 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Multi-modal Fusion Framework Based on Multi-task Correlation Learning for Cancer Prognosis Prediction
Jan 22, 2022
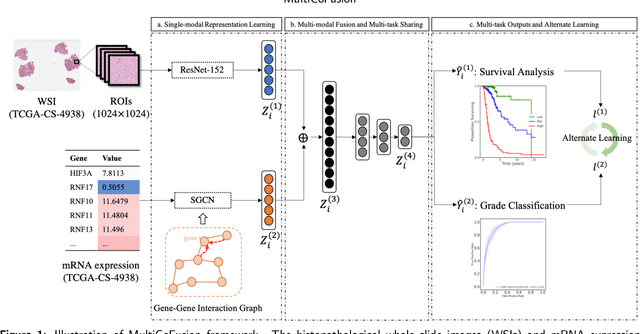
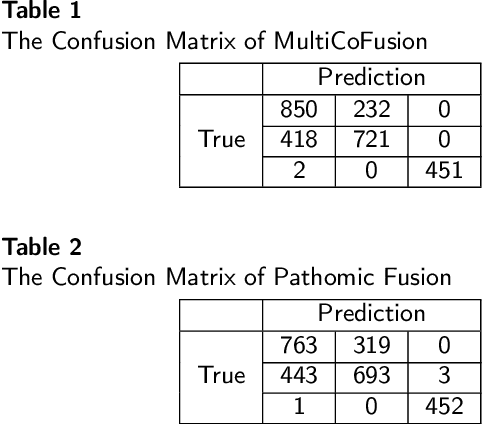
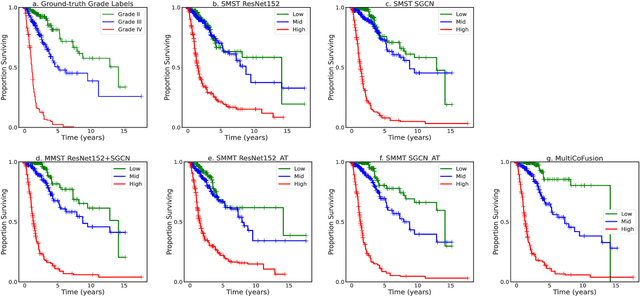
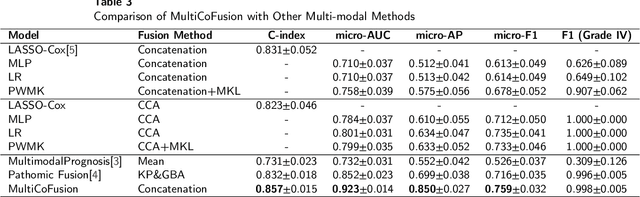
Morphological attributes from histopathological images and molecular profiles from genomic data are important information to drive diagnosis, prognosis, and therapy of cancers. By integrating these heterogeneous but complementary data, many multi-modal methods are proposed to study the complex mechanisms of cancers, and most of them achieve comparable or better results from previous single-modal methods. However, these multi-modal methods are restricted to a single task (e.g., survival analysis or grade classification), and thus neglect the correlation between different tasks. In this study, we present a multi-modal fusion framework based on multi-task correlation learning (MultiCoFusion) for survival analysis and cancer grade classification, which combines the power of multiple modalities and multiple tasks. Specifically, a pre-trained ResNet-152 and a sparse graph convolutional network (SGCN) are used to learn the representations of histopathological images and mRNA expression data respectively. Then these representations are fused by a fully connected neural network (FCNN), which is also a multi-task shared network. Finally, the results of survival analysis and cancer grade classification output simultaneously. The framework is trained by an alternate scheme. We systematically evaluate our framework using glioma datasets from The Cancer Genome Atlas (TCGA). Results demonstrate that MultiCoFusion learns better representations than traditional feature extraction methods. With the help of multi-task alternating learning, even simple multi-modal concatenation can achieve better performance than other deep learning and traditional methods. Multi-task learning can improve the performance of multiple tasks not just one of them, and it is effective in both single-modal and multi-modal data.
