 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CPRAL: Collaborative Panoptic-Regional Active Learning for Semantic Segmentation
Jan 11, 2022
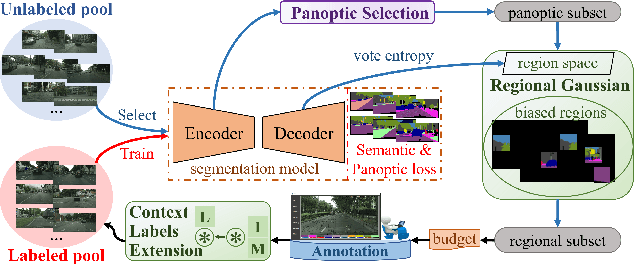
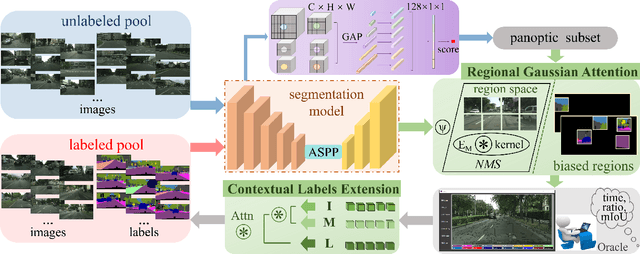
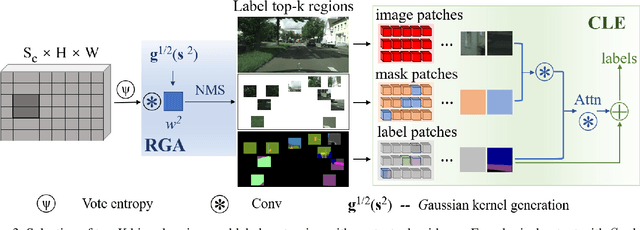

Acquiring the most representative examples via active learning (AL) can benefit many data-dependent computer vision tasks by minimizing efforts of image-level or pixel-wise annotations. In this paper, we propose a novel Collaborative Panoptic-Regional Active Learning framework (CPRAL) to address the semantic segmentation task. For a small batch of images initially sampled with pixel-wise annotations, we employ panoptic information to initially select unlabeled samples. Considering the class imbalance in the segmentation dataset, we import a Regional Gaussian Attention module (RGA) to achieve semantics-biased selection. The subset is highlighted by vote entropy and then attended by Gaussian kernels to maximize the biased regions. We also propose a Contextual Labels Extension (CLE) to boost regional annotations with contextual attention guidance. With the collaboration of semantics-agnostic panoptic matching and regionbiased selection and extension, our CPRAL can strike a balance between labeling efforts and performance and compromise the semantics distribution. We perform extensive experiments on Cityscapes and BDD10K datasets and show that CPRAL outperforms the cutting-edge methods with impressive results and less labeling proportion.
Pre-Trained Neural Language Models for Automatic Mobile App User Feedback Answer Generation
Feb 04, 2022Studies show that developers' answers to the mobile app users' feedbacks on app stores can increase the apps' star rating. To help app developers generate answers that are related to the users' issues, recent studies develop models to generate the answers automatically. Aims: The app response generation models use deep neural networks and require training data. Pre-Trained neural language Models (PTM) used in Natural Language Processing (NLP) take advantage of the information they learned from a large corpora in an unsupervised manner, and can reduce the amount of required training data. In this paper, we evaluate PTMs to generate replies to the mobile app user feedbacks. Method: We train a Transformer model from scratch and fine-tune two PTMs to evaluate the generated responses, which are compared to RRGEN, a current app response model. We also evaluate the models with different portions of the training data. Results: The results on a large dataset evaluated by automatic metrics show that PTMs obtain lower scores than the baselines. However, our human evaluation confirms that PTMs can generate more relevant and meaningful responses to the posted feedbacks. Moreover, the performance of PTMs has less