 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MIRA: Leveraging Multi-Intention Co-click Information in Web-scale Document Retrieval using Deep Neural Networks
Jul 03, 2020
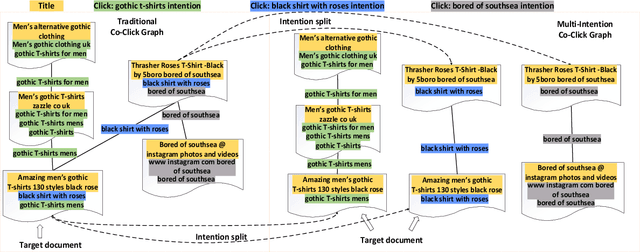
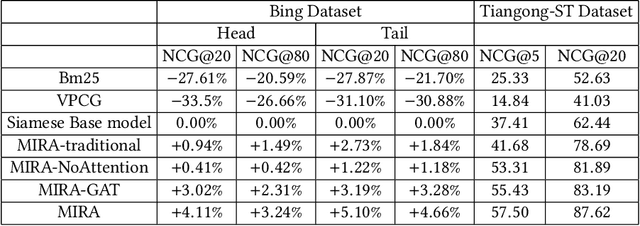
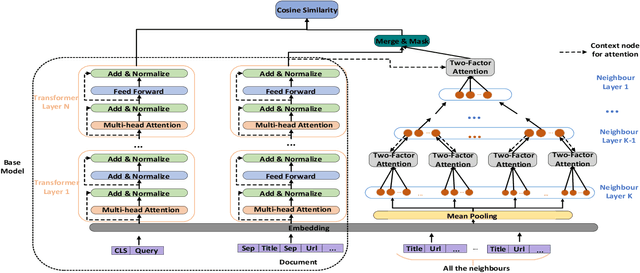
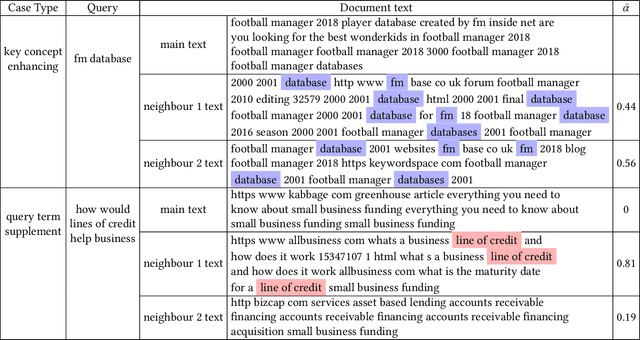
We study the problem of deep recall model in industrial web search, which is, given a user query, retrieve hundreds of most relevance documents from billions of candidates. The common framework is to train two encoding models based on neural embedding which learn the distributed representations of queries and documents separately and match them in the latent semantic space. However, all the exiting encoding models only leverage the information of the document itself, which is often not sufficient in practice when matching with query terms, especially for the hard tail queries. In this work we aim to leverage the additional information for each document from its co-click neighbour to help document retrieval. The challenges include how to effectively extract information and eliminate noise when involving co-click information in deep model while meet the demands of billion-scale data size for real time online inference. To handle the noise in co-click relations, we firstly propose a web-scale Multi-Intention Co-click document Graph(MICG) which builds the co-click connections between documents on click intention level but not on document level. Then we present an encoding framework MIRA based on Bert and graph attention networks which leverages a two-factor attention mechanism to aggregate neighbours. To meet the online latency requirements, we only involve neighbour information in document side, which can save the time-consuming query neighbor search in real time serving. We conduct extensive offline experiments on both public dataset and private web-scale dataset from two major commercial search engines demonstrating the effectiveness and scalability of the proposed method compared with several baselines. And a further case study reveals that co-click relations mainly help improve web search quality from two aspects: key concept enhancing and query term complementary.
