 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CRIS: CLIP-Driven Referring Image Segmentation
Nov 30, 2021
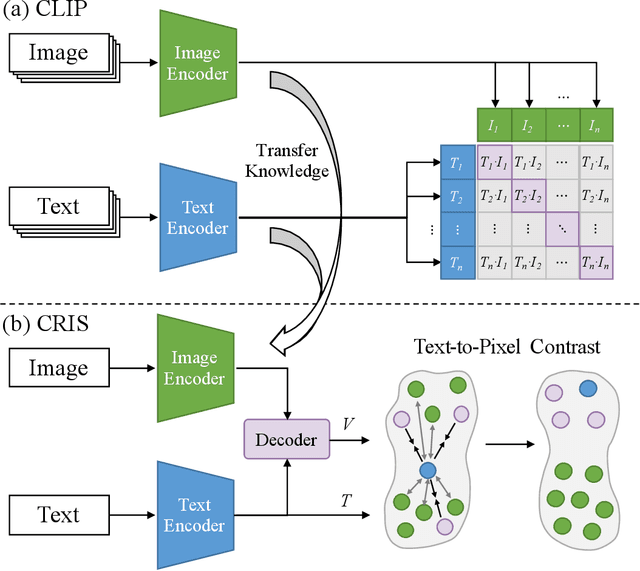
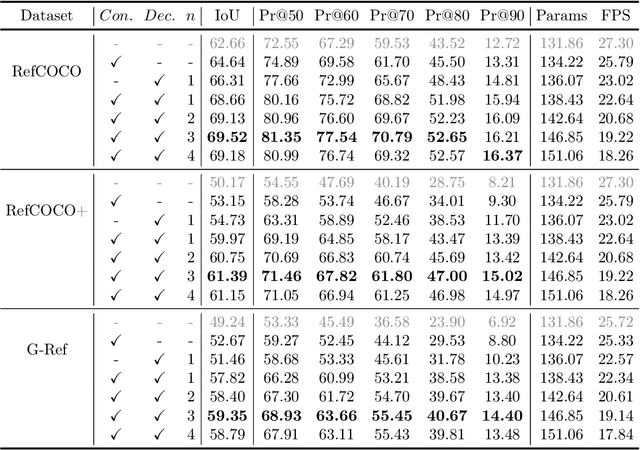

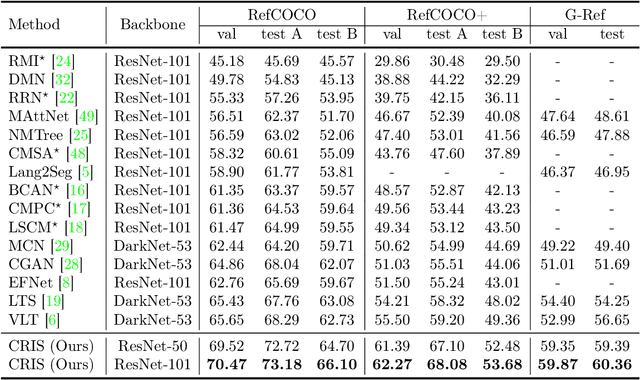
Referring image segmentation aims to segment a referent via a natural linguistic expression.Due to the distinct data properties between text and image, it is challenging for a network to well align text and pixel-level features. Existing approaches use pretrained models to facilitate learning, yet separately transfer the language/vision knowledge from pretrained models, ignoring the multi-modal corresponding information. Inspired by the recent advance in Contrastive Language-Image Pretraining (CLIP), in this paper, we propose an end-to-end CLIP-Driven Referring Image Segmentation framework (CRIS). To transfer the multi-modal knowledge effectively, CRIS resorts to vision-language decoding and contrastive learning for achieving the text-to-pixel alignment. More specifically, we design a vision-language decoder to propagate fine-grained semantic information from textual representations to each pixel-level activation, which promotes consistency between the two modalities. In addition, we present text-to-pixel contrastive learning to explicitly enforce the text feature similar to the related pixel-level features and dissimilar to the irrelevances. The experimental results on three benchmark datasets demonstrate that our proposed framework significantly outperforms the state-of-the-art performance without any post-processing. The code will be released.
