 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AirPose: Multi-View Fusion Network for Aerial 3D Human Pose and Shape Estimation
Jan 20, 2022

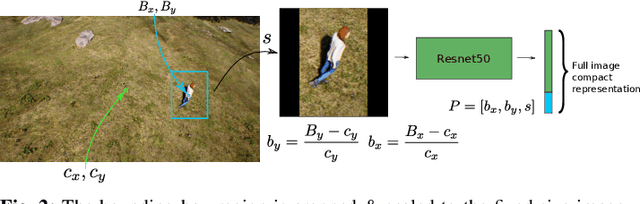
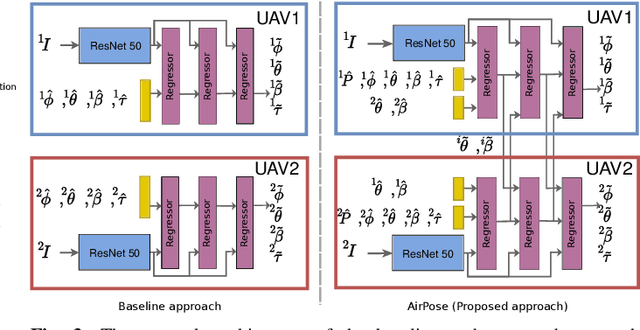

In this letter, we present a novel markerless 3D human motion capture (MoCap) system for unstructured, outdoor environments that uses a team of autonomous unmanned aerial vehicles (UAVs) with on-board RGB cameras and computation. Existing methods are limited by calibrated cameras and off-line processing. Thus, we present the first method (AirPose) to estimate human pose and shape using images captured by multiple extrinsically uncalibrated flying cameras. AirPose itself calibrates the cameras relative to the person instead of relying on any pre-calibration. It uses distributed neural networks running on each UAV that communicate viewpoint-independent information with each other about the person (i.e., their 3D shape and articulated pose). The person's shape and pose are parameterized using the SMPL-X body model, resulting in a compact representation, that minimizes communication between the UAVs. The network is trained using synthetic images of realistic virtual environments, and fine-tuned on a small set of real images. We also introduce an optimization-based post-processing method (AirPose$^{+}$) for offline applications that require higher MoCap quality. We make our method's code and data available for research at https://github.com/robot-perception-group/AirPose. A video describing the approach and results is available at https://youtu.be/xLYe1TNHsfs.
Head2Toe: Utilizing Intermediate Representations for Better Transfer Learning
Jan 10, 2022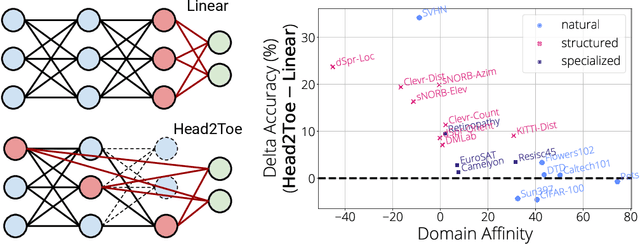
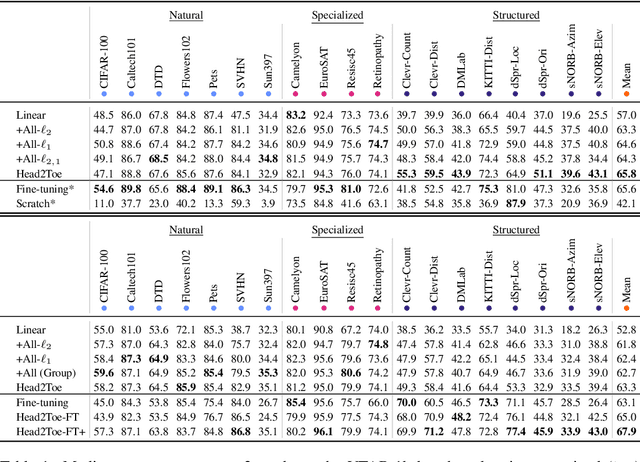
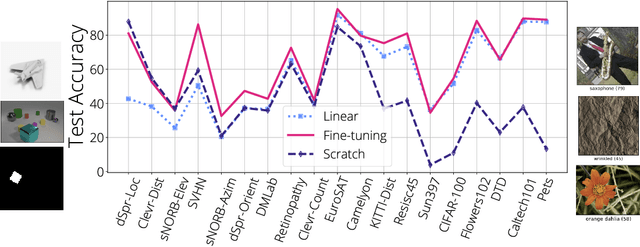
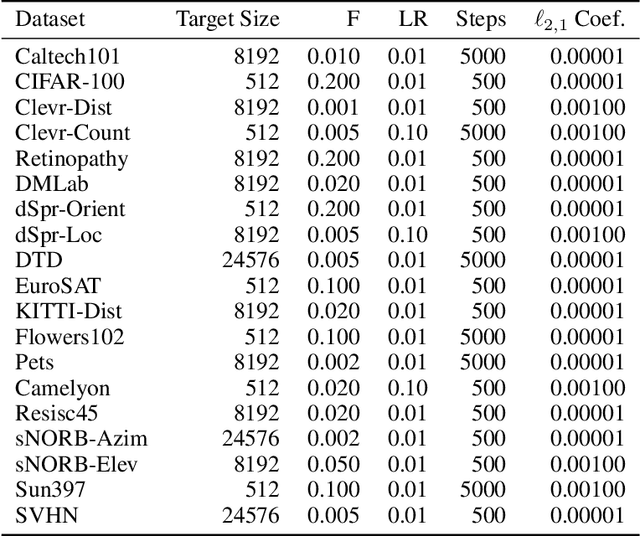
