 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information State Embedding in Partially Observable Cooperative Multi-Agent Reinforcement Learning
Apr 18, 2020
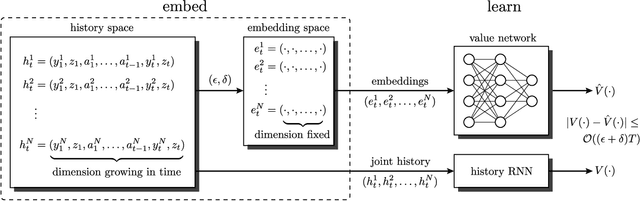
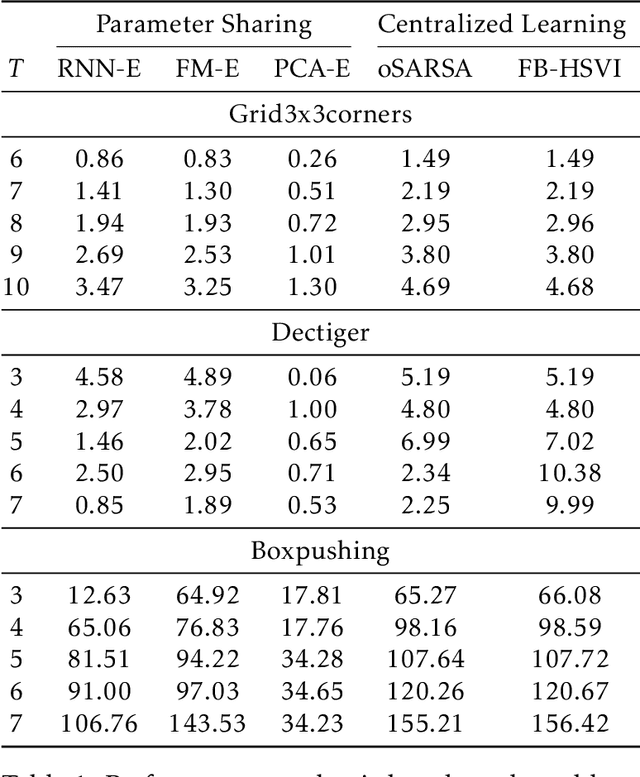
Multi-agent reinforcement learning (MARL) under partial observability has long been considered challenging, primarily due to the requirement for each agent to maintain a belief over all other agents' local histories -- a domain that generally grows exponentially over time. In this work, we investigate a partially observable MARL problem in which agents are cooperative. To enable the development of tractable algorithms, we introduce the concept of an information state embedding that serves to compress agents' histories. We quantify how the compression error influences the resulting value functions for decentralized control. Furthermore, we propose three natural embeddings, based on finite-memory truncation, principal component analysis, and recurrent neural networks. The output of these embeddings are then used as the information state, and can be fed into any MARL algorithm. The proposed embed-then-learn pipeline opens the black-box of existing MARL algorithms, allowing us to establish some theoretical guarantees (error bounds of value functions) while still achieving competitive performance with many end-to-end approaches.
GeoNeRF: Generalizing NeRF with Geometry Priors
Nov 26, 2021

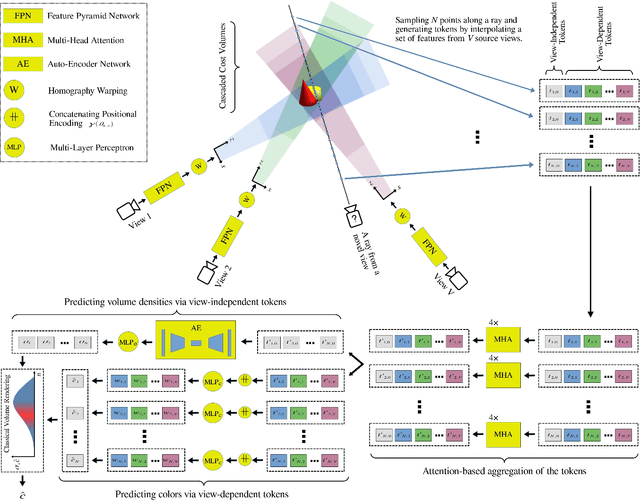
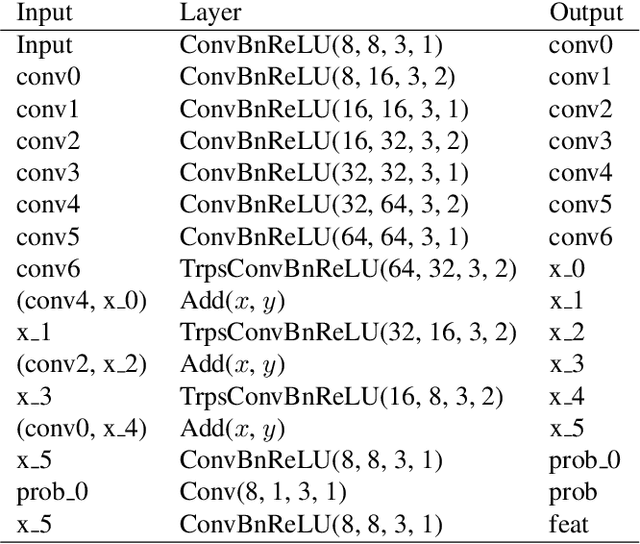
We present GeoNeRF, a generalizable photorealistic novel view synthesis method based on neural radiance fields. Our approach consists of two main stages: a geometry reasoner and a renderer. To render a novel view, the geometry reasoner first constructs cascaded cost volumes for each nearby source view. Then, using a Transformer-based attention mechanism and the cascaded cost volumes, the renderer infers geometry and appearance, and renders detailed images via classical volume rendering techniques. This architecture, in particular, allows sophisticated occlusion reasoning, gathering information from consistent source views. Moreover, our method can easily be