 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Overconfident and Unconfident AI Hinder Human-AI Collaboration
Feb 12, 2024
As artificial intelligence (AI) advances, human-AI collaboration has become increasingly prevalent across both professional and everyday settings. In such collaboration, AI can express its confidence level about its performance, serving as a crucial indicator for humans to evaluate AI's suggestions. However, AI may exhibit overconfidence or underconfidence--its expressed confidence is higher or lower than its actual performance--which may lead humans to mistakenly evaluate AI advice. Our study investigates the influences of AI's overconfidence and underconfidence on human trust, their acceptance of AI suggestions, and collaboration outcomes. Our study reveal that disclosing AI confidence levels and performance feedback facilitates better recognition of AI confidence misalignments. However, participants tend to withhold their trust as perceiving such misalignments, leading to a rejection of AI suggestions and subsequently poorer performance in collaborative tasks. Conversely, without such information, participants struggle to identify misalignments, resulting in either the neglect of correct AI advice or the following of incorrect AI suggestions, adversely affecting collaboration. This study offers valuable insights for enhancing human-AI collaboration by underscoring the importance of aligning AI's expressed confidence with its actual performance and the necessity of calibrating human trust towards AI confidence.
Sensor Misalignment-tolerant AUV Navigation with Passive DoA and Doppler Measurements
Feb 11, 2024We present a sensor misalignment-tolerant AUV navigation method that leverages measurements from an acoustic array and dead reckoned information. Recent studies have demonstrated the potential use of passive acoustic Direction of Arrival (DoA) measurements for AUV navigation without requiring ranging measurements. However, the sensor misalignment between the acoustic array and the attitude sensor was not accounted for. Such misalignment may deteriorate the navigation accuracy. This paper proposes a novel approach that allows simultaneous AUV navigation, beacon localization, and sensor alignment. An Unscented Kalman Filter (UKF) that enables the necessary calculations to be completed at an affordable computational load is developed. A Nonlinear Least Squares (NLS)-based technique is employed to find an initial solution for beacon localization and sensor alignment as early as possible using a short-term window of measurements. Experimental results demonstrate the performance of the proposed method.
Convolutional Neural Networks Towards Facial Skin Lesions Detection
Feb 13, 2024Facial analysis has emerged as a prominent area of research with diverse applications, including cosmetic surgery programs, the beauty industry, photography, and entertainment. Manipulating patient images often necessitates professional image processing software. This study contributes by providing a model that facilitates the detection of blemishes and skin lesions on facial images through a convolutional neural network and machine learning approach. The proposed method offers advantages such as simple architecture, speed and suitability for image processing while avoiding the complexities associated with traditional methods. The model comprises four main steps: area selection, scanning the chosen region, lesion diagnosis, and marking the identified lesion. Raw data for this research were collected from a reputable clinic in Tehran specializing in skincare and beauty services. The dataset includes administrative information, clinical data, and facial and profile images. A total of 2300 patient images were extracted from this raw data. A software tool was developed to crop and label lesions, with input from two treatment experts. In the lesion preparation phase, the selected area was standardized to 50 * 50 pixels. Subsequently, a convolutional neural network model was employed for lesion labeling. The classification model demonstrated high accuracy, with a measure of 0.98 for healthy skin and 0.97 for lesioned skin specificity. Internal validation involved performance indicators and cross-validation, while external validation compared the model's performance indicators with those of the transfer learning method using the Vgg16 deep network model. Compared to existing studies, the results of this research showcase the efficacy and desirability of the proposed model and methodology.
Rethinking U-net Skip Connections for Biomedical Image Segmentation
Feb 13, 2024The U-net architecture has significantly impacted deep learning-based segmentation of medical images. Through the integration of long-range skip connections, it facilitated the preservation of high-resolution features. Out-of-distribution data can, however, substantially impede the performance of neural networks. Previous works showed that the trained network layers differ in their susceptibility to this domain shift, e.g., shallow layers are more affected than deeper layers. In this work, we investigate the implications of this observation of layer sensitivity to domain shifts of U-net-style segmentation networks. By copying features of shallow layers to corresponding decoder blocks, these bear the risk of re-introducing domain-specific information. We used a synthetic dataset to model different levels of data distribution shifts and evaluated the impact on downstream segmentation performance. We quantified the inherent domain susceptibility of each network layer, using the Hellinger distance. These experiments confirmed the higher domain susceptibility of earlier network layers. When gradually removing skip connections, a decrease in domain susceptibility of deeper layers could be observed. For downstream segmentation performance, the original U-net outperformed the variant without any skip connections. The best performance, however, was achieved when removing the uppermost skip connection - not only in the presence of domain shifts but also for in-domain test data. We validated our results on three clinical datasets - two histopathology datasets and one magnetic resonance dataset - with performance increases of up to 10% in-domain and 13% cross-domain when removing the uppermost skip connection.
