 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Metric Hypertransformers are Universal Adapted Maps
Jan 31, 2022


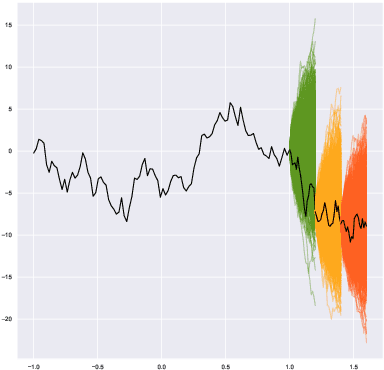

We introduce a universal class of geometric deep learning models, called metric hypertransformers (MHTs), capable of approximating any adapted map $F:\mathscr{X}^{\mathbb{Z}}\rightarrow \mathscr{Y}^{\mathbb{Z}}$ with approximable complexity, where $\mathscr{X}\subseteq \mathbb{R}^d$ and $\mathscr{Y}$ is any suitable metric space, and $\mathscr{X}^{\mathbb{Z}}$ (resp. $\mathscr{Y}^{\mathbb{Z}}$) capture all discrete-time paths on $\mathscr{X}$ (resp. $\mathscr{Y}$). Suitable spaces $\mathscr{Y}$ include various (adapted) Wasserstein spaces, all Fr\'{e}chet spaces admitting a Schauder basis, and a variety of Riemannian manifolds arising from information geometry. Even in the static case, where $f:\mathscr{X}\rightarrow \mathscr{Y}$ is a H\"{o}lder map, our results provide the first (quantitative) universal approximation theorem compatible with any such $\mathscr{X}$ and $\mathscr{Y}$. Our universal approximation theorems are quantitative, and they depend on the regularity of $F$, the choice of activation function, the metric entropy and diameter of $\mathscr{X}$, and on the regularity of the compact set of paths whereon the approximation is performed. Our guiding examples originate from mathematical finance. Notably, the MHT models introduced here are able to approximate a broad range of stochastic processes' kernels, including solutions to SDEs, many processes with arbitrarily long memory, and functions mapping sequential data to sequences of forward rate curves.
MEGA: Model Stealing via Collaborative Generator-Substitute Networks
Jan 31, 2022Deep machine learning models are increasingly deployedin the wild for providing services to users. Adversaries maysteal the knowledge of these valuable models by trainingsubstitute models according to the inference results of thetargeted deployed models. Recent data-free model stealingmethods are shown effective to extract the knowledge of thetarget model without using real query examples, but they as-sume rich inference information, e.g., class probabilities andlogits. However, they are all based on competing generator-substitute networks and hence encounter training instability.In this paper we propose a data-free model stealing frame-work,MEGA, which is based on collaborative generator-substitute networks and only requires the target model toprovide label prediction for synthetic query examples. Thecore of our method is a model stealing optimization con-sisting of two collaborative models (i) the substitute modelwhich imitates the target model through the synthetic queryexamples and their inferred labels and (ii) the generatorwhich synthesizes images such that the confidence of thesubstitute model over each query example is maximized. Wepropose a novel coordinate descent training procedure andanalyze its convergence. We also empirically evaluate thetrained substitute model on three datasets and its applicationon black-box adversarial attacks. Our results show that theaccuracy of our trained substitute model and the adversarialattack success rate over it can be up to 33% and 40% higherthan state-of-the-art data-free black-box attacks.