drop compared to other models when the amount of training data is reduced to 1/3. Conclusion: PTMs are useful in generating responses to app reviews and are more robust models to the amount of training data provided. However, the prediction time is 19X than RRGEN. This study can provide new avenues for research in adapting the PTMs for analyzing mobile app user feedbacks. Index Terms-mobile app user feedback analysis, neural pre-trained language models, automatic answer generation
MobileFaceSwap: A Lightweight Framework for Video Face Swapping
Jan 11, 2022
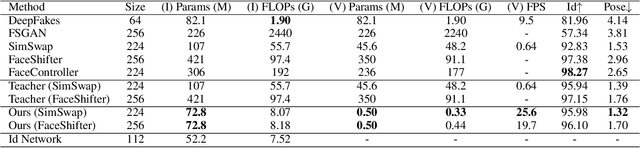
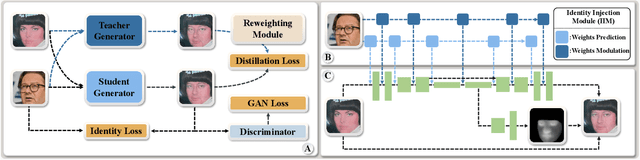
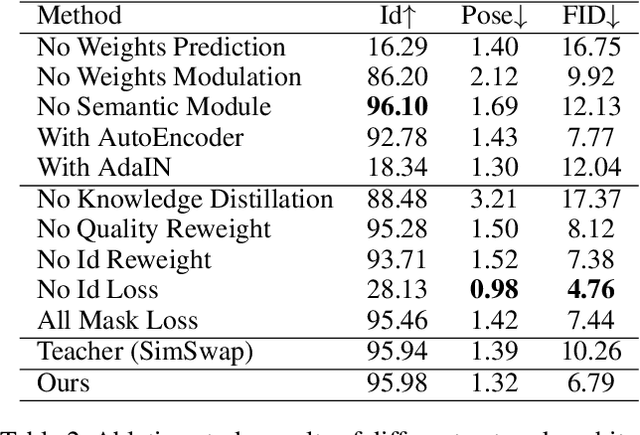
Advanced face swapping methods have achieved appealing results. However, most of these methods have many parameters and computations, which makes it challenging to apply them in real-time applications or deploy them on edge devices like mobile phones. In this work, we propose a lightweight Identity-aware Dynamic Network (IDN) for subject-agnostic face swapping by dynamically adjusting the model parameters according to the identity information. In particular, we design an efficient Identity Injection Module (IIM) by introducing two dynamic neural network techniques, including the weights prediction and weights modulation. Once the IDN is updated, it can be applied to swap faces given any target image or video. The presented IDN contains only 0.50M parameters and needs 0.33G FLOPs per frame, making it capable for real-time video face swapping on mobile phones. In addition, we introduce a knowledge distillation-based method for stable training, and a loss reweighting module is employed to obtain better synthesized results. Finally, our method achieves comparable results with the teacher models and other state-of-the-art methods.
Pixel-Stega: Generative Image Steganography Based on Autoregressive Models
Dec 21, 2021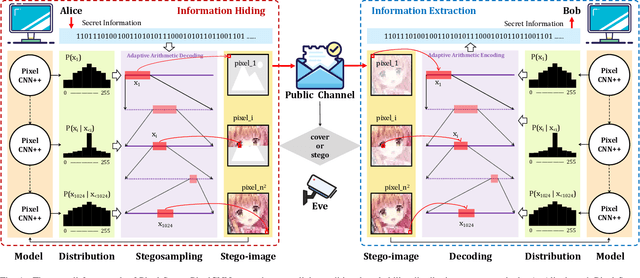

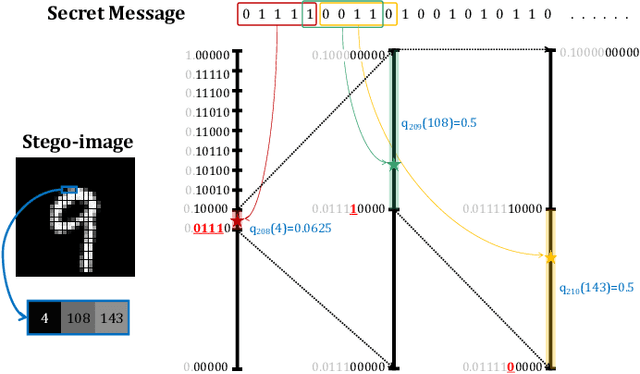

In this letter, we explored generative image steganography based on autoregressive models. We proposed Pixel-Stega, which implements pixel-level information hiding with autoregressive models and arithmetic coding algorithm. Firstly, one of the autoregressive models, PixelCNN++, is utilized to produce explicit conditional probability distribution of each pixel. Secondly, secret messages are encoded to the selection of pixels through steganographic sampling (stegosampling) based on arithmetic coding. We carried out qualitative and quantitative assessment on gray-scale and colour image datasets. Experimental results show that Pixel-Stega is able to embed secret messages adaptively according to the entropy of the pixels to achieve both high embedding capacity (up to 4.3 bpp) and nearly perfect imperceptibility (about 50% detection accuracy).
