 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploiting Domain-Specific Features to Enhance Domain Generalization
Oct 18, 2021

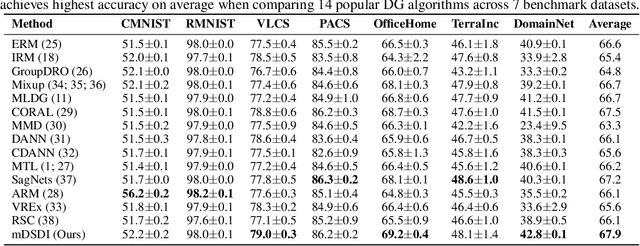

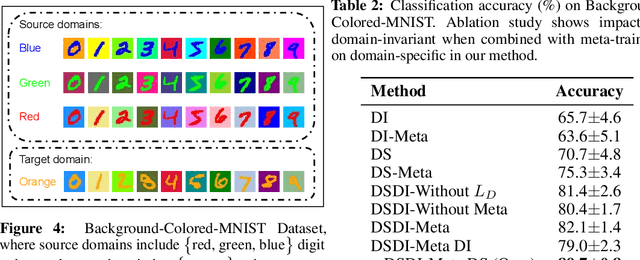
Domain Generalization (DG) aims to train a model, from multiple observed source domains, in order to perform well on unseen target domains. To obtain the generalization capability, prior DG approaches have focused on extracting domain-invariant information across sources to generalize on target domains, while useful domain-specific information which strongly correlates with labels in individual domains and the generalization to target domains is usually ignored. In this paper, we propose meta-Domain Specific-Domain Invariant (mDSDI) - a novel theoretically sound framework that extends beyond the invariance view to further capture the usefulness of domain-specific information. Our key insight is to disentangle features in the latent space while jointly learning both domain-invariant and domain-specific features in a unified framework. The domain-specific representation is optimized through the meta-learning framework to adapt from source domains, targeting a robust generalization on unseen domains. We empirically show that mDSDI provides competitive results with state-of-the-art techniques in DG. A further ablation study with our generated dataset, Background-Colored-MNIST, confirms the hypothesis that domain-specific is essential, leading to better results when compared with only using domain-invariant.
Conditional Information Gain Networks