RePaint: Inpainting using Denoising Diffusion Probabilistic Models
Jan 24, 2022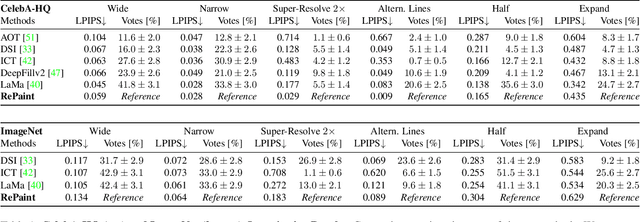
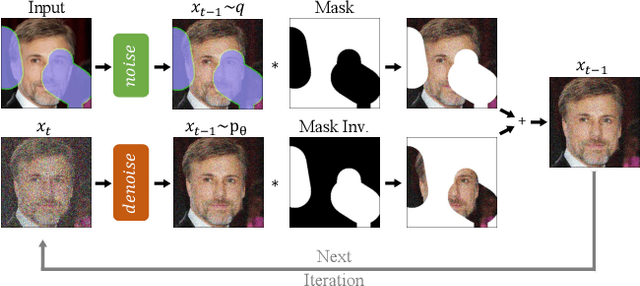


Free-form inpainting is the task of adding new content to an image in the regions specified by an arbitrary binary mask. Most existing approaches train for a certain distribution of masks, which limits their generalization capabilities to unseen mask types. Furthermore, training with pixel-wise and perceptual losses often leads to simple textural extensions towards the missing areas instead of semantically meaningful generation. In this work, we propose RePaint: A Denoising Diffusion Probabilistic Model (DDPM) based inpainting approach that is applicable to even extreme masks. We employ a pretrained unconditional DDPM as the generative prior. To condition the generation process, we only alter the reverse diffusion iterations by sampling the unmasked regions using the given image information. Since this technique does not modify or condition the original DDPM network itself, the model produces high-quality and diverse output images for any inpainting form. We validate our method for both faces and general-purpose image inpainting using standard and extreme masks. RePaint outperforms state-of-the-art Autoregressive, and GAN approaches for at least five out of six mask distributions. Github Repository: git.io/RePaint
Pythia: A Customizable Hardware Prefetching Framework Using Online Reinforcement Learning
Oct 19, 2021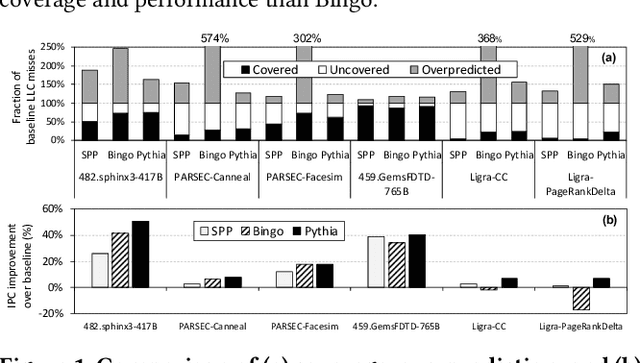
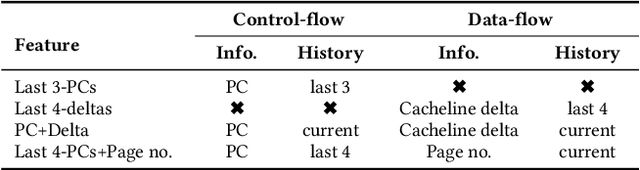
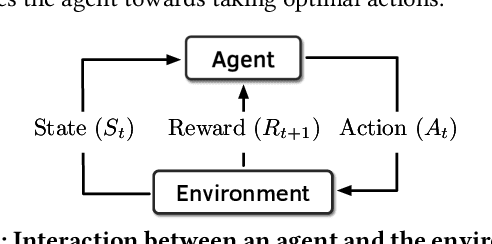

Past research has proposed numerous hardware prefetching techniques, most of which rely on exploiting one specific type of program context information (e.g., program counter, cacheline address) to predict future memory accesses. These techniques either completely neglect a prefetcher's undesirable effects (e.g., memory bandwidth usage) on the overall system, or incorporate system-level feedback as an afterthought to a system-unaware prefetch algorithm. We show that prior prefetchers often lose their performance benefit over a wide range of workloads and system configurations due to their inherent inability to take multiple different types of program context and system-level feedback information into account while prefetching. In this paper, we make a case for designing a holistic prefetch algorithm that learns to prefetch using multiple different types of program context and system-level feedback information inherent to its design. To this end, we propose Pythia, which formulates the prefetcher as a reinforcement learning agent. For every demand request, Pythia observes multiple different types of program context information to make a prefetch decision. For every prefetch decision, Pythia receives a numerical reward that evaluates prefetch quality under the current memory bandwidth usage. Pythia uses this reward to reinforce the correlation between program context information and prefetch decision to generate highly accurate, timely, and system-aware prefetch requests in the future. Our extensive evaluations using simulation and hardware synthesis show that Pythia outperforms multiple state-of-the-art prefetchers over a wide range of workloads and system configurations, while incurring only 1.03% area overhead over a desktop-class processor and no software changes in workloads. The source code of Pythia can be freely downloaded from https://github.com/CMU-SAFARI/Pythia.
