 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Autoencoding Video Latents for Adversarial Video Generation
Jan 18, 2022
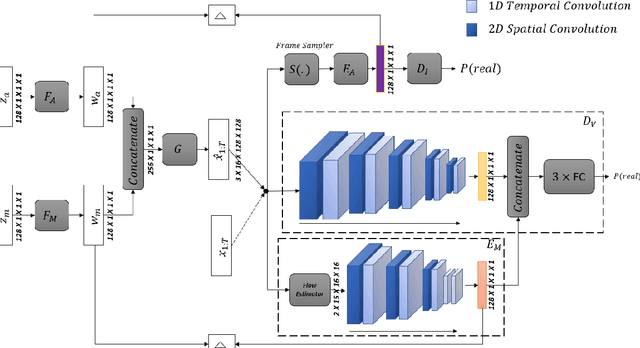
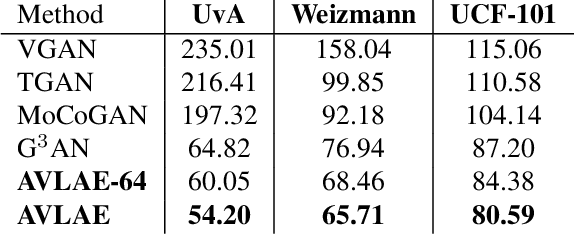
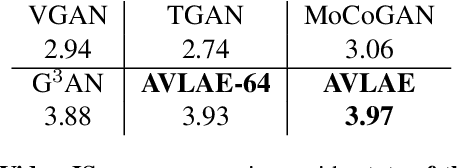

Given the three dimensional complexity of a video signal, training a robust and diverse GAN based video generative model is onerous due to large stochasticity involved in data space. Learning disentangled representations of the data help to improve robustness and provide control in the sampling process. For video generation, there is a recent progress in this area by considering motion and appearance as orthogonal information and designing architectures that efficiently disentangle them. These approaches rely on handcrafting architectures that impose structural priors on the generator to decompose appearance and motion codes in the latent space. Inspired from the recent advancements in the autoencoder based image generation, we present AVLAE (Adversarial Video Latent AutoEncoder) which is a two stream latent autoencoder where the video distribution is learned by adversarial training. In particular, we propose to autoencode the motion and appearance latent vectors of the video generator in the adversarial setting. We demonstrate that our approach learns to disentangle motion and appearance codes even without the explicit structural composition in the generator. Several experiments with qualitative and quantitative results demonstrate the effectiveness of our method.
Asymmetric Graph Representation Learning
Oct 14, 2021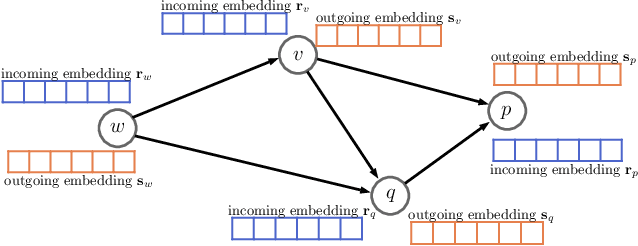
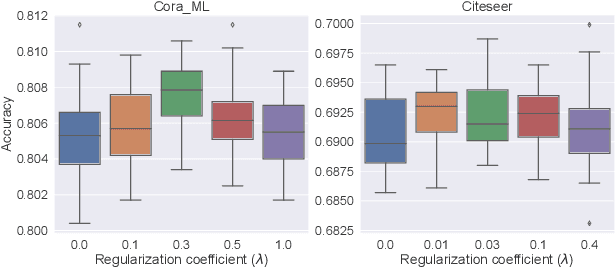
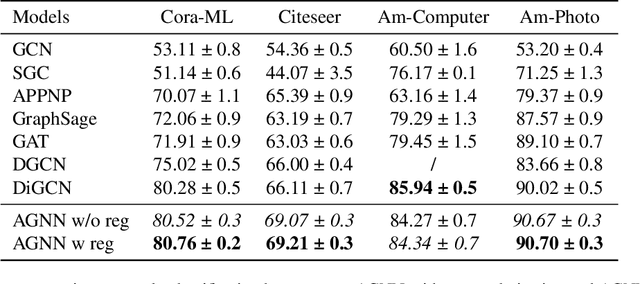
Despite the enormous success of graph neural networks (GNNs), most existing GNNs can only be applicable to undirected graphs where relationships among connected nodes are two-way symmetric (i.e., information can be passed back and forth). However, there is a vast amount of applications where the information flow is asymmetric, leading to directed graphs where information can only be passed in one direction. For example, a directed edge indicates that the information can only be conveyed forwardly from the start node to the end node, but not backwardly. To accommodate such an asymmetric structure of directed graphs within the framework of GNNs, we propose a simple yet remarkably effective framework for directed graph analysis to incorporate such one-way information passing. We define an incoming embedding and an outgoing embedding for each node to model its sending and receiving features respectively. We further develop two steps in our directed GNN model with the first one to aggregate/update the incoming features of nodes and the second one to aggregate/update the outgoing features. By imposing the two roles for each node, the likelihood of a directed edge can be calculated based on the outgoing embedding of the start node and the incoming embedding of the end node. The log-likelihood of all edges plays a natural role of regularization for the proposed model, which can alleviate the over-smoothing problem of the deep GNNs. Extensive experiments on multiple real-world directed graphs demonstrate outstanding performances of the proposed model in both node-level and graph-level tasks.