Contrastive and Selective Hidden Embeddings for Medical Image Segmentation
Jan 21, 2022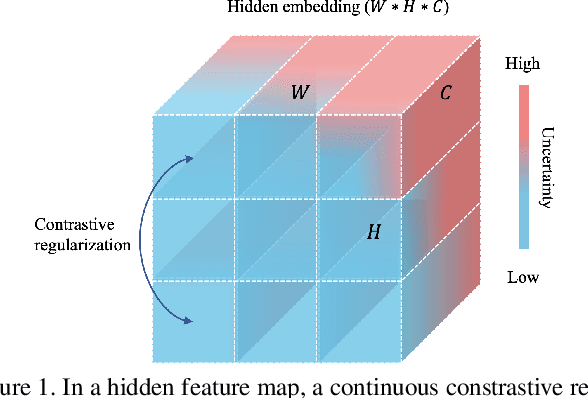
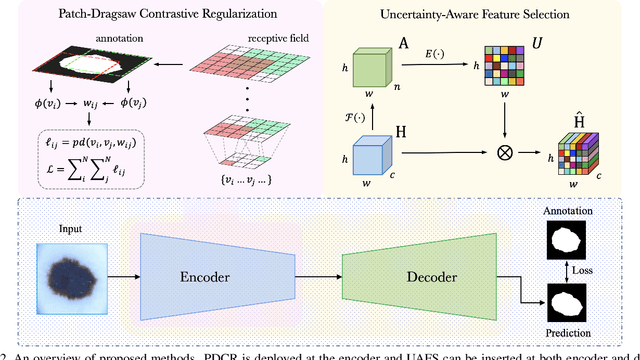
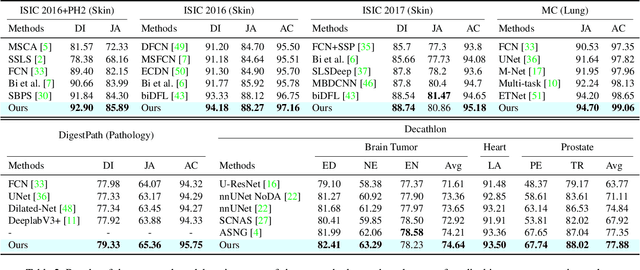
Medical image segmentation has been widely recognized as a pivot procedure for clinical diagnosis, analysis, and treatment planning. However, the laborious and expensive annotation process lags down the speed of further advances. Contrastive learning-based weight pre-training provides an alternative by leveraging unlabeled data to learn a good representation. In this paper, we investigate how contrastive learning benefits the general supervised medical segmentation tasks. To this end, patch-dragsaw contrastive regularization (PDCR) is proposed to perform patch-level tugging and repulsing with the extent controlled by a continuous affinity score. And a new structure dubbed uncertainty-aware feature selection block (UAFS) is designed to perform the feature selection process, which can handle the learning target shift caused by minority features with high uncertainty. By plugging the proposed 2 modules into the existing segmentation architecture, we achieve state-of-the-art results across 8 public datasets from 6 domains. Newly designed modules further decrease the amount of training data to a quarter while achieving comparable, if not better, performances. From this perspective, we take the opposite direction of the original self/un-supervised contrastive learning by further excavating information contained within the label.
Stock Movement Prediction Based on Bi-typed and Hybrid-relational Market Knowledge Graph via Dual Attention Networks
Jan 11, 2022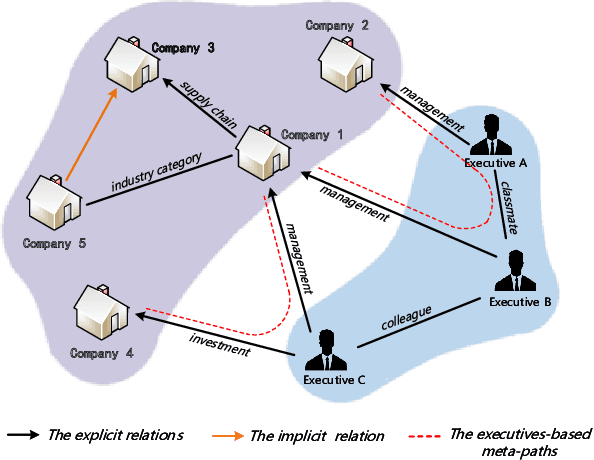
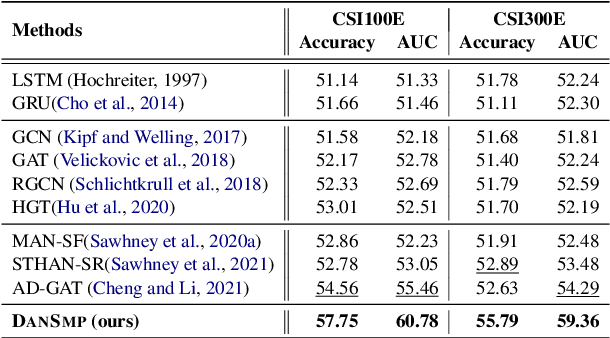
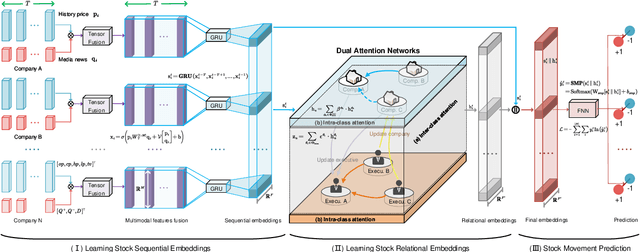
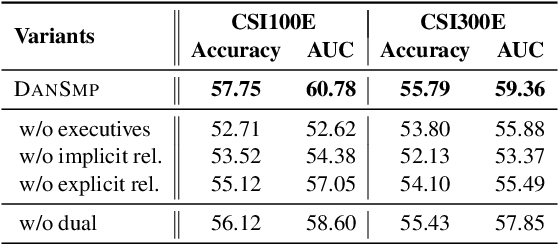
Stock Movement Prediction (SMP) aims at predicting listed companies' stock future price trend, which is a challenging task due to the volatile nature of financial markets. Recent financial studies show that the momentum spillover effect plays a significant role in stock fluctuation. However, previous studies typically only learn the simple connection information among related companies, which inevitably fail to model complex relations of listed companies in the real financial market. To address this issue, we first construct a more