 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Discovering Nonlinear Relations with Minimum Predictive Information Regularization
Jan 07, 2020
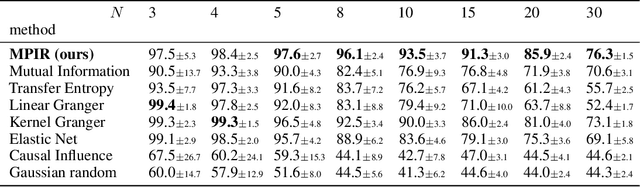
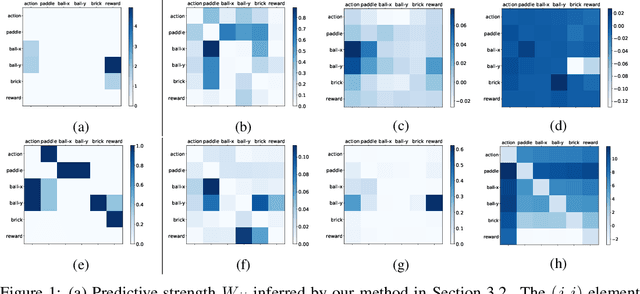
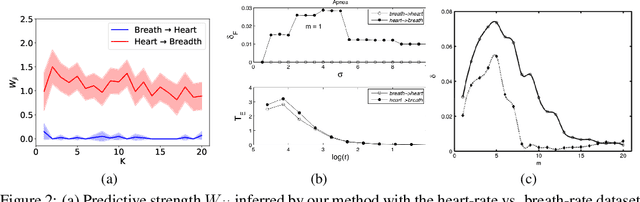
Identifying the underlying directional relations from observational time series with nonlinear interactions and complex relational structures is key to a wide range of applications, yet remains a hard problem. In this work, we introduce a novel minimum predictive information regularization method to infer directional relations from time series, allowing deep learning models to discover nonlinear relations. Our method substantially outperforms other methods for learning nonlinear relations in synthetic datasets, and discovers the directional relations in a video game environment and a heart-rate vs. breath-rate dataset.
Open Information Extraction from Question-Answer Pairs
Apr 06, 2019



Open Information Extraction (OpenIE) extracts meaningful structured tuples from free-form text. Most previous work on OpenIE considers extracting data from one sentence at a time. We describe NeurON, a system for extracting tuples from question-answer pairs. Since real questions and answers often contain precisely the information that users care about, such information is particularly desirable to extend a knowledge base with. NeurON addresses several challenges. First, an answer text is often hard to understand without knowing the question, and second, relevant information can span multiple sentences. To address these, NeurON formulates extraction as a multi-source sequence-to-sequence learning task, wherein it combines distributed representations of a question and an answer to generate knowledge facts. We describe experiments on two real-world datasets that demonstrate that NeurON can find a significant number of new and interesting facts to extend a knowledge base compared to state-of-the-art OpenIE methods.