Bayesian Optimization Based Trustworthiness Model for Multi-robot Bounding Overwatch
Jan 06, 2022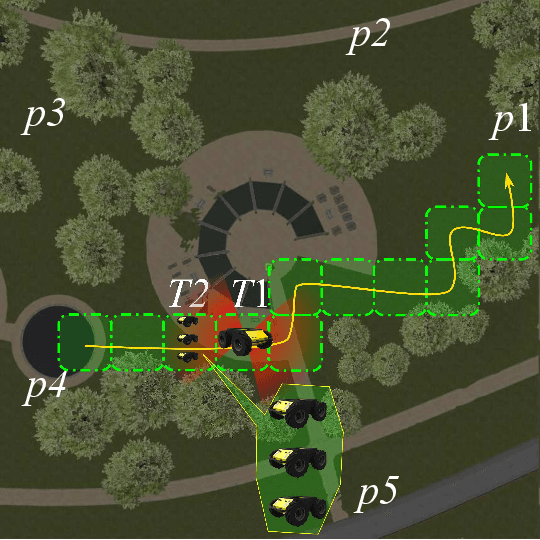
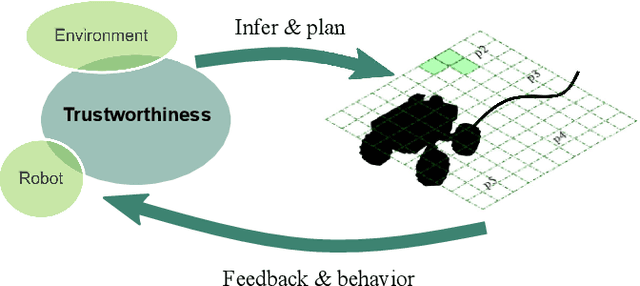
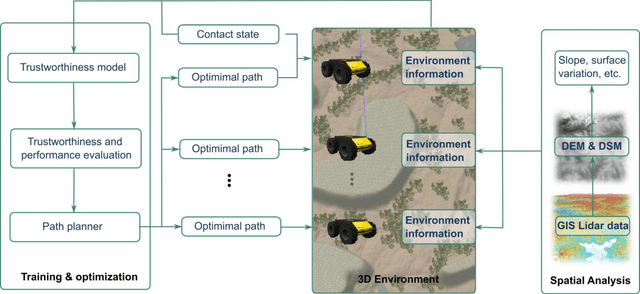

In multi-robot system (MRS) bounding overwatch, it is crucial to determine which point to choose for overwatch at each step and whether the robots' positions are trustworthy so that the overwatch can be performed effectively. In this paper, we develop a Bayesian optimization based computational trustworthiness model (CTM) for the MRS to select overwatch points. The CTM can provide real-time trustworthiness evaluation for the MRS on the overwatch points by referring to the robots' situational awareness information, such as traversability and line of sight. The evaluation can quantify each robot's trustworthiness in protecting its robot team members during the bounding overwatch. The trustworthiness evaluation can generate a dynamic cost map for each robot in the workspace and help obtain the most trustworthy bounding overwatch path. Our proposed Bayesian based CTM and motion planning can reduce the number of explorations for the workspace in data collection and improve the CTM learning efficiency. It also enables the MRS to deal with the dynamic and uncertain environments for the multi-robot bounding overwatch task. A robot simulation is implemented in ROS Gazebo to demonstrate the effectiveness of the proposed framework.
Text Information Aggregation with Centrality Attention
Nov 16, 2020
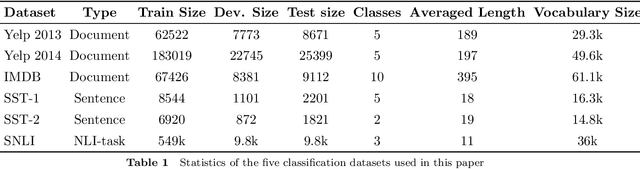
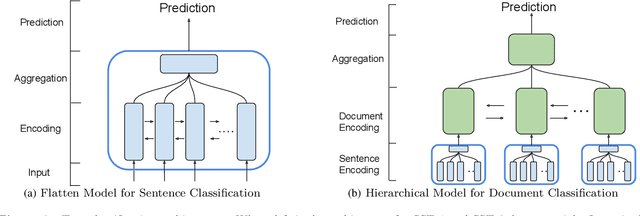
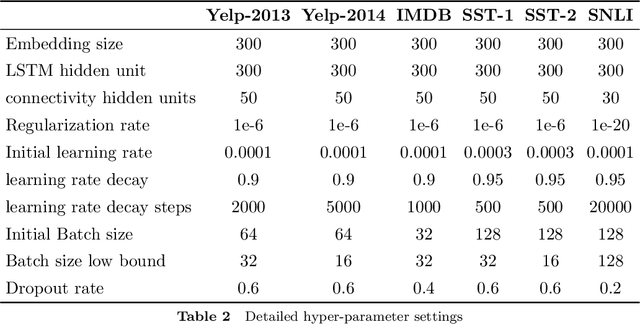
A lot of natural language processing problems need to encode the text sequence as a fix-length vector, which usually involves aggregation process of combining the representations of all the words, such as pooling or self-attention. However, these widely used aggregation approaches did not take higher-order relationship among the words into consideration. Hence we propose a new way of obtaining aggregation weights, called eigen-centrality self-attention. More specifically, we