comprehensive Market Knowledge Graph (MKG) which contains bi-typed entities including listed companies and their associated executives, and hybrid-relations including the explicit relations and implicit relations. Afterward, we propose DanSmp, a novel Dual Attention Networks to learn the momentum spillover signals based upon the constructed MKG for stock prediction. The empirical experiments on our constructed datasets against nine SOTA baselines demonstrate that the proposed DanSmp is capable of improving stock prediction with the constructed MKG.
TransBTSV2: Wider Instead of Deeper Transformer for Medical Image Segmentation
Jan 30, 2022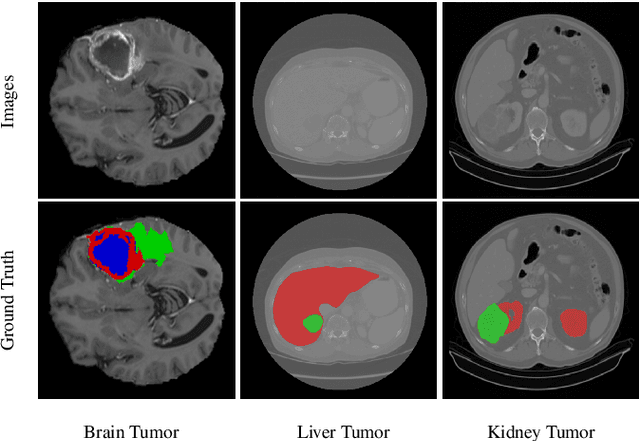
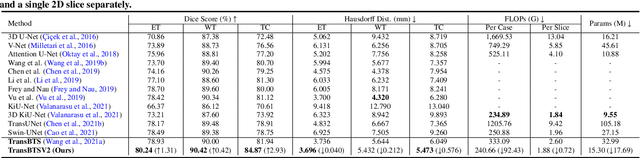
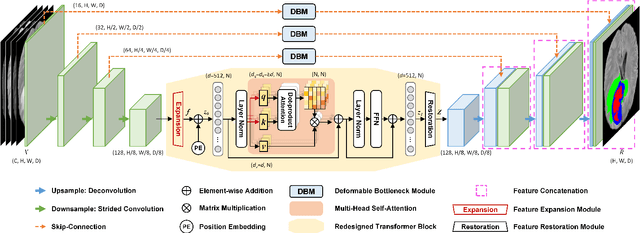
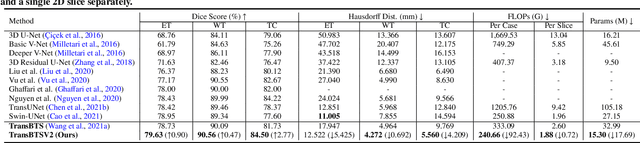
Transformer, benefiting from global (long-range) information modeling using self-attention mechanism, has been successful in natural language processing and computer vision recently. Convolutional Neural Networks, capable of capturing local features, are unable to model explicit long-distance dependencies from global feature space. However, both local and global features are crucial for dense prediction tasks, especially for 3D medical image segmentation. In this paper, we exploit Transformer in 3D CNN for 3D medical image volumetric segmentation and propose a novel network named TransBTSV2 based on the encoder-decoder structure. Different from our original TransBTS, the proposed TransBTSV2 is not limited to brain tumor segmentation (BTS) but focuses on general medical image segmentation, providing a strong and efficient 3D baseline for volumetric segmentation of medical images. As a hybrid CNN-Transformer architecture, TransBTSV2 can achieve accurate segmentation of medical images without any pre-training. With the proposed insight to redesign the internal structure of Transformer and the introduced Deformable Bottleneck Module, a highly efficient architecture is achieved with superior performance. Extensive experimental results on four medical image datasets (BraTS 2019, BraTS 2020, LiTS 2017 and KiTS 2019) demonstrate that TransBTSV2 achieves comparable or better results as compared to the state-of-the-art methods for the segmentation of brain tumor, liver tumor as well as kidney tumor. Code is available at https://github.com/Wenxuan-1119/TransBTS.
