 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Joint Learning of Linear Time-Invariant Dynamical Systems
Dec 22, 2021
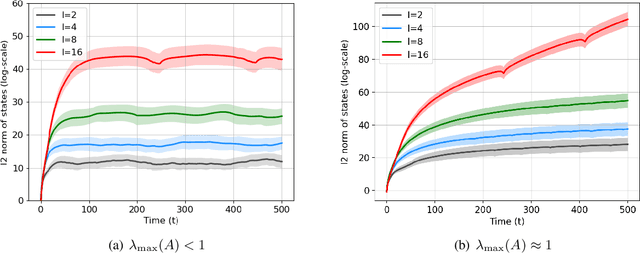
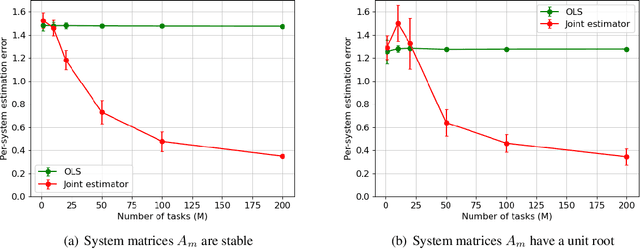
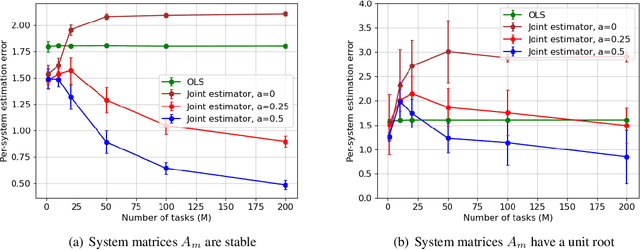
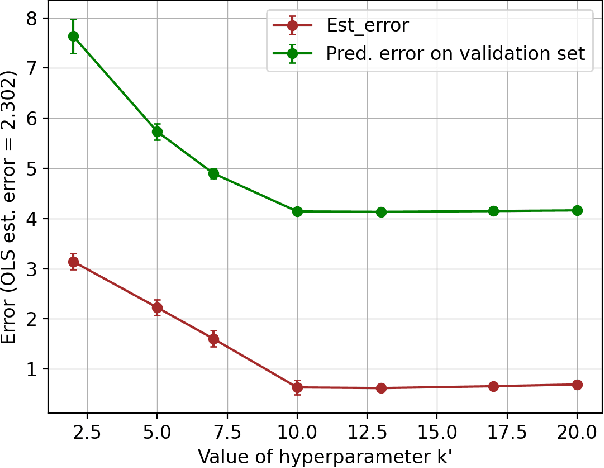
Learning the parameters of a linear time-invariant dynamical system (LTIDS) is a problem of current interest. In many applications, one is interested in jointly learning the parameters of multiple related LTIDS, which remains unexplored to date. To that end, we develop a joint estimator for learning the transition matrices of LTIDS that share common basis matrices. Further, we establish finite-time error bounds that depend on the underlying sample size, dimension, number of tasks, and spectral properties of the transition matrices. The results are obtained under mild regularity assumptions and showcase the gains from pooling information across LTIDS, in comparison to learning each system separately. We also study the impact of misspecifying the joint structure of the transition matrices and show that the established results are robust in the presence of moderate misspecifications.
