 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A novel approach to sentiment analysis in Persian using discourse and external semantic information
Jul 18, 2020
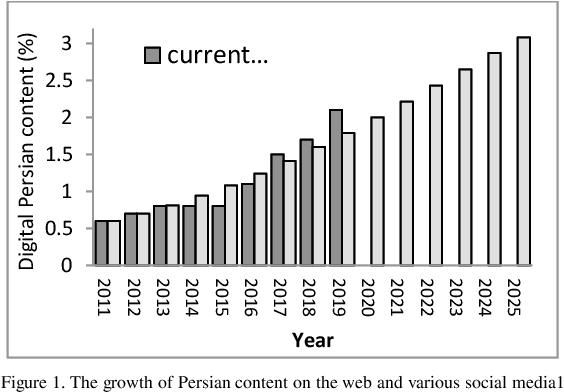
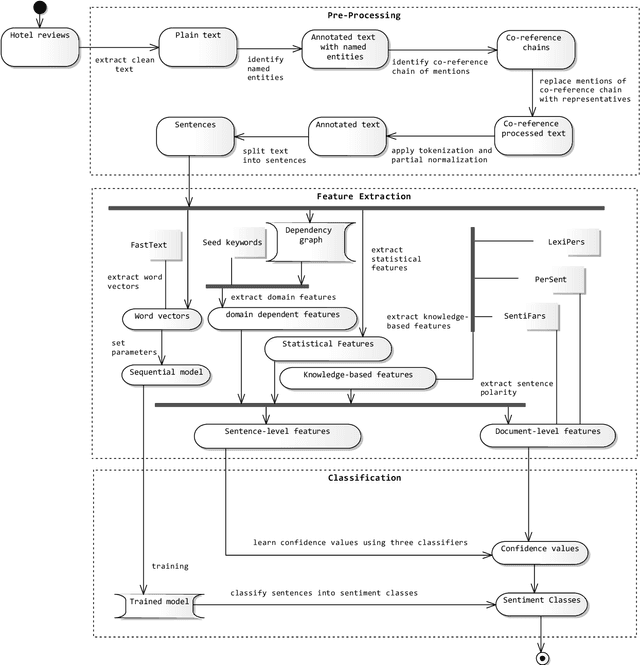
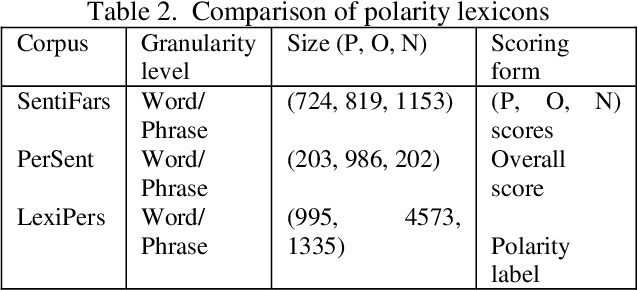
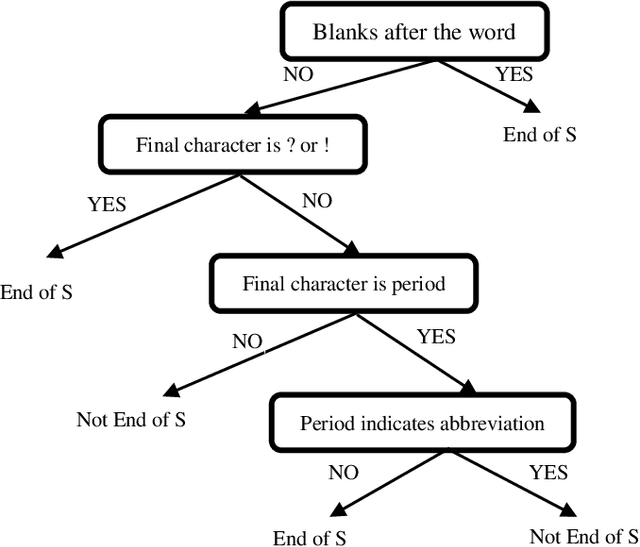
Sentiment analysis attempts to identify, extract and quantify affective states and subjective information from various types of data such as text, audio, and video. Many approaches have been proposed to extract the sentiment of individuals from documents written in natural languages in recent years. The majority of these approaches have focused on English, while resource-lean languages such as Persian suffer from the lack of research work and language resources. Due to this gap in Persian, the current work is accomplished to introduce new methods for sentiment analysis which have been applied on Persian. The proposed approach in this paper is two-fold: The first one is based on classifier combination, and the second one is based on deep neural networks which benefits from word embedding vectors. Both approaches takes advantage of local discourse information and external knowledge bases, and also cover several language issues such as negation and intensification, andaddresses different granularity levels, namely word, aspect, sentence, phrase and document-levels. To evaluate the performance of the proposed approach, a Persian dataset is collected from Persian hotel reviews referred as hotel reviews. The proposed approach has been compared to counterpart methods based on the benchmark dataset. The experimental results approve the effectiveness of the proposed approach when compared to related works.