Skyline variations allow estimating distance to trees on landscape photos using semantic segmentation
Jan 14, 2022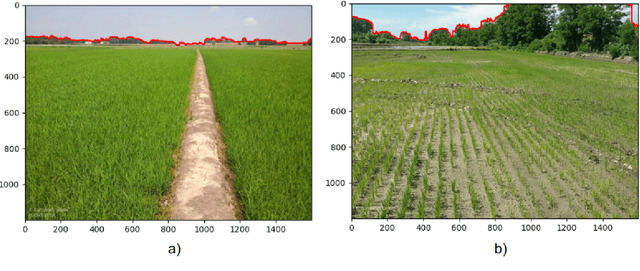
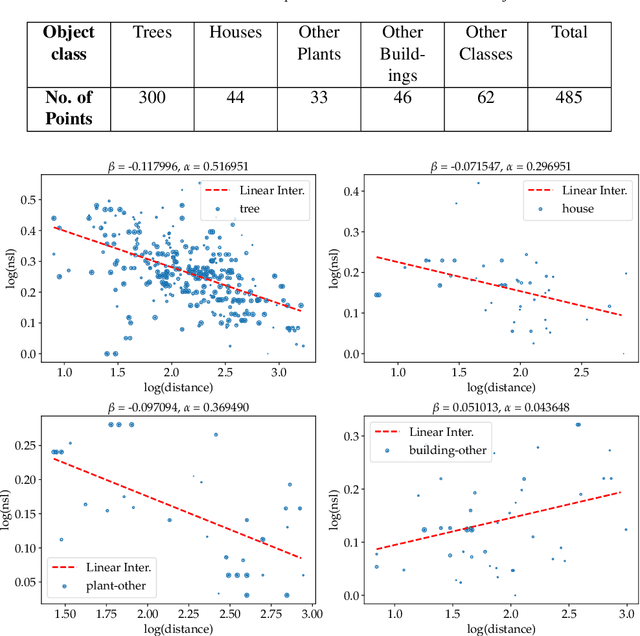
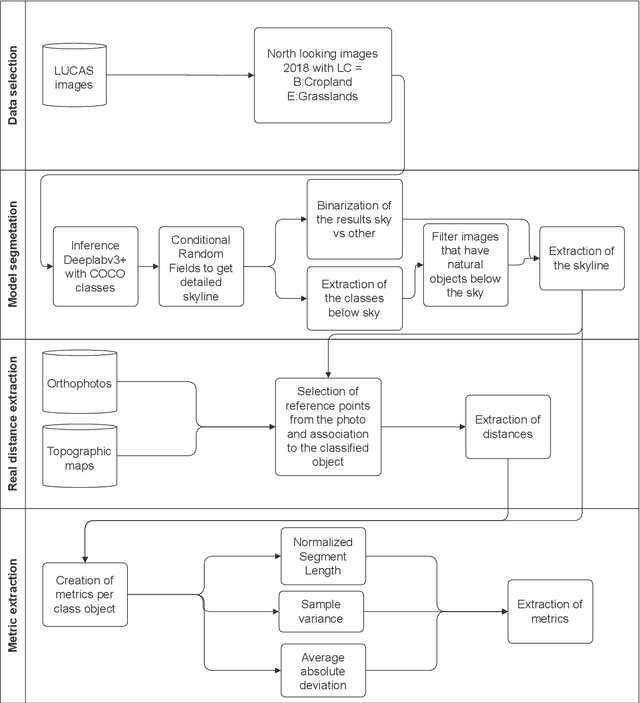

Approximate distance estimation can be used to determine fundamental landscape properties including complexity and openness. We show that variations in the skyline of landscape photos can be used to estimate distances to trees on the horizon. A methodology based on the variations of the skyline has been developed and used to investigate potential relationships with the distance to skyline objects. The skyline signal, defined by the skyline height expressed in pixels, was extracted for several Land Use/Cover Area frame Survey (LUCAS) landscape photos. Photos were semantically segmented with DeepLabV3+ trained with the Common Objects in Context (COCO) dataset. This provided pixel-level classification of the objects forming the skyline. A Conditional Random Fields (CRF) algorithm was also applied to increase the details of the skyline signal. Three metrics, able to capture the skyline signal variations, were then considered for the analysis. These metrics shows a functional relationship with distance for the class of trees, whose contours have a fractal nature. In particular, regression analysis was performed against 475 ortho-photo based distance measurements, and, in the best case, a R2 score equal to 0.47 was achieved. This is an encouraging result which shows the potential of skyline variation metrics for inferring distance related information.
