 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MIC: Model-agnostic Integrated Cross-channel Recommenders
Oct 22, 2021

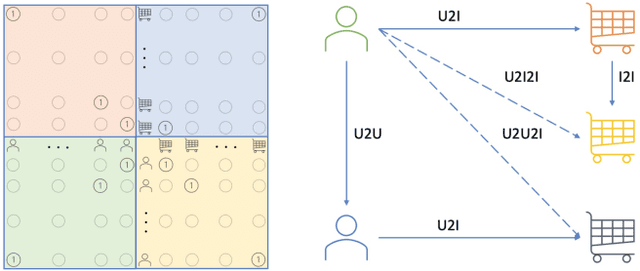
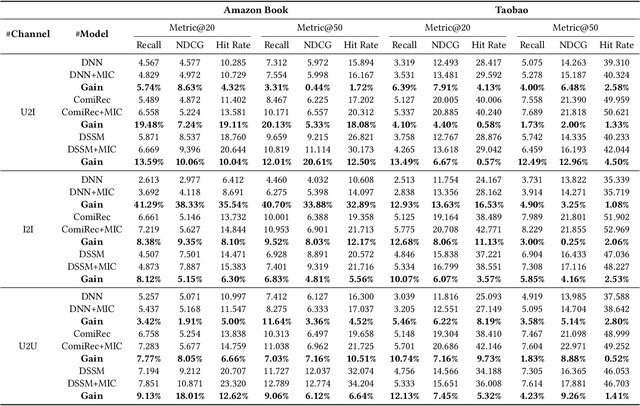
Semantically connecting users and items is a fundamental problem for the matching stage of an industrial recommender system. Recent advances in this topic are based on multi-channel retrieval to efficiently measure users' interest on items from the massive candidate pool. However, existing work are primarily built upon pre-defined retrieval channels, including User-CF (U2U), Item-CF (I2I), and Embedding-based Retrieval (U2I), thus access to the limited correlation between users and items which solely entail from partial information of latent interactions. In this paper, we propose a model-agnostic integrated cross-channel (MIC) approach for the large-scale recommendation, which maximally leverages the inherent multi-channel mutual information to enhance the matching performance. Specifically, MIC robustly models correlation within user-item, user-user, and item-item from latent interactions in a universal schema. For each channel, MIC naturally aligns pairs with semantic similarity and distinguishes them otherwise with more uniform anisotropic representation space. While state-of-the-art methods require specific architectural design, MIC intuitively considers them as a whole by enabling the complete information flow among users and items. Thus MIC can be easily plugged into other retrieval recommender systems. Extensive experiments show that our MIC helps several state-of-the-art models boost their performance on two real-world benchmarks. The satisfactory deployment of the proposed MIC on industrial online services empirically proves its scalability and flexibility.