Adverse Weather Image Translation with Asymmetric and Uncertainty-aware GAN
Dec 08, 2021
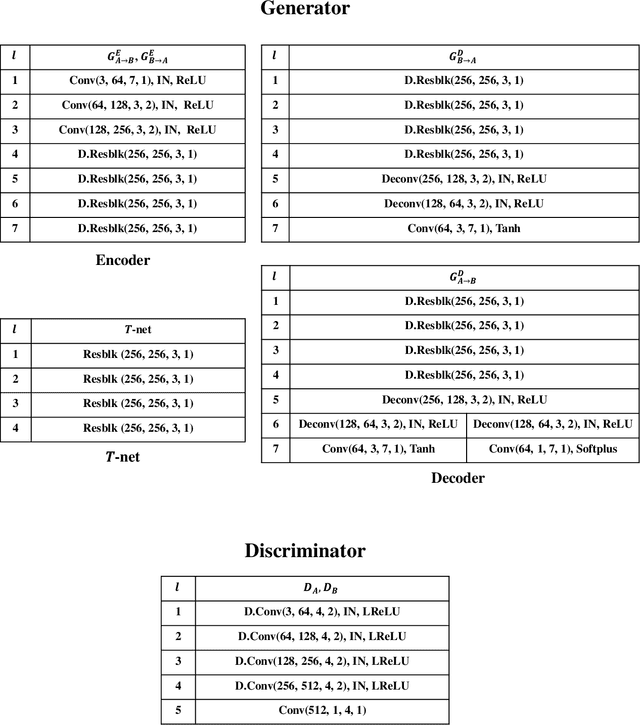


Adverse weather image translation belongs to the unsupervised image-to-image (I2I) translation task which aims to transfer adverse condition domain (eg, rainy night) to standard domain (eg, day). It is a challenging task because images from adverse domains have some artifacts and insufficient information. Recently, many studies employing Generative Adversarial Networks (GANs) have achieved notable success in I2I translation but there are still limitations in applying them to adverse weather enhancement. Symmetric architecture based on bidirectional cycle-consistency loss is adopted as a standard framework for unsupervised domain transfer methods. However, it can lead to inferior translation result if the two domains have imbalanced information. To address this issue, we propose a novel GAN model, i.e., AU-GAN, which has an asymmetric architecture for adverse domain translation. We insert a proposed feature transfer network (${T}$-net) in only a normal domain generator (i.e., rainy night-> day) to enhance encoded features of the adverse domain image. In addition, we introduce asymmetric feature matching for disentanglement of encoded features. Finally, we propose uncertainty-aware cycle-consistency loss to address the regional uncertainty of a cyclic reconstructed image. We demonstrate the effectiveness of our method by qualitative and quantitative comparisons with state-of-the-art models. Codes are available at https://github.com/jgkwak95/AU-GAN.