Dynamic Token Normalization Improves Vision Transformer
Dec 05, 2021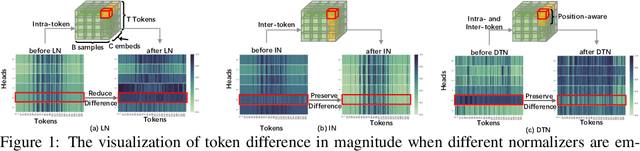
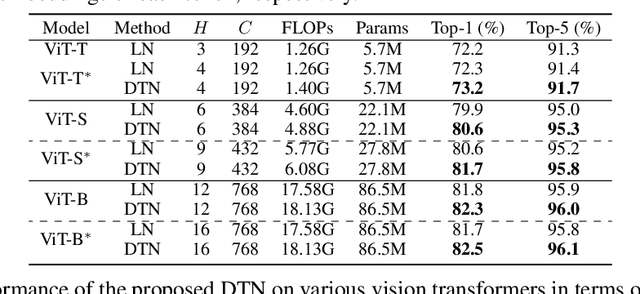
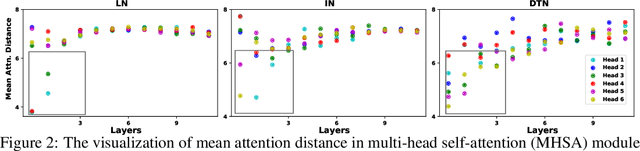

Vision Transformer (ViT) and its variants (e.g., Swin, PVT) have achieved great success in various computer vision tasks, owing to their capability to learn long-range contextual information. Layer Normalization (LN) is an essential ingredient in these models. However, we found that the ordinary LN makes tokens at different positions similar in magnitude because it normalizes embeddings within each token. It is difficult for Transformers to capture inductive bias such as the positional context in an image with LN. We tackle this problem by proposing a new normalizer, termed Dynamic Token Normalization (DTN), where normalization is performed both within each token (intra-token) and across different tokens (inter-token). DTN has several merits. Firstly, it is built on a unified formulation and thus can represent various existing normalization methods. Secondly, DTN learns to normalize tokens in both intra-token and inter-token manners, enabling Transformers to capture both the global contextual information and the local positional context. {Thirdly, by simply replacing LN layers, DTN can be readily plugged into various vision transformers, such as ViT, Swin, PVT, LeViT, T2T-ViT, BigBird and Reformer. Extensive experiments show that the transformer equipped with DTN consistently outperforms baseline model with minimal extra parameters and computational overhead. For example, DTN outperforms LN by $0.5\%$ - $1.2\%$ top-1 accuracy on ImageNet, by $1.2$ - $1.4$ box AP in object detection on COCO benchmark, by $2.3\%$ - $3.9\%$ mCE in robustness experiments on ImageNet-C, and by $0.5\%$ - $0.8\%$ accuracy in Long ListOps on Long-Range Arena.} Codes will be made public at \url{https://github.com/wqshao126/DTN}
Implications of Topological Imbalance for Representation Learning on Biomedical Knowledge Graphs
Dec 13, 2021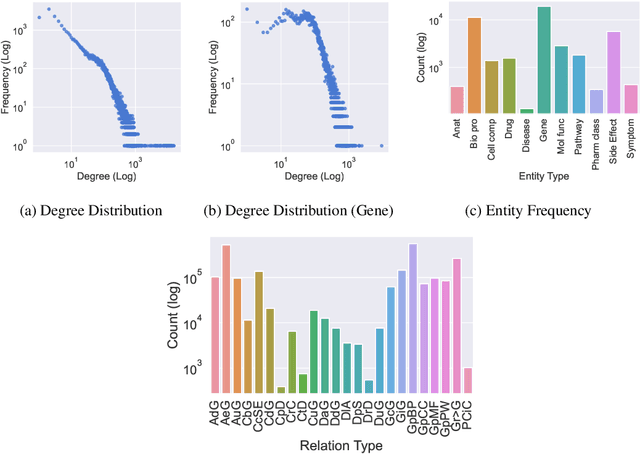
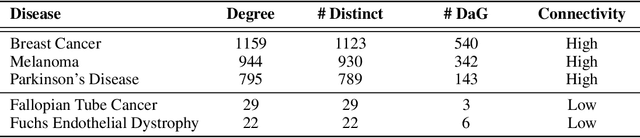
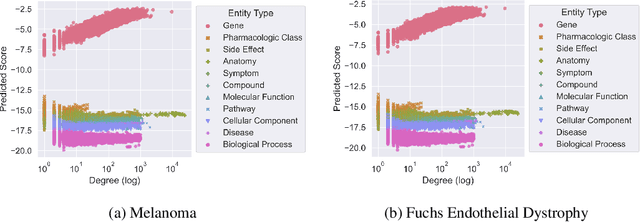
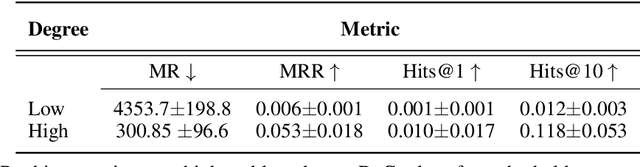
