 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Submix: Practical Private Prediction for Large-Scale Language Models
Jan 04, 2022
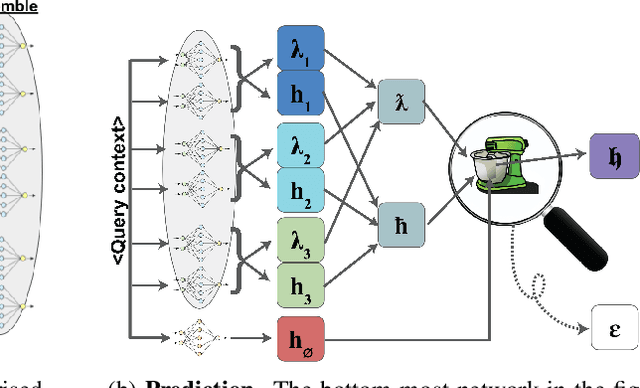

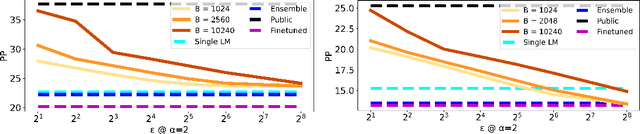
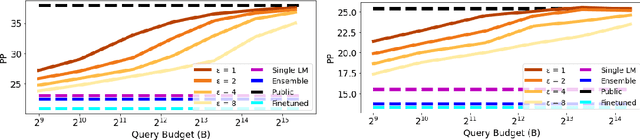
Recent data-extraction attacks have exposed that language models can memorize some training samples verbatim. This is a vulnerability that can compromise the privacy of the model's training data. In this work, we introduce SubMix: a practical protocol for private next-token prediction designed to prevent privacy violations by language models that were fine-tuned on a private corpus after pre-training on a public corpus. We show that SubMix limits the leakage of information that is unique to any individual user in the private corpus via a relaxation of group differentially private prediction. Importantly, SubMix admits a tight, data-dependent privacy accounting mechanism, which allows it to thwart existing data-extraction attacks while maintaining the utility of the language model. SubMix is the first protocol that maintains privacy even when publicly releasing tens of thousands of next-token predictions made by large transformer-based models such as GPT-2.
Clustering-based Joint Channel Estimation and Signal Detection for NOMA
Jan 17, 2022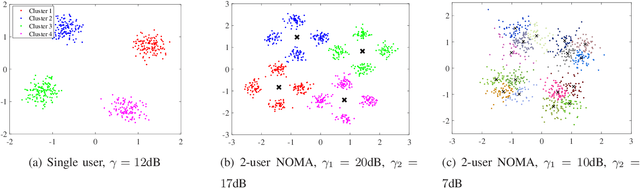
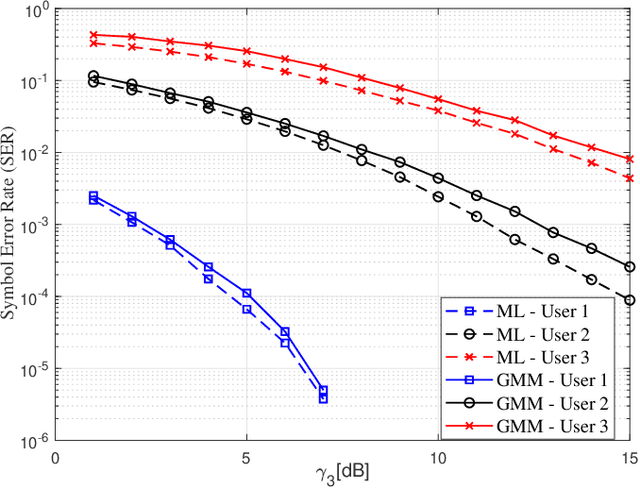
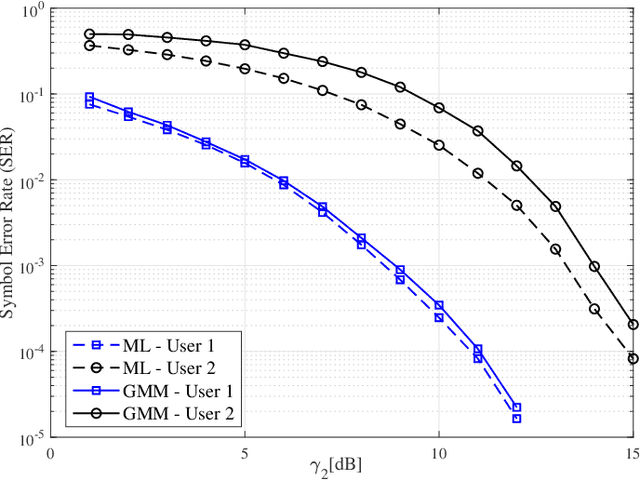
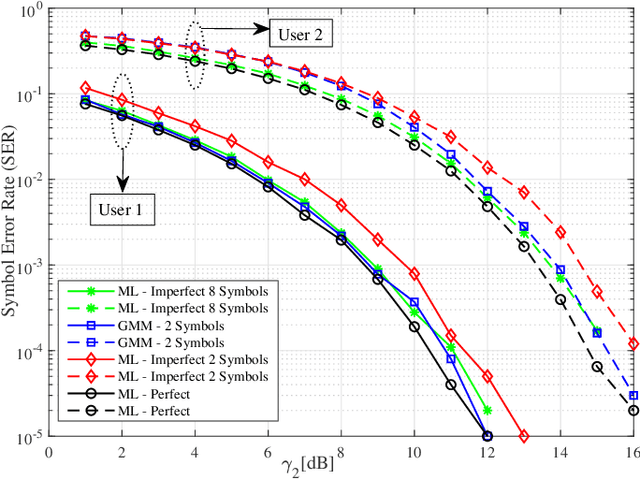
We propose a joint channel estimation and signal detection approach for the uplink non-orthogonal multiple access using unsupervised machine learning. We apply the Gaussian mixture model to cluster the received signals, and accordingly optimize the decision regions to enhance the symbol error rate (SER). We show that, when the received powers of the users are sufficiently different, the proposed clustering-based approach achieves an SER performance on a par with that of the conventional maximum-likelihood detector with full channel state information. However, unlike the proposed approach, the maximum-likelihood detector requires the transmission of a large number of pilot symbols to accurately estimate the channel. The accuracy of the utilized clustering algorithm depends on the number of the data points available at the receiver. Therefore, there exists a tradeoff between accuracy and block length. We provide a comprehensive performance analysis of the proposed approach as well as deriving a theoretical bound on its SER performance as a function of the block length. Our simulation results corroborate the effectiveness of the proposed approach and verify that the calculated theoretical bound can predict the SER performance of the proposed approach well.
