 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Closed-Loop ACAS Xu NNCS is Unsafe: Quantized State Backreachability for Verification
Jan 17, 2022
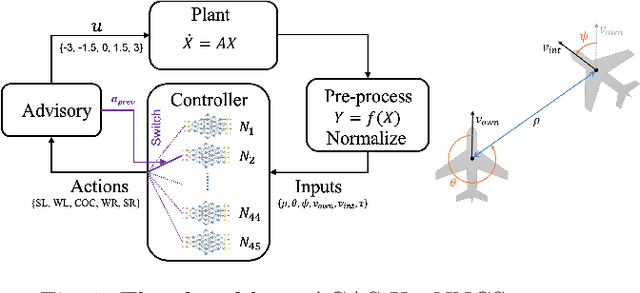
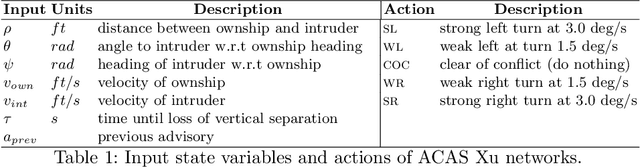
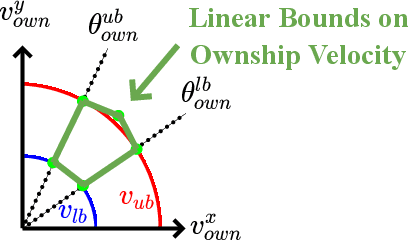
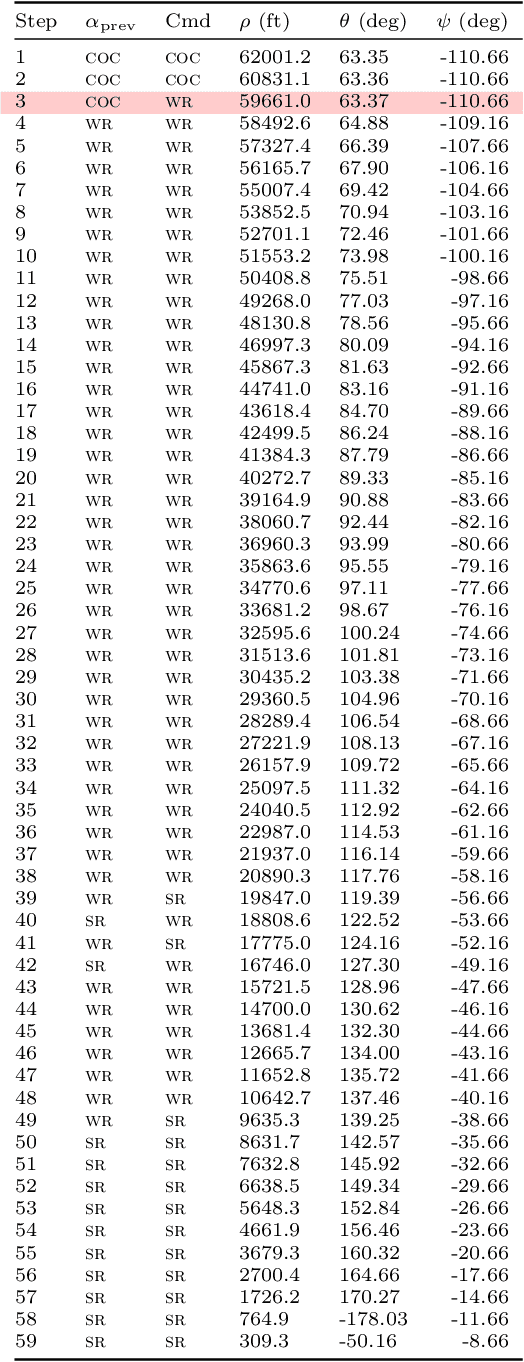
ACAS Xu is an air-to-air collision avoidance system designed for unmanned aircraft that issues horizontal turn advisories to avoid an intruder aircraft. Due the use of a large lookup table in the design, a neural network compression of the policy was proposed. Analysis of this system has spurred a significant body of research in the formal methods community on neural network verification. While many powerful methods have been developed, most work focuses on open-loop properties of the networks, rather than the main point of the system -- collision avoidance -- which requires closed-loop analysis. In this work, we develop a technique to verify a closed-loop approximation of ACAS Xu using state quantization and backreachability. We use favorable assumptions for the analysis -- perfect sensor information, instant following of advisories, ideal aircraft maneuvers and an intruder that only flies straight. When the method fails to prove the system is safe, we refine the quantization parameters until generating counterexamples where the original (non-quantized) system also has collisions.
