 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploiting Domain-Specific Features to Enhance Domain Generalization
Oct 18, 2021

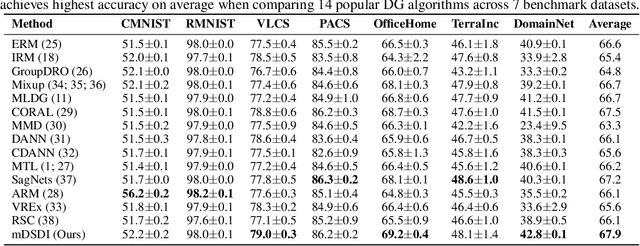

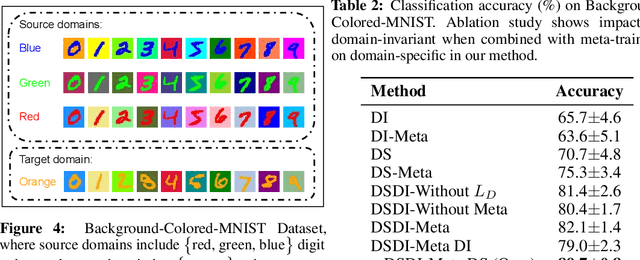
Domain Generalization (DG) aims to train a model, from multiple observed source domains, in order to perform well on unseen target domains. To obtain the generalization capability, prior DG approaches have focused on extracting domain-invariant information across sources to generalize on target domains, while useful domain-specific information which strongly correlates with labels in individual domains and the generalization to target domains is usually ignored. In this paper, we propose meta-Domain Specific-Domain Invariant (mDSDI) - a novel theoretically sound framework that extends beyond the invariance view to further capture the usefulness of domain-specific information. Our key insight is to disentangle features in the latent space while jointly learning both domain-invariant and domain-specific features in a unified framework. The domain-specific representation is optimized through the meta-learning framework to adapt from source domains, targeting a robust generalization on unseen domains. We empirically show that mDSDI provides competitive results with state-of-the-art techniques in DG. A further ablation study with our generated dataset, Background-Colored-MNIST, confirms the hypothesis that domain-specific is essential, leading to better results when compared with only using domain-invariant.
Mapping industrial poultry operations at scale with deep learning and aerial imagery
Dec 21, 2021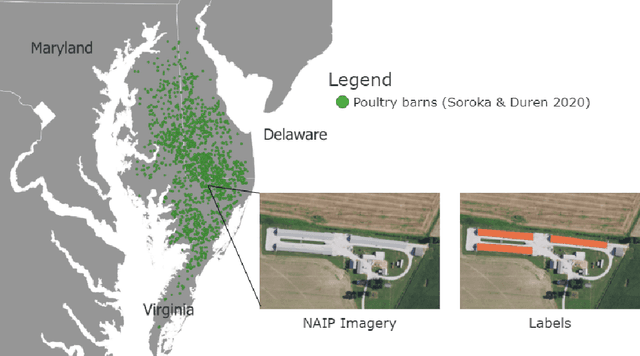
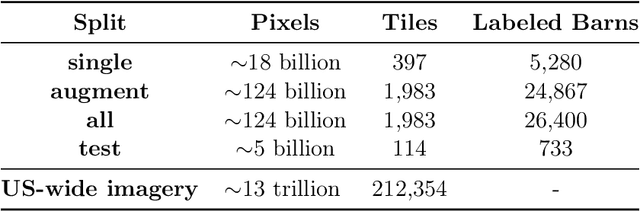
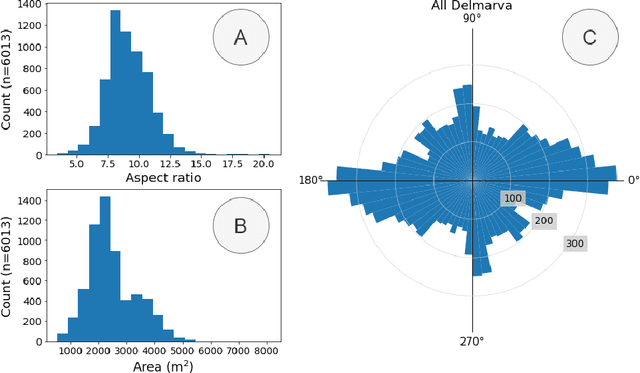
Concentrated Animal Feeding Operations (CAFOs) pose serious risks to air, water, and public health, but have proven to be challenging to regulate. The U.S. Government Accountability Office notes that a basic challenge is the lack of comprehensive location information on CAFOs. We use the USDA's National Agricultural Imagery Program (NAIP) 1m/pixel aerial imagery to detect poultry CAFOs across the continental United States. We train convolutional neural network (CNN) models to identify individual poultry barns and apply the best performing model to over 42 TB of imagery to create the first national, open-source dataset of poultry CAFOs. We validate the model predictions against held-out validation set on poultry CAFO facility locations from 10 hand-labeled counties in California and demonstrate that this approach has significant potential to fill gaps in environmental monitoring.