Towards Fast and Accurate Federated Learning with non-IID Data for Cloud-Based IoT Applications
Jan 29, 2022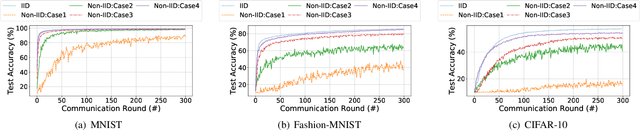
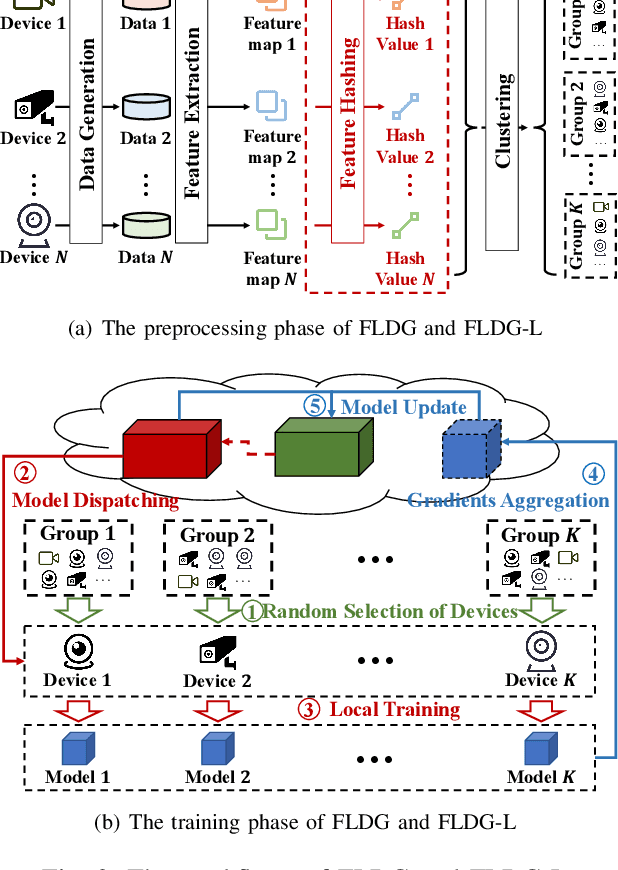
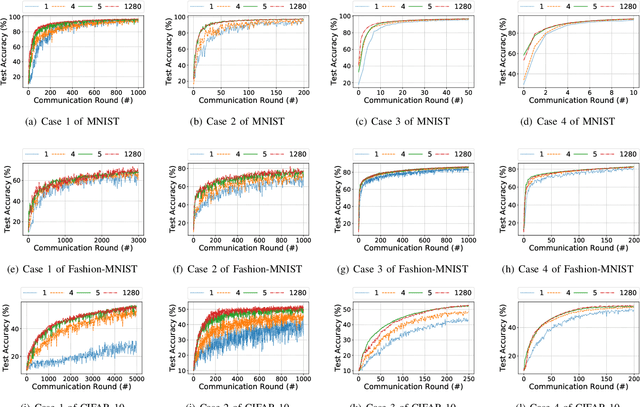
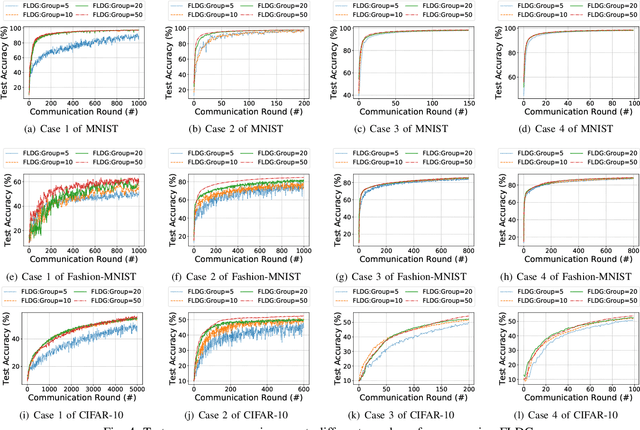
As a promising method of central model training on decentralized device data while securing user privacy, Federated Learning (FL)is becoming popular in Internet of Things (IoT) design. However, when the data collected by IoT devices are highly skewed in a non-independent and identically distributed (non-IID) manner, the accuracy of vanilla FL method cannot be guaranteed. Although there exist various solutions that try to address the bottleneck of FL with non-IID data, most of them suffer from extra intolerable communication overhead and low model accuracy. To enable fast and accurate FL, this paper proposes a novel data-based device grouping approach that can effectively reduce the disadvantages of weight divergence during the training of non-IID data. However, since our grouping method is based on the similarity of extracted feature maps from IoT devices, it may incur additional risks of privacy exposure. To solve this problem, we propose an improved version by exploiting similarity information using the Locality-Sensitive Hashing (LSH) algorithm without exposing extracted feature maps. Comprehensive experimental results on well-known benchmarks show that our approach can not only accelerate the convergence rate, but also improve the prediction accuracy for FL with non-IID data.