fine-tuned on a single scene, and renders competitive results with per-scene optimized neural rendering methods with a fraction of computational cost. Experiments show that GeoNeRF outperforms state-of-the-art generalizable neural rendering models on various synthetic and real datasets. Lastly, with a slight modification to the geometry reasoner, we also propose an alternative model that adapts to RGBD images. This model directly exploits the depth information often available thanks to depth sensors. The implementation code will be publicly available.
Beyond ImageNet Attack: Towards Crafting Adversarial Examples for Black-box Domains
Jan 27, 2022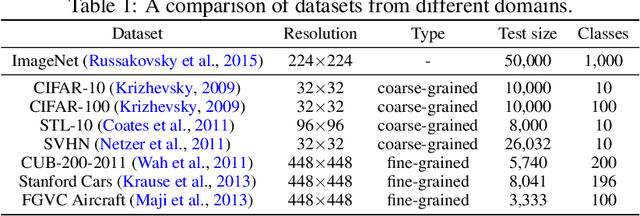
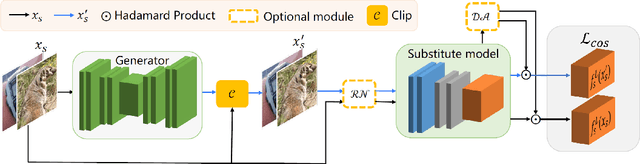
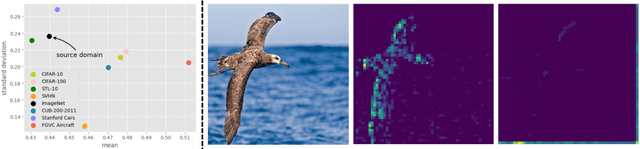
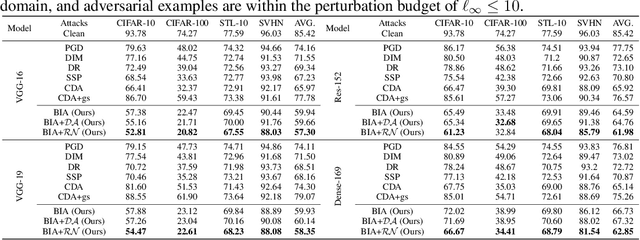
Adversarial examples have posed a severe threat to deep neural networks due to their transferable nature. Currently, various works have paid great efforts to enhance the cross-model transferability, which mostly assume the substitute model is trained in the same domain as the target model. However, in reality, the relevant information of the deployed model is unlikely to leak. Hence, it is vital to build a more practical black-box threat model to overcome this limitation and evaluate the vulnerability of deployed models. In this paper, with only the knowledge of the ImageNet domain, we propose a Beyond ImageNet Attack (BIA) to investigate the transferability towards black-box domains (unknown classification tasks). Specifically, we leverage a generative model to learn the adversarial function for disrupting low-level features of input images. Based on this framework, we further propose two variants to narrow the gap between the source and target domains from the data and model perspectives, respectively. Extensive experiments on coarse-grained and fine-grained domains demonstrate the effectiveness of our proposed methods. Notably, our methods outperform state-of-the-art approaches by up to 7.71\% (towards coarse-grained domains) and 25.91\% (towards fine-grained domains) on average. Our code is available at \url{https://github.com/qilong-zhang/Beyond-ImageNet-Attack}.