Privacy-Aware Communication Over the Wiretap Channel with Generative Networks
Oct 08, 2021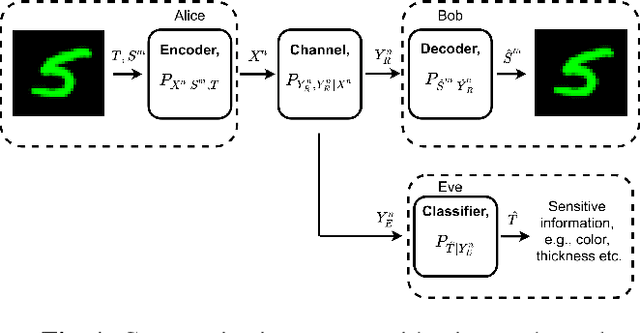
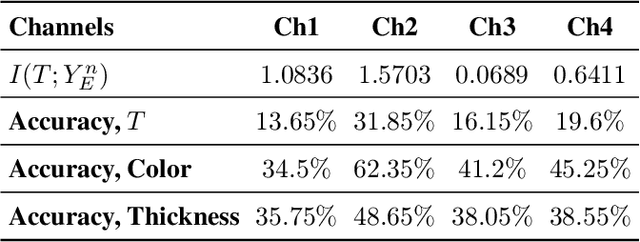
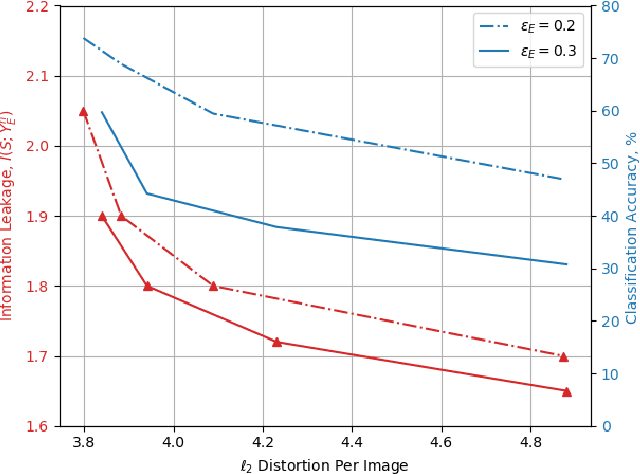

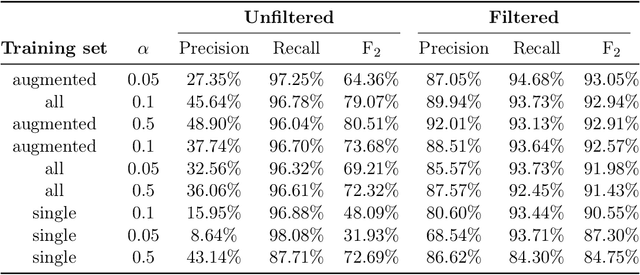
We study privacy-aware communication over a wiretap channel using end-to-end learning. Alice wants to transmit a source signal to Bob over a binary symmetric channel, while passive eavesdropper Eve tries to infer some sensitive attribute of Alice's source based on its overheard signal. Since we usually do not have access to true distributions, we propose a data-driven approach using variational autoencoder (VAE)-based joint source channel coding (JSCC). We show through simulations with the colored MNIST dataset that our approach provides high reconstruction quality at the receiver while confusing the eavesdropper about the latent sensitive attribute, which consists of the color and thickness of the digits. Finally, we consider a parallel-channel scenario, and show that our approach arranges the information transmission such that the channels with higher noise levels at the eavesdropper carry the sensitive information, while the non-sensitive information is transmitted over more vulnerable channels.