Jul 25, 2018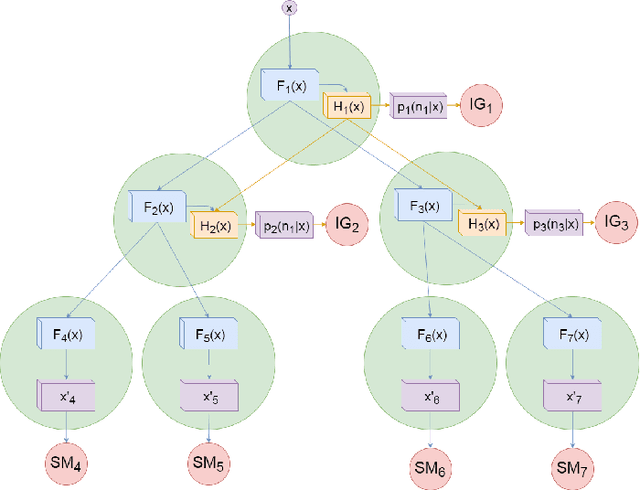
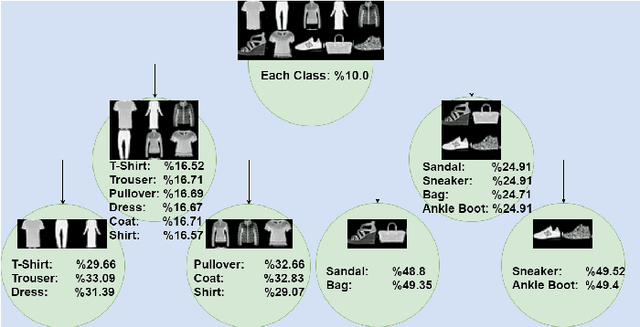
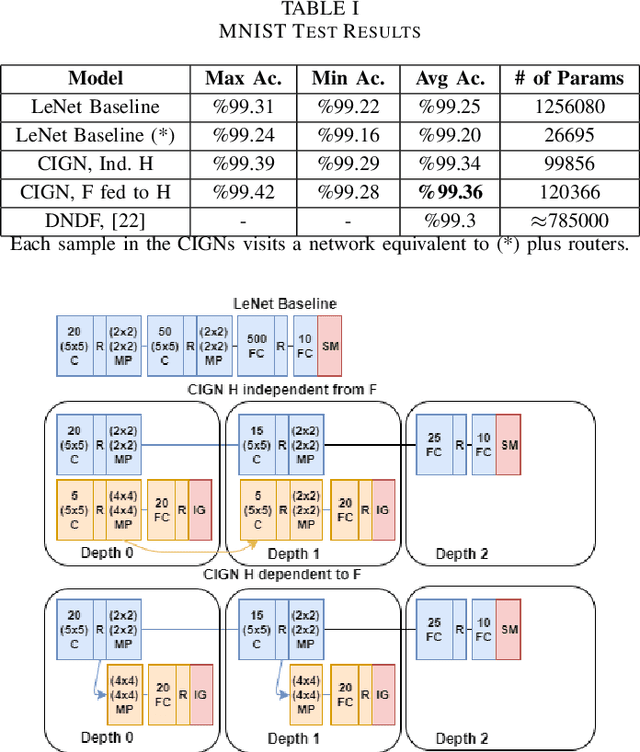
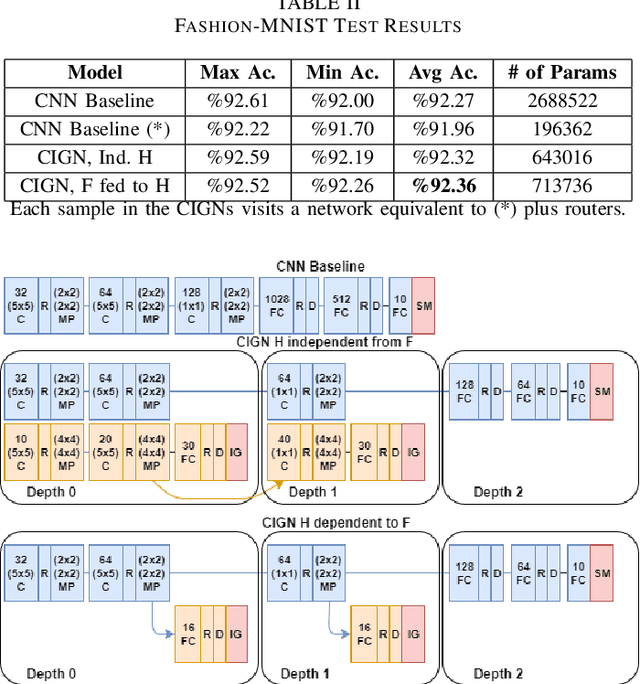
Deep neural network models owe their representational power to the high number of learnable parameters. It is often infeasible to run these largely parametrized deep models in limited resource environments, like mobile phones. Network models employing conditional computing are able to reduce computational requirements while achieving high representational power, with their ability to model hierarchies. We propose Conditional Information Gain Networks, which allow the feed forward deep neural networks to execute conditionally, skipping parts of the model based on the sample and the decision mechanisms inserted in the architecture. These decision mechanisms are trained using cost functions based on differentiable Information Gain, inspired by the training procedures of decision trees. These information gain based decision mechanisms are differentiable and can be trained end-to-end using a unified framework with a general cost function, covering both classification and decision losses. We test the effectiveness of the proposed method on MNIST and recently introduced Fashion MNIST datasets and show that our information gain based conditional execution approach can achieve better or comparable classification results using significantly fewer parameters, compared to standard convolutional neural network baselines.
Lifelong Dynamic Optimization for Self-Adaptive Systems: Fact or Fiction?