build a fully-connected graph for all the words in a sentence, then compute the eigen-centrality as the attention score of each word. The explicit modeling of relationships as a graph is able to capture some higher-order dependency among words, which helps us achieve better results in 5 text classification tasks and one SNLI task than baseline models such as pooling, self-attention and dynamic routing. Besides, in order to compute the dominant eigenvector of the graph, we adopt power method algorithm to get the eigen-centrality measure. Moreover, we also derive an iterative approach to get the gradient for the power method process to reduce both memory consumption and computation requirement.}
Lumbar Bone Mineral Density Estimation from Chest X-ray Images: Anatomy-aware Attentive Multi-ROI Modeling
Jan 05, 2022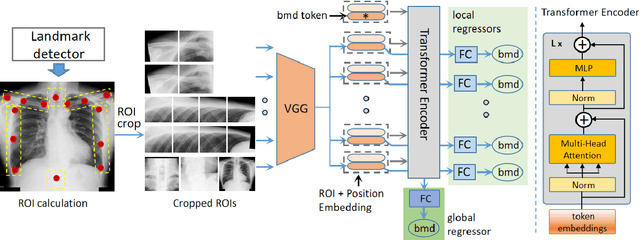
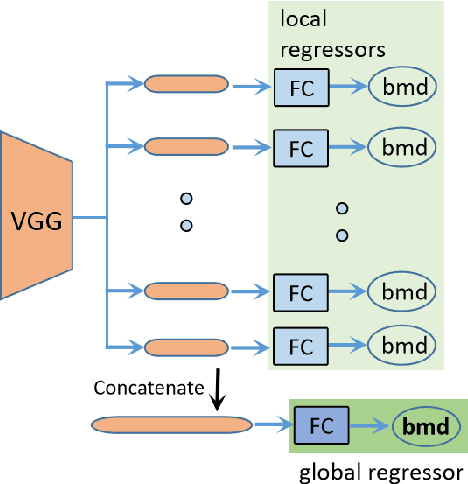
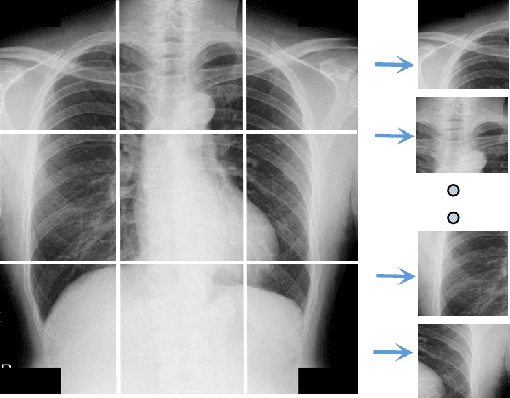
Osteoporosis is a common chronic metabolic bone disease that is often under-diagnosed and under-treated due to the limited access to bone mineral density (BMD) examinations, e.g. via Dual-energy X-ray Absorptiometry (DXA). In this paper, we propose a method to predict BMD from Chest X-ray (CXR), one of the most commonly accessible and low-cost medical imaging examinations. Our method first automatically detects Regions of Interest (ROIs) of local and global bone structures from the CXR. Then a multi-ROI deep model with transformer encoder is developed to exploit both local and global information in the chest X-ray image for accurate BMD estimation. Our method is evaluated on 13719 CXR patient cases with their ground truth BMD scores measured by gold-standard DXA. The model predicted BMD has a strong correlation with the ground truth (Pearson correlation coefficient 0.889 on lumbar 1). When applied for osteoporosis screening, it achieves a high classification performance (AUC 0.963 on lumbar 1). As the first effort in the field using CXR scans to predict the BMD, the proposed algorithm holds strong potential in early osteoporosis screening and public health promotion.
