 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On Information Gain and Regret Bounds in Gaussian Process Bandits
Sep 15, 2020


Consider the sequential optimization of an unknown, expensive to evaluate and possibly non-convex objective function $f$ from noisy observations which can be considered as a continuum-armed bandit problem. Bayesian optimization algorithms based on Gaussian Process (GP) models are shown to perform favorably in this setting. In particular, upper bounds are proven on the regret performance of two popular algorithms $-$ GP-UCB and GP-TS $-$ under both Bayesian (when $f$ is a sample from a GP) and frequentist (when $f$ lives in a reproducing kernel Hilbert space) settings. The regret bounds crucially depend on a quantity referred to as the maximal information gain $\gamma_T$ between $T(\in \mathbb{N})$ observations and the underlying GP (surrogate) model. In this paper, we build on the spectral properties of positive definite kernels to prove novel bounds on $\gamma_T$. In comparison to the existing works which rely on specific kernels (such as Mat\'ern and SE) to provide explicit bounds on $\gamma_T$ and regret, we provide general results in terms of the decay rate of the eigenvalues of the kernel. Specialising our results for common kernels leads to significant improvements over the existing bounds on $\gamma_T$ and regret. For the Mat\'ern and SE kernels, where the lower bounds on regret are known, our results reduce the gap between the upper and lower bounds from a polynomial in $T$ factor, in the existing work, to a logarithmic one, under the Bayesian setting. Furthermore, since our bounds on $\gamma_T$ are independent of the optimisation algorithm, they impact the regret bounds under various other settings where $\gamma_T$ is essential.
Finite State Markov Modeling of C-V2X Erasure Links For Performance and Stability Analysis of Platooning Applications
Nov 13, 2021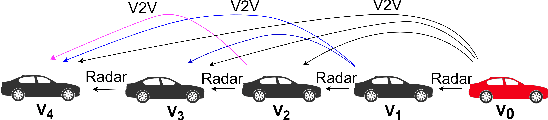
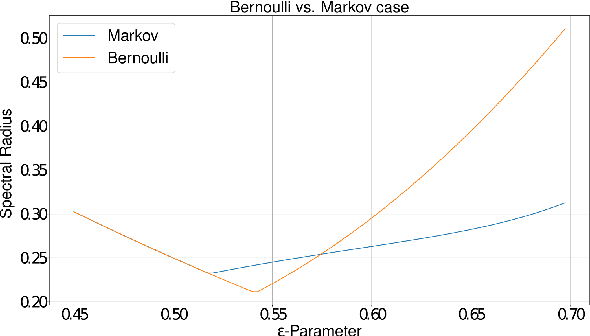
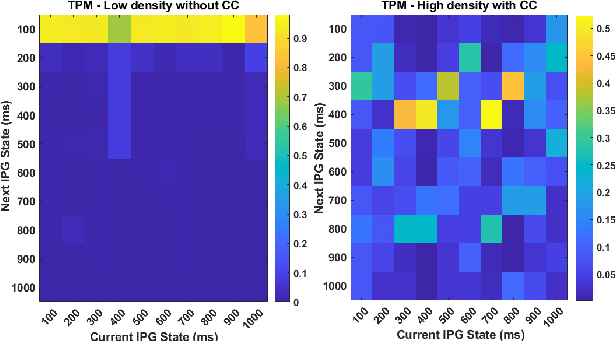
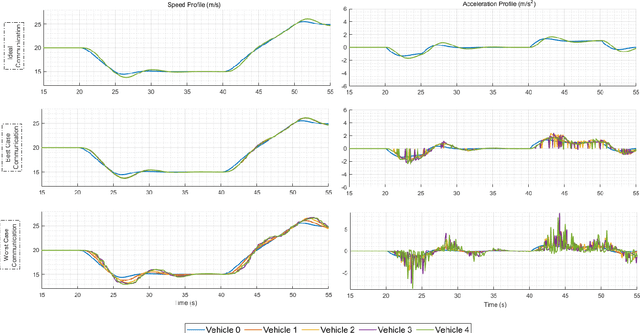
Cooperative driving systems, such as platooning, rely on communication and information exchange to create situational awareness for each agent. Design and performance of control components are therefore tightly coupled with communication component performance. The information flow between vehicles can significantly affect the dynamics of a platoon. Therefore, both the performance and the stability of a platoon depend not only on the vehicle's controller but also on the information flow Topology (IFT). The IFT can cause limitations for certain platoon properties, i.e., stability and scalability. Cellular Vehicle-To-Everything (C-V2X) has emerged as one of the main communication technologies to support connected and automated vehicle applications. As a result of packet loss, wireless channels create random link interruption and changes in network topologies. In this paper, we model the communication links between vehicles with a first-order Markov model to capture the prevalent time correlations for each link. These models enable performance evaluation through better approximation of communication links during system design stages. Our approach is to use data from experiments to model the Inter-Packet Gap (IPG) using Markov chains and derive transition probability matrices for consecutive IPG states. Training data is collected from high fidelity simulations using models derived based on empirical data for a variety of different vehicle densities and communication rates. Utilizing the IPG models, we analyze the mean-square stability of a platoon of vehicles with the standard consensus protocol tuned for ideal communication and compare the degradation in performance for different scenarios.