Improving Generalization by Controlling Label-Noise Information in Neural Network Weights
Feb 19, 2020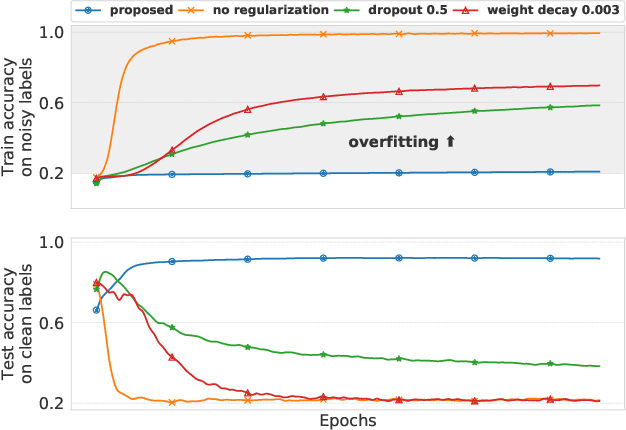
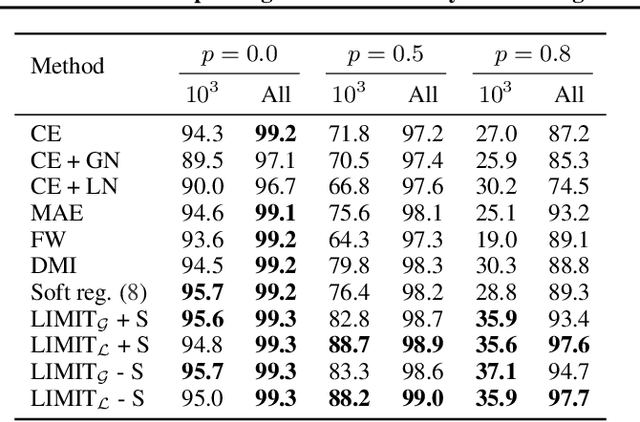
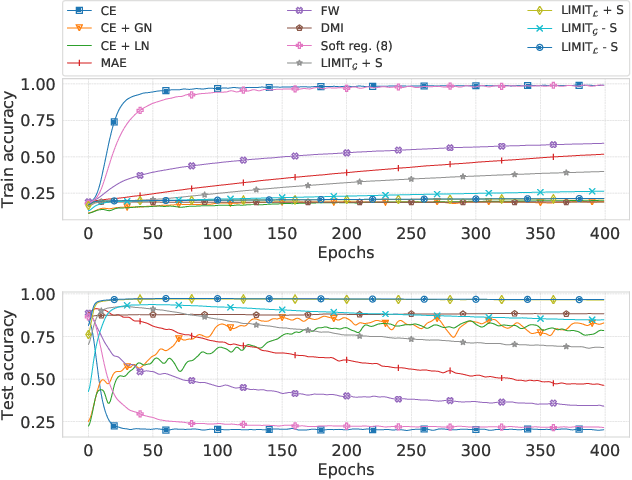
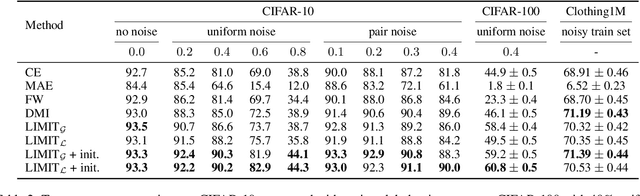
In the presence of noisy or incorrect labels, neural networks have the undesirable tendency to memorize information about the noise. Standard regularization techniques such as dropout, weight decay or data augmentation sometimes help, but do not prevent this behavior. If one considers neural network weights as random variables that depend on the data and stochasticity of training, the amount of memorized information can be quantified with the Shannon mutual information between weights and the vector of all training labels given inputs, $I(w : \mathbf{y} \mid \mathbf{x})$. We show that for any training algorithm, low values of this term correspond to reduction in memorization of label-noise and better generalization bounds. To obtain these low values, we propose training algorithms that employ an auxiliary network that predicts gradients in the final layers of a classifier without accessing labels. We illustrate the effectiveness of our approach on versions of MNIST, CIFAR-10, and CIFAR-100 corrupted with various noise models, and on a large-scale dataset Clothing1M that has noisy labels.
