 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Non-Convex Joint Community Detection and Group Synchronization via Generalized Power Method
Dec 28, 2021
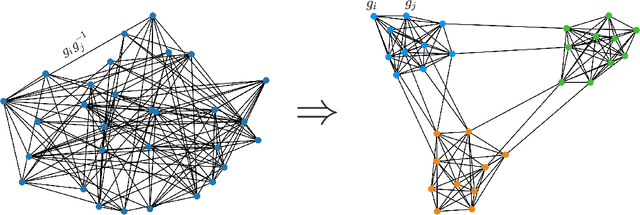

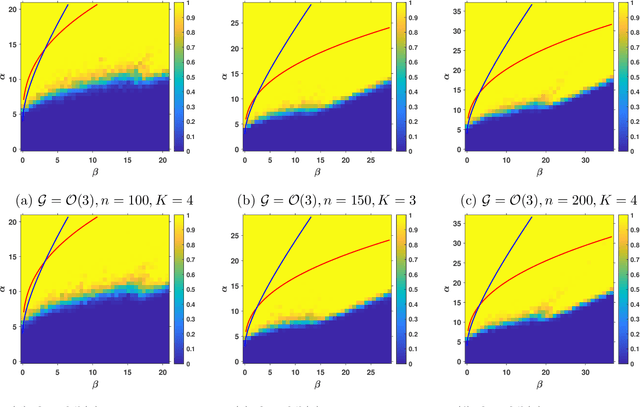
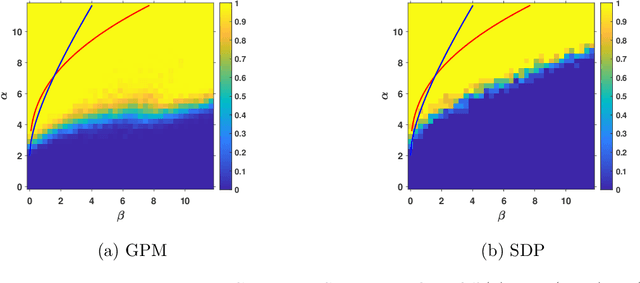
This paper proposes a Generalized Power Method (GPM) to tackle the problem of community detection and group synchronization simultaneously in a direct non-convex manner. Under the stochastic group block model (SGBM), theoretical analysis indicates that the algorithm is able to exactly recover the ground truth in $O(n\log^2n)$ time, sharply outperforming the benchmark method of semidefinite programming (SDP) in $O(n^{3.5})$ time. Moreover, a lower bound of parameters is given as a necessary condition for exact recovery of GPM. The new bound breaches the information-theoretic threshold for pure community detection under the stochastic block model (SBM), thus demonstrating the superiority of our simultaneous optimization algorithm over the trivial two-stage method which performs the two tasks in succession. We also conduct numerical experiments on GPM and SDP to evidence and complement our theoretical analysis.
Learning Representations and Agents for Information Retrieval
Aug 16, 2019

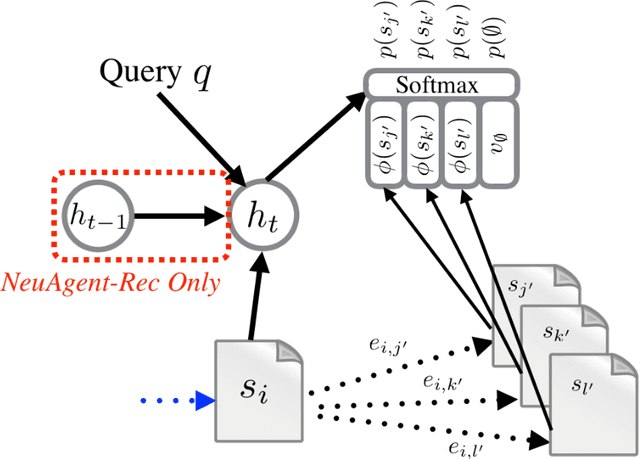

A goal shared by artificial intelligence and information retrieval is to create an oracle, that is, a machine that can answer our questions, no matter how difficult they are. A more limited, but still instrumental, version of this oracle is a question-answering system, in which an open-ended question is given to the machine, and an answer is produced based on the knowledge it has access to. Such systems already exist and are increasingly capable of answering complicated questions. This progress can be partially attributed to the recent success of machine learning and to the efficient methods for storing and retrieving information, most notably through web search engines. One can imagine that this general-purpose question-answering system can be built as a billion-parameters neural network trained end-to-end with a large number of pairs of questions and answers. We argue, however, that although this approach has been very successful for tasks such as machine translation, storing the world's knowledge as parameters of a learning machine can be very hard. A more efficient way is to train an artificial agent on how to use an external retrieval system to collect relevant information. This agent can leverage the effort that has been put into designing and running efficient storage and retrieval systems by learning how to best utilize them to accomplish a task. ...