TASSY -- A Text Annotation Survey System
Dec 14, 2021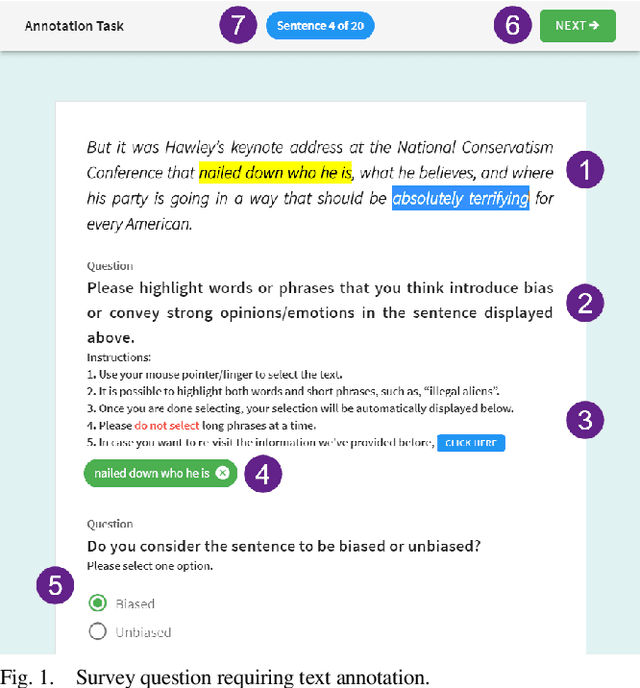
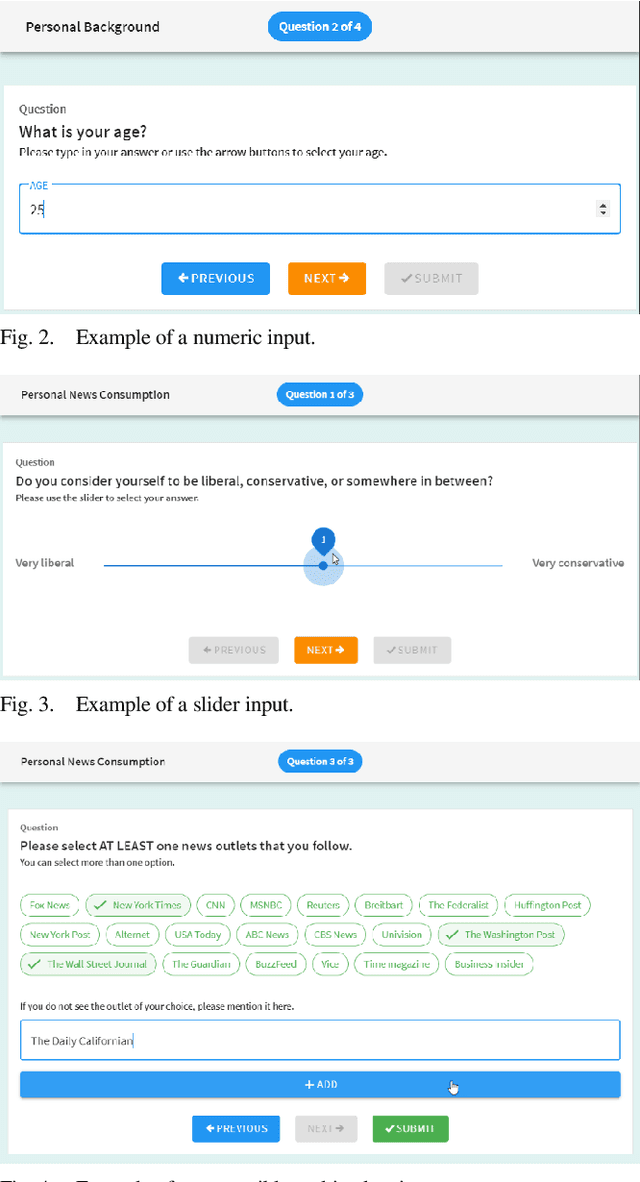
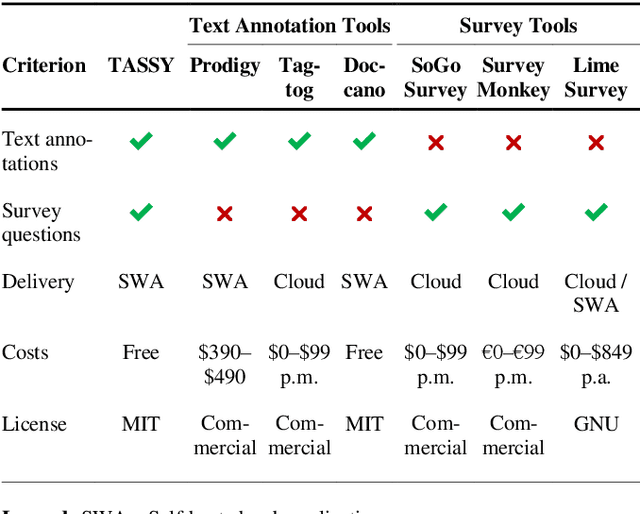
We present a free and open-source tool for creating web-based surveys that include text annotation tasks. Existing tools offer either text annotation or survey functionality but not both. Combining the two input types is particularly relevant for investigating a reader's perception of a text which also depends on the reader's background, such as age, gender, and education. Our tool caters primarily to the needs of researchers in the Library and Information Sciences, the Social Sciences, and the Humanities who apply Content Analysis to investigate, e.g., media bias, political communication, or fake news.
Machine Learning for Multimodal Electronic Health Records-based Research: Challenges and Perspectives
Nov 09, 2021
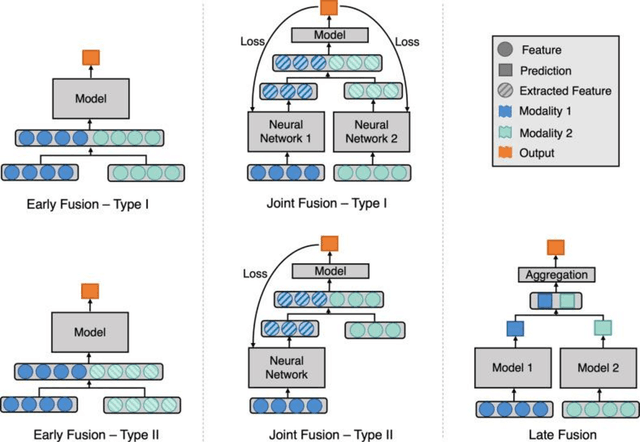
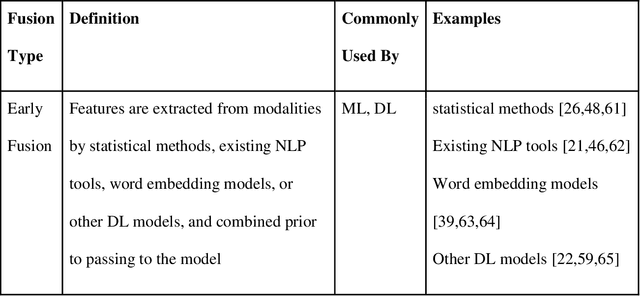
Background: Electronic Health Records (EHRs) contain rich information of patients' health history, which usually include both structured and unstructured data. There have been many studies focusing on distilling valuable information from structured data, such as disease codes, laboratory test results, and treatments. However, relying on structured data only might be insufficient in reflecting patients' comprehensive information and such data may occasionally contain erroneous records. Objective: With the recent advances of machine learning (ML) and deep learning (DL) techniques, an increasing number of studies seek to obtain more accurate results by incorporating unstructured free-text data as well. This paper reviews studies that use multimodal data, i.e. a combination of structured and unstructured data, from EHRs as input for conventional ML or DL models to address the targeted tasks. Materials and Methods: We searched in the Institute of Electrical and Electronics Engineers (IEEE) Digital Library, PubMed, and Association for Computing Machinery (ACM) Digital Library for articles related to ML-based multimodal EHR studies. Results and Discussion: With the final 94 included studies, we focus on how data from different modalities were combined and interacted using conventional ML and DL techniques, and how these algorithms were applied in EHR-related tasks. Further, we investigate the advantages and limitations of these fusion methods and indicate future directions for ML-based multimodal EHR research.