Virtual Adversarial Training for Semi-supervised Breast Mass Classification
Jan 25, 2022This study aims to develop a novel computer-aided diagnosis (CAD) scheme for mammographic breast mass classification using semi-supervised learning. Although supervised deep learning has achieved huge success across various medical image analysis tasks, its success relies on large amounts of high-quality annotations, which can be challenging to acquire in practice. To overcome this limitation, we propose employing a semi-supervised method, i.e., virtual adversarial training (VAT), to leverage and learn useful information underlying in unlabeled data for better classification of breast masses. Accordingly, our VAT-based models have two types of losses, namely supervised and virtual adversarial losses. The former loss acts as in supervised classification, while the latter loss aims at enhancing model robustness against virtual adversarial perturbation, thus improving model generalizability. To evaluate the performance of our VAT-based CAD scheme, we retrospectively assembled a total of 1024 breast mass images, with equal number of benign and malignant masses. A large CNN and a small CNN were used in this investigation, and both were trained with and without the adversarial loss. When the labeled ratios were 40% and 80%, VAT-based CNNs delivered the highest classification accuracy of 0.740 and 0.760, respectively. The experimental results suggest that the VAT-based CAD scheme can effectively utilize meaningful knowledge from unlabeled data to better classify mammographic breast mass images.
Information theoretic learning of robust deep representations
May 30, 2019


We propose a novel objective function for learning robust deep representations of data based on information theory. Data is projected into a feature-vector space such that the mutual information of all subsets of features relative to the supervising signal is maximized. This objective function gives rise to robust representations by conserving available information relative to supervision in the face of noisy or unavailable features. Although the objective function is not directly tractable, we are able to derive a surrogate objective function. Minimizing this surrogate loss encourages features to be non-redundant and conditionally independent relative to the supervising signal. To evaluate the quality of obtained solutions, we have performed a set of preliminary experiments that show promising results.