Quantum Capsule Networks
Jan 05, 2022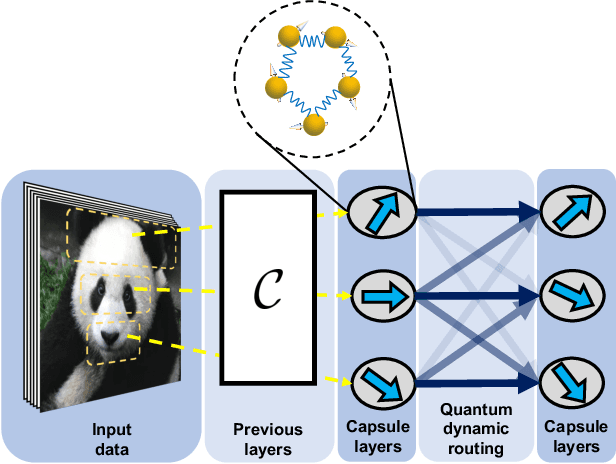
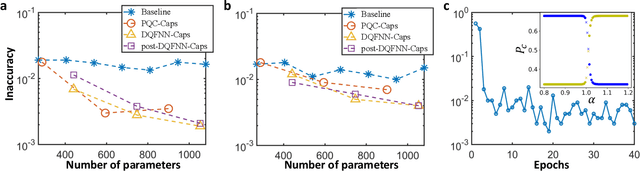
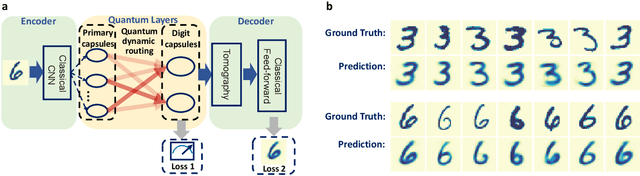
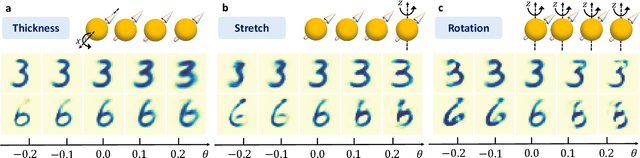
Capsule networks, which incorporate the paradigms of connectionism and symbolism, have brought fresh insights into artificial intelligence. The capsule, as the building block of capsule networks, is a group of neurons represented by a vector to encode different features of an entity. The information is extracted hierarchically through capsule layers via routing algorithms. Here, we introduce a quantum capsule network (dubbed QCapsNet) together with a quantum dynamic routing algorithm. Our model enjoys an exponential speedup in the dynamic routing process and exhibits an enhanced representation power. To benchmark the performance of the QCapsNet, we carry out extensive numerical simulations on the classification of handwritten digits and symmetry-protected topological phases, and show that the QCapsNet can achieve the state-of-the-art accuracy and outperforms conventional quantum classifiers evidently. We further unpack the output capsule state and find that a particular subspace may correspond to a human-understandable feature of the input data, which indicates the potential explainability of such networks. Our work reveals an intriguing prospect of quantum capsule networks in quantum machine learning, which may provide a valuable guide towards explainable quantum artificial intelligence.