Infrastructure-enabled GPS Spoofing Detection and Correction
Feb 11, 2022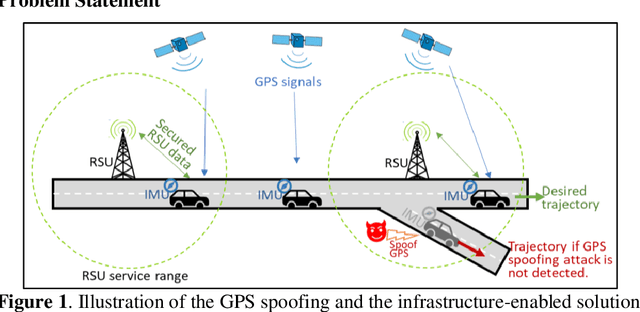
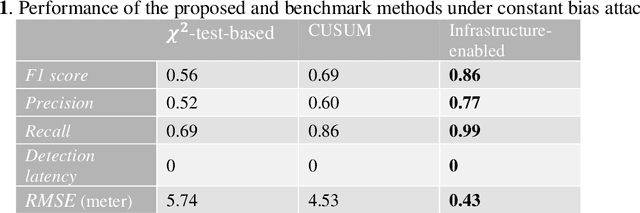
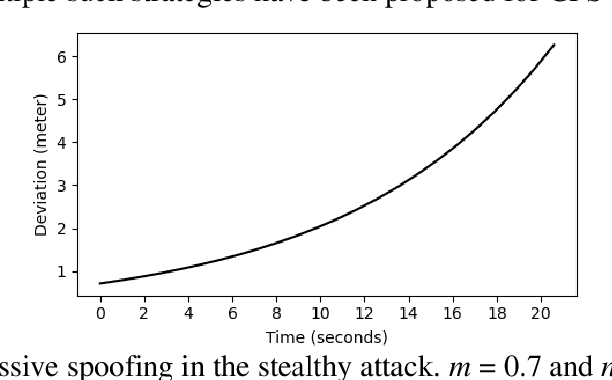
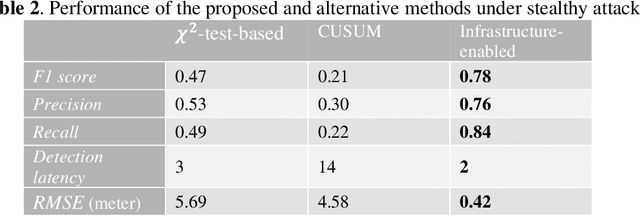
Accurate and robust localization is crucial for supporting high-level driving automation and safety. Modern localization solutions rely on various sensors, among which GPS has been and will continue to be essential. However, GPS can be vulnerable to malicious attacks and GPS spoofing has been identified as a high threat. GPS spoofing injects false information into true GPS measurements, aiming to deviate a vehicle from its true trajectory, endangering the safety of road users. With various types of vehicle-based sensors emerging, recent studies propose to detect GPS spoofing by fusing data from multiple sensors and identifying inconsistencies among them. Yet, these methods often require sophisticated algorithms and cannot handle stealthy or coordinated attacks targeting multiple sensors. With infrastructure becoming increasingly important in supporting emerging vehicle technologies and systems (e.g., automated vehicles), this study explores the potential of applying infrastructure data in defending against GPS spoofing. We propose an infrastructure-enabled method by deploying roadside infrastructure as an independent, secured data source. A real-time detector, based on the Isolation Forest, is constructed to detect GPS spoofing. Once spoofing is detected, GPS measurements are isolated, and the potentially compromised location estimator is corrected using the infrastructure data. The proposed method relies less on vehicular onboard data than existing solutions. Enabled by the secure infrastructure data, we can design a simpler yet more effective solution against GPS spoofing, compared with state-of-the-art defense methods. We test the proposed method using both simulation data and real-world GPS data, and show its effectiveness in defending various types of GPS spoofing attacks, including a type of stealthy attacks that are proposed to fail the production-grade autonomous driving systems.
