 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adaptive Modeling Against Adversarial Attacks
Dec 23, 2021
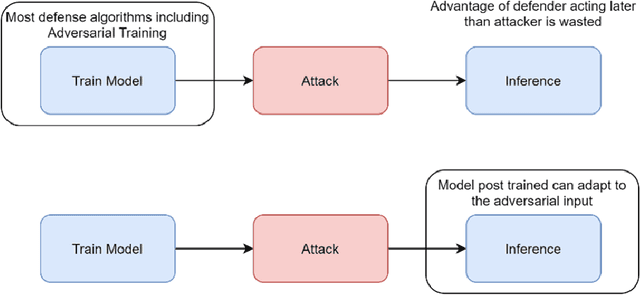

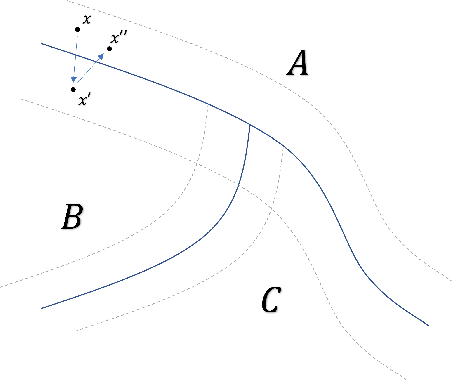
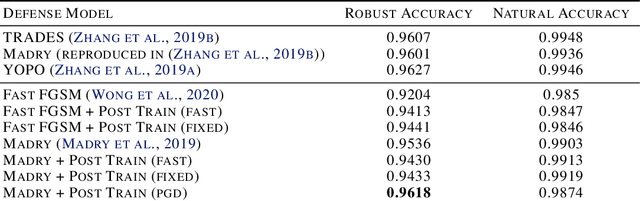
Adversarial training, the process of training a deep learning model with adversarial data, is one of the most successful adversarial defense methods for deep learning models. We have found that the robustness to white-box attack of an adversarially trained model can be further improved if we fine tune this model in inference stage to adapt to the adversarial input, with the extra information in it. We introduce an algorithm that "post trains" the model at inference stage between the original output class and a "neighbor" class, with existing training data. The accuracy of pre-trained Fast-FGSM CIFAR10 classifier base model against white-box projected gradient attack (PGD) can be significantly improved from 46.8% to 64.5% with our algorithm.
A Graph Symmetrisation Bound on Channel Information Leakage under Blowfish Privacy
Jul 12, 2020
Blowfish privacy is a recent generalisation of differential privacy that enables improved utility while maintaining privacy policies with semantic guarantees, a factor that has driven the popularity of differential privacy in computer science. This paper relates Blowfish privacy to an important measure of privacy loss of information channels from the communications theory community: min-entropy leakage. Symmetry in an input data neighbouring relation is central to known connections between differential privacy and min-entropy leakage. But while differential privacy exhibits strong symmetry, Blowfish neighbouring relations correspond to arbitrary simple graphs owing to the framework's flexible privacy policies. To bound the min-entropy leakage of Blowfish-private mechanisms we organise our analysis over symmetrical partitions corresponding to orbits of graph automorphism groups. A construction meeting our bound with asymptotic equality demonstrates sharpness.