Transfer-learning methods aim to improve performance in a data-scarce target domain using a model pretrained on a data-rich source domain. A cost-efficient strategy, linear probing, involves freezing the source model and training a new classification head for the target domain. This strategy is outperformed by a more costly but state-of-the-art method -- fine-tuning all parameters of the source model to the target domain -- possibly because fine-tuning allows the model to leverage useful information from intermediate layers which is otherwise discarded by the later pretrained layers. We explore the hypothesis that these intermediate layers might be directly exploited. We propose a method, Head-to-Toe probing (Head2Toe), that selects features from all layers of the source model to train a classification head for the target-domain. In evaluations on the VTAB-1k, Head2Toe matches performance obtained with fine-tuning on average while reducing training and storage cost hundred folds or more, but critically, for out-of-distribution transfer, Head2Toe outperforms fine-tuning.
Trimap-guided Feature Mining and Fusion Network for Natural Image Matting
Dec 03, 2021
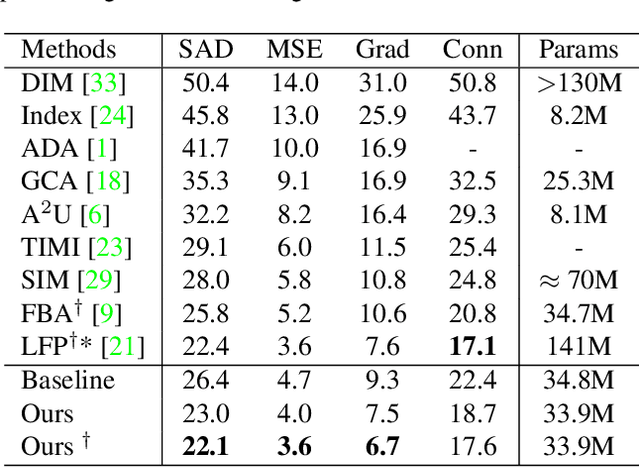
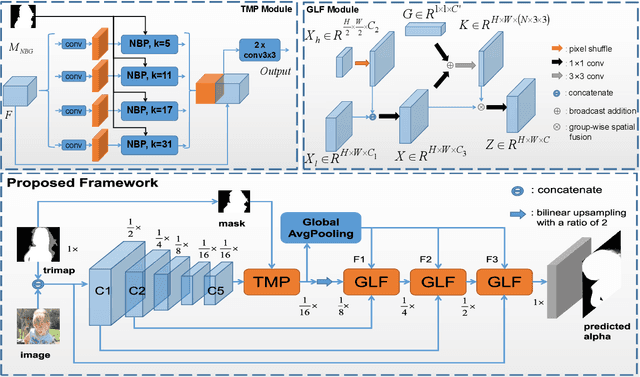
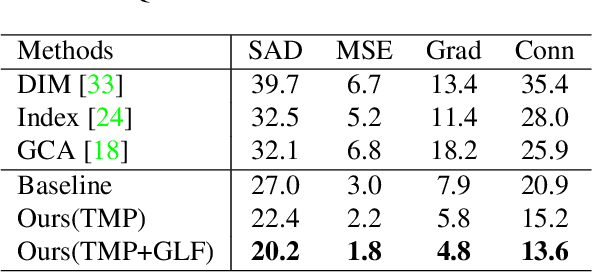
Utilizing trimap guidance and fusing multi-level features are two important issues for trimap-based matting with pixel-level prediction. To utilize trimap guidance, most existing approaches simply concatenate trimaps and images together to feed a deep network or apply an extra network to extract more trimap guidance, which meets the conflict between efficiency and effectiveness. For emerging content-based feature fusion, most existing matting methods only focus on local features which lack the guidance of a global feature with strong semantic information related to the interesting object. In this paper, we propose a trimap-guided feature mining and fusion network consisting of our trimap-guided non-background multi-scale pooling (TMP) module and global-local context-aware fusion (GLF) modules. Considering that trimap provides strong semantic guidance, our TMP module focuses effective feature mining on interesting objects under the guidance of trimap without extra parameters. Furthermore, our GLF modules use global semantic information of interesting objects mined by our TMP module to guide an effective global-local context-aware multi-level feature fusion. In addition, we build a common interesting object matting (CIOM) dataset to advance high-quality image matting. Experimental results on the Composition-1k test set, Alphamatting benchmark, and our CIOM test set demonstrate that our method outperforms state-of-the-art approaches. Code and models will be publicly available soon.