GroupIM: A Mutual Information Maximization Framework for Neural Group Recommendation
Jun 09, 2020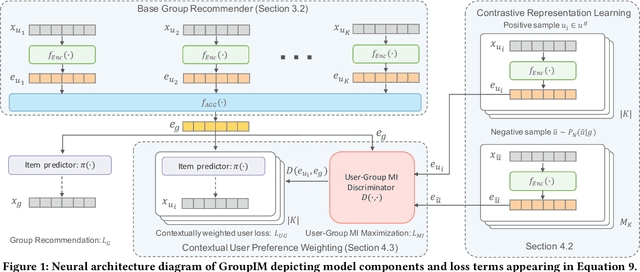
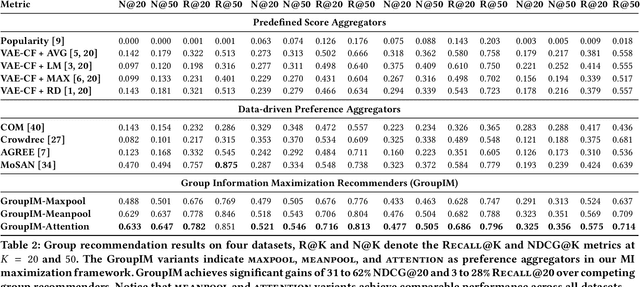
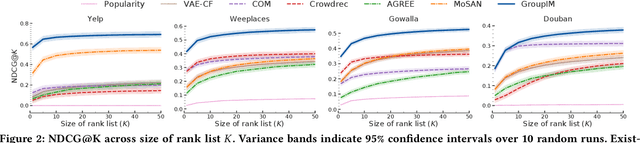
We study the problem of making item recommendations to ephemeral groups, which comprise users with limited or no historical activities together. Existing studies target persistent groups with substantial activity history, while ephemeral groups lack historical interactions. To overcome group interaction sparsity, we propose data-driven regularization strategies to exploit both the preference covariance amongst users who are in the same group, as well as the contextual relevance of users' individual preferences to each group. We make two contributions. First, we present a recommender architecture-agnostic framework GroupIM that can integrate arbitrary neural preference encoders and aggregators for ephemeral group recommendation. Second, we regularize the user-group latent space to overcome group interaction sparsity by: maximizing mutual information between representations of groups and group members; and dynamically prioritizing the preferences of highly informative members through contextual preference weighting. Our experimental results on several real-world datasets indicate significant performance improvements (31-62% relative NDCG@20) over state-of-the-art group recommendation techniques.
Calibrated Feature Decomposition for Generalizable Person Re-Identification
Nov 27, 2021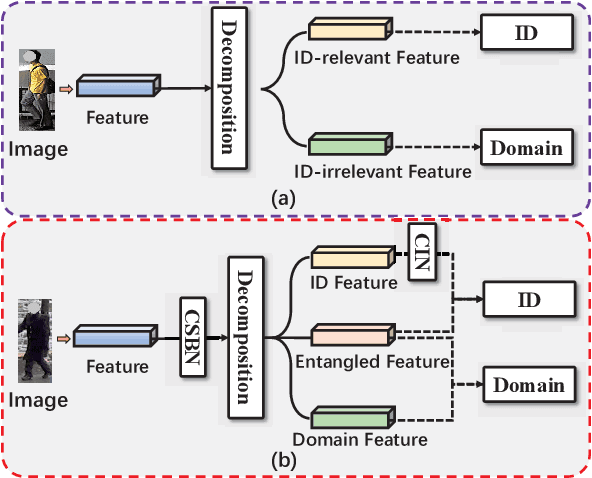
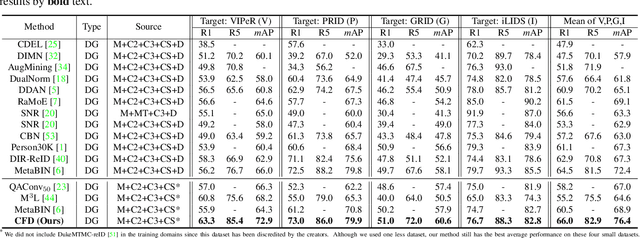
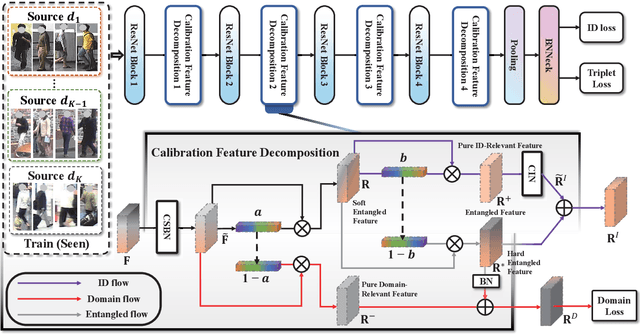
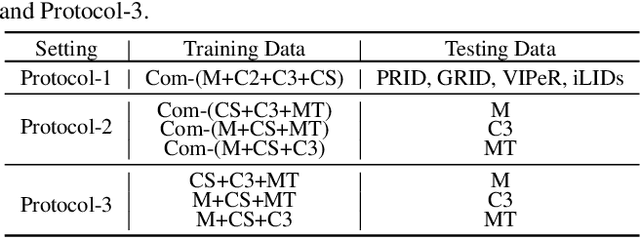
Existing disentangled-based methods for generalizable person re-identification aim at directly disentangling person representations into domain-relevant interference and identity-relevant feature. However, they ignore that some crucial characteristics are stubbornly entwined in both the domain-relevant interference and identity-relevant feature, which are intractable to decompose in an unsupervised manner. In this paper, we propose a simple yet effective Calibrated Feature Decomposition (CFD) module that focuses on improving the generalization capacity for person re-identification through a more judicious feature decomposition and reinforcement strategy. Specifically, a calibrated-and-standardized Batch normalization (CSBN) is designed to learn calibrated person representation by jointly exploring