 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hybrid 3D Beamforming Relying on Sensor-Based Training and Channel Estimation for Reconfigurable Intelligent Surface Aided TeraHertz MIMO systems
Jan 26, 2022
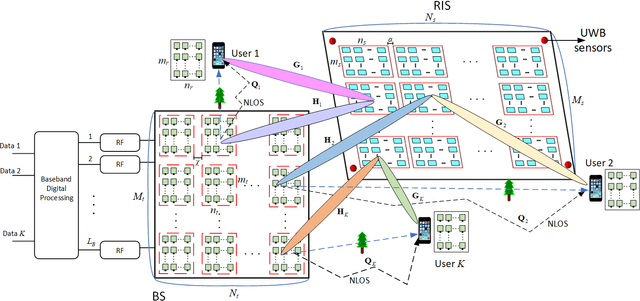
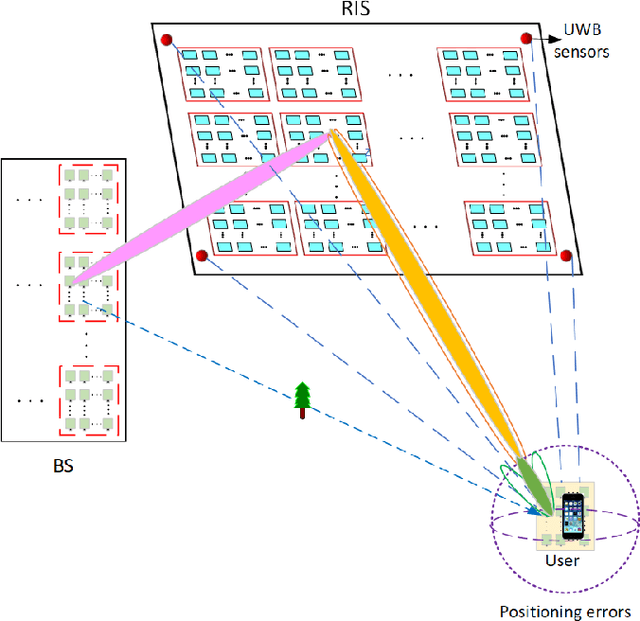
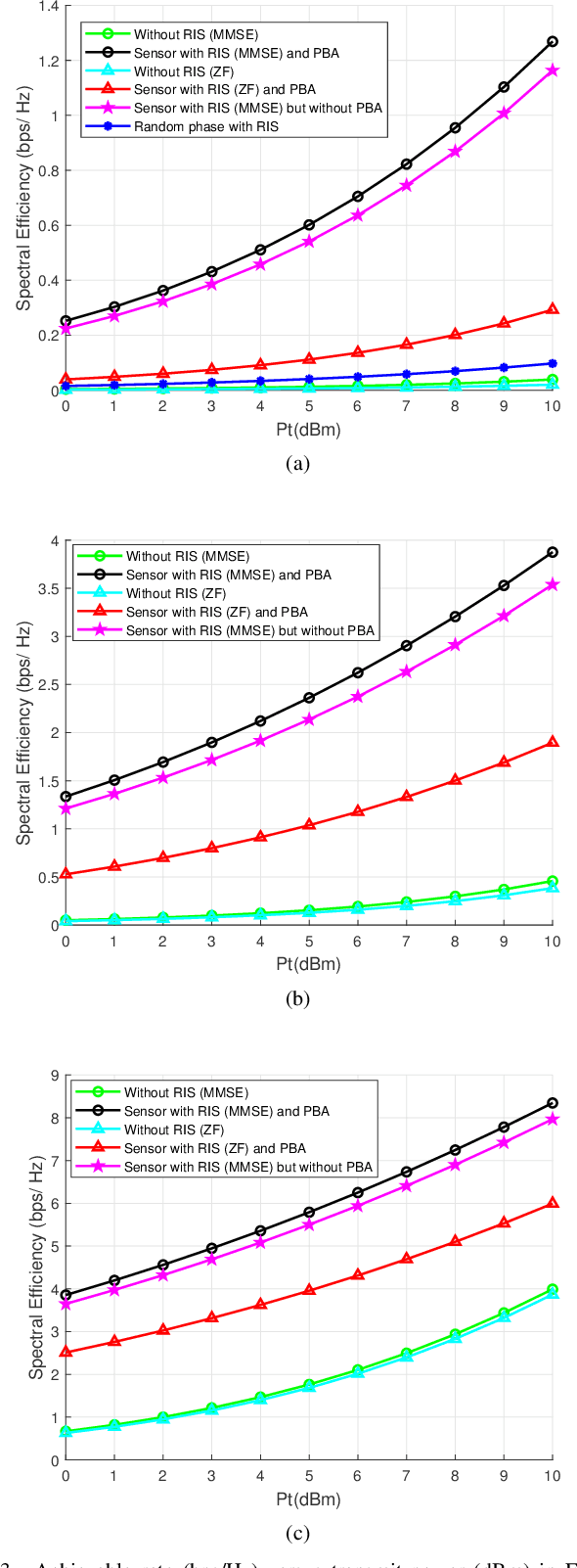
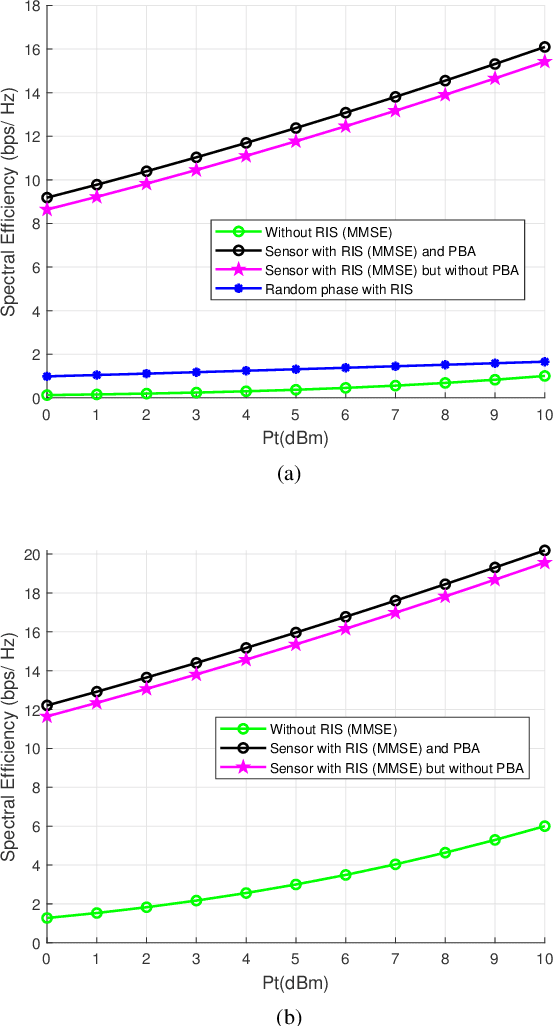
Terahertz (THz) systems have the benefit of high bandwidth and hence are capable of supporting ultra-high data rates, albeit at the cost of high pathloss. Hence they tend to harness high-gain beamforming. Therefore a novel hybrid 3D beamformer relying on sophisticated sensor-based beam training and channel estimation is proposed for Reconfigurable Intelligent Surface (RIS) aided THz MIMO systems. A so-called array-of-subarray based THz BS architecture is adopted and the corresponding sub-RIS structure is proposed. The BS, RIS and receiver antenna arrays of the users are all uniform planar arrays (UPAs). The Ultra-wideband (UWB) sensors are integrated into the RIS and the user location information obtained by the UWB sensors is exploited for channel estimation and beamforming. Furthermore, the novel concept of a Precise Beamforming Algorithm (PBA) is proposed, which further improves the beam-forming accuracy by circumventing the performance limitations imposed by positioning errors. Moreover, the conditions of maintaining the orthogonality of the RIS-aided THz channel are derived in support of spatial multiplexing. The closed-form expressions of the near-field and far-field path-loss are also derived. Our simulation results show that the proposed scheme accurately estimates the RIS-aided THz channel and the spectral efficiency is much improved, despite its low complexity. This makes our solution eminently suitable for delay-sensitive applications.