Learning Oriented Remote Sensing Object Detection via Naive Geometric Computing
Dec 01, 2021
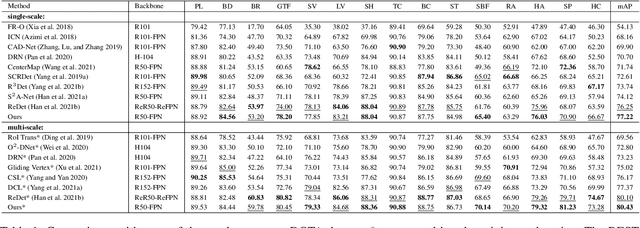
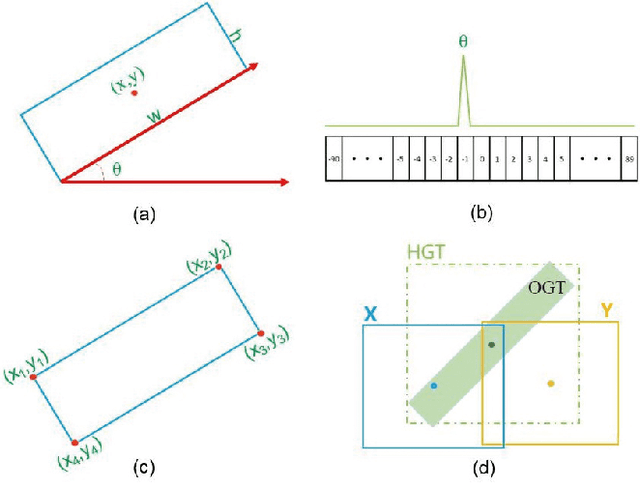
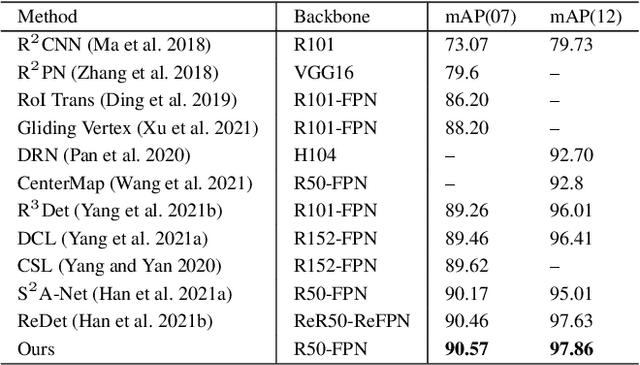
Detecting oriented objects along with estimating their rotation information is one crucial step for analyzing remote sensing images. Despite that many methods proposed recently have achieved remarkable performance, most of them directly learn to predict object directions under the supervision of only one (e.g. the rotation angle) or a few (e.g. several coordinates) groundtruth values individually. Oriented object detection would be more accurate and robust if extra constraints, with respect to proposal and rotation information regression, are adopted for joint supervision during training. To this end, we innovatively propose a mechanism that simultaneously learns the regression of horizontal proposals, oriented proposals, and rotation angles of objects in a consistent manner, via naive geometric computing, as one additional steady constraint (see Figure 1). An oriented center prior guided label assignment strategy is proposed for further enhancing the quality of proposals, yielding better performance. Extensive experiments demonstrate the model equipped with our idea significantly outperforms the baseline by a large margin to achieve a new state-of-the-art result without any extra computational burden during inference. Our proposed idea is simple and intuitive that can be readily implemented. Source codes and trained models are involved in supplementary files.