UAV Path Planning using Global and Local Map Information with Deep Reinforcement Learning
Nov 02, 2020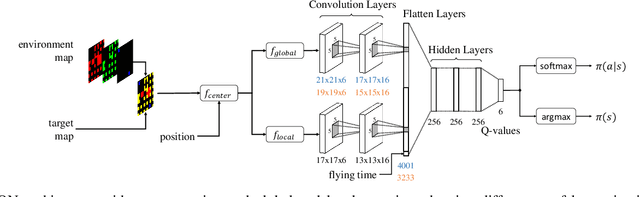
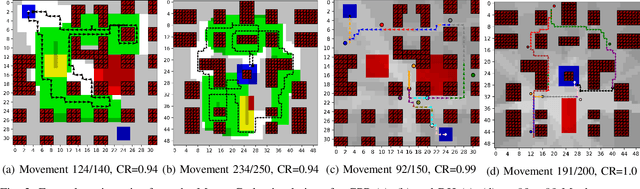
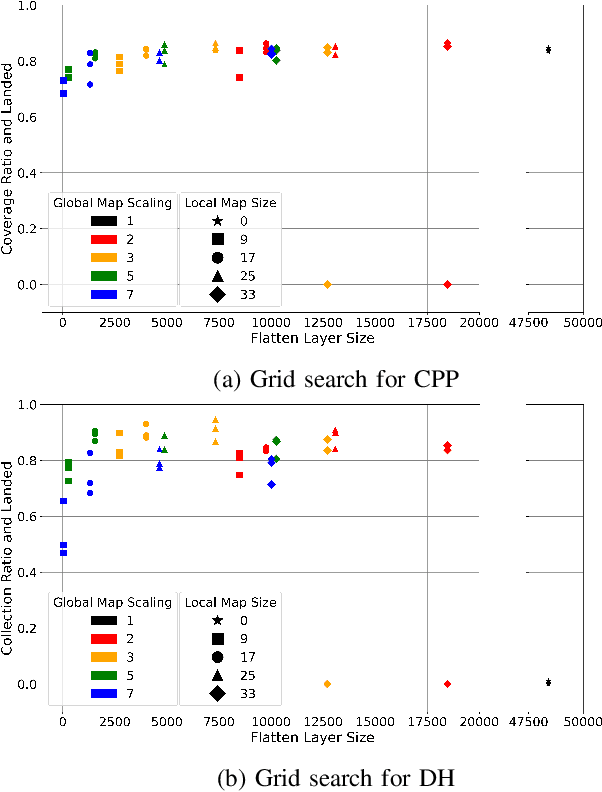
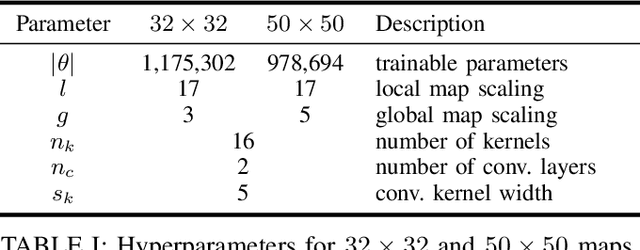
Path planning methods for autonomous unmanned aerial vehicles (UAVs) are typically designed for one specific type of mission. In this work, we present a method for autonomous UAV path planning based on deep reinforcement learning (DRL) that can be applied to a wide range of mission scenarios. Specifically, we compare coverage path planning (CPP), where the UAV's goal is to survey an area of interest to data harvesting (DH), where the UAV collects data from distributed Internet of Things (IoT) sensor devices. By exploiting structured map information of the environment, we train double deep Q-networks (DDQNs) with identical architectures on both distinctly different mission scenarios, to make movement decisions that balance the respective mission goal with navigation constraints. By introducing a novel approach exploiting a compressed global map of the environment combined with a cropped but uncompressed local map showing the vicinity of the UAV agent, we demonstrate that the proposed method can efficiently scale to large environments. We also extend previous results for generalizing control policies that require no retraining when scenario parameters change and offer a detailed analysis of crucial map processing parameters' effects on path planning performance.