English-to-Chinese Transliteration with Phonetic Back-transliteration
Dec 20, 2021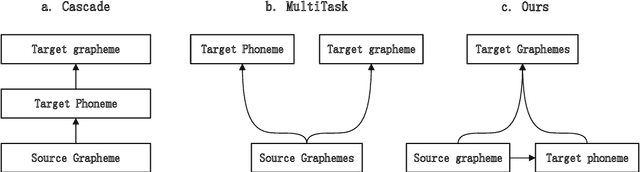
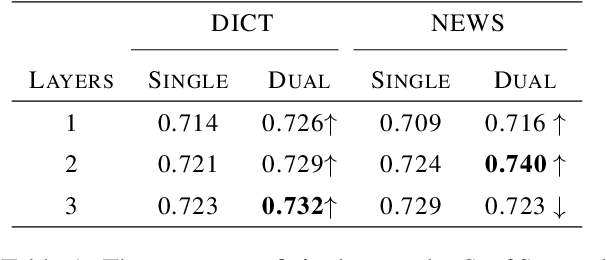
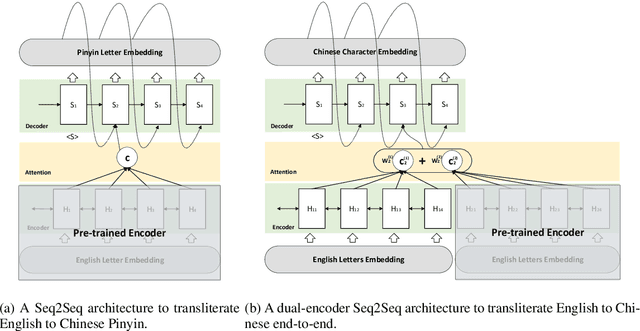
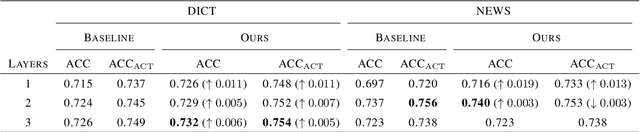
Transliteration is a task of translating named entities from a language to another, based on phonetic similarity. The task has embraced deep learning approaches in recent years, yet, most ignore the phonetic features of the involved languages. In this work, we incorporate phonetic information into neural networks in two ways: we synthesize extra data using forward and back-translation but in a phonetic manner; and we pre-train models on a phonetic task before learning transliteration. Our experiments include three language pairs and six directions, namely English to and from Chinese, Hebrew and Thai. Results indicate that our proposed approach brings benefits to the model and achieves better or similar performance when compared to state of the art.
Accurate Hydrologic Modeling Using Less Information
Nov 21, 2019
Joint models are a common and important tool in the intersection of machine learning and the physical sciences, particularly in contexts where real-world measurements are scarce. Recent developments in rainfall-runoff modeling, one of the prime challenges in hydrology, show the value of a joint model with shared representation in this important context. However, current state-of-the-art models depend on detailed and reliable attributes characterizing each site to help the model differentiate correctly between the behavior of different sites. This dependency can present a challenge in data-poor regions. In this paper, we show that we can replace the need for such location-specific attributes with a completely data-driven learned embedding, and match previous state-of-the-art results with less information.