Collaborative Information Bottleneck
Nov 17, 2017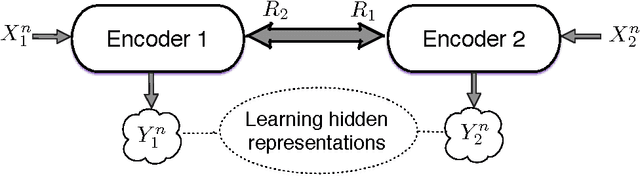
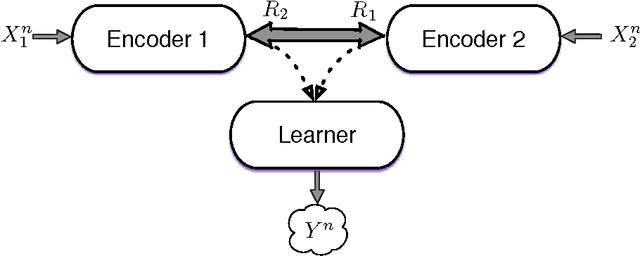
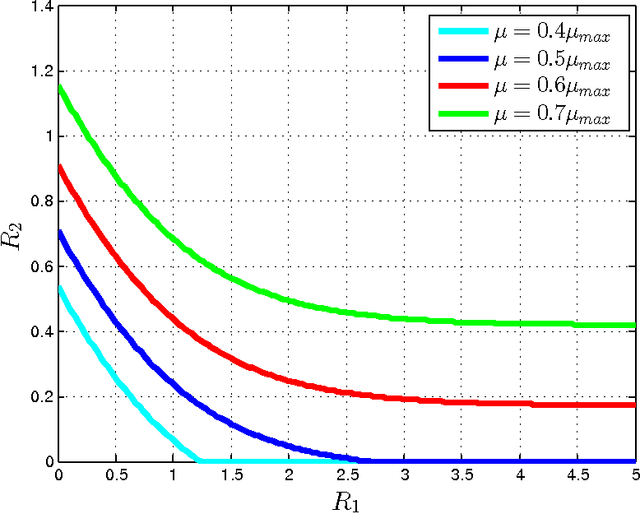
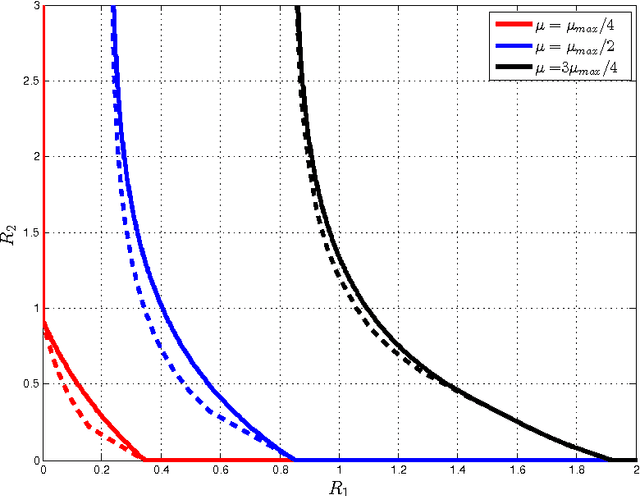
This paper investigates a multi-terminal source coding problem under a logarithmic loss fidelity which does not necessarily lead to an additive distortion measure. The problem is motivated by an extension of the Information Bottleneck method to a multi-source scenario where several encoders have to build cooperatively rate-limited descriptions of their sources in order to maximize information with respect to other unobserved (hidden) sources. More precisely, we study fundamental information-theoretic limits of the so-called: (i) Two-way Collaborative Information Bottleneck (TW-CIB) and (ii) the Collaborative Distributed Information Bottleneck (CDIB) problems. The TW-CIB problem consists of two distant encoders that separately observe marginal (dependent) components $X_1$ and $X_2$ and can cooperate through multiple exchanges of limited information with the aim of extracting information about hidden variables $(Y_1,Y_2)$, which can be arbitrarily dependent on $(X_1,X_2)$. On the other hand, in CDIB there are two cooperating encoders which separately observe $X_1$ and $X_2$ and a third node which can listen to the exchanges between the two encoders in order to obtain information about a hidden variable $Y$. The relevance (figure-of-merit) is measured in terms of a normalized (per-sample) multi-letter mutual information metric (log-loss fidelity) and an interesting tradeoff arises by constraining the complexity of descriptions, measured in terms of the rates needed for the exchanges between the encoders and decoders involved. Inner and outer bounds to the complexity-relevance region of these problems are derived from which optimality is characterized for several cases of interest. Our resulting theoretical complexity-relevance regions are finally evaluated for binary symmetric and Gaussian statistical models.
Dynamic Graph Learning-Neural Network for Multivariate Time Series Modeling
Dec 06, 2021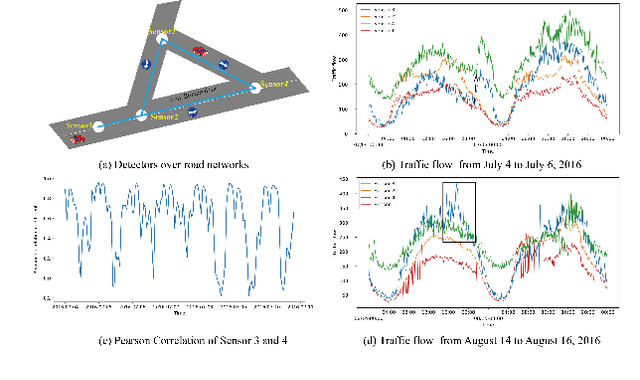
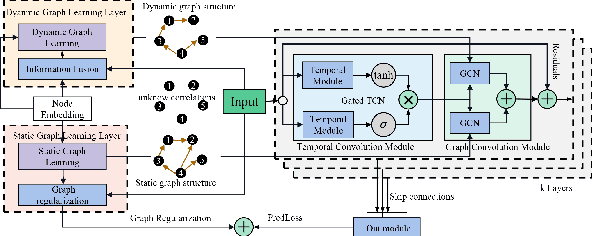