Words of Wisdom: Representational Harms in Learning From AI Communication
Nov 16, 2021
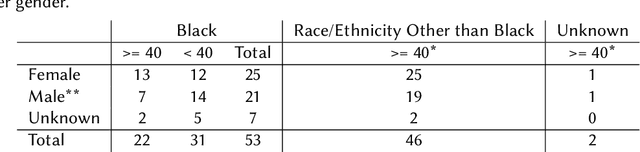
Many educational technologies use artificial intelligence (AI) that presents generated or produced language to the learner. We contend that all language, including all AI communication, encodes information about the identity of the human or humans who contributed to crafting the language. With AI communication, however, the user may index identity information that does not match the source. This can lead to representational harms if language associated with one cultural group is presented as "standard" or "neutral", if the language advantages one group over another, or if the language reinforces negative stereotypes. In this work, we discuss a case study using a Visual Question Generation (VQG) task involving gathering crowdsourced data from targeted demographic groups. Generated questions will be presented to human evaluators to understand how they index the identity behind the language, whether and how they perceive any representational harms, and how they would ideally address any such harms caused by AI communication. We reflect on the educational applications of this work as well as the implications for equality, diversity, and inclusion (EDI).
Trimap-guided Feature Mining and Fusion Network for Natural Image Matting
Dec 01, 2021
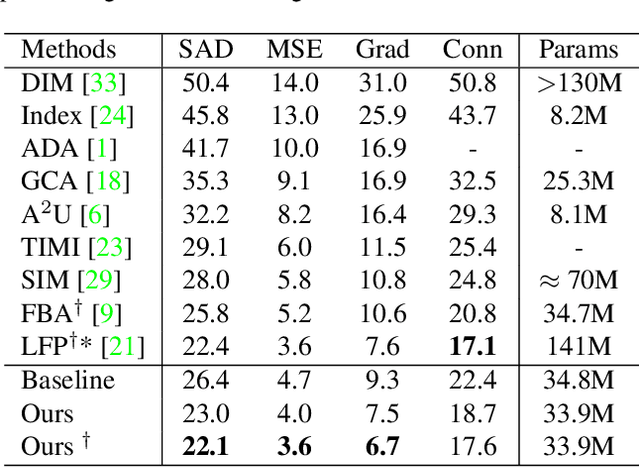
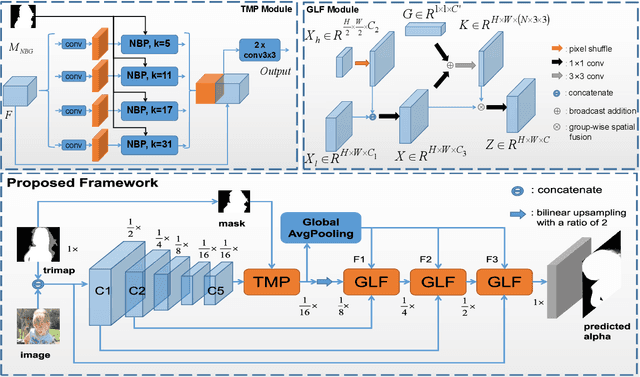
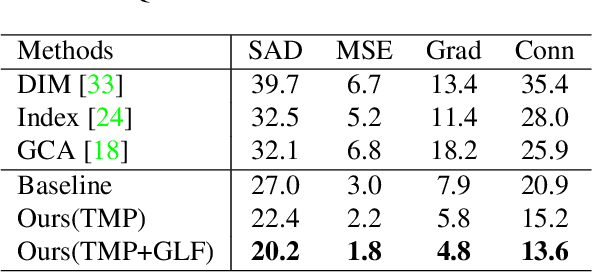
Utilizing trimap guidance and fusing multi-level features are two important issues for trimap-based matting with pixel-level prediction. To utilize trimap guidance, most existing approaches simply concatenate trimaps and images together to feed a deep network or apply an extra network to extract more trimap guidance, which meets the conflict between efficiency and effectiveness. For emerging content-based feature fusion, most existing matting methods only focus on local features which lack the guidance of a global feature with strong semantic information related to the interesting object. In this paper, we propose a trimap-guided feature mining and fusion network consisting of our trimap-guided non-background multi-scale pooling (TMP) module and global-local context-aware fusion (GLF) modules. Considering that trimap provides strong semantic guidance, our TMP module focuses effective feature mining on interesting objects under the guidance of trimap without extra parameters. Furthermore, our GLF modules use global semantic information of interesting objects mined by our TMP module to guide an effective global-local context-aware multi-level feature fusion. In addition, we build a common interesting object matting (CIOM) dataset to advance high-quality image matting. Experimental results on the Composition-1k test set, Alphamatting benchmark, and our CIOM test set demonstrate that our method outperforms state-of-the-art approaches. Code and models will be publicly available soon.