Compactness Score: A Fast Filter Method for Unsupervised Feature Selection
Jan 31, 2022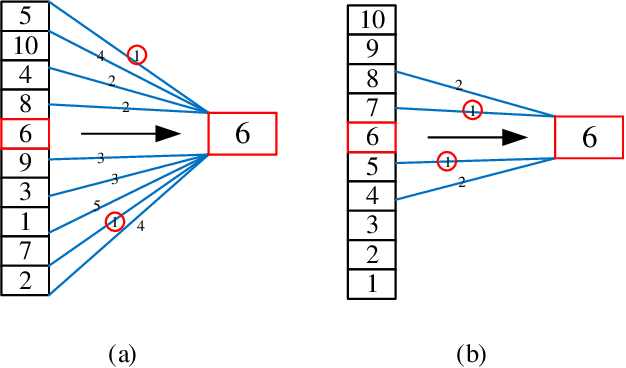
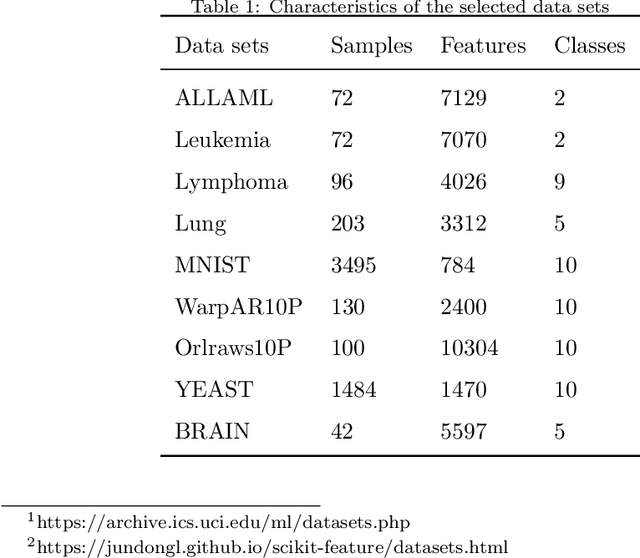
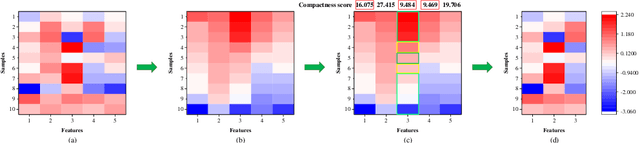
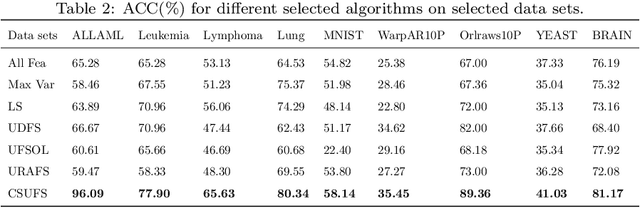
For feature engineering, feature selection seems to be an important research content in which is anticipated to select "excellent" features from candidate ones. Different functions can be realized through feature selection, such as dimensionality reduction, model effect improvement, and model performance improvement. Along with the flourish of the information age, huge amounts of high-dimensional data are generated day by day, while we need to spare great efforts and time to label such data. Therefore, various algorithms are proposed to address such data, among which unsupervised feature selection has attracted tremendous interests. In many classification tasks, researchers found that data seem to be usually close to each other if they are from the same class; thus, local compactness is of great importance for the evaluation of a feature. In this manuscript, we propose a fast unsupervised feature selection method, named as, Compactness Score (CSUFS), to select desired features. To demonstrate the efficiency and accuracy, several data sets are chosen with intensive experiments being performed. Later, the effectiveness and superiority of our method are revealed through addressing clustering tasks. Here, the performance is indicated by several well-known evaluation metrics, while the efficiency is reflected by the corresponding running time. As revealed by the simulation results, our proposed algorithm seems to be more accurate and efficient compared with existing algorithms.