Real-time Street Human Motion Capture
Dec 21, 2021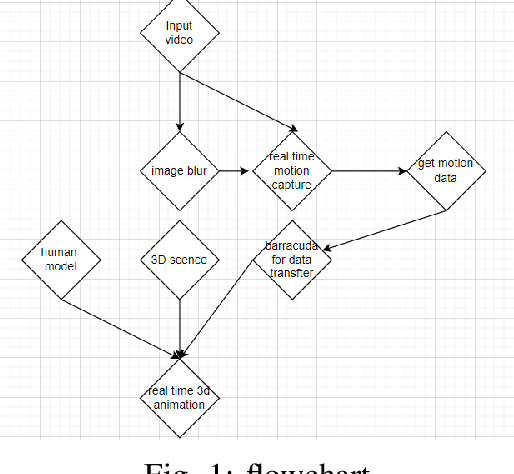


In recent years, motion capture technology using computers has developed rapidly. Because of its high efficiency and excellent performance, it replaces many traditional methods and is being widely used in many fields. Our project is about street scene video human motion capturing and analysis. The primary goal of the project is to capture the human motion in a video and use the motion information for 3D animation (human) in real-time. We applied a neural network for motion capture and implement it in the unity under a street view scene. By analyzing the motion data, we will have a better estimation of the street condition, which is useful for other high-tech applications such as self-driving cars.
A Scalable Deep Reinforcement Learning Model for Online Scheduling Coflows of Multi-Stage Jobs for High Performance Computing
Dec 21, 2021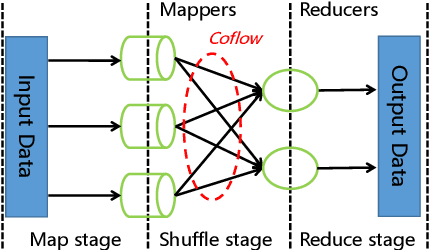

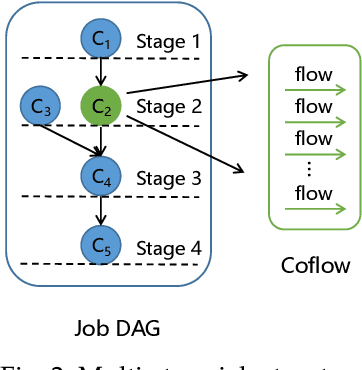

Coflow is a recently proposed networking abstraction to help improve the communication performance of data-parallel computing jobs. In multi-stage jobs, each job consists of multiple coflows and is represented by a Directed Acyclic Graph (DAG). Efficiently scheduling coflows is critical to improve the data-parallel computing performance in data centers. Compared with hand-tuned scheduling heuristics, existing work DeepWeave [1] utilizes Reinforcement Learning (RL) framework to generate highly-efficient coflow scheduling policies automatically. It employs a graph neural network (GNN) to encode the job information in a set of embedding vectors, and feeds a flat embedding vector containing the whole job information to the policy network. However, this method has poor scalability as it is unable to cope with jobs represented by DAGs of arbitrary sizes and shapes, which requires a large policy network for processing a high-dimensional embedding vector that is difficult to train. In this paper, we first utilize a directed acyclic graph neural network (DAGNN) to process the input and propose a novel Pipelined-DAGNN, which can effectively speed up the feature extraction process of the DAGNN. Next, we feed the embedding sequence composed of schedulable coflows instead of a flat embedding of all coflows to the policy network, and output a priority sequence, which makes the size of the policy network depend on only the dimension of features instead of the product of dimension and number of nodes in the job's DAG.Furthermore, to improve the accuracy of the priority scheduling policy, we incorporate the Self-Attention Mechanism into a deep RL model to capture the interaction between different parts of the embedding sequence to make the output priority scores relevant. Based on this model, we then develop a coflow scheduling algorithm for online multi-stage jobs.