Jan 18, 2022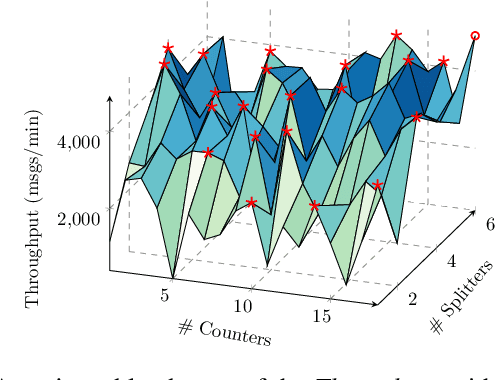
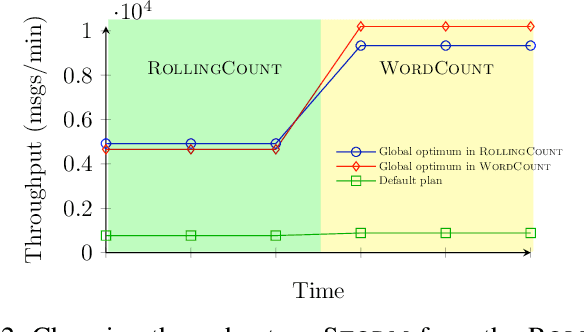
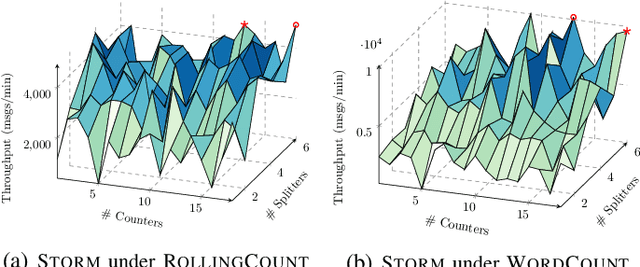
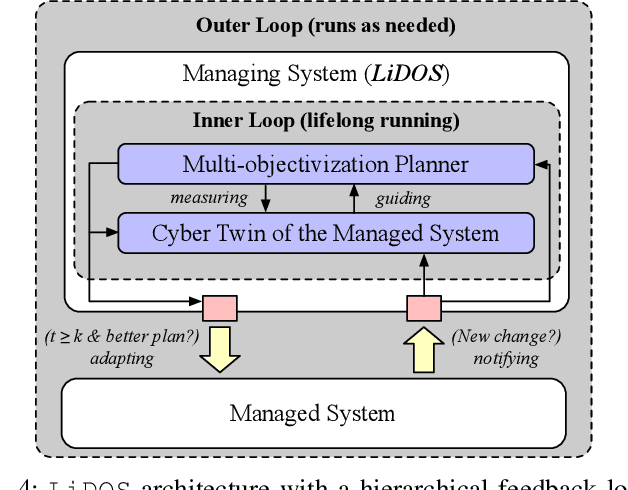
When faced with changing environment, highly configurable software systems need to dynamically search for promising adaptation plan that keeps the best possible performance, e.g., higher throughput or smaller latency -- a typical planning problem for self-adaptive systems (SASs). However, given the rugged and complex search landscape with multiple local optima, such a SAS planning is challenging especially in dynamic environments. In this paper, we propose LiDOS, a lifelong dynamic optimization framework for SAS planning. What makes LiDOS unique is that to handle the "dynamic", we formulate the SAS planning as a multi-modal optimization problem, aiming to preserve the useful information for better dealing with the local optima issue under dynamic environment changes. This differs from existing planners in that the "dynamic" is not explicitly handled during the search process in planning. As such, the search and planning in LiDOS run continuously over the lifetime of SAS, terminating only when it is taken offline or the search space has been covered under an environment. Experimental results on three real-world SASs show that the concept of explicitly handling dynamic as part of the search in the SAS planning is effective, as LiDOS outperforms its stationary counterpart overall with up to 10x improvement. It also achieves better results in general over state-of-the-art planners and with 1.4x to 10x speedup on generating promising adaptation plans.