Utilizing Textual Reviews in Latent Factor Models for Recommender Systems
Nov 16, 2021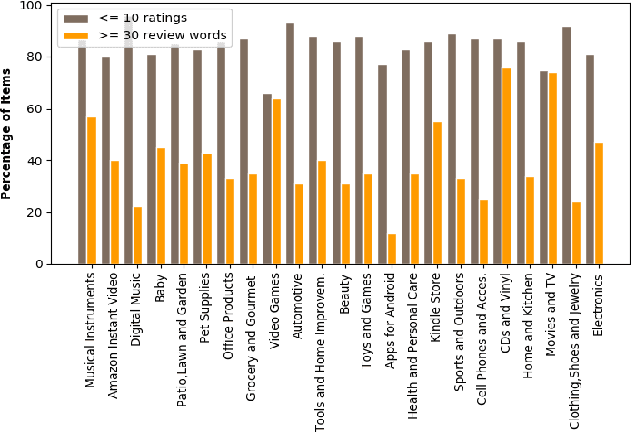
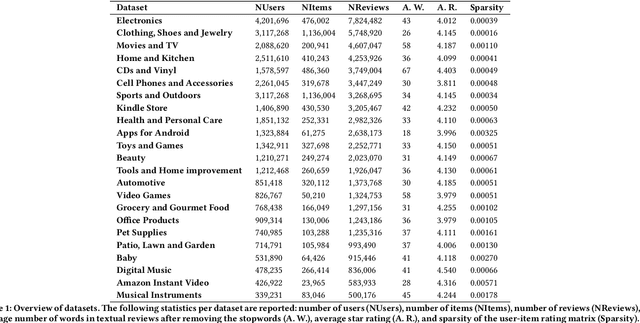
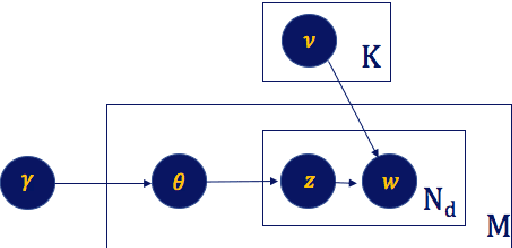
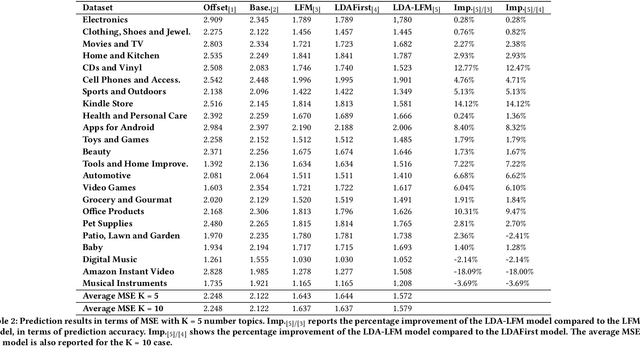
Most of the existing recommender systems are based only on the rating data, and they ignore other sources of information that might increase the quality of recommendations, such as textual reviews, or user and item characteristics. Moreover, the majority of those systems are applicable only on small datasets (with thousands of observations) and are unable to handle large datasets (with millions of observations). We propose a recommender algorithm that combines a rating modelling technique (i.e., Latent Factor Model) with a topic modelling method based on textual reviews (i.e., Latent Dirichlet Allocation), and we extend the algorithm such that it allows adding extra user- and item-specific information to the system. We evaluate the performance of the algorithm using Amazon.com datasets with different sizes, corresponding to 23 product categories. After comparing the built model to four other models we found that combining textual reviews with ratings leads to better recommendations. Moreover, we found that adding extra user and item features to the model increases its prediction accuracy, which is especially true for medium and large datasets.