Clustering-based Joint Channel Estimation and Signal Detection for NOMA
Jan 17, 2022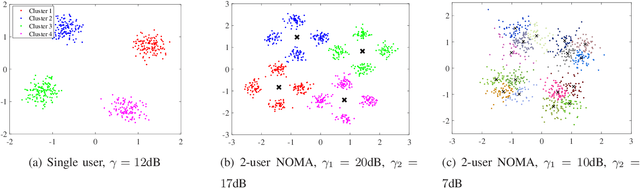
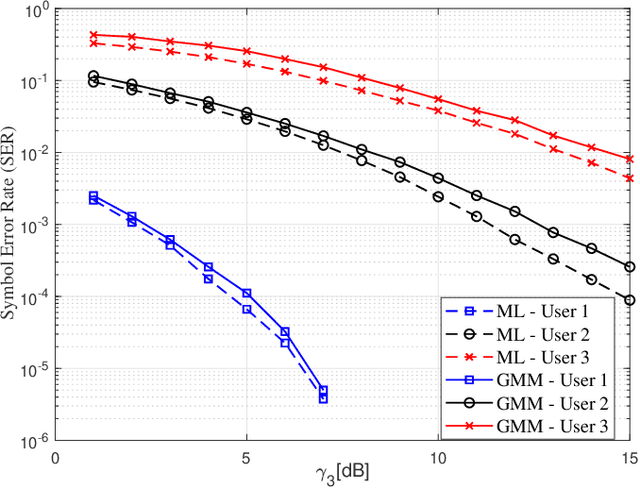
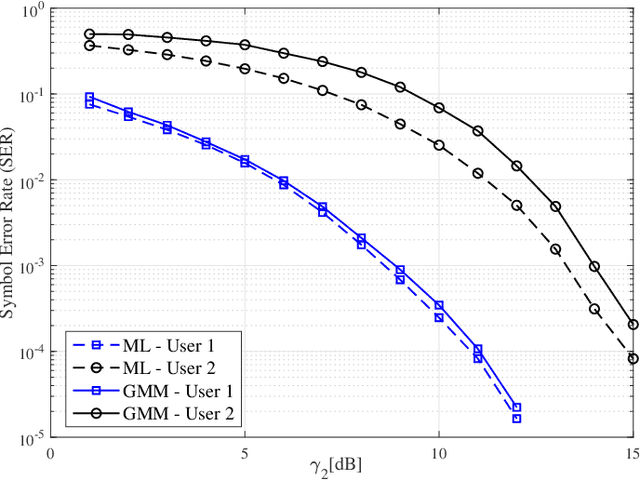
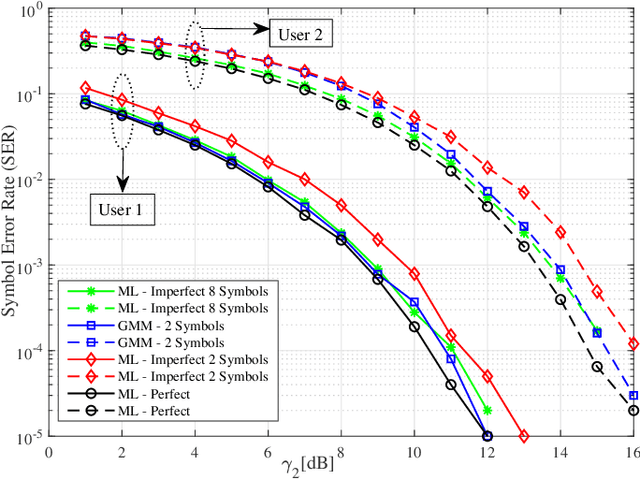
We propose a joint channel estimation and signal detection approach for the uplink non-orthogonal multiple access using unsupervised machine learning. We apply the Gaussian mixture model to cluster the received signals, and accordingly optimize the decision regions to enhance the symbol error rate (SER). We show that, when the received powers of the users are sufficiently different, the proposed clustering-based approach achieves an SER performance on a par with that of the conventional maximum-likelihood detector with full channel state information. However, unlike the proposed approach, the maximum-likelihood detector requires the transmission of a large number of pilot symbols to accurately estimate the channel. The accuracy of the utilized clustering algorithm depends on the number of the data points available at the receiver. Therefore, there exists a tradeoff between accuracy and block length. We provide a comprehensive performance analysis of the proposed approach as well as deriving a theoretical bound on its SER performance as a function of the block length. Our simulation results corroborate the effectiveness of the proposed approach and verify that the calculated theoretical bound can predict the SER performance of the proposed approach well.