Attention over Self-attention:Intention-aware Re-ranking with Dynamic Transformer Encoders for Recommendation
Jan 14, 2022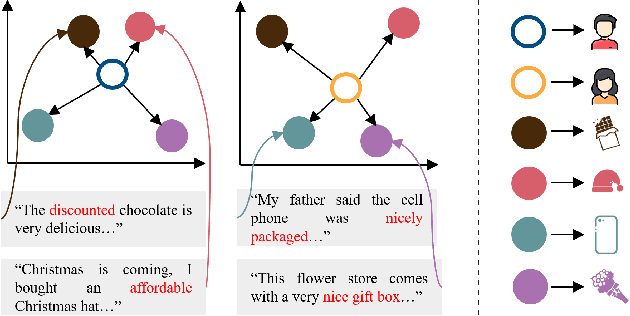
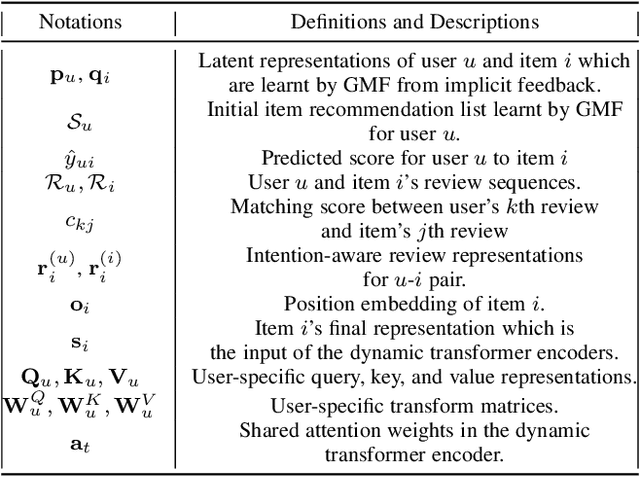
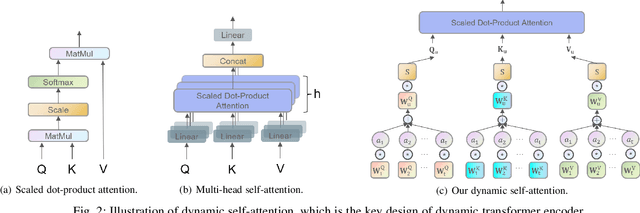
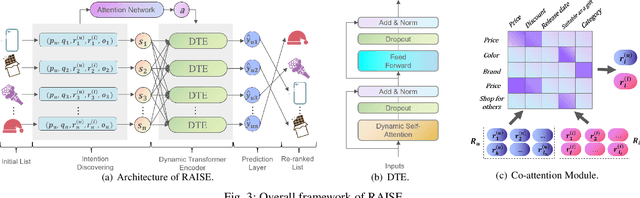
Re-ranking models refine the item recommendation list generated by the prior global ranking model with intra-item relationships. However, most existing re-ranking solutions refine recommendation list based on the implicit feedback with a shared re-ranking model, which regrettably ignore the intra-item relationships under diverse user intentions. In this paper, we propose a novel Intention-aware Re-ranking Model with Dynamic Transformer Encoder (RAISE), aiming to perform user-specific prediction for each target user based on her intentions. Specifically, we first propose to mine latent user intentions from text reviews with an intention discovering module (IDM). By differentiating the importance of review information with a co-attention network, the latent user intention can be explicitly modeled for each user-item pair. We then introduce a dynamic transformer encoder (DTE) to capture user-specific intra-item relationships among item candidates by seamlessly accommodating the learnt latent user intentions via IDM. As such, RAISE is able to perform user-specific prediction without increasing the depth (number of blocks) and width (number of heads) of the prediction model. Empirical study on four public datasets shows the superiority of our proposed RAISE, with up to 13.95%, 12.30%, and 13.03% relative improvements evaluated by Precision, MAP, and NDCG respectively.
