 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Amicable examples for informed source separation
Oct 11, 2021
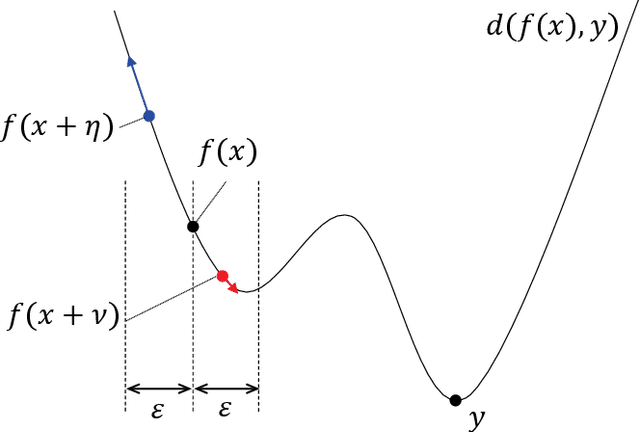
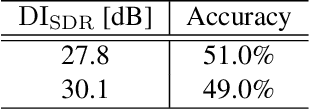
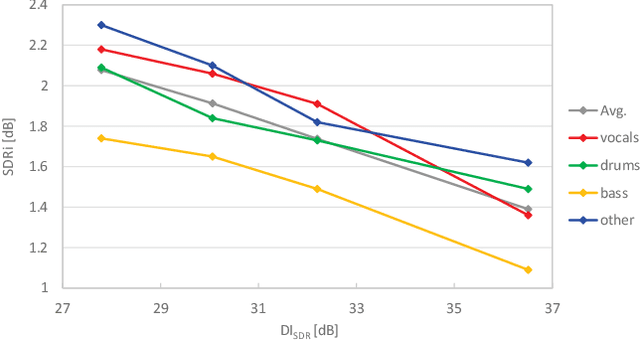
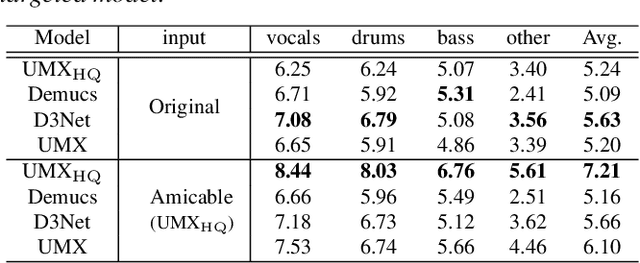
This paper deals with the problem of informed source separation (ISS), where the sources are accessible during the so-called \textit{encoding} stage. Previous works computed side-information during the encoding stage and source separation models were designed to utilize the side-information to improve the separation performance. In contrast, in this work, we improve the performance of a pretrained separation model that does not use any side-information. To this end, we propose to adopt an adversarial attack for the opposite purpose, i.e., rather than computing the perturbation to degrade the separation, we compute an imperceptible perturbation called amicable noise to improve the separation. Experimental results show that the proposed approach selectively improves the performance of the targeted separation model by 2.23 dB on average and is robust to signal compression. Moreover, we propose multi-model multi-purpose learning that control the effect of the perturbation on different models individually.