Joint transmit and reflective beamforming for IRS-assisted integrated sensing and communication
Nov 26, 2021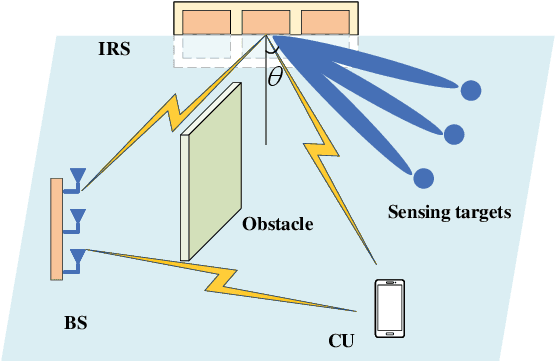
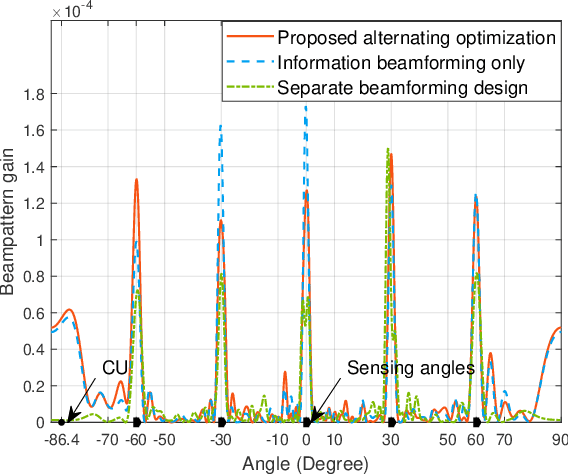
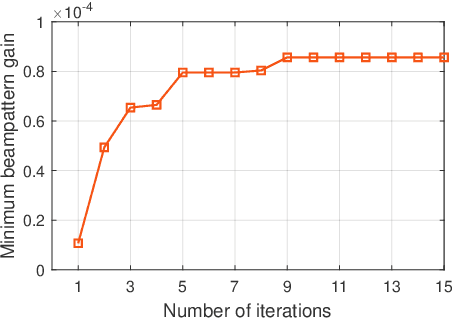
This letter studies an intelligent reflecting surface (IRS)-assisted integrated sensing and communication (ISAC) system, in which one IRS is deployed to not only assist the wireless communication from a multi-antenna base station (BS) to a single-antenna communication user (CU), but also create virtual line-of-sight (LoS) links for sensing targets at areas with LoS links blocked. We consider that the BS transmits combined information and sensing signals for ISAC. Under this setup, we jointly optimize the transmit information and sensing beamforming at the BS and the reflective beamforming at the IRS, to maximize the IRS's minimum beampattern gain towards the desired sensing angles, subject to the minimum signal-to-noise ratio (SNR) requirement at the CU and the maximum transmit power constraint at the BS. Although the formulated SNR-constrained beampattern gain maximization problem is non-convex and difficult to solve, we present an efficient algorithm to obtain a high-quality solution using alternating optimization and semi-definite relaxation (SDR). Numerical results show that the proposed algorithm achieves improved sensing performance while ensuring the communication requirement.