Deep Image Matting with Flexible Guidance Input
Oct 21, 2021
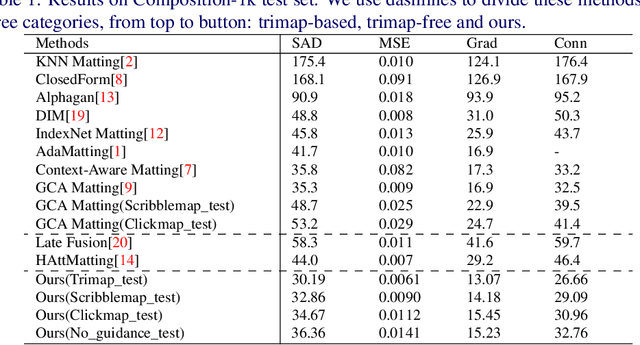
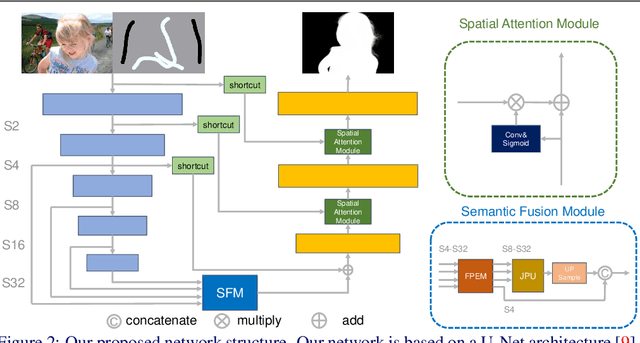

Image matting is an important computer vision problem. Many existing matting methods require a hand-made trimap to provide auxiliary information, which is very expensive and limits the real world usage. Recently, some trimap-free methods have been proposed, which completely get rid of any user input. However, their performance lag far behind trimap-based methods due to the lack of guidance information. In this paper, we propose a matting method that use Flexible Guidance Input as user hint, which means our method can use trimap, scribblemap or clickmap as guidance information or even work without any guidance input. To achieve this, we propose Progressive Trimap Deformation(PTD) scheme that gradually shrink the area of the foreground and background of the trimap with the training step increases and finally become a scribblemap. To make our network robust to any user scribble and click, we randomly sample points on foreground and background and perform curve fitting. Moreover, we propose Semantic Fusion Module(SFM) which utilize the Feature Pyramid Enhancement Module(FPEM) and Joint Pyramid Upsampling(JPU) in matting task for the first time. The experiments show that our method can achieve state-of-the-art results comparing with existing trimap-based and trimap-free methods.
Task Oriented Channel State Information Quantization
Apr 02, 2019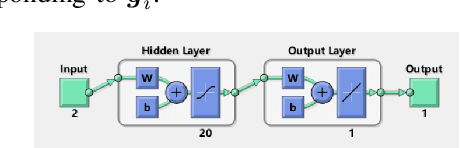
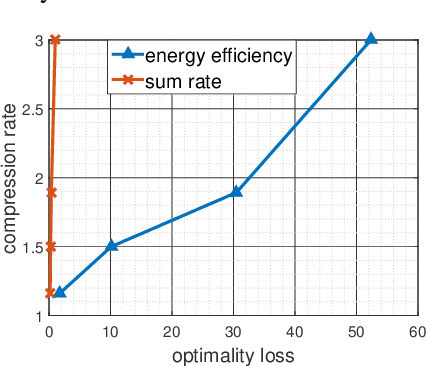
In this paper, we propose a new perspective for quantizing a signal and more specifically the channel state information (CSI). The proposed point of view is fully relevant for a receiver which has to send a quantized version of the channel state to the transmitter. Roughly, the key idea is that the receiver sends the right amount of information to the transmitter so that the latter be able to take its (resource allocation) decision. More formally, the decision task of the transmitter is to maximize an utility function u(x;g) with respect to x (e.g., a power allocation vector) given the knowledge of a quantized version of the function parameters g. We exhibit a special case of an energy-efficient power control (PC) problem for which the optimal task oriented CSI quantizer (TOCQ) can be found analytically. For more general utility functions, we propose to use neural networks (NN) based learning. Simulations show that the compression rate obtained by adapting the feedback information rate to the function to be optimized may be significantly increased.