CLIP4Caption ++: Multi-CLIP for Video Caption
Oct 14, 2021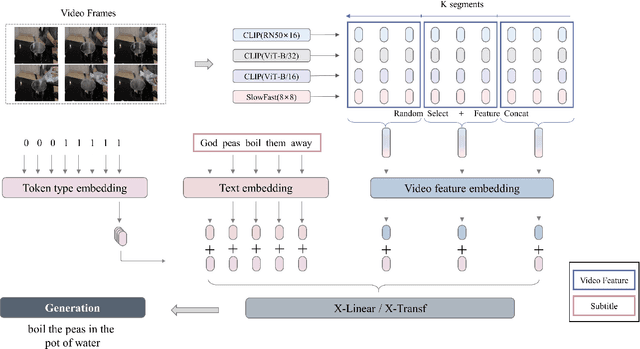
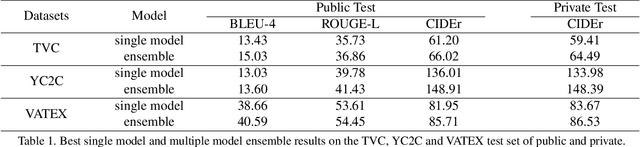

This report describes our solution to the VALUE Challenge 2021 in the captioning task. Our solution, named CLIP4Caption++, is built on X-Linear/X-Transformer, which is an advanced model with encoder-decoder architecture. We make the following improvements on the proposed CLIP4Caption++: We employ an advanced encoder-decoder model architecture X-Transformer as our main framework and make the following improvements: 1) we utilize three strong pre-trained CLIP models to extract the text-related appearance visual features. 2) we adopt the TSN sampling strategy for data enhancement. 3) we involve the video subtitle information to provide richer semantic information. 3) we introduce the subtitle information, which fuses with the visual features as guidance. 4) we design word-level and sentence-level ensemble strategies. Our proposed method achieves 86.5, 148.4, 64.5 CIDEr scores on VATEX, YC2C, and TVC datasets, respectively, which shows the superior performance of our proposed CLIP4Caption++ on all three datasets.
TrialGraph: Machine Intelligence Enabled Insight from Graph Modelling of Clinical Trials
Dec 15, 2021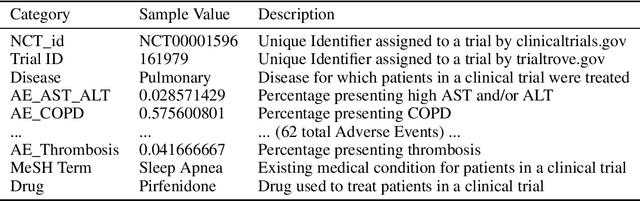
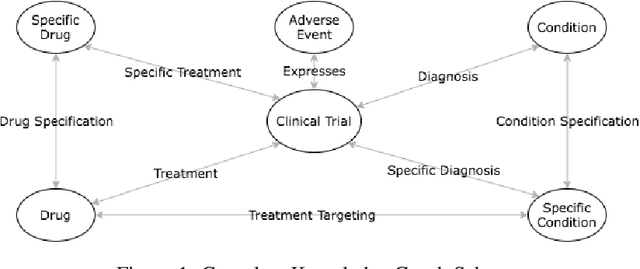
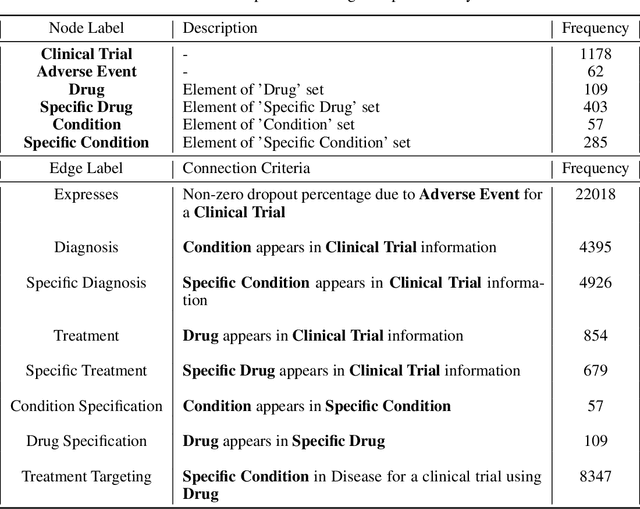

A major impediment to successful drug development is the complexity, cost, and scale of clinical trials. The detailed internal structure of clinical trial data can make conventional optimization difficult to achieve. Recent advances in machine learning, specifically graph-structured data analysis, have the potential to enable significant progress in improving the clinical trial design. TrialGraph seeks to apply these methodologies to produce a proof-of-concept framework for developing models which can aid drug development and benefit patients. In this work, we first introduce a curated clinical trial data set compiled from the CT.gov, AACT and TrialTrove databases (n=1191 trials; representing one million patients) and describe the conversion of this data to graph-structured formats. We then detail the mathematical basis and implementation of a selection of graph machine learning algorithms, which typically use standard machine classifiers on graph data embedded in a low-dimensional feature space. We trained these models to predict side effect information for a clinical trial given information on the disease, existing medical conditions, and treatment. The MetaPath2Vec algorithm performed exceptionally well, with standard Logistic Regression, Decision Tree, Random Forest, Support Vector, and Neural Network classifiers exhibiting typical ROC-AUC scores of 0.85, 0.68, 0.86, 0.80, and 0.77, respectively. Remarkably, the best performing classifiers could only produce typical ROC-AUC scores of 0.70 when trained on equivalent array-structured data. Our work demonstrates that graph modelling can significantly improve prediction accuracy on appropriate datasets. Successive versions of the project that refine modelling assumptions and incorporate more data types can produce excellent predictors with real-world applications in drug development.