intra-domain calibration and inter-domain standardization of multi-source domain features. CSBN restricts instance-level inconsistency of feature distribution for each domain and captures intrinsic domain-level specific statistics. The calibrated person representation is subtly decomposed into the identity-relevant feature, domain feature, and the remaining entangled one. For enhancing the generalization ability and ensuring high discrimination of the identity-relevant feature, a calibrated instance normalization (CIN) is introduced to enforce discriminative id-relevant information, and filter out id-irrelevant information, and meanwhile the rich complementary clues from the remaining entangled feature are further employed to strengthen it. Extensive experiments demonstrate the strong generalization capability of our framework. Our models empowered by CFD modules significantly outperform the state-of-the-art domain generalization approaches on multiple widely-used benchmarks. Code will be made public: https://github.com/zkcys001/CFD.
Enhanced Membership Inference Attacks against Machine Learning Models
Nov 18, 2021
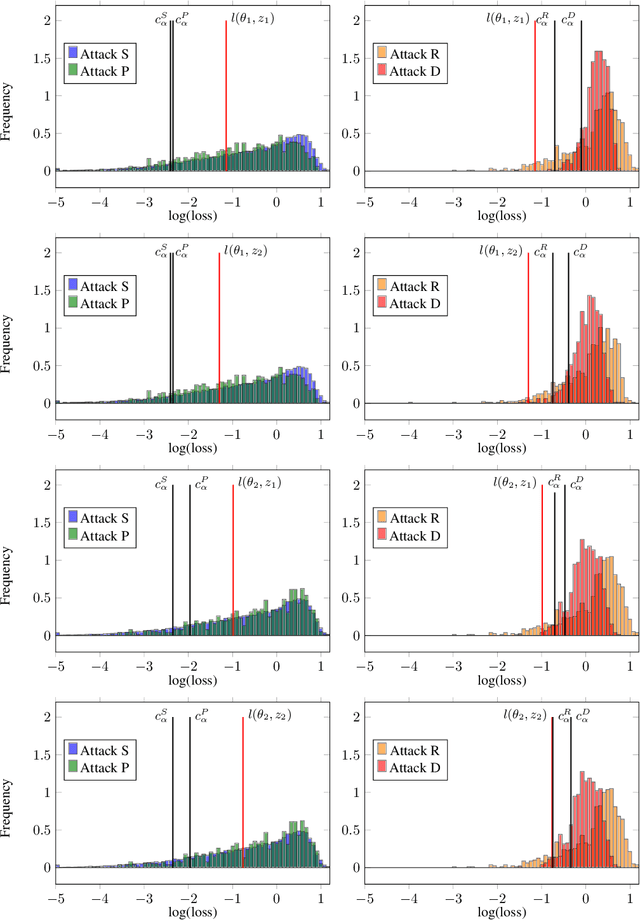
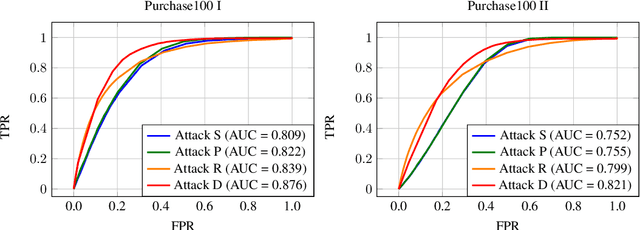

How much does a given trained model leak about each individual data record in its training set? Membership inference attacks are used as an auditing tool to quantify the private information that a model leaks about the individual data points in its training set. Membership inference attacks are influenced by different uncertainties that an attacker has to resolve about training data, the training algorithm, and the underlying data distribution. Thus attack success rates, of many attacks in the literature, do not precisely capture the information leakage of models about their data, as they also reflect other uncertainties that the attack algorithm has. In this paper, we explain the implicit assumptions and also the simplifications made in prior work using the framework of hypothesis testing. We also derive new attack algorithms from the framework that can achieve a high AUC score while also highlighting the different factors that affect their performance. Our algorithms capture a very precise approximation of privacy loss in models, and can be used as a tool to perform an accurate and informed estimation of privacy risk in machine learning models. We provide a thorough empirical evaluation of our attack strategies on various machine learning tasks and benchmark datasets.