A Survey of Plagiarism Detection Systems: Case of Use with English, French and Arabic Languages
Jan 10, 2022
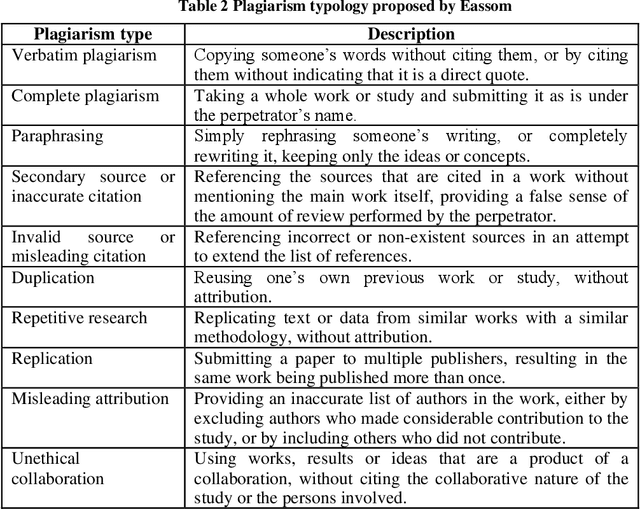
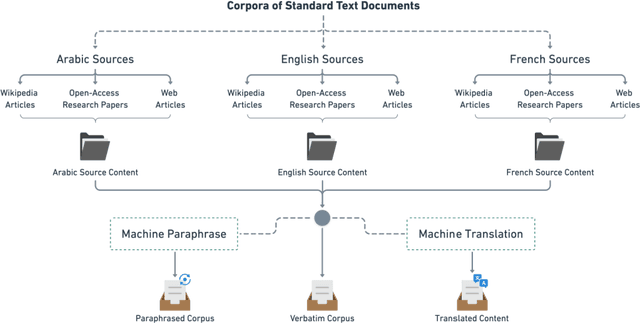

In academia, plagiarism is certainly not an emerging concern, but it became of a greater magnitude with the popularisation of the Internet and the ease of access to a worldwide source of content, rendering human-only intervention insufficient. Despite that, plagiarism is far from being an unaddressed problem, as computer-assisted plagiarism detection is currently an active area of research that falls within the field of Information Retrieval (IR) and Natural Language Processing (NLP). Many software solutions emerged to help fulfil this task, and this paper presents an overview of plagiarism detection systems for use in Arabic, French, and English academic and educational settings. The comparison was held between eight systems and was performed with respect to their features, usability, technical aspects, as well as their performance in detecting three levels of obfuscation from different sources: verbatim, paraphrase, and cross-language plagiarism. An indepth examination of technical forms of plagiarism was also performed in the context of this study. In addition, a survey of plagiarism typologies and classifications proposed by different authors is provided.
