 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-Supervised Predictive Convolutional Attentive Block for Anomaly Detection
Nov 18, 2021
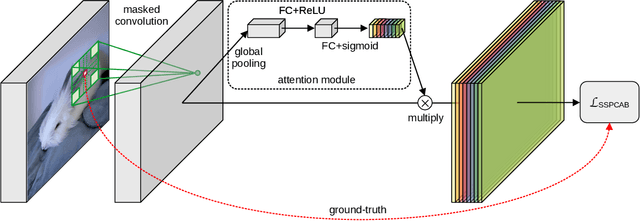
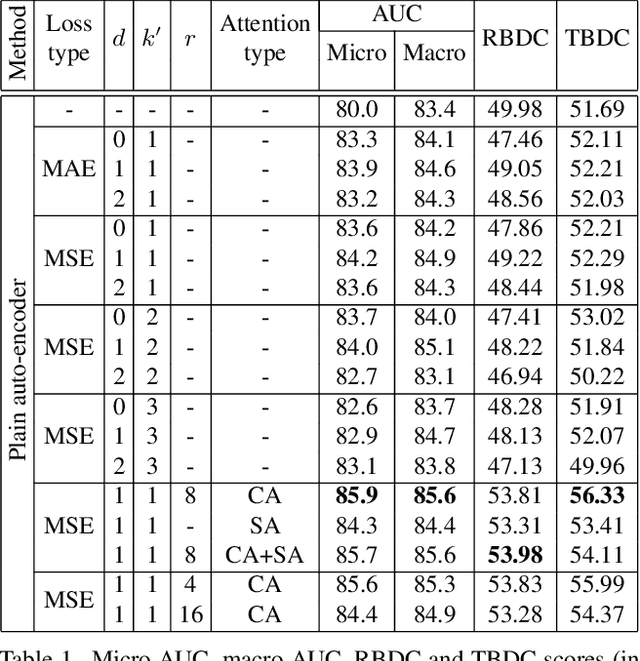
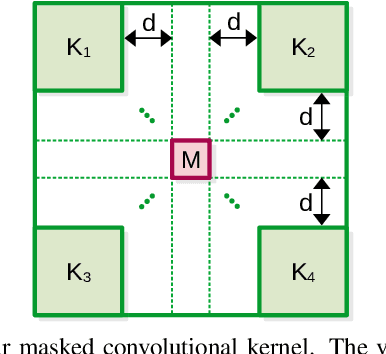
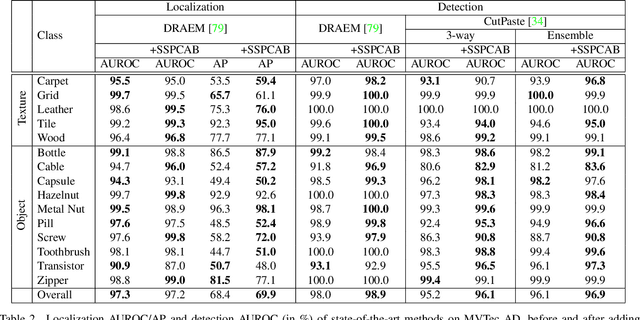
Anomaly detection is commonly pursued as a one-class classification problem, where models can only learn from normal training samples, while being evaluated on both normal and abnormal test samples. Among the successful approaches for anomaly detection, a distinguished category of methods relies on predicting masked information (e.g. patches, future frames, etc.) and leveraging the reconstruction error with respect to the masked information as an abnormality score. Different from related methods, we propose to integrate the reconstruction-based functionality into a novel self-supervised predictive architectural building block. The proposed self-supervised block is generic and can easily be incorporated into various state-of-the-art anomaly detection methods. Our block starts with a convolutional layer with dilated filters, where the center area of the receptive field is masked. The resulting activation maps are passed through a channel attention module. Our block is equipped with a loss that minimizes the reconstruction error with respect to the masked area in the receptive field. We demonstrate the generality of our block by integrating it into several state-of-the-art frameworks for anomaly detection on image and video, providing empirical evidence that shows considerable performance improvements on MVTec AD, Avenue, and ShanghaiTech.