Medial Spectral Coordinates for 3D Shape Analysis
Nov 30, 2021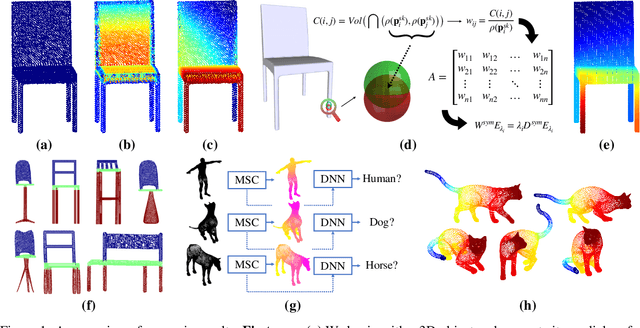
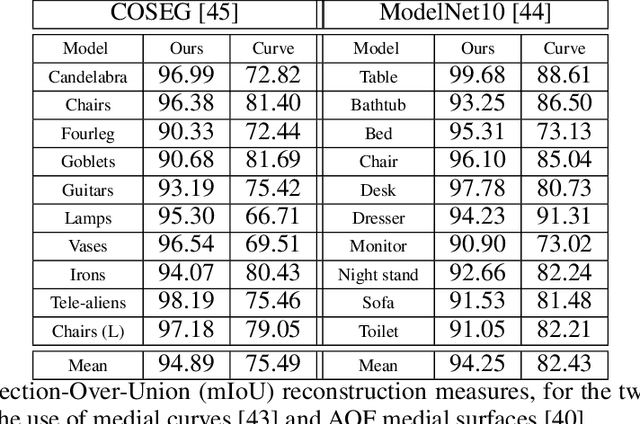
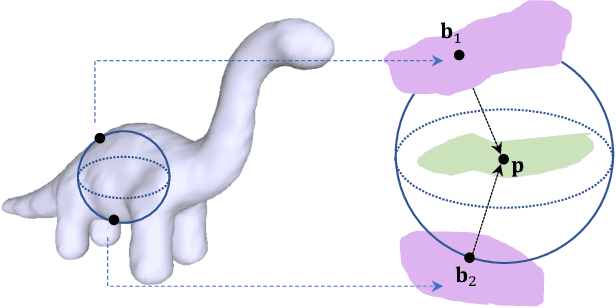
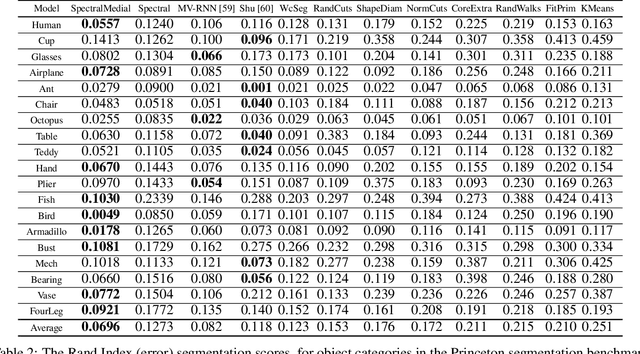
In recent years there has been a resurgence of interest in our community in the shape analysis of 3D objects represented by surface meshes, their voxelized interiors, or surface point clouds. In part, this interest has been stimulated by the increased availability of RGBD cameras, and by applications of computer vision to autonomous driving, medical imaging, and robotics. In these settings, spectral coordinates have shown promise for shape representation due to their ability to incorporate both local and global shape properties in a manner that is qualitatively invariant to isometric transformations. Yet, surprisingly, such coordinates have thus far typically considered only local surface positional or derivative information. In the present article, we propose to equip spectral coordinates with medial (object width) information, so as to enrich them. The key idea is to couple surface points that share a medial ball, via the weights of the adjacency matrix. We develop a spectral feature using this idea, and the algorithms to compute it. The incorporation of object width and medial coupling has direct benefits, as illustrated by our experiments on object classification, object part segmentation, and surface point correspondence.