Cross-Modality Multi-Atlas Segmentation Using Deep Neural Networks
Feb 04, 2022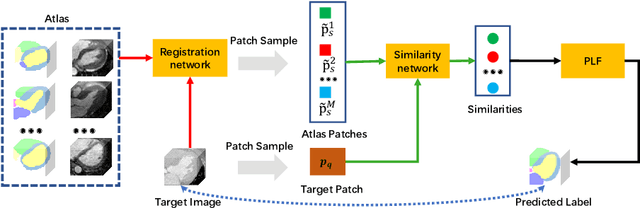
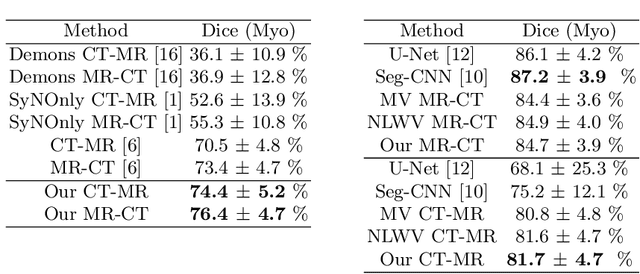
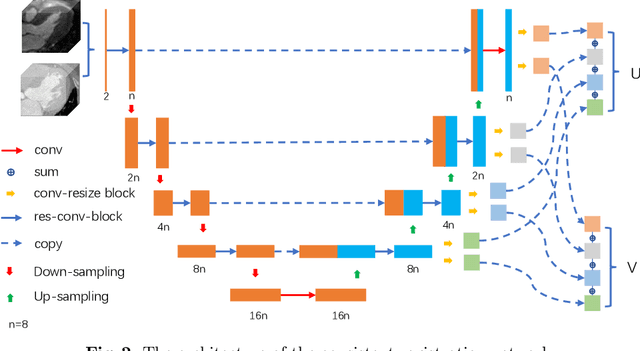
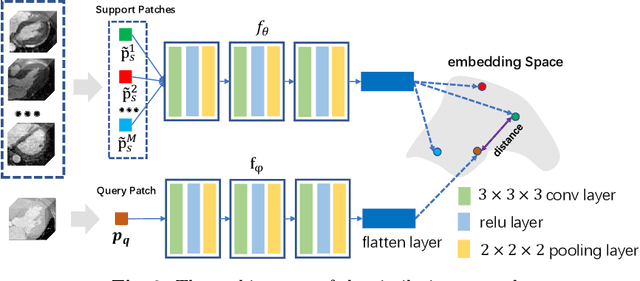
Multi-atlas segmentation (MAS) is a promising framework for medical image segmentation. Generally, MAS methods register multiple atlases, i.e., medical images with corresponding labels, to a target image; and the transformed atlas labels can be combined to generate target segmentation via label fusion schemes. Many conventional MAS methods employed the atlases from the same modality as the target image. However, the number of atlases with the same modality may be limited or even missing in many clinical applications. Besides, conventional MAS methods suffer from the computational burden of registration or label fusion procedures. In this work, we design a novel cross-modality MAS framework, which uses available atlases from a certain modality to segment a target image from another modality. To boost the computational efficiency of the framework, both the image registration and label fusion are achieved by well-designed deep neural networks. For the atlas-to-target image registration, we propose a bi-directional registration network (BiRegNet), which can efficiently align images from different modalities. For the label fusion, we design a similarity estimation network (SimNet), which estimates the fusion weight of each atlas by measuring its similarity to the target image. SimNet can learn multi-scale information for similarity estimation to improve the performance of label fusion. The proposed framework was evaluated by the left ventricle and liver segmentation tasks on the MM-WHS and CHAOS datasets, respectively. Results have shown that the framework is effective for cross-modality MAS in both registration and label fusion. The code will be released publicly on \url{https://github.com/NanYoMy/cmmas} once the manuscript is accepted.