Structure and position-aware graph neural network for airway labeling
Jan 12, 2022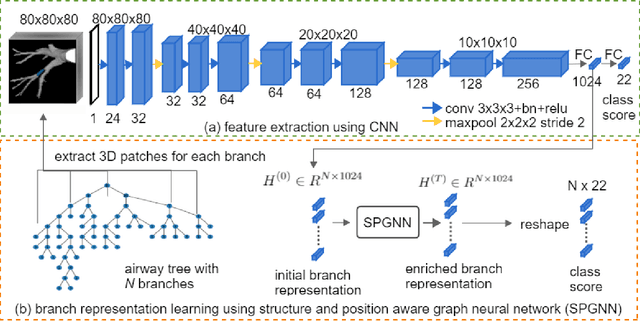
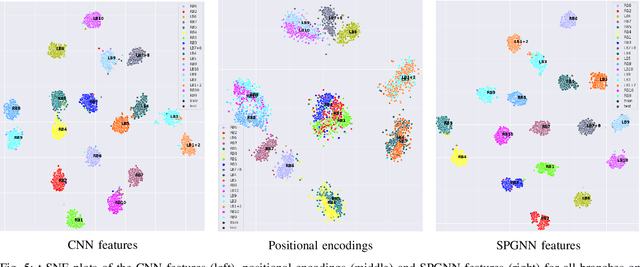
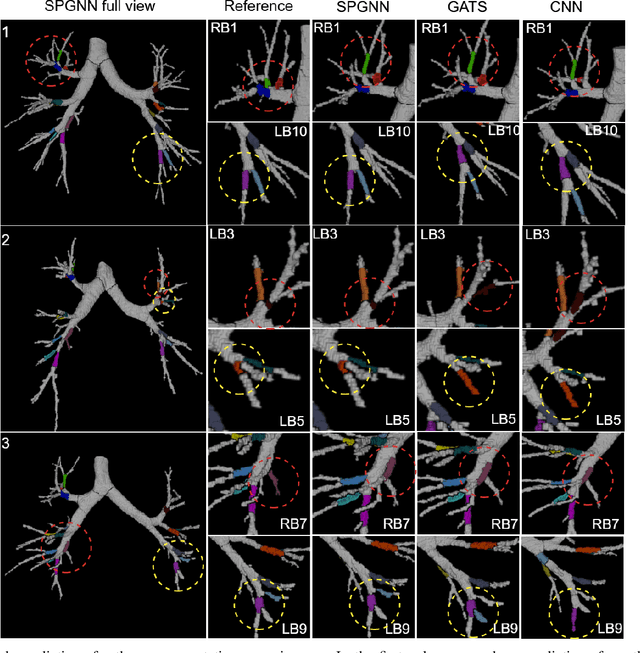
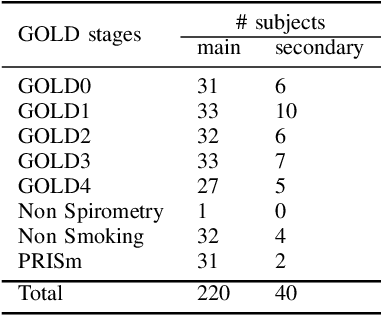
We present a novel graph-based approach for labeling the anatomical branches of a given airway tree segmentation. The proposed method formulates airway labeling as a branch classification problem in the airway tree graph, where branch features are extracted using convolutional neural networks (CNN) and enriched using graph neural networks. Our graph neural network is structure-aware by having each node aggregate information from its local neighbors and position-aware by encoding node positions in the graph. We evaluated the proposed method on 220 airway trees from subjects with various severity stages of Chronic Obstructive Pulmonary Disease (COPD). The results demonstrate that our approach is computationally efficient and significantly improves branch classification performance than the baseline method. The overall average accuracy of our method reaches 91.18\% for labeling all 18 segmental airway branches, compared to 83.83\% obtained by the standard CNN method. We published our source code at https://github.com/DIAGNijmegen/spgnn. The proposed algorithm is also publicly available at https://grand-challenge.org/algorithms/airway-anatomical-labeling/.
SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation
Feb 11, 2022

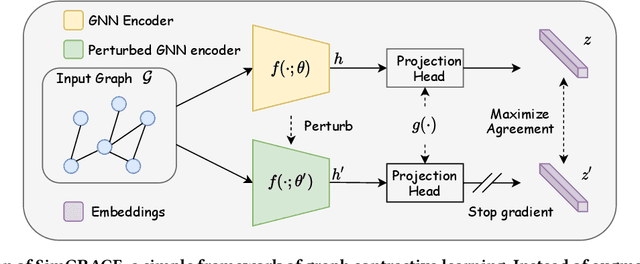
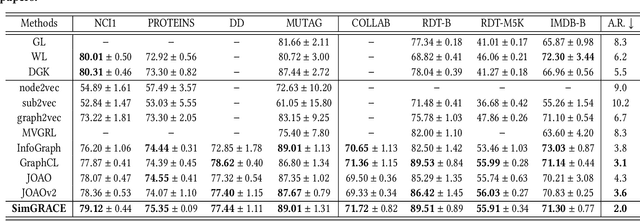
Graph contrastive learning (GCL) has emerged as a dominant technique for graph representation learning which maximizes the mutual information between paired graph augmentations that share the same semantics. Unfortunately, it is difficult to preserve semantics well during augmentations in view of the diverse nature of graph data. Currently, data augmentations in GCL that are designed to preserve semantics broadly fall into three unsatisfactory ways. First, the augmentations can be manually picked per dataset by trial-and-errors. Second, the augmentations can be selected via cumbersome search. Third, the augmentations can be obtained by introducing expensive domain-specific knowledge as guidance. All of these limit the efficiency and more general applicability of existing GCL methods. To circumvent these crucial issues, we propose a \underline{Sim}ple framework for \underline{GRA}ph \underline{C}ontrastive l\underline{E}arning, \textbf{SimGRACE} for brevity, which does not require data augmentations. Specifically, we take original graph as input and GNN model with its perturbed version as two encoders to obtain two correlated views for contrast. SimGRACE is inspired by the observation that graph data can preserve their semantics well during encoder perturbations while not requiring manual trial-and-errors, cumbersome search or expensive domain knowledge for augmentations selection. Also, we explain why SimGRACE can succeed. Furthermore, we devise adversarial training scheme, dubbed \textbf{AT-SimGRACE}, to enhance the robustness of graph contrastive learning and theoretically explain the reasons. Albeit simple, we show that SimGRACE can yield competitive or better performance compared with state-of-the-art methods in terms of generalizability, transferability and robustness, while enjoying unprecedented degree of flexibility and efficiency.
* Accepted by The Web Conference 2022 (WWW 2022)
Spectral image clustering on dual-energy CT scans using functional regression mixtures
Jan 31, 2022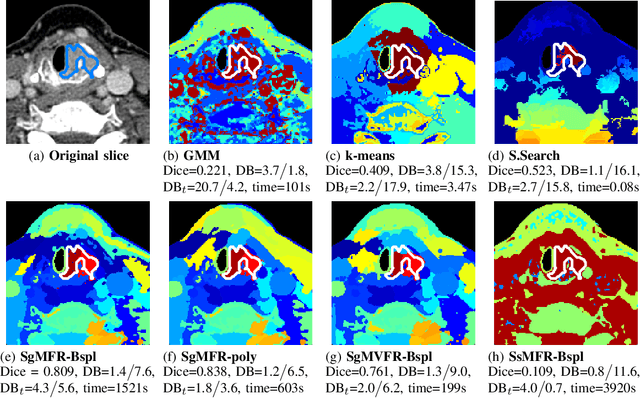