Transfer Learning Based Multi-Objective Genetic Algorithm for Dynamic Community Detection
Oct 09, 2021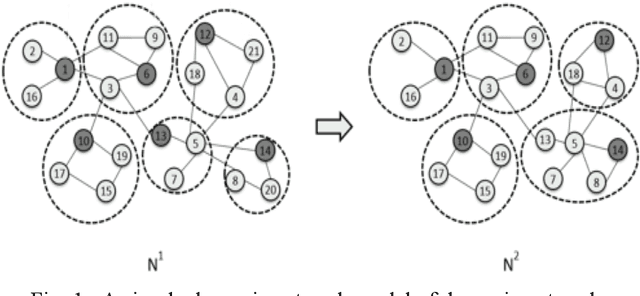

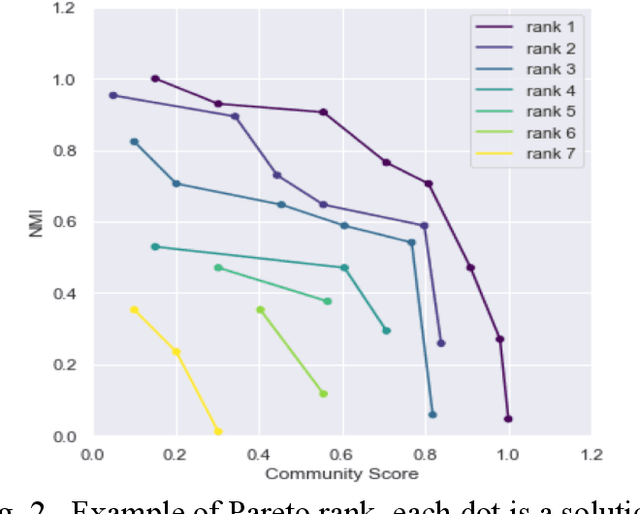

Dynamic community detection is the hotspot and basic problem of complex network and artificial intelligence research in recent years. It is necessary to maximize the accuracy of clustering as the network structure changes, but also to minimize the two consecutive clustering differences between the two results. There is a trade-off relationship between these two objectives. In this paper, we propose a Feature Transfer Based Multi-Objective Optimization Genetic Algorithm (TMOGA) based on transfer learning and traditional multi-objective evolutionary algorithm framework. The main idea is to extract stable features from past community structures, retain valuable feature information, and integrate this feature information into current optimization processes to improve the evolutionary algorithms. Additionally, a new theoretical framework is proposed in this paper to analyze community detection problem based on information theory. Then, we exploit this framework to prove the rationality of TMOGA. Finally, the experimental results show that our algorithm can achieve better clustering effects compared with the state-of-the-art dynamic network community detection algorithms in diverse test problems.
An Evolutionary Game for Mobile User Access Mode Selection in sub-$6$ GHz/mmWave Cellular Networks
Jan 10, 2022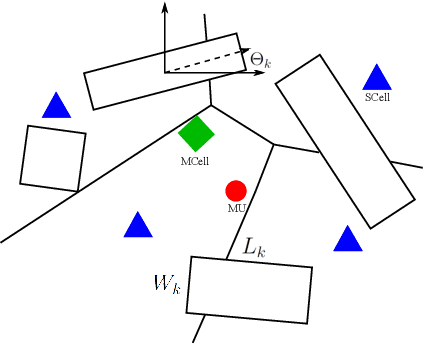