S2MS: Self-Supervised Learning Driven Multi-Spectral CT Image Enhancement
Jan 26, 2022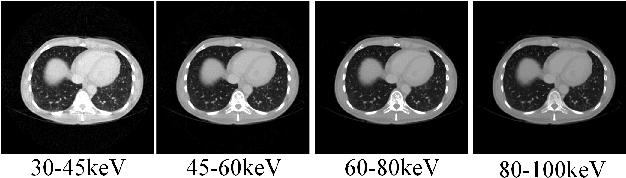
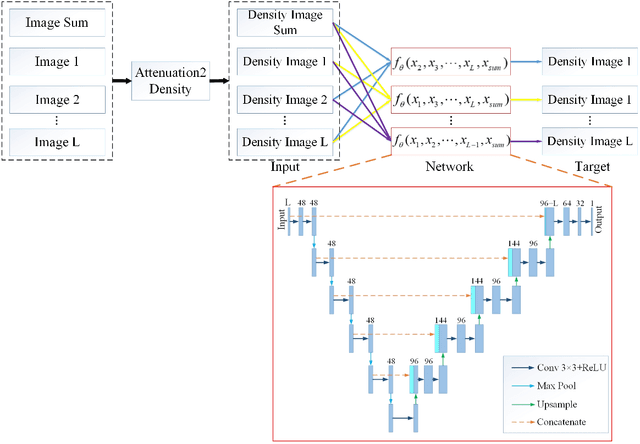
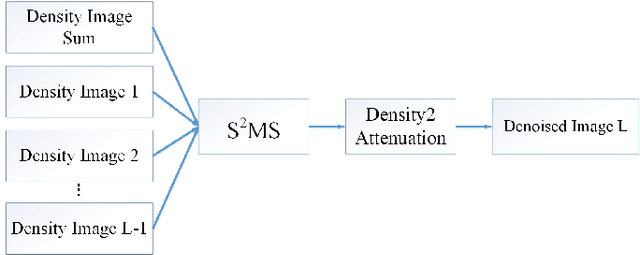
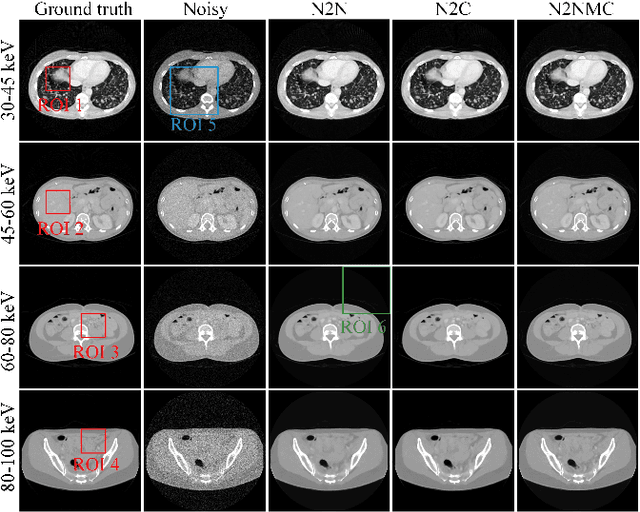
Photon counting spectral CT (PCCT) can produce reconstructed attenuation maps in different energy channels, reflecting energy properties of the scanned object. Due to the limited photon numbers and the non-ideal detector response of each energy channel, the reconstructed images usually contain much noise. With the development of Deep Learning (DL) technique, different kinds of DL-based models have been proposed for noise reduction. However, most of the models require clean data set as the training labels, which are not always available in medical imaging field. Inspiring by the similarities of each channel's reconstructed image, we proposed a self-supervised learning based PCCT image enhancement framework via multi-spectral channels (S2MS). In S2MS framework, both the input and output labels are noisy images. Specifically, one single channel image was used as output while images of other single channels and channel-sum image were used as input to train the network, which can fully use the spectral data information without extra cost. The simulation results based on the AAPM Low-dose CT Challenge database showed that the proposed S2MS model can suppress the noise and preserve details more effectively in comparison with the traditional DL models, which has potential to improve the image quality of PCCT in clinical applications.
RailLoMer: Rail Vehicle Localization and Mapping with LiDAR-IMU-Odometer-GNSS Data Fusion
Nov 30, 2021
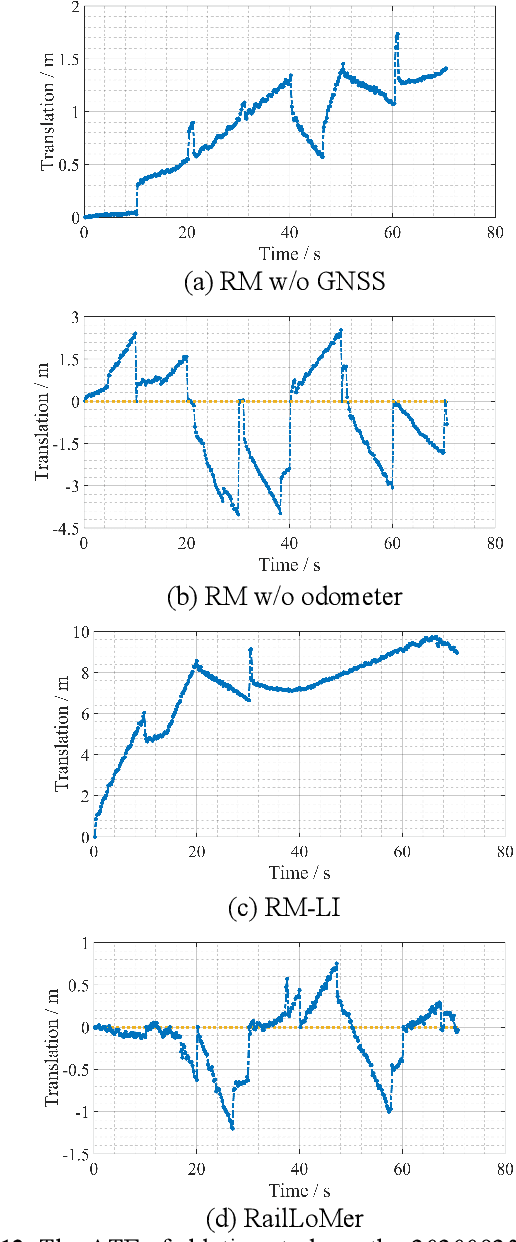
We present RailLoMer in this article, to achieve real-time accurate and robust odometry and mapping for rail vehicles. RailLoMer receives measurements from two LiDARs, an IMU, train odometer, and a global navigation satellite system (GNSS) receiver. As frontend, the estimated motion from IMU/odometer preintegration de-skews the denoised point clouds and produces initial guess for frame-to-frame LiDAR