Tailor Versatile Multi-modal Learning for Multi-label Emotion Recognition
Jan 15, 2022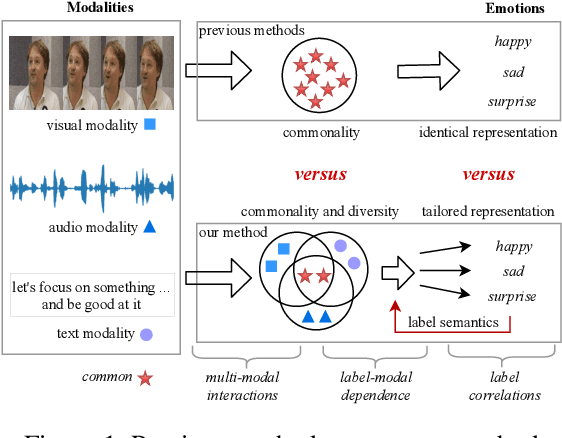

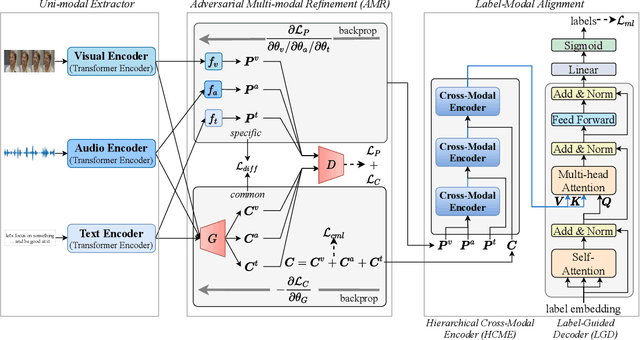
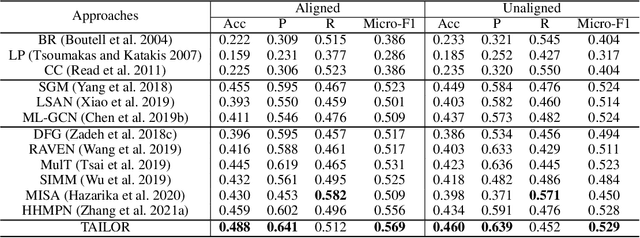
Multi-modal Multi-label Emotion Recognition (MMER) aims to identify various human emotions from heterogeneous visual, audio and text modalities. Previous methods mainly focus on projecting multiple modalities into a common latent space and learning an identical representation for all labels, which neglects the diversity of each modality and fails to capture richer semantic information for each label from different perspectives. Besides, associated relationships of modalities and labels have not been fully exploited. In this paper, we propose versaTile multi-modAl learning for multI-labeL emOtion Recognition (TAILOR), aiming to refine multi-modal representations and enhance discriminative capacity of each label. Specifically, we design an adversarial multi-modal refinement module to sufficiently explore the commonality among different modalities and strengthen the diversity of each modality. To further exploit label-modal dependence, we devise a BERT-like cross-modal encoder to gradually fuse private and common modality representations in a granularity descent way, as well as a label-guided decoder to adaptively generate a tailored representation for each label with the guidance of label semantics. In addition, we conduct experiments on the benchmark MMER dataset CMU-MOSEI in both aligned and unaligned settings, which demonstrate the superiority of TAILOR over the state-of-the-arts. Code is available at https://github.com/kniter1/TAILOR.