MyoPS: A Benchmark of Myocardial Pathology Segmentation Combining Three-Sequence Cardiac Magnetic Resonance Images
Jan 10, 2022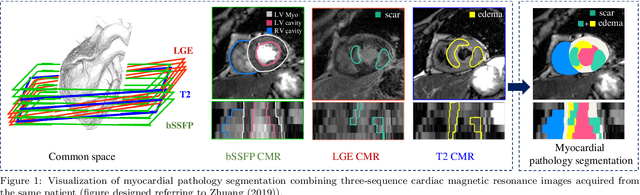
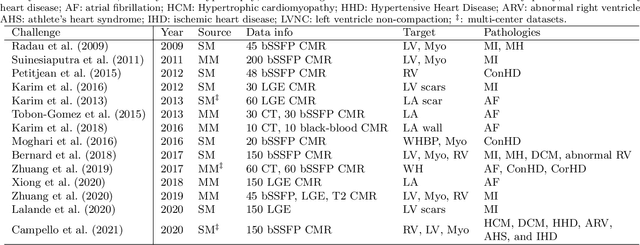
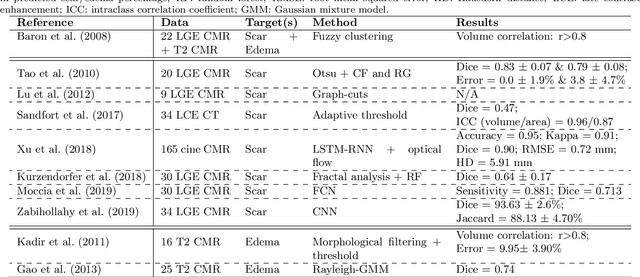
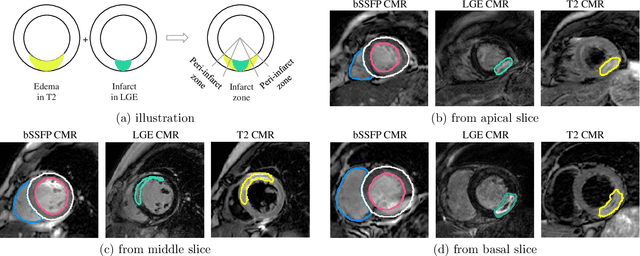
Assessment of myocardial viability is essential in diagnosis and treatment management of patients suffering from myocardial infarction, and classification of pathology on myocardium is the key to this assessment. This work defines a new task of medical image analysis, i.e., to perform myocardial pathology segmentation (MyoPS) combining three-sequence cardiac magnetic resonance (CMR) images, which was first proposed in the MyoPS challenge, in conjunction with MICCAI 2020. The challenge provided 45 paired and pre-aligned CMR images, allowing algorithms to combine the complementary information from the three CMR sequences for pathology segmentation. In this article, we provide details of the challenge, survey the works from fifteen participants and interpret their methods according to five aspects, i.e., preprocessing, data augmentation, learning strategy, model architecture and post-processing. In addition, we analyze the results with respect to different factors, in order to examine the key obstacles and explore potential of solutions, as well as to provide a benchmark for future research. We conclude that while promising results have been reported, the research is still in the early stage, and more in-depth exploration is needed before a successful application to the clinics. Note that MyoPS data and evaluation tool continue to be publicly available upon registration via its homepage (www.sdspeople.fudan.edu.cn/zhuangxiahai/0/myops20/).