* 2 pages, 2 figures
Generating Rich Product Descriptions for Conversational E-commerce Systems
Nov 30, 2021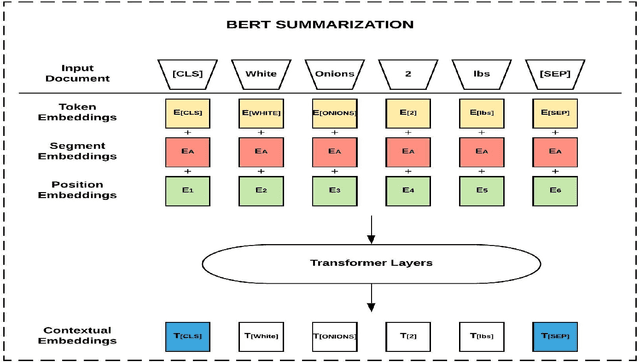

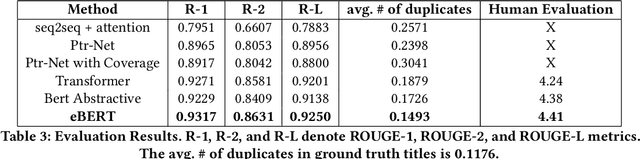
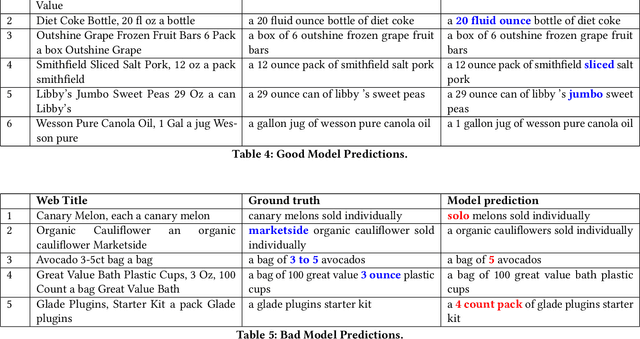
Through recent advancements in speech technologies and introduction of smart assistants, such as Amazon Alexa, Apple Siri and Google Home, increasing number of users are interacting with various applications through voice commands. E-commerce companies typically display short product titles on their webpages, either human-curated or algorithmically generated, when brevity is required. However, these titles are dissimilar from natural spoken language. For example, "Lucky Charms Gluten Free Break-fast Cereal, 20.5 oz a box Lucky Charms Gluten Free" is acceptable to display on a webpage, while a similar title cannot be used in a voice based text-to-speech application. In such conversational systems, an easy to comprehend sentence, such as "a 20.5 ounce box of lucky charms gluten free cereal" is preferred. Compared to display devices, where images and detailed product information can be presented to users, short titles for products which convey the most important information, are necessary when interfacing with voice assistants. We propose eBERT, a sequence-to-sequence approach by further pre-training the BERT embeddings on an e-commerce product description corpus, and then fine-tuning the resulting model to generate short, natural, spoken language titles from input web titles. Our extensive experiments on a real-world industry dataset, as well as human evaluation of model output, demonstrate that eBERT summarization outperforms comparable baseline models. Owing to the efficacy of the model, a version of this model has been deployed in real-world setting.