Transformer-based Image Compression
Nov 12, 2021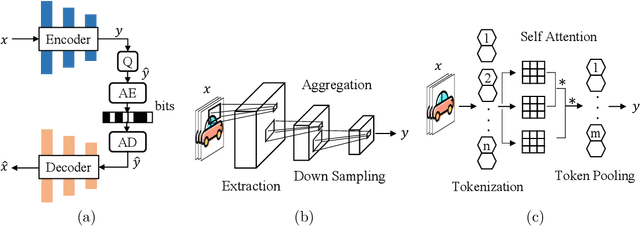
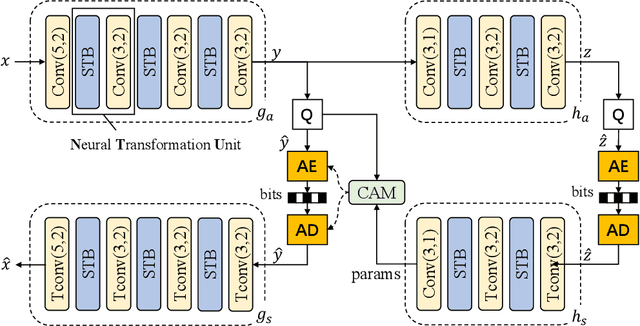
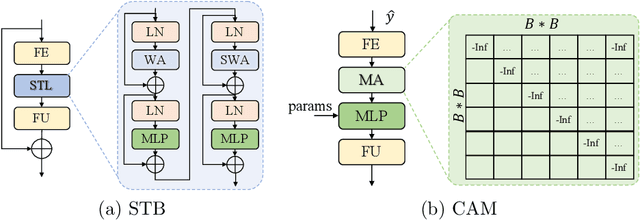

A Transformer-based Image Compression (TIC) approach is developed which reuses the canonical variational autoencoder (VAE) architecture with paired main and hyper encoder-decoders. Both main and hyper encoders are comprised of a sequence of neural transformation units (NTUs) to analyse and aggregate important information for more compact representation of input image, while the decoders mirror the encoder-side operations to generate pixel-domain image reconstruction from the compressed bitstream. Each NTU is consist of a Swin Transformer Block (STB) and a convolutional layer (Conv) to best embed both long-range and short-range information; In the meantime, a casual attention module (CAM) is devised for adaptive context modeling of latent features to utilize both hyper and autoregressive priors. The TIC rivals with state-of-the-art approaches including deep convolutional neural networks (CNNs) based learnt image coding (LIC) methods and handcrafted rules-based intra profile of recently-approved Versatile Video Coding (VVC) standard, and requires much less model parameters, e.g., up to 45% reduction to leading-performance LIC.
Improving GAN Equilibrium by Raising Spatial Awareness
Dec 01, 2021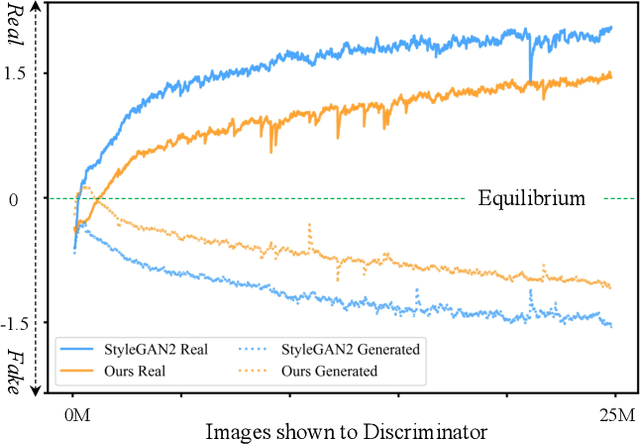
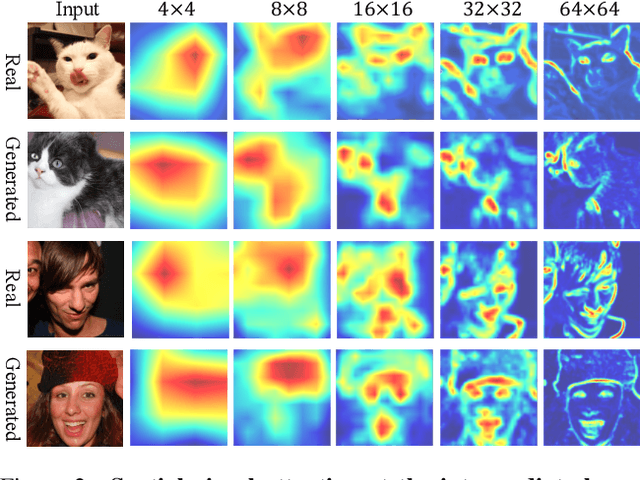

The success of Generative Adversarial Networks (GANs) is largely built upon the adversarial training between a generator (G) and a discriminator (D). They are expected to reach a certain equilibrium where D cannot distinguish the generated images from the real ones. However, in practice it is difficult to achieve such an equilibrium in GAN training, instead, D almost always surpasses G. We attribute this phenomenon to the information asymmetry between D and G. Specifically, we observe that D learns its own visual attention when determining whether an image is real or fake, but G has no explicit clue on which regions to focus on for a particular synthesis. To alleviate the issue of D dominating the competition in GANs, we aim to raise the spatial awareness of G. Randomly sampled multi-level heatmaps are encoded into the intermediate layers of G as an inductive bias. Thus G can purposefully improve the synthesis of certain image regions. We further propose to align the spatial awareness of G with the attention map induced from D. Through this way we effectively lessen the information gap between D and G. Extensive results show that our method pushes the two-player game in GANs closer to the equilibrium, leading to a better synthesis performance. As a byproduct, the introduced spatial awareness facilitates interactive editing over the output synthesis. Demo video and more results are at https://genforce.github.io/eqgan/.