Differentially Private Reinforcement Learning with Linear Function Approximation
Jan 18, 2022Motivated by the wide adoption of reinforcement learning (RL) in real-world personalized services, where users' sensitive and private information needs to be protected, we study regret minimization in finite-horizon Markov decision processes (MDPs) under the constraints of differential privacy (DP). Compared to existing private RL algorithms that work only on tabular finite-state, finite-actions MDPs, we take the first step towards privacy-preserving learning in MDPs with large state and action spaces. Specifically, we consider MDPs with linear function approximation (in particular linear mixture MDPs) under the notion of joint differential privacy (JDP), where the RL agent is responsible for protecting users' sensitive data. We design two private RL algorithms that are based on value iteration and policy optimization, respectively, and show that they enjoy sub-linear regret performance while guaranteeing privacy protection. Moreover, the regret bounds are independent of the number of states, and scale at most logarithmically with the number of actions, making the algorithms suitable for privacy protection in nowadays large-scale personalized services. Our results are achieved via a general procedure for learning in linear mixture MDPs under changing regularizers, which not only generalizes previous results for non-private learning, but also serves as a building block for general private reinforcement learning.
Contrastive estimation reveals topic posterior information to linear models
Mar 04, 2020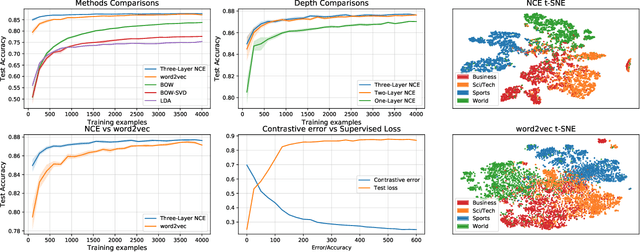
Contrastive learning is an approach to representation learning that utilizes naturally occurring similar and dissimilar pairs of data points to find useful embeddings of data. In the context of document classification under topic modeling assumptions, we prove that contrastive learning is capable of recovering a representation of documents that reveals their underlying topic posterior information to linear models. We apply this procedure in a semi-supervised setup and demonstrate empirically that linear classifiers with these representations perform well in document classification tasks with very few training examples.