Largest Eigenvalues of the Conjugate Kernel of Single-Layered Neural Networks
Jan 13, 2022
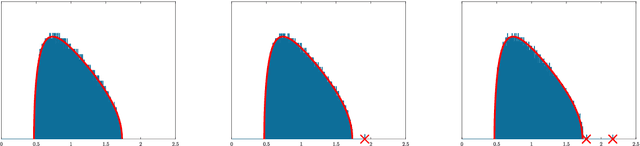
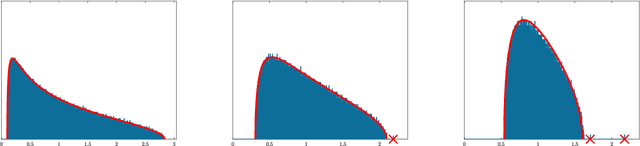
This paper is concerned with the asymptotic distribution of the largest eigenvalues for some nonlinear random matrix ensemble stemming from the study of neural networks. More precisely we consider $M= \frac{1}{m} YY^\top$ with $Y=f(WX)$ where $W$ and $X$ are random rectangular matrices with i.i.d. centered entries. This models the data covariance matrix or the Conjugate Kernel of a single layered random Feed-Forward Neural Network. The function $f$ is applied entrywise and can be seen as the activation function of the neural network. We show that the largest eigenvalue has the same limit (in probability) as that of some well-known linear random matrix ensembles. In particular, we relate the asymptotic limit of the largest eigenvalue for the nonlinear model to that of an information-plus-noise random matrix, establishing a possible phase transition depending on the function $f$ and the distribution of $W$ and $X$. This may be of interest for applications to machine learning.
Relational Graph Learning for Grounded Video Description Generation
Dec 02, 2021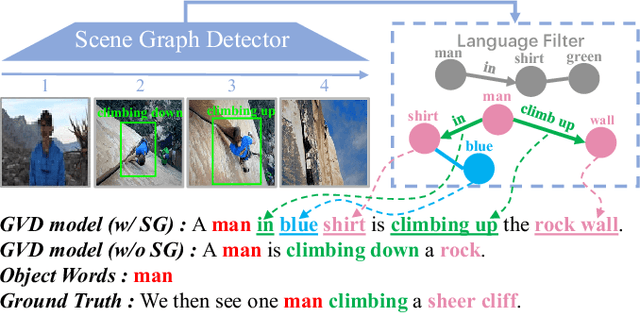
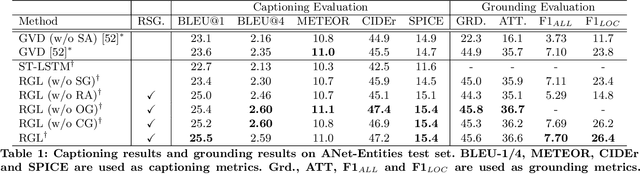
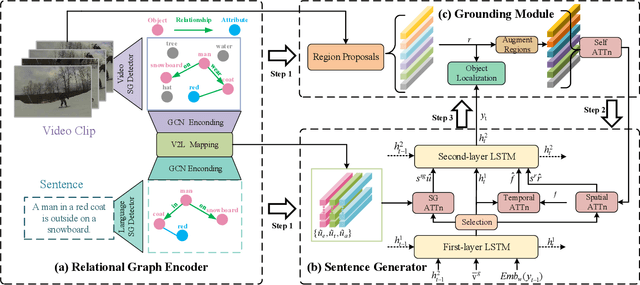
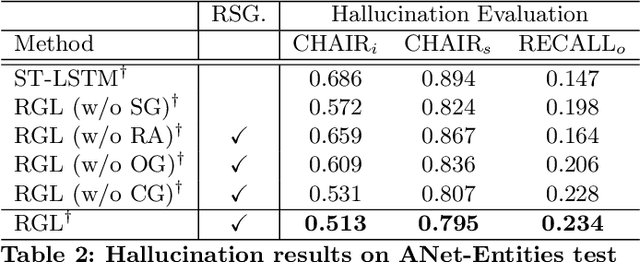
Grounded video description (GVD) encourages captioning models to attend to appropriate video regions (e.g., objects) dynamically and generate a description. Such a setting can help explain the decisions of captioning models and prevents the model from hallucinating object words in its description. However, such design mainly focuses on object word generation and thus may ignore fine-grained information and suffer from missing visual concepts. Moreover, relational words (e.g., "jump left or right") are usual spatio-temporal inference results, i.e., these words cannot be grounded on certain spatial regions. To tackle the above limitations, we design a novel relational graph learning framework for GVD, in which a language-refined scene graph representation is designed to explore fine-grained visual