When to Call Your Neighbor? Strategic Communication in Cooperative Stochastic Bandits
Oct 08, 2021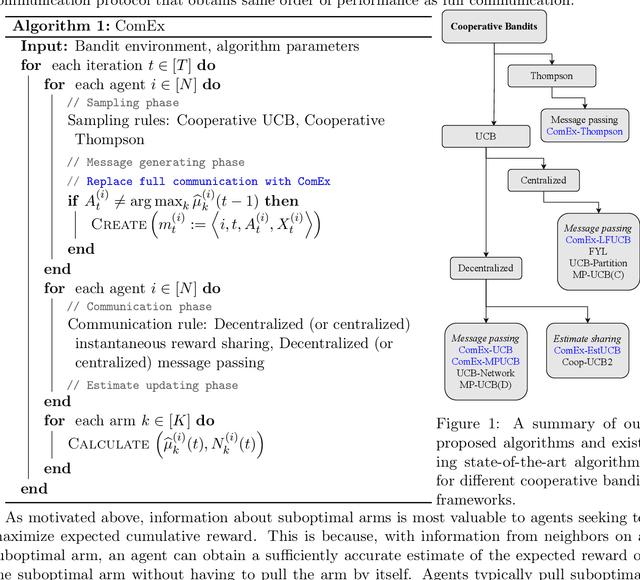
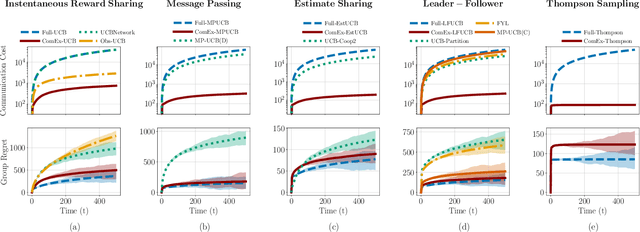
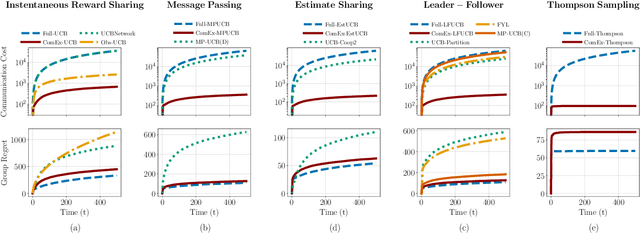
In cooperative bandits, a framework that captures essential features of collective sequential decision making, agents can minimize group regret, and thereby improve performance, by leveraging shared information. However, sharing information can be costly, which motivates developing policies that minimize group regret while also reducing the number of messages communicated by agents. Existing cooperative bandit algorithms obtain optimal performance when agents share information with their neighbors at \textit{every time step}, i.e., full communication. This requires $\Theta(T)$ number of messages, where $T$ is the time horizon of the decision making process. We propose \textit{ComEx}, a novel cost-effective communication protocol in which the group achieves the same order of performance as full communication while communicating only $O(\log T)$ number of messages. Our key step is developing a method to identify and only communicate the information crucial to achieving optimal performance. Further we propose novel algorithms for several benchmark cooperative bandit frameworks and show that our algorithms obtain \textit{state-of-the-art} performance while consistently incurring a significantly smaller communication cost than existing algorithms.
UAV Path Planning using Global and Local Map Information with Deep Reinforcement Learning
Nov 02, 2020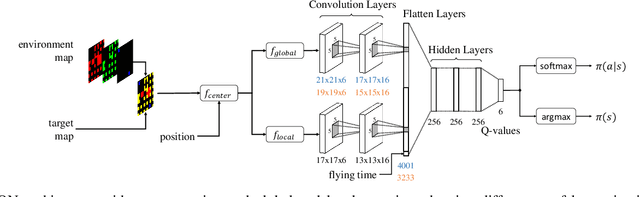
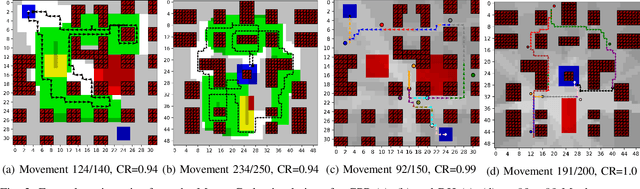
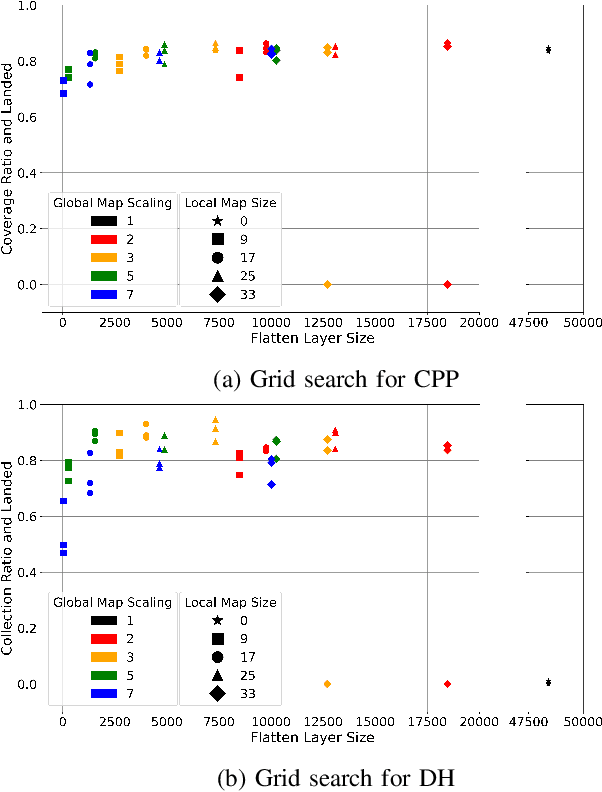
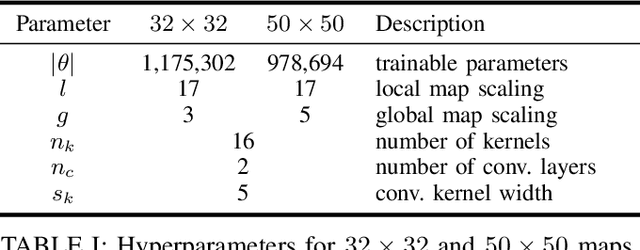
Path planning methods for autonomous unmanned aerial vehicles (UAVs) are typically designed for one specific type of mission. In this work, we present a method for autonomous UAV path planning based on deep reinforcement learning (DRL) that can be applied to a wide range of mission scenarios. Specifically, we compare coverage path planning (CPP), where the UAV's goal is to survey an area of interest to data harvesting (DH), where the UAV collects data from distributed Internet of Things (IoT) sensor devices. By exploiting structured map information of the environment, we train double deep Q-networks (DDQNs) with identical architectures on both distinctly different mission scenarios, to make movement decisions that balance the respective mission goal with navigation constraints. By introducing a novel approach exploiting a compressed global map of the environment combined with a cropped but uncompressed local map showing the vicinity of the UAV agent, we demonstrate that the proposed method can efficiently scale to large environments. We also extend previous results for generalizing control policies that require no retraining when scenario parameters change and offer a detailed analysis of crucial map processing parameters' effects on path planning performance.
Learning Transformer Features for Image Quality Assessment
Dec 01, 2021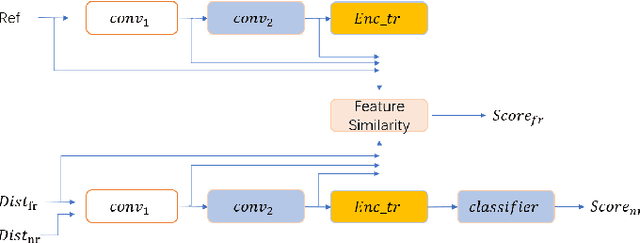
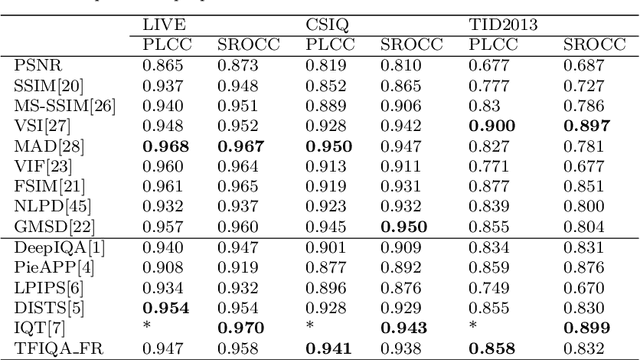
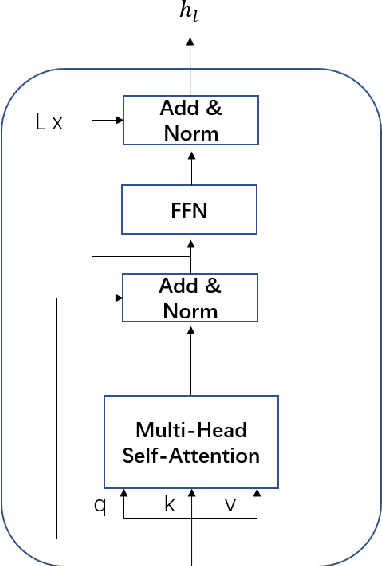
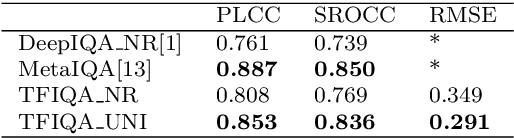
Objective image quality evaluation is a challenging task, which aims to measure the quality of a given image automatically. According to the availability of the reference images, there are Full-Reference and No-Reference IQA tasks, respectively. Most deep learning approaches use regression from deep features extracted by Convolutional Neural Networks. For the FR task, another option is conducting a statistical comparison on deep features. For all these methods, non-local information is usually neglected. In addition, the relationship between FR and NR tasks is less explored. Motivated by the recent success of transformers in modeling contextual information, we propose a unified IQA framework that utilizes CNN backbone and transformer encoder to extract features. The proposed framework is compatible with both FR and NR modes and allows for a joint training scheme. Evaluation experiments on three standard IQA datasets, i.e., LIVE, CSIQ and TID2013, and KONIQ-10K, show that our proposed model can achieve state-of-the-art FR performance. In addition, comparable NR performance is achieved in extensive experiments, and the results show that the NR performance can be leveraged by the joint training scheme.