Multivariate time series forecasting is a challenging task because the data involves a mixture of long- and short-term patterns, with dynamic spatio-temporal dependencies among variables. Existing graph neural networks (GNN) typically model multivariate relationships with a pre-defined spatial graph or learned fixed adjacency graph. It limits the application of GNN and fails to handle the above challenges. In this paper, we propose a novel framework, namely static- and dynamic-graph learning-neural network (SDGL). The model acquires static and dynamic graph matrices from data to model long- and short-term patterns respectively. Static matric is developed to capture the fixed long-term association pattern via node embeddings, and we leverage graph regularity for controlling the quality of the learned static graph. To capture dynamic dependencies among variables, we propose dynamic graphs learning method to generate time-varying matrices based on changing node features and static node embeddings. And in the method, we integrate the learned static graph information as inductive bias to construct dynamic graphs and local spatio-temporal patterns better. Extensive experiments are conducted on two traffic datasets with extra structural information and four time series datasets, which show that our approach achieves state-of-the-art performance on almost all datasets. If the paper is accepted, I will open the source code on github.
An Integrated Approach for Video Captioning and Applications
Jan 23, 2022



Physical computing infrastructure, data gathering, and algorithms have recently had significant advances to extract information from images and videos. The growth has been especially outstanding in image captioning and video captioning. However, most of the advancements in video captioning still take place in short videos. In this research, we caption longer videos only by using the keyframes, which are a small subset of the total video frames. Instead of processing thousands of frames, only a few frames are processed depending on the number of keyframes. There is a trade-off between the computation of many frames and the speed of the captioning process. The approach in this research is to allow the user to specify the trade-off between execution time and accuracy. In addition, we argue that linking images, videos, and natural language offers many practical benefits and immediate practical applications. From the modeling perspective, instead of designing and staging explicit algorithms to process videos and generate captions in complex processing pipelines, our contribution lies in designing hybrid deep learning architectures to apply in long videos by captioning video keyframes. We consider the technology and the methodology that we have developed as steps toward the applications discussed in this research.
