 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Video Intelligence as a component of a Global Security system
Jan 12, 2022
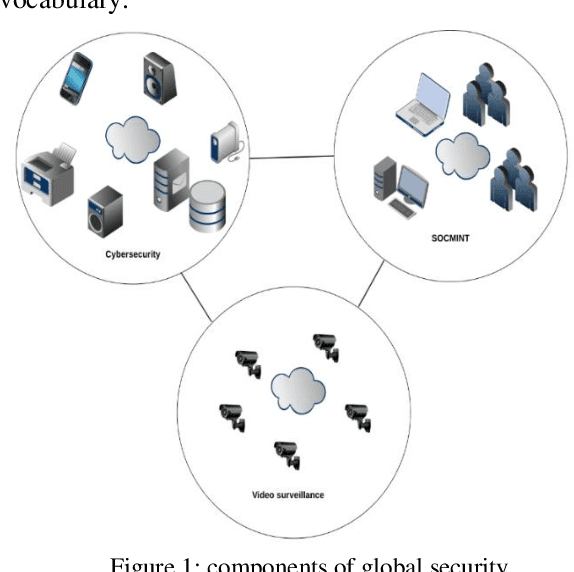
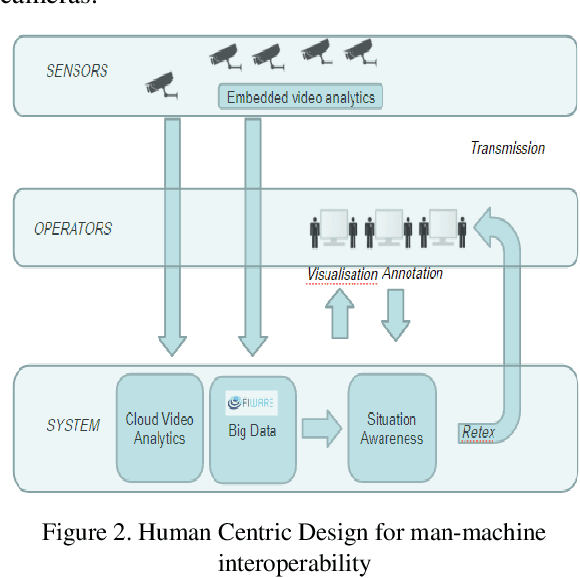
This paper describes the evolution of our research from video analytics to a global security system with focus on the video surveillance component. Indeed video surveillance has evolved from a commodity security tool up to the most efficient way of tracking perpetrators when terrorism hits our modern urban centers. As number of cameras soars, one could expect the system to leverage the huge amount of data carried through the video streams to provide fast access to video evidences, actionable intelligence for monitoring real-time events and enabling predictive capacities to assist operators in their surveillance tasks. This research explores a hybrid platform for video intelligence capture, automated data extraction, supervised Machine Learning for intelligently assisted urban video surveillance; Extension to other components of a global security system are discussed. Applying Knowledge Management principles in this research helps with deep problem understanding and facilitates the implementation of efficient information and experience sharing decision support systems providing assistance to people on the field as well as in operations centers. The originality of this work is also the creation of "common" human-machine and machine to machine language and a security ontology.