Information State Embedding in Partially Observable Cooperative Multi-Agent Reinforcement Learning
Apr 18, 2020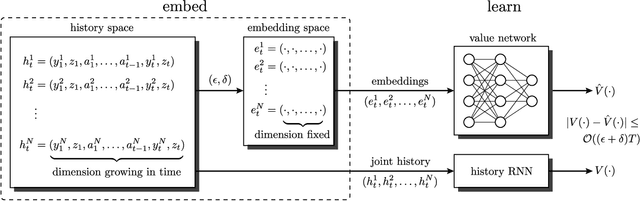
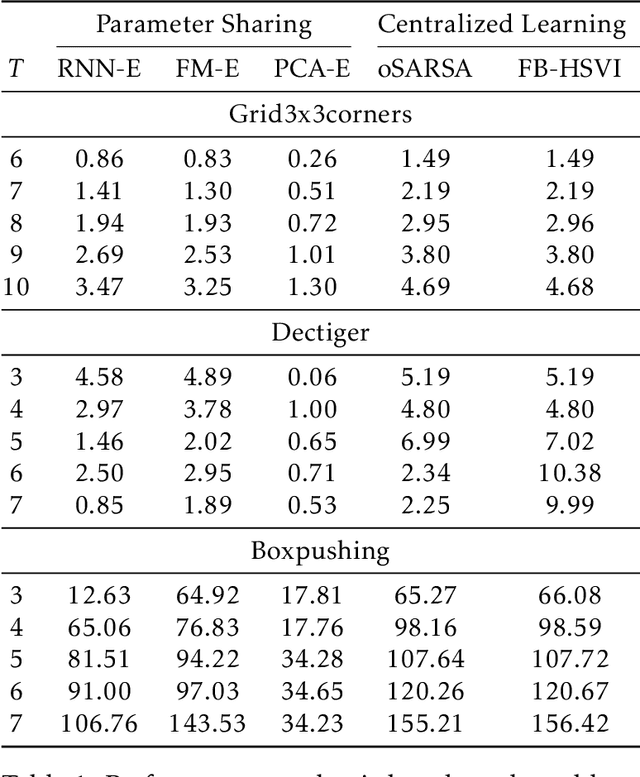
Multi-agent reinforcement learning (MARL) under partial observability has long been considered challenging, primarily due to the requirement for each agent to maintain a belief over all other agents' local histories -- a domain that generally grows exponentially over time. In this work, we investigate a partially observable MARL problem in which agents are cooperative. To enable the development of tractable algorithms, we introduce the concept of an information state embedding that serves to compress agents' histories. We quantify how the compression error influences the resulting value functions for decentralized control. Furthermore, we propose three natural embeddings, based on finite-memory truncation, principal component analysis, and recurrent neural networks. The output of these embeddings are then used as the information state, and can be fed into any MARL algorithm. The proposed embed-then-learn pipeline opens the black-box of existing MARL algorithms, allowing us to establish some theoretical guarantees (error bounds of value functions) while still achieving competitive performance with many end-to-end approaches.