Rethinking Softmax with Cross-Entropy: Neural Network Classifier as Mutual Information Estimator
Nov 25, 2019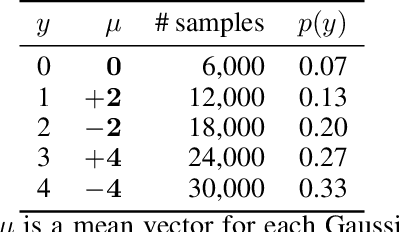
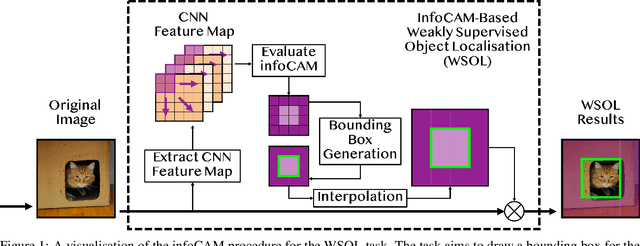
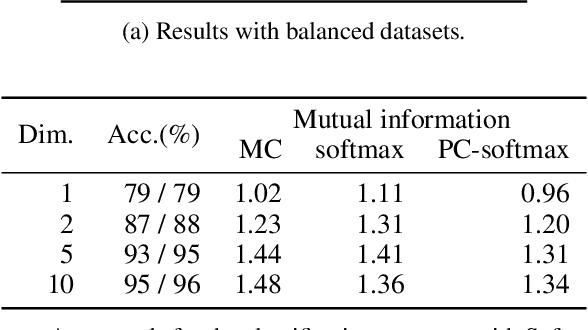

Mutual information is widely applied to learn latent representations of observations, whilst its implication in classification neural networks remain to be better explained. In this paper, we show that optimising the parameters of classification neural networks with softmax cross-entropy is equivalent to maximising the mutual information between inputs and labels under the balanced data assumption. Through the experiments on synthetic and real datasets, we show that softmax cross-entropy can estimate mutual information approximately. When applied to image classification, this relation helps approximate the point-wise mutual information between an input image and a label without modifying the network structure. In this end, we propose infoCAM, informative class activation map, which highlights regions of the input image that are the most relevant to a given label based on differences in information. The activation map helps localise the target object in an image. Through the experiments on the semi-supervised object localisation task with two real-world datasets, we evaluate the effectiveness of the information-theoretic approach.
Data-Driven Deep Learning Based Hybrid Beamforming for Aerial Massive MIMO-OFDM Systems with Implicit CSI
Feb 10, 2022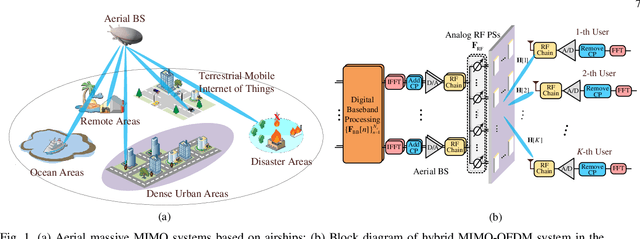
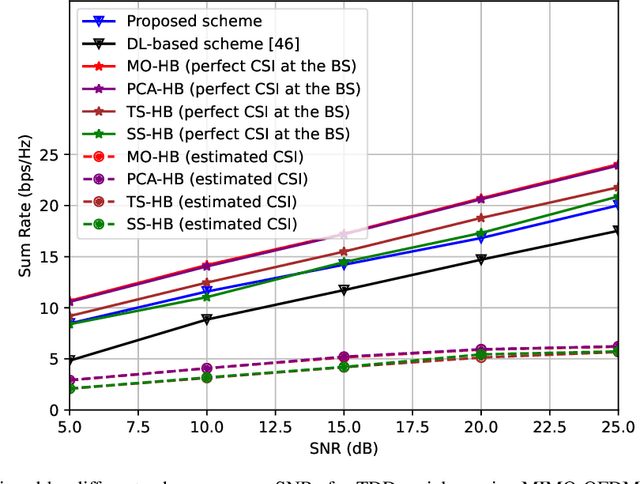
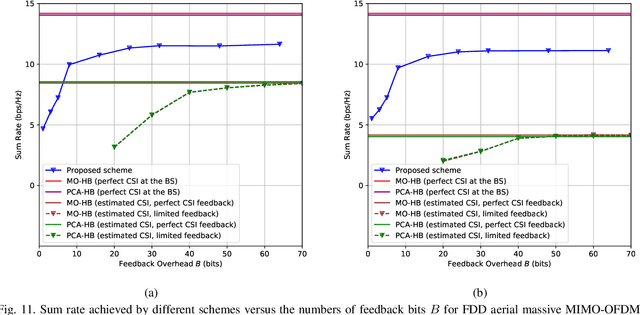
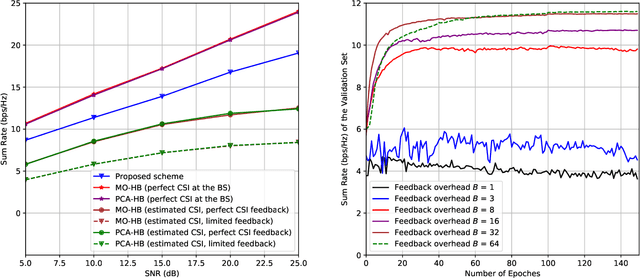