Query Efficient Decision Based Sparse Attacks Against Black-Box Deep Learning Models
Jan 31, 2022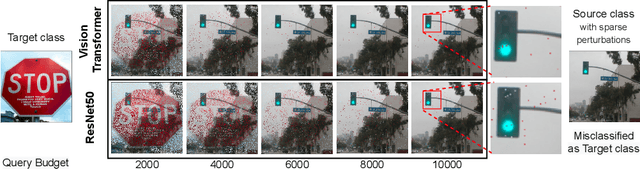

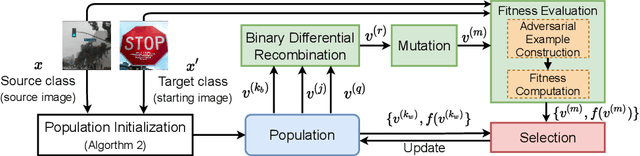
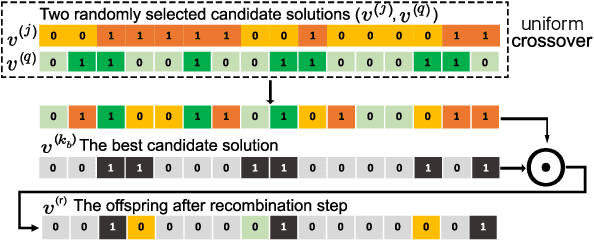
Despite our best efforts, deep learning models remain highly vulnerable to even tiny adversarial perturbations applied to the inputs. The ability to extract information from solely the output of a machine learning model to craft adversarial perturbations to black-box models is a practical threat against real-world systems, such as autonomous cars or machine learning models exposed as a service (MLaaS). Of particular interest are sparse attacks. The realization of sparse attacks in black-box models demonstrates that machine learning models are more vulnerable than we believe. Because these attacks aim to minimize the number of perturbed pixels measured by l_0 norm-required to mislead a model by solely observing the decision (the predicted label) returned to a model query; the so-called decision-based attack setting. But, such an attack leads to an NP-hard optimization problem. We develop an evolution-based algorithm-SparseEvo-for the problem and evaluate against both convolutional deep neural networks and vision transformers. Notably, vision transformers are yet to be investigated under a decision-based attack setting. SparseEvo requires significantly fewer model queries than the state-of-the-art sparse attack Pointwise for both untargeted and targeted attacks. The attack algorithm, although conceptually simple, is also competitive with only a limited query budget against the state-of-the-art gradient-based whitebox attacks in standard computer vision tasks such as ImageNet. Importantly, the query efficient SparseEvo, along with decision-based attacks, in general, raise new questions regarding the safety of deployed systems and poses new directions to study and understand the robustness of machine learning models.