Skyline variations allow estimating distance to trees on landscape photos using semantic segmentation
Jan 14, 2022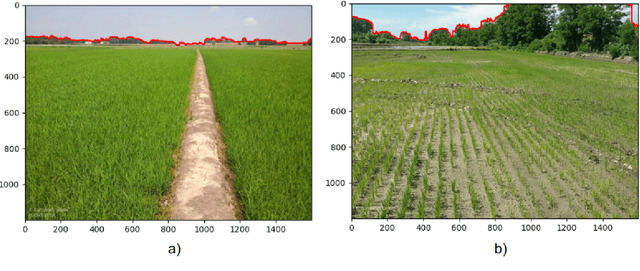
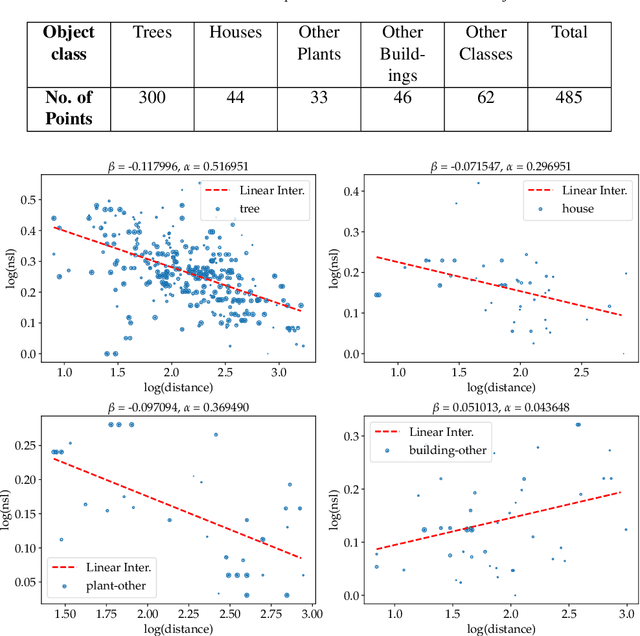
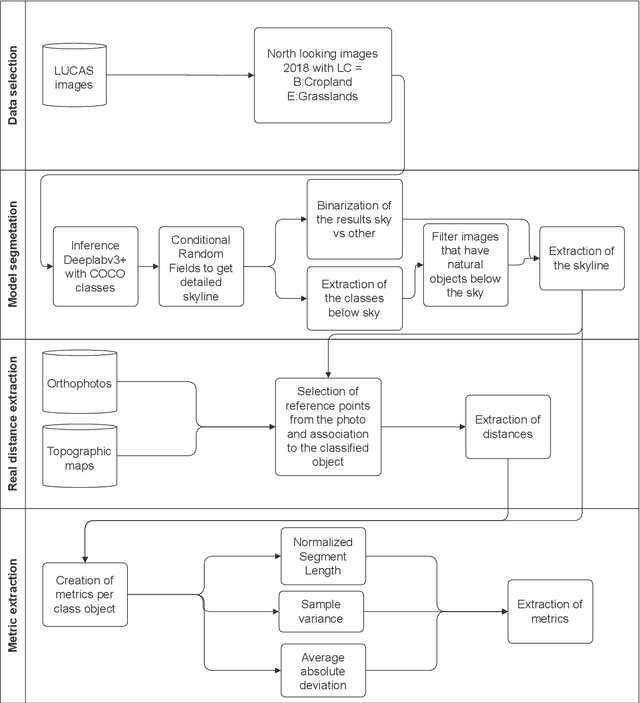

Approximate distance estimation can be used to determine fundamental landscape properties including complexity and openness. We show that variations in the skyline of landscape photos can be used to estimate distances to trees on the horizon. A methodology based on the variations of the skyline has been developed and used to investigate potential relationships with the distance to skyline objects. The skyline signal, defined by the skyline height expressed in pixels, was extracted for several Land Use/Cover Area frame Survey (LUCAS) landscape photos. Photos were semantically segmented with DeepLabV3+ trained with the Common Objects in Context (COCO) dataset. This provided pixel-level classification of the objects forming the skyline. A Conditional Random Fields (CRF) algorithm was also applied to increase the details of the skyline signal. Three metrics, able to capture the skyline signal variations, were then considered for the analysis. These metrics shows a functional relationship with distance for the class of trees, whose contours have a fractal nature. In particular, regression analysis was performed against 475 ortho-photo based distance measurements, and, in the best case, a R2 score equal to 0.47 was achieved. This is an encouraging result which shows the potential of skyline variation metrics for inferring distance related information.