Bag of Tricks for Natural Policy Gradient Reinforcement Learning
Jan 22, 2022
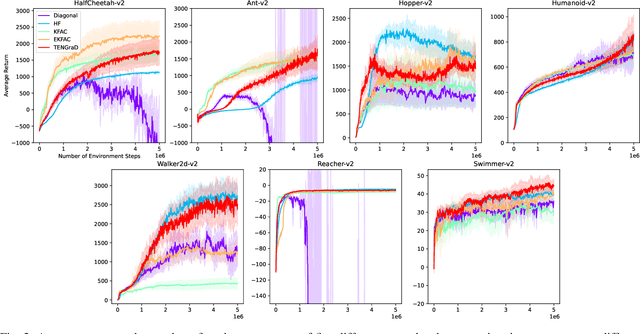

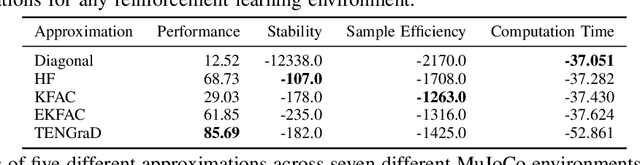
Natural policy gradient methods are popular reinforcement learning methods that improve the stability of policy gradient methods by preconditioning the gradient with the inverse of the Fisher-information matrix. However, leveraging natural policy gradient methods in an optimal manner can be very challenging as many implementation details must be set to achieve optimal performance. To the best of the authors' knowledge, there has not been a study that has investigated strategies for setting these details for natural policy gradient methods to achieve high performance in a comprehensive and systematic manner. To address this, we have implemented and compared strategies that impact performance in natural policy gradient reinforcement learning across five different second-order approximations. These include varying batch sizes and optimizing the critic network using the natural gradient. Furthermore, insights about the fundamental trade-offs when optimizing for performance (stability, sample efficiency, and computation time) were generated. Experimental results indicate that the proposed collection of strategies for performance optimization can improve results by 86% to 181% across the MuJuCo control benchmark, with TENGraD exhibiting the best approximation performance amongst the tested approximations. Code in this study is available at https://github.com/gebob19/natural-policy-gradient-reinforcement-learning.
Distributed gradient-based optimization in the presence of dependent aperiodic communication
Jan 27, 2022Iterative distributed optimization algorithms involve multiple agents that communicate with each other, over time, in order to minimize/maximize a global objective. In the presence of unreliable communication networks, the Age-of-Information (AoI), which measures the freshness of data received, may be large and hence hinder algorithmic convergence. In this paper, we study the convergence of general distributed gradient-based optimization algorithms in the presence of communication that neither happens periodically nor at stochastically independent points in time. We show that convergence is guaranteed provided the random variables associated with the AoI processes are stochastically dominated by a random variable with finite first moment. This improves on previous requirements of boundedness of more than the first moment. We then introduce stochastically strongly connected (SSC) networks, a new stochastic form of strong connectedness for time-varying networks. We show: If for any $p \ge0$ the processes that describe the success of communication between agents in a SSC network are $\alpha$-mixing with $n^{p-1}\alpha(n)$ summable, then the associated AoI processes are stochastically dominated by a random variable with finite $p$-th moment. In combination with our first contribution, this implies that distributed stochastic gradient descend converges in the presence of AoI, if $\alpha(n)$ is summable.