Improving on the standard of care for diseases is predicated on better treatments, which in turn relies on finding and developing new drugs. However, drug discovery is a complex and costly process. Adoption of methods from machine learning has given rise to creation of drug discovery knowledge graphs which utilize the inherent interconnected nature of the domain. Graph-based data modelling, combined with knowledge graph embeddings provide a more intuitive representation of the domain and are suitable for inference tasks such as predicting missing links. One such example would be producing ranked lists of likely associated genes for a given disease, often referred to as target discovery. It is thus critical that these predictions are not only pertinent but also biologically meaningful. However, knowledge graphs can be biased either directly due to the underlying data sources that are integrated or due to modeling choices in the construction of the graph, one consequence of which is that certain entities can get topologically overrepresented. We show how knowledge graph embedding models can be affected by this structural imbalance, resulting in densely connected entities being highly ranked no matter the context. We provide support for this observation across different datasets, models and predictive tasks. Further, we show how the graph topology can be perturbed to artificially alter the rank of a gene via random, biologically meaningless information. This suggests that such models can be more influenced by the frequency of entities rather than biological information encoded in the relations, creating issues when entity frequency is not a true reflection of underlying data. Our results highlight the importance of data modeling choices and emphasizes the need for practitioners to be mindful of these issues when interpreting model outputs and during knowledge graph composition.
Strategies in JPEG compression using Convolutional Neural Network (CNN)
Dec 06, 2021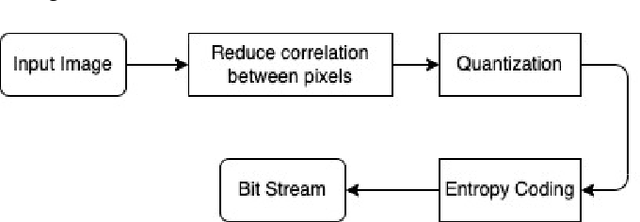
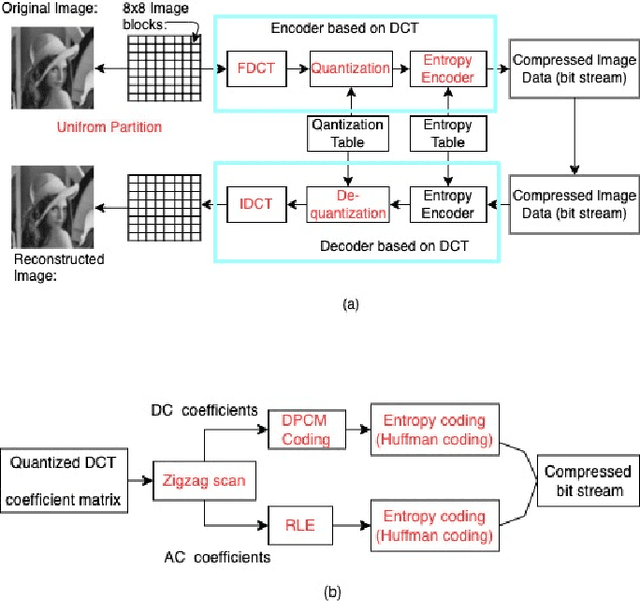
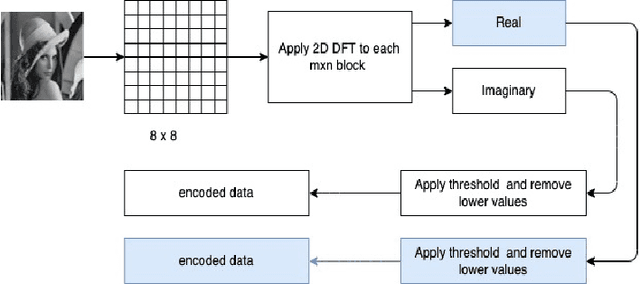

Interests in digital image processing are growing enormously in recent decades. As a result, different data compression techniques have been proposed which are concerned mostly with the minimization of information used for the representation of images. With the advances of deep neural networks, image compression can be achieved to a higher degree. This paper describes an overview of JPEG Compression, Discrete Fourier Transform (DFT), Convolutional Neural Network (CNN), quality metrics to measure the performance of image compression and discuss the advancement of deep learning for image compression mostly focused on JPEG, and suggests that adaptation of model improve the compression.