Query Efficient Decision Based Sparse Attacks Against Black-Box Deep Learning Models
Jan 31, 2022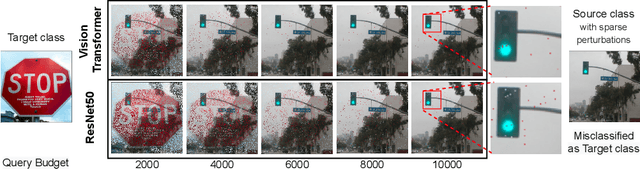

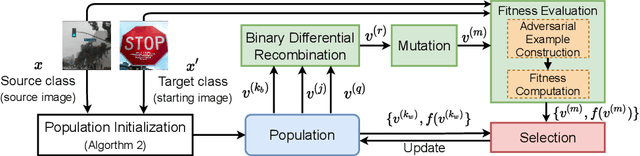
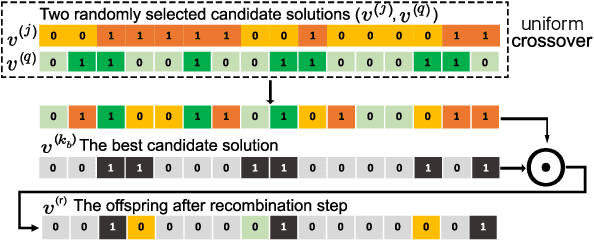
Despite our best efforts, deep learning models remain highly vulnerable to even tiny adversarial perturbations applied to the inputs. The ability to extract information from solely the output of a machine learning model to craft adversarial perturbations to black-box models is a practical threat against real-world systems, such as autonomous cars or machine learning models exposed as a service (MLaaS). Of particular interest are sparse attacks. The realization of sparse attacks in black-box models demonstrates that machine learning models are more vulnerable than we believe. Because these attacks aim to minimize the number of perturbed pixels measured by l_0 norm-required to mislead a model by solely observing the decision (the predicted label) returned to a model query; the so-called decision-based attack setting. But, such an attack leads to an NP-hard optimization problem. We develop an evolution-based algorithm-SparseEvo-for the problem and evaluate against both convolutional deep neural networks and vision transformers. Notably, vision transformers are yet to be investigated under a decision-based attack setting. SparseEvo requires significantly fewer model queries than the state-of-the-art sparse attack Pointwise for both untargeted and targeted attacks. The attack algorithm, although conceptually simple, is also competitive with only a limited query budget against the state-of-the-art gradient-based whitebox attacks in standard computer vision tasks such as ImageNet. Importantly, the query efficient SparseEvo, along with decision-based attacks, in general, raise new questions regarding the safety of deployed systems and poses new directions to study and understand the robustness of machine learning models.
A Game Theoretic Approach for Parking Spot Search with Limited Parking Lot Information
May 11, 2020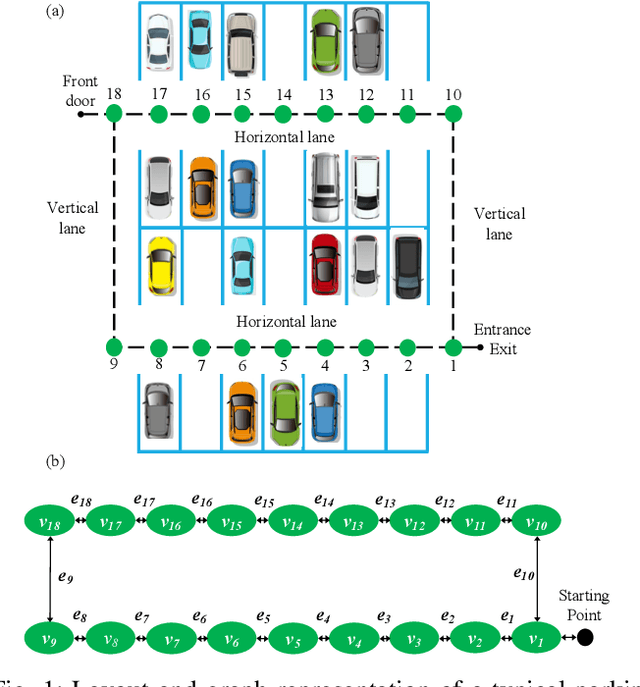
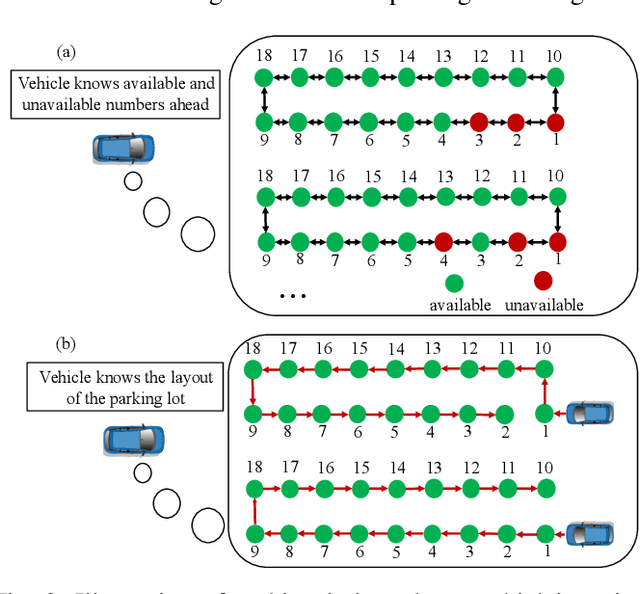


We propose a game theoretic approach to address the problem of searching for available parking spots in a parking lot and picking the ``optimal'' one to park. The approach exploits limited information provided by the parking lot, i.e., its layout and the current number of cars in it. Considering the fact that such information is or can be easily made available for many structured parking lots, the proposed approach can be applicable without requiring major updates to existing parking facilities. For large parking lots, a sampling-based strategy is integrated with the proposed approach to overcome the associated computational challenge. The proposed approach is compared against a state-of-the-art heuristic-based parking spot search strategy in the literature through simulation studies and demonstrates its advantage in terms of achieving lower cost function values.