Deep Task-Based Analog-to-Digital Conversion
Jan 29, 2022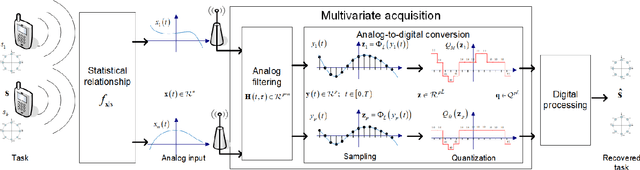
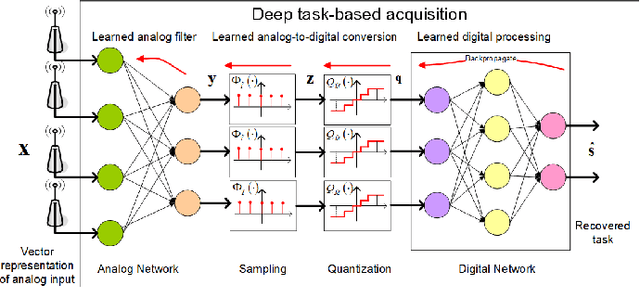
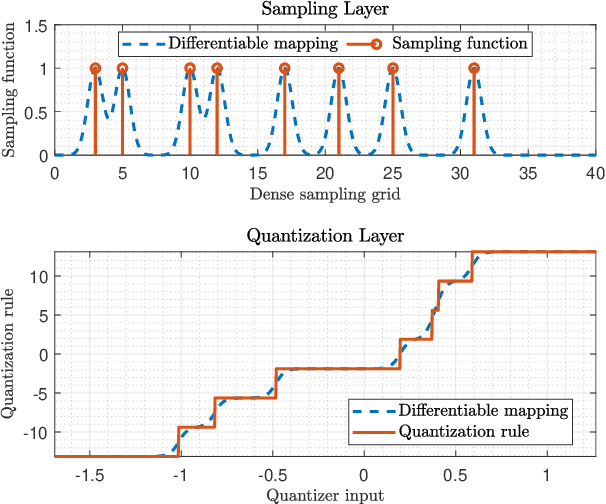
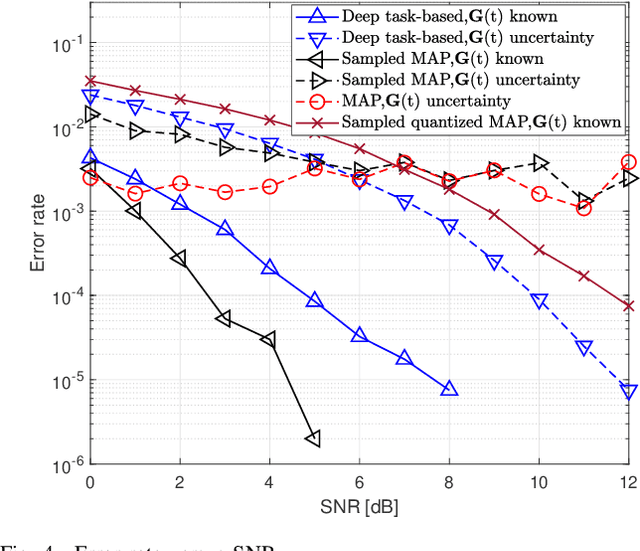
Analog-to-digital converters (ADCs) allow physical signals to be processed using digital hardware. Their conversion consists of two stages: Sampling, which maps a continuous-time signal into discrete-time, and quantization, i.e., representing the continuous-amplitude quantities using a finite number of bits. ADCs typically implement generic uniform conversion mappings that are ignorant of the task for which the signal is acquired, and can be costly when operating in high rates and fine resolutions. In this work we design task-oriented ADCs which learn from data how to map an analog signal into a digital representation such that the system task can be efficiently carried out. We propose a model for sampling and quantization that facilitates the learning of non-uniform mappings from data. Based on this learnable ADC mapping, we present a mechanism for optimizing a hybrid acquisition system comprised of analog combining, tunable ADCs with fixed rates, and digital processing, by jointly learning its components end-to-end. Then, we show how one can exploit the representation of hybrid acquisition systems as deep network to optimize the sampling rate and quantization rate given the task by utilizing Bayesian meta-learning techniques. We evaluate the proposed deep task-based ADC in two case studies: the first considers symbol detection in multi-antenna digital receivers, where multiple analog signals are simultaneously acquired in order to