CLOOB: Modern Hopfield Networks with InfoLOOB Outperform CLIP
Oct 21, 2021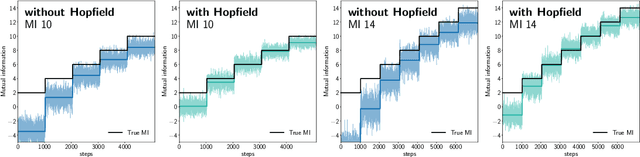
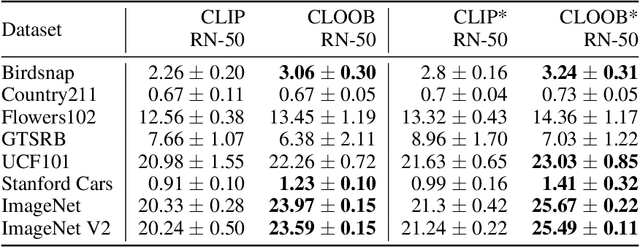
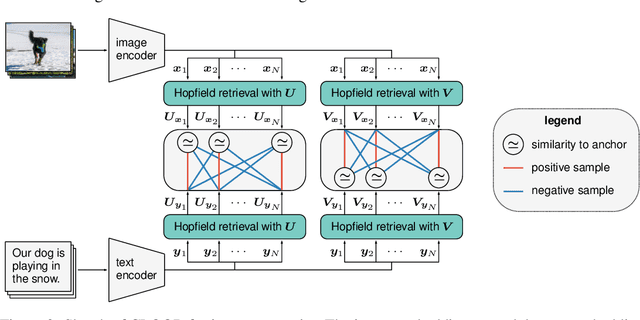
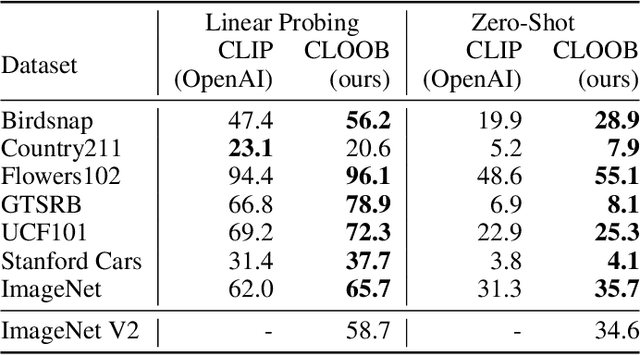
Contrastive learning with the InfoNCE objective is exceptionally successful in various self-supervised learning tasks. Recently, the CLIP model yielded impressive results on zero-shot transfer learning when using InfoNCE for learning visual representations from natural language supervision. However, InfoNCE as a lower bound on the mutual information has been shown to perform poorly for high mutual information. In contrast, the InfoLOOB upper bound (leave one out bound) works well for high mutual information but suffers from large variance and instabilities. We introduce "Contrastive Leave One Out Boost" (CLOOB), where modern Hopfield networks boost learning with the InfoLOOB objective. Modern Hopfield networks replace the original embeddings by retrieved embeddings in the InfoLOOB objective. The retrieved embeddings give InfoLOOB two assets. Firstly, the retrieved embeddings stabilize InfoLOOB, since they are less noisy and more similar to one another than the original embeddings. Secondly, they are enriched by correlations, since the covariance structure of embeddings is reinforced through retrievals. We compare CLOOB to CLIP after learning on the Conceptual Captions and the YFCC dataset with respect to their zero-shot transfer learning performance on other datasets. CLOOB consistently outperforms CLIP at zero-shot transfer learning across all considered architectures and datasets.
PreDisM: Pre-Disaster Modelling With CNN Ensembles for At-Risk Communities
Dec 26, 2021



The machine learning community has recently had increased interest in the climate and disaster damage domain due to a marked increased occurrences of natural hazards (e.g., hurricanes, forest fires, floods, earthquakes). However, not enough attention has been devoted to mitigating probable destruction from impending natural hazards. We explore this crucial space by predicting building-level damages on a before-the-fact basis that would allow state actors and non-governmental organizations to be best equipped with resource distribution to minimize or preempt losses. We introduce PreDisM that employs an ensemble of ResNets and fully connected layers over decision trees to capture image-level and meta-level information to accurately estimate weakness of man-made structures to disaster-occurrences. Our model performs well and is responsive to tuning across types of disasters and highlights the space of preemptive hazard damage modelling.
Thompson Sampling with Information Relaxation Penalties
Feb 12, 2019
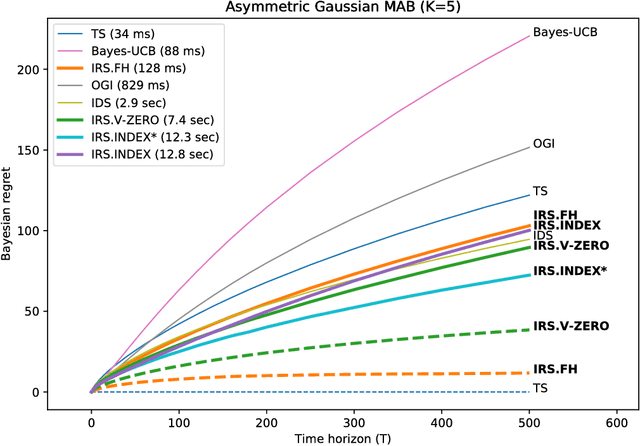
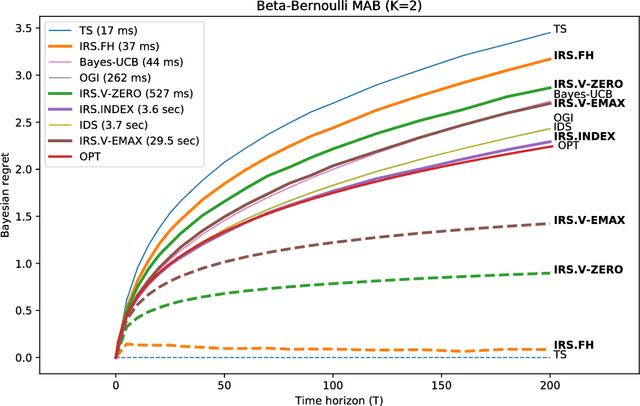
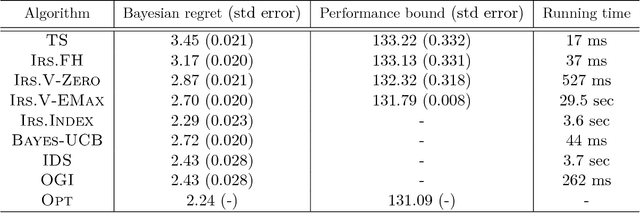