The cluster structure function
Jan 04, 2022
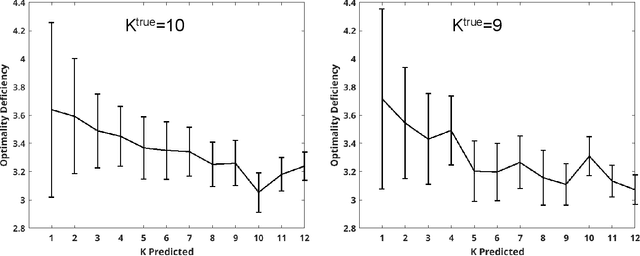
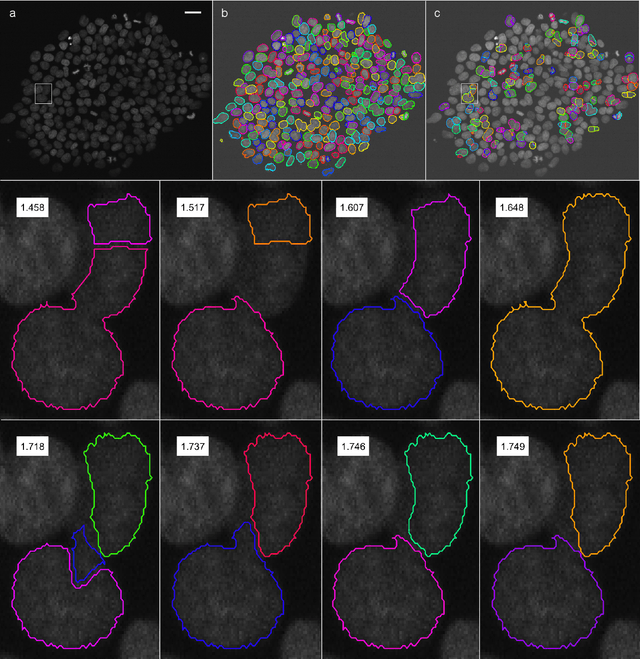
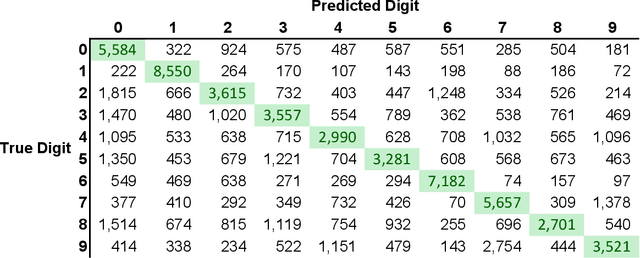
For each partition of a data set into a given number of parts there is a partition such that every part is as much as possible a good model (an "algorithmic sufficient statistic") for the data in that part. Since this can be done for every number between one and the number of data, the result is a function, the cluster structure function. It maps the number of parts of a partition to values related to the deficiencies of being good models by the parts. Such a function starts with a value at least zero for no partition of the data set and descents to zero for the partition of the data set into singleton parts. The optimal clustering is the one chosen to minimize the cluster structure function. The theory behind the method is expressed in algorithmic information theory (Kolmogorov complexity). In practice the Kolmogorov complexities involved are approximated by a concrete compressor. We give examples using real data sets: the MNIST handwritten digits and the segmentation of real cells as used in stem cell research.
Lifelong Dynamic Optimization for Self-Adaptive Systems: Fact or Fiction?