recover a set of discrete information symbols. The second application is the beamforming of analog channel data acquired in ultrasound imaging. Our numerical results demonstrate that the proposed approach achieves performance which is comparable to operating with high sampling rates and fine resolution quantization, while operating with reduced overall bit rate.
Transformer-based Image Compression
Nov 12, 2021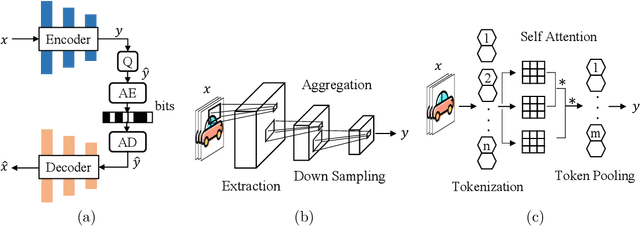
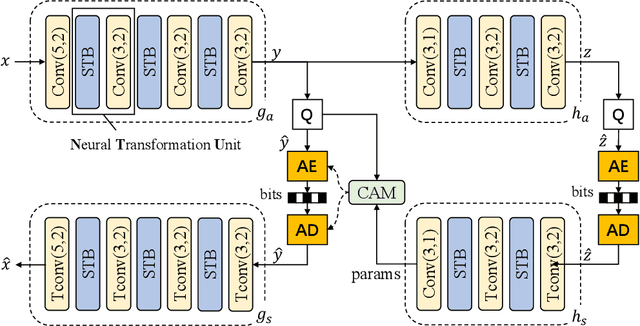
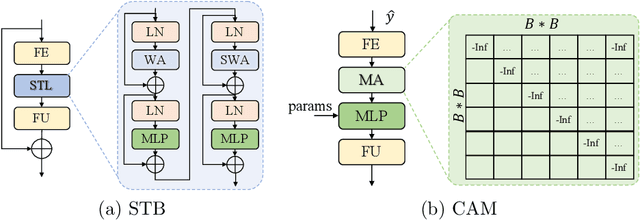

A Transformer-based Image Compression (TIC) approach is developed which reuses the canonical variational autoencoder (VAE) architecture with paired main and hyper encoder-decoders. Both main and hyper encoders are comprised of a sequence of neural transformation units (NTUs) to analyse and aggregate important information for more compact representation of input image, while the decoders mirror the encoder-side operations to generate pixel-domain image reconstruction from the compressed bitstream. Each NTU is consist of a Swin Transformer Block (STB) and a convolutional layer (Conv) to best embed both long-range and short-range information; In the meantime, a casual attention module (CAM) is devised for adaptive context modeling of latent features to utilize both hyper and autoregressive priors. The TIC rivals with state-of-the-art approaches including deep convolutional neural networks (CNNs) based learnt image coding (LIC) methods and handcrafted rules-based intra profile of recently-approved Versatile Video Coding (VVC) standard, and requires much less model parameters, e.g., up to 45% reduction to leading-performance LIC.
