing the noisy labels. Given the refined results, We further present a memory-based listwise loss to directly optimize the average precision in an approximate manner. Extensive experiments on three benchmarks demonstrate the effectiveness of the proposed approach against the state-of-the-art.
Geometric Multimodal Deep Learning with Multi-Scaled Graph Wavelet Convolutional Network
Nov 26, 2021

Multimodal data provide complementary information of a natural phenomenon by integrating data from various domains with very different statistical properties. Capturing the intra-modality and cross-modality information of multimodal data is the essential capability of multimodal learning methods. The geometry-aware data analysis approaches provide these capabilities by implicitly representing data in various modalities based on their geometric underlying structures. Also, in many applications, data are explicitly defined on an intrinsic geometric structure. Generalizing deep learning methods to the non-Euclidean domains is an emerging research field, which has recently been investigated in many studies. Most of those popular methods are developed for unimodal data. In this paper, a multimodal multi-scaled graph wavelet convolutional network (M-GWCN) is proposed as an end-to-end network. M-GWCN simultaneously finds intra-modality representation by applying the multiscale graph wavelet transform to provide helpful localization properties in the graph domain of each modality, and cross-modality representation by learning permutations that encode correlations among various modalities. M-GWCN is not limited to either the homogeneous modalities with the same number of data, or any prior knowledge indicating correspondences between modalities. Several semi-supervised node classification experiments have been conducted on three popular unimodal explicit graph-based datasets and five multimodal implicit ones. The experimental results indicate the superiority and effectiveness of the proposed methods compared with both spectral graph domain convolutional neural networks and state-of-the-art multimodal methods.
Cycle-Balanced Representation Learning For Counterfactual Inference
Oct 29, 2021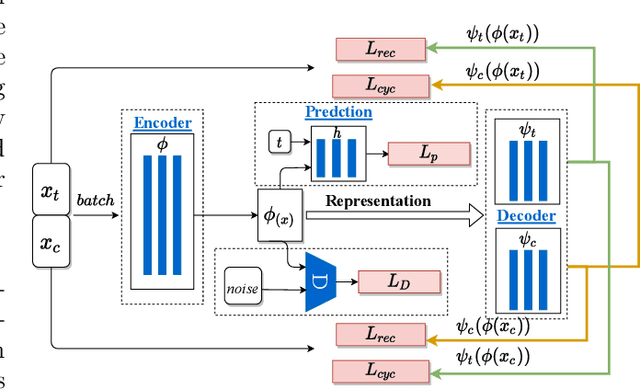
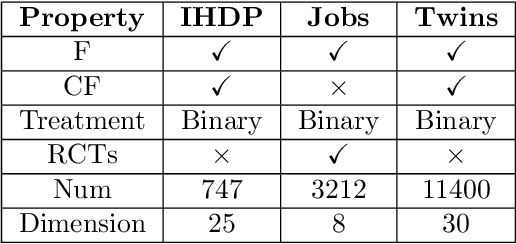
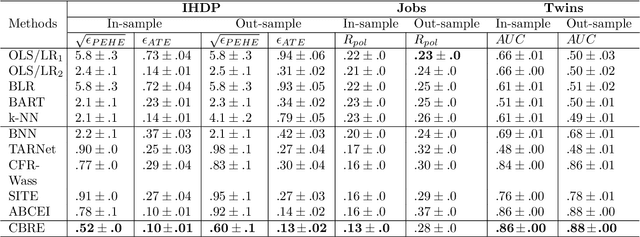
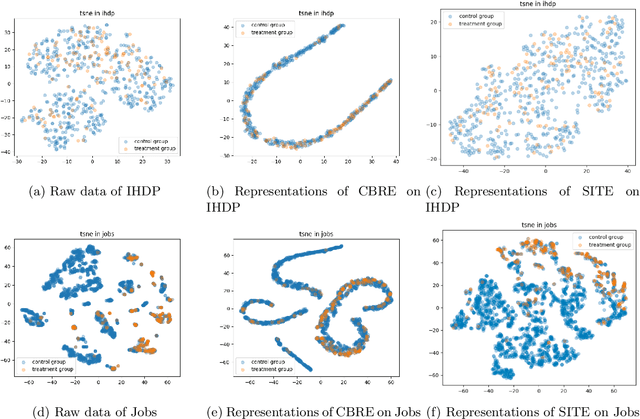
With the widespread accumulation of observational data, researchers obtain a new direction to learn counterfactual effects in many domains (e.g., health care and computational advertising) without Randomized Controlled Trials(RCTs). However, observational data suffer from inherent missing counterfactual outcomes, and distribution discrepancy between treatment and control groups due to behaviour preference. Motivated by recent advances of representation learning in the field of domain adaptation, we propose a novel framework based on Cycle-Balanced REpresentation learning for counterfactual inference (CBRE), to solve above problems. Specifically, we realize a robust balanced representation for different groups using adversarial training, and meanwhile construct an information loop, such that preserve original data properties cyclically, which reduces information loss when transforming data into latent representation space.Experimental results on three real-world datasets demonstrate that CBRE matches/outperforms the state-of-the-art methods, and it has a great potential to be applied to counterfactual inference.