In an aerial hybrid massive multiple-input multiple-output (MIMO) and orthogonal frequency division multiplexing (OFDM) system, how to design a spectral-efficient broadband multi-user hybrid beamforming with a limited pilot and feedback overhead is challenging. To this end, by modeling the key transmission modules as an end-to-end (E2E) neural network, this paper proposes a data-driven deep learning (DL)-based unified hybrid beamforming framework for both the time division duplex (TDD) and frequency division duplex (FDD) systems with implicit channel state information (CSI). For TDD systems, the proposed DL-based approach jointly models the uplink pilot combining and downlink hybrid beamforming modules as an E2E neural network. While for FDD systems, we jointly model the downlink pilot transmission, uplink CSI feedback, and downlink hybrid beamforming modules as an E2E neural network. Different from conventional approaches separately processing different modules, the proposed solution simultaneously optimizes all modules with the sum rate as the optimization object. Therefore, by perceiving the inherent property of air-to-ground massive MIMO-OFDM channel samples, the DL-based E2E neural network can establish the mapping function from the channel to the beamformer, so that the explicit channel reconstruction can be avoided with reduced pilot and feedback overhead. Besides, practical low-resolution phase shifters (PSs) introduce the quantization constraint, leading to the intractable gradient backpropagation when training the neural network. To mitigate the performance loss caused by the phase quantization error, we adopt the transfer learning strategy to further fine-tune the E2E neural network based on a pre-trained network that assumes the ideal infinite-resolution PSs. Numerical results show that our DL-based schemes have considerable advantages over state-of-the-art schemes.