Is Dynamic Rumor Detection on social media Viable? An Unsupervised Perspective
Nov 23, 2021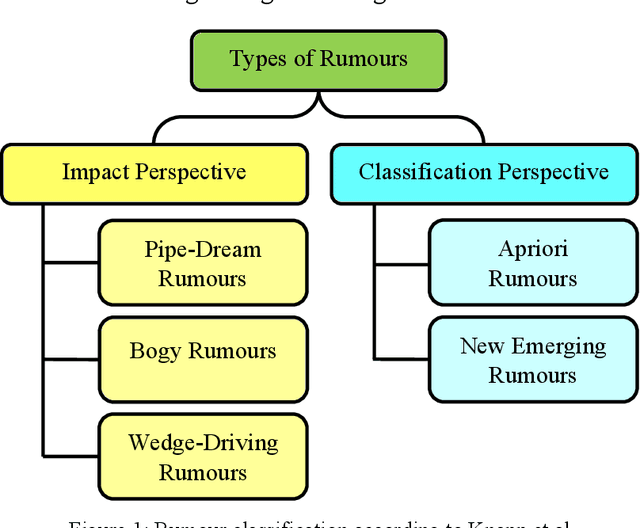
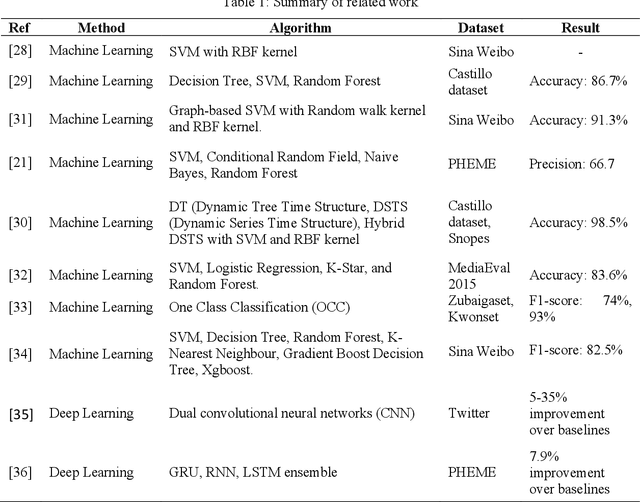
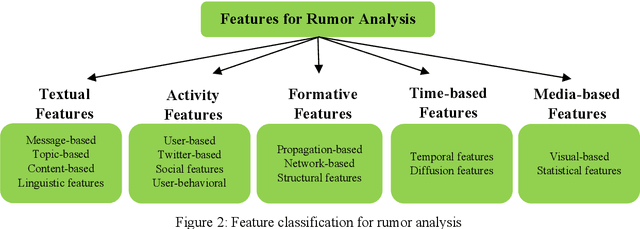
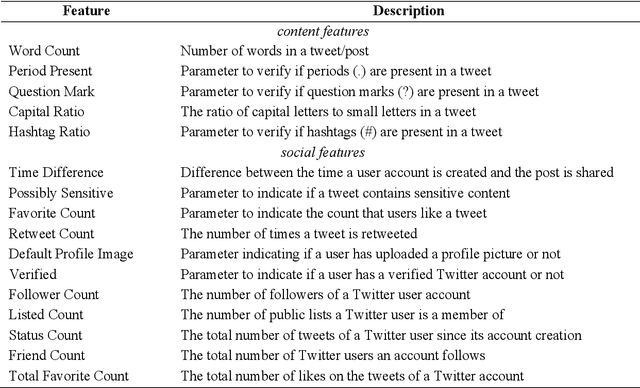
With the growing popularity and ease of access to the internet, the problem of online rumors is escalating. People are relying on social media to gain information readily but fall prey to false information. There is a lack of credibility assessment techniques for online posts to identify rumors as soon as they arrive. Existing studies have formulated several mechanisms to combat online rumors by developing machine learning and deep learning algorithms. The literature so far provides supervised frameworks for rumor classification that rely on huge training datasets. However, in the online scenario where supervised learning is exigent, dynamic rumor identification becomes difficult. Early detection of online rumors is a challenging task, and studies relating to them are relatively few. It is the need of the hour to identify rumors as soon as they appear online. This work proposes a novel framework for unsupervised rumor detection that relies on an online post's content and social features using state-of-the-art clustering techniques. The proposed architecture outperforms several existing baselines and performs better than several supervised techniques. The proposed method, being lightweight, simple, and robust, offers the suitability of being adopted as a tool for online rumor identification.