Learning When and What to Ask: a Hierarchical Reinforcement Learning Framework
Oct 14, 2021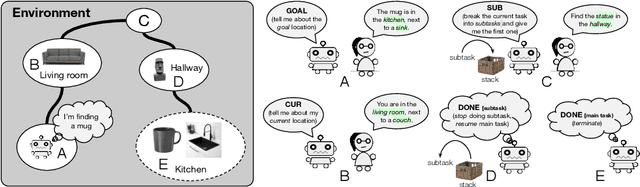
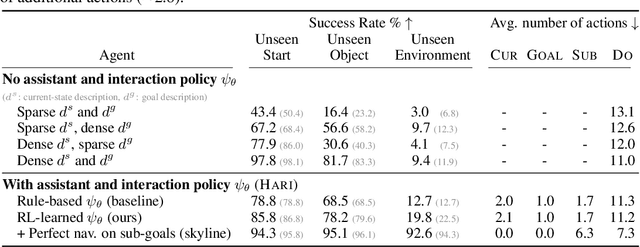
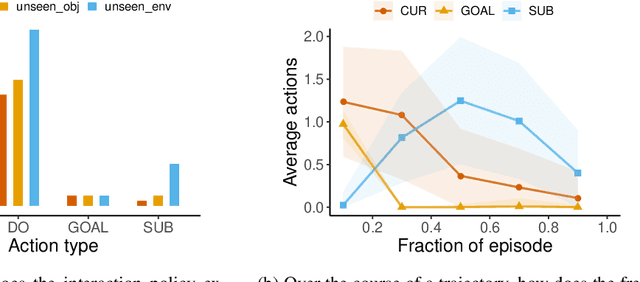

Reliable AI agents should be mindful of the limits of their knowledge and consult humans when sensing that they do not have sufficient knowledge to make sound decisions. We formulate a hierarchical reinforcement learning framework for learning to decide when to request additional information from humans and what type of information would be helpful to request. Our framework extends partially-observed Markov decision processes (POMDPs) by allowing an agent to interact with an assistant to leverage their knowledge in accomplishing tasks. Results on a simulated human-assisted navigation problem demonstrate the effectiveness of our framework: aided with an interaction policy learned by our method, a navigation policy achieves up to a 7x improvement in task success rate compared to performing tasks only by itself. The interaction policy is also efficient: on average, only a quarter of all actions taken during a task execution are requests for information. We analyze benefits and challenges of learning with a hierarchical policy structure and suggest directions for future work.
End-to-End Trainable One-Stage Parking Slot Detection Integrating Global and Local Information
Mar 05, 2020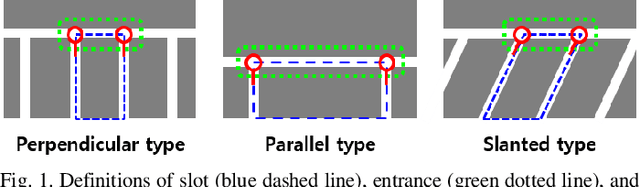
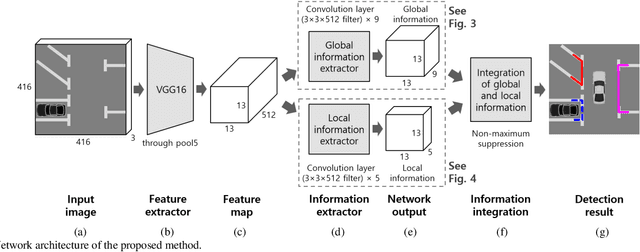

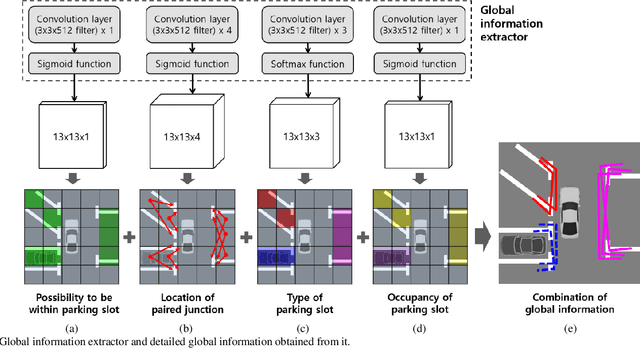
This paper proposes an end-to-end trainable one-stage parking slot detection method for around view monitor (AVM) images. The proposed method simultaneously acquires global information (entrance, type, and occupancy of parking slot) and local information (location and orientation of junction) by using a convolutional neural network (CNN), and integrates them to detect parking slots with their properties. This method divides an AVM image into a grid and performs a CNN-based feature extraction. For each cell of the grid, the global and local information of the parking slot is obtained by applying convolution filters to the extracted feature map. Final detection results are produced by integrating the global and local information of the parking slot through non-maximum suppression (NMS). Since the proposed method obtains most of the information of the parking slot using a fully convolutional network without a region proposal stage, it is an end-to-end trainable one-stage detector. In experiments, this method was quantitatively evaluated using the public dataset and outperforms previous methods by showing both recall and precision of 99.77%, type classification accuracy of 100%, and occupancy classification accuracy of 99.31% while processing 60 frames per second.