An Evolutionary Game for Mobile User Access Mode Selection in sub-$6$ GHz/mmWave Cellular Networks
Jan 10, 2022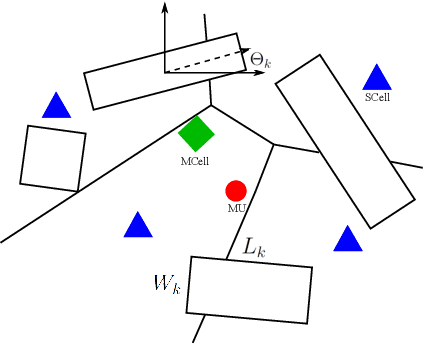
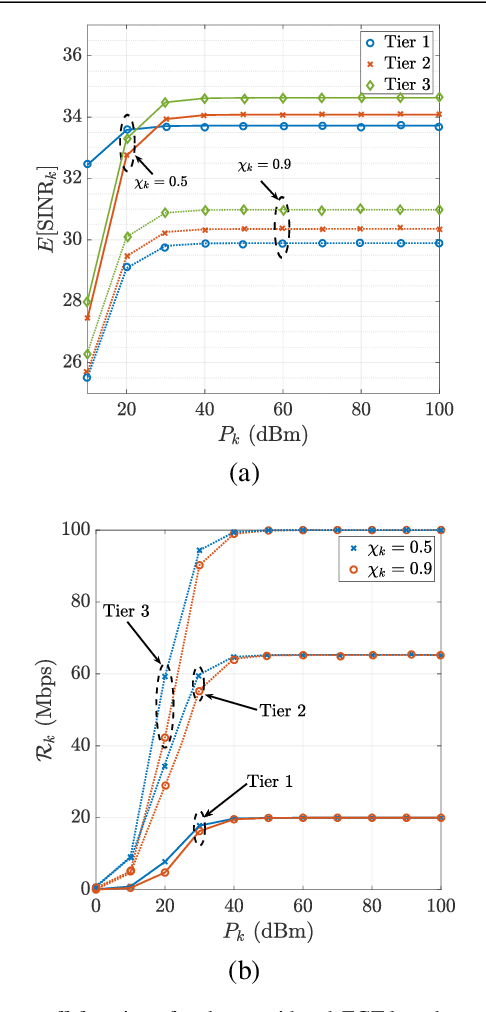
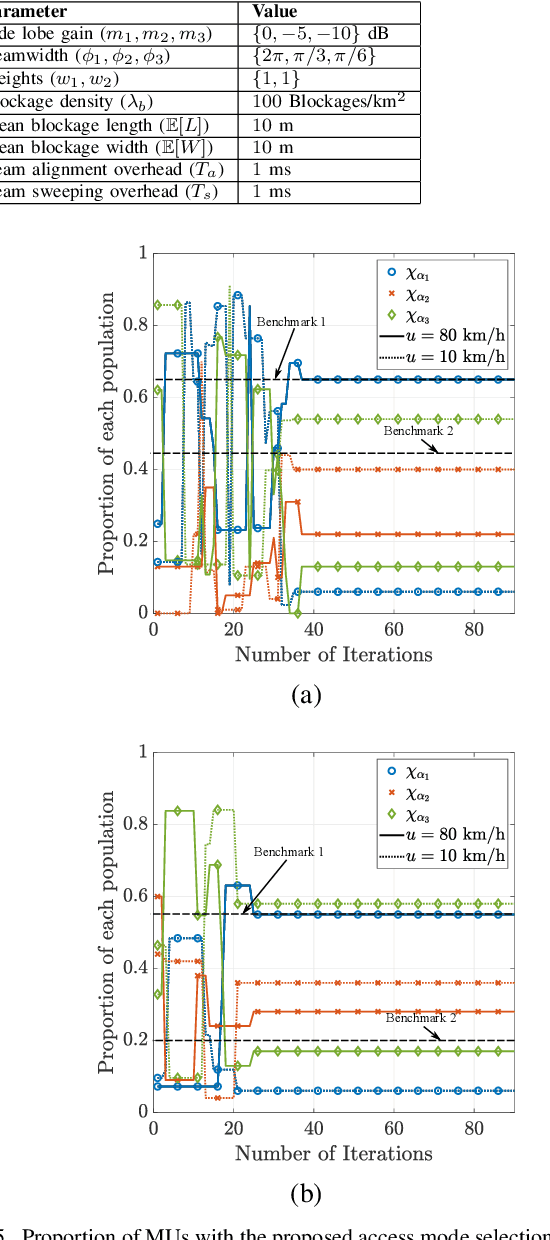
By utilizing the combination of two powerful tools i.e., stochastic geometry (SG) and evolutionary game theory (EGT), in this paper, we study the problem of mobile user (MU) mode selection in heterogeneous sub-$6$ GHz/millimeter wave (mmWave) cellular networks. Particularly, by using SG tools, we first propose an analytical framework to assess the performance of the considered networks in terms of average signal-to-interference-plus-noise (SINR) ratio, average rate, and mobility-induced time overhead, for scenarios with user mobility{.} According to the SG-based framework, an EGT-based approach is presented to solve the problem of access mode selection. Specifically, two EGT-based models are considered, where for each MU its utility function depends on the average SINR and the average rate, respectively, while the time overhead is considered as a penalty term. A distributed algorithm is proposed to reach the evolutionary equilibrium, where the existence and stability of the equilibrium is theoretically analyzed and proved. Moreover, we extend the formulation by considering information delay exchange and evaluate its impact on the convergence of the proposed algorithm. Our results reveal that the proposed technique can offer better spectral efficiency and connectivity in heterogeneous sub-$6$ GHz/mmWave cellular networks with mobility, compared with the conventional access mode selection techniques.