Cross-Modality Multi-Atlas Segmentation Using Deep Neural Networks
Feb 04, 2022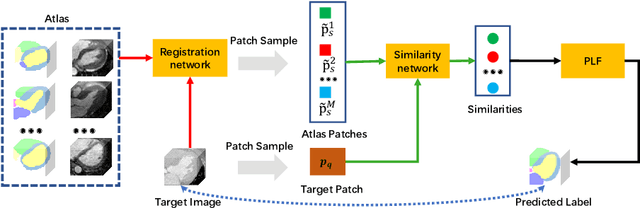
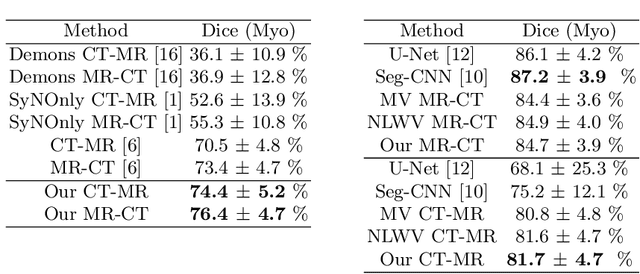
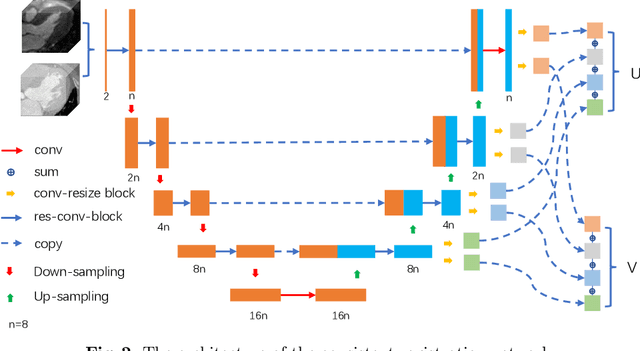
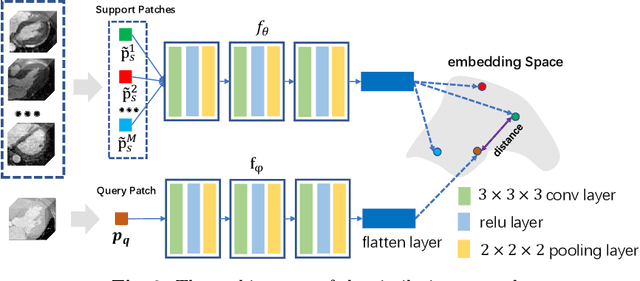
Multi-atlas segmentation (MAS) is a promising framework for medical image segmentation. Generally, MAS methods register multiple atlases, i.e., medical images with corresponding labels, to a target image; and the transformed atlas labels can be combined to generate target segmentation via label fusion schemes. Many conventional MAS methods employed the atlases from the same modality as the target image. However, the number of atlases with the same modality may be limited or even missing in many clinical applications. Besides, conventional MAS methods suffer from the computational burden of registration or label fusion procedures. In this work, we design a novel cross-modality MAS framework, which uses available atlases from a certain modality to segment a target image from another modality. To boost the computational efficiency of the framework, both the image registration and label fusion are achieved by well-designed deep neural networks. For the atlas-to-target image registration, we propose a bi-directional registration network (BiRegNet), which can efficiently align images from different modalities. For the label fusion, we design a similarity estimation network (SimNet), which estimates the fusion weight of each atlas by measuring its similarity to the target image. SimNet can learn multi-scale information for similarity estimation to improve the performance of label fusion. The proposed framework was evaluated by the left ventricle and liver segmentation tasks on the MM-WHS and CHAOS datasets, respectively. Results have shown that the framework is effective for cross-modality MAS in both registration and label fusion. The code will be released publicly on \url{https://github.com/NanYoMy/cmmas} once the manuscript is accepted.