Amicable examples for informed source separation
Oct 11, 2021
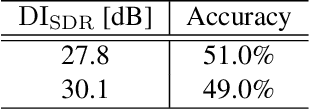
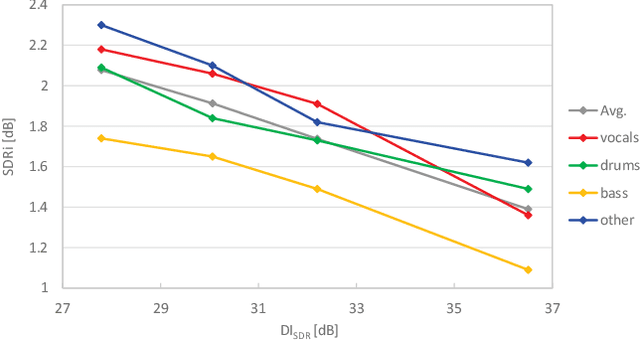
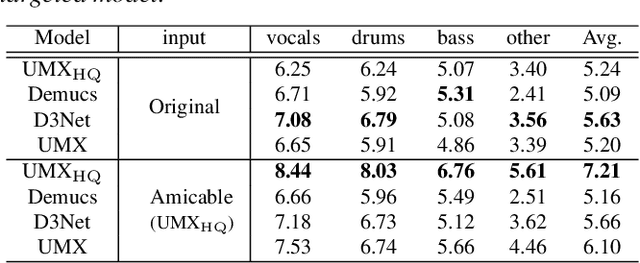
This paper deals with the problem of informed source separation (ISS), where the sources are accessible during the so-called \textit{encoding} stage. Previous works computed side-information during the encoding stage and source separation models were designed to utilize the side-information to improve the separation performance. In contrast, in this work, we improve the performance of a pretrained separation model that does not use any side-information. To this end, we propose to adopt an adversarial attack for the opposite purpose, i.e., rather than computing the perturbation to degrade the separation, we compute an imperceptible perturbation called amicable noise to improve the separation. Experimental results show that the proposed approach selectively improves the performance of the targeted separation model by 2.23 dB on average and is robust to signal compression. Moreover, we propose multi-model multi-purpose learning that control the effect of the perturbation on different models individually.