Extending Multi-Object Tracking systems to better exploit appearance and 3D information
Dec 25, 2019
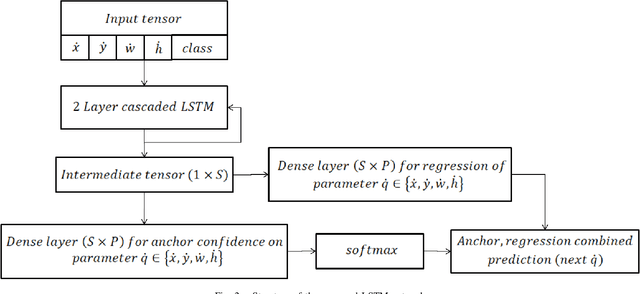
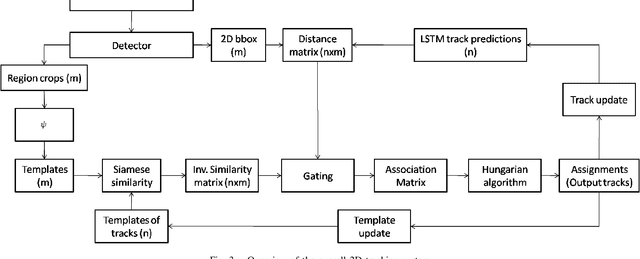
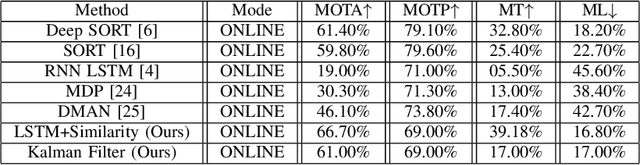
Tracking multiple objects in real time is essential for a variety of real-world applications, with self-driving industry being at the foremost. This work involves exploiting temporally varying appearance and motion information for tracking. Siamese networks have recently become highly successful at appearance based single object tracking and Recurrent Neural Networks have started dominating both motion and appearance based tracking. Our work focuses on combining Siamese networks and RNNs to exploit appearance and motion information respectively to build a joint system capable of real time multi-object tracking. We further explore heuristics based constraints for tracking in the Birds Eye View Space for efficiently exploiting 3D information as a constrained optimization problem for track prediction.
Bioacoustic Event Detection with prototypical networks and data augmentation
Dec 16, 2021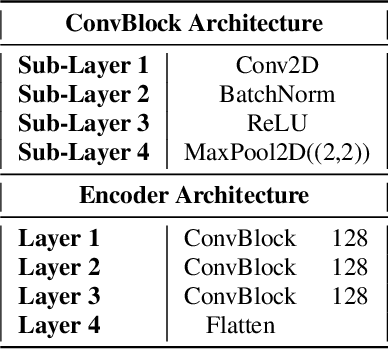
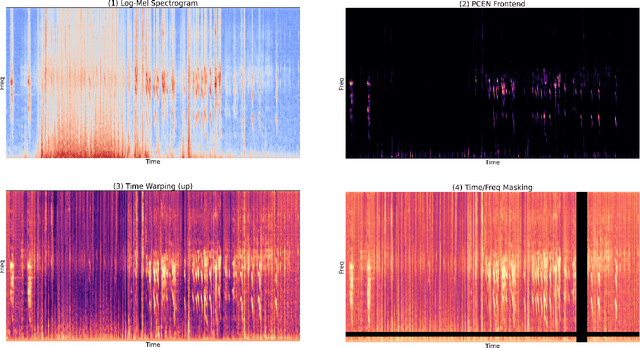
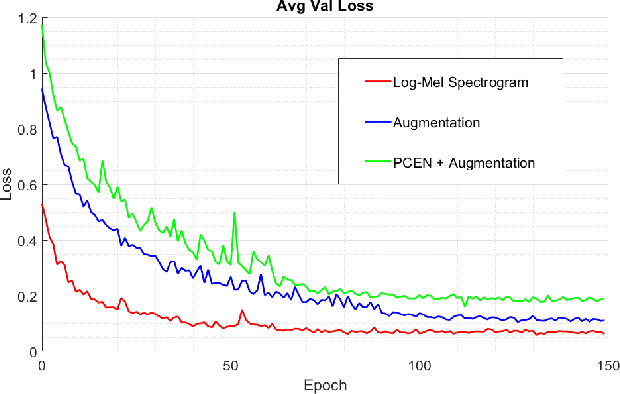
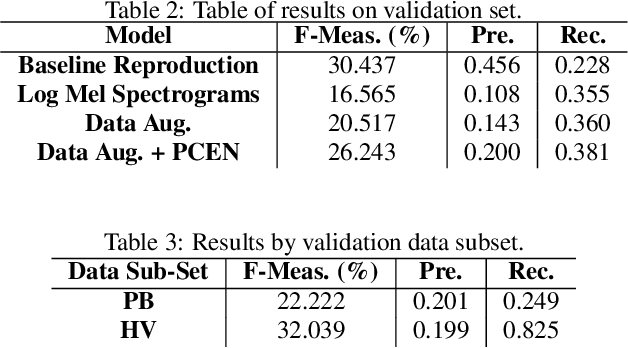
This report presents deep learning and data augmentation techniques used by a system entered into the Few-Shot Bioacoustic Event Detection for the DCASE2021 Challenge. The remit was to develop a few-shot learning system for animal (mammal and bird) vocalisations. Participants were tasked with developing a method that can extract information from five exemplar vocalisations, or shots, of mammals or birds and detect and classify sounds in field recordings. In the system described in this report, prototypical networks are used to learn a metric space, from which classification is performed by computing the distance of a query point to class prototypes, classifying based on shortest distance. We describe the architecture of this network, feature extraction methods, and data augmentation performed on the given dataset and compare our work to the challenge's baseline networks.