BoxeR: Box-Attention for 2D and 3D Transformers
Nov 25, 2021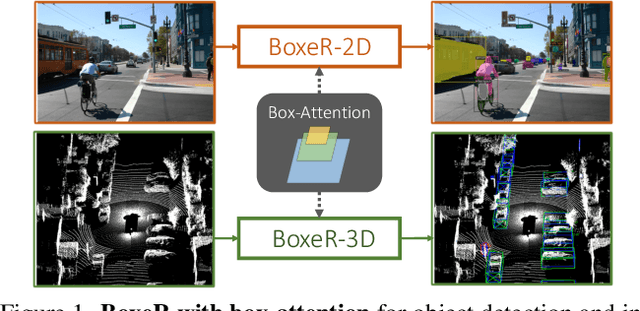
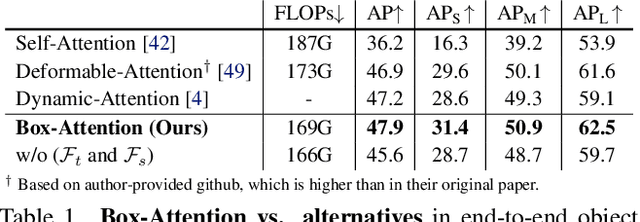
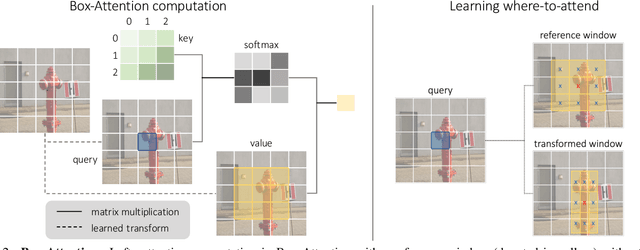

In this paper, we propose a simple attention mechanism, we call Box-Attention. It enables spatial interaction between grid features, as sampled from boxes of interest, and improves the learning capability of transformers for several vision tasks. Specifically, we present BoxeR, short for Box Transformer, which attends to a set of boxes by predicting their transformation from a reference window on an input feature map. The BoxeR computes attention weights on these boxes by considering its grid structure. Notably, BoxeR-2D naturally reasons about box information within its attention module, making it suitable for end-to-end instance detection and segmentation tasks. By learning invariance to rotation in the box-attention module, BoxeR-3D is capable of generating discriminative information from a bird-eye-view plane for 3D end-to-end object detection. Our experiments demonstrate that the proposed BoxeR-2D achieves better results on COCO detection, and reaches comparable performance with well-established and highly-optimized Mask R-CNN on COCO instance segmentation. BoxeR-3D already obtains a compelling performance for the vehicle category of Waymo Open, without any class-specific optimization. The code will be released.
Stochastic Coded Federated Learning with Convergence and Privacy Guarantees
Jan 26, 2022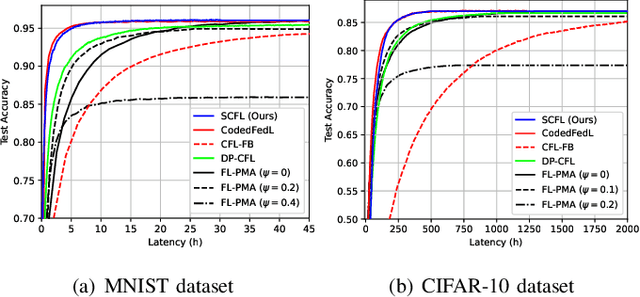
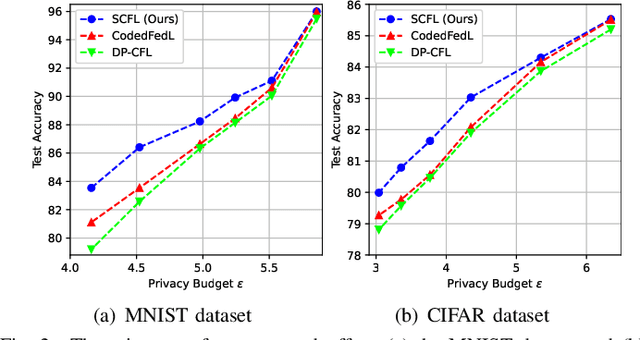
Federated learning (FL) has attracted much attention as a privacy-preserving distributed machine learning framework, where many clients collaboratively train a machine learning model by exchanging model updates with a parameter server instead of sharing their raw data. Nevertheless, FL training suffers from slow convergence and unstable performance due to stragglers caused by the heterogeneous computational resources of clients and fluctuating communication rates. This paper proposes a coded FL framework, namely stochastic coded federated learning (SCFL) to mitigate the straggler issue. In the proposed framework, each client generates a privacy-preserving coded dataset by adding additive noise to the random linear combination of its local data. The server collects the coded datasets from all the clients to construct a composite dataset, which helps to compensate for the straggling effect. In the training process, the server as well as clients perform mini-batch stochastic gradient descent (SGD), and the server adds a make-up term in model aggregation to obtain unbiased gradient estimates. We characterize the privacy guarantee by the mutual information differential privacy (MI-DP) and analyze the convergence performance in federated learning. Besides, we demonstrate a privacy-performance tradeoff of the proposed SCFL method by analyzing the influence of the privacy constraint on the convergence rate. Finally, numerical experiments corroborate our analysis and show the benefits of SCFL in achieving fast convergence while preserving data privacy.