concepts. Furthermore, the refined graph can be regarded as relational inductive knowledge to assist captioning models in selecting the relevant information it needs to generate correct words. We validate the effectiveness of our model through automatic metrics and human evaluation, and the results indicate that our approach can generate more fine-grained and accurate description, and it solves the problem of object hallucination to some extent.
Lightweight Compositional Embeddings for Incremental Streaming Recommendation
Feb 04, 2022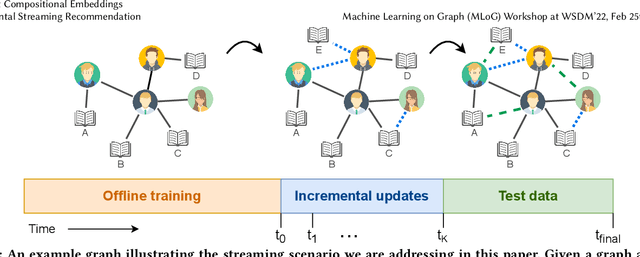

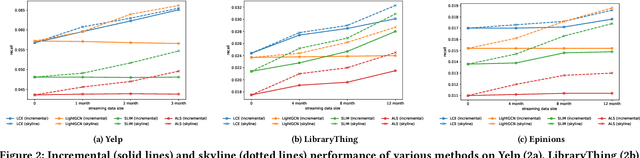
Most work in graph-based recommender systems considers a {\em static} setting where all information about test nodes (i.e., users and items) is available upfront at training time. However, this static setting makes little sense for many real-world applications where data comes in continuously as a stream of new edges and nodes, and one has to update model predictions incrementally to reflect the latest state. To fully capitalize on the newly available data in the stream, recent graph-based recommendation models would need to be repeatedly retrained, which is infeasible in practice. In this paper, we study the graph-based streaming recommendation setting and propose a compositional recommendation model -- Lightweight Compositional Embedding (LCE) -- that supports incremental updates under low computational cost. Instead of learning explicit embeddings for the full set of nodes, LCE learns explicit embeddings for only a subset of nodes and represents the other nodes {\em implicitly}, through a composition function based on their interactions in the graph. This provides an effective, yet efficient, means to leverage streaming graph data when one node type (e.g., items) is more amenable to static representation. We conduct an extensive empirical study to compare LCE to a set of competitive baselines on three large-scale user-item recommendation datasets with interactions under a streaming setting. The results demonstrate the superior performance of LCE, showing that it achieves nearly skyline performance with significantly fewer parameters than alternative graph-based models.