Simple Fair Power Allocation for NOMA-Based Visible Light Communication Systems
Dec 08, 2021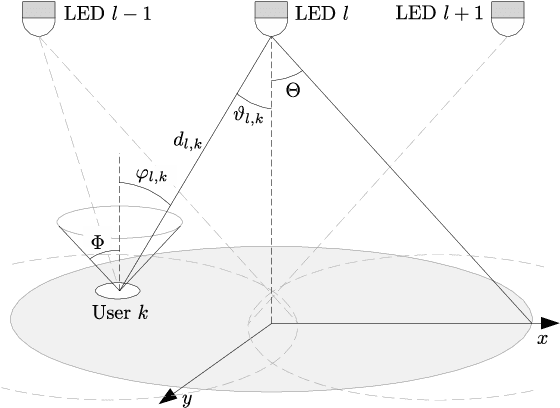
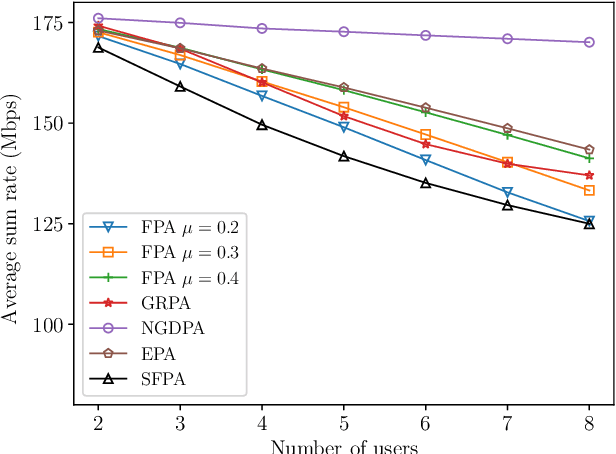
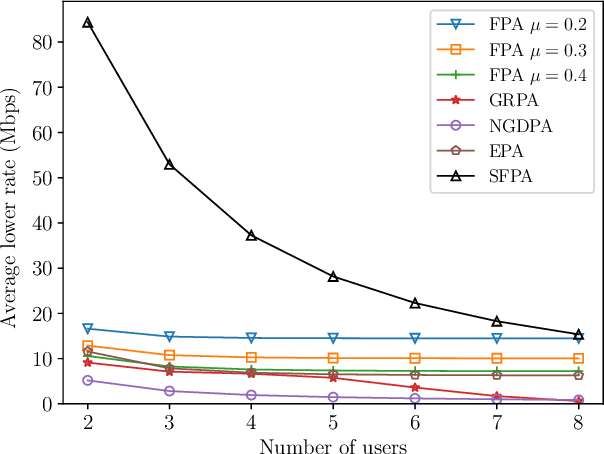
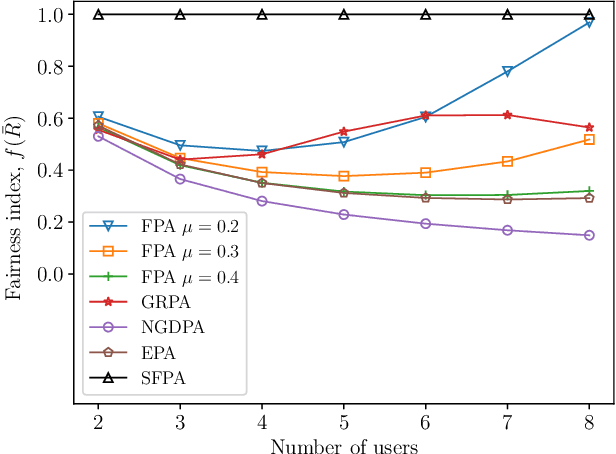
Non-orthogonal multiple access (NOMA) in the power-domain has been recognized as a promising technique to overcome the bandwidth limitations of current visible light communication (VLC) systems. In this letter, we investigate the power allocation (PA) problem in an NOMA-VLC system under high signal-to-noise-ratio (SNR) regime. A simple fair power allocation strategy (SFPA) is proposed to ensure equitable allocation of transmission resources in a multi-user scenario. SFPA requires minimal channel state information (CSI), making it less prone to channel estimation errors. Results show that NOMA with SFPA provides fairer and higher achievable rates per user (up to 79.5\% higher in the studied setup), without significantly compromising the overall system performance.