A Secure Key Sharing Algorithm Exploiting Phase Reciprocity in Wireless Channels
Nov 30, 2021
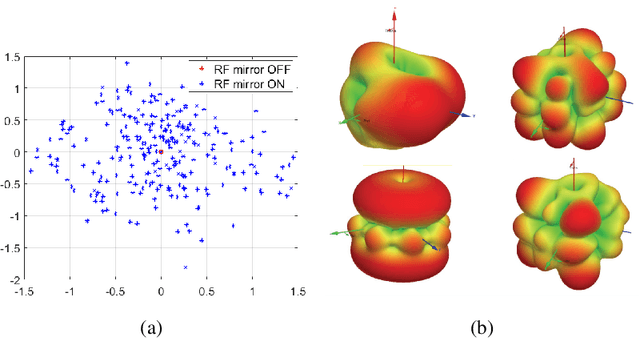
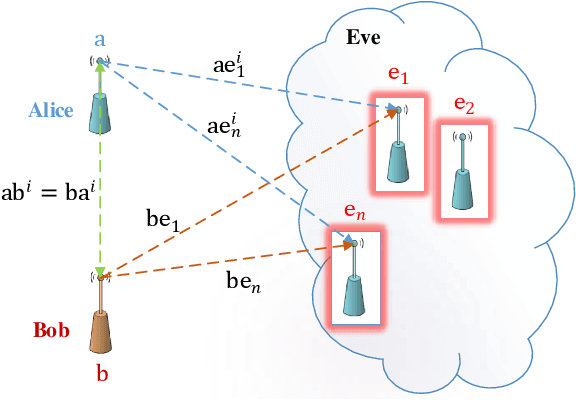
This article presents a secure key exchange algorithm that exploits reciprocity in wireless channels to share a secret key between two nodes $A$ and $B$. Reciprocity implies that the channel phases in the links $A\rightarrow B$ and $B\rightarrow A$ are the same. A number of such reciprocal phase values are measured at nodes $A$ and $B$, called shared phase values hereafter. Each shared phase value is used to mask points of a Phase Shift Keying (PSK) constellation. Masking is achieved by rotating each PSK constellation with a shared phase value. Rotation of constellation is equivalent to adding phases modulo-$2\pi$, and as the channel phase is uniformly distributed in $[0,2\pi)$, the result of summation conveys zero information about summands. To enlarge the key size over a static or slow fading channel, the Radio Frequency (RF) propagation path is perturbed to create several independent realizations of multi-path fading, each used to share a new phase value. To eavesdrop a phase value shared in this manner, the Eavesdropper (Eve) will always face an under-determined system of linear equations which will not reveal any useful information about its actual solution value. This property is used to establish a secure key between two legitimate users.