Lifelong Dynamic Optimization for Self-Adaptive Systems: Fact or Fiction?
Jan 18, 2022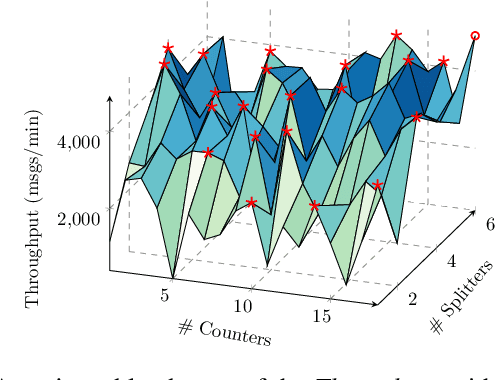
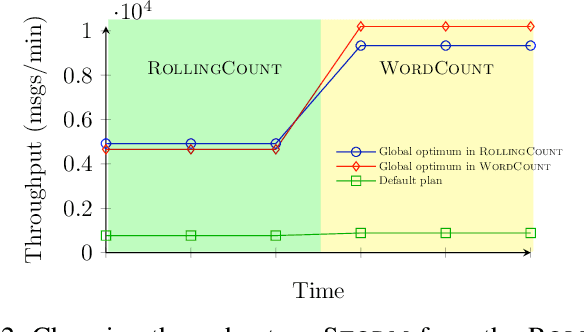
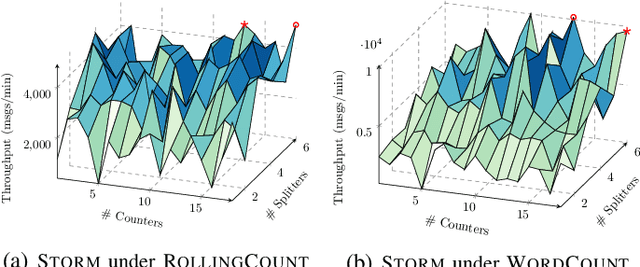
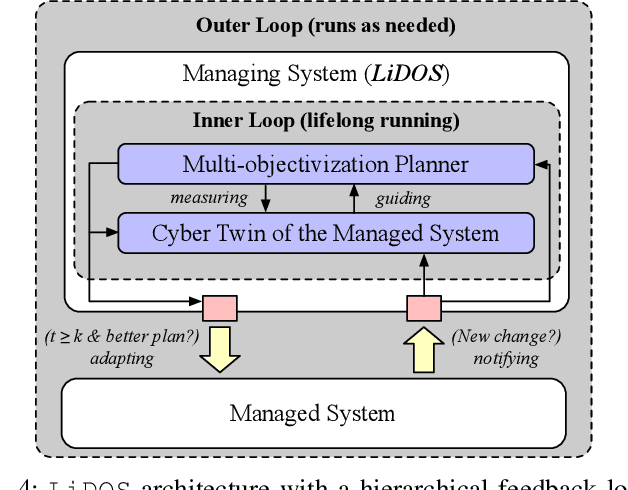
When faced with changing environment, highly configurable software systems need to dynamically search for promising adaptation plan that keeps the best possible performance, e.g., higher throughput or smaller latency -- a typical planning problem for self-adaptive systems (SASs). However, given the rugged and complex search landscape with multiple local optima, such a SAS planning is challenging especially in dynamic environments. In this paper, we propose LiDOS, a lifelong dynamic optimization framework for SAS planning. What makes LiDOS unique is that to handle the "dynamic", we formulate the SAS planning as a multi-modal optimization problem, aiming to preserve the useful information for better dealing with the local optima issue under dynamic environment changes. This differs from existing planners in that the "dynamic" is not explicitly handled during the search process in planning. As such, the search and planning in LiDOS run continuously over the lifetime of SAS, terminating only when it is taken offline or the search space has been covered under an environment. Experimental results on three real-world SASs show that the concept of explicitly handling dynamic as part of the search in the SAS planning is effective, as LiDOS outperforms its stationary counterpart overall with up to 10x improvement. It also achieves better results in general over state-of-the-art planners and with 1.4x to 10x speedup on generating promising adaptation plans.