Multi-Modal Fusion for Sensorimotor Coordination in Steering Angle Prediction
Feb 11, 2022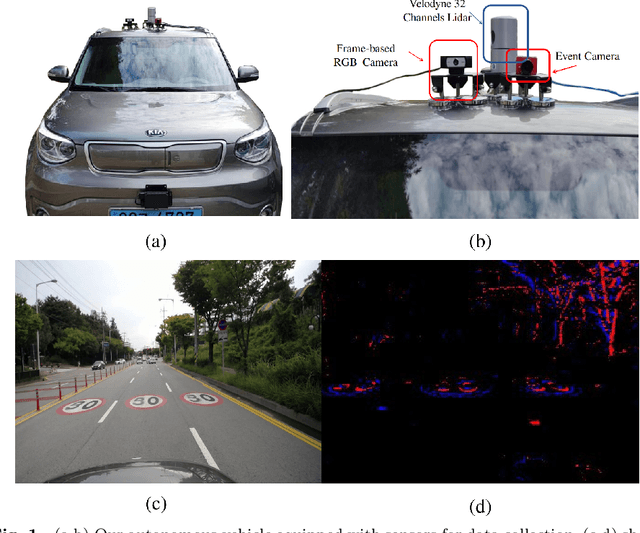
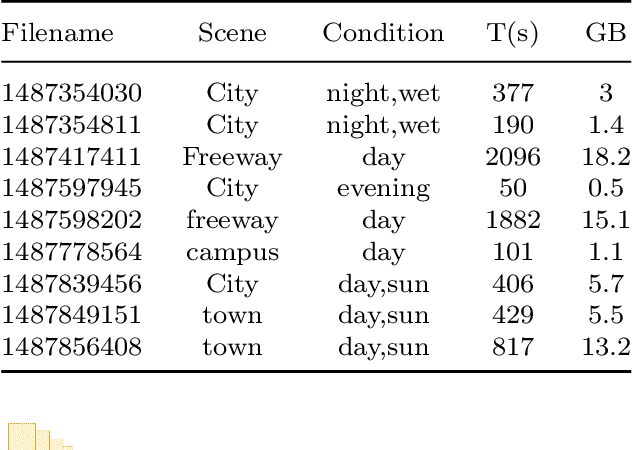
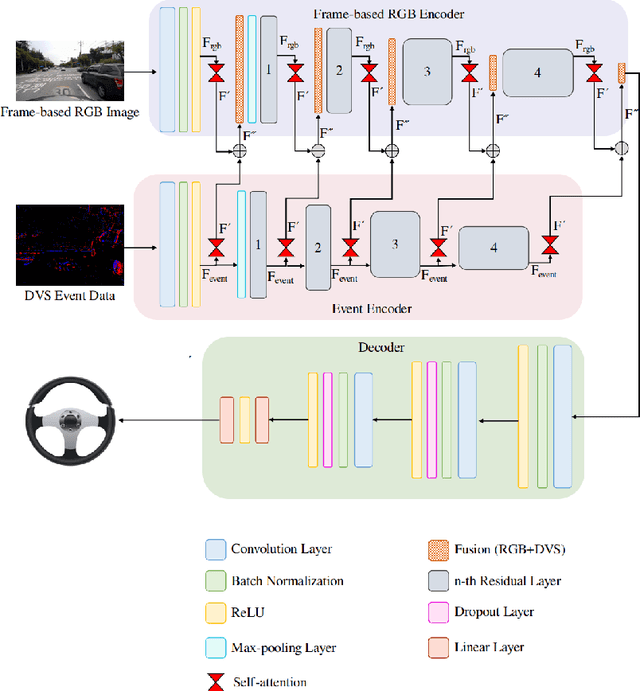
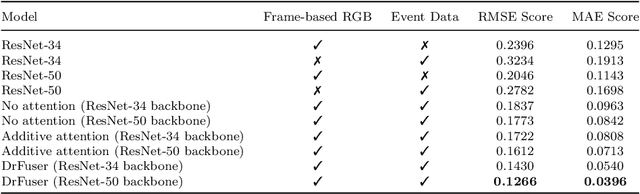
Imitation learning is employed to learn sensorimotor coordination for steering angle prediction in an end-to-end fashion requires expert demonstrations. These expert demonstrations are paired with environmental perception and vehicle control data. The conventional frame-based RGB camera is the most common exteroceptive sensor modality used to acquire the environmental perception data. The frame-based RGB camera has produced promising results when used as a single modality in learning end-to-end lateral control. However, the conventional frame-based RGB camera has limited operability in illumination variation conditions and is affected by the motion blur. The event camera provides complementary information to the frame-based RGB camera. This work explores the fusion of frame-based RGB and event data for learning end-to-end lateral control by predicting steering angle. In addition, how the representation from event data fuse with frame-based RGB data helps to predict the lateral control robustly for the autonomous vehicle. To this end, we propose DRFuser, a novel convolutional encoder-decoder architecture for learning end-to-end lateral control. The encoder module is branched between the frame-based RGB data and event data along with the self-attention layers. Moreover, this study has also contributed to our own collected dataset comprised of event, frame-based RGB, and vehicle control data. The efficacy of the proposed method is experimentally evaluated on our collected dataset, Davis Driving dataset (DDD), and Carla Eventscape dataset. The experimental results illustrate that the proposed method DRFuser outperforms the state-of-the-art in terms of root-mean-square error (RMSE) and mean absolute error (MAE) used as evaluation metrics.