odometry. As backend, a sliding window based factor graph is formulated to jointly optimize multi-modal information. In addition, we leverage the plane constraints from extracted rail tracks and the structure appearance descriptor to further improve the system robustness against repetitive structures. To ensure a globally-consistent and less blurry mapping result, we develop a two-stage mapping method that first performs scan-to-map in local scale, then utilizes the GNSS information to register the submaps. The proposed method is extensively evaluated on datasets gathered for a long time range over numerous scales and scenarios, and show that RailLoMer delivers decimeter-grade localization accuracy even in large or degenerated environments. We also integrate RailLoMer into an interactive train state and railway monitoring system prototype design, which has already been deployed to an experimental freight traffic railroad.
Neural Motion Planning for Autonomous Parking
Nov 16, 2021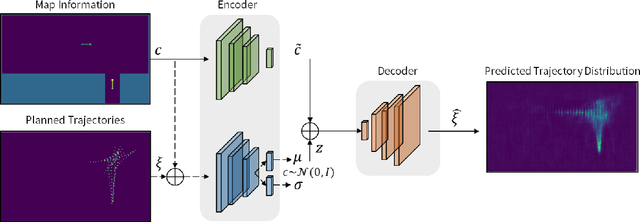
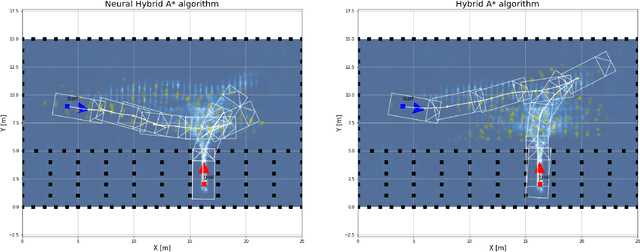
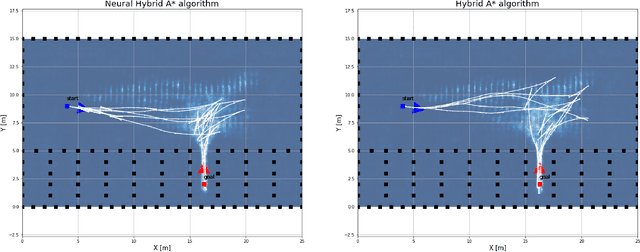
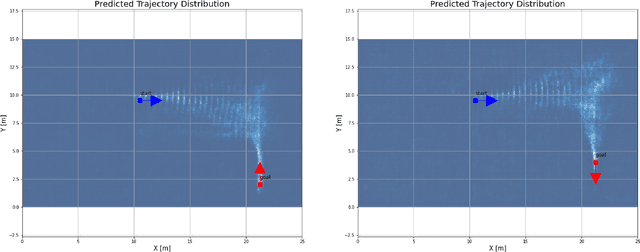
This paper presents a hybrid motion planning strategy that combines a deep generative network with a conventional motion planning method. Existing planning methods such as A* and Hybrid A* are widely used in path planning tasks because of their ability to determine feasible paths even in complex environments; however, they have limitations in terms of efficiency. To overcome these limitations, a path planning algorithm based on a neural network, namely the neural Hybrid A*, is introduced. This paper proposes using a conditional variational autoencoder (CVAE) to guide the search algorithm by exploiting the ability of CVAE to learn information about the planning space given the information of the parking environment. A non-uniform expansion strategy is utilized based on a distribution of feasible trajectories learned in the demonstrations. The proposed method effectively learns the representations of a given state, and shows improvement in terms of algorithm performance.