Thompson Sampling with Information Relaxation Penalties
Feb 12, 2019
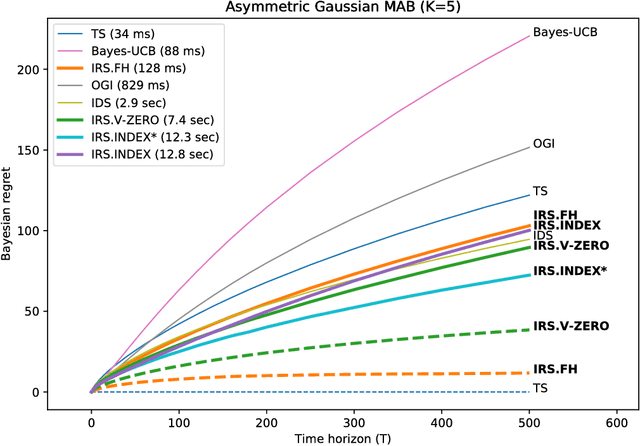
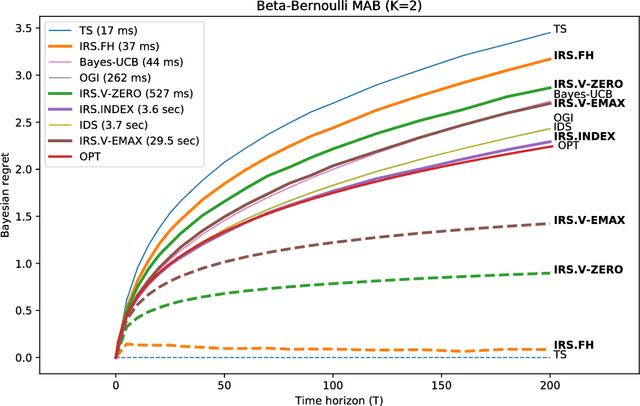
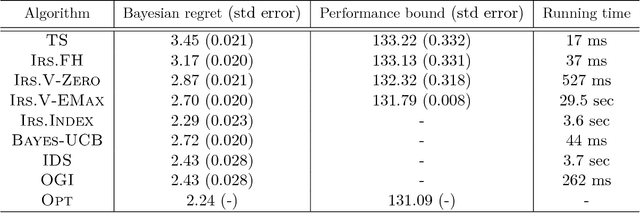
We consider a finite time horizon multi-armed bandit (MAB) problem in a Bayesian framework, for which we develop a general set of control policies that leverage ideas from information relaxations of stochastic dynamic optimization problems. In crude terms, an information relaxation allows the decision maker (DM) to have access to the future (unknown) rewards and incorporate them in her optimization problem to pick an action at time $t$, but penalizes the decision maker for using this information. In our setting, the future rewards allow the DM to better estimate the unknown mean reward parameters of the multiple arms, and optimize her sequence of actions. By picking different information penalties, the DM can construct a family of policies of increasing complexity that, for example, include Thompson Sampling and the true optimal (but intractable) policy as special cases. We systematically develop this framework of information relaxation sampling, propose an intuitive family of control policies for our motivating finite time horizon Bayesian MAB problem, and prove associated structural results and performance bounds. Numerical experiments suggest that this new class of policies performs well, in particular in settings where the finite time horizon introduces significant tension in the problem. Finally, inspired by the finite time horizon Gittins index, we propose an index policy that builds on our framework that particularly outperforms to the state-of-the-art algorithms in our numerical experiments.