Geometry-Entangled Visual Semantic Transformer for Image Captioning
Sep 29, 2021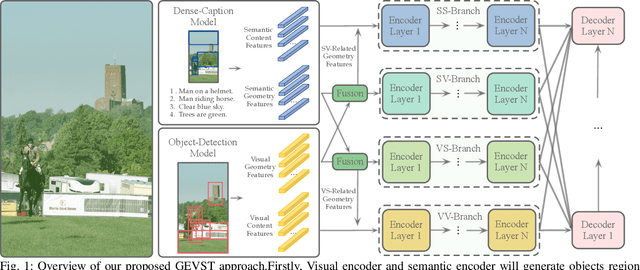
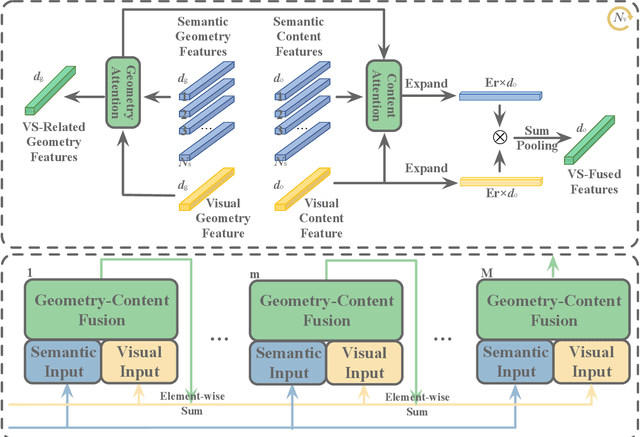
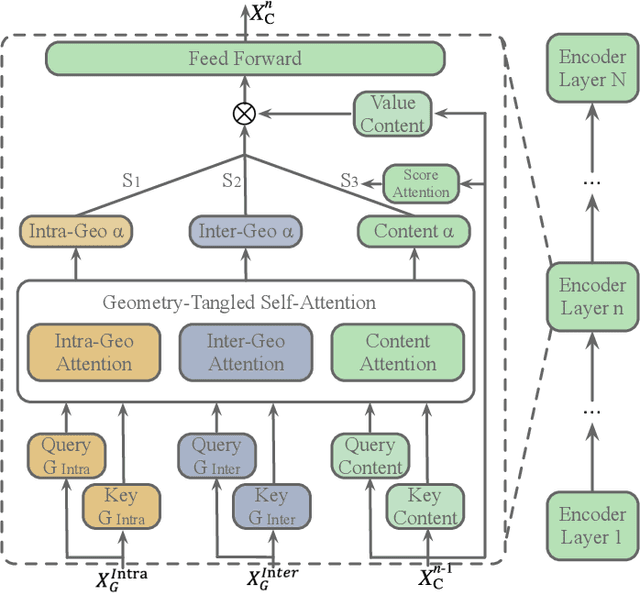
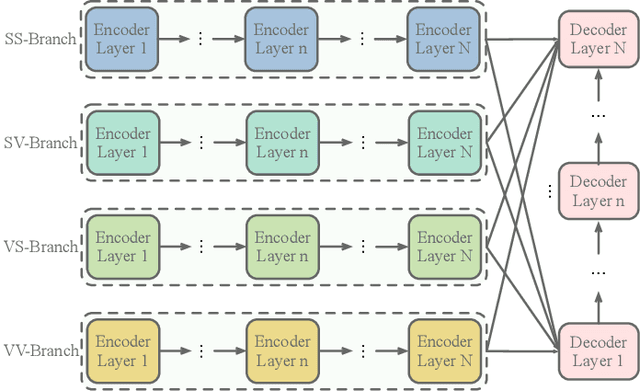
Recent advancements of image captioning have featured Visual-Semantic Fusion or Geometry-Aid attention refinement. However, those fusion-based models, they are still criticized for the lack of geometry information for inter and intra attention refinement. On the other side, models based on Geometry-Aid attention still suffer from the modality gap between visual and semantic information. In this paper, we introduce a novel Geometry-Entangled Visual Semantic Transformer (GEVST) network to realize the complementary advantages of Visual-Semantic Fusion and Geometry-Aid attention refinement. Concretely, a Dense-Cap model proposes some dense captions with corresponding geometry information at first. Then, to empower GEVST with the ability to bridge the modality gap among visual and semantic information, we build four parallel transformer encoders VV(Pure Visual), VS(Semantic fused to Visual), SV(Visual fused to Semantic), SS(Pure Semantic) for final caption generation. Both visual and semantic geometry features are used in the Fusion module and also the Self-Attention module for better attention measurement. To validate our model, we conduct extensive experiments on the MS-COCO dataset, the experimental results show that our GEVST model can obtain promising performance gains.