* 8 pages, 1 figure. arXiv admin note: substantial text overlap with arXiv:2007.11768
Deep Learning Based Near-OrthogonalSuperposition Code for Short Message Transmission
Nov 05, 2021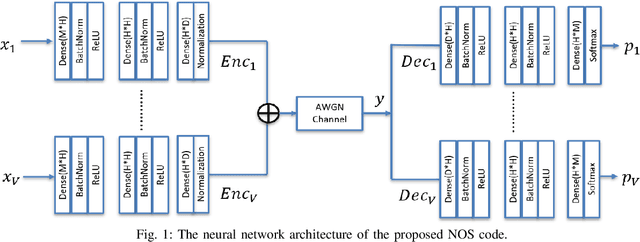
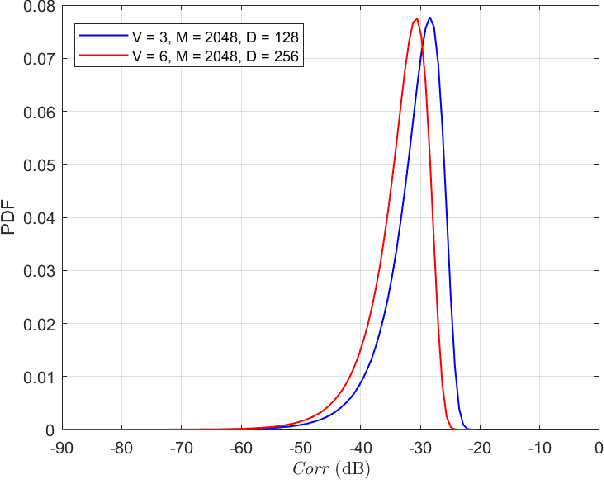
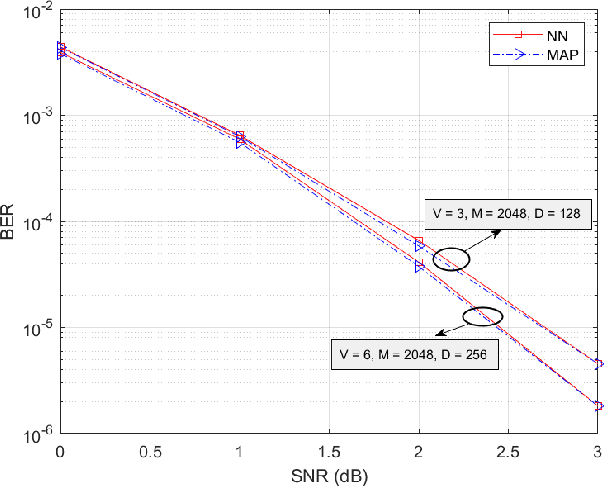
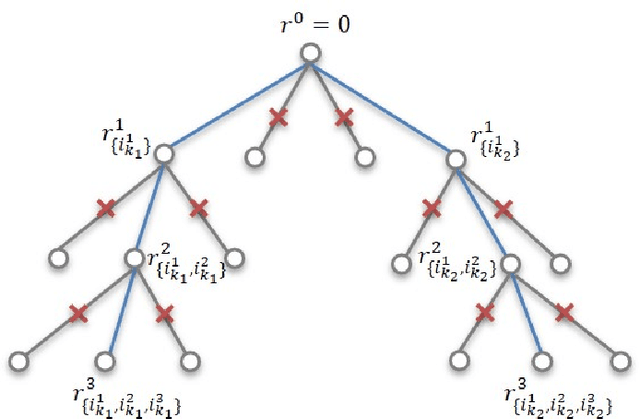
Massive machine type communication (mMTC) hasattracted new coding schemes optimized for reliable short mes-sage transmission. In this paper, a novel deep learning basednear-orthogonal superposition (NOS) coding scheme is proposedfor reliable transmission of short messages in the additive whiteGaussian noise (AWGN) channel for mMTC applications. Sim-ilar to recent hyper-dimensional modulation (HDM), the NOSencoder spreads the information bits to multiple near-orthogonalhigh dimensional vectors to be combined (superimposed) into asingle vector for transmission. The NOS decoder first estimatesthe information vectors and then performs a cyclic redundancycheck (CRC)-assistedK-best tree-search algorithm to furtherreduce the packet error rate. The proposed NOS encoder anddecoder are deep neural networks (DNNs) jointly trained asan auto-encoder and decoder pair to learn a new NOS codingscheme with near-orthogonal codewords. Simulation results showthe proposed deep learning-based NOS scheme outperformsHDM and Polar code with CRC-aided list decoding for short(32-bit) message transmission.