Learning Physics through Images: An Application to Wind-Driven Spatial Patterns
Feb 03, 2022
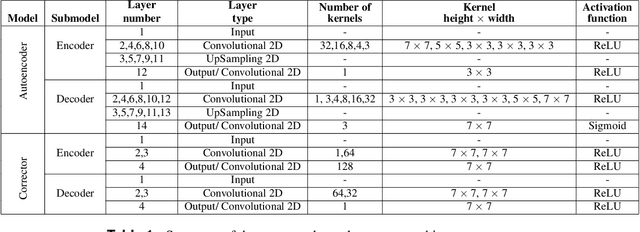
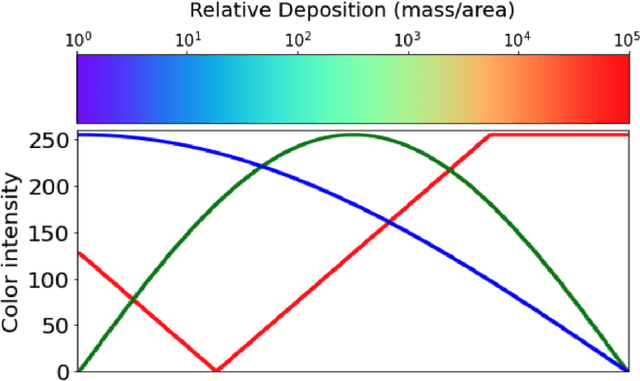
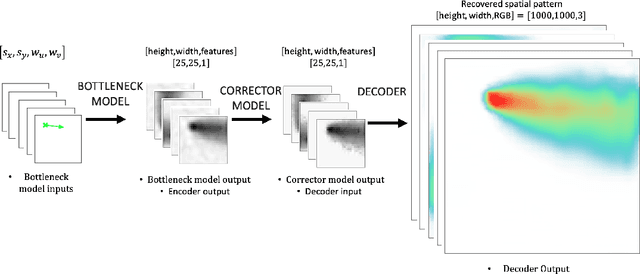
For centuries, scientists have observed nature to understand the laws that govern the physical world. The traditional process of turning observations into physical understanding is slow. Imperfect models are constructed and tested to explain relationships in data. Powerful new algorithms are available that can enable computers to learn physics by observing images and videos. Inspired by this idea, instead of training machine learning models using physical quantities, we trained them using images, that is, pixel information. For this work, and as a proof of concept, the physics of interest are wind-driven spatial patterns. Examples of these phenomena include features in Aeolian dunes and the deposition of volcanic ash, wildfire smoke, and air pollution plumes. We assume that the spatial patterns were collected by an imaging device that records the magnitude of the logarithm of deposition as a red, green, blue (RGB) color image with channels containing values ranging from 0 to 255. In this paper, we explore deep convolutional neural network-based autoencoders to exploit relationships in wind-driven spatial patterns, which commonly occur in geosciences, and reduce their dimensionality. Reducing the data dimension size with an encoder allows us to train regression models linking geographic and meteorological scalar input quantities to the encoded space. Once this is achieved, full