Training Fair Deep Neural Networks by Balancing Influence
Jan 15, 2022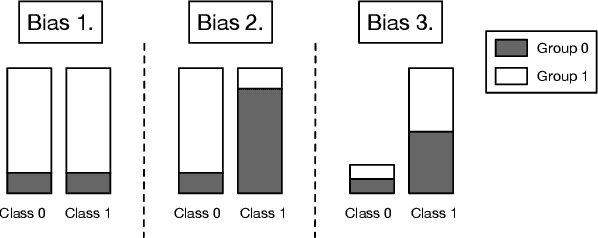
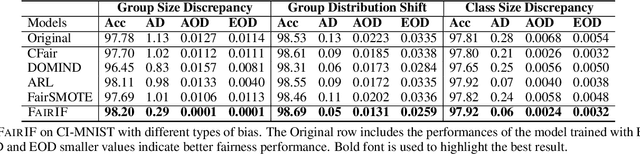
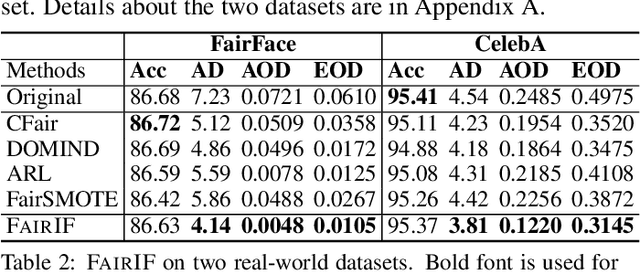

Most fair machine learning methods either highly rely on the sensitive information of the training samples or require a large modification on the target models, which hinders their practical application. To address this issue, we propose a two-stage training algorithm named FAIRIF. It minimizes the loss over the reweighted data set (second stage) where the sample weights are computed to balance the model performance across different demographic groups (first stage). FAIRIF can be applied on a wide range of models trained by stochastic gradient descent without changing the model, while only requiring group annotations on a small validation set to compute sample weights. Theoretically, we show that, in the classification setting, three notions of disparity among different groups can be mitigated by training with the weights. Experiments on synthetic data sets demonstrate that FAIRIF yields models with better fairness-utility trade-offs against various types of bias; and on real-world data sets, we show the effectiveness and scalability of FAIRIF. Moreover, as evidenced by the experiments with pretrained models, FAIRIF is able to alleviate the unfairness issue of pretrained models without hurting their performance.
TransFGU: A Top-down Approach to Fine-Grained Unsupervised Semantic Segmentation
Dec 02, 2021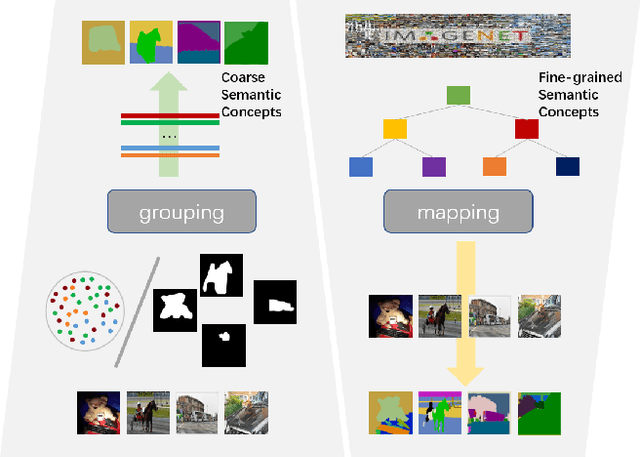
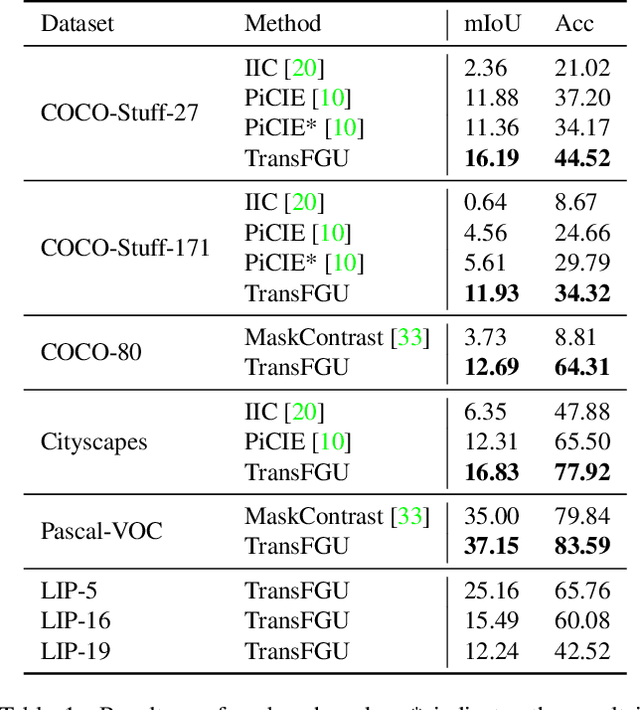
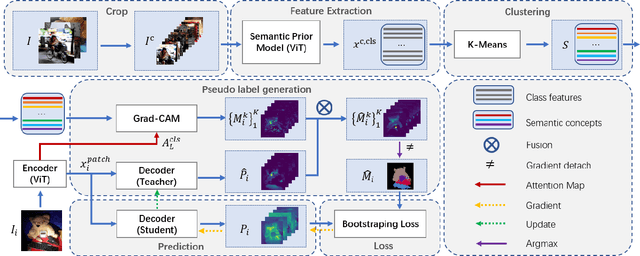
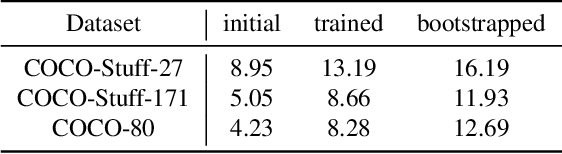
Unsupervised semantic segmentation aims to obtain high-level semantic representation on low-level visual features without manual annotations. Most existing methods are bottom-up approaches that try to group pixels into regions based on their visual cues or certain predefined rules. As a result, it is