We consider a finite time horizon multi-armed bandit (MAB) problem in a Bayesian framework, for which we develop a general set of control policies that leverage ideas from information relaxations of stochastic dynamic optimization problems. In crude terms, an information relaxation allows the decision maker (DM) to have access to the future (unknown) rewards and incorporate them in her optimization problem to pick an action at time $t$, but penalizes the decision maker for using this information. In our setting, the future rewards allow the DM to better estimate the unknown mean reward parameters of the multiple arms, and optimize her sequence of actions. By picking different information penalties, the DM can construct a family of policies of increasing complexity that, for example, include Thompson Sampling and the true optimal (but intractable) policy as special cases. We systematically develop this framework of information relaxation sampling, propose an intuitive family of control policies for our motivating finite time horizon Bayesian MAB problem, and prove associated structural results and performance bounds. Numerical experiments suggest that this new class of policies performs well, in particular in settings where the finite time horizon introduces significant tension in the problem. Finally, inspired by the finite time horizon Gittins index, we propose an index policy that builds on our framework that particularly outperforms to the state-of-the-art algorithms in our numerical experiments.
Community Detection and Matrix Completion with Two-Sided Graph Side-Information
Dec 06, 2019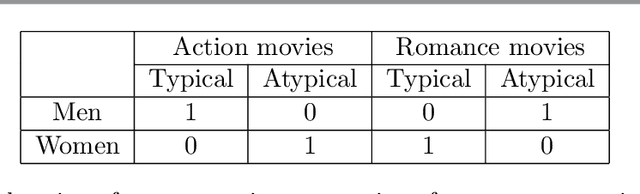
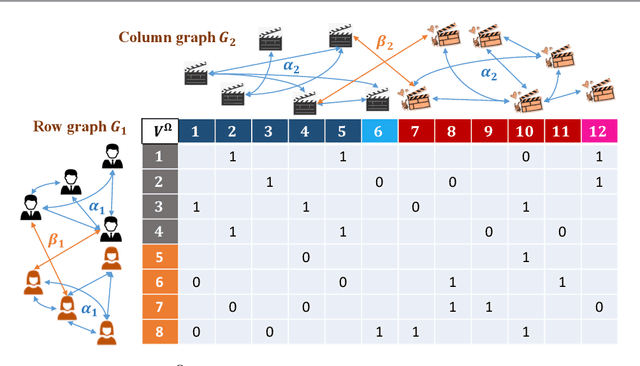
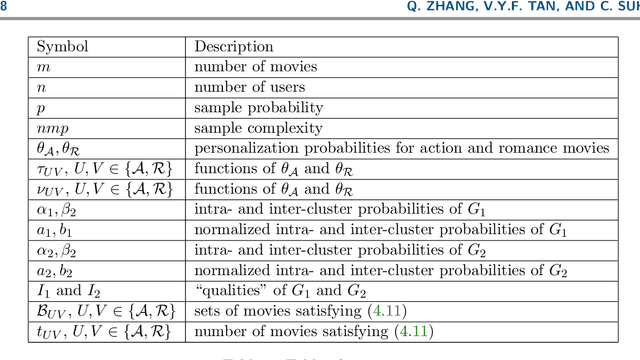
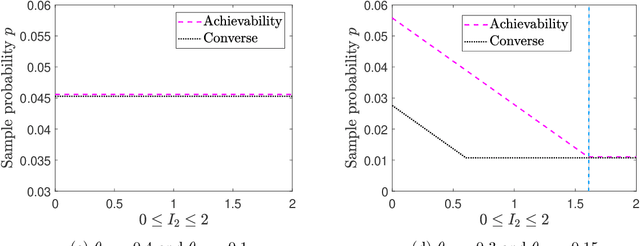
We consider the problem of recovering communities of users and communities of items (such as movies) based on a partially observed rating matrix as well as side-information in the form of similarity graphs of the users and items. The user-to-user and item-to-item similarity graphs are generated according to the celebrated stochastic block model (SBM). We develop lower and upper bounds on the minimum expected number of observed ratings (also known as the sample complexity) needed for this recovery task. These bounds are functions of various parameters including the quality of the graph side-information which is manifested in the intra- and inter-cluster probabilities of the SBMs. We show that these bounds match for a wide range of parameters of interest, and match up to a constant factor of two for the remaining parameter regime. Our information-theoretic results quantify the benefits of the two-sided graph side-information for recovery, and further analysis reveals that the two pieces of graph side-information produce an interesting synergistic effect under certain scenarios. This means that if one observes only one of the two graphs, then the required sample complexity worsens to the case in which none of the graphs is observed. Thus both graphs are strictly needed to reduce the sample complexity.