Boosting Robustness of Image Matting with Context Assembling and Strong Data Augmentation
Jan 18, 2022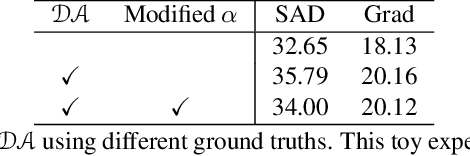

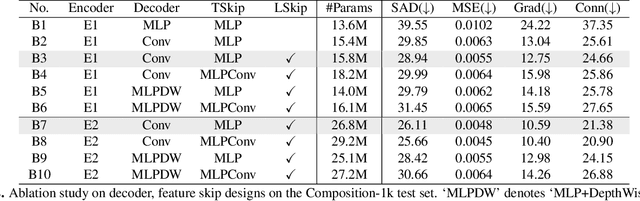
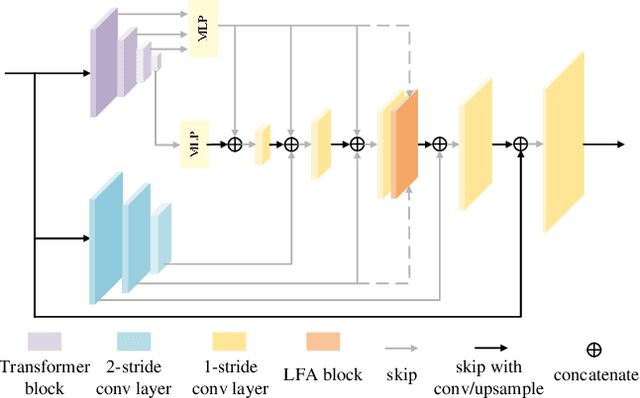
Deep image matting methods have achieved increasingly better results on benchmarks (e.g., Composition-1k/alphamatting.com). However, the robustness, including robustness to trimaps and generalization to images from different domains, is still under-explored. Although some works propose to either refine the trimaps or adapt the algorithms to real-world images via extra data augmentation, none of them has taken both into consideration, not to mention the significant performance deterioration on benchmarks while using those data augmentation. To fill this gap, we propose an image matting method which achieves higher robustness (RMat) via multilevel context assembling and strong data augmentation targeting matting. Specifically, we first build a strong matting framework by modeling ample global information with transformer blocks in the encoder, and focusing on details in combination with convolution layers as well as a low-level feature assembling attention block in the decoder. Then, based on this strong baseline, we analyze current data augmentation and explore simple but effective strong data augmentation to boost the baseline model and contribute a more generalizable matting method. Compared with previous methods, the proposed method not only achieves state-of-the-art results on the Composition-1k benchmark (11% improvement on SAD and 27% improvement on Grad) with smaller model size, but also shows more robust generalization results on other benchmarks, on real-world images, and also on varying coarse-to-fine trimaps with our extensive experiments.
A novel knowledge graph development for industry design: A case study on indirect coal liquefaction process
Nov 27, 2021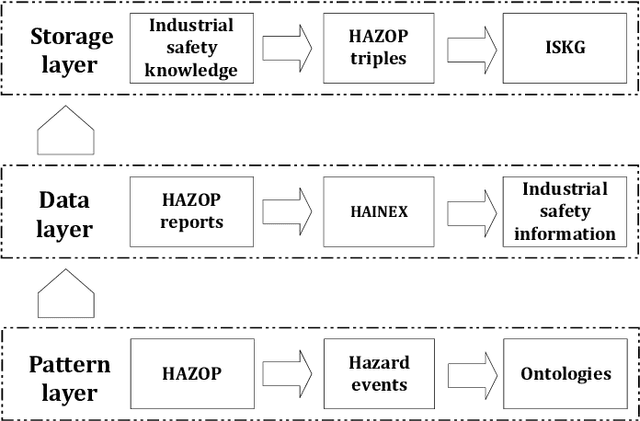
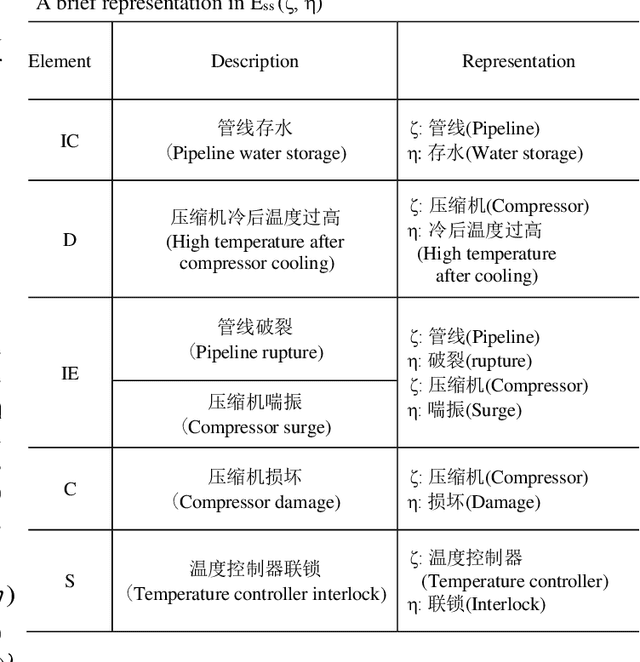

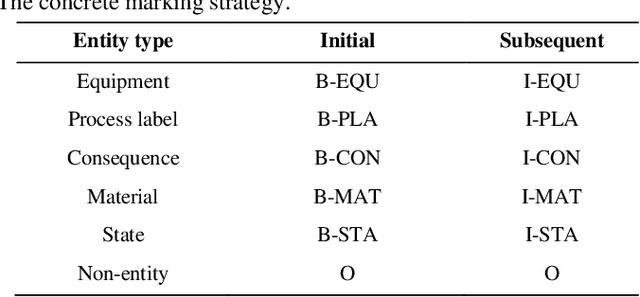