Explainable Landscape-Aware Optimization Performance Prediction
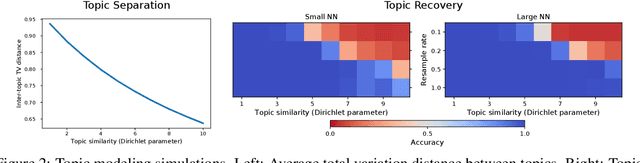
Oct 22, 2021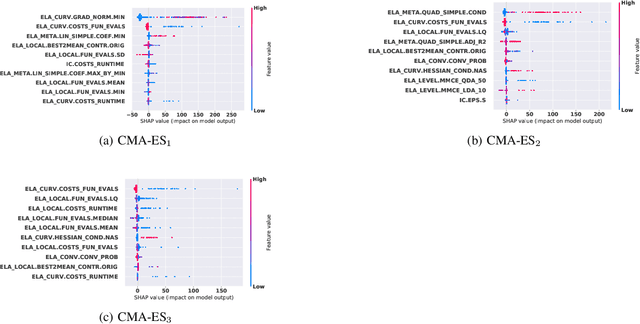
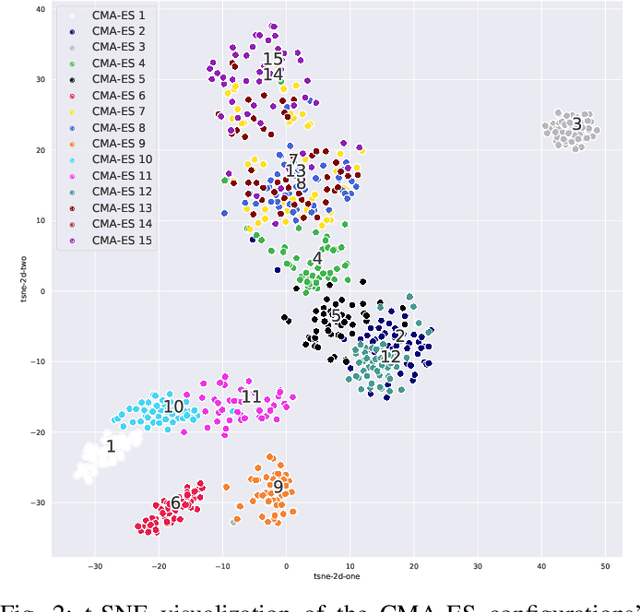
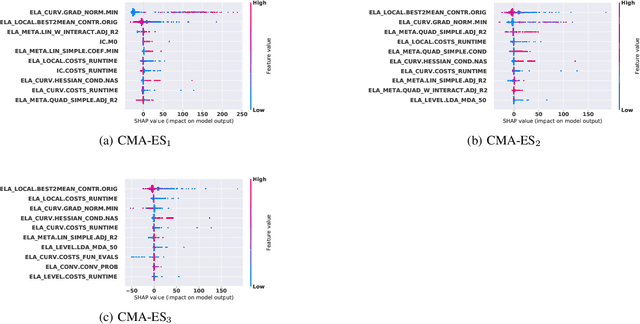

Efficient solving of an unseen optimization problem is related to appropriate selection of an optimization algorithm and its hyper-parameters. For this purpose, automated algorithm performance prediction should be performed that in most commonly-applied practices involves training a supervised ML algorithm using a set of problem landscape features. However, the main issue of training such models is their limited explainability since they only provide information about the joint impact of the set of landscape features to the end prediction results. In this study, we are investigating explainable landscape-aware regression models where the contribution of each landscape feature to the prediction of the optimization algorithm performance is estimated on a global and local level. The global level provides information about the impact of the feature across all benchmark problems' instances, while the local level provides information about the impact on a specific problem instance. The experimental results are obtained using the COCO benchmark problems and three differently configured modular CMA-ESs. The results show a proof of concept that different set of features are important for different problem instances, which indicates that further personalization of the landscape space is required when training an automated algorithm performance prediction model.
It's All in the Head: Representation Knowledge Distillation through Classifier Sharing
Jan 18, 2022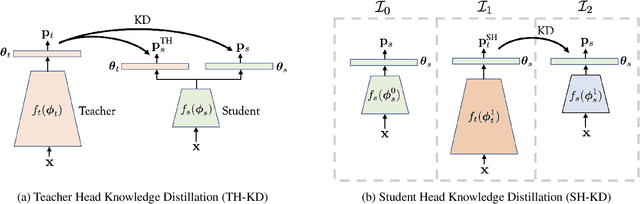
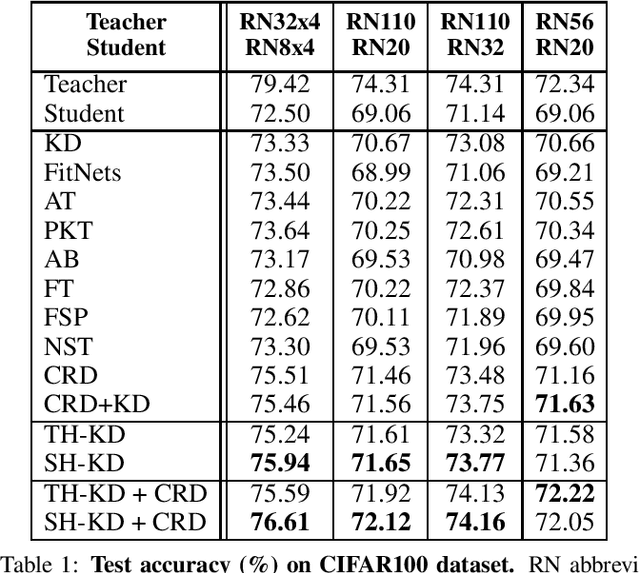
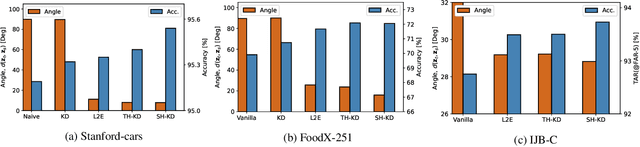