Interactive Medical Image Segmentation with Self-Adaptive Confidence Calibration
Nov 15, 2021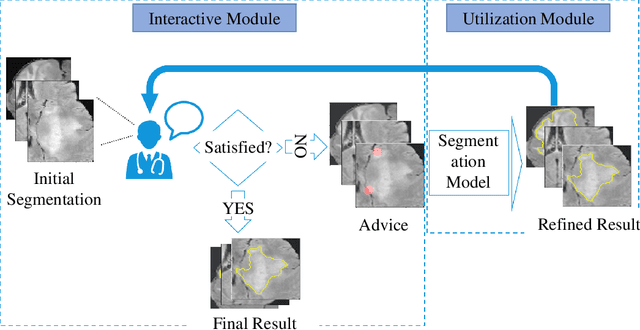
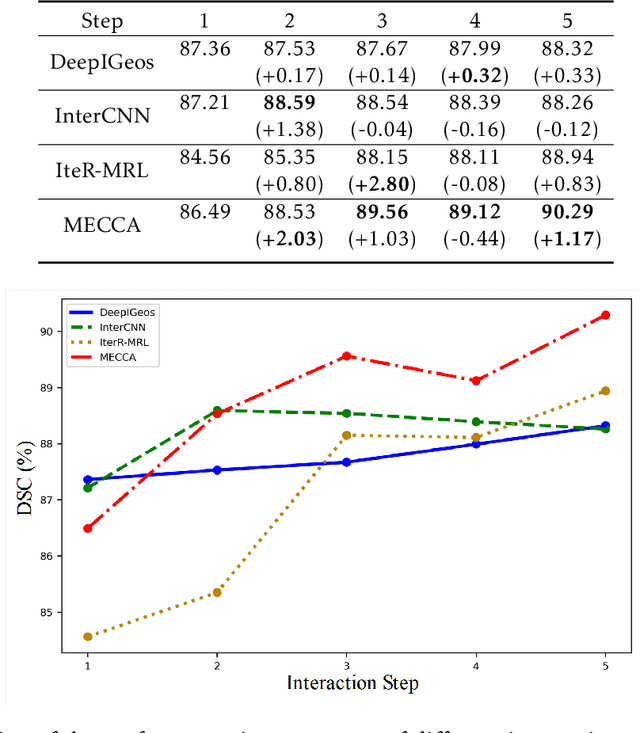
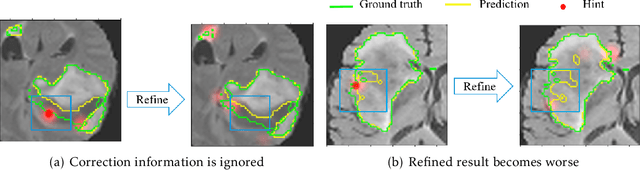

Medical image segmentation is one of the fundamental problems for artificial intelligence-based clinical decision systems. Current automatic medical image segmentation methods are often failed to meet clinical requirements. As such, a series of interactive segmentation algorithms are proposed to utilize expert correction information. However, existing methods suffer from some segmentation refining failure problems after long-term interactions and some cost problems from expert annotation, which hinder clinical applications. This paper proposes an interactive segmentation framework, called interactive MEdical segmentation with self-adaptive Confidence CAlibration (MECCA), by introducing the corrective action evaluation, which combines the action-based confidence learning and multi-agent reinforcement learning (MARL). The evaluation is established through a novel action-based confidence network, and the corrective actions are obtained from MARL. Based on the confidential information, a self-adaptive reward function is designed to provide more detailed feedback, and a simulated label generation mechanism is proposed on unsupervised data to reduce over-reliance on labeled data. Experimental results on various medical image datasets have shown the significant performance of the proposed algorithm.