Hybrid Reinforcement Learning-Based Eco-Driving Strategy for Connected and Automated Vehicles at Signalized Intersections
Jan 28, 2022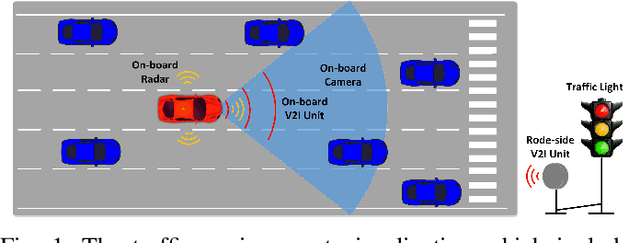
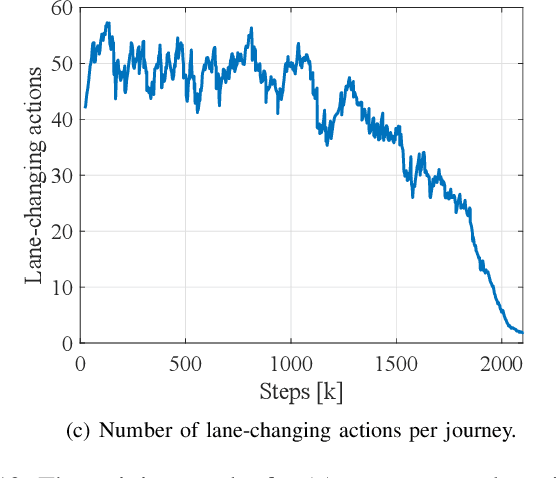
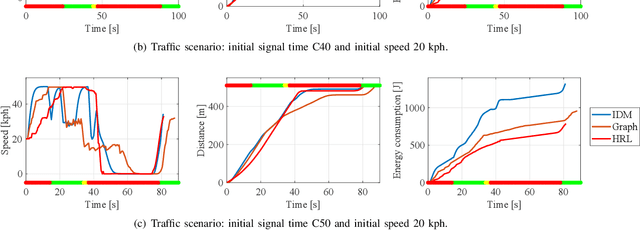
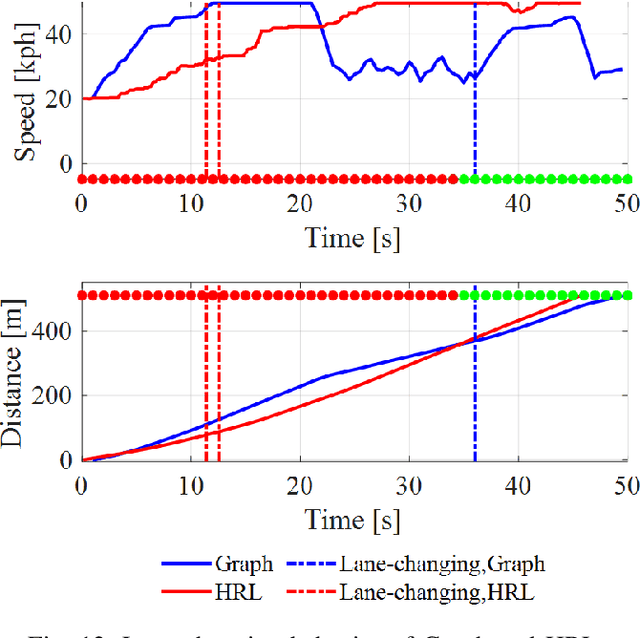
Taking advantage of both vehicle-to-everything (V2X) communication and automated driving technology, connected and automated vehicles are quickly becoming one of the transformative solutions to many transportation problems. However, in a mixed traffic environment at signalized intersections, it is still a challenging task to improve overall throughput and energy efficiency considering the complexity and uncertainty in the traffic system. In this study, we proposed a hybrid reinforcement learning (HRL) framework which combines the rule-based strategy and the deep reinforcement learning (deep RL) to support connected eco-driving at signalized intersections in mixed traffic. Vision-perceptive methods are integrated with vehicle-to-infrastructure (V2I) communications to achieve higher mobility and energy efficiency in mixed connected traffic. The HRL framework has three components: a rule-based driving manager that operates the collaboration between the rule-based policies and the RL policy; a multi-stream neural network that extracts the hidden features of vision and V2I information; and a deep RL-based policy network that generate both longitudinal and lateral eco-driving actions. In order to evaluate our approach, we developed a Unity-based simulator and designed a mixed-traffic intersection scenario. Moreover, several baselines were implemented to compare with our new design, and numerical experiments were conducted to test the performance of the HRL model. The experiments show that our HRL method can reduce energy consumption by 12.70% and save 11.75% travel time when compared with a state-of-the-art model-based Eco-Driving approach.