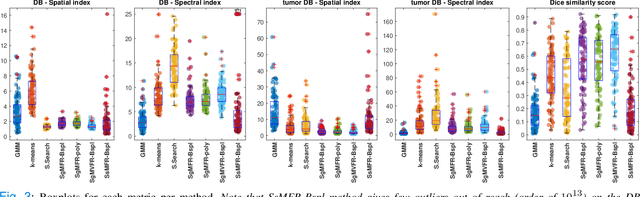
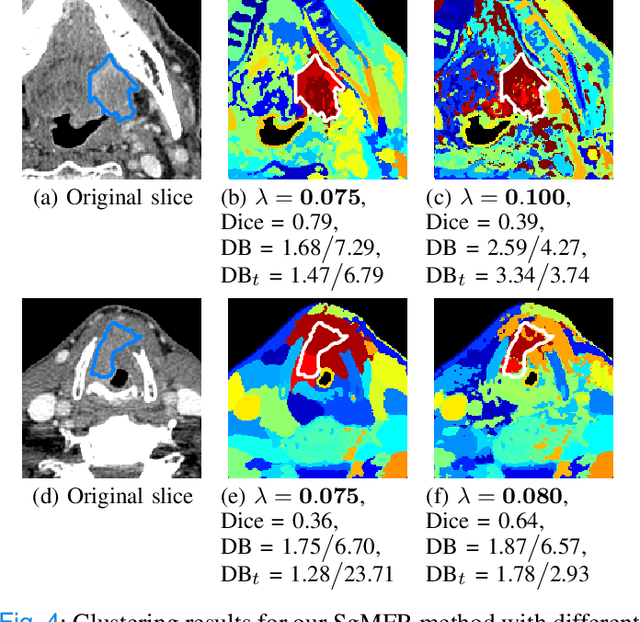
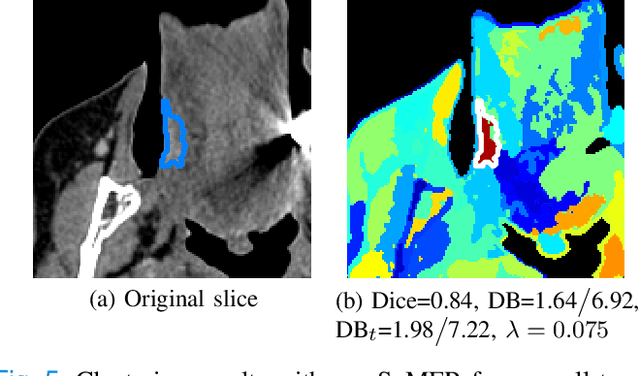
Dual-energy computed tomography (DECT) is an advanced CT scanning technique enabling material characterization not possible with conventional CT scans. It allows the reconstruction of energy decay curves at each 3D image voxel, representing varying image attenuation at different effective scanning energy levels. In this paper, we develop novel functional data analysis (FDA) techniques and adapt them to the analysis of DECT decay curves. More specifically, we construct functional mixture models that integrate spatial context in mixture weights, with mixture component densities being constructed upon the energy decay curves as functional observations. We design unsupervised clustering algorithms by developing dedicated expectation maximization (EM) algorithms for the maximum likelihood estimation of the model parameters. To our knowledge, this is the first article to adapt statistical FDA tools and model-based clustering to take advantage of the full spectral information provided by DECT. We evaluate our methods on 91 head and neck cancer DECT scans. We compare our unsupervised clustering results to tumor contours traced manually by radiologists, as well as to several baseline algorithms. Given the inter-rater variability even among experts at delineating head and neck tumors, and given the potential importance of tissue reactions surrounding the tumor itself, our proposed methodology has the potential to add value in downstream machine learning applications for clinical outcome prediction based on DECT data in head and neck cancer.
Relevance Vector Machine with Weakly Informative Hyperprior and Extended Predictive Information Criterion
May 07, 2020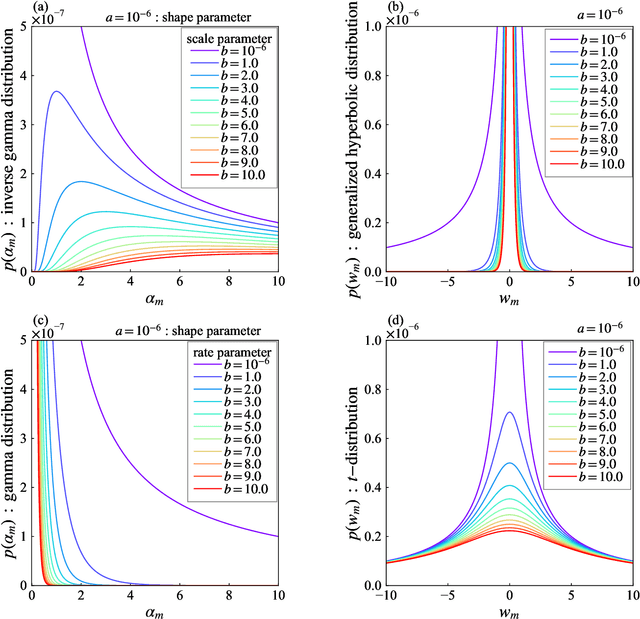
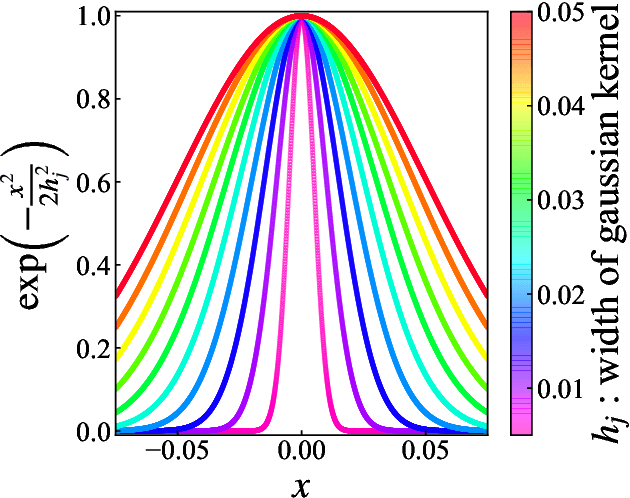
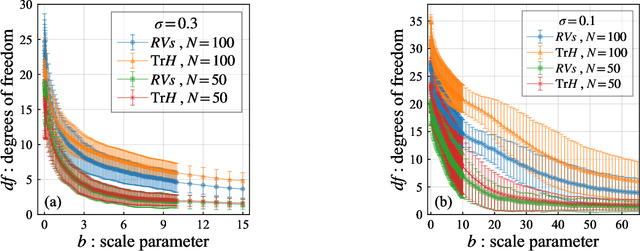
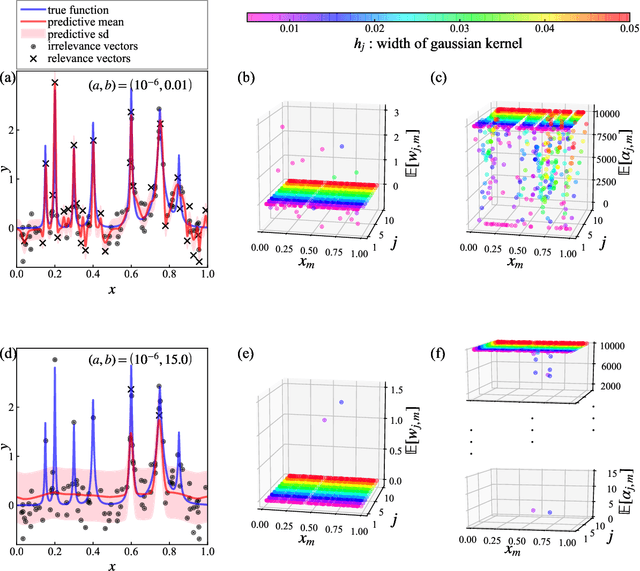