Hazard and operability analysis (HAZOP) is a remarkable representative in industrial safety engineering, the HAZOP report contains a great storehouse of industrial safety knowledge (ISK). In order to unlock the value of ISK and improve HAZOP efficiency, a novel knowledge graph development for industrial safety (ISKG) is proposed. Firstly, according to the international standard IEC61882, we use the top-down approach to disintegrate HAZOP into hazard events with multi-level information, which constructs the ontology library. Secondly, using the bottom-up approach and natural language processing technology, we present an ingenious information extraction model termed HAINEX based on hybrid deep learning. Briefly, the HAINEX consists of the following modules: an improved industrial bidirectional encoder for extracting semantic features, a bidirectional long short-term memory network for obtaining the context representation, and a decoder based on conditional random field with an improved industrial loss function. Finally, the constructed HAZOP triples are imported into the graph database. Experiments show that HAINEX is advanced and reliable. We take the indirect coal liquefaction process as a case study to develop ISKG. ISKG oriented applications, such as ISK visualization, ISK retrieval, auxiliary HAZOP and hazard propagation reasoning, can mine the potential of ISK and improve HAZOP efficiency, which is of great significance in strengthening industrial safety. What is more, the ISKG based question-answering system can be applied to teaching guidance to popularize the safety knowledge and enhance prevention awareness for non-professionals.
Bioacoustic Event Detection with prototypical networks and data augmentation
Dec 16, 2021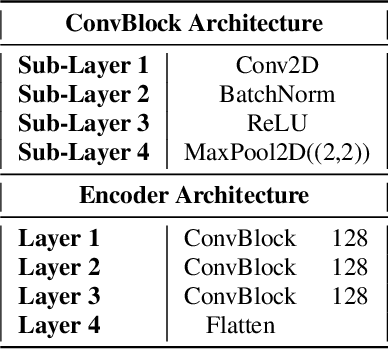
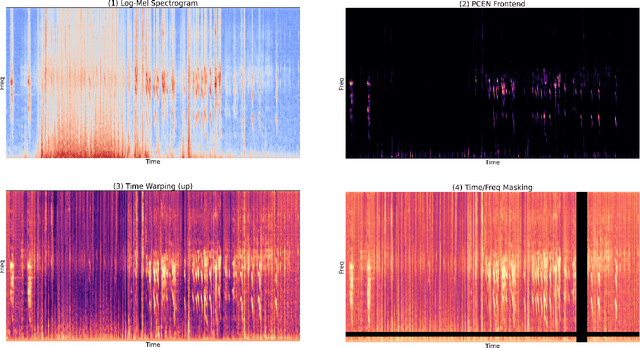
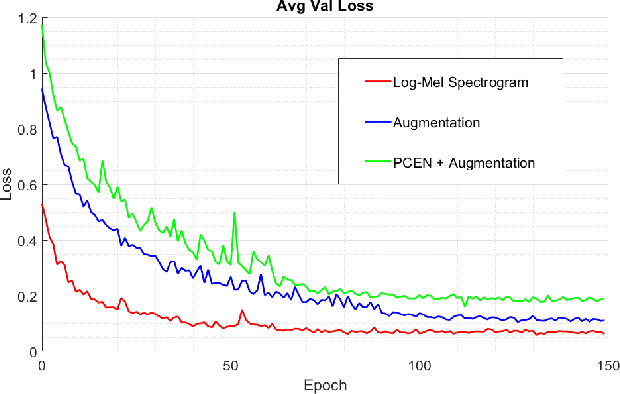
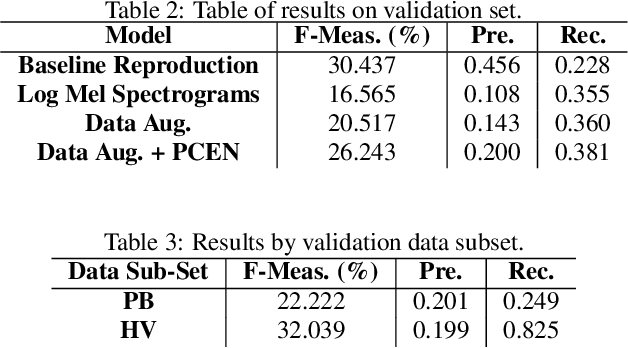