COROLLA: An Efficient Multi-Modality Fusion Framework with Supervised Contrastive Learning for Glaucoma Grading
Jan 11, 2022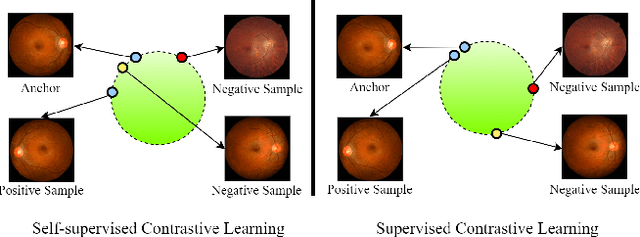
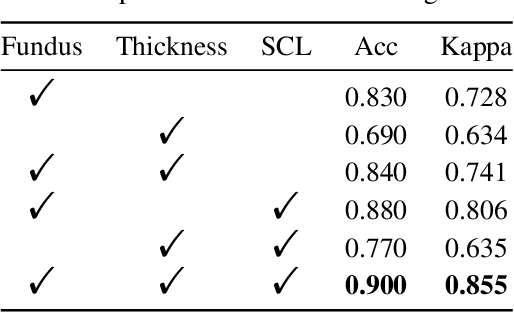
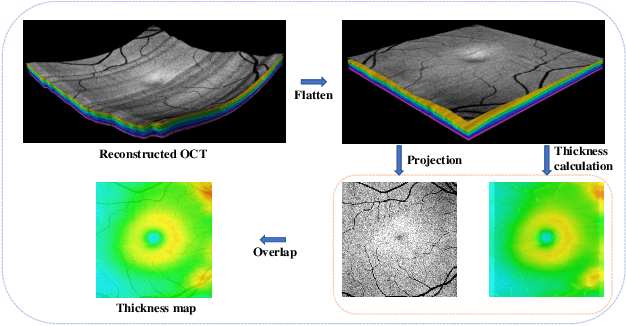
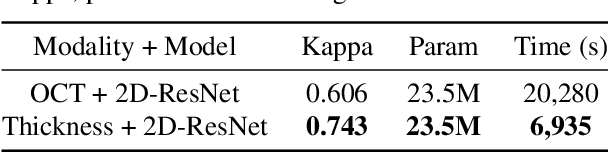
Glaucoma is one of the ophthalmic diseases that may cause blindness, for which early detection and treatment are very important. Fundus images and optical coherence tomography (OCT) images are both widely-used modalities in diagnosing glaucoma. However, existing glaucoma grading approaches mainly utilize a single modality, ignoring the complementary information between fundus and OCT. In this paper, we propose an efficient multi-modality supervised contrastive learning framework, named COROLLA, for glaucoma grading. Through layer segmentation as well as thickness calculation and projection, retinal thickness maps are extracted from the original OCT volumes and used as a replacing modality, resulting in more efficient calculations with less memory usage. Given the high structure and distribution similarities across medical image samples, we employ supervised contrastive learning to increase our models' discriminative power with better convergence. Moreover, feature-level fusion of paired fundus image and thickness map is conducted for enhanced diagnosis accuracy. On the GAMMA dataset, our COROLLA framework achieves overwhelming glaucoma grading performance compared to state-of-the-art methods.
Efficient Non-Local Contrastive Attention for Image Super-Resolution
Jan 11, 2022
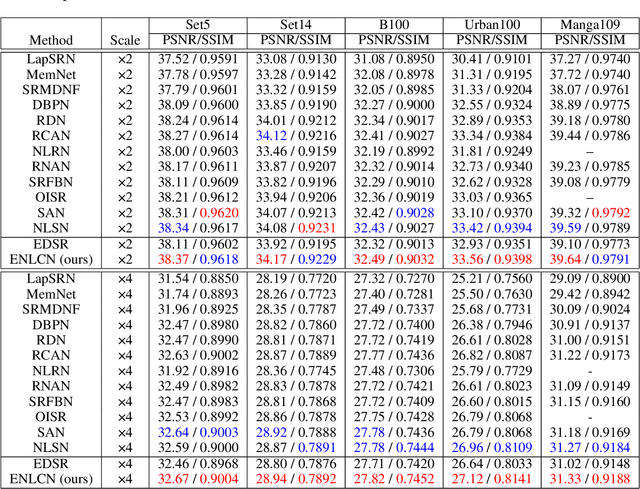
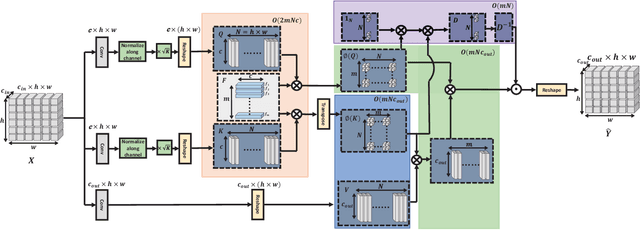

Non-Local Attention (NLA) brings significant improvement for Single Image Super-Resolution (SISR) by leveraging intrinsic feature correlation in natural images. However, NLA gives noisy information large weights and consumes quadratic computation resources with respect to the input size, limiting its performance and application. In this paper, we propose a novel Efficient Non-Local Contrastive Attention (ENLCA) to perform long-range visual modeling and leverage more relevant non-local features. Specifically, ENLCA consists of two parts, Efficient Non-Local Attention (ENLA) and Sparse Aggregation. ENLA adopts the kernel method to approximate exponential function and obtains linear computation complexity. For Sparse Aggregation, we multiply inputs by an amplification factor to focus on informative features, yet the variance of approximation increases exponentially. Therefore, contrastive learning is applied to further separate relevant and irrelevant features. To demonstrate the effectiveness of ENLCA, we build an architecture called Efficient Non-Local Contrastive Network (ENLCN) by adding a few of our modules in a simple backbone. Extensive experimental results show that ENLCN reaches superior performance over state-of-the-art approaches on both quantitative and qualitative evaluations.