Class-Aware Generative Adversarial Transformers for Medical Image Segmentation
Jan 26, 2022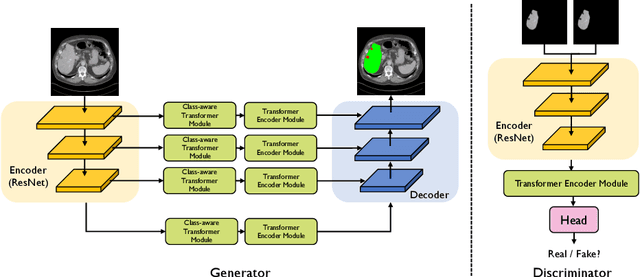
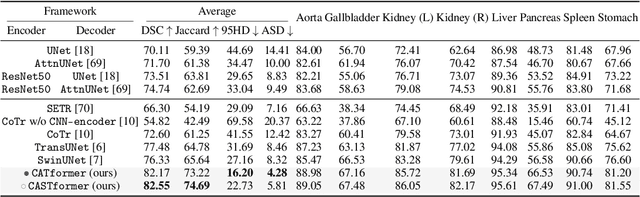
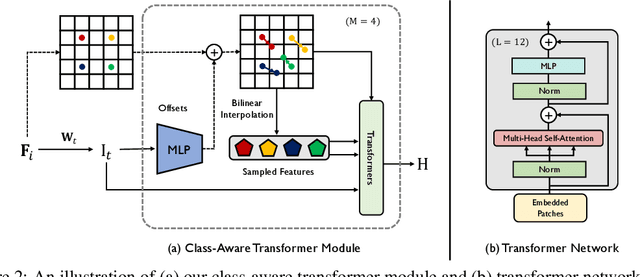
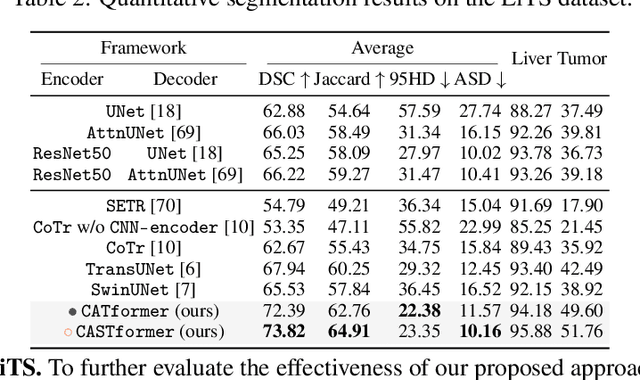
Transformers have made remarkable progress towards modeling long-range dependencies within the medical image analysis domain. However, current transformer-based models suffer from several disadvantages: 1) existing methods fail to capture the important features of the images due to the naive tokenization scheme; 2) the models suffer from information loss because they only consider single-scale feature representations; and 3) the segmentation label maps generated by the models are not accurate enough without considering rich semantic contexts and anatomical textures. In this work, we present CA-GANformer, a novel type of generative adversarial transformers, for medical image segmentation. First, we take advantage of the pyramid structure to construct multi-scale representations and handle multi-scale variations. We then design a novel class-aware transformer module to better learn the discriminative regions of objects with semantic structures. Lastly, we utilize an adversarial training strategy that boosts segmentation accuracy and correspondingly allows a transformer-based discriminator to capture high-level semantically correlated contents and low-level anatomical features. Our experiments demonstrate that CA-GANformer dramatically outperforms previous state-of-the-art transformer-based approaches on three benchmarks, obtaining absolute 2.54%-5.88% improvements in Dice over previous models. Further qualitative experiments provide a more detailed picture of the model's inner workings, shed light on the challenges in improved transparency, and demonstrate that transfer learning can greatly improve performance and reduce the size of medical image datasets in training, making CA-GANformer a strong starting point for downstream medical image analysis tasks. Codes and models will be available to the public.