MetaKG: Meta-learning on Knowledge Graph for Cold-start Recommendation
Feb 08, 2022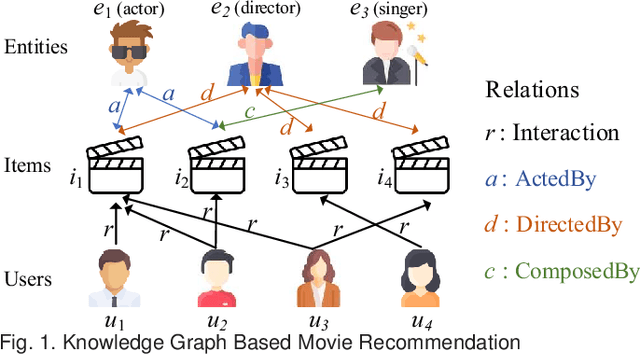
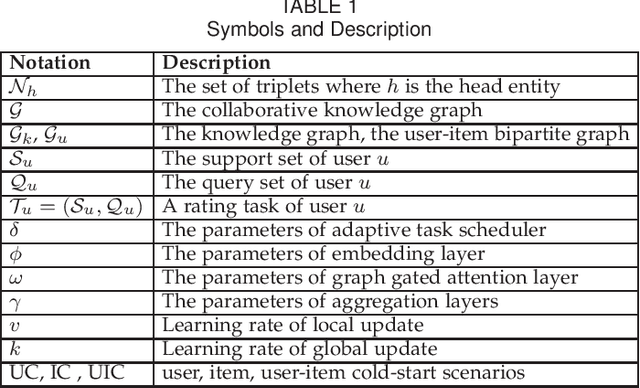
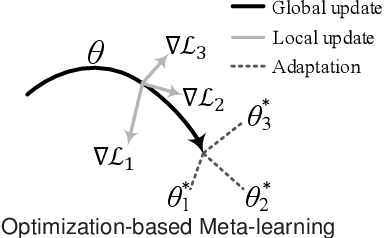
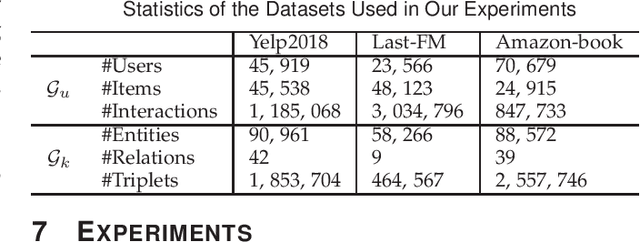
A knowledge graph (KG) consists of a set of interconnected typed entities and their attributes. Recently, KGs are popularly used as the auxiliary information to enable more accurate, explainable, and diverse user preference recommendations. Specifically, existing KG-based recommendation methods target modeling high-order relations/dependencies from long connectivity user-item interactions hidden in KG. However, most of them ignore the cold-start problems (i.e., user cold-start and item cold-start) of recommendation analytics, which restricts their performance in scenarios when involving new users or new items. Inspired by the success of meta-learning on scarce training samples, we propose a novel meta-learning based framework called MetaKG, which encompasses a collaborative-aware meta learner and a knowledge-aware meta learner, to capture meta users' preference and entities' knowledge for cold-start recommendations. The collaborative-aware meta learner aims to locally aggregate user preferences for each user preference learning task. In contrast, the knowledge-aware meta learner is to globally generalize knowledge representation across different user preference learning tasks. Guided by two meta learners, MetaKG can effectively capture the high-order collaborative relations and semantic representations, which could be easily adapted to cold-start scenarios. Besides, we devise a novel adaptive task scheduler which can adaptively select the informative tasks for meta learning in order to prevent the model from being corrupted by noisy tasks. Extensive experiments on various cold-start scenarios using three real data sets demonstrate that our presented MetaKG outperforms all the existing state-of-the-art competitors in terms of effectiveness, efficiency, and scalability.