Random Style Transfer based Domain Generalization Networks Integrating Shape and Spatial Information
Sep 03, 2020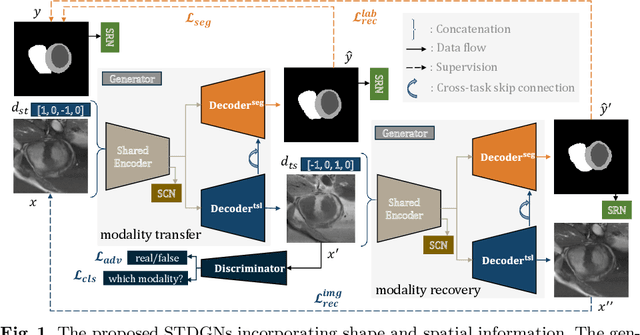
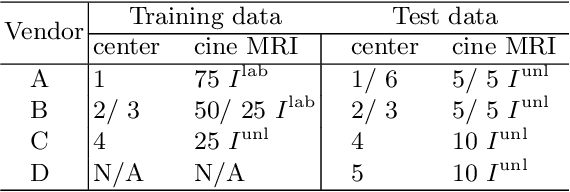
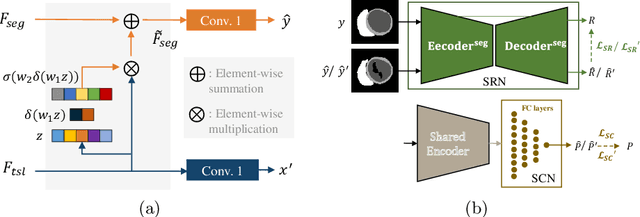
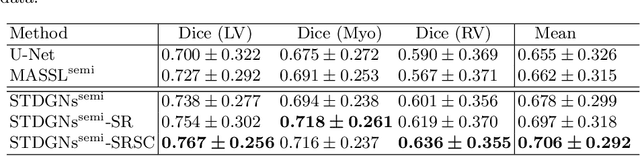
Deep learning (DL)-based models have demonstrated good performance in medical image segmentation. However, the models trained on a known dataset often fail when performed on an unseen dataset collected from different centers, vendors and disease populations. In this work, we present a random style transfer network to tackle the domain generalization problem for multi-vendor and center cardiac image segmentation. Style transfer is used to generate training data with a wider distribution/ heterogeneity, namely domain augmentation. As the target domain could be unknown, we randomly generate a modality vector for the target modality in the style transfer stage, to simulate the domain shift for unknown domains. The model can be trained in a semi-supervised manner by simultaneously optimizing a supervised segmentation and an unsupervised style translation objective. Besides, the framework incorporates the spatial information and shape prior of the target by introducing two regularization terms. We evaluated the proposed framework on 40 subjects from the M\&Ms challenge2020, and obtained promising performance in the segmentation for data from unknown vendors and centers.
Towards Intelligibility-Oriented Audio-Visual Speech Enhancement
Nov 18, 2021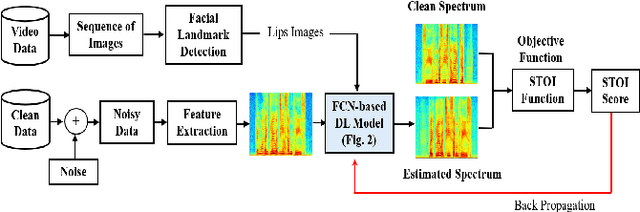
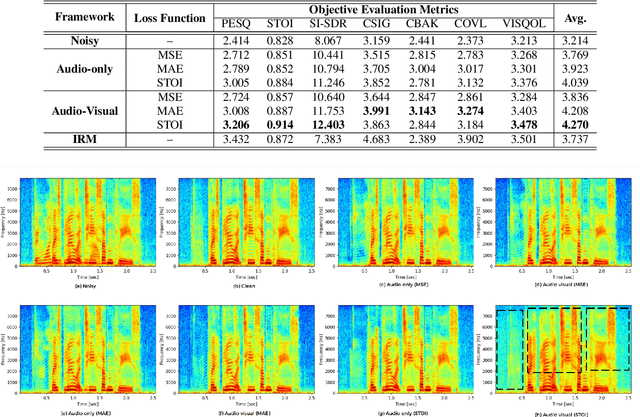
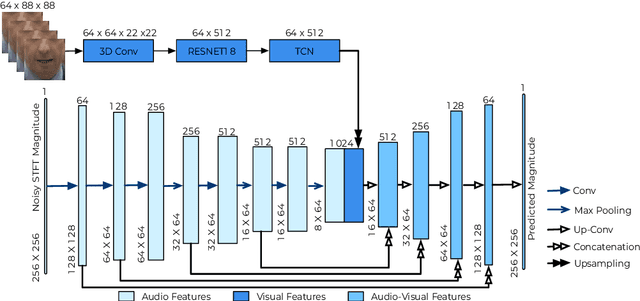
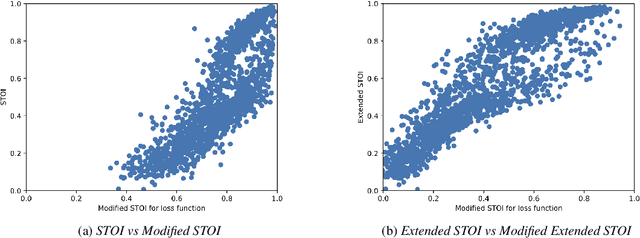
Existing deep learning (DL) based speech enhancement approaches are generally optimised to minimise the distance between clean and enhanced speech features. These often result in improved speech quality however they suffer from a lack of generalisation and may not deliver the required speech intelligibility in real noisy situations. In an attempt to address these challenges, researchers have explored intelligibility-oriented (I-O) loss functions and integration of audio-visual (AV) information for more robust speech enhancement (SE). In this paper, we introduce DL based I-O SE algorithms exploiting