LoNLI: An Extensible Framework for Testing Diverse Logical Reasoning Capabilities for NLI
Dec 04, 2021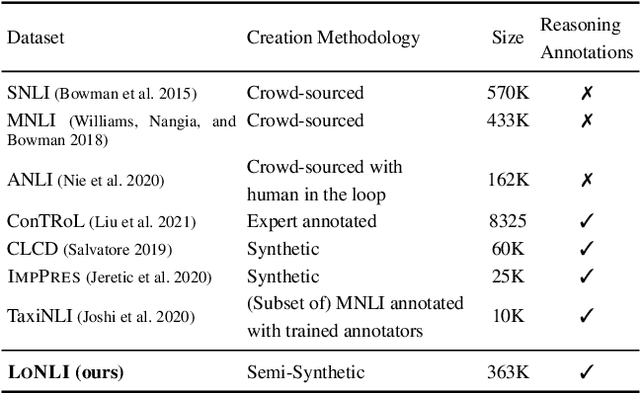
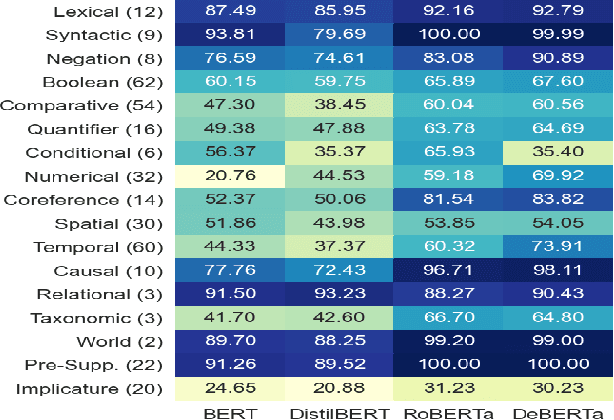

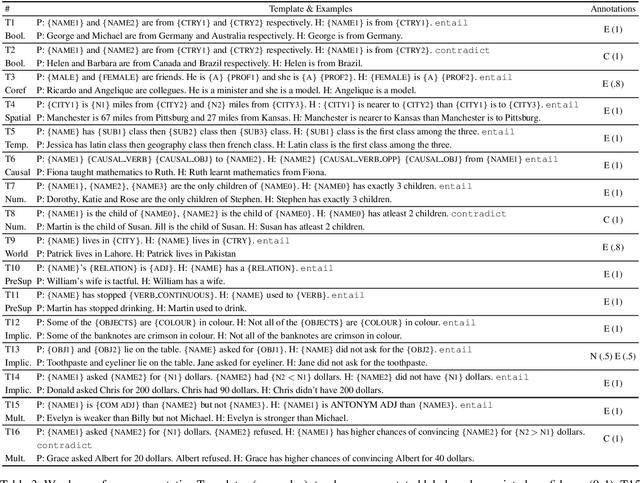
Natural Language Inference (NLI) is considered a representative task to test natural language understanding (NLU). In this work, we propose an extensible framework to collectively yet categorically test diverse Logical reasoning capabilities required for NLI (and by extension, NLU). Motivated by behavioral testing, we create a semi-synthetic large test-bench (363 templates, 363k examples) and an associated framework that offers following utilities: 1) individually test and analyze reasoning capabilities along 17 reasoning dimensions (including pragmatic reasoning), 2) design experiments to study cross-capability information content (leave one out or bring one in); and 3) the synthetic nature enable us to control for artifacts and biases. The inherited power of automated test case instantiation from free-form natural language templates (using CheckList), and a well-defined taxonomy of capabilities enable us to extend to (cognitively) harder test cases while varying the complexity of natural language. Through our analysis of state-of-the-art NLI systems, we observe that our benchmark is indeed hard (and non-trivial even with training on additional resources). Some capabilities stand out as harder. Further fine-grained analysis and fine-tuning experiments reveal more insights about these capabilities and the models -- supporting and extending previous observations. Towards the end we also perform an user-study, to investigate whether behavioral information can be utilised to generalize much better for some models compared to others.