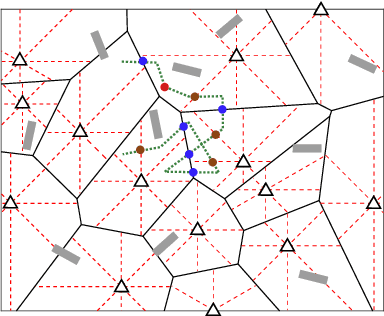
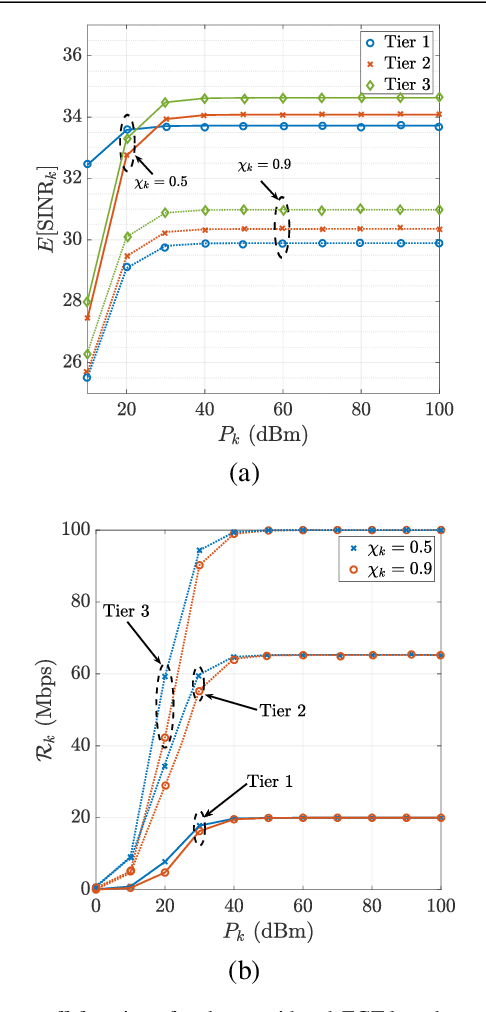
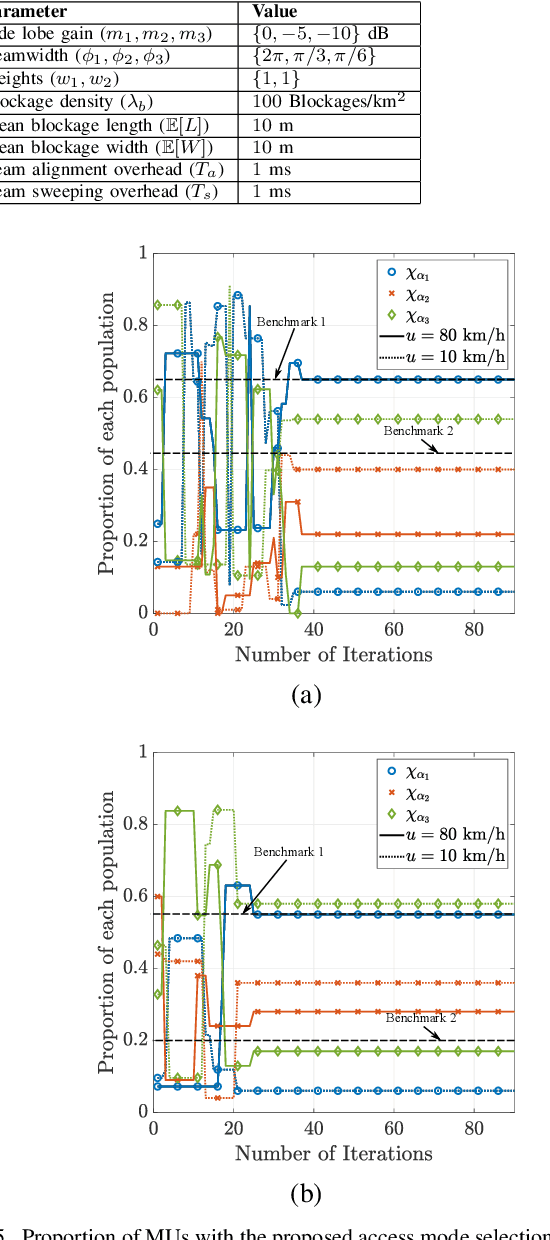
By utilizing the combination of two powerful tools i.e., stochastic geometry (SG) and evolutionary game theory (EGT), in this paper, we study the problem of mobile user (MU) mode selection in heterogeneous sub-$6$ GHz/millimeter wave (mmWave) cellular networks. Particularly, by using SG tools, we first propose an analytical framework to assess the performance of the considered networks in terms of average signal-to-interference-plus-noise (SINR) ratio, average rate, and mobility-induced time overhead, for scenarios with user mobility{.} According to the SG-based framework, an EGT-based approach is presented to solve the problem of access mode selection. Specifically, two EGT-based models are considered, where for each MU its utility function depends on the average SINR and the average rate, respectively, while the time overhead is considered as a penalty term. A distributed algorithm is proposed to reach the evolutionary equilibrium, where the existence and stability of the equilibrium is theoretically analyzed and proved. Moreover, we extend the formulation by considering information delay exchange and evaluate its impact on the convergence of the proposed algorithm. Our results reveal that the proposed technique can offer better spectral efficiency and connectivity in heterogeneous sub-$6$ GHz/mmWave cellular networks with mobility, compared with the conventional access mode selection techniques.