AV information, which is a novel and previously unexplored research direction. Specifically, we present a fully convolutional AV SE model that uses a modified short-time objective intelligibility (STOI) metric as a training cost function. To the best of our knowledge, this is the first work that exploits the integration of AV modalities with an I-O based loss function for SE. Comparative experimental results demonstrate that our proposed I-O AV SE framework outperforms audio-only (AO) and AV models trained with conventional distance-based loss functions, in terms of standard objective evaluation measures when dealing with unseen speakers and noises.
Non-linear Motion Estimation for Video Frame Interpolation using Space-time Convolutions
Jan 27, 2022Video frame interpolation aims to synthesize one or multiple frames between two consecutive frames in a video. It has a wide range of applications including slow-motion video generation, frame-rate up-scaling and developing video codecs. Some older works tackled this problem by assuming per-pixel linear motion between video frames. However, objects often follow a non-linear motion pattern in the real domain and some recent methods attempt to model per-pixel motion by non-linear models (e.g., quadratic). A quadratic model can also be inaccurate, especially in the case of motion discontinuities over time (i.e. sudden jerks) and occlusions, where some of the flow information may be invalid or inaccurate. In our paper, we propose to approximate the per-pixel motion using a space-time convolution network that is able to adaptively select the motion model to be used. Specifically, we are able to softly switch between a linear and a quadratic model. Towards this end, we use an end-to-end 3D CNN encoder-decoder architecture over bidirectional optical flows and occlusion maps to estimate the non-linear motion model of each pixel. Further, a motion refinement module is employed to refine the non-linear motion and the interpolated frames are estimated by a simple warping of the neighboring frames with the estimated per-pixel motion. Through a set of comprehensive experiments, we validate the effectiveness of our model and show that our method outperforms state-of-the-art algorithms on four datasets (Vimeo, DAVIS, HD and GoPro).