This report presents deep learning and data augmentation techniques used by a system entered into the Few-Shot Bioacoustic Event Detection for the DCASE2021 Challenge. The remit was to develop a few-shot learning system for animal (mammal and bird) vocalisations. Participants were tasked with developing a method that can extract information from five exemplar vocalisations, or shots, of mammals or birds and detect and classify sounds in field recordings. In the system described in this report, prototypical networks are used to learn a metric space, from which classification is performed by computing the distance of a query point to class prototypes, classifying based on shortest distance. We describe the architecture of this network, feature extraction methods, and data augmentation performed on the given dataset and compare our work to the challenge's baseline networks.
LF-YOLO: A Lighter and Faster YOLO for Weld Defect Detection of X-ray Image
Nov 18, 2021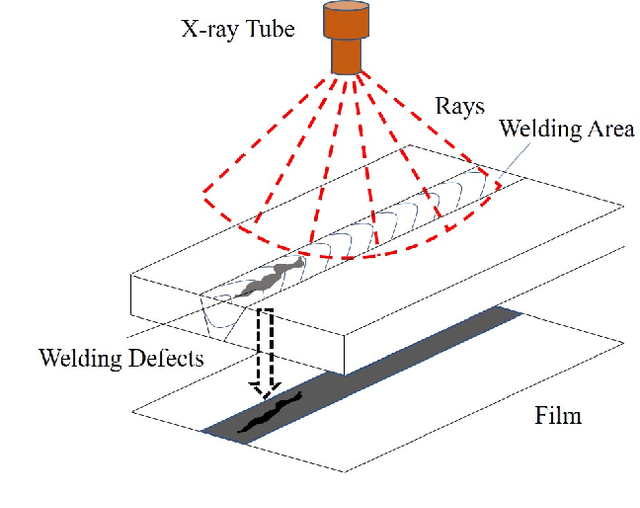

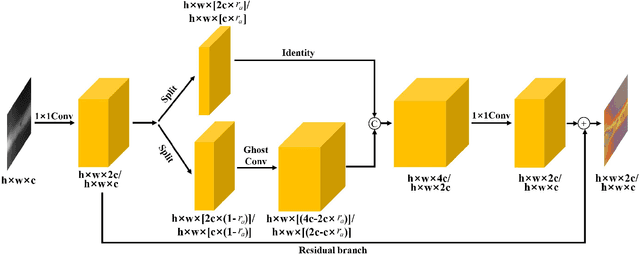
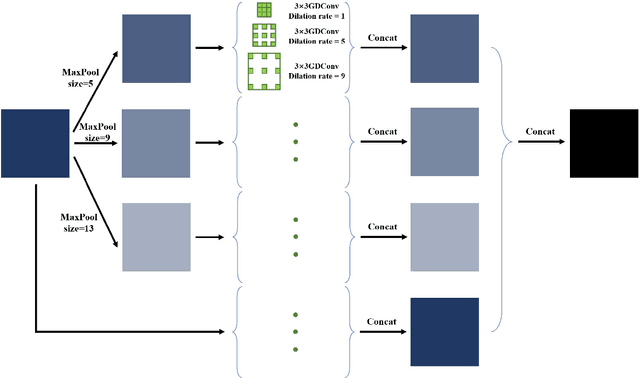
X-ray image plays an important role in manufacturing industry for quality assurance, because it can reflect the internal condition of weld region. However, the shape and scale of different defect types vary greatly, which makes it challenging for model to detect weld defects. In this paper, we propose a weld defect detection method based on convolution neural network, namely Lighter and Faster YOLO (LF-YOLO). In particularly, a reinforced multiscale feature (RMF) module is designed to implement both parameter-based and parameter-free multi-scale information extracting operation. RMF enables the extracted feature map capable to represent more plentiful information, which is achieved by superior hierarchical fusion structure. To improve the performance of detection network, we propose an efficient feature extraction (EFE) module. EFE processes input data with extremely low consumption, and improves the practicability of whole network in actual industry. Experimental results show that our weld defect detection