Imbalanced data preprocessing techniques utilizing local data characteristics
Nov 28, 2021
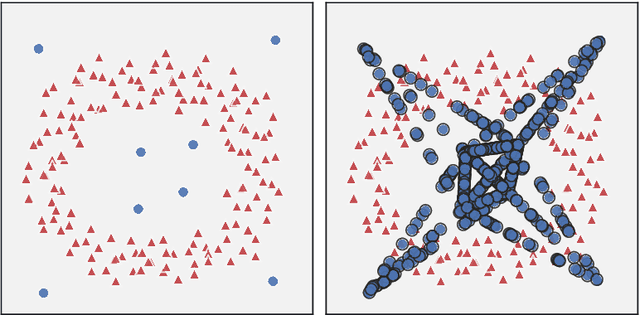
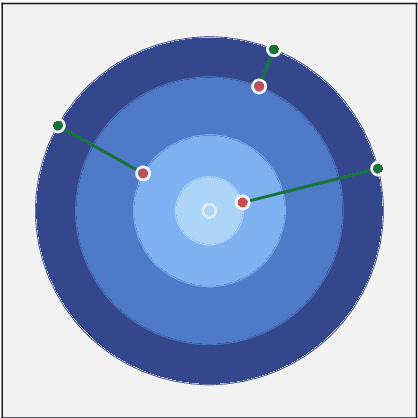
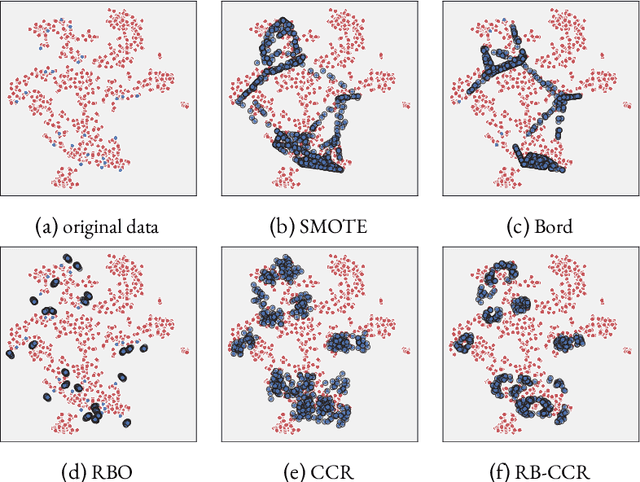
Data imbalance, that is the disproportion between the number of training observations coming from different classes, remains one of the most significant challenges affecting contemporary machine learning. The negative impact of data imbalance on traditional classification algorithms can be reduced by the data preprocessing techniques, methods that manipulate the training data to artificially reduce the degree of imbalance. However, the existing data preprocessing techniques, in particular SMOTE and its derivatives, which constitute the most prevalent paradigm of imbalanced data preprocessing, tend to be susceptible to various data difficulty factors. This is in part due to the fact that the original SMOTE algorithm does not utilize the information about majority class observations. The focus of this thesis is development of novel data resampling strategies natively utilizing the information about the distribution of both minority and majority class. The thesis summarizes the content of 12 research papers focused on the proposed binary data resampling strategies, their translation to the multi-class setting, and the practical application to the problem of histopathological data classification.