difficult for these bottom-up approaches to generate fine-grained semantic segmentation when coming to complicated scenes with multiple objects and some objects sharing similar visual appearance. In contrast, we propose the first top-down unsupervised semantic segmentation framework for fine-grained segmentation in extremely complicated scenarios. Specifically, we first obtain rich high-level structured semantic concept information from large-scale vision data in a self-supervised learning manner, and use such information as a prior to discover potential semantic categories presented in target datasets. Secondly, the discovered high-level semantic categories are mapped to low-level pixel features by calculating the class activate map (CAM) with respect to certain discovered semantic representation. Lastly, the obtained CAMs serve as pseudo labels to train the segmentation module and produce final semantic segmentation. Experimental results on multiple semantic segmentation benchmarks show that our top-down unsupervised segmentation is robust to both object-centric and scene-centric datasets under different semantic granularity levels, and outperforms all the current state-of-the-art bottom-up methods. Our code is available at \url{https://github.com/damo-cv/TransFGU}.
Hybrid Reinforcement Learning-Based Eco-Driving Strategy for Connected and Automated Vehicles at Signalized Intersections
Jan 28, 2022
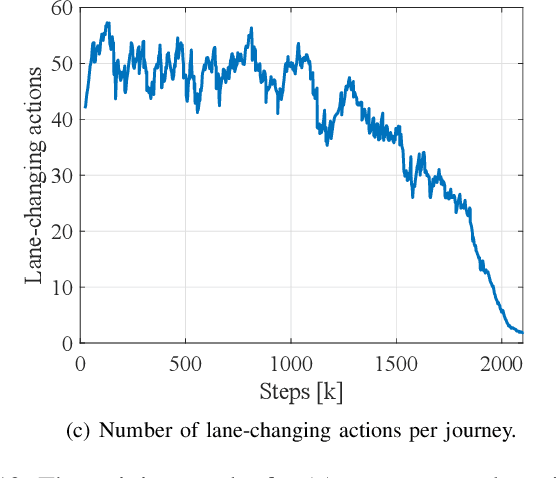
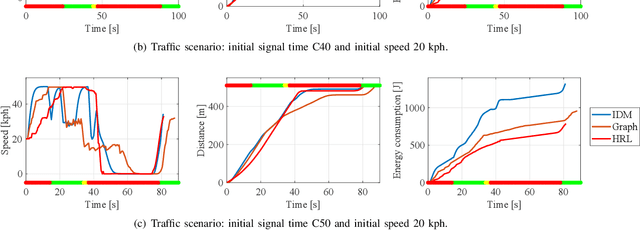
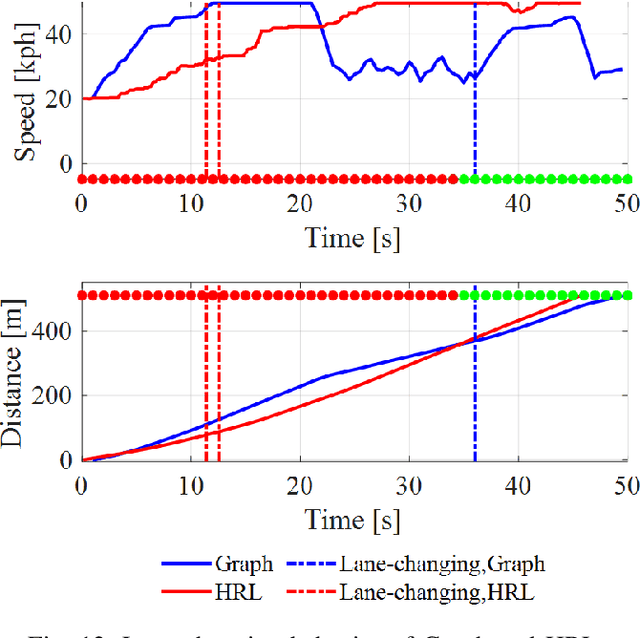
Taking advantage of both vehicle-to-everything (V2X) communication and automated driving technology, connected and automated vehicles are quickly becoming one of the transformative solutions to many transportation problems. However, in a mixed traffic environment at signalized intersections, it is still a challenging task to improve overall throughput and energy efficiency considering the complexity and uncertainty in the traffic system. In