Incompleteness of graph convolutional neural networks for points clouds in three dimensions
Jan 18, 2022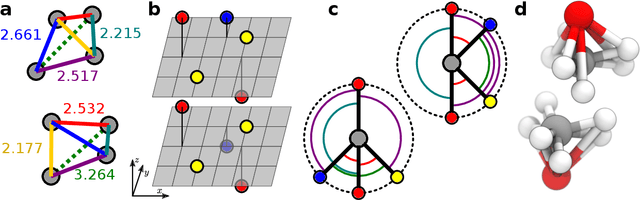
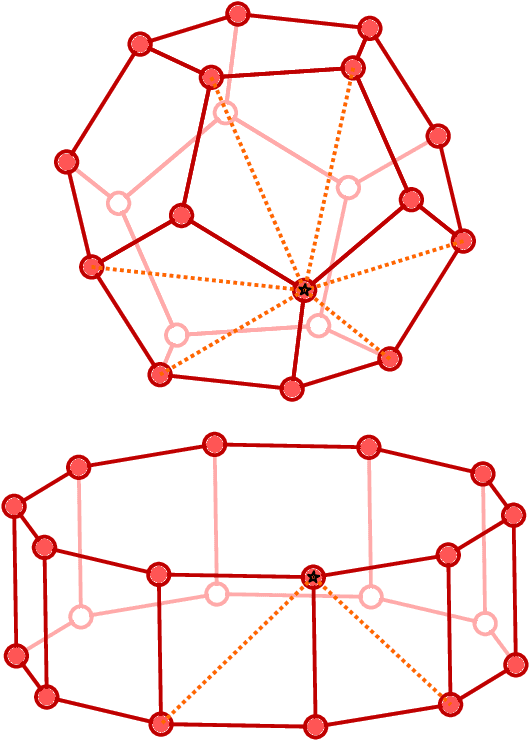
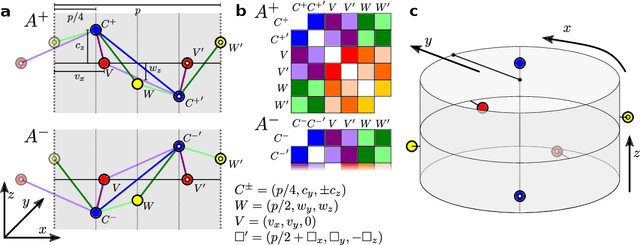
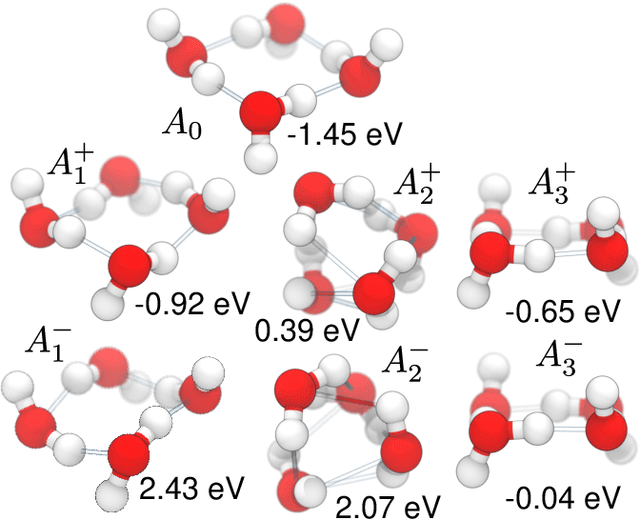
Graph convolutional neural networks (GCNN) are very popular methods in machine learning and have been applied very successfully to the prediction of the properties of molecules and materials. First-order GCNNs are well known to be incomplete, i.e., there exist graphs that are distinct but appear identical when seen through the lens of the GCNN. More complicated schemes have thus been designed to increase their resolving power. Applications to molecules (and more generally, point clouds), however, add a geometric dimension to the problem. The most straightforward and prevalent approach to construct graph representation for the molecules regards atoms as vertices in a graph and draws a bond between each pair of atoms within a certain preselected cutoff. Bonds can be decorated with the distance between atoms, and the resulting "distance graph convolution NNs" (dGCNN) have empirically demonstrated excellent resolving power and are widely used in chemical ML. Here we show that even for the restricted case of graphs induced by 3D atom clouds dGCNNs are not complete. We construct pairs of distinct point clouds that generate graphs that, for any cutoff radius, are equivalent based on a first-order Weisfeiler-Lehman test. This class of degenerate structures includes chemically-plausible configurations, setting an ultimate limit to the expressive power of some of the well-established GCNN architectures for atomistic machine learning. Models that explicitly use angular information in the description of atomic environments can resolve these degeneracies.