Jan 18, 2022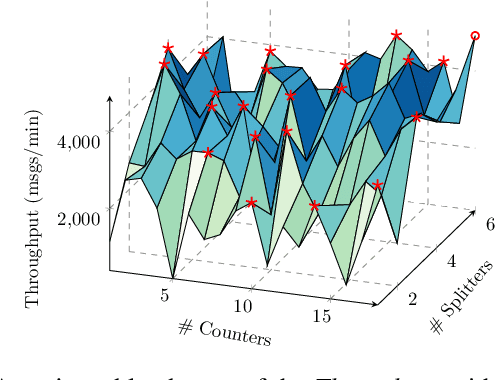
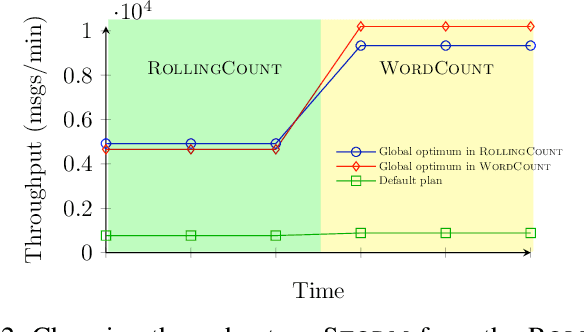
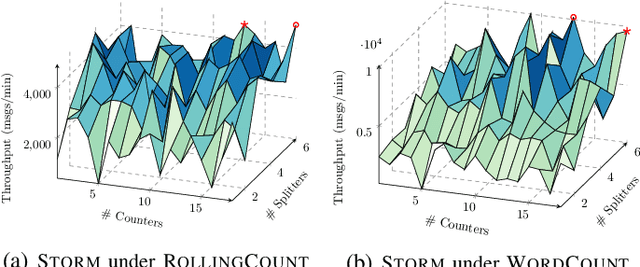
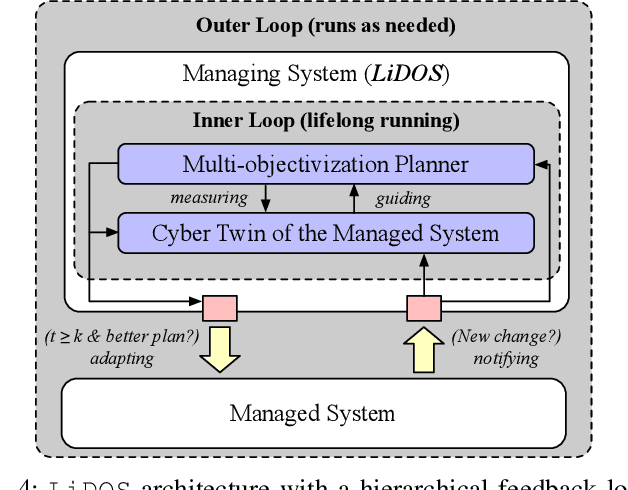
When faced with changing environment, highly configurable software systems need to dynamically search for promising adaptation plan that keeps the best possible performance, e.g., higher throughput or smaller latency -- a typical planning problem for self-adaptive systems (SASs). However, given the rugged and complex search landscape with multiple local optima, such a SAS planning is challenging especially in dynamic environments. In this paper, we propose LiDOS, a lifelong dynamic optimization framework for SAS planning. What makes LiDOS unique is that to handle the "dynamic", we formulate the SAS planning as a multi-modal optimization problem, aiming to preserve the useful information for better dealing with the local optima issue under dynamic environment changes. This differs from existing planners in that the "dynamic" is not explicitly handled during the search process in planning. As such, the search and planning in LiDOS run continuously over the lifetime of SAS, terminating only when it is taken offline or the search space has been covered under an environment. Experimental results on three real-world SASs show that the concept of explicitly handling dynamic as part of the search in the SAS planning is effective, as LiDOS outperforms its stationary counterpart overall with up to 10x improvement. It also achieves better results in general over state-of-the-art planners and with 1.4x to 10x speedup on generating promising adaptation plans.