A Cross-Level Information Transmission Network for Predicting Phenotype from New Genotype: Application to Cancer Precision Medicine
Oct 09, 2020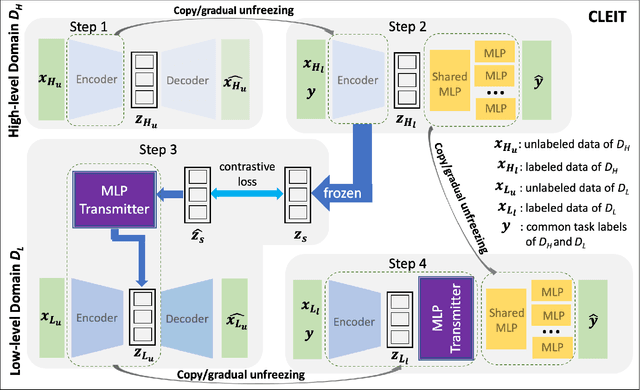
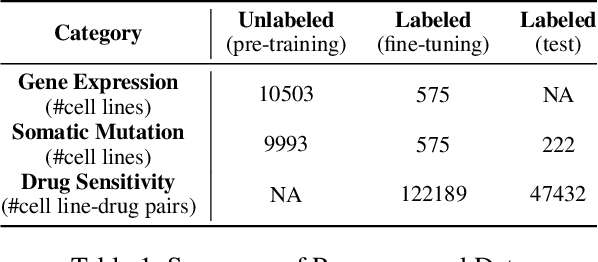
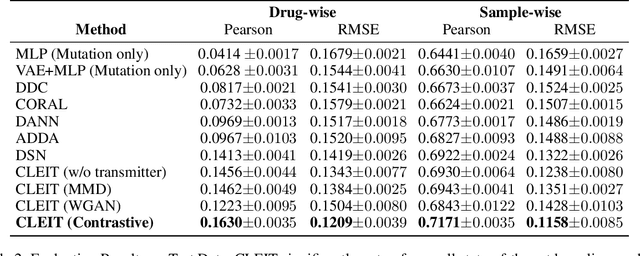
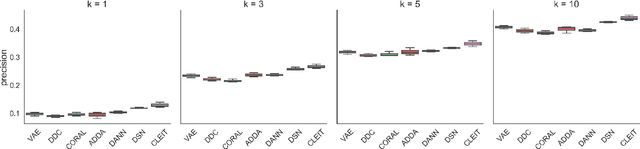
An unsolved fundamental problem in biology and ecology is to predict observable traits (phenotypes) from a new genetic constitution (genotype) of an organism under environmental perturbations (e.g., drug treatment). The emergence of multiple omics data provides new opportunities but imposes great challenges in the predictive modeling of genotype-phenotype associations. Firstly, the high-dimensionality of genomics data and the lack of labeled data often make the existing supervised learning techniques less successful. Secondly, it is a challenging task to integrate heterogeneous omics data from different resources. Finally, the information transmission from DNA to phenotype involves multiple intermediate levels of RNA, protein, metabolite, etc. The higher-level features (e.g., gene expression) usually have stronger discriminative power than the lower level features (e.g., somatic mutation). To address above issues, we proposed a novel Cross-LEvel Information Transmission network (CLEIT) framework. CLEIT aims to explicitly model the asymmetrical multi-level organization of the biological system. Inspired by domain adaptation, CLEIT first learns the latent representation of high-level domain then uses it as ground-truth embedding to improve the representation learning of the low-level domain in the form of contrastive loss. In addition, we adopt a pre-training-fine-tuning approach to leveraging the unlabeled heterogeneous omics data to improve the generalizability of CLEIT. We demonstrate the effectiveness and performance boost of CLEIT in predicting anti-cancer drug sensitivity from somatic mutations via the assistance of gene expressions when compared with state-of-the-art methods.