PSC-CPI: Multi-Scale Protein Sequence-Structure Contrasting for Efficient and Generalizable Compound-Protein Interaction Prediction
Feb 13, 2024Compound-Protein Interaction (CPI) prediction aims to predict the pattern and strength of compound-protein interactions for rational drug discovery. Existing deep learning-based methods utilize only the single modality of protein sequences or structures and lack the co-modeling of the joint distribution of the two modalities, which may lead to significant performance drops in complex real-world scenarios due to various factors, e.g., modality missing and domain shifting. More importantly, these methods only model protein sequences and structures at a single fixed scale, neglecting more fine-grained multi-scale information, such as those embedded in key protein fragments. In this paper, we propose a novel multi-scale Protein Sequence-structure Contrasting framework for CPI prediction (PSC-CPI), which captures the dependencies between protein sequences and structures through both intra-modality and cross-modality contrasting. We further apply length-variable protein augmentation to allow contrasting to be performed at different scales, from the amino acid level to the sequence level. Finally, in order to more fairly evaluate the model generalizability, we split the test data into four settings based on whether compounds and proteins have been observed during the training stage. Extensive experiments have shown that PSC-CPI generalizes well in all four settings, particularly in the more challenging ``Unseen-Both" setting, where neither compounds nor proteins have been observed during training. Furthermore, even when encountering a situation of modality missing, i.e., inference with only single-modality protein data, PSC-CPI still exhibits comparable or even better performance than previous approaches.
Learning to Generate Context-Sensitive Backchannel Smiles for Embodied AI Agents with Applications in Mental Health Dialogues
Feb 13, 2024Addressing the critical shortage of mental health resources for effective screening, diagnosis, and treatment remains a significant challenge. This scarcity underscores the need for innovative solutions, particularly in enhancing the accessibility and efficacy of therapeutic support. Embodied agents with advanced interactive capabilities emerge as a promising and cost-effective supplement to traditional caregiving methods. Crucial to these agents' effectiveness is their ability to simulate non-verbal behaviors, like backchannels, that are pivotal in establishing rapport and understanding in therapeutic contexts but remain under-explored. To improve the rapport-building capabilities of embodied agents we annotated backchannel smiles in videos of intimate face-to-face conversations over topics such as mental health, illness, and relationships. We hypothesized that both speaker and listener behaviors affect the duration and intensity of backchannel smiles. Using cues from speech prosody and language along with the demographics of the speaker and listener, we found them to contain significant predictors of the intensity of backchannel smiles. Based on our findings, we introduce backchannel smile production in embodied agents as a generation problem. Our attention-based generative model suggests that listener information offers performance improvements over the baseline speaker-centric generation approach. Conditioned generation using the significant predictors of smile intensity provides statistically significant improvements in empirical measures of generation quality. Our user study by transferring generated smiles to an embodied agent suggests that agent with backchannel smiles is perceived to be more human-like and is an attractive alternative for non-personal conversations over agent without backchannel smiles.
Thompson Sampling for Stochastic Bandits with Noisy Contexts: An Information-Theoretic Regret Analysis
Jan 21, 2024We explore a stochastic contextual linear bandit problem where the agent observes a noisy, corrupted version of the true context through a noise channel with an unknown noise parameter. Our objective is to design an action policy that can approximate" that of an oracle, which has access to the reward model, the channel parameter, and the predictive distribution of the true context from the observed noisy context. In a Bayesian framework, we introduce a Thompson sampling algorithm for Gaussian bandits with Gaussian context noise. Adopting an information-theoretic analysis, we demonstrate the Bayesian regret of our algorithm concerning the oracle's action policy. We also extend this problem to a scenario where the agent observes the true context with some delay after receiving the reward and show that delayed true contexts lead to lower Bayesian regret. Finally, we empirically demonstrate the performance of the proposed algorithms against baselines.