predictive spatial patterns are reconstructed using the decoder. We demonstrate this approach on images of spatial deposition from a pollution source, where the encoder compresses the dimensionality to 0.02% of the original size and the full predictive model performance on test data achieves an accuracy of 92%.
PropagationNet: Propagate Points to Curve to Learn Structure Information
Jun 25, 2020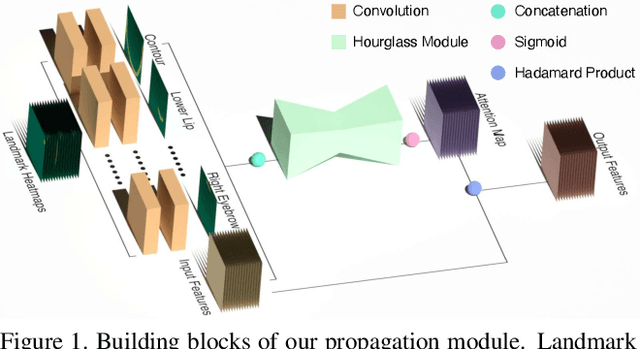
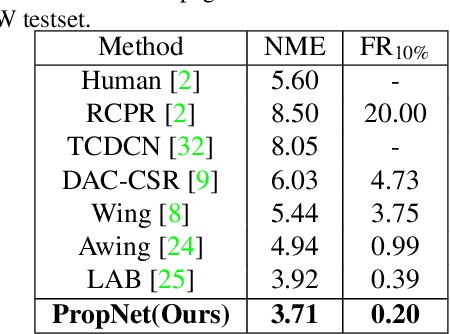
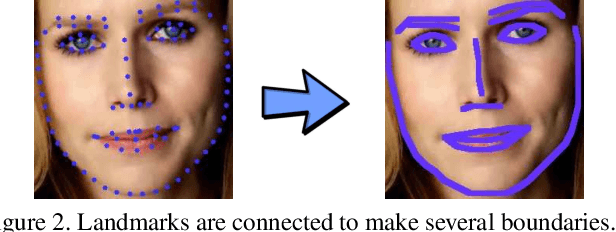
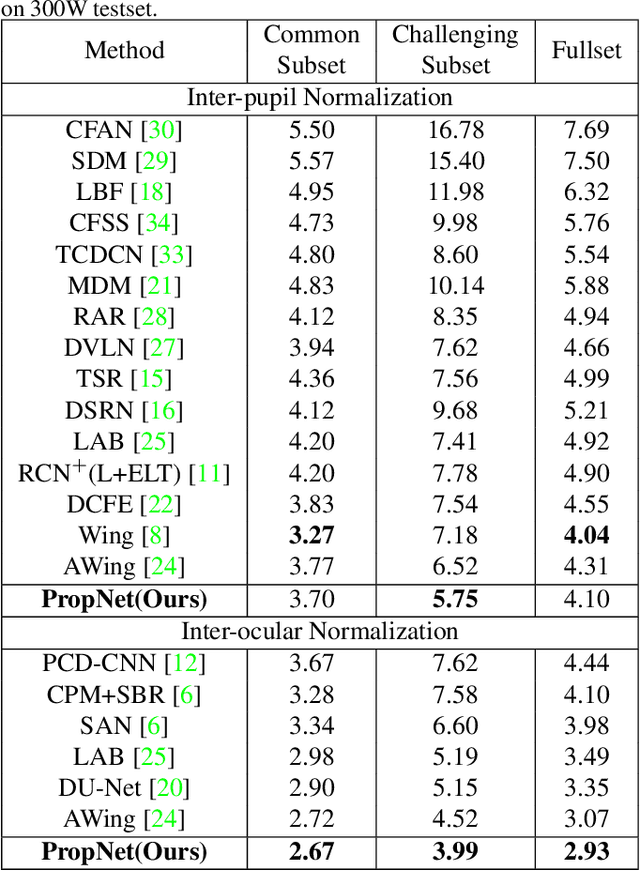
Deep learning technique has dramatically boosted the performance of face alignment algorithms. However, due to large variability and lack of samples, the alignment problem in unconstrained situations, \emph{e.g}\onedot large head poses, exaggerated expression, and uneven illumination, is still largely unsolved. In this paper, we explore the instincts and reasons behind our two proposals, \emph{i.e}\onedot Propagation Module and Focal Wing Loss, to tackle the problem. Concretely, we present a novel structure-infused face alignment algorithm based on heatmap regression via propagating landmark heatmaps to boundary heatmaps, which provide structure information for further attention map generation. Moreover, we propose a Focal Wing Loss for mining and emphasizing the difficult samples under in-the-wild condition. In addition, we adopt methods like CoordConv and Anti-aliased CNN from other fields that address the shift-variance problem of CNN for face alignment. When implementing extensive experiments on different benchmarks, \emph{i.e}\onedot WFLW, 300W, and COFW, our method outperforms state-of-the-arts by a significant margin. Our proposed approach achieves 4.05\% mean error on WFLW, 2.93\% mean error on 300W full-set, and 3.71\% mean error on COFW.