Resistance Training using Prior Bias: toward Unbiased Scene Graph Generation
Jan 18, 2022


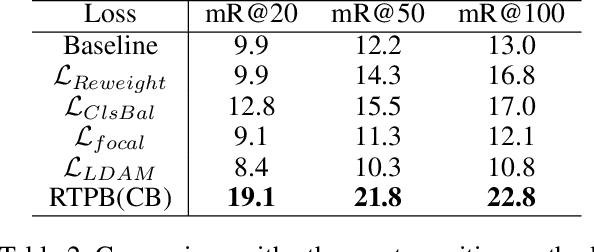
Scene Graph Generation (SGG) aims to build a structured representation of a scene using objects and pairwise relationships, which benefits downstream tasks. However, current SGG methods usually suffer from sub-optimal scene graph generation because of the long-tailed distribution of training data. To address this problem, we propose Resistance Training using Prior Bias (RTPB) for the scene graph generation. Specifically, RTPB uses a distributed-based prior bias to improve models' detecting ability on less frequent relationships during training, thus improving the model generalizability on tail categories. In addition, to further explore the contextual information of objects and relationships, we design a contextual encoding backbone network, termed as Dual Transformer (DTrans). We perform extensive experiments on a very popular benchmark, VG150, to demonstrate the effectiveness of our method for the unbiased scene graph generation. In specific, our RTPB achieves an improvement of over 10% under the mean recall when applied to current SGG methods. Furthermore, DTrans with RTPB outperforms nearly all state-of-the-art methods with a large margin.
Deep learning fluid flow reconstruction around arbitrary two-dimensional objects from sparse sensors using conformal mappings
Feb 08, 2022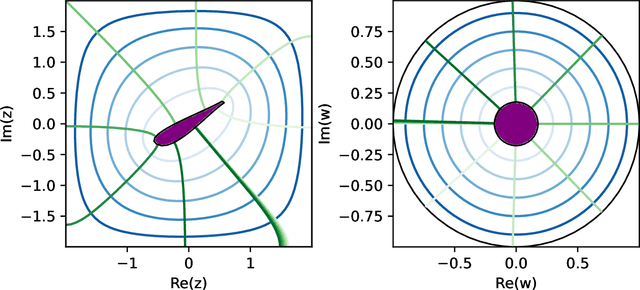
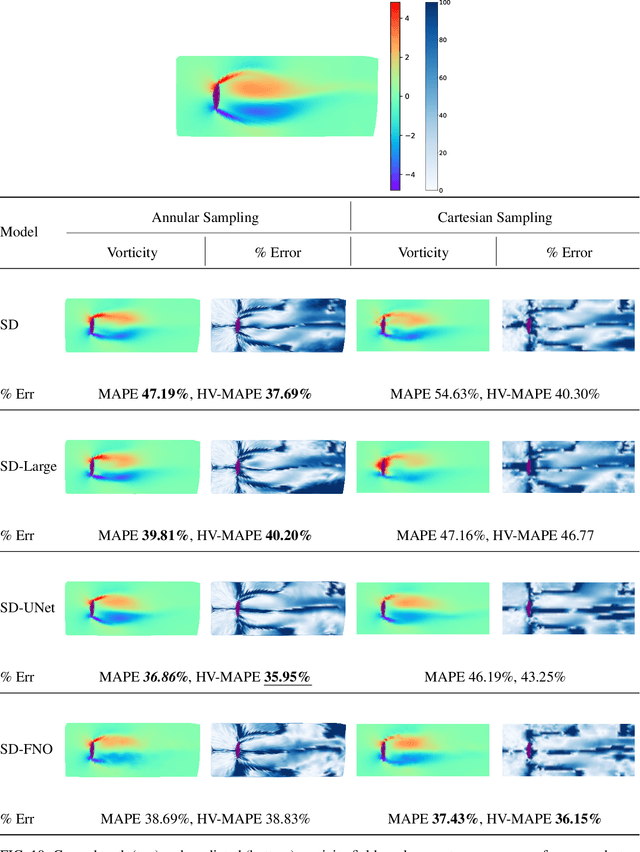
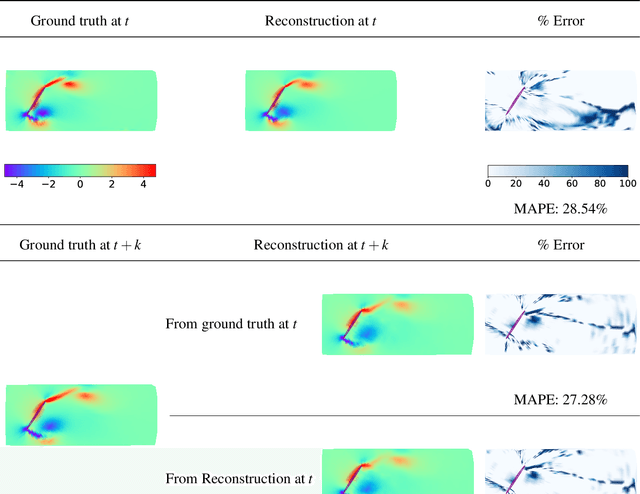
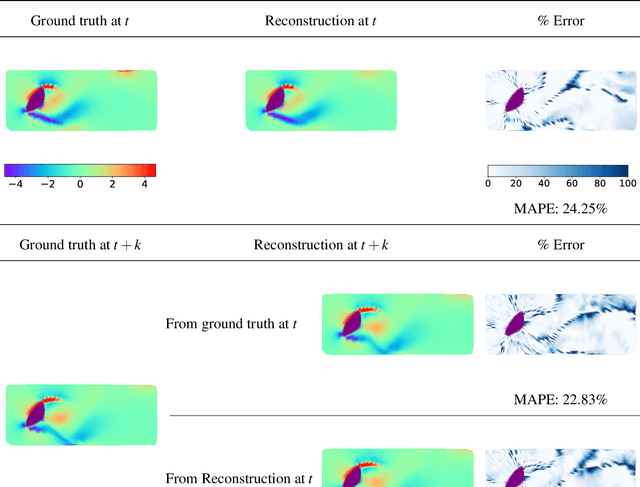
The usage of deep neural networks (DNNs) for flow reconstruction (FR) tasks from a limited number of sensors is attracting strong research interest, owing to DNNs' ability to replicate very high dimensional relationships. Trained over a single flow case for a given Reynolds number or over a reduced range of Reynolds numbers, these models are unfortunately not able to handle fluid flows around different objects without re-training. In this work, we propose a new framework called Spatial Multi-Geometry FR (SMGFR) task, capable of reconstructing fluid flows around different two-dimensional objects without re-training, mapping the computational domain as an annulus. Different DNNs for different sensor setups (where information about the flow is collected) are trained with high-fidelity simulation data for a Reynolds number equal to approximately $300$ for 64 objects