Learning Audio-Visual Speech Representation by Masked Multimodal Cluster Prediction
Jan 05, 2022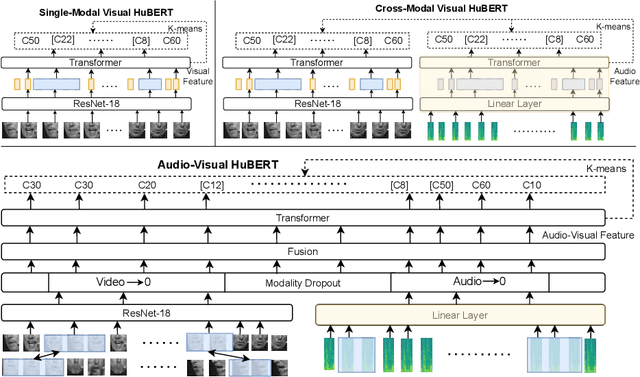
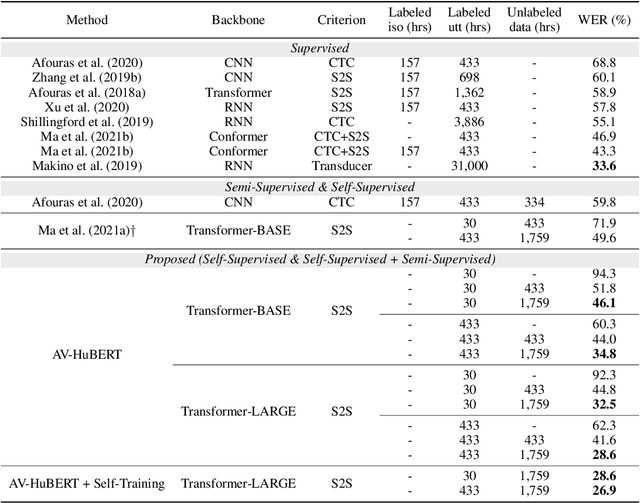


Video recordings of speech contain correlated audio and visual information, providing a strong signal for speech representation learning from the speaker's lip movements and the produced sound. We introduce Audio-Visual Hidden Unit BERT (AV-HuBERT), a self-supervised representation learning framework for audio-visual speech, which masks multi-stream video input and predicts automatically discovered and iteratively refined multimodal hidden units. AV-HuBERT learns powerful audio-visual speech representation benefiting both lip-reading and automatic speech recognition. On the largest public lip-reading benchmark LRS3 (433 hours), AV-HuBERT achieves 32.5% WER with only 30 hours of labeled data, outperforming the former state-of-the-art approach (33.6%) trained with a thousand times more transcribed video data (31K hours). The lip-reading WER is further reduced to 26.9% when using all 433 hours of labeled data from LRS3 and combined with self-training. Using our audio-visual representation on the same benchmark for audio-only speech recognition leads to a 40% relative WER reduction over the state-of-the-art performance (1.3% vs 2.3%). Our code and models are available at https://github.com/facebookresearch/av_hubert
A generalized algorithm and framework for online 3-dimensional bin packing in an automated sorting center
Nov 01, 2021
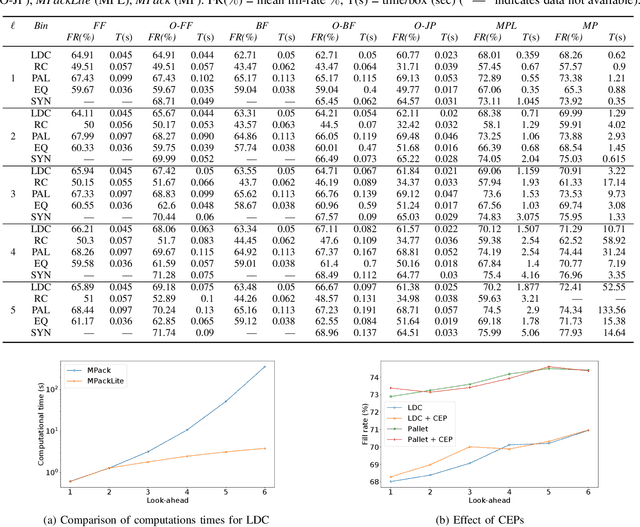
Online 3-dimensional bin packing problem (O3D-BPP) is getting renewed prominence due to the industrial automation brought by Industry 4.0. However, due to limited attention in the past and its challenging nature, a good approximate algorithm is in scarcity as compared to 1D or 2D problems. This paper considers real-time O$3$D-BPP of cuboidal boxes with partial information (look-ahead) in an automated robotic sorting center. We present two rolling-horizon mixed-integer linear programming (MILP) cum-heuristic based algorithms: MPack (for bench-marking) and MPackLite (for real-time deployment). Additionally, we present a framework OPack that adapts and improves the performance of BP heuristics by utilizing information in an online setting with a look-ahead. We then perform a comparative analysis of BP heuristics (with and without OPack), MPack, and MPackLite on synthetic and industry provided data with increasing look-ahead. MPackLite and the baseline heuristics perform within bounds of robot operations and thus, can be used in real-time.
Text Information Aggregation with Centrality Attention
Nov 16, 2020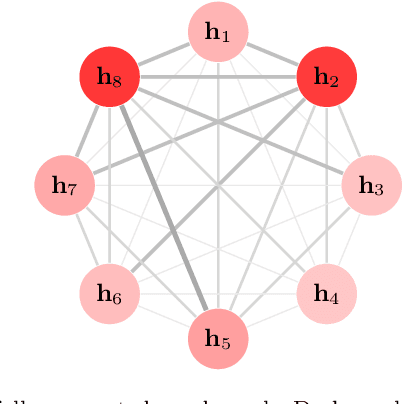