this study, we proposed a hybrid reinforcement learning (HRL) framework which combines the rule-based strategy and the deep reinforcement learning (deep RL) to support connected eco-driving at signalized intersections in mixed traffic. Vision-perceptive methods are integrated with vehicle-to-infrastructure (V2I) communications to achieve higher mobility and energy efficiency in mixed connected traffic. The HRL framework has three components: a rule-based driving manager that operates the collaboration between the rule-based policies and the RL policy; a multi-stream neural network that extracts the hidden features of vision and V2I information; and a deep RL-based policy network that generate both longitudinal and lateral eco-driving actions. In order to evaluate our approach, we developed a Unity-based simulator and designed a mixed-traffic intersection scenario. Moreover, several baselines were implemented to compare with our new design, and numerical experiments were conducted to test the performance of the HRL model. The experiments show that our HRL method can reduce energy consumption by 12.70% and save 11.75% travel time when compared with a state-of-the-art model-based Eco-Driving approach.
Edge-Enhanced Global Disentangled Graph Neural Network for Sequential Recommendation
Nov 23, 2021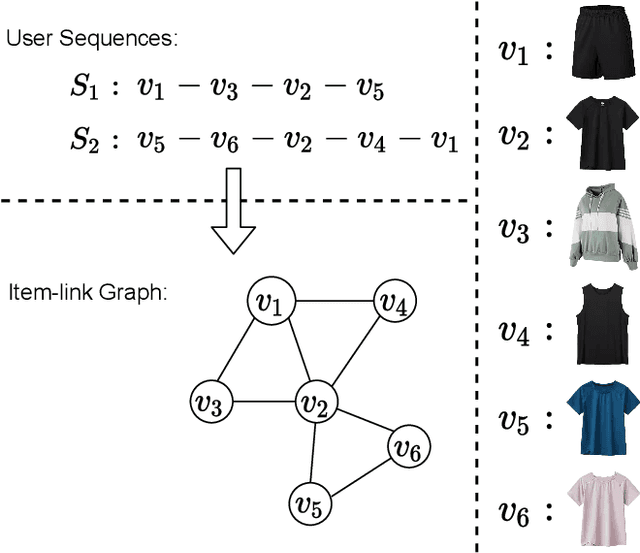
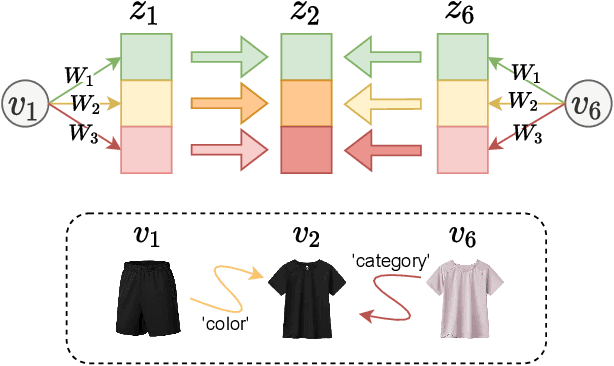
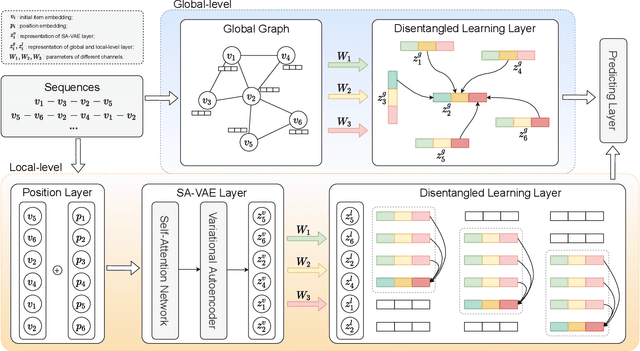
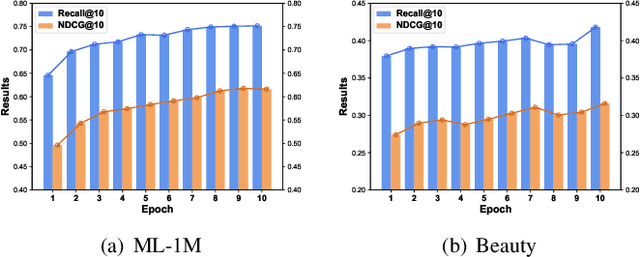
Sequential recommendation has been a widely popular topic of recommender systems. Existing works have contributed to enhancing the prediction ability of sequential recommendation systems based on various methods, such as recurrent networks and self-attention mechanisms. However, they fail to discover and distinguish various relationships between items, which could be underlying factors which motivate user behaviors. In this paper, we propose an Edge-Enhanced Global Disentangled Graph Neural Network (EGD-GNN) model to capture the relation information between items for global item representation and local user intention learning. At the global level, we build a global-link graph over all sequences to model item relationships. Then a channel-aware disentangled learning layer is designed to decompose edge information into different channels, which can be aggregated to represent the target item from its neighbors. At the local level, we apply a variational auto-encoder framework to learn user intention over the current sequence. We evaluate our proposed method on three real-world datasets. Experimental results show that our model can get a crucial improvement over state-of-the-art baselines and is able to distinguish item features.
A Mutual Information Maximization Perspective of Language Representation Learning
Oct 18, 2019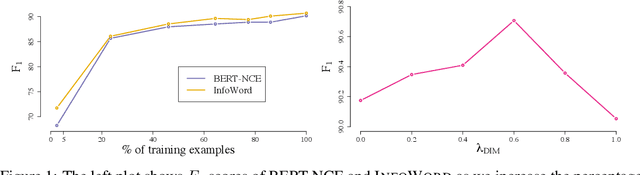
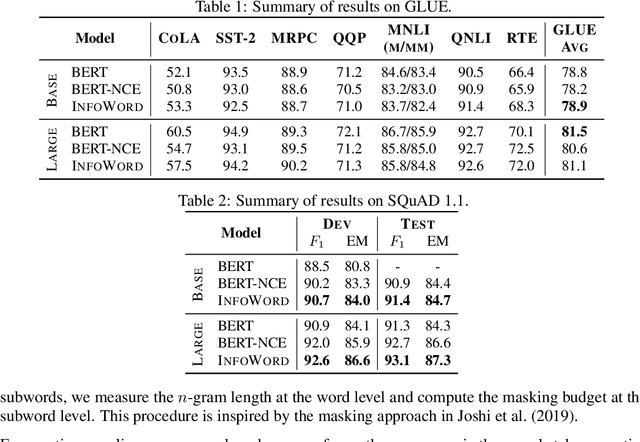
We show state-of-the-art word representation learning methods maximize an objective function that is a lower bound on the mutual information between different parts of a word sequence (i.e., a sentence). Our formulation provides an alternative perspective that unifies classical word embedding models (e.g., Skip-gram) and modern contextual embeddings (e.g., BERT, XLNet). In addition to enhancing our theoretical understanding of these methods, our derivation leads to a principled framework that can be used to construct new self-supervised tasks. We provide an example by drawing inspirations from related methods based on mutual information maximization that have been successful in computer vision, and introduce a simple self-supervised objective that maximizes the mutual information between a global sentence representation and n-grams in the sentence. Our analysis offers a holistic view of representation learning methods to transfer knowledge and translate progress across multiple domains (e.g., natural language processing, computer vision, audio processing).