SaL-Lightning Dataset: Search and Eye Gaze Behavior, Resource Interactions and Knowledge Gain during Web Search
Jan 07, 2022
The emerging research field Search as Learning investigates how the Web facilitates learning through modern information retrieval systems. SAL research requires significant amounts of data that capture both search behavior of users and their acquired knowledge in order to obtain conclusive insights or train supervised machine learning models. However, the creation of such datasets is costly and requires interdisciplinary efforts in order to design studies and capture a wide range of features. In this paper, we address this issue and introduce an extensive dataset based on a user study, in which $114$ participants were asked to learn about the formation of lightning and thunder. Participants' knowledge states were measured before and after Web search through multiple-choice questionnaires and essay-based free recall tasks. To enable future research in SAL-related tasks we recorded a plethora of features and person-related attributes. Besides the screen recordings, visited Web pages, and detailed browsing histories, a large number of behavioral features and resource features were monitored. We underline the usefulness of the dataset by describing three, already published, use cases.
Simple Baseline for Single Human Motion Forecasting
Oct 14, 2021

Global human motion forecasting is important in many fields, which is the combination of global human trajectory prediction and local human pose prediction. Visual and social information are often used to boost model performance, however, they may consume too much computational resource. In this paper, we establish a simple but effective baseline for single human motion forecasting without visual and social information, equipped with useful training tricks. Our method "futuremotion_ICCV21" outperforms existing methods by a large margin on SoMoF benchmark. We hope our work provide new ideas for future research.
Robust Voting Rules from Algorithmic Robust Statistics
Dec 13, 2021In this work we study the problem of robustly learning a Mallows model. We give an algorithm that can accurately estimate the central ranking even when a constant fraction of its samples are arbitrarily corrupted. Moreover our robustness guarantees are dimension-independent in the sense that our overall accuracy does not depend on the number of alternatives being ranked. Our work can be thought of as a natural infusion of perspectives from algorithmic robust statistics into one of the central inference problems in voting and information-aggregation. Specifically, our voting rule is efficiently computable and its outcome cannot be changed by much by a large group of colluding voters.
Privacy Aware Person Detection in Surveillance Data
Oct 28, 2021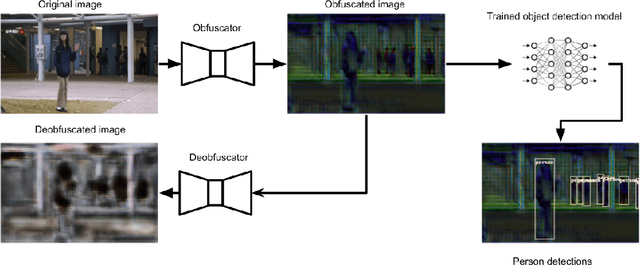
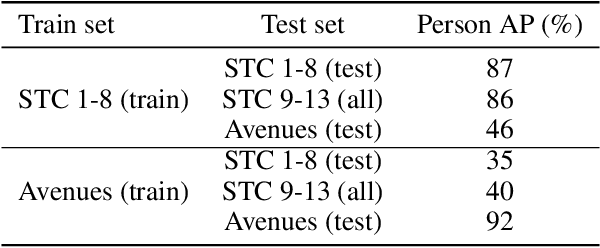

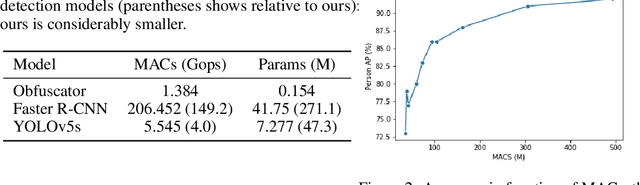
Crowd management relies on inspection of surveillance video either by operators or by object detection models. These models are large, making it difficult to deploy them on resource constrained edge hardware. Instead, the computations are often offloaded to a (third party) cloud platform. While crowd management may be a legitimate application, transferring video from the camera to remote infrastructure may open the door for extracting additional information that are infringements of privacy, like person tracking or face recognition. In this paper, we use adversarial training to obtain a lightweight obfuscator that transforms video frames to only retain the necessary information for person detection. Importantly, the obfuscated data can be processed by publicly available object detectors without retraining and without significant loss of accuracy.