Virtual Adversarial Training for Semi-supervised Breast Mass Classification
Jan 25, 2022This study aims to develop a novel computer-aided diagnosis (CAD) scheme for mammographic breast mass classification using semi-supervised learning. Although supervised deep learning has achieved huge success across various medical image analysis tasks, its success relies on large amounts of high-quality annotations, which can be challenging to acquire in practice. To overcome this limitation, we propose employing a semi-supervised method, i.e., virtual adversarial training (VAT), to leverage and learn useful information underlying in unlabeled data for better classification of breast masses. Accordingly, our VAT-based models have two types of losses, namely supervised and virtual adversarial losses. The former loss acts as in supervised classification, while the latter loss aims at enhancing model robustness against virtual adversarial perturbation, thus improving model generalizability. To evaluate the performance of our VAT-based CAD scheme, we retrospectively assembled a total of 1024 breast mass images, with equal number of benign and malignant masses. A large CNN and a small CNN were used in this investigation, and both were trained with and without the adversarial loss. When the labeled ratios were 40% and 80%, VAT-based CNNs delivered the highest classification accuracy of 0.740 and 0.760, respectively. The experimental results suggest that the VAT-based CAD scheme can effectively utilize meaningful knowledge from unlabeled data to better classify mammographic breast mass images.
Exploiting Both Domain-specific and Invariant Knowledge via a Win-win Transformer for Unsupervised Domain Adaptation
Nov 25, 2021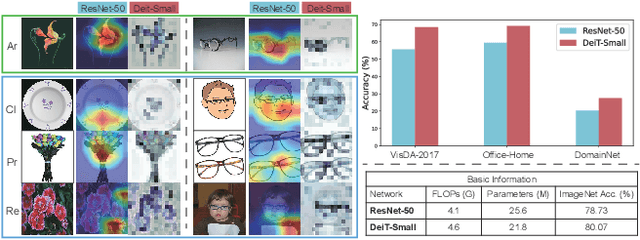
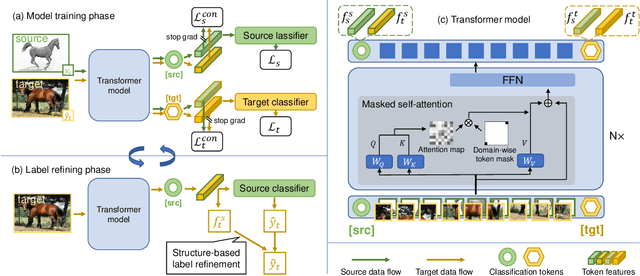
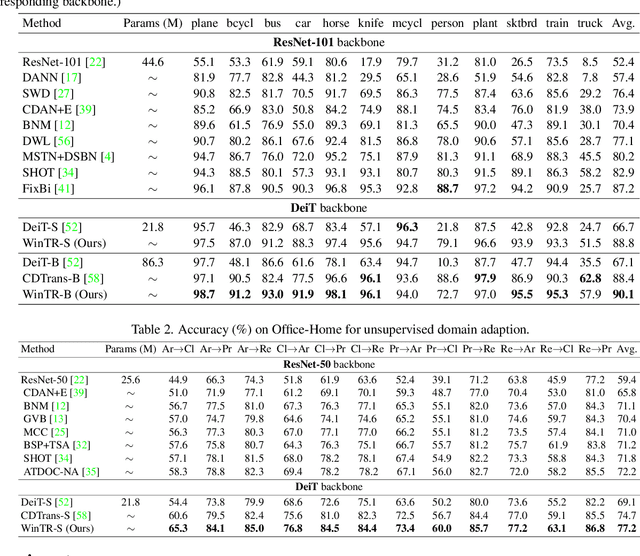
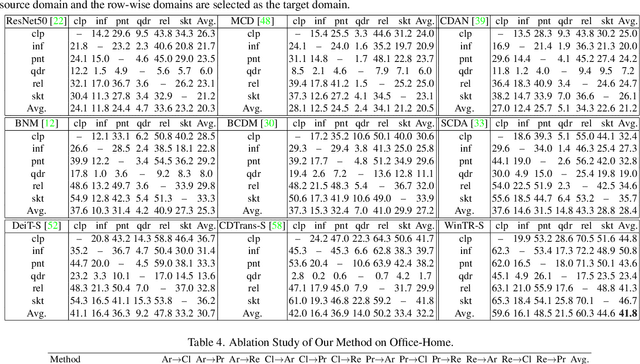