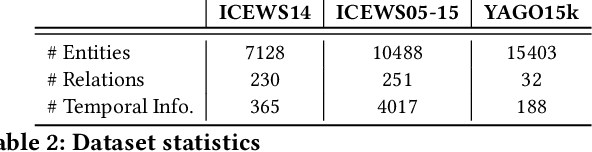
MIRA: Multihop Relation Prediction in Temporal Knowledge Graphs
Oct 27, 2021
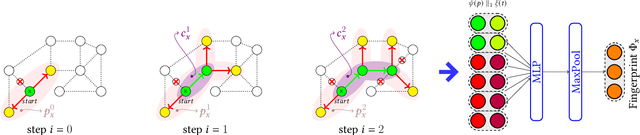
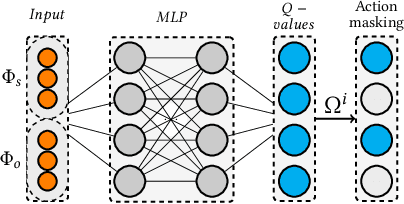
In knowledge graph reasoning, we observe a trend to analyze temporal data evolving over time. The additional temporal dimension is attached to facts in a knowledge base resulting in quadruples between entities such as (Nintendo, released, Super Mario, Sep-13-1985), where the relation between two entities is associated to a specific time interval or point in time. Multi-hop reasoning on inferred subgraphs connecting entities within a knowledge graph can be formulated as a reinforcement learning task where the agent sequentially performs inference upon the explored subgraph. The task in this work is to infer the predicate between a subject and an object entity, i.e., (subject, ?, object, time), being valid at a certain timestamp or time interval. Given query entities, our agent starts to gather temporal relevant information about the neighborhood of the subject and object. The encoding of information about the explored graph structures is referred to as fingerprints. Subsequently, we use the two fingerprints as input to a Q-Network. Our agent decides sequentially which relational type needs to be explored next expanding the local subgraphs of the query entities in order to find promising paths between them. The evaluation shows that the proposed method not only yields results being in line with state-of-the-art embedding algorithms for temporal Knowledge Graphs (tKG), but we also gain information about the relevant structures between subjects and objects.
Improving GAN Equilibrium by Raising Spatial Awareness
Dec 01, 2021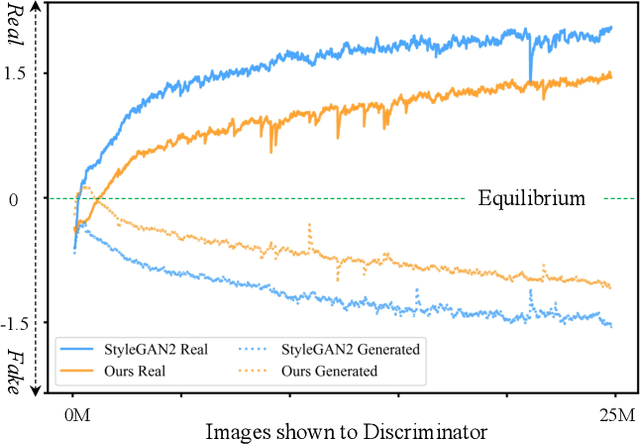
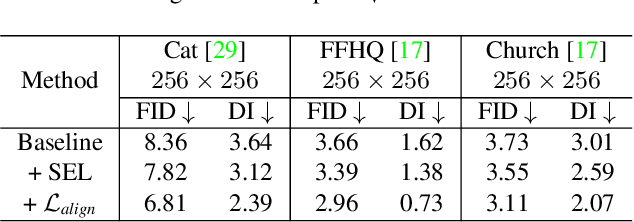
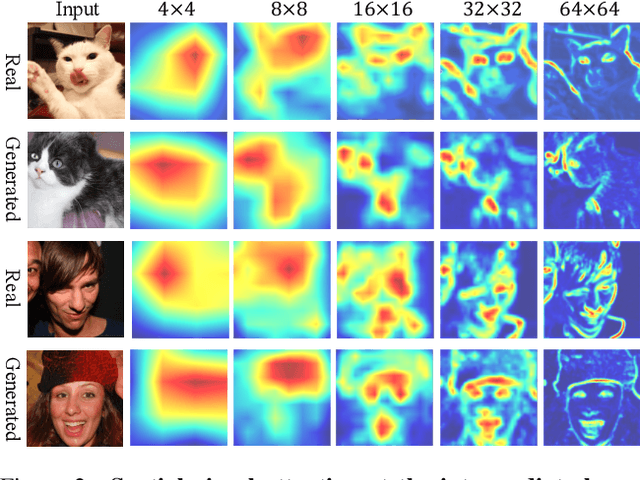