Clustering Mixtures with Almost Optimal Separation in Polynomial Time
Dec 01, 2021We consider the problem of clustering mixtures of mean-separated Gaussians in high dimensions. We are given samples from a mixture of $k$ identity covariance Gaussians, so that the minimum pairwise distance between any two pairs of means is at least $\Delta$, for some parameter $\Delta > 0$, and the goal is to recover the ground truth clustering of these samples. It is folklore that separation $\Delta = \Theta (\sqrt{\log k})$ is both necessary and sufficient to recover a good clustering, at least information theoretically. However, the estimators which achieve this guarantee are inefficient. We give the first algorithm which runs in polynomial time, and which almost matches this guarantee. More precisely, we give an algorithm which takes polynomially many samples and time, and which can successfully recover a good clustering, so long as the separation is $\Delta = \Omega (\log^{1/2 + c} k)$, for any $c > 0$. Previously, polynomial time algorithms were only known for this problem when the separation was polynomial in $k$, and all algorithms which could tolerate $\textsf{poly}( \log k )$ separation required quasipolynomial time. We also extend our result to mixtures of translations of a distribution which satisfies the Poincar\'{e} inequality, under additional mild assumptions. Our main technical tool, which we believe is of independent interest, is a novel way to implicitly represent and estimate high degree moments of a distribution, which allows us to extract important information about high-degree moments without ever writing down the full moment tensors explicitly.
The cluster structure function
Jan 04, 2022
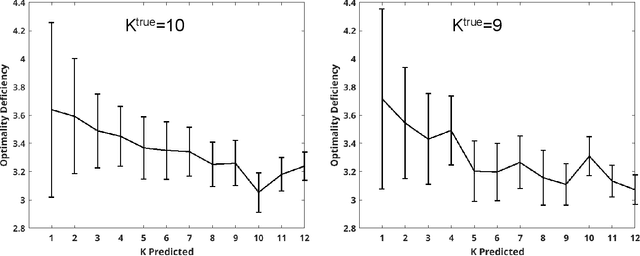
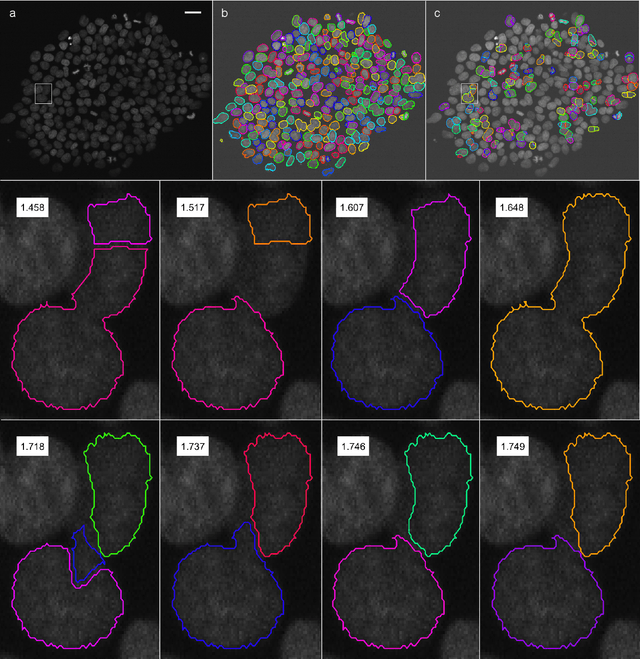
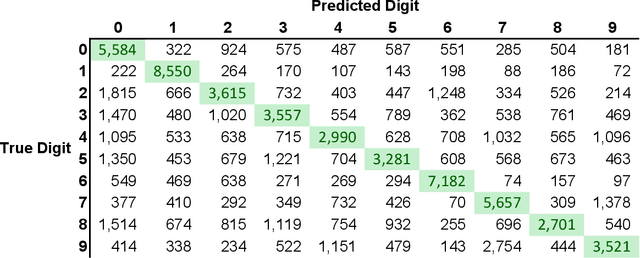
For each partition of a data set into a given number of parts there is a partition such that every part is as much as possible a good model (an "algorithmic sufficient statistic") for the data in that part. Since this can be done for every number between one and the number of data, the result is a function, the cluster structure function. It maps the number of parts of a partition to values related to the deficiencies of being good models by the parts. Such a function starts with a value at least zero for no partition of the data set and descents to zero for the partition of the data set into singleton parts. The optimal clustering is the one chosen to minimize the cluster structure function. The theory behind the method is expressed in algorithmic information theory (Kolmogorov complexity). In practice the Kolmogorov complexities involved are approximated by a concrete compressor. We give examples using real data sets: the MNIST handwritten digits and the segmentation of real cells as used in stem cell research.