An Artificial Intelligence Dataset for Solar Energy Locations in India
Jan 31, 2022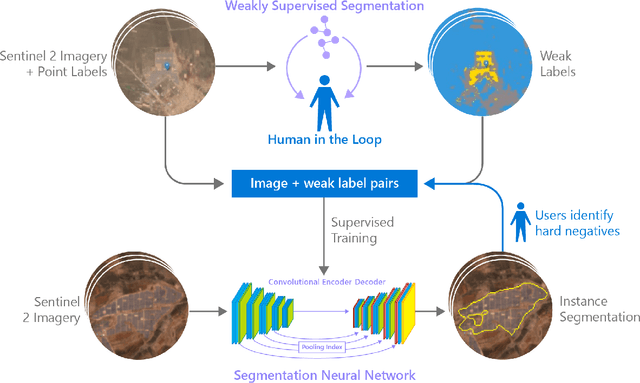
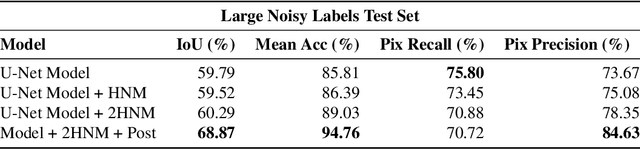


Rapid development of renewable energy sources, particularly solar photovoltaics, is critical to mitigate climate change. As a result, India has set ambitious goals to install 300 gigawatts of solar energy capacity by 2030. Given the large footprint projected to meet these renewable energy targets the potential for land use conflicts over environmental and social values is high. To expedite development of solar energy, land use planners will need access to up-to-date and accurate geo-spatial information of PV infrastructure. The majority of recent studies use either predictions of resource suitability or databases that are either developed thru crowdsourcing that often have significant sampling biases or have time lags between when projects are permitted and when location data becomes available. Here, we address this shortcoming by developing a spatially explicit machine learning model to map utility-scale solar projects across India. Using these outputs, we provide a cumulative measure of the solar footprint across India and quantified the degree of land modification associated with land cover types that may cause conflicts. Our analysis indicates that over 74\% of solar development In India was built on landcover types that have natural ecosystem preservation, and agricultural values. Thus, with a mean accuracy of 92\% this method permits the identification of the factors driving land suitability for solar projects and will be of widespread interest for studies seeking to assess trade-offs associated with the global decarbonization of green-energy systems. In the same way, our model increases the feasibility of remote sensing and long-term monitoring of renewable energy deployment targets.
Variational Learning for Unsupervised Knowledge Grounded Dialogs
Nov 23, 2021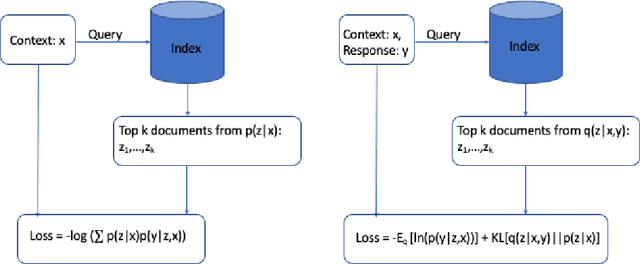
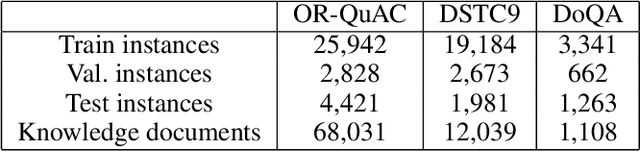
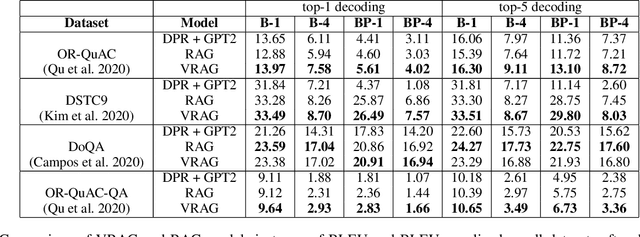
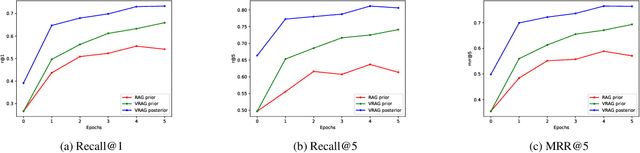
Recent methods for knowledge grounded dialogs generate responses by incorporating information from an external textual document. These methods do not require the exact document to be known during training and rely on the use of a retrieval system to fetch relevant documents from a large index. The documents used to generate the responses are modeled as latent variables whose prior probabilities need to be estimated. Models such as RAG , marginalize the document probabilities over the documents retrieved from the index to define the log likelihood loss function which is optimized end-to-end. In this paper, we develop a variational approach to the above technique wherein, we instead maximize the Evidence Lower bound (ELBO). Using a collection of three publicly available open-conversation datasets, we demonstrate how the posterior distribution, that has information from the ground-truth response, allows for a better approximation of the objective function during training. To overcome the challenges associated with sampling over a large knowledge collection, we develop an efficient approach to approximate the ELBO. To the best of our knowledge we are the first to apply variational training for open-scale unsupervised knowledge grounded dialog systems.