Search for temporal cell segmentation robustness in phase-contrast microscopy videos
Dec 16, 2021Studying cell morphology changes in time is critical to understanding cell migration mechanisms. In this work, we present a deep learning-based workflow to segment cancer cells embedded in 3D collagen matrices and imaged with phase-contrast microscopy. Our approach uses transfer learning and recurrent convolutional long-short term memory units to exploit the temporal information from the past and provide a consistent segmentation result. Lastly, we propose a geometrical-characterization approach to studying cancer cell morphology. Our approach provides stable results in time, and it is robust to the different weight initialization or training data sampling. We introduce a new annotated dataset for 2D cell segmentation and tracking, and an open-source implementation to replicate the experiments or adapt them to new image processing problems.
Narrative Maps: An Algorithmic Approach to Represent and Extract Information Narratives
Sep 09, 2020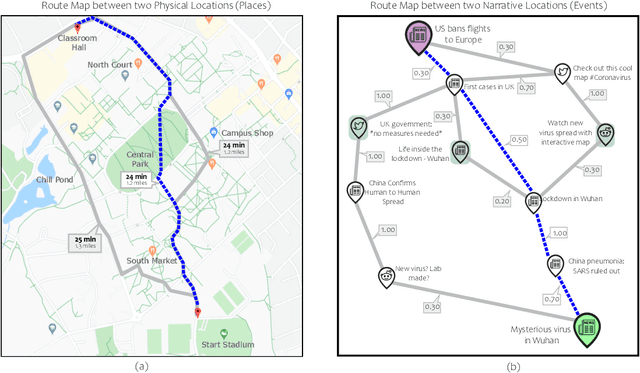
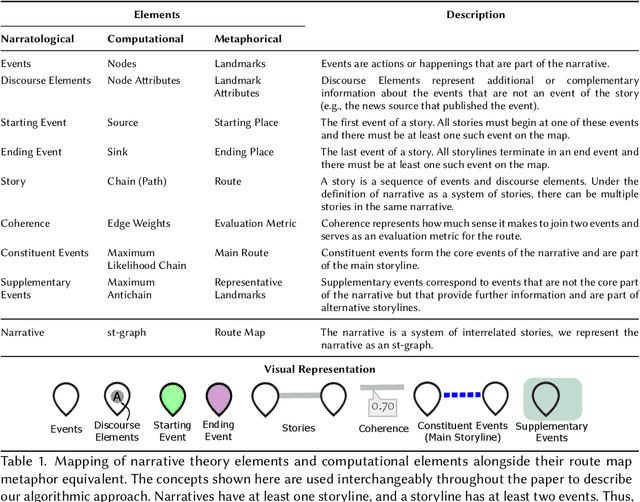
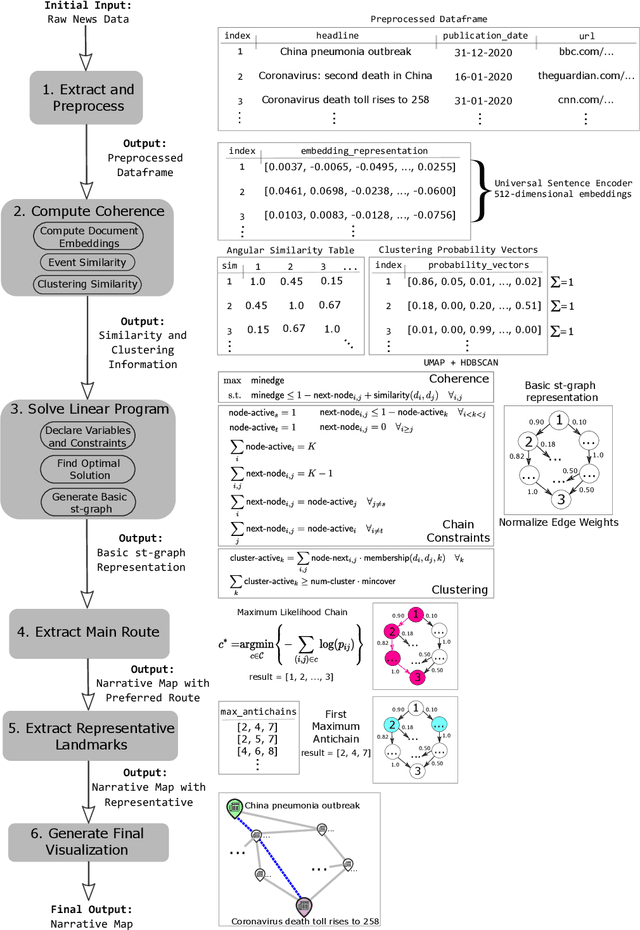
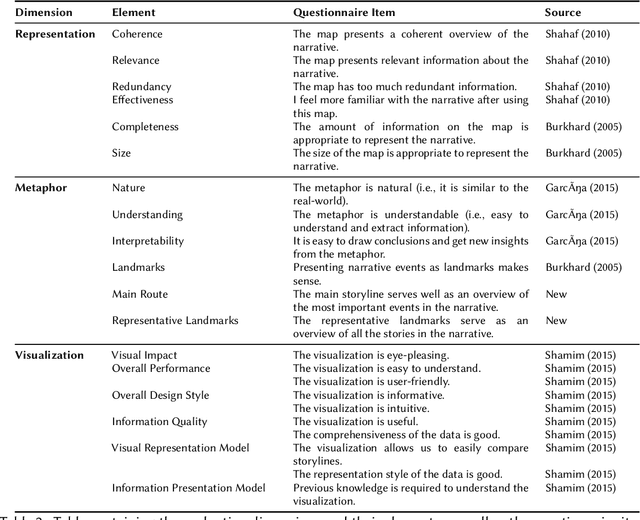
Narratives are fundamental to our perception of the world and are pervasive in all activities that involve the representation of events in time. Yet, modern online information systems do not incorporate narratives in their representation of events occurring over time. This article aims to bridge this gap, combining the theory of narrative representations with the data from modern online systems. We make three key contributions: a theory-driven computational representation of narratives, a novel extraction algorithm to obtain these representations from data, and an evaluation of our approach. In particular, given the effectiveness of visual metaphors, we employ a route map metaphor to design a narrative map representation. The narrative map representation illustrates the events and stories in the narrative as a series of landmarks and routes on the map. Each element of our representation is backed by a corresponding element from formal narrative theory, thus providing a solid theoretical background