SigGAN : Adversarial Model for Learning Signed Relationships in Networks
Jan 17, 2022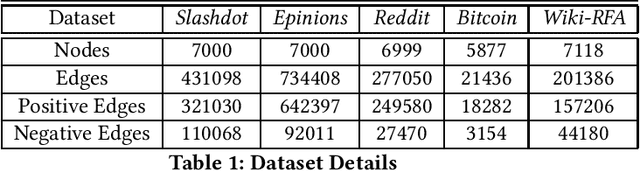
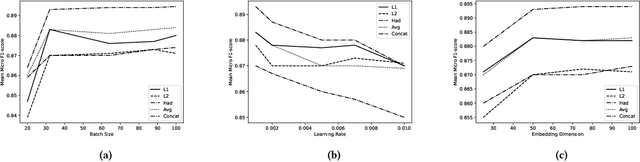
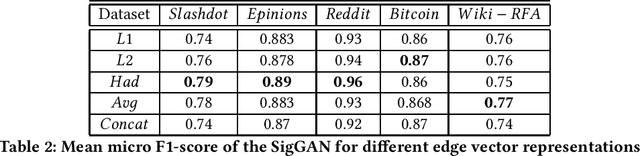
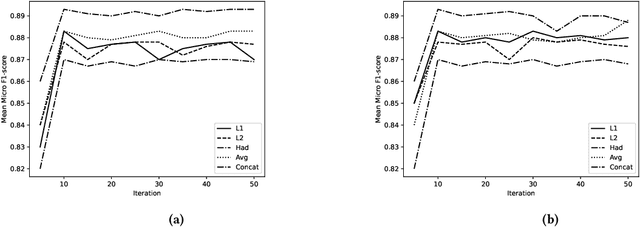
Signed link prediction in graphs is an important problem that has applications in diverse domains. It is a binary classification problem that predicts whether an edge between a pair of nodes is positive or negative. Existing approaches for link prediction in unsigned networks cannot be directly applied for signed link prediction due to their inherent differences. Further, additional structural constraints, like, the structural balance property of the signed networks must be considered for signed link prediction. Recent signed link prediction approaches generate node representations using either generative models or discriminative models. Inspired by the recent success of Generative Adversarial Network (GAN) based models which comprises of a discriminator and generator in several applications, we propose a Generative Adversarial Network (GAN) based model for signed networks, SigGAN. It considers the requirements of signed networks, such as, integration of information from negative edges, high imbalance in number of positive and negative edges and structural balance theory. Comparing the performance with state of the art techniques on several real-world datasets validates the effectiveness of SigGAN.
FCMNet: Full Communication Memory Net for Team-Level Cooperation in Multi-Agent Systems
Jan 31, 2022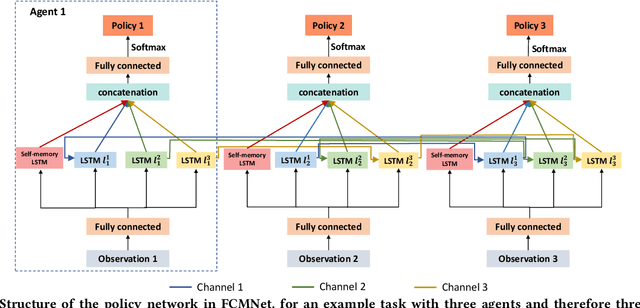


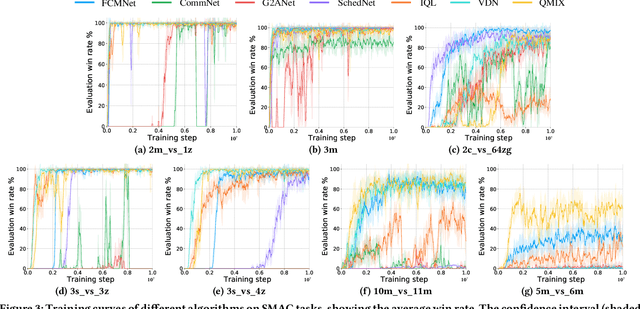
Decentralized cooperation in partially-observable multi-agent systems requires effective communications among agents. To support this effort, this work focuses on the class of problems where global communications are available but may be unreliable, thus precluding differentiable communication learning methods. We introduce FCMNet, a reinforcement learning based approach that allows agents to simultaneously learn a) an effective multi-hop communications protocol and b) a common, decentralized policy that enables team-level decision-making. Specifically, our proposed method utilizes the hidden states of multiple directional recurrent neural networks as communication messages among agents. Using a simple multi-hop topology, we endow each agent with the ability to receive information sequentially encoded by every other agent at each time step, leading to improved global cooperation. We demonstrate FCMNet on a challenging set of StarCraft II micromanagement tasks with shared rewards, as well as a collaborative multi-agent pathfinding task with individual rewards. There, our comparison results show that FCMNet outperforms state-of-the-art communication-based reinforcement learning methods in all StarCraft II micromanagement tasks, and value decomposition methods in certain tasks. We further investigate the robustness of FCMNet under realistic communication disturbances, such as random message loss or binarized messages (i.e., non-differentiable communication channels), to showcase FMCNet's potential applicability to robotic tasks under a variety of real-world conditions.