network achieves satisfactory balance between performance and consumption, and reaches 92.9 mean average precision mAP50 with 61.5 frames per second (FPS). To further prove the ability of our method, we test it on public dataset MS COCO, and the results show that our LF-YOLO has a outstanding versatility detection performance. The code is available at https://github.com/lmomoy/LF-YOLO.
Theory of Mind Based Assistive Communication in Complex Human Robot Cooperation
Sep 03, 2021
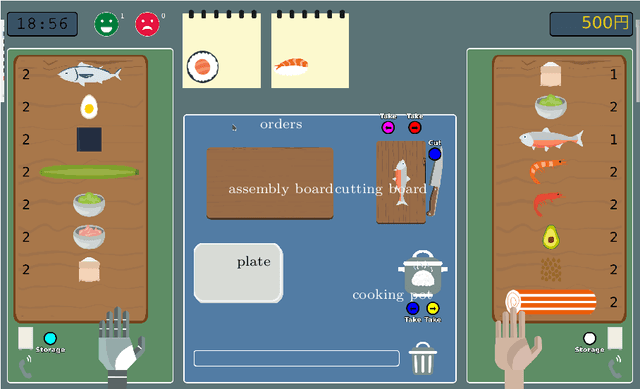
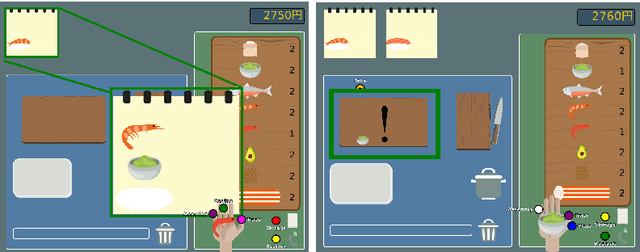
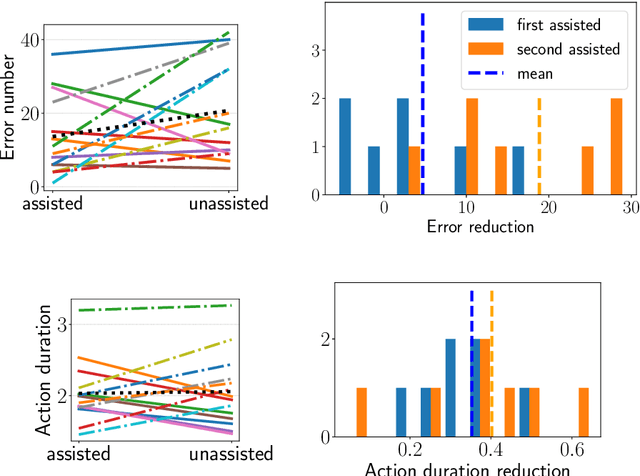
When cooperating with a human, a robot should not only care about its environment and task but also develop an understanding of the partner's reasoning. To support its human partner in complex tasks, the robot can share information that it knows. However simply communicating everything will annoy and distract humans since they might already be aware of and not all information is relevant in the current situation. The questions when and what type of information the human needs, are addressed through the concept of Theory of Mind based Communication which selects information sharing actions based on evaluation of relevance and an estimation of human beliefs. We integrate this into a communication assistant to support humans in a cooperative setting and evaluate performance benefits. We designed a human robot Sushi making task that is challenging for the human and generates different situations where humans are unaware and communication could be beneficial. We evaluate the influence of the human centric communication concept on performance with a user study. Compared to the condition without information exchange, assisted participants can recover from unawareness much earlier. The approach respects the costs of communication and balances interruptions better than other approaches. By providing information adapted to specific situations, the robot does not instruct but enable the human to make good decision.