to our method. Our approach extracts the underlying graph structure of the narrative map using a novel optimization technique focused on maximizing coherence while respecting structural and coverage constraints. We showcase the effectiveness of our approach by performing a user evaluation to assess the quality of the representation, metaphor, and visualization. Evaluation results indicate that the Narrative Map representation is a powerful method to communicate complex narratives to individuals. Our findings have implications for intelligence analysts, computational journalists, and misinformation researchers.
LaMDA: Language Models for Dialog Applications
Jan 21, 2022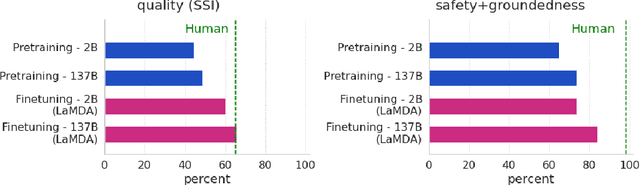
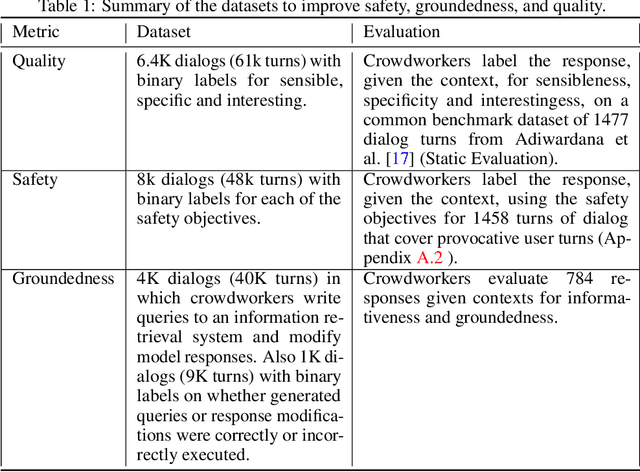

We present LaMDA: Language Models for Dialog Applications. LaMDA is a family of Transformer-based neural language models specialized for dialog, which have up to 137B parameters and are pre-trained on 1.56T words of public dialog data and web text. While model scaling alone can improve quality, it shows less improvements on safety and factual grounding. We demonstrate that fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards the two key challenges of safety and factual grounding. The first challenge, safety, involves ensuring that the model's responses are consistent with a set of human values, such as preventing harmful suggestions and unfair bias. We quantify safety using a metric based on an illustrative set of human values, and we find that filtering candidate responses using a LaMDA classifier fine-tuned with a small amount of crowdworker-annotated data offers a promising approach to improving model safety. The second challenge, factual grounding, involves enabling the model to consult external knowledge sources, such as an information retrieval system, a language translator, and a calculator. We quantify factuality using a groundedness metric, and we find that our approach enables the model to generate responses grounded in known sources, rather than responses that merely sound plausible. Finally, we explore the use of LaMDA in the domains of education and content recommendations, and analyze their helpfulness and role consistency.