Monitoring crop phenology with street-level imagery using computer vision
Dec 16, 2021
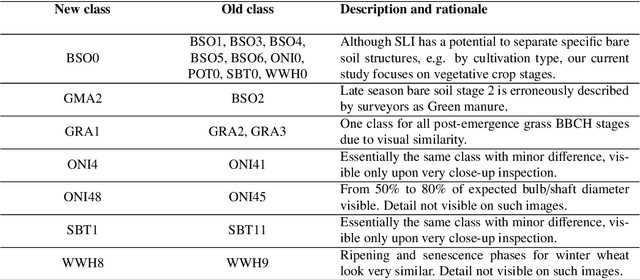


Street-level imagery holds a significant potential to scale-up in-situ data collection. This is enabled by combining the use of cheap high quality cameras with recent advances in deep learning compute solutions to derive relevant thematic information. We present a framework to collect and extract crop type and phenological information from street level imagery using computer vision. During the 2018 growing season, high definition pictures were captured with side-looking action cameras in the Flevoland province of the Netherlands. Each month from March to October, a fixed 200-km route was surveyed collecting one picture per second resulting in a total of 400,000 geo-tagged pictures. At 220 specific parcel locations detailed on the spot crop phenology observations were recorded for 17 crop types. Furthermore, the time span included specific pre-emergence parcel stages, such as differently cultivated bare soil for spring and summer crops as well as post-harvest cultivation practices, e.g. green manuring and catch crops. Classification was done using TensorFlow with a well-known image recognition model, based on transfer learning with convolutional neural networks (MobileNet). A hypertuning methodology was developed to obtain the best performing model among 160 models. This best model was applied on an independent inference set discriminating crop type with a Macro F1 score of 88.1% and main phenological stage at 86.9% at the parcel level. Potential and caveats of the approach along with practical considerations for implementation and improvement are discussed. The proposed framework speeds up high quality in-situ data collection and suggests avenues for massive data collection via automated classification using computer vision.
Combining optimal control and learning for autonomous aerial navigation in novel indoor environments
Dec 07, 2021
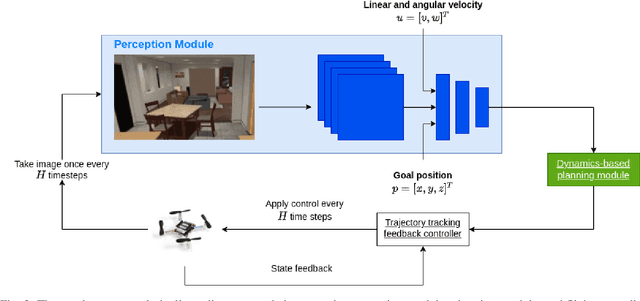


This report proposes a combined optimal control and perception framework for Micro Aerial Vehicle (MAV) autonomous navigation in novel indoor enclosed environments, relying exclusively on on-board sensor data. We use privileged information from a simulator to generate optimal waypoints in 3D space for our perception system learns to imitate. The trained learning based perception module in turn is able to generate similar obstacle avoiding waypoints from sensor data (RGB + IMU) alone. We demonstrate the efficacy of the framework across novel scenes in the iGibson simulation environment.