The success of Generative Adversarial Networks (GANs) is largely built upon the adversarial training between a generator (G) and a discriminator (D). They are expected to reach a certain equilibrium where D cannot distinguish the generated images from the real ones. However, in practice it is difficult to achieve such an equilibrium in GAN training, instead, D almost always surpasses G. We attribute this phenomenon to the information asymmetry between D and G. Specifically, we observe that D learns its own visual attention when determining whether an image is real or fake, but G has no explicit clue on which regions to focus on for a particular synthesis. To alleviate the issue of D dominating the competition in GANs, we aim to raise the spatial awareness of G. Randomly sampled multi-level heatmaps are encoded into the intermediate layers of G as an inductive bias. Thus G can purposefully improve the synthesis of certain image regions. We further propose to align the spatial awareness of G with the attention map induced from D. Through this way we effectively lessen the information gap between D and G. Extensive results show that our method pushes the two-player game in GANs closer to the equilibrium, leading to a better synthesis performance. As a byproduct, the introduced spatial awareness facilitates interactive editing over the output synthesis. Demo video and more results are at https://genforce.github.io/eqgan/.
Dynamic Coherence-Based EM Ray Tracing Simulations in Vehicular Environments
Dec 14, 2021
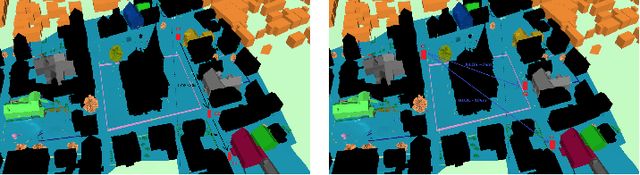
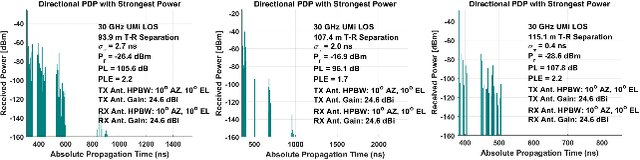
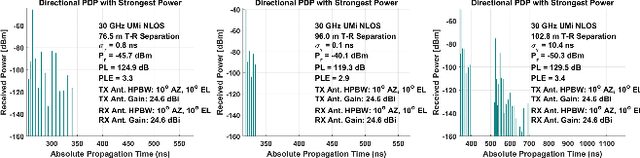
5G applications have become increasingly popular in recent years as the spread of 5G network deployment has grown. For vehicular networks, mmWave band signals have been well studied and used for communication and sensing. In this work, we propose a new dynamic ray tracing algorithm that exploits spatial and temporal coherence. We evaluate the performance by comparing the results on typical vehicular communication scenarios with NYUSIM, which builds on stochastic models, and Winprop, which utilizes the deterministic model for simulations with given environment information. We compare the performance of our algorithm on complex, urban models and observe the reduction in computation time by 60% compared to NYUSIM and 30% compared to Winprop, while maintaining similar prediction accuracy.