Stable and Compact Face Recognition via Unlabeled Data Driven Sparse Representation-Based Classification
Nov 04, 2021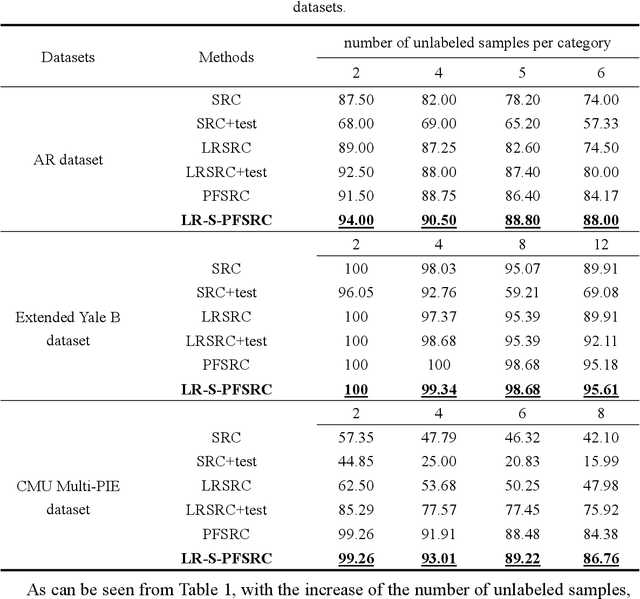
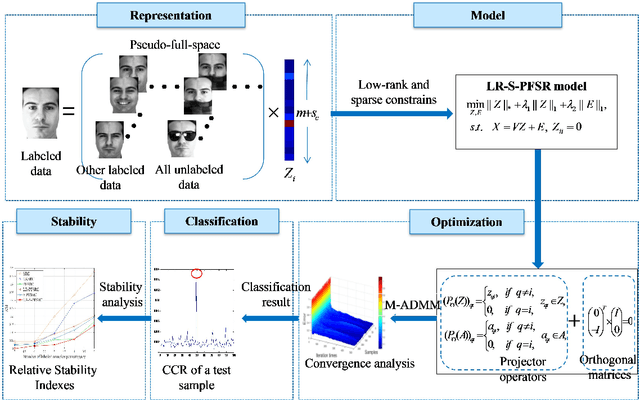
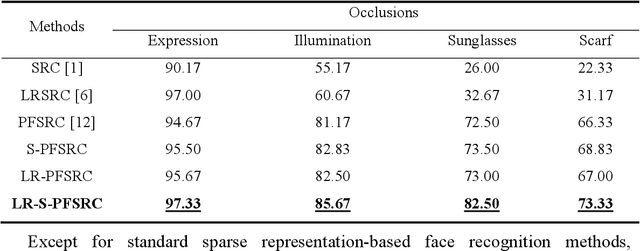

Sparse representation-based classification (SRC) has attracted much attention by casting the recognition problem as simple linear regression problem. SRC methods, however, still is limited to enough labeled samples per category, insufficient use of unlabeled samples, and instability of representation. For tackling these problems, an unlabeled data driven inverse projection pseudo-full-space representation-based classification model is proposed with low-rank sparse constraints. The proposed model aims to mine the hidden semantic information and intrinsic structure information of all available data, which is suitable for few labeled samples and proportion imbalance between labeled samples and unlabeled samples problems in frontal face recognition. The mixed Gauss-Seidel and Jacobian ADMM algorithm is introduced to solve the model. The convergence, representation capability and stability of the model are analyzed. Experiments on three public datasets show that the proposed LR-S-PFSRC model achieves stable results, especially for proportion imbalance of samples.