In the variational relevance vector machine, the gamma distribution is representative as a hyperprior over the noise precision of automatic relevance determination prior. Instead of the gamma hyperprior, we propose to use the inverse gamma hyperprior with a shape parameter close to zero and a scale parameter not necessary close to zero. This hyperprior is associated with the concept of a weakly informative prior. The effect of this hyperprior is investigated through regression to non-homogeneous data. Because it is difficult to capture the structure of such data with a single kernel function, we apply the multiple kernel method, in which multiple kernel functions with different widths are arranged for input data. We confirm that the degrees of freedom in a model is controlled by adjusting the scale parameter and keeping the shape parameter close to zero. A candidate for selecting the scale parameter is the predictive information criterion. However the estimated model using this criterion seems to cause over-fitting. This is because the multiple kernel method makes the model a situation where the dimension of the model is larger than the data size. To select an appropriate scale parameter even in such a situation, we also propose an extended prediction information criterion. It is confirmed that a multiple kernel relevance vector regression model with good predictive accuracy can be obtained by selecting the scale parameter minimizing extended prediction information criterion.
A Survey on Using Gaze Behaviour for Natural Language Processing
Jan 03, 2022
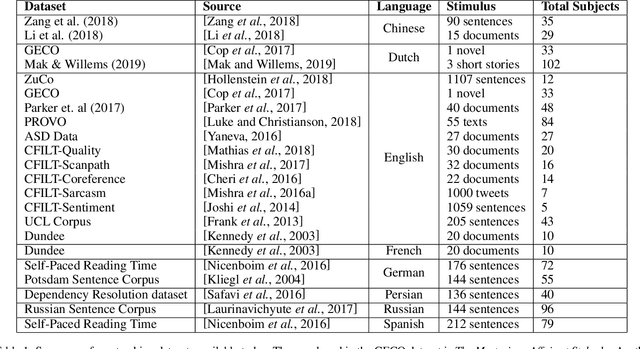

Gaze behaviour has been used as a way to gather cognitive information for a number of years. In this paper, we discuss the use of gaze behaviour in solving different tasks in natural language processing (NLP) without having to record it at test time. This is because the collection of gaze behaviour is a costly task, both in terms of time and money. Hence, in this paper, we focus on research done to alleviate the need for recording gaze behaviour at run time. We also mention different eye tracking corpora in multiple languages, which are currently available and can be used in natural language processing. We conclude our paper by discussing applications in a domain - education - and how learning gaze behaviour can help in solving the tasks of complex word identification and automatic essay grading.