randomly generated using Bezier curves. The performance of the models and sensor setups are then assessed for the flow around 16 unseen objects. It is shown that our mapping approach improves percentage errors by up to 15\% in SMGFR when compared to a more conventional approach where the models are trained on a Cartesian grid. Finally, the SMGFR task is extended to predictions of fluid flow snapshots in the future, introducing the Spatio-temporal MGFR (STMGFR) task. For this spatio-temporal reconstruction task, a novel approach is developed involving splitting DNNs into a spatial and a temporal component. Our results demonstrate that this approach is able to reproduce, in time and in space, the main features of a fluid flow around arbitrary objects.
Marius++: Large-Scale Training of Graph Neural Networks on a Single Machine
Feb 04, 2022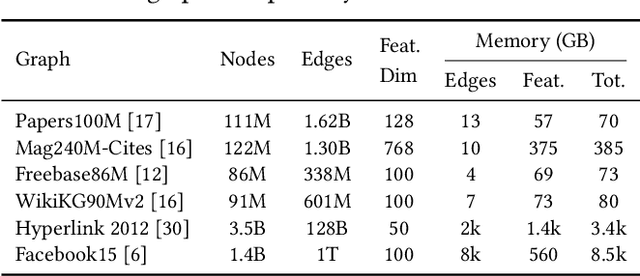
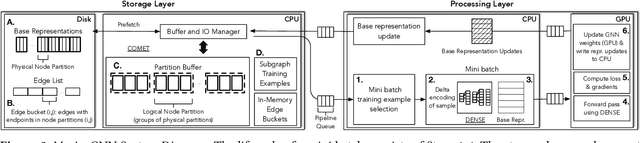
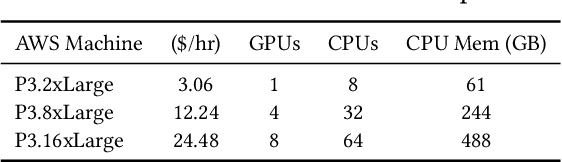
Graph Neural Networks (GNNs) have emerged as a powerful model for ML over graph-structured data. Yet, scalability remains a major challenge for using GNNs over billion-edge inputs. The creation of mini-batches used for training incurs computational and data movement costs that grow exponentially with the number of GNN layers as state-of-the-art models aggregate information from the multi-hop neighborhood of each input node. In this paper, we focus on scalable training of GNNs with emphasis on resource efficiency. We show that out-of-core pipelined mini-batch training in a single machine outperforms resource-hungry multi-GPU solutions. We introduce Marius++, a system for training GNNs over billion-scale graphs. Marius++ provides disk-optimized training for GNNs and introduces a series of data organization and algorithmic contributions that 1) minimize the memory-footprint and end-to-end time required for training and 2) ensure that models learned with disk-based training exhibit accuracy similar to those fully trained in mixed CPU/GPU settings. We evaluate Marius++ against PyTorch Geometric and Deep Graph Library using seven benchmark (model, data set) settings and find that Marius++ with one GPU can achieve the same level of model accuracy up to 8$\times$ faster than these systems when they are using up to eight GPUs. For these experiments, disk-based training allows Marius++ deployments to be up to 64$\times$ cheaper in monetary cost than those of the competing systems.