Single-Modal Entropy based Active Learning for Visual Question Answering
Nov 18, 2021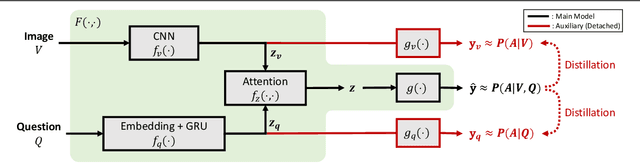
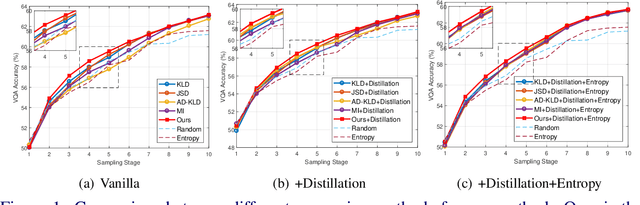
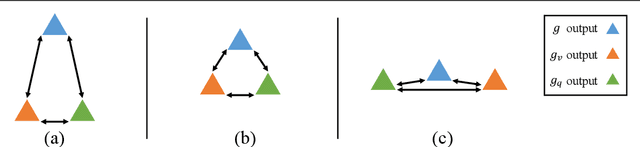
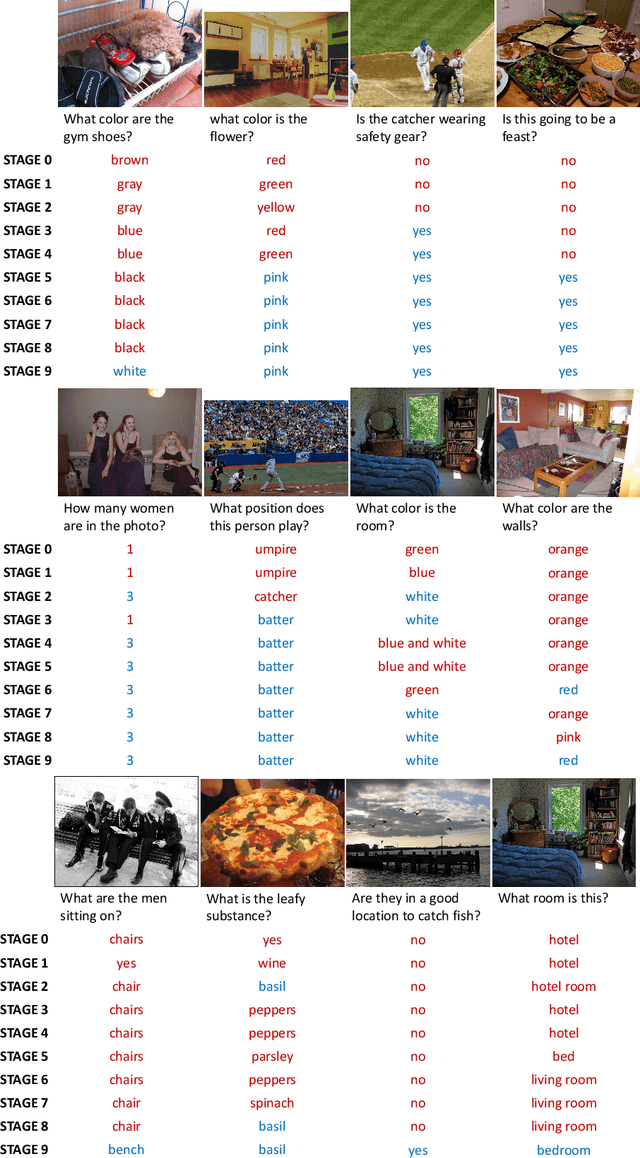
Constructing a large-scale labeled dataset in the real world, especially for high-level tasks (eg, Visual Question Answering), can be expensive and time-consuming. In addition, with the ever-growing amounts of data and architecture complexity, Active Learning has become an important aspect of computer vision research. In this work, we address Active Learning in the multi-modal setting of Visual Question Answering (VQA). In light of the multi-modal inputs, image and question, we propose a novel method for effective sample acquisition through the use of ad hoc single-modal branches for each input to leverage its information. Our mutual information based sample acquisition strategy Single-Modal Entropic Measure (SMEM) in addition to our self-distillation technique enables the sample acquisitor to exploit all present modalities and find the most informative samples. Our novel idea is simple to implement, cost-efficient, and readily adaptable to other multi-modal tasks. We confirm our findings on various VQA datasets through state-of-the-art performance by comparing to existing Active Learning baselines.