Interactive Feature Fusion for End-to-End Noise-Robust Speech Recognition
Oct 11, 2021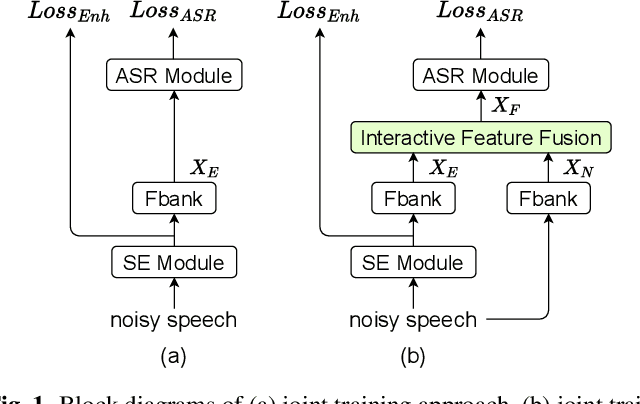
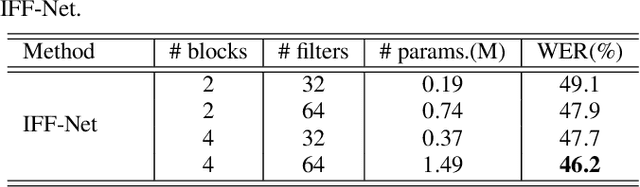
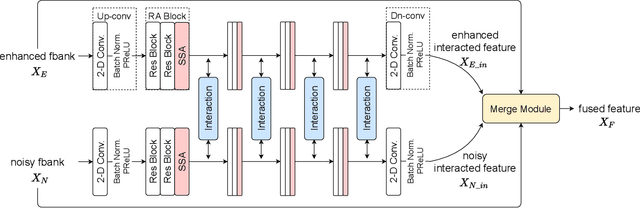
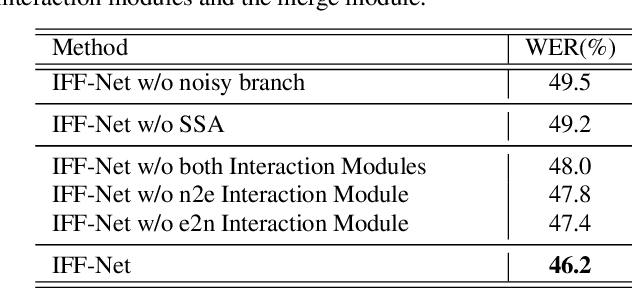
Speech enhancement (SE) aims to suppress the additive noise from a noisy speech signal to improve the speech's perceptual quality and intelligibility. However, the over-suppression phenomenon in the enhanced speech might degrade the performance of downstream automatic speech recognition (ASR) task due to the missing latent information. To alleviate such problem, we propose an interactive feature fusion network (IFF-Net) for noise-robust speech recognition to learn complementary information from the enhanced feature and original noisy feature. Experimental results show that the proposed method achieves absolute word error rate (WER) reduction of 4.1% over the best baseline on RATS Channel-A corpus. Our further analysis indicates that the proposed IFF-Net can complement some missing information in the over-suppressed enhanced feature.
Improving Performance of Semantic Segmentation CycleGANs by Noise Injection into the Latent Segmentation Space
Jan 17, 2022In recent years, semantic segmentation has taken benefit from various works in computer vision. Inspired by the very versatile CycleGAN architecture, we combine semantic segmentation with the concept of cycle consistency to enable a multitask training protocol. However, learning is largely prevented by the so-called steganography effect, which expresses itself as watermarks in the latent segmentation domain, making image reconstruction a too easy task. To combat this, we propose a noise injection, based either on quantization noise or on Gaussian noise addition to avoid this disadvantageous information flow in the cycle architecture. We find that noise injection significantly reduces the generation of watermarks and thus allows the recognition of highly relevant classes such as "traffic signs", which are hardly detected by the ERFNet baseline. We report mIoU and PSNR results on the Cityscapes dataset for semantic segmentation and image reconstruction, respectively. The proposed methodology allows to achieve an mIoU improvement on the Cityscapes validation set of 5.7% absolute over the same CycleGAN without noise injection, and still an absolute 4.9% over the ERFNet non-cyclic baseline.