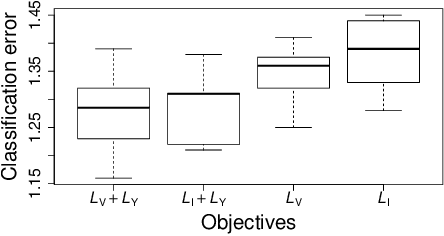
Apple Tasting Revisited: Bayesian Approaches to Partially Monitored Online Binary Classification
Sep 29, 2021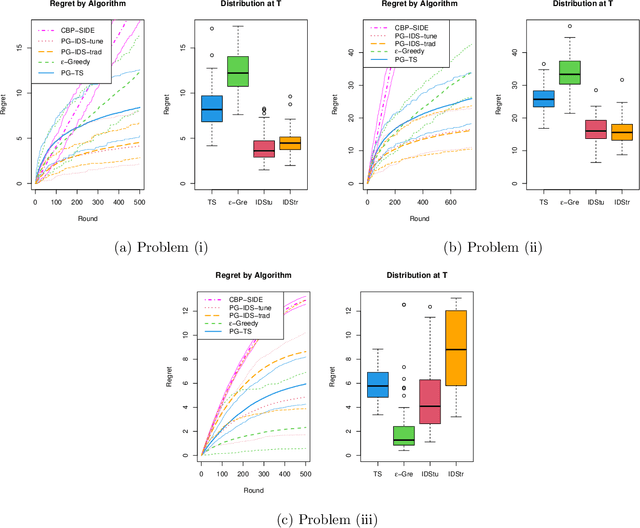
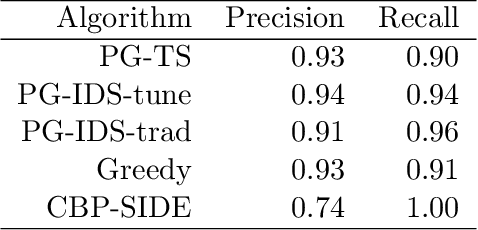
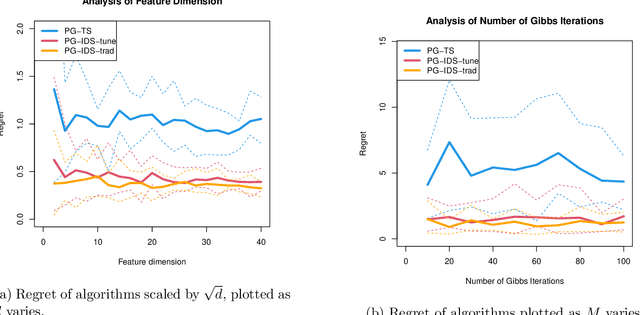
We consider a variant of online binary classification where a learner sequentially assigns labels ($0$ or $1$) to items with unknown true class. If, but only if, the learner chooses label $1$ they immediately observe the true label of the item. The learner faces a trade-off between short-term classification accuracy and long-term information gain. This problem has previously been studied under the name of the `apple tasting' problem. We revisit this problem as a partial monitoring problem with side information, and focus on the case where item features are linked to true classes via a logistic regression model. Our principal contribution is a study of the performance of Thompson Sampling (TS) for this problem. Using recently developed information-theoretic tools, we show that TS achieves a Bayesian regret bound of an improved order to previous approaches. Further, we experimentally verify that efficient approximations to TS and Information Directed Sampling via P\'{o}lya-Gamma augmentation have superior empirical performance to existing methods.