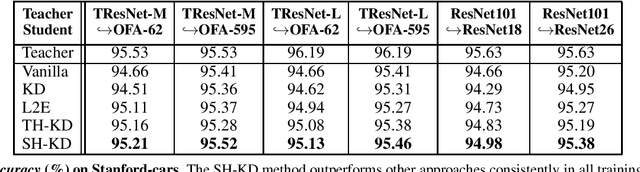
Representation knowledge distillation aims at transferring rich information from one model to another. Current approaches for representation distillation mainly focus on the direct minimization of distance metrics between the models' embedding vectors. Such direct methods may be limited in transferring high-order dependencies embedded in the representation vectors, or in handling the capacity gap between the teacher and student models. In this paper, we introduce two approaches for enhancing representation distillation using classifier sharing between the teacher and student. Specifically, we first show that connecting the teacher's classifier to the student backbone and freezing its parameters is beneficial for the process of representation distillation, yielding consistent improvements. Then, we propose an alternative approach that asks to tailor the teacher model to a student with limited capacity. This approach competes with and in some cases surpasses the first method. Via extensive experiments and analysis, we show the effectiveness of the proposed methods on various datasets and tasks, including image classification, fine-grained classification, and face verification. For example, we achieve state-of-the-art performance for face verification on the IJB-C dataset for a MobileFaceNet model: TAR@(FAR=1e-5)=93.7\%. Code is available at https://github.com/Alibaba-MIIL/HeadSharingKD.
Picasso: Model-free Feature Visualization
Nov 24, 2021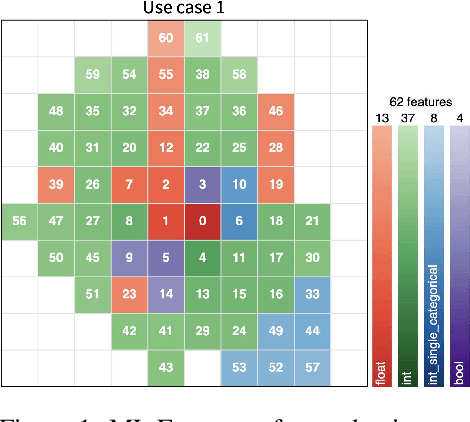
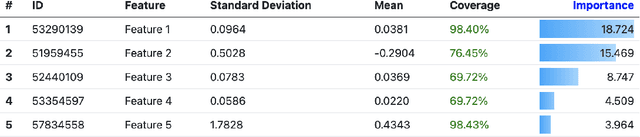
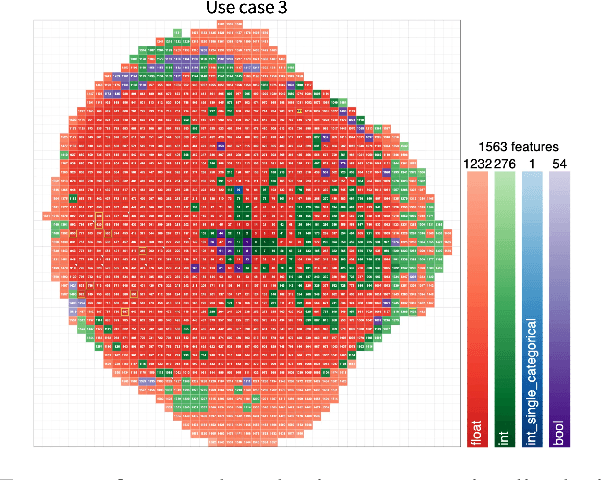
Today, Machine Learning (ML) applications can have access to tens of thousands of features. With such feature sets, efficiently browsing and curating subsets of most relevant features is a challenge. In this paper, we present a novel approach to visualize up to several thousands of features in a single image. The image not only shows information on individual features, but also expresses feature interactions via the relative positioning of features.