On Causal Inference for Data-free Structured Pruning
Dec 19, 2021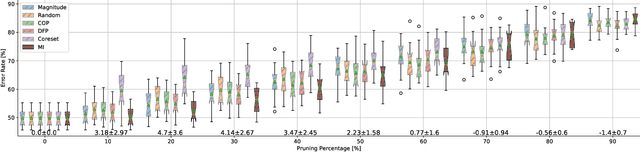
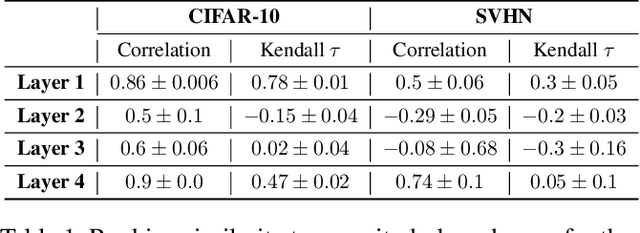
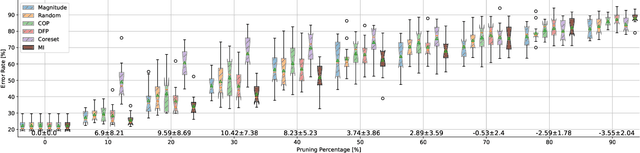

Neural networks (NNs) are making a large impact both on research and industry. Nevertheless, as NNs' accuracy increases, it is followed by an expansion in their size, required number of compute operations and energy consumption. Increase in resource consumption results in NNs' reduced adoption rate and real-world deployment impracticality. Therefore, NNs need to be compressed to make them available to a wider audience and at the same time decrease their runtime costs. In this work, we approach this challenge from a causal inference perspective, and we propose a scoring mechanism to facilitate structured pruning of NNs. The approach is based on measuring mutual information under a maximum entropy perturbation, sequentially propagated through the NN. We demonstrate the method's performance on two datasets and various NNs' sizes, and we show that our approach achieves competitive performance under challenging conditions.