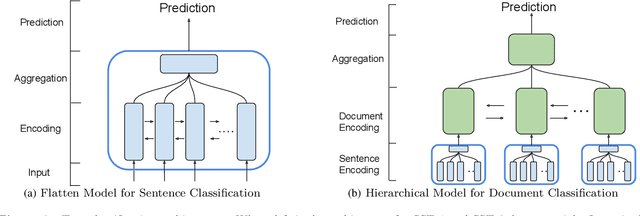
A lot of natural language processing problems need to encode the text sequence as a fix-length vector, which usually involves aggregation process of combining the representations of all the words, such as pooling or self-attention. However, these widely used aggregation approaches did not take higher-order relationship among the words into consideration. Hence we propose a new way of obtaining aggregation weights, called eigen-centrality self-attention. More specifically, we build a fully-connected graph for all the words in a sentence, then compute the eigen-centrality as the attention score of each word. The explicit modeling of relationships as a graph is able to capture some higher-order dependency among words, which helps us achieve better results in 5 text classification tasks and one SNLI task than baseline models such as pooling, self-attention and dynamic routing. Besides, in order to compute the dominant eigenvector of the graph, we adopt power method algorithm to get the eigen-centrality measure. Moreover, we also derive an iterative approach to get the gradient for the power method process to reduce both memory consumption and computation requirement.}
Few-Shot Object Detection by Attending to Per-Sample-Prototype
Sep 16, 2021


Few-shot object detection aims to detect instances of specific categories in a query image with only a handful of support samples. Although this takes less effort than obtaining enough annotated images for supervised object detection, it results in a far inferior performance compared to the conventional object detection methods. In this paper, we propose a meta-learning-based approach that considers the unique characteristics of each support sample. Rather than simply averaging the information of the support samples to generate a single prototype per category, our method can better utilize the information of each support sample by treating each support sample as an individual prototype. Specifically, we introduce two types of attention mechanisms for aggregating the query and support feature maps. The first is to refine the information of few-shot samples by extracting shared information between the support samples through attention. Second, each support sample is used as a class code to leverage the information by comparing similarities between each support feature and query features. Our proposed method is complementary to the previous methods, making it easy to plug and play for further improvement. We have evaluated our method on PASCAL VOC and COCO benchmarks, and the results verify the effectiveness of our method. In particular, the advantages of our method are maximized when there is more diversity among support data.