Conditional Mutual information-based Contrastive Loss for Financial Time Series Forecasting
Feb 18, 2020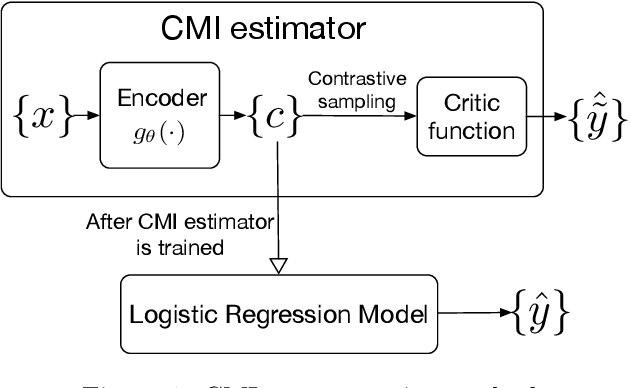



We present a method for financial time series forecasting using representation learning techniques. Recent progress on deep autoregressive models has shown their ability to capture long-term dependencies of the sequence data. However, the shortage of available financial data for training will make the deep models susceptible to the overfitting problem. In this paper, we propose a neural-network-powered conditional mutual information (CMI) estimator for learning representations for the forecasting task. Specifically, we first train an encoder to maximize the mutual information between the latent variables and the label information conditioned on the encoded observed variables. Then the features extracted from the trained encoder are used to learn a subsequent logistic regression model for predicting time series movements. Our proposed estimator transforms the CMI maximization problem to a classification problem whether two encoded representations are sampled from the same class or not. This is equivalent to perform pairwise comparisons of the training datapoints, and thus, improves the generalization ability of the deep autoregressive model. Empirical experiments indicate that our proposed method has the potential to advance the state-of-the-art performance.
SwinUNet3D -- A Hierarchical Architecture for Deep Traffic Prediction using Shifted Window Transformers
Jan 17, 2022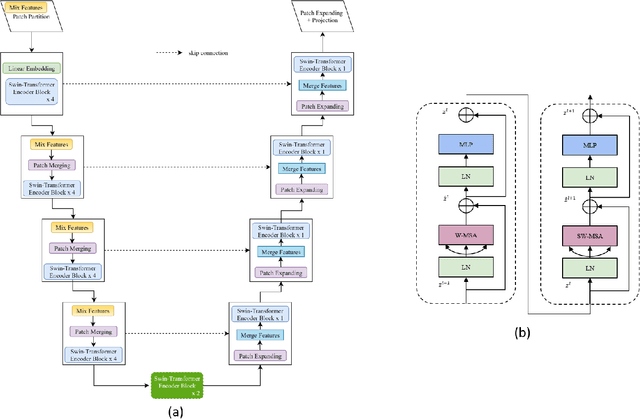
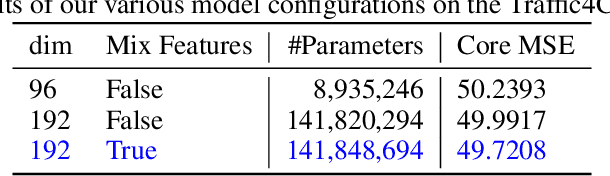

Traffic forecasting is an important element of mobility management, an important key that drives the logistics industry. Over the years, lots of work have been done in Traffic forecasting using time series as well as spatiotemporal dynamic forecasting. In this paper, we explore the use of vision transformer in a UNet setting. We completely remove all convolution-based building blocks in UNet, while using 3D shifted window transformer in both encoder and decoder branches. In addition, we experiment with the use of feature mixing just before patch encoding to control the inter-relationship of the feature while avoiding contraction of the depth dimension of our spatiotemporal input. The proposed network is tested on the data provided by Traffic Map Movie Forecasting Challenge 2021(Traffic4cast2021), held in the competition track of Neural Information Processing Systems (NeurIPS). Traffic4cast2021 task is to predict an hour (6 frames) of traffic conditions (volume and average speed)from one hour of given traffic state (12 frames averaged in 5 minutes time span). Source code is available online at https://github.com/bojesomo/Traffic4Cast2021-SwinUNet3D.