PrognoseNet: A Generative Probabilistic Framework for Multimodal Position Prediction given Context Information
Oct 02, 2020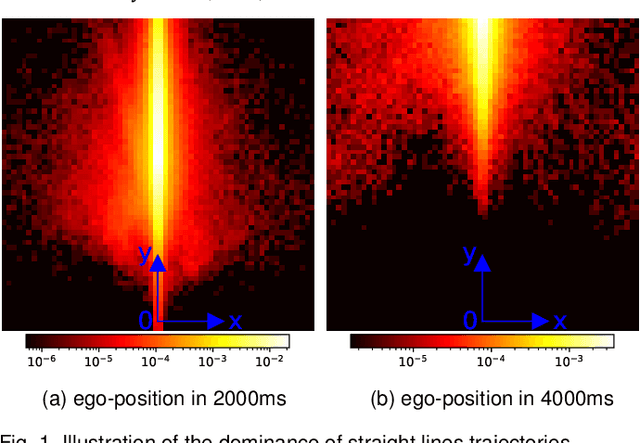
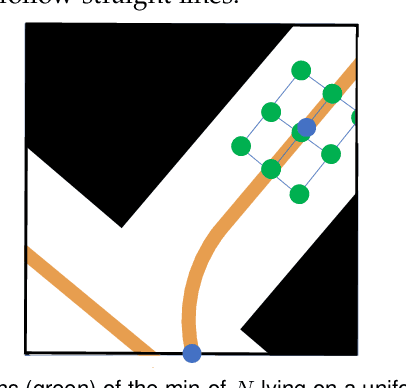

The ability to predict multiple possible future positions of the ego-vehicle given the surrounding context while also estimating their probabilities is key to safe autonomous driving. Most of the current state-of-the-art Deep Learning approaches are trained on trajectory data to achieve this task. However trajectory data captured by sensor systems is highly imbalanced, since by far most of the trajectories follow straight lines with an approximately constant velocity. This poses a huge challenge for the task of predicting future positions, which is inherently a regression problem. Current state-of-the-art approaches alleviate this problem only by major preprocessing of the training data, e.g. resampling, clustering into anchors etc. In this paper we propose an approach which reformulates the prediction problem as a classification task, allowing for powerful tools, e.g. focal loss, to combat the imbalance. To this end we design a generative probabilistic model consisting of a deep neural network with a Mixture of Gaussian head. A smart choice of the latent variable allows for the reformulation of the log-likelihood function as a combination of a classification problem and a much simplified regression problem. The output of our model is an estimate of the probability density function of future positions, hence allowing for prediction of multiple possible positions while also estimating their probabilities. The proposed approach can easily incorporate context information and does not require any preprocessing of the data.
Complexity and Aesthetics in Generative and Evolutionary Art
Jan 05, 2022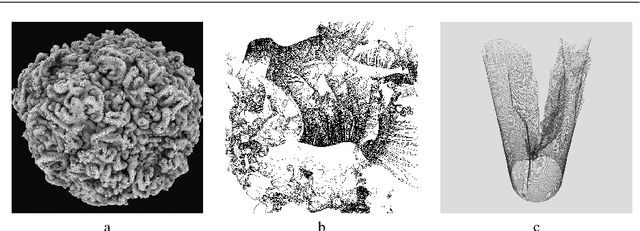

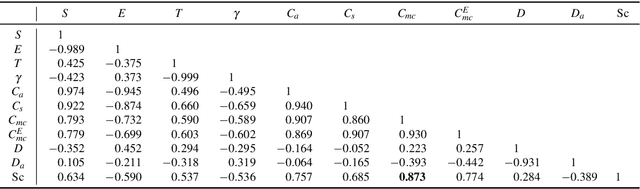
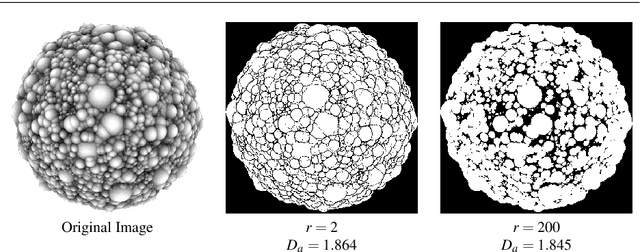
In this paper we examine the concept of complexity as it applies to generative and evolutionary art and design. Complexity has many different, discipline specific definitions, such as complexity in physical systems (entropy), algorithmic measures of information complexity and the field of "complex systems". We apply a series of different complexity measures to three different evolutionary art datasets and look at the correlations between complexity and individual aesthetic judgement by the artist (in the case of two datasets) or the physically measured complexity of generative 3D forms. Our results show that the degree of correlation is different for each set and measure, indicating that there is no overall "better" measure. However, specific measures do perform well on individual datasets, indicating that careful choice can increase the value of using such measures. We then assess the value of complexity measures for the audience by undertaking a large-scale survey on the perception of complexity and aesthetics. We conclude by discussing the value of direct measures in generative and evolutionary art, reinforcing recent findings from neuroimaging and psychology which suggest human aesthetic judgement is informed by many extrinsic factors beyond the measurable properties of the object being judged.