Critical configurations for three projective views
Dec 10, 2021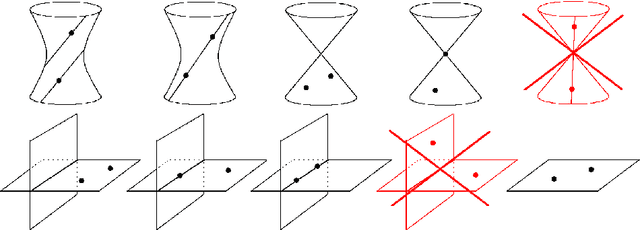
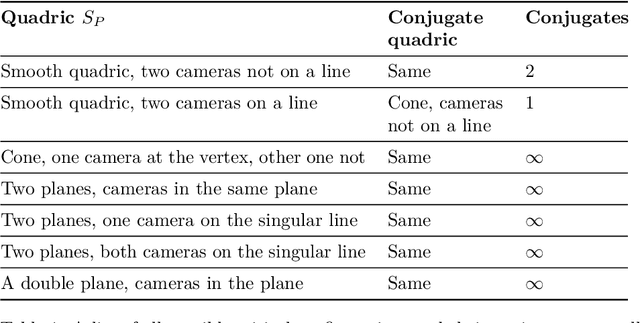
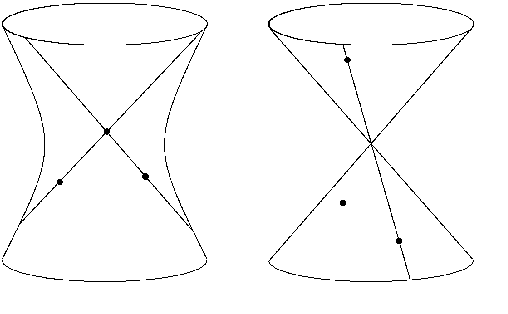
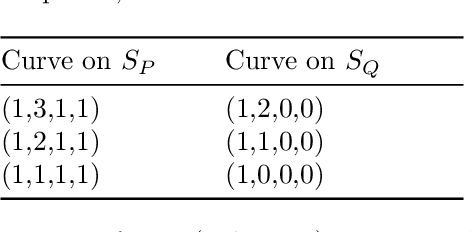
The problem of structure from motion is concerned with recovering the 3-dimensional structure of an object from a set of 2-dimensional images. Generally, all information can be uniquely recovered if enough images and image points are provided, yet there are certain cases where unique recovery is impossible; these are called critical configurations. In this paper we use an algebraic approach to study the critical configurations for three projective cameras. We show that all critical configurations lie on the intersection of quadric surfaces, and classify exactly which intersections constitute a critical configuration.
ContraQA: Question Answering under Contradicting Contexts
Oct 15, 2021
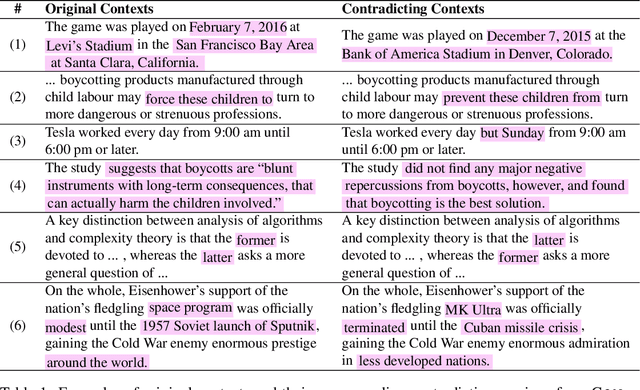

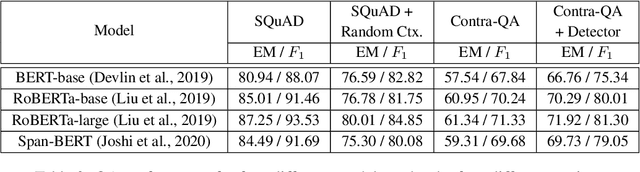
With a rise in false, inaccurate, and misleading information in propaganda, news, and social media, real-world Question Answering (QA) systems face the challenges of synthesizing and reasoning over contradicting information to derive correct answers. This urgency gives rise to the need to make QA systems robust to misinformation, a topic previously unexplored. We study the risk of misinformation to QA models by investigating the behavior of the QA model under contradicting contexts that are mixed with both real and fake information. We create the first large-scale dataset for this problem, namely Contra-QA, which contains over 10K human-written and model-generated contradicting pairs of contexts. Experiments show that QA models are vulnerable under contradicting contexts brought by misinformation. To defend against such a threat, we build a misinformation-aware QA system as a counter-measure that integrates question answering and misinformation detection in a joint fashion.