Context Matters in Semantically Controlled Language Generation for Task-oriented Dialogue Systems
Nov 28, 2021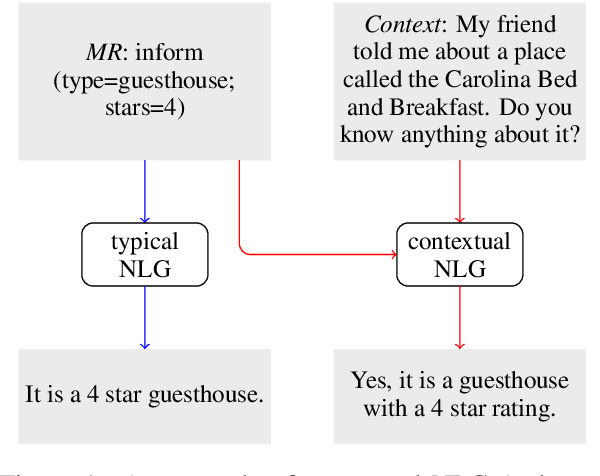

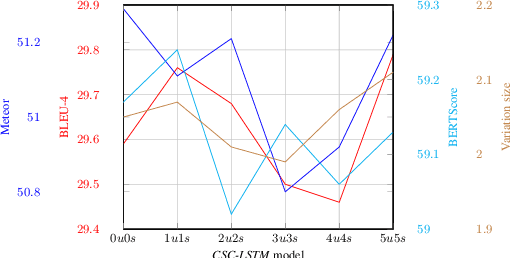
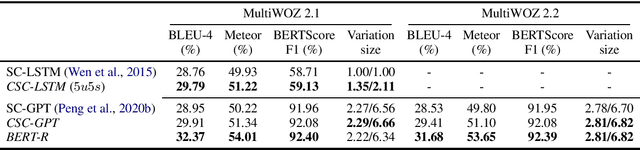
This work combines information about the dialogue history encoded by pre-trained model with a meaning representation of the current system utterance to realize contextual language generation in task-oriented dialogues. We utilize the pre-trained multi-context ConveRT model for context representation in a model trained from scratch; and leverage the immediate preceding user utterance for context generation in a model adapted from the pre-trained GPT-2. Both experiments with the MultiWOZ dataset show that contextual information encoded by pre-trained model improves the performance of response generation both in automatic metrics and human evaluation. Our presented contextual generator enables higher variety of generated responses that fit better to the ongoing dialogue. Analysing the context size shows that longer context does not automatically lead to better performance, but the immediate preceding user utterance plays an essential role for contextual generation. In addition, we also propose a re-ranker for the GPT-based generation model. The experiments show that the response selected by the re-ranker has a significant improvement on automatic metrics.