Unsupervised Domain Adaptation (UDA) aims to transfer knowledge from a labeled source domain to an unlabeled target domain. Most existing UDA approaches enable knowledge transfer via learning domain-invariant representation and sharing one classifier across two domains. However, ignoring the domain-specific information that are related to the task, and forcing a unified classifier to fit both domains will limit the feature expressiveness in each domain. In this paper, by observing that the Transformer architecture with comparable parameters can generate more transferable representations than CNN counterparts, we propose a Win-Win TRansformer framework (WinTR) that separately explores the domain-specific knowledge for each domain and meanwhile interchanges cross-domain knowledge. Specifically, we learn two different mappings using two individual classification tokens in the Transformer, and design for each one a domain-specific classifier. The cross-domain knowledge is transferred via source guided label refinement and single-sided feature alignment with respect to source or target, which keeps the integrity of domain-specific information. Extensive experiments on three benchmark datasets show that our method outperforms the state-of-the-art UDA methods, validating the effectiveness of exploiting both domain-specific and invariant
ITA: Image-Text Alignments for Multi-Modal Named Entity Recognition
Dec 13, 2021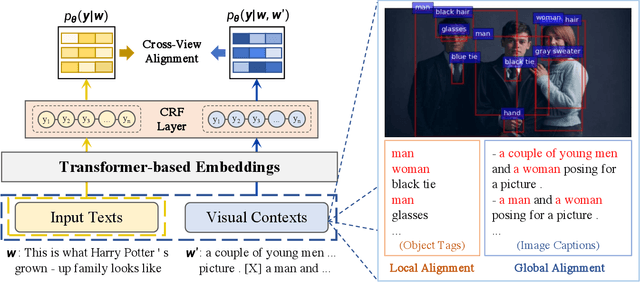
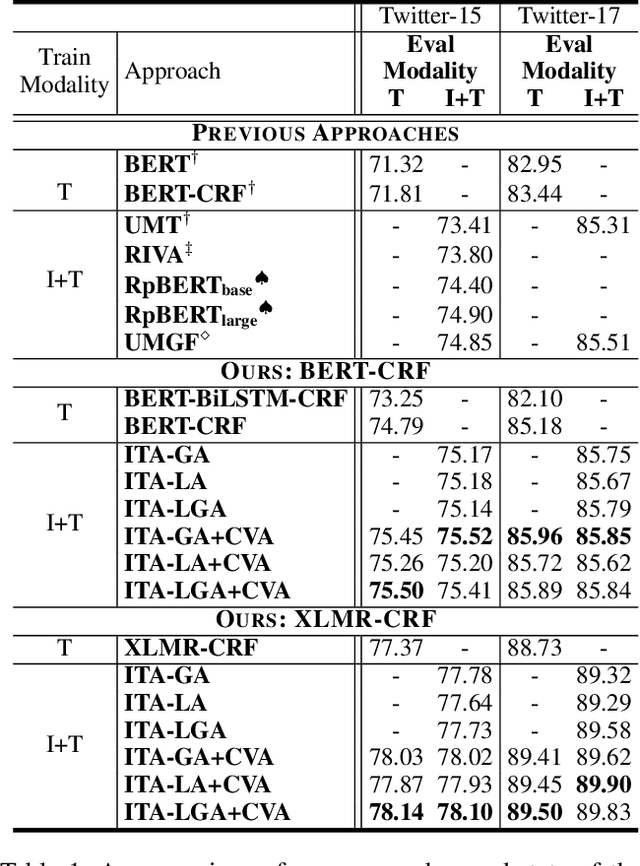
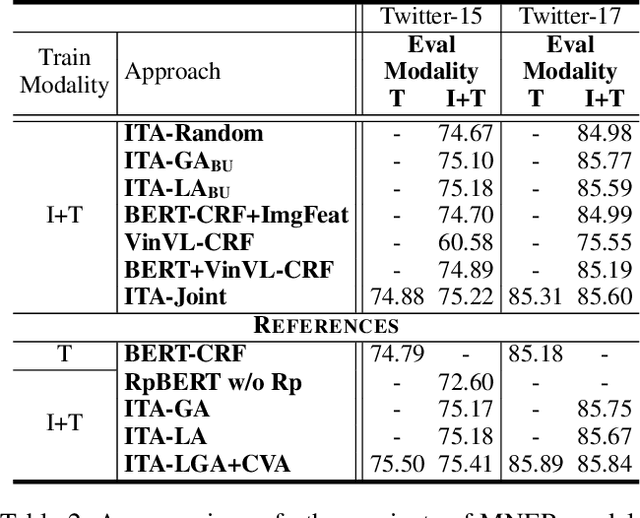
Recently, Multi-modal Named Entity Recognition (MNER) has attracted a lot of attention. Most of the work utilizes image information through region-level visual representations obtained from a pretrained object detector and relies on an attention mechanism to model the interactions between image and text representations. However, it is difficult to model such interactions as image and text representations are trained separately on the data of their respective modality and are not aligned in the same space. As text representations take the most important role in MNER, in this paper, we propose {\bf I}mage-{\bf t}ext {\bf A}lignments (ITA) to align image features into the textual space, so that the attention mechanism in transformer-based pretrained textual embeddings can be better utilized. ITA first locally and globally aligns regional object tags and image-level captions as