Privacy-Aware Communication Over the Wiretap Channel with Generative Networks
Oct 08, 2021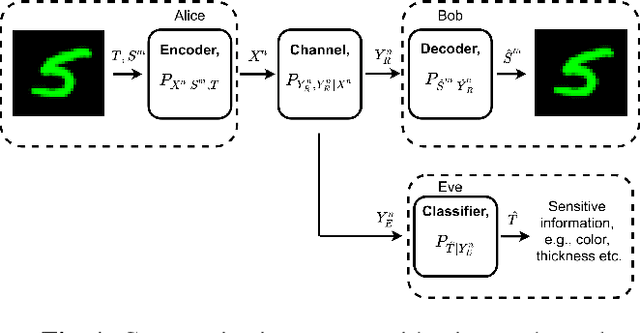
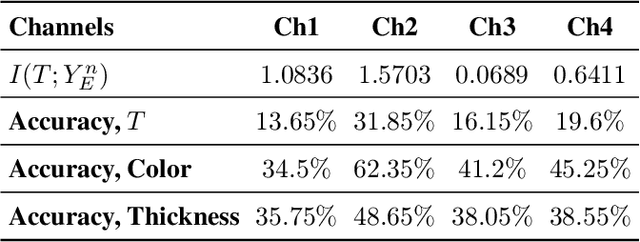
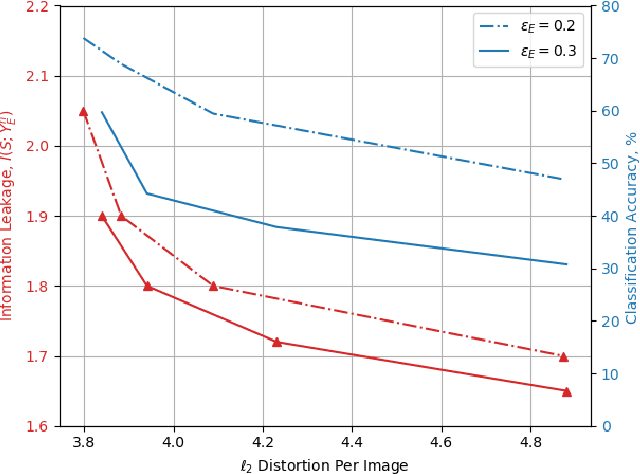

We study privacy-aware communication over a wiretap channel using end-to-end learning. Alice wants to transmit a source signal to Bob over a binary symmetric channel, while passive eavesdropper Eve tries to infer some sensitive attribute of Alice's source based on its overheard signal. Since we usually do not have access to true distributions, we propose a data-driven approach using variational autoencoder (VAE)-based joint source channel coding (JSCC). We show through simulations with the colored MNIST dataset that our approach provides high reconstruction quality at the receiver while confusing the eavesdropper about the latent sensitive attribute, which consists of the color and thickness of the digits. Finally, we consider a parallel-channel scenario, and show that our approach arranges the information transmission such that the channels with higher noise levels at the eavesdropper carry the sensitive information, while the non-sensitive information is transmitted over more vulnerable channels.