Gated SwitchGAN for multi-domain facial image translation
Nov 28, 2021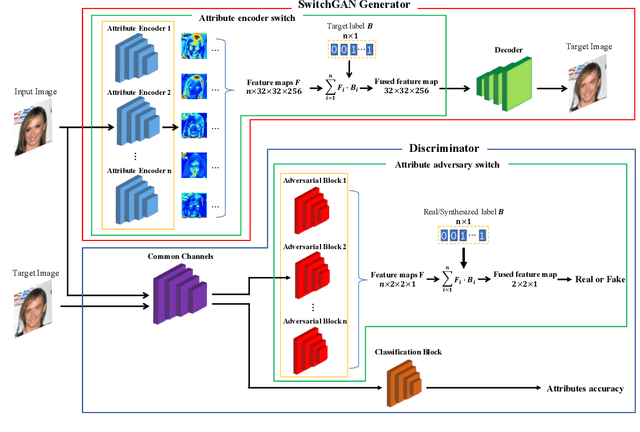


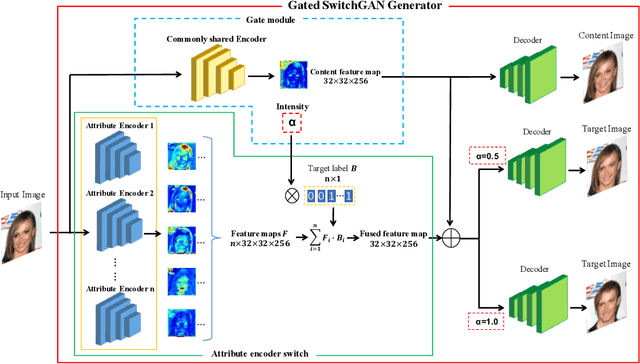
Recent studies on multi-domain facial image translation have achieved impressive results. The existing methods generally provide a discriminator with an auxiliary classifier to impose domain translation. However, these methods neglect important information regarding domain distribution matching. To solve this problem, we propose a switch generative adversarial network (SwitchGAN) with a more adaptive discriminator structure and a matched generator to perform delicate image translation among multiple domains. A feature-switching operation is proposed to achieve feature selection and fusion in our conditional modules. We demonstrate the effectiveness of our model. Furthermore, we also introduce a new capability of our generator that represents attribute intensity control and extracts content information without tailored training. Experiments on the Morph, RaFD and CelebA databases visually and quantitatively show that our extended SwitchGAN (i.e., Gated SwitchGAN) can achieve better translation results than StarGAN, AttGAN and STGAN. The attribute classification accuracy achieved using the trained ResNet-18 model and the FID score obtained using the ImageNet pretrained Inception-v3 model also quantitatively demonstrate the superior performance of our models.
Scotch: An Efficient Secure Computation Framework for Secure Aggregation
Jan 19, 2022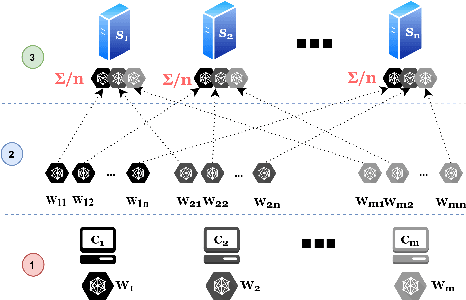
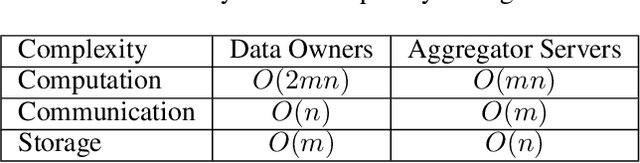
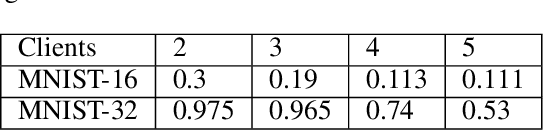
Federated learning enables multiple data owners to jointly train a machine learning model without revealing their private datasets. However, a malicious aggregation server might use the model parameters to derive sensitive information about the training dataset used. To address such leakage, differential privacy and cryptographic techniques have been investigated in prior work, but these often result in large communication overheads or impact model performance. To mitigate this centralization of power, we propose \textsc{Scotch}, a decentralized \textit{m-party} secure-computation framework for federated aggregation that deploys MPC primitives, such as \textit{secret sharing}. Our protocol is simple, efficient, and provides strict privacy guarantees against curious aggregators or colluding data-owners with minimal communication overheads compared to other existing \textit{state-of-the-art} privacy-preserving federated learning frameworks. We evaluate our framework by performing extensive experiments on multiple datasets with promising results. \textsc{Scotch} can train the standard MLP NN with the training dataset split amongst 3 participating users and 3 aggregating servers with 96.57\% accuracy on MNIST, and 98.40\% accuracy on the Extended MNIST (digits) dataset, while providing various optimizations.