Optimal Transmit Beamforming for Secrecy Integrated Sensing and Communication
Oct 25, 2021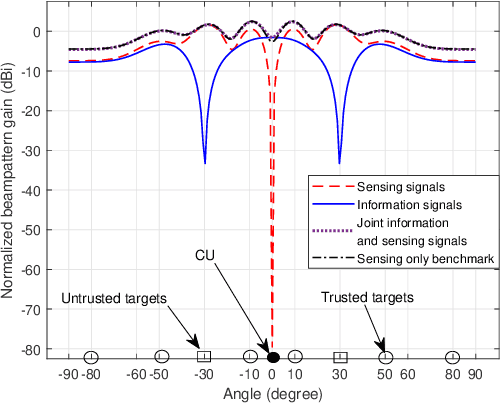
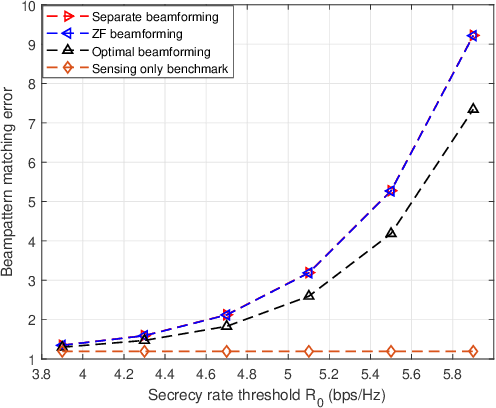
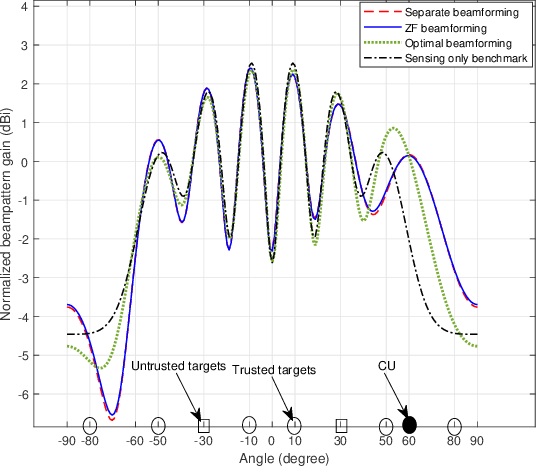
This paper studies a secrecy integrated sensing and communication (ISAC) system, in which a multi-antenna base station (BS) aims to send confidential messages to a single-antenna communication user (CU), and at the same time sense several targets that may be suspicious eavesdroppers. To ensure the sensing quality while preventing the eavesdropping, we consider that the BS sends dedicated sensing signals (in addition to confidential information signals) that play a dual role of artificial noise (AN) for confusing the eavesdropping targets. Under this setup, we jointly optimize the transmit information and sensing beamforming at the BS, to minimize the matching error between the transmit beampattern and a desired beampattern for sensing, subject to the minimum secrecy rate requirement at the CU and the transmit power constraint at the BS. Although the formulated problem is non-convex, we propose an algorithm to obtain the globally optimal solution by using the semidefinite relaxation (SDR) together with a one-dimensional (1D) search. Next, to avoid the high complexity induced by the 1D search, we also present two sub-optimal solutions based on zero-forcing and separate beamforming designs, respectively. Numerical results show that the proposed designs properly adjust the information and sensing beams to balance the tradeoffs among communicating with CU, sensing targets, and confusing eavesdroppers, thus achieving desirable transmit beampattern for sensing while ensuring the CU's secrecy rate.