Semantic Answer Type and Relation Prediction Task (SMART 2021)
Jan 10, 2022
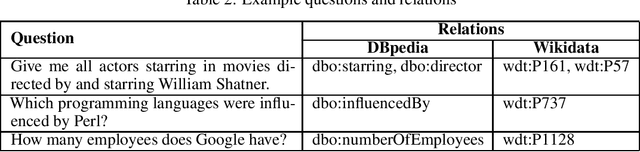
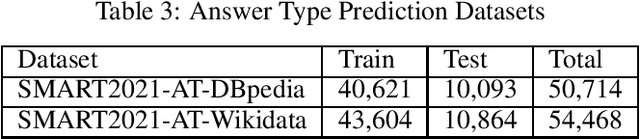
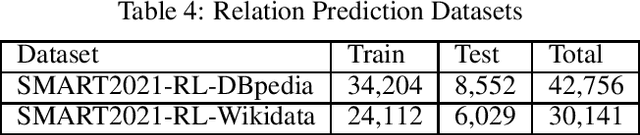
Each year the International Semantic Web Conference organizes a set of Semantic Web Challenges to establish competitions that will advance state-of-the-art solutions in some problem domains. The Semantic Answer Type and Relation Prediction Task (SMART) task is one of the ISWC 2021 Semantic Web challenges. This is the second year of the challenge after a successful SMART 2020 at ISWC 2020. This year's version focuses on two sub-tasks that are very important to Knowledge Base Question Answering (KBQA): Answer Type Prediction and Relation Prediction. Question type and answer type prediction can play a key role in knowledge base question answering systems providing insights about the expected answer that are helpful to generate correct queries or rank the answer candidates. More concretely, given a question in natural language, the first task is, to predict the answer type using a target ontology (e.g., DBpedia or Wikidata. Similarly, the second task is to identify relations in the natural language query and link them to the relations in a target ontology. This paper discusses the task descriptions, benchmark datasets, and evaluation metrics. For more information, please visit https://smart-task.github.io/2021/.
H&E-adversarial network: a convolutional neural network to learn stain-invariant features through Hematoxylin & Eosin regression
Jan 19, 2022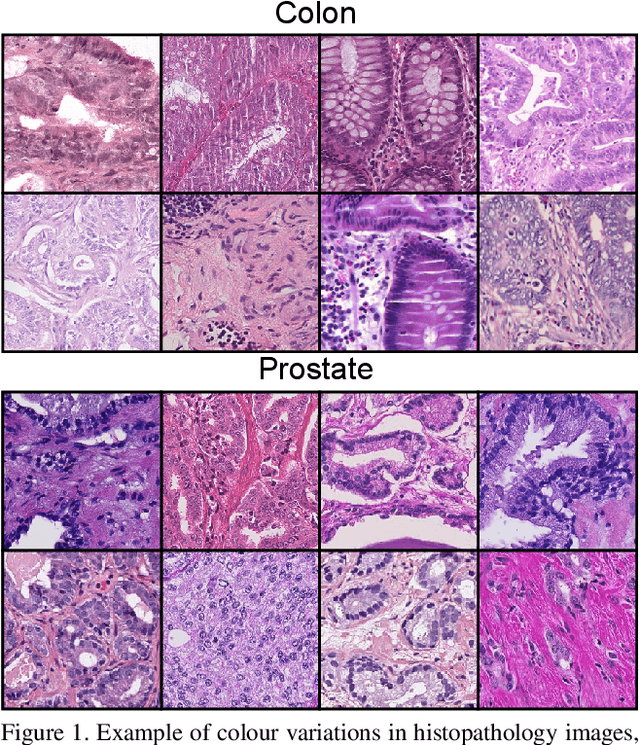
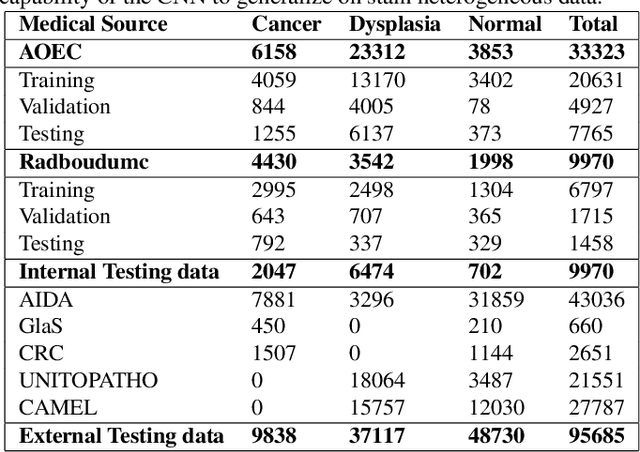
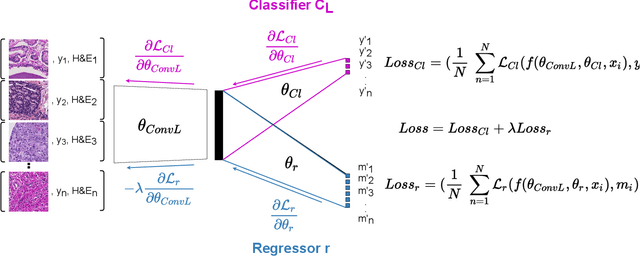
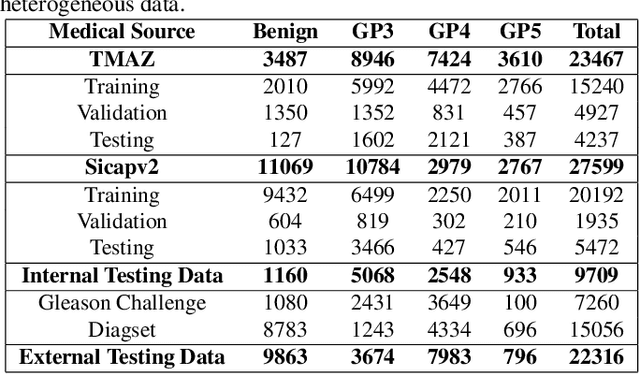
Computational pathology is a domain that aims to develop algorithms to automatically analyze large digitized histopathology images, called whole slide images (WSI). WSIs are produced scanning thin tissue samples that are stained to make specific structures visible. They show stain colour heterogeneity due to different preparation and scanning settings applied across medical centers. Stain colour heterogeneity is a problem to train convolutional neural networks (CNN), the state-of-the-art algorithms for most computational pathology tasks, since CNNs usually underperform when