Towards Reliable and Factual Response Generation: Detecting Unanswerable Questions in Information-Seeking Conversations
Jan 21, 2024Generative AI models face the challenge of hallucinations that can undermine users' trust in such systems. We approach the problem of conversational information seeking as a two-step process, where relevant passages in a corpus are identified first and then summarized into a final system response. This way we can automatically assess if the answer to the user's question is present in the corpus. Specifically, our proposed method employs a sentence-level classifier to detect if the answer is present, then aggregates these predictions on the passage level, and eventually across the top-ranked passages to arrive at a final answerability estimate. For training and evaluation, we develop a dataset based on the TREC CAsT benchmark that includes answerability labels on the sentence, passage, and ranking levels. We demonstrate that our proposed method represents a strong baseline and outperforms a state-of-the-art LLM on the answerability prediction task.
PAS-SLAM: A Visual SLAM System for Planar Ambiguous Scenes
Feb 09, 2024
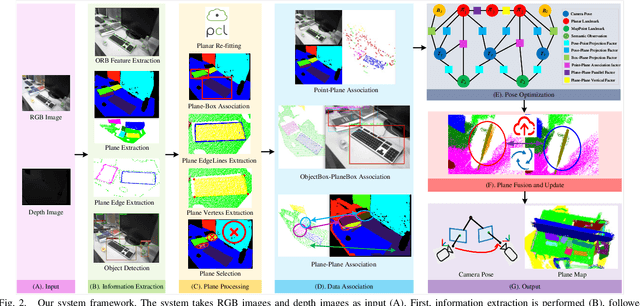
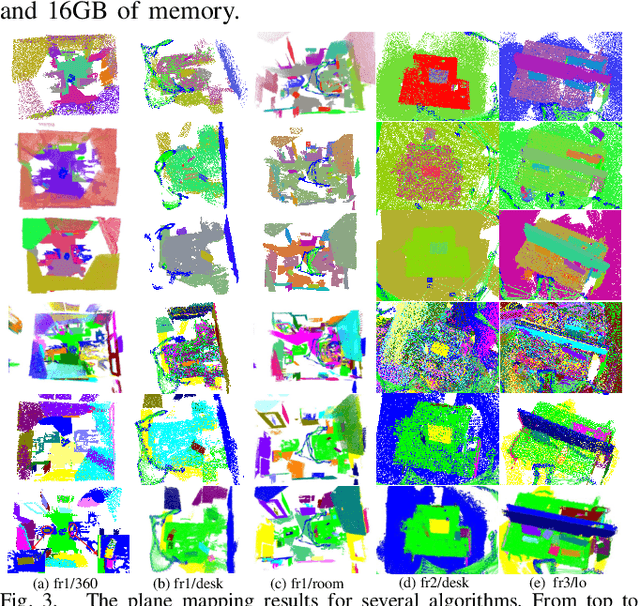

Visual SLAM (Simultaneous Localization and Mapping) based on planar features has found widespread applications in fields such as environmental structure perception and augmented reality. However, current research faces challenges in accurately localizing and mapping in planar ambiguous scenes, primarily due to the poor accuracy of the employed planar features and data association methods. In this paper, we propose a visual SLAM system based on planar features designed for planar ambiguous scenes, encompassing planar processing, data association, and multi-constraint factor graph optimization. We introduce a planar processing strategy that integrates semantic information with planar features, extracting the edges and vertices of planes to be utilized in tasks such as plane selection, data association, and pose optimization. Next, we present an integrated data association strategy that combines plane parameters, semantic information, projection IoU (Intersection over Union), and non-parametric tests, achieving accurate and robust plane data association in planar ambiguous scenes. Finally, we design a set of multi-constraint factor graphs for camera pose optimization. Qualitative and quantitative experiments conducted on publicly available datasets demonstrate that our proposed system competes effectively in both accuracy and robustness in terms of map construction and camera localization compared to state-of-the-art methods.
SCTNet: Single-Branch CNN with Transformer Semantic Information for Real-Time Segmentation
Jan 15, 2024Recent real-time semantic segmentation methods usually adopt an additional semantic branch to pursue rich long-range context. However, the additional branch incurs undesirable computational overhead and slows inference speed. To eliminate this dilemma, we propose SCTNet, a single branch CNN with transformer semantic information for real-time segmentation. SCTNet enjoys the rich semantic representations of an inference-free semantic branch while retaining the high efficiency of lightweight single branch CNN. SCTNet utilizes a transformer as the training-only semantic branch considering its superb ability to extract long-range context. With the help of the proposed transformer-like CNN block CFBlock and the semantic information alignment module, SCTNet could capture the rich semantic information from the transformer branch in training. During the inference, only the single branch CNN needs to be deployed. We conduct extensive experiments on Cityscapes, ADE20K, and COCO-Stuff-10K, and the results show that our method achieves the new state-of-the-art performance. The code and model is available at https://github.com/xzz777/SCTNet