Information State Embedding in Partially Observable Cooperative Multi-Agent Reinforcement Learning
Apr 18, 2020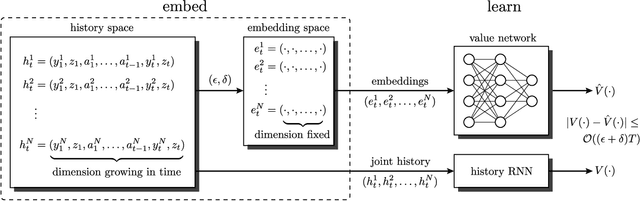
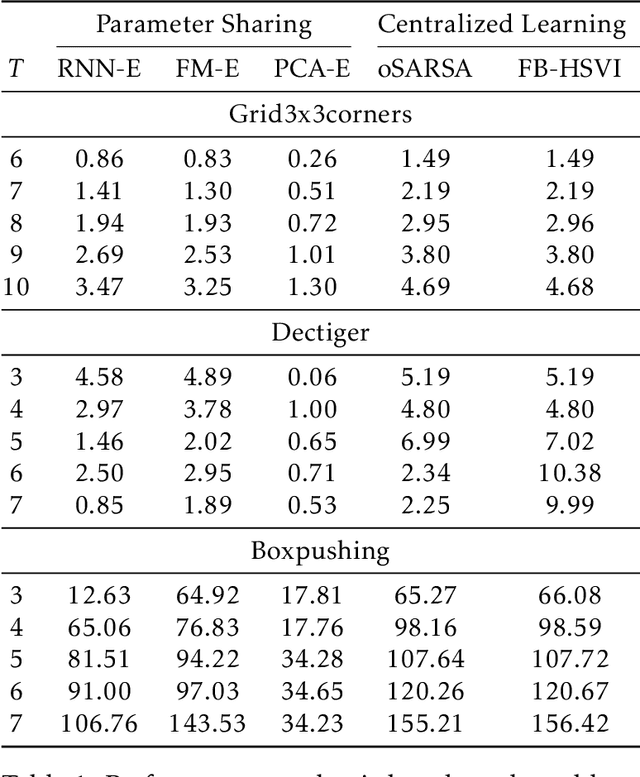
Multi-agent reinforcement learning (MARL) under partial observability has long been considered challenging, primarily due to the requirement for each agent to maintain a belief over all other agents' local histories -- a domain that generally grows exponentially over time. In this work, we investigate a partially observable MARL problem in which agents are cooperative. To enable the development of tractable algorithms, we introduce the concept of an information state embedding that serves to compress agents' histories. We quantify how the compression error influences the resulting value functions for decentralized control. Furthermore, we propose three natural embeddings, based on finite-memory truncation, principal component analysis, and recurrent neural networks. The output of these embeddings are then used as the information state, and can be fed into any MARL algorithm. The proposed embed-then-learn pipeline opens the black-box of existing MARL algorithms, allowing us to establish some theoretical guarantees (error bounds of value functions) while still achieving competitive performance with many end-to-end approaches.