* 10 pages, 8 figures, 8 tables, CVPR2020
Hierarchical Qualitative Clustering: clustering mixed datasets with critical qualitative information
Jul 06, 2020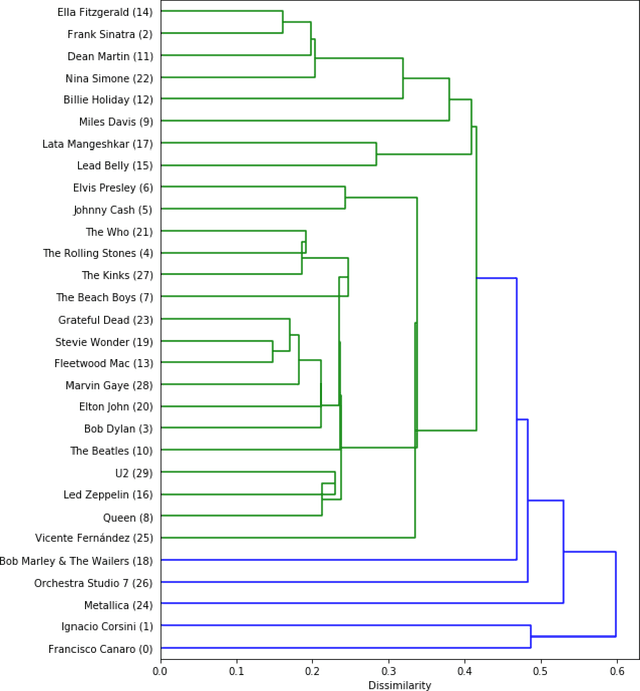
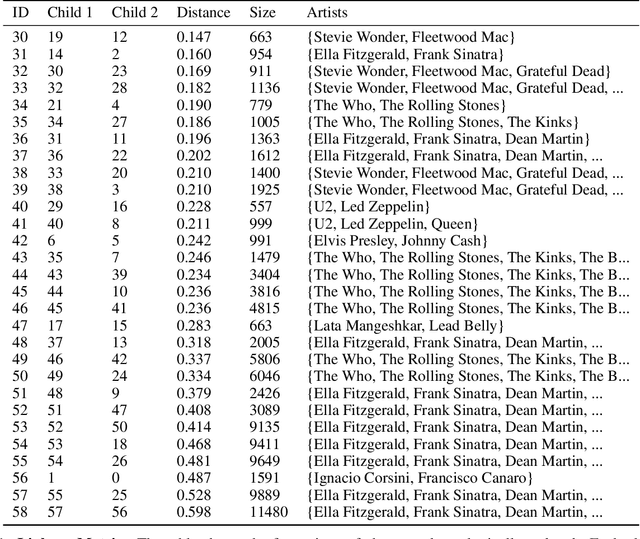
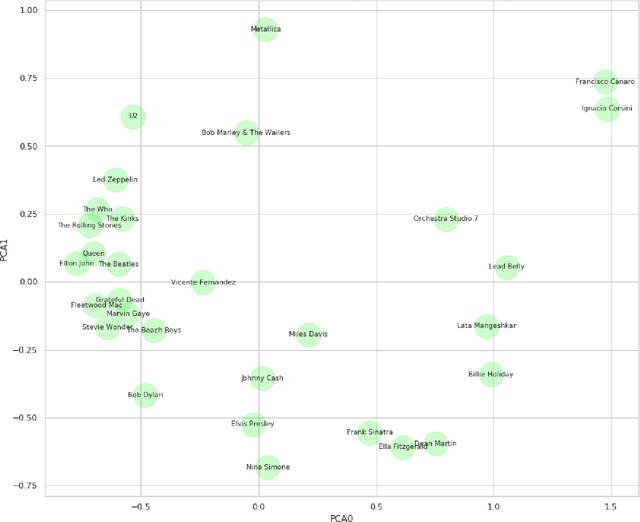
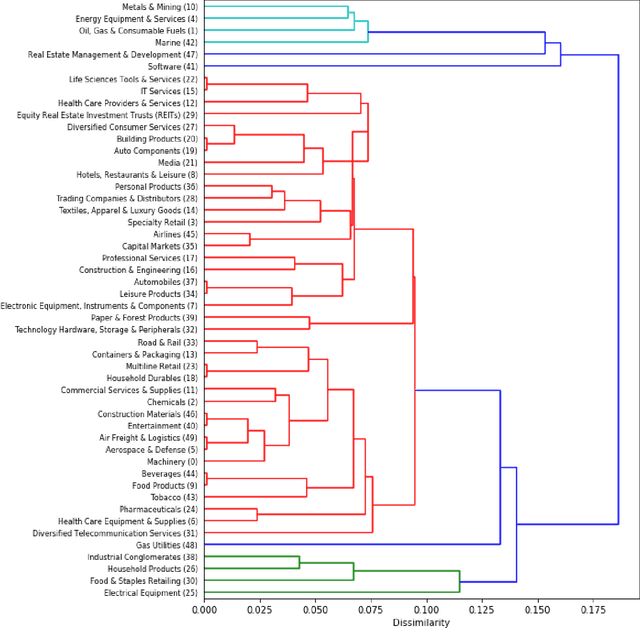
Clustering can be used to extract insights from data or to verify some of the assumptions held by the domain experts, namely data segmentation. In the literature, few methods can be applied in clustering qualitative values using the context associated with other variables present in the data, without losing interpretability. Moreover, the metrics for calculating dissimilarity between qualitative values often scale poorly for high dimensional mixed datasets. In this study, we propose a novel method for clustering qualitative values, based on Hierarchical Clustering (HQC), and using Maximum Mean Discrepancy. HQC maintains the original interpretability of the qualitative information present in the dataset. We apply HQC to two datasets. Using a mixed dataset provided by Spotify, we showcase how our method can be used for clustering music artists based on the quantitative features of thousands of songs. In addition, using financial features of companies, we cluster company industries, and discuss the implications in investment portfolios diversification.