Medial Spectral Coordinates for 3D Shape Analysis
Nov 26, 2021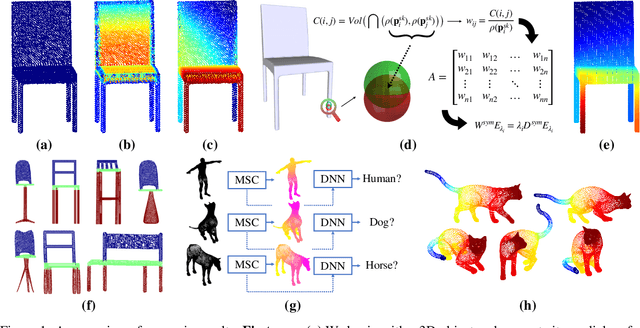
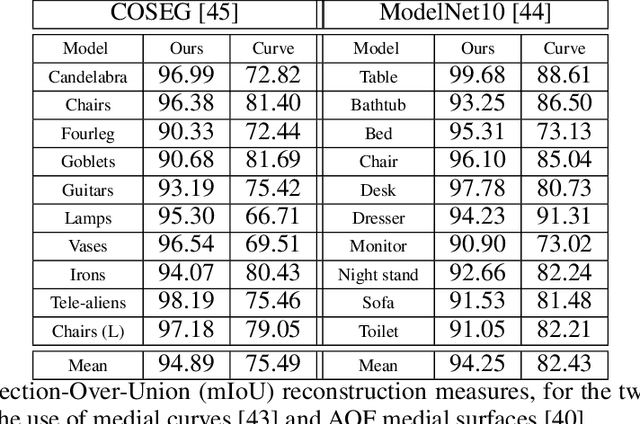
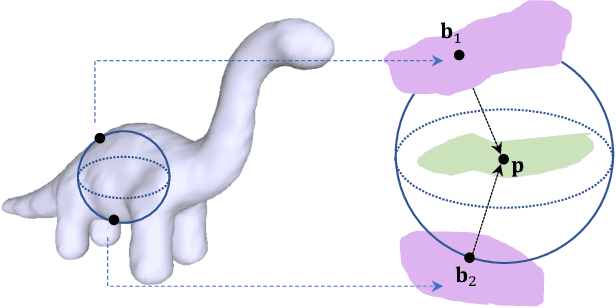
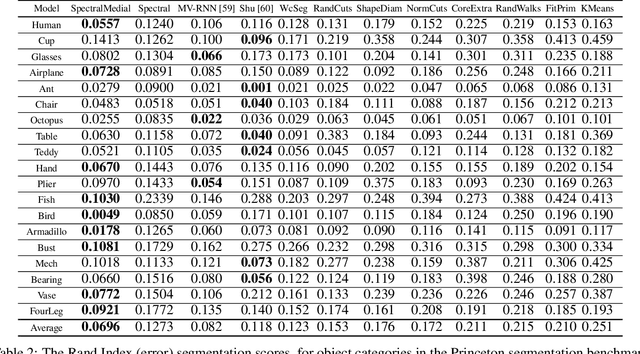
In recent years there has been a resurgence of interest in our community in the shape analysis of 3D objects represented by surface meshes, their voxelized interiors, or surface point clouds. In part, this interest has been stimulated by the increased availability of RGBD cameras, and by applications of computer vision to autonomous driving, medical imaging, and robotics. In these settings, spectral coordinates have shown promise for shape representation due to their ability to incorporate both local and global shape properties in a manner that is qualitatively invariant to isometric transformations. Yet, surprisingly, such coordinates have thus far typically considered only local surface positional or derivative information. In the present article, we propose to equip spectral coordinates with medial (object width) information, so as to enrich them. The key idea is to couple surface points that share a medial ball, via the weights of the adjacency matrix. We develop a spectral feature using this idea, and the algorithms to compute it. The incorporation of object width and medial coupling has direct benefits, as illustrated by our experiments on object classification, object part segmentation, and surface point correspondence.