Deep Task-Based Analog-to-Digital Conversion
Jan 29, 2022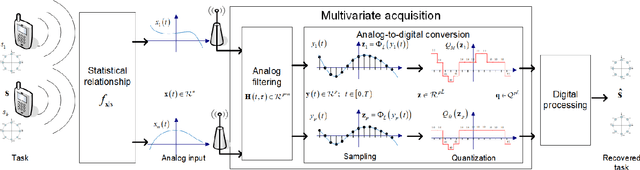
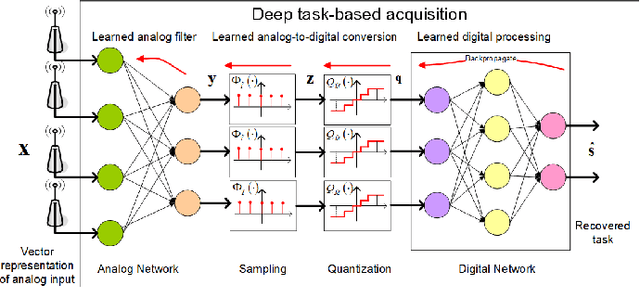
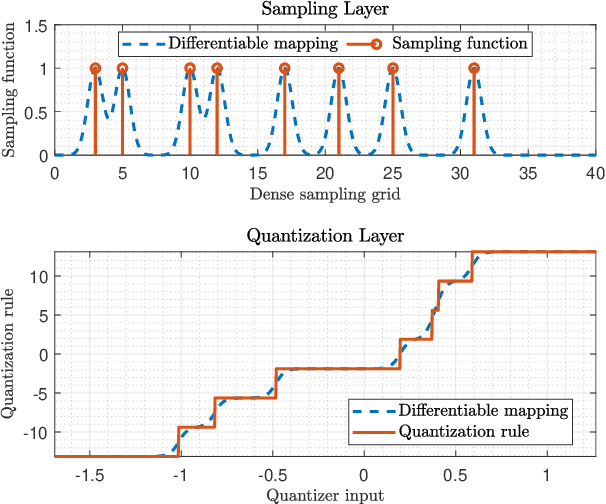
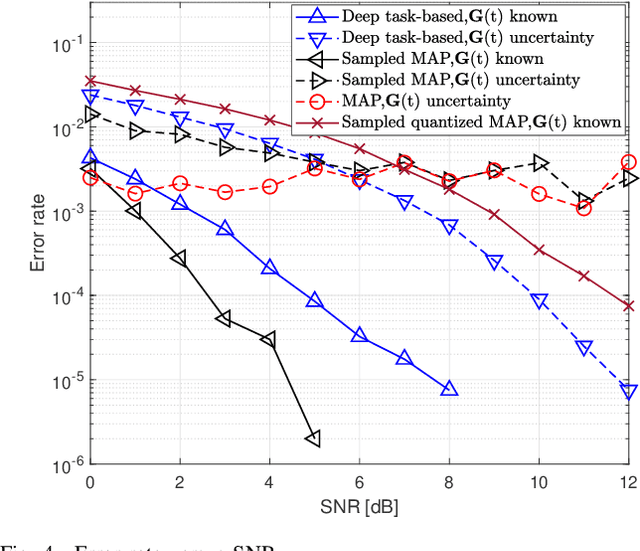
Analog-to-digital converters (ADCs) allow physical signals to be processed using digital hardware. Their conversion consists of two stages: Sampling, which maps a continuous-time signal into discrete-time, and quantization, i.e., representing the continuous-amplitude quantities using a finite number of bits. ADCs typically implement generic uniform conversion mappings that are ignorant of the task for which the signal is acquired, and can be costly when operating in high rates and fine resolutions. In this work we design task-oriented ADCs which learn from data how to map an analog signal into a digital representation such that the system task can be efficiently carried out. We propose a model for sampling and quantization that facilitates the learning of non-uniform mappings from data. Based on this learnable ADC mapping, we present a mechanism for optimizing a hybrid acquisition system comprised of analog combining, tunable ADCs with fixed rates, and digital processing, by jointly learning its components end-to-end. Then, we show how one can exploit the representation of hybrid acquisition systems as deep network to optimize the sampling rate and quantization rate given the task by utilizing Bayesian meta-learning techniques. We evaluate the proposed deep task-based ADC in two case studies: the first considers symbol detection in multi-antenna digital receivers, where multiple analog signals are simultaneously acquired in order to recover a set of discrete information symbols. The second application is the beamforming of analog channel data acquired in ultrasound imaging. Our numerical results demonstrate that the proposed approach achieves performance which is comparable to operating with high sampling rates and fine resolution quantization, while operating with reduced overall bit rate.