Learning Sparse and Continuous Graph Structures for Multivariate Time Series Forecasting
Jan 24, 2022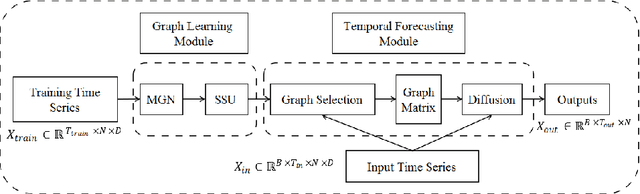

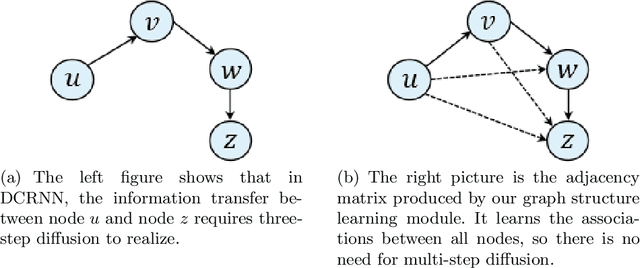
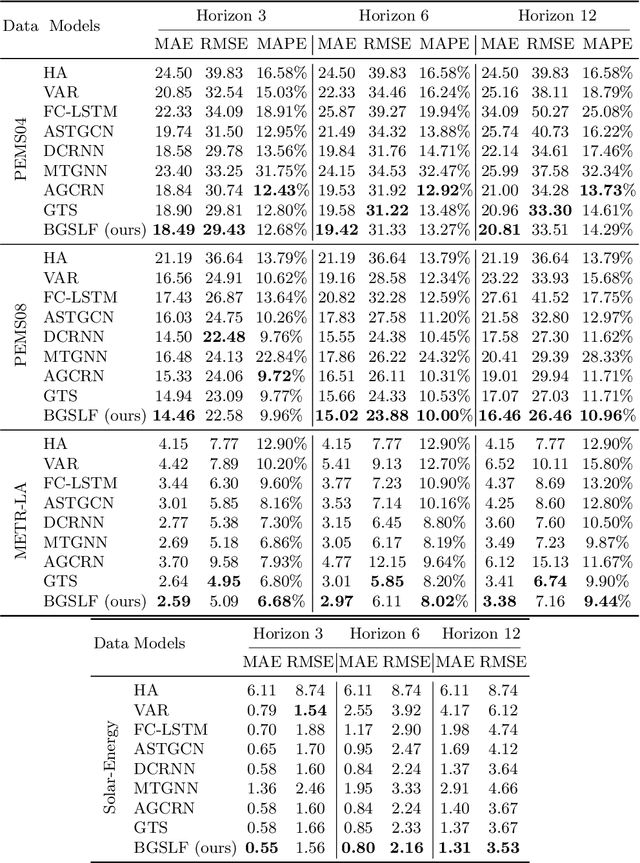
Accurate forecasting of multivariate time series is an extensively studied subject in finance, transportation, and computer science. Fully mining the correlation and causation between the variables in a multivariate time series exhibits noticeable results in improving the performance of a time series model. Recently, some models have explored the dependencies between variables through end-to-end graph structure learning without the need for pre-defined graphs. However, most current models do not incorporate the trade-off between effectiveness and flexibility and lack the guidance of domain knowledge in the design of graph learning algorithms. Besides, they have issues generating sparse graph structures, which pose challenges to end-to-end learning. In this paper, we propose Learning Sparse and Continuous Graphs for Forecasting (LSCGF), a novel deep learning model that joins graph learning and forecasting. Technically, LSCGF leverages the spatial information into convolutional operation and extracts temporal dynamics using the diffusion convolution recurrent network. At the same time, we propose a brand new method named Smooth Sparse Unit (SSU) to learn sparse and continuous graph adjacency matrix. Extensive experiments on three real-world datasets demonstrate that our model achieves state-of-the-art performances with minor trainable parameters.