visual contexts, concatenates them with the input texts as a new cross-modal input, and then feeds it into a pretrained textual embedding model. This makes it easier for the attention module of a pretrained textual embedding model to model the interaction between the two modalities since they are both represented in the textual space. ITA further aligns the output distributions predicted from the cross-modal input and textual input views so that the MNER model can be more practical and robust to noises from images. In our experiments, we show that ITA models can achieve state-of-the-art accuracy on multi-modal Named Entity Recognition datasets, even without image information.
Exploring Fusion Strategies for Accurate RGBT Visual Object Tracking
Jan 21, 2022
We address the problem of multi-modal object tracking in video and explore various options of fusing the complementary information conveyed by the visible (RGB) and thermal infrared (TIR) modalities including pixel-level, feature-level and decision-level fusion. Specifically, different from the existing methods, paradigm of image fusion task is heeded for fusion at pixel level. Feature-level fusion is fulfilled by attention mechanism with channels excited optionally. Besides, at decision level, a novel fusion strategy is put forward since an effortless averaging configuration has shown the superiority. The effectiveness of the proposed decision-level fusion strategy owes to a number of innovative contributions, including a dynamic weighting of the RGB and TIR contributions and a linear template update operation. A variant of which produced the winning tracker at the Visual Object Tracking Challenge 2020 (VOT-RGBT2020). The concurrent exploration of innovative pixel- and feature-level fusion strategies highlights the advantages of the proposed decision-level fusion method. Extensive experimental results on three challenging datasets, \textit{i.e.}, GTOT, VOT-RGBT2019, and VOT-RGBT2020, demonstrate the effectiveness and robustness of the proposed method, compared to the state-of-the-art approaches. Code will be shared at \textcolor{blue}{\emph{https://github.com/Zhangyong-Tang/DFAT}.