tested on images including different stain variations than those within data used to train the CNN. Despite several methods that were developed, stain colour heterogeneity is still an unsolved challenge that limits the development of CNNs that can generalize on data from several medical centers. This paper aims to present a novel method to train CNNs that better generalize on data including several colour variations. The method, called H&E-adversarial CNN, exploits H&E matrix information to learn stain-invariant features during the training. The method is evaluated on the classification of colon and prostate histopathology images, involving eleven heterogeneous datasets, and compared with five other techniques used to handle stain colour heterogeneity. H&E-adversarial CNNs show an improvement in performance compared to the other algorithms, demonstrating that it can help to better deal with stain colour heterogeneous images.
OPIEC: An Open Information Extraction Corpus
Apr 28, 2019
Open information extraction (OIE) systems extract relations and their arguments from natural language text in an unsupervised manner. The resulting extractions are a valuable resource for downstream tasks such as knowledge base construction, open question answering, or event schema induction. In this paper, we release, describe, and analyze an OIE corpus called OPIEC, which was extracted from the text of English Wikipedia. OPIEC complements the available OIE resources: It is the largest OIE corpus publicly available to date (over 340M triples) and contains valuable metadata such as provenance information, confidence scores, linguistic annotations, and semantic annotations including spatial and temporal information. We analyze the OPIEC corpus by comparing its content with knowledge bases such as DBpedia or YAGO, which are also based on Wikipedia. We found that most of the facts between entities present in OPIEC cannot be found in DBpedia and/or YAGO, that OIE facts often differ in the level of specificity compared to knowledge base facts, and that OIE open relations are generally highly polysemous. We believe that the OPIEC corpus is a valuable resource for future research on automated knowledge base construction.
* In Proceedings of the Conference of Automatic Knowledge Base Construction (AKBC) 2019