Attention over Self-attention:Intention-aware Re-ranking with Dynamic Transformer Encoders for Recommendation
Jan 14, 2022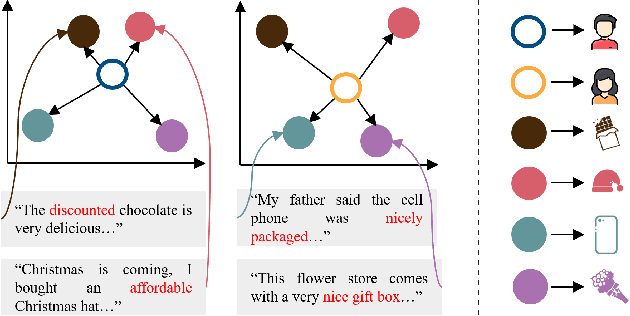
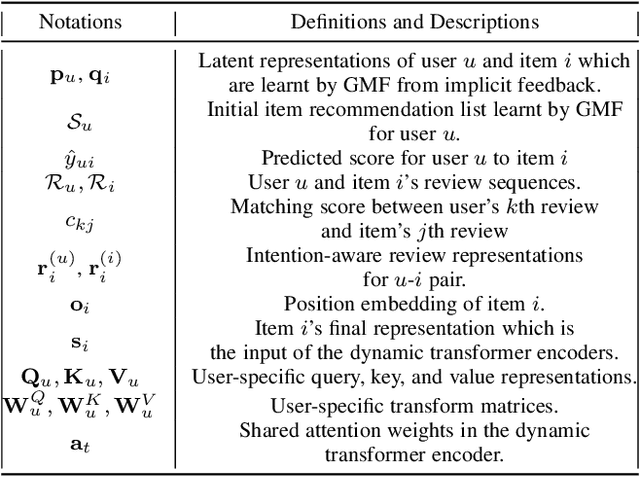
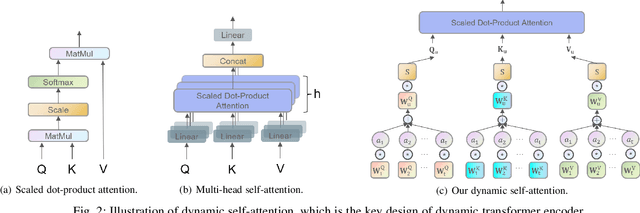
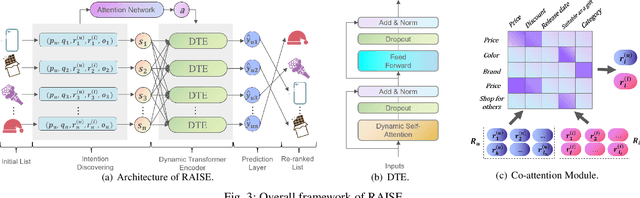
Re-ranking models refine the item recommendation list generated by the prior global ranking model with intra-item relationships. However, most existing re-ranking solutions refine recommendation list based on the implicit feedback with a shared re-ranking model, which regrettably ignore the intra-item relationships under diverse user intentions. In this paper, we propose a novel Intention-aware Re-ranking Model with Dynamic Transformer Encoder (RAISE), aiming to perform user-specific prediction for each target user based on her intentions. Specifically, we first propose to mine latent user intentions from text reviews with an intention discovering module (IDM). By differentiating the importance of review information with a co-attention network, the latent user intention can be explicitly modeled for each user-item pair. We then introduce a dynamic transformer encoder (DTE) to capture user-specific intra-item relationships among item candidates by seamlessly accommodating the learnt latent user intentions via IDM. As such, RAISE is able to perform user-specific prediction without increasing the depth (number of blocks) and width (number of heads) of the prediction model. Empirical study on four public datasets shows the superiority of our proposed RAISE, with up to 13.95%, 12.30%, and 13.03% relative improvements evaluated by Precision, MAP, and NDCG respectively.