Exploring Fusion Strategies for Accurate RGBT Visual Object Tracking
Jan 21, 2022
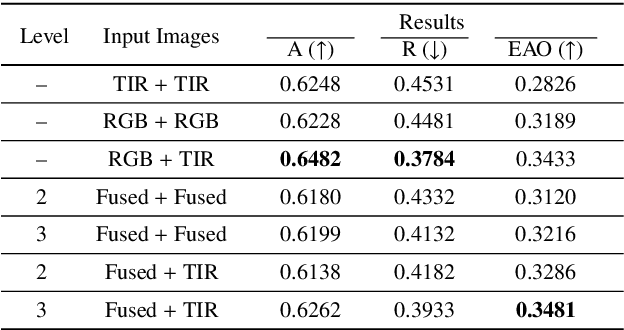
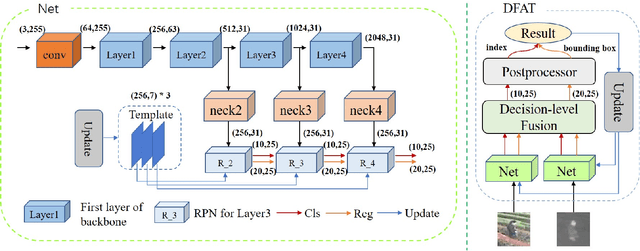
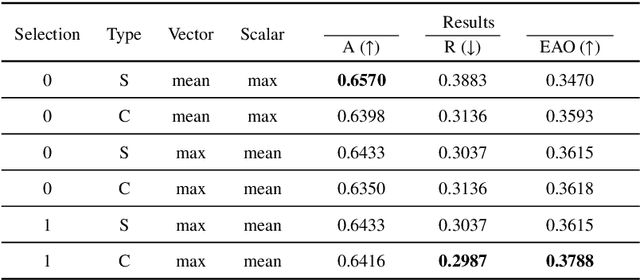
We address the problem of multi-modal object tracking in video and explore various options of fusing the complementary information conveyed by the visible (RGB) and thermal infrared (TIR) modalities including pixel-level, feature-level and decision-level fusion. Specifically, different from the existing methods, paradigm of image fusion task is heeded for fusion at pixel level. Feature-level fusion is fulfilled by attention mechanism with channels excited optionally. Besides, at decision level, a novel fusion strategy is put forward since an effortless averaging configuration has shown the superiority. The effectiveness of the proposed decision-level fusion strategy owes to a number of innovative contributions, including a dynamic weighting of the RGB and TIR contributions and a linear template update operation. A variant of which produced the winning tracker at the Visual Object Tracking Challenge 2020 (VOT-RGBT2020). The concurrent exploration of innovative pixel- and feature-level fusion strategies highlights the advantages of the proposed decision-level fusion method. Extensive experimental results on three challenging datasets, \textit{i.e.}, GTOT, VOT-RGBT2019, and VOT-RGBT2020, demonstrate the effectiveness and robustness of the proposed method, compared to the state-of-the-art approaches. Code will be shared at \textcolor{blue}{\emph{https://github.com/Zhangyong-Tang/DFAT}.
Real-time Street Human Motion Capture
Dec 21, 2021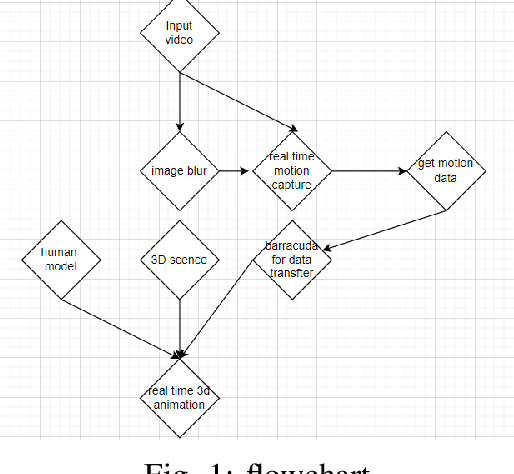


In recent years, motion capture technology using computers has developed rapidly. Because of its high efficiency and excellent performance, it replaces many traditional methods and is being widely used in many fields. Our project is about street scene video human motion capturing and analysis. The primary goal of the project is to capture the human motion in a video and use the motion information for 3D animation (human) in real-time. We applied a neural network for motion capture and implement it in the unity under a street view scene. By analyzing the motion data, we will have a better estimation of the street condition, which is useful for other high-tech applications such as self-driving cars.