Incompleteness of graph convolutional neural networks for points clouds in three dimensions
Jan 18, 2022
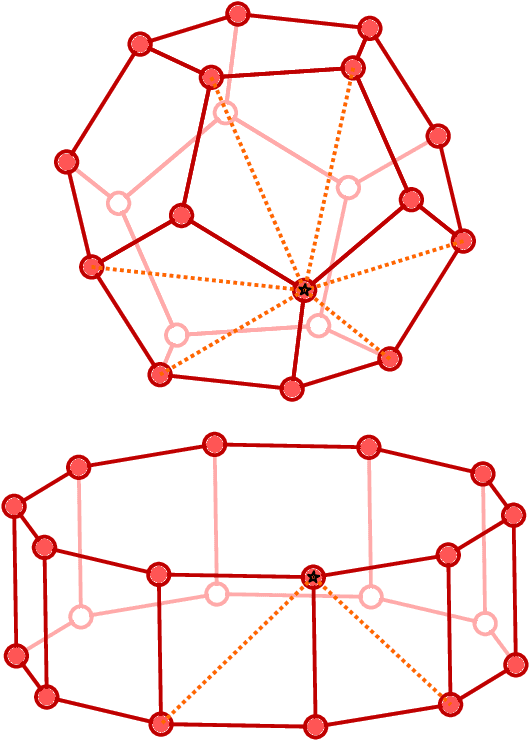
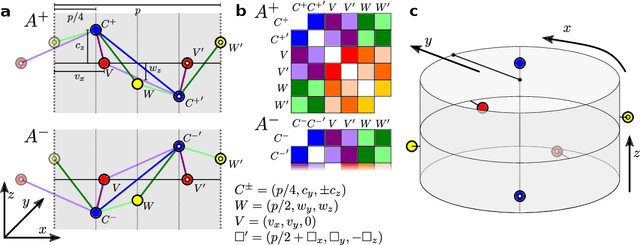
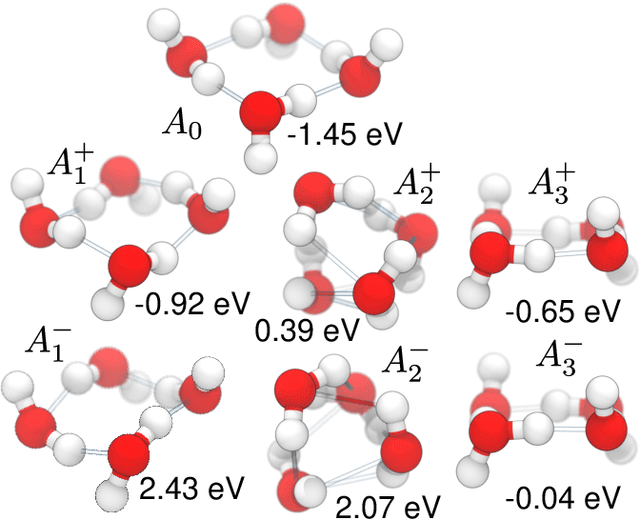
Graph convolutional neural networks (GCNN) are very popular methods in machine learning and have been applied very successfully to the prediction of the properties of molecules and materials. First-order GCNNs are well known to be incomplete, i.e., there exist graphs that are distinct but appear identical when seen through the lens of the GCNN. More complicated schemes have thus been designed to increase their resolving power. Applications to molecules (and more generally, point clouds), however, add a geometric dimension to the problem. The most straightforward and prevalent approach to construct graph representation for the molecules regards atoms as vertices in a graph and draws a bond between each pair of atoms within a certain preselected cutoff. Bonds can be decorated with the distance between atoms, and the resulting "distance graph convolution NNs" (dGCNN) have empirically demonstrated excellent resolving power and are widely used in chemical ML. Here we show that even for the restricted case of graphs induced by 3D atom clouds dGCNNs are not complete. We construct pairs of distinct point clouds that generate graphs that, for any cutoff radius, are equivalent based on a first-order Weisfeiler-Lehman test. This class of degenerate structures includes chemically-plausible configurations, setting an ultimate limit to the expressive power of some of the well-established GCNN architectures for atomistic machine learning. Models that explicitly use angular information in the description of atomic environments can resolve these degeneracies.